高阶面试-存储系统的设计
概述
分类
- 块存储 block storage
- 文件存储 file storage
- 对象存储 object storage
区别:
块存储
概述
位于最底层,块,是物理存储设备上数据存储的最小单位。硬盘(Hard Disk Drive,HDD)就属于块存储。常见的还有固态硬盘(SSD)、存储区域网络(SAN),操作系统和应用程序可以通过块级接口来访问这些数据。主要应用程序:数据库。
生产上,除了磁盘挂载,要么就是用云厂商提供的块存储,如AWS EBS,要么就是Ceph这种文件存储系统的块存储。
如何存储?
将数据分成固定大小的块(或扇区),每个块都有唯一的地址或编号标识。
假设有个硬盘,被分割为大小1MB的块,来存储数据。
硬盘初始化(10GB分为1w个1MB的块)–>数据写入(系统给数据分配一个或多个空闲的块)–>块分配(系统维护映射表记录块是否空闲)–>数据读取(应用程序请求包含数据的块的地址,系统检索后返回给应用程序)–>块管理(垃圾回收、压缩空间、快照、克隆、备份等)
物理磁盘 (Disk)
└── 分区 (Partition)├── 主分区 (Primary Partition)└── 扩展分区 (Extended Partition)└── 逻辑分区 (Logical Partition)└── 物理卷 (Physical Volume)└── 卷组 (Volume Group)└── 逻辑卷 (Logical Volume)└── 文件系统 (Filesystem)└── 块 (Block)磁盘挂载示例
-
使用
fdisk创建分区[root@72agent ~]# fdisk /dev/xvde进入
fdisk工具,开始对/dev/xvde设备进行分区操作。 -
创建新的分区
- 输入
n创建新分区Command (m for help): n - 选择分区类型
p(主分区)Select (default p): p - 设置分区编号,默认是
1Partition number (1-4, default 1): 1 - 设置起始扇区,默认是
2048First sector (2048-629145599, default 2048): - 设置结束扇区,默认是最大值
Last sector, +sectors or +size{K,M,G} (2048-629145599, default 629145599):
- 输入
-
更改分区类型
- 输入
t更改分区类型Command (m for help): t - 选择分区
1Selected partition 1 - 输入类型代码
83(Linux原生分区,可以格式化为 ext4、xfs 等 Linux 文件系统并用于普通的数据存储)Hex code (type L to list all codes): 83
- 输入
-
保存分区表并退出
Command (m for help): w -
创建物理卷 (验证设备、写入LVM元数据包括物理卷标识符UUID、卷组信息、数据区描述、更新设备信息)
[root@72agent ~]# pvcreate /dev/xvde1 -
创建卷组(将一个或多个物理卷PV组合成一个卷组VG,会写入LVM卷组元数据,包括卷组名、物理卷列表、物理扩展块大小等)
[root@72agent ~]# vgcreate appvg /dev/xvde1 -
创建逻辑卷(将卷组中的物理存储空间组织成灵活易用的逻辑卷)
[root@72agent ~]# lvcreate -l 100%VG -n applv appvg -
格式化逻辑卷为 XFS 文件系统(在逻辑卷上创建必要的文件系统结构如超级块、块组、inode表)
[root@72agent ~]# mkfs.xfs /dev/appvg/applv -
创建挂载点(访问文件系统的路径,用于组织和管理文件)
[root@72agent ~]# mkdir /app -
挂载逻辑卷到挂载点
[root@72agent ~]# mount /dev/appvg/applv /app/ -
添加挂载信息到
/etc/fstab,以便开机自动挂载[root@72agent ~]# echo "/dev/mapper/appvg-applv /app xfs defaults 0 0" >> /etc/fstab -
验证挂载情况
[root@72agent ~]# df -h
以上步骤依次执行,可以成功将 /dev/xvde 挂载到 /app 目录,并确保系统重启后自动挂载。请注意检查每个步骤的输出,以确保没有错误发生。
当然,也可以挂载逻辑卷
# 安装必要的工具(例如,使用LVM管理块存储)
sudo apt-get update
sudo apt-get install lvm2# 使用fdisk或parted创建新的分区
sudo fdisk /dev/sdx
# 创建一个新的分区并退出# 创建物理卷
sudo pvcreate /dev/sdx1# 创建卷组
sudo vgcreate vg_myvolume /dev/sdx1# 创建逻辑卷
sudo lvcreate -l 100%FREE -n lv_mydata vg_myvolume# 格式化逻辑卷
sudo mkfs.ext4 /dev/vg_myvolume/lv_mydata# 挂载逻辑卷
sudo mount /dev/vg_myvolume/lv_mydata /mnt/mydata# 写入数据到挂载的卷
echo "Hello, block storage!" | sudo tee /mnt/mydata/hello.txt# 查看数据
cat /mnt/mydata/hello.txt# 卸载卷
sudo umount /mnt/mydata
如上,可写数据到挂载的卷
文件存储
在块存储的基础上,提供更高层次的抽象。最常见,相关协议如ftp、nfs、smb、scp、rsync等
文件存储的分类:
- 基于磁盘的普通本地文件系统,如ext4、xfs等
- 网络文件系统,如nfs
- 分布式文件系统 如ceph、glusterFS等
读取 /home/user/document.txt 文件
-
查找目录
/home/user:- 查找根目录
/,找到home目录的 inode。 - 读取
home目录的数据块,找到user目录的 inode。 - 读取
user目录的数据块,找到document.txt文件的 inode 编号。
- 查找根目录
-
读取 inode:
- 根据
document.txt文件的 inode 编号,从 inode 表中读取 inode 元数据。
- 根据
-
读取数据块:
- 读取 inode 中指向的数据块,获取文件的实际内容
如果目录项和 inode 信息已经在内存中缓存,则可以减少磁盘访问次数
- 读取 inode 中指向的数据块,获取文件的实际内容
主要优化:
- 缓存 目录项和 inode 信息放入内存
- 预读 读取文件,系统会预读后续的数据块,提高顺序读性能
- 写回 文件系统缓冲区会延迟将写操作的数据写入磁盘,减少磁盘写操作次数
- 索引优化 ext4采用B+树的变体做目录索引,inode索引沿用unix系统的inode结构
对象存储
文件存储系统的特点,对文件访问,需要先访问元数据inode,再访问用户数据也就是存储文件的数据。整个过程涉及2-3次的磁盘访问,而互联网领域有大量的图片等存储需求,多次磁盘访问会显著降低性能;文件系统的方式,应用访问数据的整个访问路径较长,用户无法直接访问,必须经过nginx-应用(接口、权限、文件系统接口)-远程文件系统,而随着互联网应用的发展,有海量图片等资源,和文件存储系统不同,只需要一次存储多次访问,不需要文件锁、对文件内容的修改等,因此对象存储应运而生。如AWS S3、七牛云、腾讯云对象存储等。
如何设计对象存储
需求
mindmaproot((需求))功能性需求创建bucketbucket上传下载bucket版本控制列出bucket的对象非功能性需求大文件和很多小文件一年数据量100PB数据持久性6个9,服务可用性4个9
需求如上,假设20%小对象(小于1MB),60%中等对象(1MB-64MB),20%大对象(大于64MB)。计算得到对象总数大概0.68 billion个,一个对象的元数据1KB,那需要0.68TB空间存储元数据。
对象存储:metadata(ObjectName->ObjectId) dataStorage(objectId->Object)
分离元数据和对象数据,数据存储包含不可变数据,元数据存储包含可变数据
![[Pasted image 20240605212521.png]]
架构图
![[Pasted image 20240605213257.png]]
上传
![[Pasted image 20240605214007.png]]
对象必须在桶里面
- http put请求创建桶–>LB–>API–>IAM确保授权且有写权限–>metadata存储,db中创建bucket_info
- http put请求创建script.txt的对象–>LB–>API–>IAM–>将payload的对象数据发送到数据存储,返回对象uuid
- API调用metadataDB存储record,包含object_name、object_id(uuid)、bucket_id
下载
![[Pasted image 20240605231357.png]]
client-(GET /bucket-to-share/script.txt)->LB–>API–>IAM验证是否有读权限–>metadataDB检索uuid–>从数据存储中检索对象数据–>返回给client
数据存储服务
![[Pasted image 20240605233125.png]]
三个部分:
- 数据路由 data routing service,提供restfulAPI访问数据节点集群,无状态服务,查询placement service获取最佳数据节点读写
- 存储分布服务 placement service,负责将对象放置在不同的存储节点和数据中心,如下虚拟集群图,实现冗余存储和高可用 通过心跳监控所有数据节点。集群的话,使用paxos或raft协议构建5到7个节点的集群,保证服务的高可用。
- 数据节点 data node,也叫复制组,通过将数据复制到多个数据节点确保可靠性和持久性。每个数据节点都运行一个数据服务守护进程,给存储分布服务发送心跳,包含数据节点管理多少个磁盘驱动器,每个驱动器存储多少数据。存储分布服务给数据节点分配ID,添加到虚拟集群映射中,并返回唯一id、虚拟集群map、去哪复制数据
![[Pasted image 20240605233813.png]]
流程:
API-对象数据->dataStorage
data routing service 生成对象的uuid,请求placement service存储
placement service检查虚拟集群map,返回主节点
data routing service将数据和uuid发给主节点
主节点保存并复制给两个副本节点(CAP的三种取舍),返回响应给data routing service
uuid返回给API
数据的管理
最简单:每个对象存储到单独的文件
缺点:很多小文件,性能受影响,1.浪费数据块,典型的块是4KB,对于小文件也是占用整个磁盘块;2.inode会太多,有耗尽inode的风险;3.操作系统对大量inode的处理不好
采用方案:在一个大文件中存储多个小对象
注意:读写文件的写入访问必须串行化。现代多核处理,为每个传入请求提供专用的读写文件
![[Pasted image 20240605235652.png]]
需要知道:
- 包含小对象的数据文件
- 对象在文件中的开始下标
需要object_mapping表,object_id、file_name、start_offset、object_size
可以部署单个大型集群支持所有数据节点,但没必要,因为映射数据在每个数据节点都是孤立的,不需要共享,每个数据节点部署一个简单的RDB如sqlite
更新后如下:
![[Pasted image 20240606105245.png]]
如何保证高可用
多数据中心复制
擦除编码(erasure coding) 创建奇偶校验,对应数学公式保证在最多4个节点宕机的情况下可以重建原始数据。假设i个节点每年0.81%的故障率,根据backblaze计算,擦出编码可实现11个9的高可用。缺点:极大的复杂了数据节点的设计。
校验和checksum,在每个对象的末尾附加校验和,在将文件标记为只读之前,在末尾添加整个文件的校验和,如下
![[Pasted image 20240606133808.png]]
metadata schema
需要支持3个查询:
- find object_id by object_name
- insert and delete object by object_name
- list objects in a bucket sharing the same prefix
需要两个表
![[Pasted image 20240606134349.png]]
规模:假设100w客户,每个客户10个bucket,每个记录1kb,也就是需要 100w*10*1kb=10GB的存储空间
上规模最好不要单个数据库实例,分片扩展对象表
分片方案:
- 按bucket_id,但bucket可能包含数十亿个对象,导致热点分片hotspot shard
- 按object_id,无法快速执行1和2了
- 按bucket_name和object_name组合的hash分片呢,前两个快速,但最后一个查询不好
最后一个怎么处理?
select * from object where bucket_id='123' and object_name like 'a/b/%'
元数据服务聚合每个分片的所有对象,再将结果返回给调用者。
分页有点复杂,单个的可以用offset和limit限制,但分片的话要跟踪每个分片的游标,每个分片偏移量也可能不一样。
解决方案:将列表数据放入一个由bucket_id分片的表,仅用来列出对象,简化实现。
版本控制
![[Pasted image 20240606140115.png]]
object_version,这个字段控制,用户删除特定版本的对象时,增加删除标记
优化大文件上传
![[Pasted image 20240606141500.png]]
client-调用InitiateMultipartUpload->object storage,返回唯一标识uploadId
client-UploadPart->object storage,返回etag,也就是该部分的md5校验和
全部上传完成,client-(uploadId、part No,ETags)->object storage
data store重新组装,返回成功消息
问题:
重新组装后,旧部件没用了,需要GC
- 惰性对象回收
- 孤儿数据,如一半上传的数据
具体回收过程:
- gc将对象从
/data/b复制到/data/d的列表,跳过object2和object5,因为他们删除标志是true - 更新object_mapping表,更新object3的file_name和start_offset,通常是有大量的只读文件时才会压缩
![[Pasted image 20240606165718.png]]
背景
当时用的是moosefs,选型很简单,就是考虑支持 POSIX 接口,方便查看
文件系统 --》网络文件系统 --》分布式文件存储系统 --》S3等对象存储系统
ceph
架构
相关文章:

高阶面试-存储系统的设计
概述 分类 块存储 block storage文件存储 file storage对象存储 object storage 区别: 块存储 概述 位于最底层,块,是物理存储设备上数据存储的最小单位。硬盘(Hard Disk Drive,HDD)就属于块存储。常见的还有固态硬盘(SSD)、…...

柔性测斜仪:土木工程与地质监测的得力助手
在现代土木工程和地质工程领域,精确监测土壤和岩石的位移情况对于确保工程安全至关重要。柔性测斜仪作为一种高精度、稳定性和灵活性兼备的测量设备,已逐渐成为工程师和研究人员的得力助手。本文将深入探讨柔性测斜仪在多个关键领域的应用及其重要性。 点…...

数字资产和数据资产你真的了解吗?
数据作为新型生产要素,是数字化、网络化、智能化的基础,已快速融入生产、分配、流通、消费和社会服务管理等各环节,深刻改变着生产方式、生活方式和社会治理方式。 何为数据资产?即由个人或企业拥有或控制的,能为企业带…...
【每日一练】python运算符
1. 算术运算符 编写一个Python程序,要求用户输入两个数,并执行以下运算:加法、减法、乘法、求余、除法、以及第一个数的第二个数次方。将结果打印出来。 a input("请输入第一个数:") b input("请输入第二个数&…...
CesiumJS【Basic】- #032 绘制虚线(Primitive方式)
文章目录 绘制虚线(Primitive方式)1 目标2 代码2.1 main.ts绘制虚线(Primitive方式) 1 目标 使用Primitive方式绘制虚线 2 代码 2.1 main.ts // 定义线条的起点和终点var start = Cesium.Cartesian3.fromDegrees(-75.59777, 40.03883)...

海尔智家:科技优秀是一种习惯
海尔智家:科技优秀是一种习惯 2024-06-28 15:19代锡海 6月24日,2023年度国家科学技术奖正式揭晓。海尔智家“温湿氧磁多维精准控制家用保鲜电器技术创新与产业化”项目荣获国家科学技术进步奖,成为家电行业唯一牵头获奖企业。 很多人说&…...
【Android】实现图片和视频混合轮播(无限循环、视频自动播放)
目录 前言一、实现效果二、具体实现1. 导入依赖2. 布局3. Banner基础配置4. Banner无限循环机制5. 轮播适配器6. 视频播放处理7. 完整源码 总结 前言 我们日常的需求基本上都是图片的轮播,而在一些特殊需求,例如用于展览的的数据大屏,又想展…...

VLAN基础
一、什么是Vlan VLAN(Virtual Local Area Network)是虚拟局域网的简称,是一种将单一物理局域网(LAN)在逻辑层面上划分为多个独立的广播域的技术。每个VLAN都是一个独立的广播域,其内部主机可以直接通信&am…...

pytest-yaml-sanmu(五):跳过执行和预期失败
除了手动注册标记之外,pytest 还内置了一些标记可直接使用,每种内置标记都会用例带来不同的特殊效果,本文先介绍 3 种。 1. skip skip 标记通常用于忽略暂时无法执行,或不需要执行的用例。 pytest 在执行用例时,如果…...
)
linux指令整合(centos系统持续更新中。。。)
1、查询java进程 ps -ef|grep java 2、查询端口占用 lsof -i:端口号 3、 启动java程序 java -jar jar包路径 后台启动 nohup java -jar jar包路径 -Xms512m -Xmx512m > 日志路径 2>&1 & 4、查看服务器资源占用 top 5、关闭进程 kill -9 进程号...

个人开发实现AI套壳网站快速搭建(Vue+elementUI+SpringBoot)
目录 一、效果展示 二、项目概述 三、手把手快速搭建实现本项目 3.1 前端实现 3.2 后端方向 五、后续开发计划 一、效果展示 默认展示 一般对话展示: 代码对话展示: 二、项目概述 本项目是一个基于Web的智能对话服务平台,通过后端与第…...
Cesium与Three相机同步(3)
Cesium与Three融合的案例demo <!DOCTYPE html> <html lang"en" class"dark"><head><meta charset"UTF-8"><link rel"icon" href"/favicon.ico"><meta name"viewport" content&q…...

PMP考试报名项目经历怎么填写?指引请收好
PMP,这一全球公认的项目管理金牌认证,不仅是对项目管理能力的认可,更是职业生涯中的一大助力。然而,在报名PMP时,很多小伙伴都面临一个共同的难题:如何书写项目经验?今天,就让我们一…...

Git的基本使用方法
Git的基本使用方法 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!今天我们将深入探讨Git的基本使用方法,Git作为目前最流行的版本控制系统之一&…...

深入剖析 @Autowired 和 @Resource 在 Spring 中的区别
在 Spring 框架中,Autowired 和 Resource 是两个常用的注解,用于实现依赖注入。尽管它们都能达到将依赖对象注入到目标 bean 的目的,但在细节上存在一些显著的差异。本文将深入探讨这两个注解的区别,并结合 Spring 源码进行分析&a…...

Golang-slice理解
slice golang-slice语雀笔记整理 slicego为何设计slice?引用传递实现扩容机制 go为何设计slice? 切片对标其他语言的动态数组,底层通过数组实现,可以说是对数组的抽象,底层的内存是连续分配的所以效率高,可…...
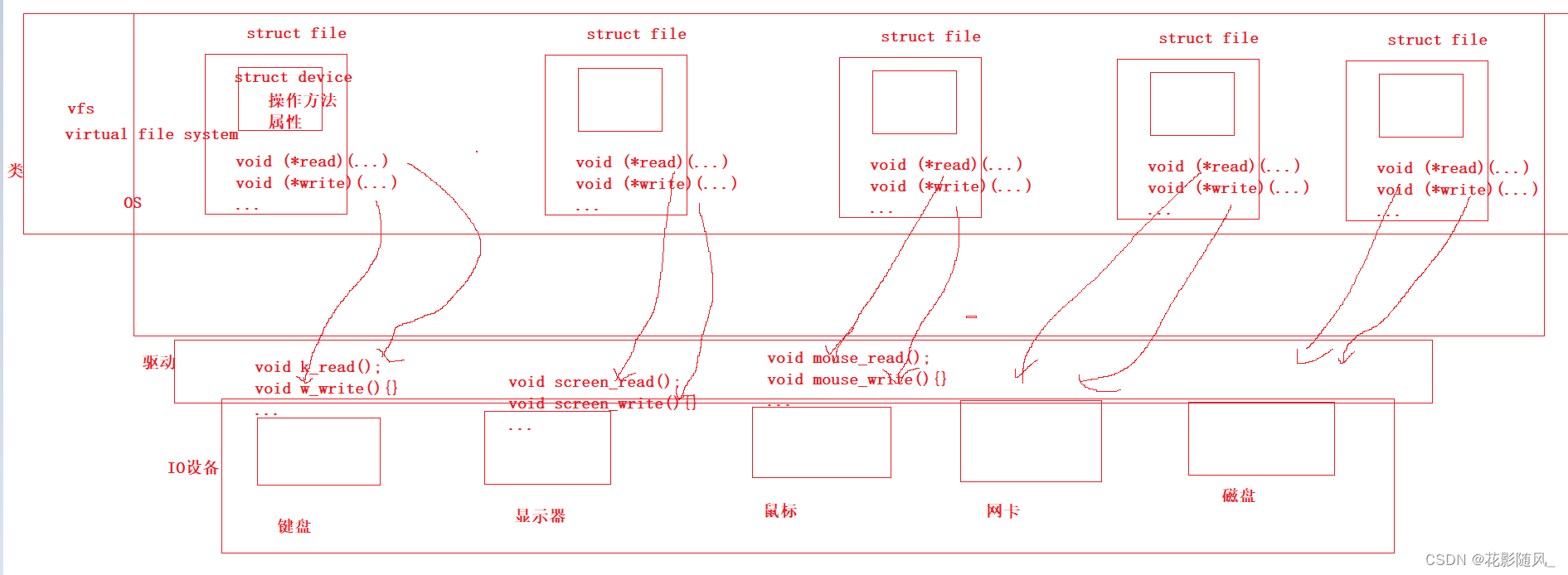
【Linux系统】文件描述符fd
1.回顾一下文件 我们之前对文件的理解是在语言层上,而语言层去理解文件是不可能的!!! 下面是一份c语言文件操作代码!!! #include<stdio.h> int main() {FILE* fd fopen("lo…...

【嵌入式——FreeRTOS】启动任务调度器
【嵌入式——FreeRTOS】启动任务调度器 开启任务调度器vTaskStartScheduler()xPortStartScheduler()prvStartFirstTask()启动第一个任务 开启任务调度器 用于启动任务调度器,任务调度器启动后,FreeRTOS便会开始进行任务调度。 //启动任务,开…...

EFCore_客户端评估与服务端评估
定义 客户端评估: 先将表的所有数据读取至内存,再在内存中对数据进行筛选,数据的筛选工作在客户端服务端评估: 先将代码翻译为SQL语句,再执行SQL语句对数据进行筛选,数据的筛选工作在服务端(默认方式) 如何…...
Java面试题--JVM大厂篇之深入了解G1 GC:高并发、响应时间敏感应用的最佳选择
引言: 在现代Java应用的性能优化中,垃圾回收器(GC)的选择至关重要。对于高并发、响应时间敏感的应用而言,G1 GC(Garbage-First Garbage Collector)无疑是一个强大的工具。本文将深入探讨G1 GC适…...

AI对话记忆管理实战:memory-organizer库解决长上下文难题
1. 项目概述:一个为AI记忆体“瘦身”与“归档”的利器最近在折腾一些本地大语言模型(LLM)的应用,比如搭建个人知识库助手或者长期对话机器人,一个绕不开的痛点就是“记忆”的管理。模型本身没有持久记忆,每…...

深度神经网络参数安全与Hessian-aware训练防御技术
1. 深度神经网络参数安全威胁现状深度神经网络(DNN)在内存中的参数面临着严重的比特翻转安全威胁。这种威胁主要来自两个方面:自然发生的硬件故障和人为发起的攻击行为。在IEEE-754 32位浮点数表示中,一个比特的翻转可能导致参数值发生灾难性变化。例如&…...

学习信息系统项目管理师我们以什么视角学习?
如果你只是死记硬背那些定义,你会觉得这本书枯燥乏味,而且做题时很容易掉进陷阱。但如果你**“入戏”**,把自己当成那个掌握全局的项目经理,很多答案你凭直觉就能选对。为了帮你把“入戏”进行到底,我给你三个**“入戏…...

CircuitPython FancyLED库:专业级可寻址LED色彩动画开发指南
1. 项目概述:为什么需要FancyLED?在嵌入式开发,尤其是物联网和交互式装置项目中,可寻址LED(如NeoPixel、DotStar)已经成为构建动态视觉反馈的核心组件。无论是制作一个会呼吸的氛围灯,还是一个能…...

电气设备、工业炉行业企业官网模板资源整理
做工业类企业网站的开发和设计时,很多人都会遇到一个痛点:行业适配的官网模板太少,要么风格老旧,要么和电气设备、工业炉这类硬核行业的调性不符,从零开发又耗时耗力。 今天就结合自己的建站经验,给大家整…...
)
手把手教你为AK7739音频芯片移植TDM接口(基于Linux ALSA框架)
手把手教你为AK7739音频芯片移植TDM接口(基于Linux ALSA框架) 在嵌入式音频系统开发中,TDM(Time Division Multiplexing)接口因其高带宽和多通道支持能力,成为专业音频设备的首选方案。AK7739作为一款高性能…...

ARM架构计数器与定时器虚拟化技术详解
1. ARM架构中的计数器-定时器虚拟化技术概述在现代虚拟化环境中,精确的时间管理是确保虚拟机性能和功能完整性的关键要素。ARMv8/v9架构通过一系列精心设计的系统寄存器和硬件特性,为hypervisor提供了强大的计数器与定时器虚拟化能力。这项技术允许每个虚…...

基于RAG的代码库智能问答工具:askyourgit部署与实战指南
1. 项目概述:当代码库成为你的对话伙伴在软件开发与团队协作的日常中,我们常常面临一个看似简单却异常耗时的问题:“这段代码是谁写的?当时为什么要这么改?”或者“我们项目里有没有处理过类似‘用户登录超时’的逻辑&…...

JetBrains IDE试用期重置完整指南:快速恢复30天免费使用权限
JetBrains IDE试用期重置完整指南:快速恢复30天免费使用权限 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 你是否正在使用JetBrains系列IDE进行开发,却面临试用期到期的问题?…...

Casdoor开源统一身份认证平台:基于OAuth 2.0与OIDC的SSO实战指南
1. 项目概述:一个开源的统一身份认证与单点登录平台如果你正在为多个内部系统各自独立的登录入口而头疼,或者厌倦了为每个新应用重复开发用户注册、登录、权限管理这些“轮子”,那么 Casdoor 这个项目绝对值得你花时间深入了解。简单来说&…...