Elasticsearch环境搭建|ES单机|ES单节点模式启动|ES集群搭建|ES集群环境搭建
文章目录
- 版本选择
- 单机ES安装与配置
- 创建非root用户
- 导入安装包
- 安装包解压
- 配置JDK环境变量
- 配置single-node
- 配置JVM参数
- 后台启动|启动日志查看
- 启动成功,访问
- 终端访问
- 浏览器访问
- Kibana安装
- 修改配置
- 后台启动|启动日志查看
- 浏览器访问
- ES三节点集群搭建
- 停止es服务
- 域名配置
- 配置修改
- 集群配置
- 配置说明
- 配置节点1
- 配置节点2
- 配置节点3
- 分别启动
- 验证集群搭建成功
- Kibana配置修改
- 重启Kibana
- 查看进程
- 停止Kibana服务
- 启动Kibana
- 验证
- ES开启认证
版本选择
在[ElasticSearch]分析京东商城商品搜索实现|聚合|全文查找|搜索引擎|ES Java High Level Rest Client|ES Java API Client这篇文章里进行了说明,使用的7.17.3版本,不再赘述。
- Elasticsearch 7.17.3下载地址
- Kibana 7.17.3下载地址
- 环境CentOS 7.6.1
单机ES安装与配置
创建非root用户
ES不允许root用户运行,使用root用户为其创建一个用户es,为用户es配置密码,并切换到es用户。
adduser es
passwd es
su es
导入安装包
将下载好的Elasticsearch,Kibana导入到es用户home目录
[es@polaris ~]$ cd ~
[es@polaris ~]$ pwd
/home/es
[es@polaris ~]$ ls
kibana-7.17.3-linux-x86_64.tar.gz
elasticsearch-7.17.3-linux-x86_64.tar.gz
安装包解压
tar -zxvf elasticsearch-7.17.3-linux-x86_64.tar.gz
tar -zxvf kibana-7.17.3-linux-x86_64.tar.gz
配置JDK环境变量
当前还在用户home目录下,
添加两行(ES7.x及以后版本内置了jdk)
export ES_JAVA_HOME=/home/es/elasticsearch-7.17.3/jdk
export ES_HOME=/home/es/elasticsearch-7.17.3
[es@polaris ~]$ vim .bash_profile # .bash_profile# Get the aliases and functions
if [ -f ~/.bashrc ]; then. ~/.bashrc
fi# User specific environment and startup programsexport ES_JAVA_HOME=/home/es/elasticsearch-7.17.3/jdk
export ES_HOME=/home/es/elasticsearch-7.17.3PATH=$PATH:$HOME/.local/bin:$HOME/binexport PATH
执行以下命令,使之生效。(之后使用es用户开启一个终端会话(参考:ES环境变量设置的问题,分析用户级环境变量设置与读取,报错分析与解决⚠️ usage of JAVA_HOME is deprecated, use ES_JAVA_HOME),该环境变量配置就会是生效的)
source .bash_profile
配置single-node
切换到es目录
cd elasticsearch-7.17.3/
# 0. 备份一下原配置文件
cp config/elasticsearch.yml config/elasticsearch.yml.origin
# 修改配置
vim config/elasticsearch.yml
# 1. 开启远程访问,监听所有网卡,可以在虚拟机外部如win主机上访问
network.host: 0.0.0.0
# 2. 单节点模式
discovery.type: single-node
配置JVM参数
官方建议:将 Xms 和 Xmx 设置为不超过总内存的 50%。 Elasticsearch 需要内存用于 JVM堆以外的用途。例如,Elasticsearch 使用堆外缓冲区来实现高效的网络通信,并依赖操作系统的文件系统缓存来高效地访问文件。 JVM本身也需要一些内存。Elasticsearch 使用的内存多于 Xmx 设置配置的限制是正常的。
机器情况:CPU 4核8线程,内存16GB,打算搭三节点集群演示,主机上还会运行一些东西,因此为每个虚拟机分配了2GB的内存,处理器数量2个,单个处理器内核数量设置为了2个,处理器内核总数为4
虚拟机内存2GB,堆内存设置不超过50%,这里设置1GB
# 0. 备份一下原配置文件
cp config/jvm.options config/jvm.options.origin
# 修改堆内存
vim config/jvm.option-Xms1g
-Xmx1g
后台启动|启动日志查看
后台启动可以保证启动成功后,当前会话断开,es还是在运行,不会随着终端会话关闭而终止。
bin/elasticsearch -d
如果启动有问题可以查看es启动日志
tail -f logs/elasticsearch.log
启动成功,访问
终端访问
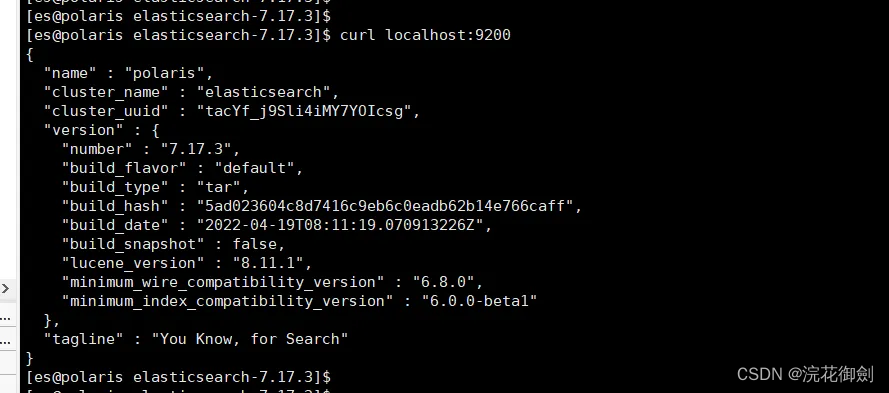
浏览器访问
如果浏览器访问不通,那么可以关闭防火墙简化操作,
云服务器的话可以通过配置安全组规则,进行端口映射,开放端口(参考:添加安全组规则)
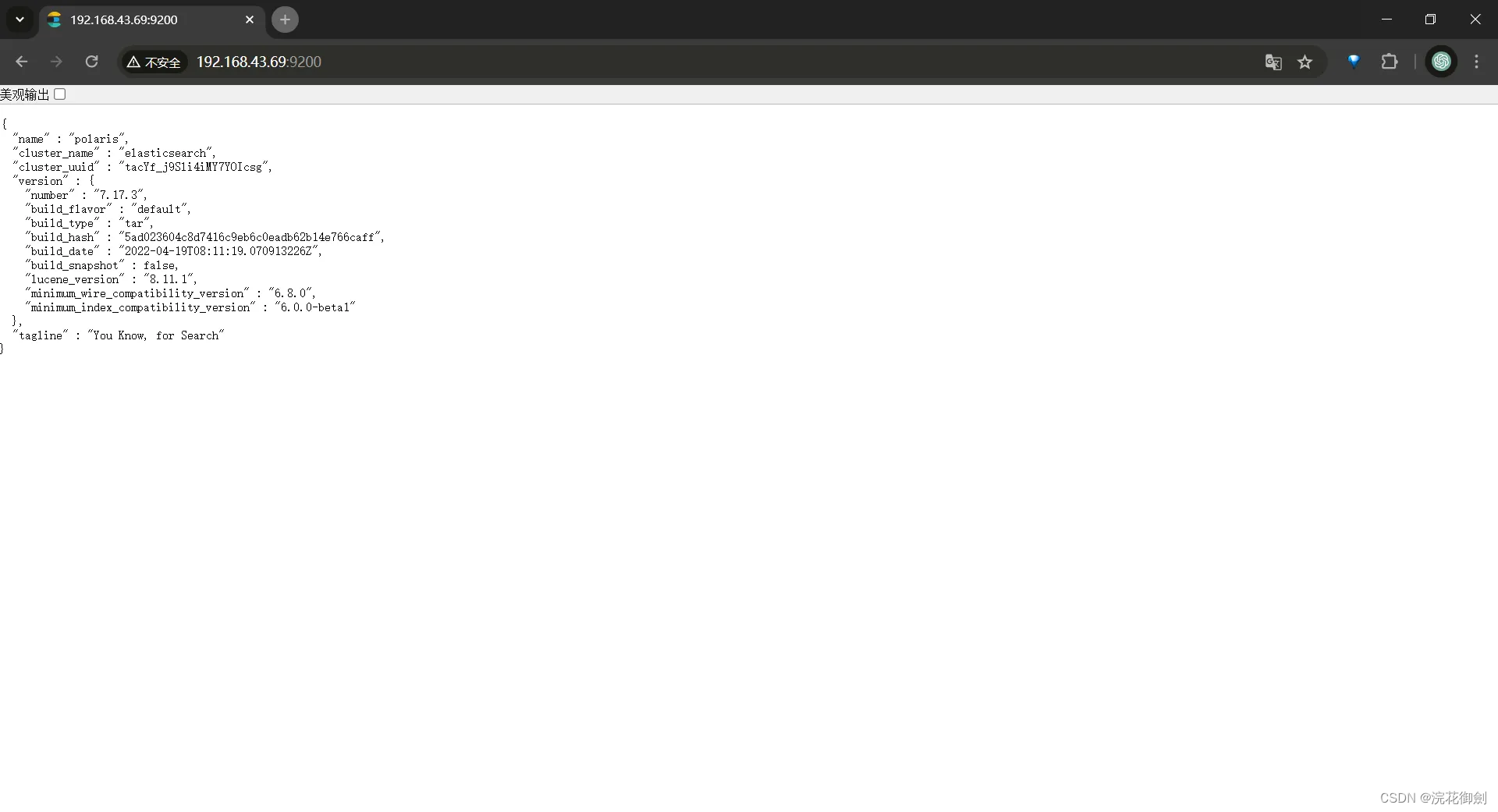
这样单节点的es就可以正常工作,之后通过修改配置把他加入到集群。
Kibana安装
Kibana是官方提供的ES一个客户端连接工具。
只在一台虚拟机上安装即可(或者win主机上安装一个都行),注意修改配置,使之能够访问到es(单机或集群),以及可以对外提供服务(Kibana对外能够被访问)。
这里是在虚拟机上安装。
修改配置
cd ~/kibana-7.17.3-linux-x86_64/
#备份一个源文件
cp config/kibana.yml config/kibana.yml.origin
#修改配置
vim config/kibana.yml#指定Kibana服务器监听的端口号
server.port: 5601
#开启远程访问,监听所有网卡,可以在虚拟机外部如win主机上访问
server.host: "0.0.0.0"
#指定Kibana连接到的ES实例的访问地址,
#如果访问本地的ES(Kibana与ES安装在同一台服务器上)就是localhost,访问其他的换成ip
#集群的话就配上所有的节点elasticsearch.hosts: ["http://192.168.43.69:9200", "http://192.168.43.133:9200", "http://192.168.43.225:9200"]
elasticsearch.hosts: ["http://localhost:9200"]
#将 Kibana 的界面语言设置为简体中文。默认en
i18n.locale: "zh-CN"
后台启动|启动日志查看
后台启动可以保证启动成功后,当前会话断开,kibana还是在运行,不会随着终端会话关闭而终止。
nohup bin/kibana &
如果启动有问题可以查看Kibana启动日志
tail -f nohup.out
浏览器访问
win主机浏览器访问机器ip+“:”+port(5601),
http://192.168.43.69:5601/
到此,Elasticsearch环境及客户端Kibana就安装配置完成。
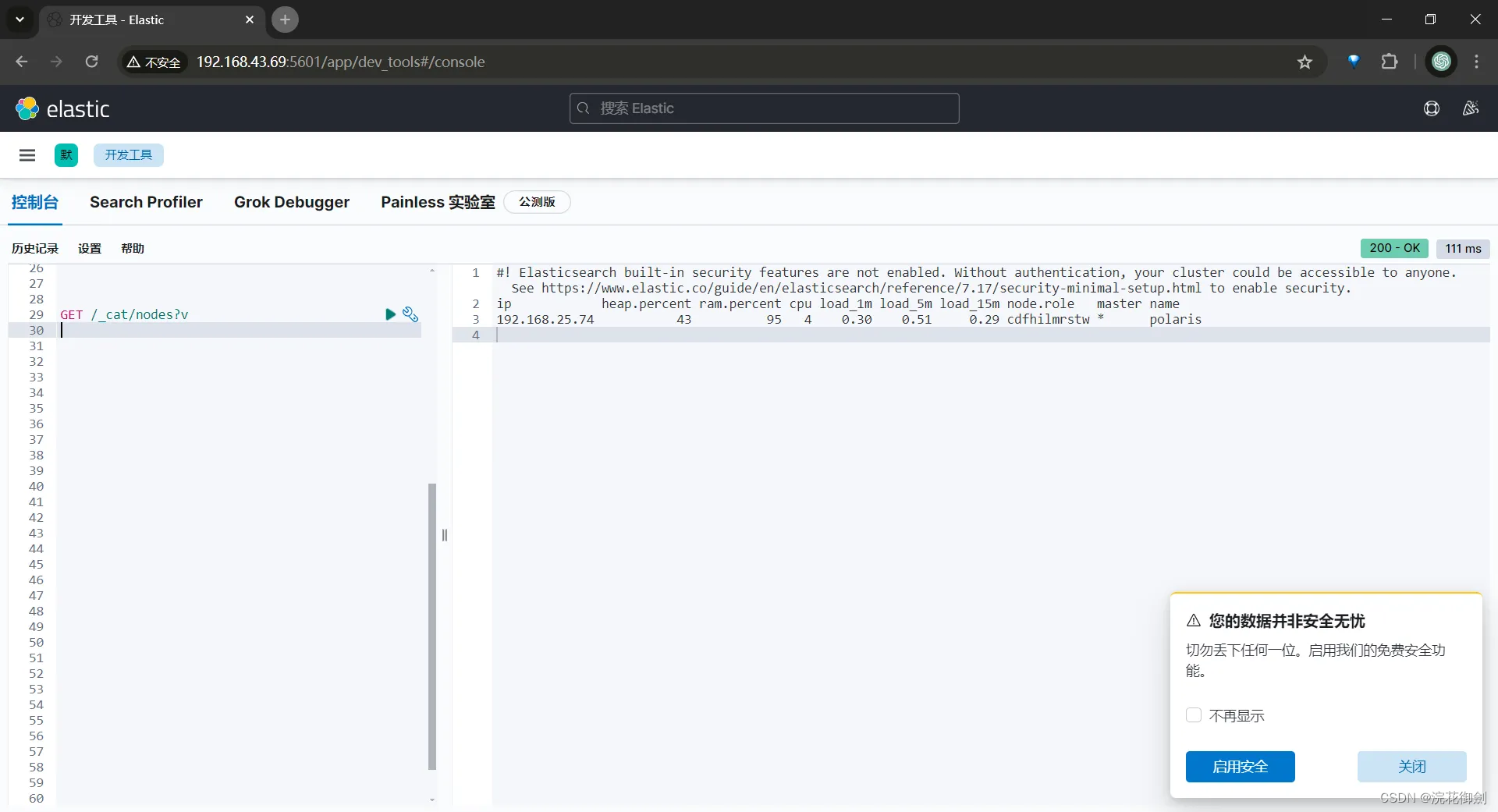
这里查看到的节点ip是192.168.25.74而不是我们访问的机器ip 192.168.43.69,是有问题的(正常情况是不会有这个问题的)。这个问题的原因参考:[ES] ElasticSearch节点加入集群失败经历分析主节点选举、ES网络配置 [publish_address不是当前机器ip]
下面说明ES集群搭建方法。
ES三节点集群搭建
可以把刚才的虚拟机克隆出额外的两个,也可以在额外的两个虚拟机上重复上面es的安装过程(Kibana不需要再装了,它只是个es连接工具,装一个就行了)
停止es服务
#查看es进程
ps -ef|grep elasticsearch
#停止es运行
kill pid #pid是上面命令查出来的进程号
域名配置
三台机器都切换root用户,配置机器ip与域名对应关系,用于在服务发现时,集群内的各节点通过这个域名彼此可以找到彼此。
su
vim /etc/hosts192.168.43.69 es-node1
192.168.43.133 es-node2
192.168.43.225 es-node3
之后再切换回es用户
su es
配置修改
注释掉单节点
#注释掉单节点
#discovery.type: single-node
集群配置
注意:数据目录日志目录单独指定,要和之前单机启动区别开
配置说明
- cluster.name:集群名称,指定一个(避免因未指定,启动一个es就会加入到集群中),配置好其他属性,然后集群同名才可加入到这个集群中。
- node.name:节点名字,集群内唯一
- node.master:是否有资格为master节点,默认为true,表示这个节点有资格成为主节点(master node)。主节点主要负责集群级别的操作,如创建或删除索引、跟踪集群中哪些节点是活动的等。
- node.data:是否为data数据节点,默认为true,表示这个节点也是一个数据节点(data node),它会存储索引数据并处理搜索请求。
- http.cors.enabled: true:允许跨源资源共享(CORS)。当你想从另一个域的网页或应用访问这个Elasticsearch节点时,CORS允许这样的请求
- http.cors.allow-origin: “*” : 允许来自任何域的CORS请求。但出于安全考虑,通常不建议在生产环境中使用*,而是指定特定的域名。
- path.data:定义了Elasticsearch用于存储索引数据的路径。
- path.logs:定义了Elasticsearch存储其日志文件的路径。
- network.host: 0.0.0.0:告诉Elasticsearch监听所有可用的网络接口。但在生产环境中,为了安全起见,通常会指定特定的IP地址或范围。
- discovery.seed_hosts:定义了Elasticsearch在启动时用于发现其他集群成员的初始主机列表。可以通过es-node1、es-node2和es-node3这些主机域名或IP地址来访问其他节点。(上面配置了域名与机器ip的映射关系,因此可以使用机器域名)
- cluster.initial_master_nodes:在Elasticsearch第一次启动时,需要指定哪些节点应该成为主节点(指定node.name指定的节点名字列表)。
配置节点1
vim config/elasticsearch.yml
# node-1
cluster.name: es-clusternode.name: node-1
node.master: true
node.data: truehttp.cors.enabled: true
http.cors.allow-origin: "*"path.data: /home/es/elasticsearch-7.17.3/data-cluster
path.logs: /home/es/elasticsearch-7.17.3/logs-clusternetwork.host: 0.0.0.0discovery.seed_hosts: ["es-node1","es-node2","es-node3"]
cluster.initial_master_nodes: ["node-1", "node-2","node-3"]配置节点2
vim config/elasticsearch.yml
# node-2
cluster.name: es-clusternode.name: node-2
node.master: true
node.data: truehttp.cors.enabled: true
http.cors.allow-origin: "*"path.data: /home/es/elasticsearch-7.17.3/data-cluster
path.logs: /home/es/elasticsearch-7.17.3/logs-clusternetwork.host: 0.0.0.0discovery.seed_hosts: ["es-node1","es-node2","es-node3"]
cluster.initial_master_nodes: ["node-1", "node-2","node-3"]
配置节点3
vim config/elasticsearch.yml
# node-3
cluster.name: es-clusternode.name: node-3
node.master: true
node.data: truehttp.cors.enabled: true
http.cors.allow-origin: "*"path.data: /home/es/elasticsearch-7.17.3/data-clusterpath.logs: /home/es/elasticsearch-7.17.3/logs-clusternetwork.host: 0.0.0.0discovery.seed_hosts: ["es-node1","es-node2","es-node3"]
cluster.initial_master_nodes: ["node-1", "node-2","node-3"]
分别启动
bin/elasticsearch -d
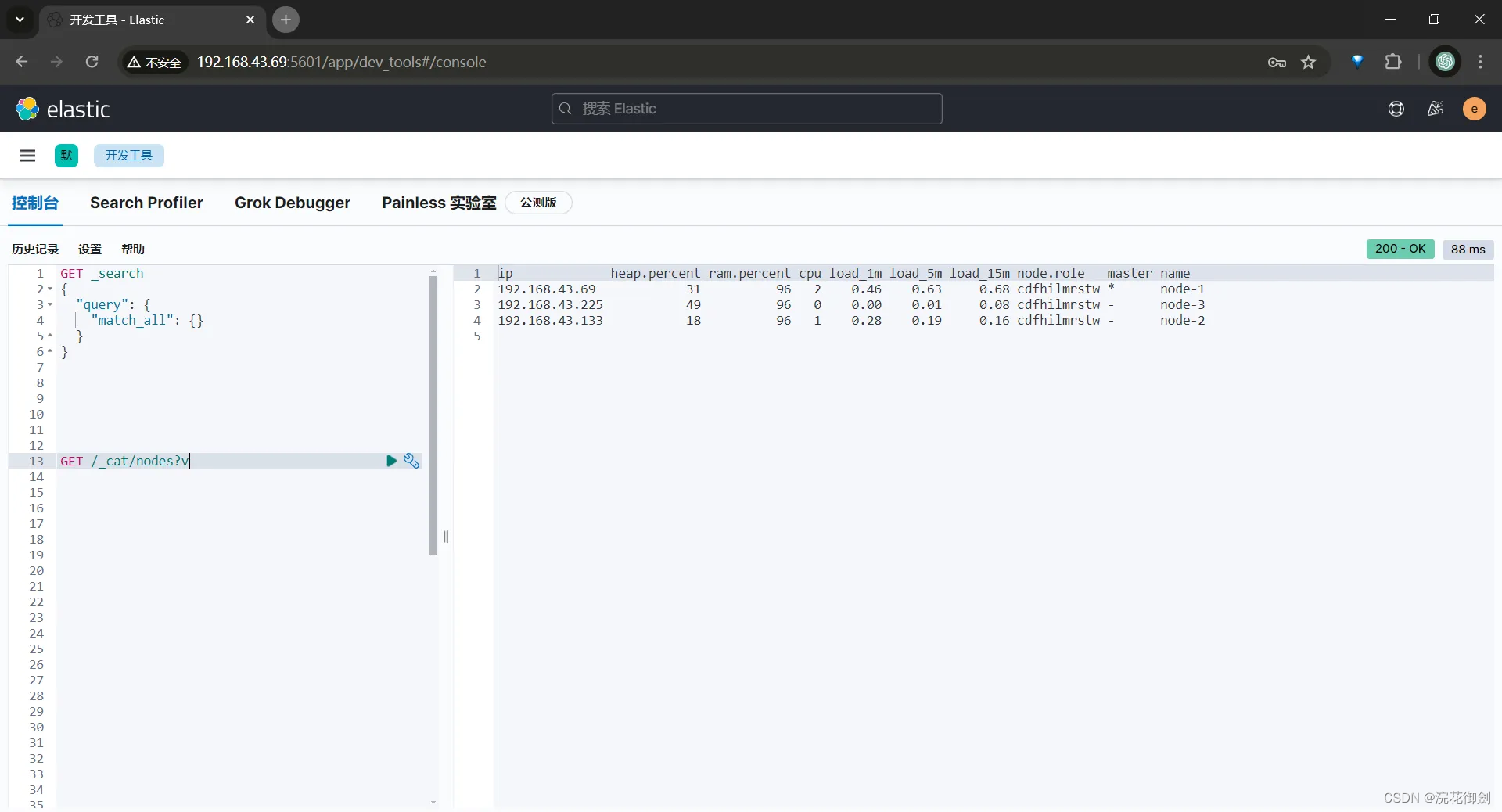
验证集群搭建成功
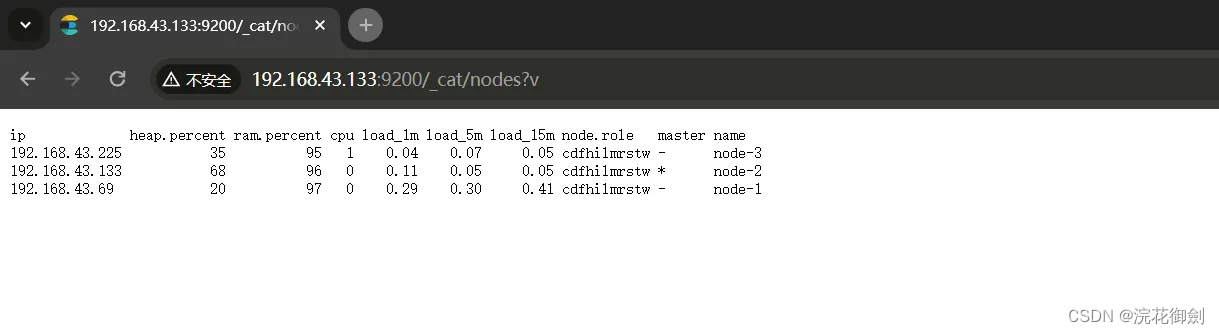
Kibana配置修改
集群搭建成功,更改kibana的配置中的ES instances地址
elasticsearch.hosts: ["http://192.168.43.6:9200", "http://192.168.43.133:9200", "http://192.168.43.225:9200"]
重启Kibana
查看进程
netstat -tunlp|grep 5601
[es@polaris kibana-7.17.3-linux-x86_64]$ netstat -tunlp|grep 5601
(Not all processes could be identified, non-owned process infowill not be shown, you would have to be root to see it all.)
tcp 0 0 0.0.0.0:5601 0.0.0.0:* LISTEN 7379/bin/../node/bi
停止Kibana服务
kill 7379
启动Kibana
nohup bin/kibana &
验证
ES开启认证
参考:Elasticsearch开启认证|为ES设置账号密码|ES账号密码设置|ES单机开启认证|ES集群开启认证
相关文章:
Elasticsearch环境搭建|ES单机|ES单节点模式启动|ES集群搭建|ES集群环境搭建
文章目录 版本选择单机ES安装与配置创建非root用户导入安装包安装包解压配置JDK环境变量配置single-node配置JVM参数后台启动|启动日志查看启动成功,访问终端访问浏览器访问 Kibana安装修改配置后台启动|启动日志查看浏览器访问 ES三节点集群搭建停止es服务域名配置…...
 JAVA 转C#)
System.currentTimeMillis() JAVA 转C#
JAVA中的System.currentTimeMillis() ,指获取当前时间与1970年1月1日00:00:00 GMT之间所差的毫秒数的方法。 这个方法返回的是一个long类型的值,表示从某个固定时间点(通常是UNIX纪元,即1970年1月1日00:00:00 GMT)到…...

人机交互新维度|硕博电子发布双编码器操作面板、无线操作面板等新品
6月15日,硕博电子召开了一场新品发布会,向业界展示了多项前沿技术成果,其中备受瞩目的当属SPM-KEYP-D08双编码器操作面板、SPM-KEYP-D16W无线操作面板、SPR-HT-XK12A无线手持发射端以及SPQ-WT-B01洒水车专用控制面板。这些创新产品的亮相&…...

简单shell
目录 预备知识 fork 进程等待 wait waitpid 环境变量 概念 分类 常见的环境变量及其用途 环境变量的查看与设置 exec系列 函数解释 命名理解 简单shell 预备知识 fork fork 是 Linux 和许多其他类 Unix 系统中的一个重要系统调用,它用于创建一个新的…...

Spring Boot + FreeMarker 实现动态Word文档导出
Spring Boot FreeMarker 实现动态Word文档导出 在现代企业应用中,文档自动化生成是一项提升工作效率的重要功能。Spring Boot与FreeMarker的组合,为开发者提供了一个强大的平台,可以轻松实现动态Word文档的导出。本文将指导你如何使用Sprin…...
3D生物打印的未来:多材料技术的突破
多材料生物打印技术是近年来发展迅速的一项技术,为组织工程和再生医学带来了新的机遇,可以帮助我们更好地理解人体组织的结构和功能,并开发新的治疗方法。 1. 组织构建 复杂性模拟:多材料生物打印技术能够构建具有层次结构和异质…...

充电宝口碑哪个好?好用充电宝品牌有哪些?好用充电宝推荐
充电宝作为我们日常生活和出行的重要伙伴,其品质和性能直接影响着我们的使用体验。今天,就来和大家探讨一下充电宝口碑哪个好,为大家盘点那些备受赞誉的好用充电宝品牌,并向您推荐几款值得入手的充电宝,外出时不再担心…...
)
Pytorch-----(6)
一 、问题 如何计算基于不同变量的操作如矩阵乘法。 二、具体实现 0.4版本以前,张量是包裹在变量之中的,后者有三个属性grad、volatile和 requires_grad属性。(grad 就是梯度属性,requires_grad属性就是 是否需要存储梯度&#x…...
)
leetcode hot100 第三题:最长连续序列(Java)
给定一个未排序的整数数组 nums ,找出数字连续的最长序列(不要求序列元素在原数组中连续)的长度。 请你设计并实现时间复杂度为 O(n) 的算法解决此问题。 示例 1: 输入:nums [100,4,200,1,3,2] 输出:4 解…...

利用Jaspar进行转录因子结合位点预测
前期我们介绍了如何进行ChIP-qPCR验证,里面提到了一个比较重要的因素——扩增范围的选择及引物的设计。相比双荧光素酶、酵母单杂-点对点验证等允许完整启动子验证的实验,ChIP-qPCR要求单次验证的范围尽量控制在150-200bp内。但一个基因的启动子一般有2-…...

Ubuntu添加系统字体
(2024.6.30) 系统字体保存路径在/usr/share/fonts下,如果此目录下缺少字体,则使用其他可视化api(如Python的pygame库)的默认配置时可能会出现乱码问题。 往Ubuntu中添加字体的方法 方法一:手…...

深度学习相关概念及术语总结2
目录 76.AUC77.DBSCAN聚类78.贝叶斯个性化排序79.BPRBandit算法 76.AUC AUC(Area Under the Curve)是一种常用的评价指标,用于衡量分类模型的性能。AUC值代表了模型在不同阈值下的真阳性率(True Positive Rate)和假阳…...

基于改进滑模、经典滑模、最优滑模控制的永磁同步电机调速系统MATLAB仿真
微❤关注“电气仔推送”获得资料(专享优惠) 模型简介 针对永磁同步电机调速系统的响应性能和抗干扰能力问题,本文做了四个仿真,分别为:永磁同步电机的PID控制调速系统、基于传统滑模控制的永磁同步电机的调速系统、最…...

windows环境下创建python虚拟环境
windows环境下创建python虚拟环境 使用virtualenv库创建虚拟环境,可使不同的项目处于不同的环境中 安装方法: pip install virtualenv -i https://pypi.tuna.tsinghua.edu.cn/simple pip install virtualenvwrapper-win -i https://pypi.tuna.tsinghua…...

Fragment切换没变化?解决办法在这里
大家好,今天跟大家分享下如何避免fragment切换失败。方法其实很简单,只要在onCreate方法中初始化一个默认的fragment即可。 //开始事务FragmentTransaction transaction getActivity().getSupportFragmentManager().beginTransaction();transaction.rep…...
Linux系统防火墙iptables(下)
备份与还原iptables规则设置 1、yum -y install iptables iptables-services 安装iptables软件包 2、systemctl start iptables.service 开启服务 3、systemctl enable iptables.service 开机自启 我们对iptables命令行中的设置,都是临时设置,只要遇到服…...

你需要精益管理咨询公司的N+1个理由
近年来,精益管理作为一种被全球众多知名企业验证过的成功管理模式,越来越受到企业的青睐。但是,为何在实施精益管理的过程中,众多企业纷纷选择请咨询公司来协助呢?今天,我们就来一起揭秘这背后的原因。 1. …...

[机器学习]-3 万字话清从传统神经网络到深度学习
神经网络(Neural Networks, NNs)是机器学习的一种重要方法,灵感来源于生物神经系统,由大量互联的节点(称为神经元或单元)组成,通过调整这些节点间的连接权重来学习和表示复杂的非线性关系。传统…...

网络安全等级保护2.0(等保2.0)全面解析
一、等保2.0的定义和背景 网络安全等级保护2.0(简称“等保2.0”)是我国网络安全领域的基本制度、基本策略、基本方法。它是在《中华人民共和国网络安全法》指导下,对我国网络安全等级保护制度进行的重大升级。等保2.0的发布与实施,…...
用Lobe Chat部署本地化, 搭建AI聊天机器人
Lobe Chat可以关联多个模型,可以调用外部OpenAI, gemini,通义千问等, 也可以关联内部本地大模型Ollama, 可以当作聊天对话框消息框来集成使用 安装方法参考: https://github.com/lobehub/lobe-chat https://lobehub.com/zh/docs/self-hosting/platform/…...

Python自动化股票分析工具:从数据采集到可视化报告全流程实战
1. 项目概述:一个面向个人投资者的自动化股票分析工具如果你和我一样,是个对A股市场有点兴趣,但又没时间天天盯盘的上班族,那你肯定也经历过这种纠结:早上开盘前想看看心仪的几只股票有没有什么异动,结果一…...

【Midjourney图像生成黑科技】:树胶重铬酸盐工艺原理、复刻难点与AI艺术胶片质感还原全流程指南
更多请点击: https://intelliparadigm.com 第一章:树胶重铬酸盐工艺的历史溯源与数字时代复兴意义 树胶重铬酸盐工艺(Gum Bichromate Process)诞生于19世纪中叶,是人类最早实现光敏图像复制的化学摄影术之一。其核心原…...
)
【2026年阿里巴巴集团暑期实习- 5月16日-算法岗-第二题- 坏掉的键盘】(题目+思路+JavaC++Python解析+在线测试)
题目内容 小明准备输入一个仅由小写英文字母组成的字符串,但他的键盘在一开始就有且仅有一个按键失灵,导致该字母在原串中的所有出现都没有被输入,最终得到的字符串为 sss。小明还告诉你:原本要输入的完整字符串中任意相邻两个字符都不相同。 请你计算,对于每一个可能的…...

Instagram视频下载终极指南:三分钟掌握免费下载技巧
Instagram视频下载终极指南:三分钟掌握免费下载技巧 【免费下载链接】instagram-video-downloader Simple website made with Next.js for downloading instagram videos with an API that can be used to integrate it in other applications. 项目地址: https:…...

开源大语言模型实战指南:从部署到微调的全流程解析
1. 项目概述:一个为开源大语言模型而生的知识库最近在折腾各种开源大语言模型(LLM)的朋友,估计都遇到过类似的烦恼:模型太多了,从Meta的Llama系列、微软的Phi,到国内的一众优秀模型,…...

6000万美元拿下世界杯:FIFA终于清醒了?
5月15号下午,央视和国际足联官宣了新周期的版权合作。朋友圈里炸开了锅,大家都在讨论那个数字:6000万美元。这是2026年美加墨世界杯的中国区转播权价格。说实话,看到这个价格我有点意外。上一届卡塔尔世界杯,传闻中的版…...

基于规则引擎与AI Agent的Google Ads自动化营销系统设计与实践
1. 项目概述:当AI遇上Google Ads,一个自动化营销引擎的诞生最近在折腾一个挺有意思的项目,起因是发现很多团队在管理Google Ads广告时,依然在重复着大量手动、低效的操作。无论是关键词的日常拓词、否定关键词的筛选,还…...

ubantu安装vscode
在火狐浏览器中搜索vscode官网,找到.deb文件下载,下载完成后文件所在的位置为 主文件夹/下载 文件夹内。...
)
紧急更新!MJ v6.1新增--style raw对表现主义的影响深度解析(附6种失效场景急救方案)
更多请点击: https://intelliparadigm.com 第一章:紧急更新!MJ v6.1新增--style raw对表现主义的影响深度解析(附6种失效场景急救方案) MidJourney v6.1 引入的 --style raw 参数并非简单降低美学修饰,而是…...

【PCL中Ptr释放问题 aligned_free 的2种解决方法】
PCL中Ptr释放问题 aligned_free解决方法1解决方法2解决方法1 添加avx指令,参考这篇博客https://blog.csdn.net/qq_60609496/article/details/123900817 解决方法2 我按照方法1尝试添加了avx或者sse等,都不行,我是要做一个静态库的时候链接…...