sam_out 目标检测的应用
- 缺点
- 参考地址
- 训练验证
- 模型
- 解析
缺点
词表太大量化才可
参考地址
https://aistudio.baidu.com/projectdetail/8103098
训练验证
import os
from glob import glob
import cv2
import paddle
import faiss
from out_yolo_model import GPT as GPT13
import pandas as pd
import json
from tqdm import tqdm
import numpy as np
from paddle.io import DataLoader, Dataset
import warningswarnings.filterwarnings('ignore')# 36 36
def gen_small_voc():num = "0123456789" + 'qwertyuiopasdfghjklzxcvbnm' + "QWERTYUIOPASDFGHJKLZXCVBNM"num = list(num)small_em_voc = dict()voc_id = 0for i in range(16):for n in num:small_em_voc[voc_id] = "{}_{}".format(i, n)voc_id += 1return small_em_vocdef random_gen_voc():num = "0123456789" + 'qwertyuiopasdfghjklzxcvbnm' + "QWERTYUIOPASDFGHJKLZXCVBNM"num = list(num)p_list = ["{}_{}".format(i, np.random.choice(num)) for i in range(16)]return "#".join(p_list)def gen_text_voc_to_token_id():large_em_voc = dict()large = []for x in range(28 * 28):for w in range(28):for h in range(28):for class_name in range(15):large.append("x_{}_w_{}_h_{}_class_{}".format(x, w, h, class_name))large.append("<|end|>")large.append("<|start|>")for ii in tqdm(large):while True:two = random_gen_voc()if large_em_voc.get(two, None) is None:large_em_voc[two] = iilarge_em_voc[ii] = twobreakpd.to_pickle(large_em_voc, "large_em_voc.pkl")class MyDataSet(Dataset):def __init__(self):super(MyDataSet, self).__init__()txt = glob("D:/chromedownload/VisDrone2019-DET-train/annotations/*")image = glob("D:/chromedownload/VisDrone2019-DET-train/images/*")data_txt_image = []for one in txt:two = one.replace("D:/chromedownload/VisDrone2019-DET-train/annotations\\","D:/chromedownload/VisDrone2019-DET-train/images\\").replace(".txt", ".jpg")if two in image:data_txt_image.append((one, two))self.data = data_txt_imageself.large_token_to_samll_token = pd.read_pickle("large_em_voc.pkl")self.small_token_to_token_id = gen_small_voc()self.small_token_to_token_id = {k: v for v, k in self.small_token_to_token_id.items()}def init_val(self):txt = glob("D:/chromedownload/VisDrone2019-DET-test-dev/annotations/*")image = glob("D:/chromedownload/VisDrone2019-DET-test-dev/images/*")data_txt_image = []for one in txt:two = one.replace("D:/chromedownload/VisDrone2019-DET-test-dev/annotations\\","D:/chromedownload/VisDrone2019-DET-test-dev/images\\").replace(".txt", ".jpg")if two in image:data_txt_image.append((one, two))self.data = data_txt_imageself.large_token_to_samll_token = pd.read_pickle("large_em_voc.pkl")self.small_token_to_token_id = gen_small_voc()self.small_token_to_token_id = {k: v for v, k in self.small_token_to_token_id.items()}def __len__(self):return len(self.data)def __getitem__(self, item):text, image = self.data[item]image = cv2.imread(image)h, w, c = image.shapeimage = cv2.resize(image, (224, 224)) / 256text_df = pd.read_csv(text)text_df = pd.DataFrame(text_df.values.tolist() + [text_df.columns.values.tolist()]).astype("float")center_x = (text_df[0] + text_df[2] / 2) * 224 / wcenter_y = (text_df[1] + text_df[3] / 2) * 224 / hcenter_w = text_df[2] / 2 * 224 / wcenter_h = text_df[3] / 2 * 224 / hxy_index = 0center_x_y = np.zeros(center_x.size)for i in range(0, 224, 8):j = i + 8for ii in range(0, 224, 8):jj = ii + 8center_x_y[(ii <= center_x.values) * (center_x.values <= jj) * (i <= center_y.values) * (center_y.values <= j)] = xy_indexxy_index += 1text_df["xy"] = center_x_ytext_df["w"] = center_wtext_df["h"] = center_htext_df = text_df.astype("int").sort_values([1, 0])text_df = text_df.iloc[:128]xy = "x_" + text_df.astype("str")["xy"] + "_w_" + text_df.astype("str")["w"] + "_h_" + text_df.astype("str")["h"] + "_class_" + text_df.astype("str")[5]xy = xy.valuestext_token = [self.large_token_to_samll_token.get(xy_i) for xy_i in xy]text_token = [[self.small_token_to_token_id.get(j) for j in jj.split("#")] for jj in text_token if jj]text_token = np.array(text_token).reshape([-1, 16])return image, text_token, [self.small_token_to_token_id.get(i) for i inself.large_token_to_samll_token.get("<|end|>").split("#")], [self.small_token_to_token_id.get(i) for i inself.large_token_to_samll_token.get("<|start|>").split("#")]def gn(items):seq_len = 0image = []for x, y, z, s in items:if y.shape[0] > seq_len:seq_len = y.shape[0]image.append(x.transpose([2, 0, 1]).reshape([1, 3, 224, 224]))seq_len += 1text = []for x, y, z, s in items:one = np.concatenate([[s], y, (seq_len - y.shape[0]) * [z]]).reshape([1, -1, 16])text.append(one)return np.concatenate(image), np.concatenate(text)def val():small_em_voc = gen_small_voc()# small_voc_em = {k: v for v, k in small_em_voc.items()}# large_em_voc = dict()model = GPT13(len(small_em_voc), 512, 32, 8)model.load_dict(paddle.load("duo_yang_xing.pkl"))model.eval()# model.load_dict(paddle.load("gpt.pdparams"))print("参数量:",sum([i.shape[0] * i.shape[-1] if len(i.shape) > 1 else i.shape[-1] for i in model.parameters()]) / 1000000000,"B")loss_func = paddle.nn.CrossEntropyLoss()bar = tqdm(range(1))batch_size = 5data_set = MyDataSet()data_set.init_val()data = DataLoader(data_set, batch_size=batch_size, shuffle=True, num_workers=5, collate_fn=gn)data_count = 0loss_list = []for epoch in bar:for image, text in data:try:out, _ = model(text[:, :-1].astype("int64"), image.astype("float32"))loss = loss_func(out, text[:, 1:].reshape([out.shape[0], -1]).astype("int64"))loss_list.append(loss.item())bar.set_description("epoch___{}__loss__{:.5f}___data_count__{}".format(epoch, np.mean(loss_list), data_count))data_count += batch_sizeexcept:paddle.device.cuda.empty_cache()def eval_data():small_em_voc = gen_small_voc()small_voc_em = {k: v for v, k in small_em_voc.items()}large_em_voc = pd.read_pickle("large_em_voc.pkl")model = GPT13(len(small_em_voc), 512, 32, 8)model.load_dict(paddle.load("duo_yang_xing.pkl"))model.eval()# model.load_dict(paddle.load("gpt.pdparams"))print("参数量:",sum([i.shape[0] * i.shape[-1] if len(i.shape) > 1 else i.shape[-1] for i in model.parameters()]) / 1000000000,"B")batch_size = 2faiss_index = faiss.IndexFlatIP(8192)key_list=[]for i in tqdm(large_em_voc.keys()):if len(i) > 32 and "#" in i:out_em=model.embedding(paddle.to_tensor([small_voc_em.get(ii) for ii in i.split("#")]).reshape([1, 1, -1])).reshape([1,-1])out_em /= np.linalg.norm(out_em, axis=-1, keepdims=True)faiss_index.add(out_em)key_list.append(large_em_voc.get(i))data_set = MyDataSet()data_set.init_val()data = DataLoader(data_set, batch_size=batch_size, shuffle=True, num_workers=5, collate_fn=gn)for image, text in data:out, _ = model(text[:, :-1].astype("int64"), image.astype("float32"))out_em = model.embedding(paddle.argmax(out, -1).reshape([batch_size,-1,16])[0,0].reshape([1,1,16])).reshape([1,-1])out_em /= np.linalg.norm(out_em, axis=-1, keepdims=True)di,index_index=faiss_index.search(out_em,10)print(key_list[index_index[0,0]])def train():small_em_voc = gen_small_voc()# small_voc_em = {k: v for v, k in small_em_voc.items()}# large_em_voc = dict()model = GPT13(len(small_em_voc), 512, 32, 8)# model.load_dict(paddle.load("duo_yang_xing.pkl"))# model.load_dict(paddle.load("gpt.pdparams"))print("参数量:",sum([i.shape[0] * i.shape[-1] if len(i.shape) > 1 else i.shape[-1] for i in model.parameters()]) / 1000000000,"B")loss_func = paddle.nn.CrossEntropyLoss()opt = paddle.optimizer.Adam(parameters=model.parameters(), learning_rate=0.0003)bar = tqdm(range(200))batch_size = 5data_set = MyDataSet()data = DataLoader(data_set, batch_size=batch_size, shuffle=True, num_workers=5, collate_fn=gn)data_count = 0for epoch in bar:for image, text in data:try:out, _ = model(text[:, :-1].astype("int64"), image.astype("float32"))loss = loss_func(out, text[:, 1:].reshape([out.shape[0], -1]).astype("int64"))bar.set_description("epoch___{}__loss__{:.5f}___data_count__{}".format(epoch, loss.item(), data_count))opt.clear_grad()loss.backward()opt.step()data_count += batch_sizeif data_count % 1000 == 0:paddle.save(model.state_dict(), "duo_yang_xing.pkl")paddle.device.cuda.empty_cache()except:paddle.device.cuda.empty_cache()paddle.save(model.state_dict(), "duo_yang_xing.pkl")paddle.save(model.state_dict(), "duo_yang_xing.pkl")if __name__ == '__main__':# gen_text_voc_to_token_id()# train()# val()eval_data()模型
import mathimport paddle
import paddle.nn as nnclass MaxState(paddle.nn.Layer):def __init__(self, hidden_dim, heads, win):super(MaxState, self).__init__()assert hidden_dim % heads == 0, "Hidden size must be divisible by the number of heads."self.head_size = hidden_dim // headsself.head = paddle.nn.Linear(hidden_dim, hidden_dim, bias_attr=False)self.head_num = headsself.win = winself.hidden = hidden_dimself.mask = paddle.triu(paddle.ones([win, win]))def forward(self, input_data, state=None):b, s, k, h, w = input_data.shape[0], input_data.shape[1], self.head_num, self.head_size, self.winwindow = paddle.ones([1, w])out = self.head(input_data)out = out.unsqueeze(-1) @ windowout = out.transpose([0, 2, 1, 3])one_list = []if state is None:state = paddle.ones([out.shape[0], out.shape[1], 1, 1]) * float("-inf")for i in range(0, s, w):j = w + ione = out[:, :, i:j]_, _, r, c = one.shapeif r != self.win:one = paddle.where(self.mask[:r, :], one, paddle.to_tensor(-float('inf')))else:one = paddle.where(self.mask, one, paddle.to_tensor(-float('inf')))one = paddle.concat([one, state @ window], axis=2)state = paddle.max(one, axis=2, keepdim=True)one = state.reshape([b, k, h, w])state = state[..., -1:]if r != self.win:one = one[..., :r]one = one.transpose([0, 3, 1, 2])one_list.append(one)out = paddle.concat(one_list, 1)out = out.reshape([b, s, -1])return out, stateclass FeedForward(nn.Layer):def __init__(self, hidden_size):super(FeedForward, self).__init__()self.ffn1 = nn.Linear(hidden_size, hidden_size * 2)self.ffn2 = nn.Linear(hidden_size * 2, hidden_size)self.gate = nn.Linear(hidden_size, hidden_size * 2)self.relu = nn.Silu()def forward(self, x):x1 = self.ffn1(x)x2 = self.relu(self.gate(x))x = x1 * x2x = self.ffn2(x)return xclass RMSNorm(nn.Layer):def __init__(self, dim, eps: float = 1e-6):super(RMSNorm, self).__init__()self.eps = epsself.fc = paddle.create_parameter(shape=[dim], dtype='float32',default_initializer=nn.initializer.Constant(value=1.0))def norm(self, x):return x * paddle.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)def forward(self, x):output = self.norm(x)return output * self.fcclass GPTDecoderLayer(nn.Layer):def __init__(self, hidden_size, num_heads):super(GPTDecoderLayer, self).__init__()# self.self_attention = MaskMultiHeadAttention(hidden_size, num_heads)self.self_attention = MaxState(hidden_size, num_heads, 8)self.ffn = FeedForward(hidden_size)self.norm = nn.LayerNorm(hidden_size)self.norm1 = RMSNorm(hidden_size)def forward(self, x, state=None, seq_len=None):x1, state = self.self_attention(x, state) # Self-Attention with residual connectionx = x1 + xx = self.norm(x)x = self.ffn(x) + x # Feed-Forward with residual connectionx = self.norm1(x)return x, stateclass PositionalEncoding(nn.Layer):def __init__(self, d_model, max_len=5000):super(PositionalEncoding, self).__init__()# Create a long enough Paddle array to hold position encodings for the maximum sequence lengthposition = paddle.arange(max_len).unsqueeze(1).astype("float32")# Create a constant 'pe' matrix with the same size as the embedding matrixdiv_term = paddle.exp(paddle.arange(0, d_model, 2) * (-math.log(10000.0) / d_model))pe = paddle.zeros([max_len, d_model])pe[:, 0::2] = paddle.sin(position * div_term)pe[:, 1::2] = paddle.cos(position * div_term)self.pe = pe.unsqueeze(0) # Shape: [1, max_len, d_model]# Register 'pe' as a buffer (non-trainable parameter)def forward(self, x, seq_len=None):# x is of shape [batch_size, seq_len, d_model]if seq_len is None:seq_len = x.shape[1]return x + self.pe[:, :seq_len, :]else:return x + self.pe[:, seq_len - 1:seq_len, :]# %%def sinusoidal_position_embedding(max_len, output_dim):# (max_len, 1)position = paddle.arange(0, max_len, dtype="float32").unsqueeze(-1)# (output_dim//2)ids = paddle.arange(0, output_dim // 2, dtype="float32") # 即公式里的i, i的范围是 [0,d/2]theta = 10000 ** (-2 * ids / output_dim)# (max_len, output_dim//2)embeddings = position * theta # 即公式里的:pos / (10000^(2i/d))sin_embeddings = paddle.sin(embeddings)cos_embeddings = paddle.cos(embeddings)return sin_embeddings, cos_embeddingsdef rope(q, sin_em, cos_em, seq_len=None):if seq_len is None:sin_em = sin_em[:q.shape[2]]cos_em = cos_em[:q.shape[2]]else:sin_em = sin_em[seq_len - 1:seq_len]cos_em = cos_em[seq_len - 1:seq_len]q1 = q.reshape([q.shape[0], q.shape[1], q.shape[2], -1, 2])[..., 1]q2 = q.reshape([q.shape[0], q.shape[1], q.shape[2], -1, 2])[..., 0]# 奇数负值*sin_em+偶数正值*cos_em 奇数正值*cos_em+偶数正值*sin_emq3 = paddle.stack([-q1 * sin_em + q2 * cos_em, q1 * cos_em + q2 * sin_em], -1)q = q3.reshape(q.shape) # reshape后就是正负交替了return qclass ConvEm(nn.Layer):def __init__(self, hidden_size):super(ConvEm, self).__init__()# 定义卷积层self.conv1 = nn.Conv2D(in_channels=3, out_channels=hidden_size//16, kernel_size=3, padding=1)self.bn1 = nn.BatchNorm2D(hidden_size//16)# 定义第二个卷积层self.conv2 = nn.Conv2D(in_channels=hidden_size//16, out_channels=hidden_size//16, kernel_size=3, padding=1)self.bn2 = nn.BatchNorm2D(hidden_size//16)def forward(self, im):# 通过第一个卷积块x = nn.functional.relu(self.bn1(self.conv1(im)))# 通过第二个卷积块x = self.bn2(self.conv2(x))+x# 应用ReLU激活函数x = nn.functional.relu(x)return paddle.nn.functional.max_pool2d(x,4)class GPT(nn.Layer):def __init__(self, vocab_size, hidden_size, num_heads, num_layers):super(GPT, self).__init__()self.embedding = nn.Embedding(vocab_size, hidden_size)self.label_embedding = nn.Embedding(vocab_size, hidden_size)self.decoder_layers = nn.LayerList([GPTDecoderLayer(hidden_size, num_heads) for _ in range(num_layers)])self.fc = nn.Linear(hidden_size, vocab_size, bias_attr=False)self.sin_em, self.cos_em = sinusoidal_position_embedding(50000, hidden_size // num_heads // 2)self.conv = paddle.nn.Conv1D(1, 16, kernel_size=3, padding=1, bias_attr=False)self.out = nn.Linear(16, 16, bias_attr=False)self.layer_nor = paddle.nn.LayerNorm(hidden_size)# self.rms_norm=RMSNorm(hidden_size)self.cv_state = ConvEm(hidden_size)def forward(self, xx, image, state=None, seq_len=None):xx = self.embedding(xx)# x = self.position_embedding(x, seq_len)image=self.cv_state(image)image =image.reshape([image.shape[0],xx.shape[-1],-1])image=image.reshape([image.shape[0],image.shape[1],-1]).unsqueeze(-1)+paddle.zeros([1,1,1,xx.shape[1]])image =image.transpose([0,3,2,1])x = paddle.max(paddle.concat([xx,image],-2), -2)if state is None:state = [None] * len(self.decoder_layers)i = 0x = rope(x.reshape([x.shape[0], x.shape[1], -1, self.sin_em.shape[1] * 2]).transpose([0, 2, 1, 3]),self.sin_em,self.cos_em, seq_len).transpose([0, 2, 1, 3]).reshape(x.shape) + xfor decoder_layer in self.decoder_layers:x1, state[i] = decoder_layer(x, state[i])x = x1 + xi += 1# out = self.fc(self.rms_norm(x))out = self.conv(x.reshape([-1, 1, x.shape[-1]])) + xx.reshape([-1, 16, x.shape[-1]])out = out.reshape([x.shape[0], -1, x.shape[-1]])out = self.fc(self.layer_nor(out))return out, state解析
这段代码定义了一个基于 PaddlePaddle 的 GPT 模型,包含了多个自定义的神经网络层和前向传播逻辑。下面是逐行解析:
import math
import paddle
import paddle.nn as nn
导入 Python 的数学库、PaddlePaddle 深度学习框架以及 PaddlePaddle 的神经网络相关模块。
class MaxState(paddle.nn.Layer):def __init__(self, hidden_dim, heads, win):super(MaxState, self).__init__()# 确保隐藏层维度能够被头数整除assert hidden_dim % heads == 0, "Hidden size must be divisible by the number of heads."# 计算每个头的尺寸self.head_size = hidden_dim // heads# 定义一个线性层self.head = paddle.nn.Linear(hidden_dim, hidden_dim, bias_attr=False)# 头的数量self.head_num = heads# 窗口大小self.win = win# 隐藏层维度self.hidden = hidden_dim# 创建上三角矩阵作为掩码self.mask = paddle.triu(paddle.ones([win, win]))def forward(self, input_data, state=None):# 获取输入数据的维度信息b, s, k, h, w = input_data.shape[0], input_data.shape[1], self.head_num, self.head_size, self.win# 创建一个窗口向量window = paddle.ones([1, w])# 通过线性层处理输入数据out = self.head(input_data)# 执行矩阵乘法out = out.unsqueeze(-1) @ window# 调整输出的维度out = out.transpose([0, 2, 1, 3])# 初始化一个列表来保存处理后的窗口数据one_list = []# 如果没有状态,则初始化状态if state is None:state = paddle.ones([out.shape[0], out.shape[1], 1, 1]) * float("-inf")# 遍历输入数据以窗口大小进行切片for i in range(0, s, w):j = w + ione = out[:, :, i:j]# 获取当前窗口的尺寸_, _, r, c = one.shape# 如果窗口尺寸不等于预设的win,则应用掩码if r != self.win:one = paddle.where(self.mask[:r, :], one, paddle.to_tensor(-float('inf')))else:one = paddle.where(self.mask, one, paddle.to_tensor(-float('inf')))# 将状态与窗口向量相乘并拼接one = paddle.concat([one, state @ window], axis=2)# 计算窗口内的最大值作为新的状态state = paddle.max(one, axis=2, keepdim=True)# 调整状态的形状one = state.reshape([b, k, h, w])state = state[..., -1:]# 如果窗口尺寸不等于预设的win,则裁剪输出if r != self.win:one = one[..., :r]# 调整输出的维度并添加到列表中one = one.transpose([0, 3, 1, 2])one_list.append(one)# 将所有窗口的数据拼接起来out = paddle.concat(one_list, 1)# 调整输出的形状out = out.reshape([b, s, -1])# 返回处理后的输出和状态return out, state
MaxState 类定义了一个自定义的神经网络层,它似乎用于处理输入数据的窗口并计算每个窗口的最大状态。
class FeedForward(nn.Layer):def __init__(self, hidden_size):super(FeedForward, self).__init__()# 定义两个线性层self.ffn1 = nn.Linear(hidden_size, hidden_size * 2)self.ffn2 = nn.Linear(hidden_size * 2, hidden_size)# 定义门控机制self.gate = nn.Linear(hidden_size, hidden_size * 2)# 定义激活函数self.relu = nn.Silu()def forward(self, x):# 通过第一个线性层x1 = self.ffn1(x)# 通过门控机制和激活函数x2 = self.relu(self.gate(x))# 元素乘x = x1 * x2# 通过第二个线性层x = self.ffn2(x)# 返回输出return x
FeedForward 类定义了一个前馈神经网络层,它包含两个线性层和一个门控机制,以及一个激活函数。这个前馈网络用于 GPT 模型中的每个解码器层。
class RMSNorm(nn.Layer):def __init__(self, dim, eps: float = 1e-6):super(RMSNorm, self).__init__()self.eps = eps# 创建一个可学习的参数,初始化为1.0self.fc = paddle.create_parameter(shape=[dim], dtype='float32',default_initializer=nn.initializer.Constant(value=1.0))def norm(self, x):# 计算 RMSNormreturn x * paddle.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)def forward(self, x):# 应用 RMSNorm 并乘以可学习的参数output = self.norm(x)return output * self.fc
RMSNorm 类实现了 RMSNorm 归一化,这是一种在自然语言处理模型中常用的归一化技术。
class GPTDecoderLayer(nn.Layer):def __init__(self, hidden_size, num_heads):super(GPTDecoderLayer, self).__init__()# 自我注意力层# self.self_attention = MaskMultiHeadAttention(hidden_size, num_heads)self.self_attention = MaxState(hidden_size, num_heads, 8)# 前馈网络self.ffn = FeedForward(hidden_size)# 层归一化self.norm = nn.LayerNorm(hidden_size)# RMSNorm 归一化self.norm1 = RMSNorm(hidden_size)def forward(self, x, state=None, seq_len=None):# 自我注意力层的前向传播x1, state = self.self_attention(x, state)# 残差连接和层归一化x = x1 + xx = self.norm(x)# 前馈网络的前向传播x = self.ffn(x) + x# 残差连接和 RMSNorm 归一化x = self.norm1(x)# 返回输出和状态return x, state
GPTDecoderLayer 类定义了 GPT 模型中的一个解码器层,它包含自我注意力层、前馈网络和两种归一化层。
class PositionalEncoding(nn.Layer):def __init__(self, d_model, max_len=5000):super(PositionalEncoding, self).__init__()# 创建位置编码position = paddle.arange(max_len).unsqueeze(1).astype("float32")div_term = paddle.exp(paddle.arange(0, d_model, 2) * (-math.log(10000.0) / d_model))pe = paddle.zeros([max_len, d_model])pe[:, 0::2] = paddle.sin(position * div_term)pe[:, 1::2] = paddle.cos(position * div_term)self.pe = pe.unsqueeze(0) # Shape: [1, max_len, d_model]# 将位置编码注册为缓冲区(非可训练参数)def forward(self, x, seq_len=None):# 如果没有提供序列长度,则使用整个位置编码if seq_len is None:seq_len = x.shape[1]return x + self.pe[:, :seq_len, :]else:return x + self.pe[:, seq_len - 1:seq_len, :]
PositionalEncoding 类实现了位置编码,这是一种在序列模型中常用的技术,用于给模型提供关于输入序列中单词顺序的信息。
def sinusoidal_position_embedding(max_len, output_dim):# 创建正弦和余弦位置嵌入position = paddle.arange(0, max_len, dtype="float32").unsqueeze(-1)ids = paddle.arange(0, output_dim // 2, dtype="float32")theta = 10000 ** (-2 * ids / output_dim)embeddings = position * thetasin_embeddings = paddle.sin(embeddings)cos_embeddings = paddle.cos(embeddings)return sin_embeddings, cos_embeddings
sinusoidal_position_embedding 函数实现了正弦和余弦位置嵌入的计算。
def rope(q, sin_em, cos_em, seq_len=None):# 应用旋转位置嵌入if seq_len is None:sin_em = sin_em[:q.shape[2]]cos_em = cos_em[:q.shape[2]]else:sin_em = sin_em[seq_len - 1:seq_len]cos_em = cos_em[seq_len - 1:seq_len]# 执行旋转操作q1 = q.reshape([q.shape[0], q.shape[1], q.shape[2], -1, 2])[..., 1]q2 = q.reshape([q.shape[0], q.shape[1], q.shape[2], -1, 2])[..., 0]# 奇数负值*sin_em+偶数正值*cos_em 奇数正值*cos_em+偶数正值*sin_emq3 = paddle.stack([-q1 * sin_em + q2 * cos_em, q1 * cos_em + q2 * sin_em], -1)q = q3.reshape(q.shape) # reshape后就是正负交替了return q
rope 函数实现了旋转位置嵌入(RoPE),这是一种改进的位置编码方法,它通过对嵌入向量进行旋转来编码位置信息。
class ConvEm(nn.Layer):def __init__(self, hidden_size):super(ConvEm, self).__init__()# 定义卷积层self.conv1 = nn.Conv2D(in_channels=3, out_channels=hidden_size//16, kernel_size=3, padding=1)self.bn1 = nn.BatchNorm2D(hidden_size//16)# 定义第二个卷积层self.conv2 = nn.Conv2D(in_channels=hidden_size//16, out_channels=hidden_size//16, kernel_size=3, padding=1)self.bn2 = nn.BatchNorm2D(hidden_size//16)def forward(self, im):# 通过第一个卷积块x = nn.functional.relu(self.bn1(self.conv1(im)))# 通过第二个卷积块x = self.bn2(self.conv2(x))+x# 应用ReLU激活函数x = nn.functional.relu(x)return paddle.nn.functional.max_pool2d(x,4)
ConvEm 类定义了一个卷积神经网络,用于处理图像数据,提取特征,并将其转换为与 GPT 模型兼容的嵌入向量。
class GPT(nn.Layer):def __init__(self, vocab_size, hidden_size, num_heads, num_layers):super(GPT, self).__init__()# 定义词嵌入层self.embedding = nn.Embedding(vocab_size, hidden_size)# 定义标签嵌入层self.label_embedding = nn.Embedding(vocab_size, hidden_size)# 定义解码器层列表self.decoder_layers = nn.LayerList([GPTDecoderLayer(hidden_size, num_heads) for _ in range(num_layers)])# 定义输出层的线性层self.fc = nn.Linear(hidden_size, vocab_size, bias_attr=False)# 创建正弦和余弦位置嵌入self.sin_em, self.cos_em = sinusoidal_position_embedding(50000, hidden_size // num_heads // 2)# 定义卷积层self.conv = paddle.nn.Conv1D(1, 16, kernel_size=3, padding=1, bias_attr=False)# 定义输出层的线性层self.out = nn.Linear(16, 16, bias_attr=False)# 定义层归一化self.layer_nor = paddle.nn.LayerNorm(hidden_size)# 定义RMSNorm归一化# self.rms_norm=RMSNorm(hidden_size)# 定义卷积状态层self.cv_state = ConvEm(hidden_size)def forward(self, xx, image, state=None, seq_len=None):# 通过词嵌入层xx = self.embedding(xx)# 通过卷积状态层处理图像数据image=self.cv_state(image)image =image.reshape([image.shape[0],xx.shape[-1],-1])image=image.reshape([image.shape[0],image.shape[1],-1]).unsqueeze(-1)+paddle.zeros([1,1,1,xx.shape[1]])image =image.transpose([0,3,2,1])x = paddle.max(paddle.concat([xx,image],-2), -2)if state is None:state = [None] * len(self.decoder_layers)i = 0# 应用旋转位置嵌入x = rope(x.reshape([x.shape[0], x.shape[1], -1, self.sin_em.shape[1] * 2]).transpose([0, 2, 1, 3]),self.sin_em,self.cos_em, seq_len).transpose([0, 2, 1, 3]).reshape(x.shape) + x# 通过解码器层列表for decoder_layer in self.decoder_layers:x1, state[i] = decoder_layer(x, state[i])x = x1 + xi += 1# 通过输出层的线性层out = self.fc(self.layer_nor(x))return out, state
在 GPT 类的 forward 方法中,最后一个步骤是通过输出层的线性层将解码器层的输出映射到词汇表的大小。然后,该函数返回最终的输出和状态。
整个 GPT 模型通过这些自定义层和位置编码,以及旋转位置嵌入(RoPE)等技术,实现了对输入序列的编码和解码,从而能够生成或预测序列中的下一个单词。
需要注意的是,这段代码可能需要根据具体的 PaddlePaddle 版本和环境进行调整,以确保代码的正确性和兼容性。此外,由于代码较长,可能存在一些错误或者不完整的部分,因此在实际使用前需要仔细检查和调试。
相关文章:

sam_out 目标检测的应用
缺点参考地址训练验证模型解析 缺点 词表太大量化才可 参考地址 https://aistudio.baidu.com/projectdetail/8103098 训练验证 import os from glob import glob import cv2 import paddle import faiss from out_yolo_model import GPT as GPT13 import pandas as pd imp…...

VLAN原理与配置
AUTHOR :闫小雨 DATE:2024-04-28 目录 VLAN的三种端口类型 VLAN原理 什么是VLAN 为什么使用VLAN VLAN的基本原理 VLAN标签 VLAN标签各字段含义如下: VLAN的划分方式 VLAN的划分包括如下5种方法: VLAN的接口链路类型 创建V…...

使用Spring Boot实现RESTful API
使用Spring Boot实现RESTful API 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!今天我们将深入探讨如何利用Spring Boot框架实现RESTful API,这是现…...
:八所高校)
中英双语介绍美国常春藤联盟( Ivy League):八所高校
中文版 常春藤联盟简介 常春藤联盟(Ivy League)是美国东北部八所私立大学组成的高校联盟。虽然最初是因体育联盟而得名,但这些学校以其学术卓越、历史悠久、校友杰出而闻名于世。以下是对常春藤联盟的详细介绍,包括其由来、成员…...

【计算机网络】常见的网络通信协议
目录 1. TCP/IP协议 2. HTTP协议 3. FTP协议 4. SMTP协议 5. POP3协议 6. IMAP协议 7. DNS协议 8. DHCP协议 9. SSH协议 10. SSL/TLS协议 11. SNMP协议 12. NTP协议 13. VoIP协议 14. WebSocket协议 15. BGP协议 16. OSPF协议 17. RIP协议 18. ICMP协议 1…...

java实现http/https请求
在Java中,有多种方式可以实现HTTP或HTTPS请求。以下是使用第三方库Apache HttpClient来实现HTTP/HTTPS请求的工具类。 优势和特点 URIBuilder的优势在于它提供了一种简单而灵活的方式来构造URI,帮助开发人员避免手动拼接URI字符串,并处理参…...

NC204871 求和
链接 思路: 对于一个子树来说,子树的节点就包括在整颗树的dfs序中子树根节点出现的前后之间,所以我们先进行一次dfs,用b数组的0表示区间左端点,1表示区间右端点,同时用a数组来标记dfs序中的值。处理完dfs序…...

git克隆代码warning: could not find UI helper ‘git-credential-manager-ui‘
git克隆代码warning: could not find UI helper ‘git-credential-manager-ui’ 方案 git config --global --unset credential.helpergit-credential-manager configure...

Generator 是怎么样使用的以及各个阶段的变化如何
Generators 是 JavaScript 中一种特殊类型的函数,可以在执行过程中暂停,并且在需要时恢复执行。它们是通过 function* 关键字来定义的。Generator 函数返回的是一个迭代器对象,通过调用该迭代器对象的 next() 方法来控制函数的执行。在调用 n…...

一文了解Java中 Vector、ArrayList、LinkedList 之间的区别
目录 1. 数据结构 Vector 和 ArrayList LinkedList 2. 线程安全 Vector ArrayList 和 LinkedList 3. 性能 插入和删除操作 随机访问 4. 内存使用 ArrayList 和 Vector LinkedList 5. 迭代器行为 ArrayList 和 Vector LinkedList 6. 扩展策略 ArrayList Vecto…...

【论文复现|智能算法改进】基于自适应动态鲸鱼优化算法的路径规划研究
目录 1.算法原理2.改进点3.结果展示4.参考文献5.代码获取 1.算法原理 SCI二区|鲸鱼优化算法(WOA)原理及实现【附完整Matlab代码】 2.改进点 非线性收敛因子 WOA 主要通过控制系数向量 A 来决定鲸鱼是搜索猎物还是捕获猎物,即系数向量 A 可…...

【Win测试】窗口捕获的学习笔记
2 辨析笔记 2.1 mss:捕获屏幕可见区域,不适合捕获后台应用 Claude-3.5-Sonnet: MSS库可以用来捕获屏幕上可见的内容;然而,如果游戏窗口被其他窗口完全遮挡或最小化,MSS将无法捕获到被遮挡的游戏窗口内容,而…...

PostgreSQL的学习心得和知识总结(一百四十七)|深入理解PostgreSQL数据库之transaction chain的使用和实现
目录结构 注:提前言明 本文借鉴了以下博主、书籍或网站的内容,其列表如下: 1、参考书籍:《PostgreSQL数据库内核分析》 2、参考书籍:《数据库事务处理的艺术:事务管理与并发控制》 3、PostgreSQL数据库仓库…...

宝塔linux网站迁移步骤
网站迁移到新服务器步骤 1.宝塔网站迁移,有个一键迁移工具,参考官网 宝塔一键迁移API版本 3.0版本教程 - Linux面板 - 宝塔面板论坛 (bt.cn)2 2.修改域名解析为新ip 3.如果网站没有域名,而是用ip访问的,则新宝塔数据库的wp_o…...
: MOSFETIGBT)
电路笔记(三极管器件): MOSFETIGBT
MOSFET vs IGBT MOSFET主要用于低电压和功率系统,而IGBT更适合高电压和功率系统。 1. MOSFET(金属氧化物半导体场效应晶体管) 优势: 高开关速度和响应速度,适合高频应用。(IGBT不适合高频应用,…...

Docker 镜像导出和导入
docker 镜像导出 # 导出 docker 镜像到本地文件 docker save -o [输出文件名.tar] [镜像名称[:标签]] # 示例 docker save -o minio.tar minio/minio:latest-o 或 --output:指定导出文件的路径和名称[镜像名称[:标签]]:导出镜像名称以及可选的标签 dock…...
QueryClientProvider is not defined
QueryClientProvider is not defined 运行一个svelte的项目,报错如上,前后查找解决不了,然后没办法, 本来是用yarn 安装的依赖,改用npm install,再次运行就成功了...
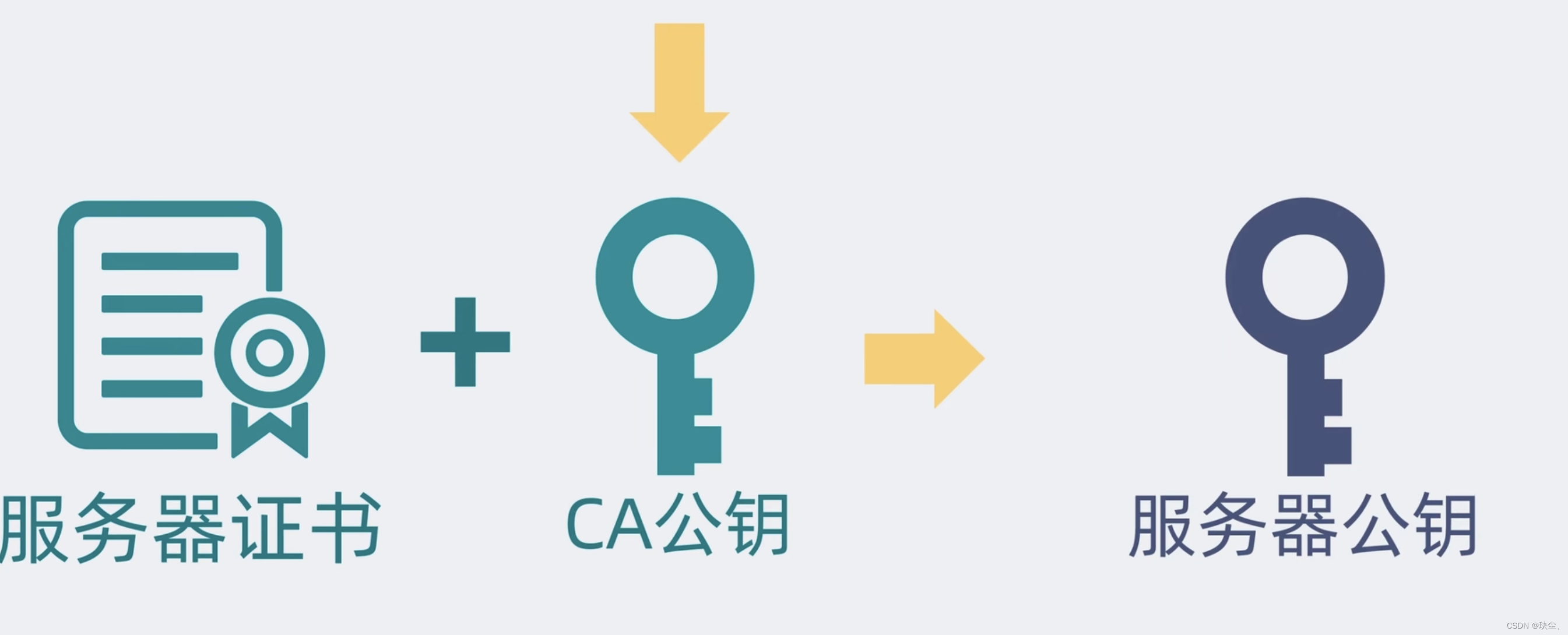
HTTPS是什么?原理是什么?用公钥加密为什么不能用公钥解密?
HTTPS(HyperText Transfer Protocol Secure)是HTTP的安全版本,它通过在HTTP协议之上加入SSL/TLS协议来实现数据加密传输,确保数据在客户端和服务器之间的传输过程中不会被窃取或篡改。 HTTPS 的工作原理 客户端发起HTTPS请求&…...

系统中非功能性需求的思考
概要 设计系统时不仅要考虑功能性需求,还要考虑一些非功能性需求,比如: 扩展性可靠性和冗余安全和隐私服务依赖SLA要求 下面对这5项需要考虑的事项做个简单的说明 1. 可扩展性 数据量增长如何扩展? 流量增长如何扩展…...

力扣第215题“数组中的第K个最大元素”
在本篇文章中,我们将详细解读力扣第215题“数组中的第K个最大元素”。通过学习本篇文章,读者将掌握如何使用快速选择算法和堆排序来解决这一问题,并了解相关的复杂度分析和模拟面试问答。每种方法都将配以详细的解释,以便于理解。…...

JAVA低空经济无人机飞手接单平台系统源码开发与部署方案
随着低空经济产业的快速发展,无人机应用场景不断拓展,航拍、测绘、巡检、物流等领域对专业飞手的需求日益增长,飞手接单难、需求方找飞手繁琐的行业痛点愈发突出。一、系统开发核心原则(务实合规,贴合场景)…...

JSON格式强制输出失败,深度解析DeepSeek-R1/V3模型token级响应机制与schema约束绕过方案
更多请点击: https://intelliparadigm.com 第一章:JSON格式强制输出失败的现象与根本归因 典型失败现象 当后端服务(如 Go/Node.js/Python)尝试通过 HTTP 响应强制输出 JSON 数据时,常出现空响应、500 错误、或返回 …...

Crustocean/conch:轻量级容器化工具,简化开发者本地环境搭建
1. 项目概述:一个面向开发者的轻量级容器化工具最近在和一些做后端开发的朋友聊天,发现大家普遍有个痛点:本地开发环境和线上环境不一致,导致“在我机器上好好的”这种经典问题频繁上演。虽然Docker已经普及,但完整的D…...

React极简表单库veyra-forms:轻量级、类型安全的表单状态管理方案
1. 项目概述:一个被低估的轻量级表单解决方案在Web开发的世界里,表单处理是个既基础又麻烦的活儿。从简单的联系表单到复杂的多步骤数据收集,开发者们总是在寻找一个平衡点:既要功能强大、易于集成,又要足够轻量、不拖…...

Claude任务大师浏览器扩展:AI自动化工作流与Chrome插件开发实战
1. 项目概述与核心价值最近在折腾AI自动化工作流,发现一个痛点:虽然像Claude这样的AI助手能力很强,但每次想让它帮我处理网页内容,都得手动复制粘贴,效率实在太低。直到我发现了GitHub上一个名为“claude-task-master-…...

AI智能体配置管理:从环境变量到结构化配置的工程实践
1. 项目概述:一个为AI智能体量身定制的配置管理中枢最近在折腾AI智能体(Agent)相关的项目,无论是基于LangChain、AutoGPT还是其他框架,一个绕不开的痛点就是配置管理。API密钥、模型参数、工具配置、环境变量……这些零…...

Kali Linux 新手速成:Docker 部署实战与靶场环境一键构建
1. Kali Linux与Docker的黄金组合 刚接触网络安全的朋友们,肯定对Kali Linux不陌生。这个专为安全测试设计的操作系统,就像是一把瑞士军刀,集成了各种强大的工具。但今天我要分享的是一个更高效的玩法——用Docker来部署漏洞靶场。 为什么说这…...

3D打印技术如何重塑消费电子供应链:从原型验证到小批量生产
1. 项目概述:当3D打印遇上消费电子最近几年,我身边不少做产品设计、硬件开发的朋友,聊天时总会不约而同地提到一个词:3D打印。以前大家觉得这玩意儿就是个做手办、打样机的“玩具”,但现在风向明显变了。尤其是在消费电…...

Vivado XADC IP核 配置与接口实战解析
1. XADC IP核基础入门 XADC(Xilinx Analog-to-Digital Converter)是Xilinx FPGA芯片内置的高精度模拟数字转换模块,它能实时监测芯片内部的电压、温度以及外部模拟信号。在Vivado开发环境中,我们可以通过XADC Wizard IP核快速配置…...

ARM L220 L2缓存控制器架构解析与问题解决方案
1. ARM L220 L2缓存控制器深度解析与问题实战指南作为ARM11系列处理器的关键组件,L220 Level 2 Cache控制器在提升系统性能方面发挥着不可替代的作用。这款发布于2009年的缓存控制器采用当时先进的AXI总线协议,支持多核环境下的缓存一致性管理࿰…...