Hugging Face Accelerate 两个后端的故事:FSDP 与 DeepSpeed
社区中有两个流行的零冗余优化器 (Zero Redundancy Optimizer,ZeRO)算法实现,一个来自DeepSpeed,另一个来自PyTorch。Hugging FaceAccelerate对这两者都进行了集成并通过接口暴露出来,以供最终用户在训练/微调模型时自主选择其中之一。
本文重点介绍了 Accelerate 对外暴露的这两个后端之间的差异。为了让用户能够在这两个后端之间无缝切换,我们在 Accelerate 中合并了一个精度相关的 PR及一个新的概念指南。
零冗余优化器 (Zero Redundancy Optimizer,ZeRO)https://arxiv.org/abs/1910.02054
DeepSpeedhttps://github.com/microsoft/DeepSpeed
PyTorchhttps://pytorch.org/docs/stable/fsdp.html
Acceleratehttps://hf.co/docs/accelerate/en/index
一个精度相关的 PRhttps://github.com/huggingface/accelerate/issues/2624
一个新的概念指南https://hf.co/docs/accelerate/concept_guides/fsdp_and_deepspeed
FSDP 和 DeepSpeed 可以互换吗?
最近,我们尝试分别使用 DeepSpeed 和 PyTorch FSDP 进行训练,发现两者表现有所不同。我们使用的是 Mistral-7B 基础模型,并以半精度 (bfloat16) 加载。可以看到 DeepSpeed (蓝色) 损失函数收敛良好,但 FSDP (橙色) 损失函数没有收敛,如图 1 所示。
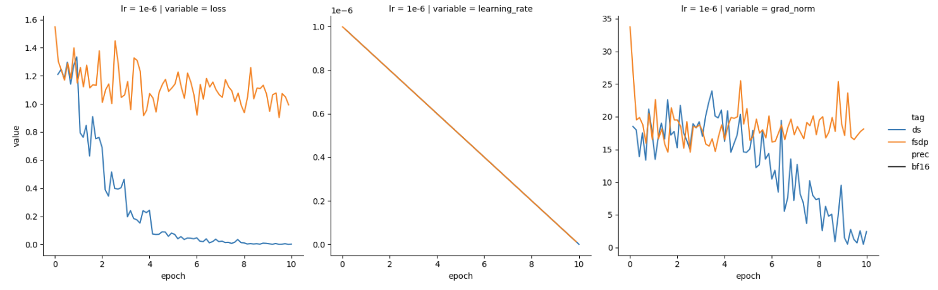
我们猜想可能需要根据 GPU 数量对学习率进行缩放,且由于我们使用了 4 个 GPU,于是我们将学习率提高了 4 倍。然后,损失表现如图 2 所示。
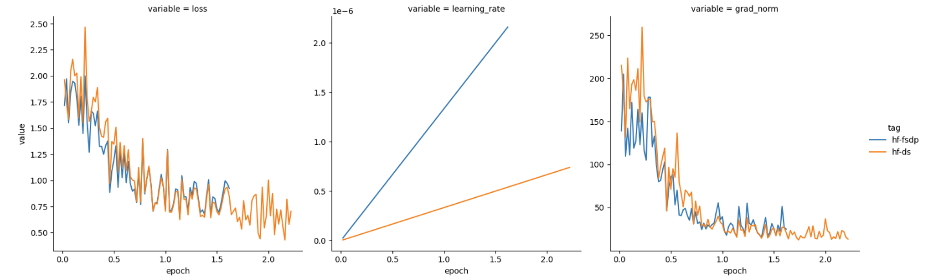
看起来,通过按 GPU 数量缩放 FSDP 学习率,已经达到了预期!然而,当我们在不进行缩放的情况下尝试其他学习率 (1e-5) 时,我们却又观察到这两个框架的损失和梯度范数特征又是趋近一致的,如图 3 所示。
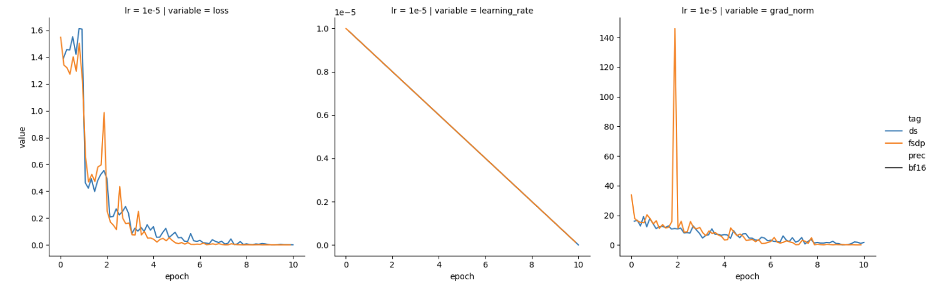
精度很重要
在 DeepSpeed 代码库的 DeepSpeedZeroOptimizer_Stage3 (顾名思义,处理第 3 阶段优化器分片) 实现代码中,我们注意到 trainable_param_groups (可训参数组) 被传入一个内部函数 _setup_for_real_optimizer,该函数会调用另一个名为 _create_fp32_partitions 的函数。正如其名称中的 fp32 所示,DeepSpeed 内部执行了精度上转,并在设计上始终将主权重保持为 fp32 精度。而上转至全精度意味着:同一个学习率,上转后的优化器可以收敛,而原始低精度下的优化器则可能不会收敛。前述现象就是这种精度差异的产物。
在 FSDP 中,在把模型和优化器参数分片到各 GPU 上之前,这些参数首先会被“展平”为一维张量。FSDP 和 DeepSpeed 对这些“展平”参数使用了不同的 dtype,这会影响 PyTorch 优化器的表现。表 1 概述了两个框架各自的处理流程,“本地?”列说明了当前步骤是否是由各 GPU 本地执行的,如果是这样的话,那么上转的内存开销就可以分摊到各个 GPU。
| 流程 | 本地? | 框架 | 详情 |
|---|---|---|---|
模型加载 (如 AutoModel.from_pretrained(..., torch_dtype=torch_dtype)) | ❌ | ||
| 准备,如创建“展平参数” | ✅ | FSDP DeepSpeed | 使用 torch_dtype不管 torch_dtype,直接创建为 float32 |
| 优化器初始化 | ✅ | FSDP DeepSpeed | 用 torch_dtype 创建参数用 float32 创建参数 |
| 训练步 (前向、后向、归约) | ❌ | FSDP DeepSpeed | 遵循fsdp.MixedPrecision 遵循 deepspeed_config_file 中的混合精度设置 |
| 优化器 (准备阶段) | ✅ | FSDP DeepSpeed | 按需上转至 torch_dtype所有均上转至 float32 |
| 优化器 (实际执行阶段) | ✅ | FSDP DeepSpeed | 以 torch_dtype 精度进行以 float32 精度进行 |
表 1:FSDP 与 DeepSpeed 混合精度处理异同
fsdp.MixedPrecisionhttps://pytorch.org/docs/stable/fsdp.html#torch.distributed.fsdp.MixedPrecision
几个要点:
正如 🤗 Accelerate 上的这一问题所述,混合精度训练的经验法则是将可训参数精度保持为
float32。当在大量 GPU 上进行分片时,上转 (如
DeepSpeed中所做的那样) 对内存消耗的影响可能可以忽略不计。然而,当在少量 GPU 上使用DeepSpeed时,内存消耗会显著增加,高达 2 倍。FSDP 的 PyTorch 原生实现不会强制上转,其支持用户以低精度操作 PyTorch 优化器,因此相比
DeepSpeed提供了更大的灵活性。
这一问题https://github.com/huggingface/accelerate/issues/2624#issuecomment-2058402753
在 🤗 Accelerate 中对齐 DeepSpeed 和 FSDP 的行为
为了在🤗 Accelerate 中更好地对齐 DeepSpeed 和 FSDP 的行为,我们可以在启用混合精度时自动对 FSDP 执行上转。我们为此做了一个 PR,该 PR 现已包含在0.30.0 版本中了。
0.30.0 版本https://github.com/huggingface/accelerate/releases/tag/v0.30.0
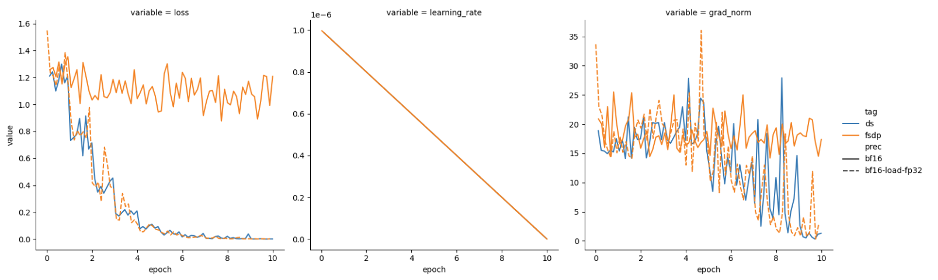
有了这个 PR,FSDP 就能以两种模式运行:
与 DeepSpeed 一致的
混合精度模式针对内存受限场景的低精度模式,如图 4 所示。
表 2 总结了两种新的 FSDP 模式,并与 DeepSpeed 进行了比较。
| 框架 | 模型加载 (torch_dtype) | 混合精度 | 准备 (本地) | 训练 | 优化器 (本地) |
|---|---|---|---|---|---|
| FSDP (低精度模式) | bf16 | 缺省 (无) | bf16 | bf16 | bf16 |
| FSDP (混合精度模式) | bf16 | bf16 | fp32 | bf16 | fp32 |
| DeepSpeed | bf16 | bf16 | fp32 | bf16 | fp32 |
表 2:两种新 FSDP 模式总结及与 DeepSpeed 的对比
吞吐量测试结果
我们使用IBM Granite 7B模型 (其架构为 Meta Llama2) 进行吞吐量比较。我们比较了模型的浮点算力利用率 (Model Flops Utilization,MFU) 和每 GPU 每秒词元数这两个指标,并针对 FSDP (完全分片) 和 DeepSpeed (ZeRO3) 两个场景进行了测量。
IBM Granite 7Bhttps://hf.co/ibm-granite/granite-7b-base
如上文,我们使用 4 张 A100 GPU,超参如下:
batch size 为 8
模型加载为
torch.bfloat16使用
torch.bfloat16混合精度
表 3 表明 FSDP 和 DeepSpeed 的表现类似,这与我们的预期相符。
随着大规模对齐技术 (如InstructLab及GLAN) 的流行,我们计划对结合各种提高吞吐量的方法 (如,序列组装 + 4D 掩码、torch.compile、选择性 checkpointing) 进行全面的吞吐量对比基准测试。
InstructLabhttps://github.com/instructlab
GLANhttps://arxiv.org/abs/2402.13064
| 框架 | 每 GPU 每秒词元数 | **每步耗时 (s) ** | **浮点算力利用率 (MFU) ** |
|---|---|---|---|
| FSDP (混合精度模式) | 3158.7 | 10.4 | 0.41 |
| DeepSpeed | 3094.5 | 10.6 | 0.40 |
表 3:四张 A100 GPU 上 FSDP 和 DeepSpeed 之间的大致吞吐量比较。
最后的话
我们提供了新的概念指南以帮助用户在两个框架之间迁移。该指南可以帮助用户厘清以下问题:
如何实现等效的分片策略?
如何进行高效的模型加载?
FSDP 和 DeepSpeed 中如何管理权重预取?
与 DeepSpeed 对等的 FSDP 封装是什么?
我们在 🤗 Accelerate 中考虑了配置这些框架的各种方式:
使用
accelerate launch从命令行配置从🤗 Accelerate 提供给DeepSpeedhttps://hf.co/docs/accelerate/main/en/package_reference/deepspeed和FSDPhttps://hf.co/docs/accelerate/main/en/package_reference/fsdp的各种
Plugin类中配置
🤗 Accelerate 使得在 FSDP 和 DeepSpeed 之间切换非常丝滑,大部分工作都只涉及更改 Accelerate 配置文件 (有关这方面的说明,请参阅新的概念指南) 。
除了配置变更之外,还有一些如检查点处理方式的差异等,我们一并在指南中进行了说明。
本文中的所有实验都可以使用原始 🤗 Accelerate 问题中的代码重现。
概念指南https://hf.co/docs/accelerate/v0.31.0/en/concept_guides/fsdp_and_deepspeed
原始 🤗 Accelerate 问题https://github.com/huggingface/accelerate/issues/2624
我们计划后续在更大规模 GPU 上进行吞吐量比较,并对各种不同技术进行比较,以在保持模型质量的前提下更好地利用更多的 GPU 进行微调和对齐。
致谢
本工作凝聚了来自多个组织的多个团队的共同努力。始于 IBM 研究中心,特别是发现该问题的 Aldo Pareja 和发现精度差距并解决该问题的 Fabian Lim。Zach Mueller 和Stas Bekman在提供反馈和修复 accelerate 的问题上表现出色。Meta PyTorch 团队的 Less Wright 对有关 FSDP 参数的问题非常有帮助。最后,我们还要感谢 DeepSpeed 团队对本文提供的反馈。
Stas Bekmanhttps://github.com/stas00
DeepSpeedhttps://www.deepspeed.ai/
英文原文: https://hf.co/blog/deepspeed-to-fsdp-and-back
原文作者: Yu Chin Fabian, aldo pareja, Zachary Mueller, Stas Bekman
译者: Matrix Yao (姚伟峰),英特尔深度学习工程师,工作方向为 transformer-family 模型在各模态数据上的应用及大规模模型的训练推理。
相关文章:
Hugging Face Accelerate 两个后端的故事:FSDP 与 DeepSpeed
社区中有两个流行的零冗余优化器 (Zero Redundancy Optimizer,ZeRO)算法实现,一个来自DeepSpeed,另一个来自PyTorch。Hugging FaceAccelerate对这两者都进行了集成并通过接口暴露出来,以供最终用户在训练/微调模型时自主选择其中之…...

TextField是用于在用户界面中输入文本的控件。它广泛应用于表单、搜索框、评论区等需要用户输入文字的场景
TextField是用于在用户界面中输入文本的控件。它广泛应用于表单、搜索框、评论区等需要用户输入文字的场景。以下是对TextField的详细解释,涵盖其各个方面的功能和属性。 基本属性 text 描述:TextField中当前显示的文本。用法:text: "示…...
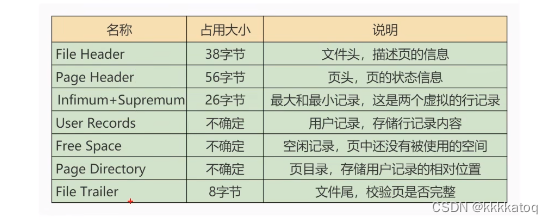
MYSQL 四、mysql进阶 5(InnoDB数据存储结构)
一、数据库的存储结构:页 索引结构给我们提供了高效的索引方式,不过索引信息以及数据记录都是保存在文件上的,确切说时存储在页结构中,另一方面,索引是在存储引擎中实现的,Mysql服务器上的存储引擎负责对表…...
Spring企业开发核心框架-下
五、Spring AOP面向切面编程 1、场景设定和问题复现 ①准备AOP项目 项目名:Spring-aop-annotation ②声明接口 /*** - * / 运算的标准接口!*/ public interface Calculator { int add(int i, int j); int sub(int i, int j); int mul(int i, in…...

X射线底片焊缝缺陷检测
实现四种焊缝缺陷的检测和分割处理。...

直播的js代码debug解析找到protobuf消息的定义
我们都知道直播的弹幕消息是通过websocket发送的,而且是通过protobuf传输的,那么这里面传输了哪些内容,这个proto文件又要怎么定义?每个消息叫什么,消息里面又包含有哪些字段,每个字段又是什么类型…...

详细学习es6扩展运算符
ES6中的扩展运算符(Spread Operator)是一种非常方便的语法,主要用于将可迭代对象(比如数组、字符串等)展开成多个参数。以下是关于ES6扩展运算符的详细内容: 用法: 在数组字面量中展开数组&am…...
HEC-HMS水文模型教程
原文链接:HEC-HMS水文模型教程https://mp.weixin.qq.com/s?__bizMzUzNTczMDMxMg&mid2247607904&idx5&sn1a210328a3fc8f941b433674d8fe2c85&chksmfa826787cdf5ee91d01b6981ebd89deac3e350d747d0fec45ce2ef75d7cb8009341c6f55114d&token90645021…...
Spring Cloud LoadBalancer基础入门与应用实践
官网地址:https://docs.spring.io/spring-cloud-commons/reference/spring-cloud-commons/loadbalancer.html 【1】概述 Spring Cloud LoadBalancer是由SpringCloud官方提供的一个开源的、简单易用的客户端负载均衡器,它包含在SpringCloud-commons中用…...
layui在表格中嵌入上传按钮,并修改上传进度条
当需要在表格中添加上传文件按钮,并不需要弹出填写表单的框的时候,需要在layui中,用按钮触发文件选择 有一点需要说明的是,layui定义table并不是在定义的标签中渲染,而是在紧接着的标签中渲染,所以要获取实…...
14-10 AIGC 项目生命周期——第一阶段
生成式 AI 项目生命周期的整个过程类似于从范围、选择、调整和对齐/协调模型以及应用程序集成开始的顺序依赖过程。流程表明每个步骤都建立在前一步的基础上。有必要了解每个阶段对于项目的成功都至关重要。 下面的流程图重点介绍了生成式 AI 项目生命周期的第一阶段 1 — “范…...

经典小游戏(一)C实现——三子棋
switch(input){case 1:printf("三子棋\n");//这里先测试是否会执行成功break;case 0:printf("退出游戏\n");break;default :printf("选择错误,请重新选择!\n");break;}}while(input);//直到输入的结果为假,循环才会结束} …...
如何利用AI生成可视化图表(统计图、流程图、思维导图……)免代码一键绘制图表
由于目前的AI生成图表工具存在以下几个方面的问题: 大多AI图表平台是纯英文,对国内用户来说不够友好;部分平台在生成图表前仍需选择图表类型、配置项,操作繁琐;他们仍需一份规整的数据表格,需要人为对数据…...
Firefox 编译指南2024 Windows10-使用Git 管理您的Firefox(五)
1. 引言 在现代软件开发中,版本控制系统(VCS)是不可或缺的工具,它不仅帮助开发者有效管理代码的变化,还支持团队协作与项目管理。Mercurial 是一个高效且易用的分布式版本控制系统,其设计目标是简洁、快速…...
ubuntu 18 虚拟机安装(1)
ubuntu 18 虚拟机安装 ubuntu 18.04.6 Ubuntu 18.04.6 LTS (Bionic Beaver) https://releases.ubuntu.com/bionic/ 参考: 设置固定IP地址 https://blog.csdn.net/wowocpp/article/details/126160428 https://www.jianshu.com/p/1d133c0dec9d ubuntu-18.04.6-l…...

Github 上 Star 数最多的大模型应用基础服务 Dify 深度解读(一)
背景介绍 接触过大模型应用开发的研发同学应该都或多或少地听过 Dify 这个大模型应用基础服务,这个项目自从 2023 年上线以来,截止目前(2024-6)已经获得了 35k 多的 star,是目前大模型应用基础服务中最热门的项目之一…...

XStream导出xml文件
最终效果 pom依赖 <dependency><groupId>com.thoughtworks.xstream</groupId><artifactId>xstream</artifactId><version>1.4.11.1</version></dependency>代码 XStreamUtil 这个直接复制即可 import com.thoughtworks.xst…...

陪诊小程序搭建:构建便捷医疗陪诊服务的创新实践
在当今快节奏的社会,医疗服务与人们的生活息息相关。然而,在医疗体系中,患者往往面临着信息不对称、流程繁琐、陪伴需求得不到满足等问题。为了解决这些问题,我们提出了一种创新的解决方案——陪诊小程序,旨在为患者提…...

0139__TCP协议
全网最详细TCP参数讲解,再也不用担心没有面试机会了_tcp的参数-CSDN博客 TCP协议详解-腾讯云开发者社区-腾讯云 TCP-各种参数 - 简书...
家政小程序的开发,带动市场快速发展,提高家政服务质量
当下生活水平逐渐提高,也增加了年轻人的工作压力,同时老龄化也在日益增加,使得大众对家政的需求日益提高,能力、服务质量高的家政人员能够有效提高大众的生活幸福指数。 但是,传统的家政服务模式存在着效率低、用户与…...

轻量级协作平台设计:集成Git与敏捷开发的项目管理实践
1. 项目概述与核心价值最近在团队协作和项目管理工具选型上,又和几个技术负责人聊了一圈。大家普遍的感受是,市面上的工具要么太重,像Jira、Confluence,配置复杂,学习成本高,小团队用起来像“杀鸡用牛刀”&…...

如何在Windows上高效使用酷安社区:UWP桌面客户端完全指南
如何在Windows上高效使用酷安社区:UWP桌面客户端完全指南 【免费下载链接】Coolapk-UWP 一个基于 UWP 平台的第三方酷安客户端 项目地址: https://gitcode.com/gh_mirrors/co/Coolapk-UWP 你是否经常在手机小屏幕上刷酷安,眼睛酸痛却停不下来&…...

基于Adafruit Audio FX的智能穿戴音频系统设计与实现
1. 项目概述:一件会“捧场”的智能夹克你有没有想过,你的衣服可以成为你专属的喜剧演员、气氛组或者随身音效库?想象一下,在朋友聚会时,一个恰到好处的罐头笑声从你的口袋响起;或者在你做出一个帅气动作时&…...

用Circuit Playground Express制作可穿戴互动闪光T恤:零焊接图形化编程入门
1. 项目概述:一件会“跳舞”的闪光T恤几年前,当我第一次把微控制器缝进衣服里时,那感觉既兴奋又麻烦——满桌子的电线、烙铁,还有对洗衣机深深的恐惧。但现在,像Adafruit的Circuit Playground Express(后面…...

【2026最新】鸿蒙NEXT数据持久化实战:培训班管理系统数据存储全攻略
鸿蒙开发中数据总是丢失?本地存储和网络请求搞不定?本文用15分钟带你彻底搞懂Preferences、RDB、HTTP三大数据持久化方案,附完整培训班管理系统实战代码和踩坑记录,让你的鸿蒙App数据存储从此安全可靠!一、学员信息本地…...

ctfileGet:城通网盘直连地址解析工具的技术原理与实用指南
ctfileGet:城通网盘直连地址解析工具的技术原理与实用指南 【免费下载链接】ctfileGet 获取城通网盘一次性直连地址 项目地址: https://gitcode.com/gh_mirrors/ct/ctfileGet ctfileGet是一个基于Web的开源工具,专门用于解析城通网盘分享链接并获…...

多脉冲重复频率解速度模糊:原理、仿真与MATLAB实现
1. 脉冲雷达的速度模糊问题 雷达测速的基本原理大家都懂,就是通过多普勒效应计算目标速度。但实际操作中会遇到一个头疼的问题——速度模糊。这就像用卷尺量身高,如果身高超过卷尺长度,就得把几段卷尺接起来量,但接缝处容易出错。…...
)
用STM32F103C8T6和HC-05蓝牙模块,从零DIY一辆蓝牙遥控小车(附完整代码与MIT App Inventor教程)
从零打造STM32蓝牙遥控小车:硬件配置到APP开发全指南 项目背景与核心价值 对于嵌入式开发初学者来说,理论知识和实际项目之间往往存在一道难以跨越的鸿沟。而一个完整的硬件项目实践,恰恰是填补这一空白的最佳方式。基于STM32F103C8T6和HC-05…...

电气设备、工业炉行业企业官网模板资源整理
做工业类企业网站的开发和设计时,很多人都会遇到一个痛点:行业适配的官网模板太少,要么风格老旧,要么和电气设备、工业炉这类硬核行业的调性不符,从零开发又耗时耗力。 今天就结合自己的建站经验,给大家整…...

UPS Ground运输时间估算:从纽约10013到全美各区域的实操指南
1. 物流时间估算的核心价值与挑战在电商和供应链的世界里,时间就是金钱,而运输时间则是连接承诺与现实的桥梁。无论是作为卖家管理客户预期,还是作为买家规划项目进度,一个相对准确的运输时间预估都至关重要。UPS Ground作为美国境…...