Pytorch实战(二)
文章目录
- 前言
- 一、LeNet5原理
- 1.1LeNet5网络结构
- 1.2LeNet网络参数
- 1.3LeNet5网络总结
- 二、AlexNext
- 2.1AlexNet网络结构
- 2.2AlexNet网络参数
- 2.3Dropout操作
- 2.4PCA图像增强
- 2.5LRN正则化
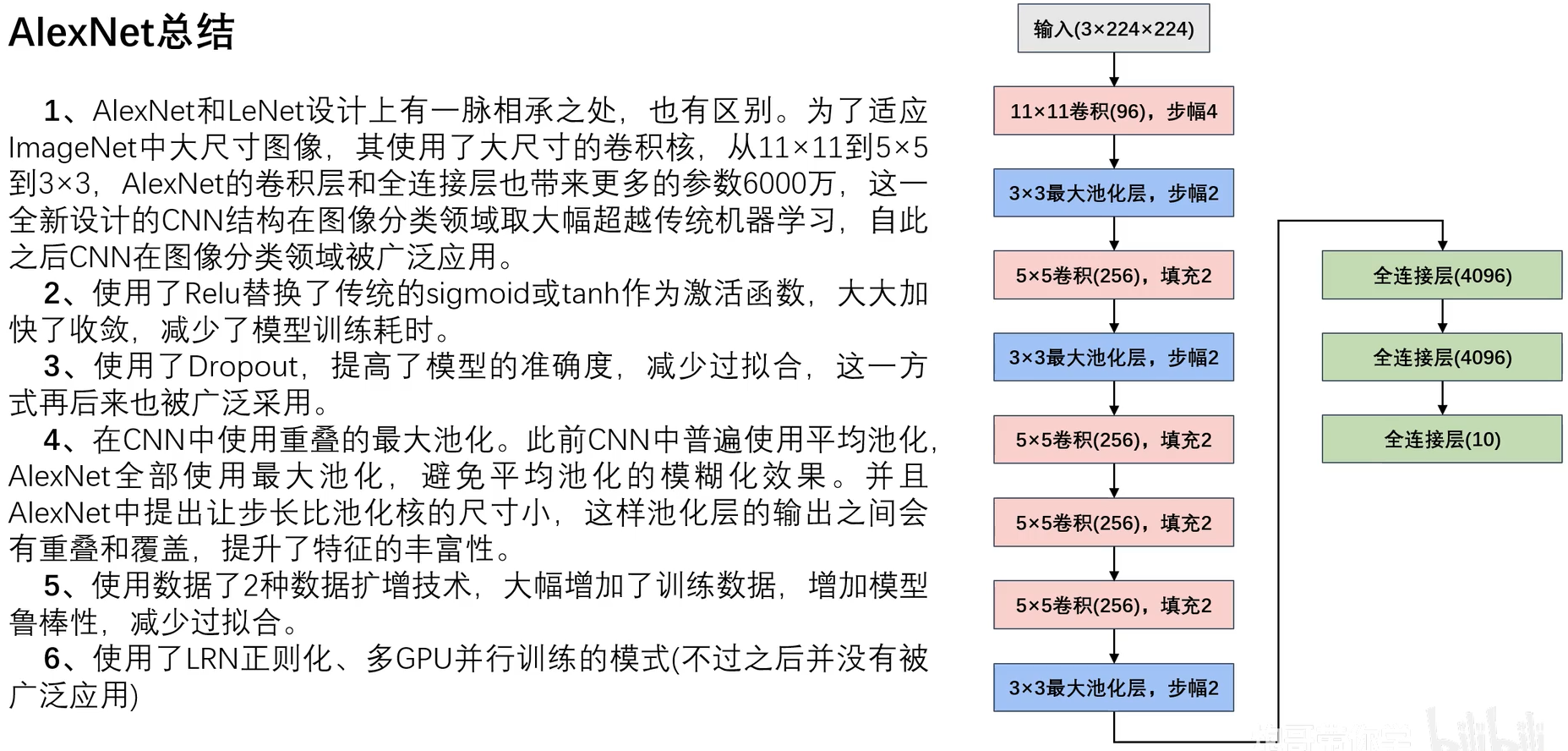
- 2.6AlexNet总结
- 三、LeNet实战
- 3.1LeNet5模型搭建
- 3.2可视化数据
- 3.3加载训练、验证数据集
- 3.4模型训练
- 3.5可视化训练结果
- 3.6模型测试
- 四、AlexNet实战
前言
参考原视频:哔哩哔哩。
一、LeNet5原理
1.1LeNet5网络结构
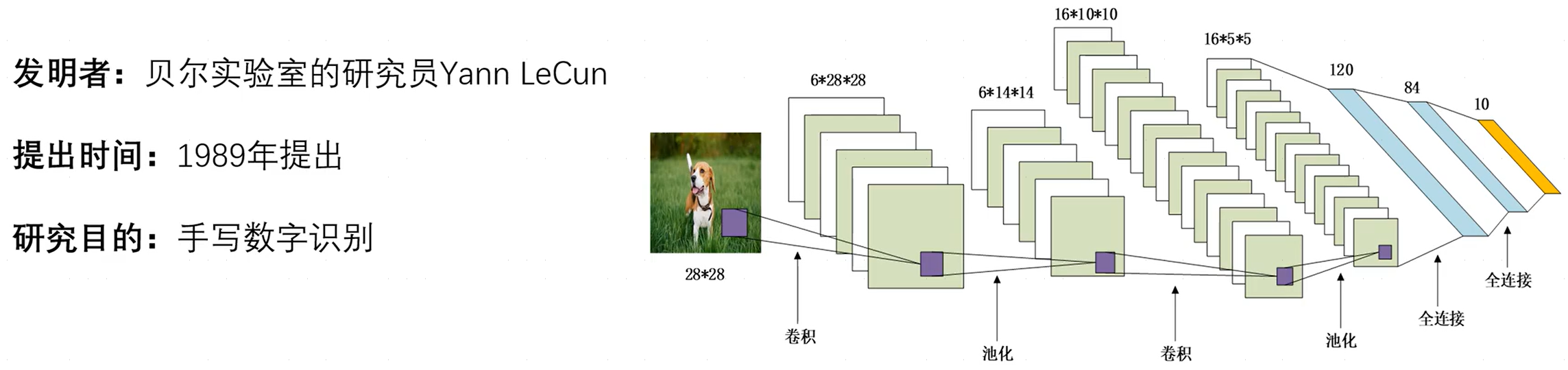
LeNet-5,其中, 5 5 5表示神经网络中带有参数的网络层数量为 5 5 5,如卷积层带有参数 ( w , b ) (w,b) (w,b),而池化层仅仅是一种操作,并不带有参数,而在LeNet-5中共含有两层卷积层、三层全连接层(有一层未标出)。
- 卷积层和池化层:用于提取特征。
- 全连接层:一般位于整个卷积神经网络的最后,负责将卷积输出的二维特征图转化成一维的一个向量(将特征空间映射到标记空间),由此实现了端到端的学习过程(即:输入一张图像或一段语音,输出一个向量或信息)。全连接层的每一个结点都与上一层的所有结点相连因而称之为全连接层。由于其全相连的特性,一般全连接层的参数也是最多的。
事实上,不同的卷积核提取的特征并不相同,比如猫、狗、鸟都有眼睛,而如果只用局部特征的话不足以确定具体类别,此时就需要使用全连接层组合这些特征来最终确定是哪一个分类,即起到组合特征和分类器功能。
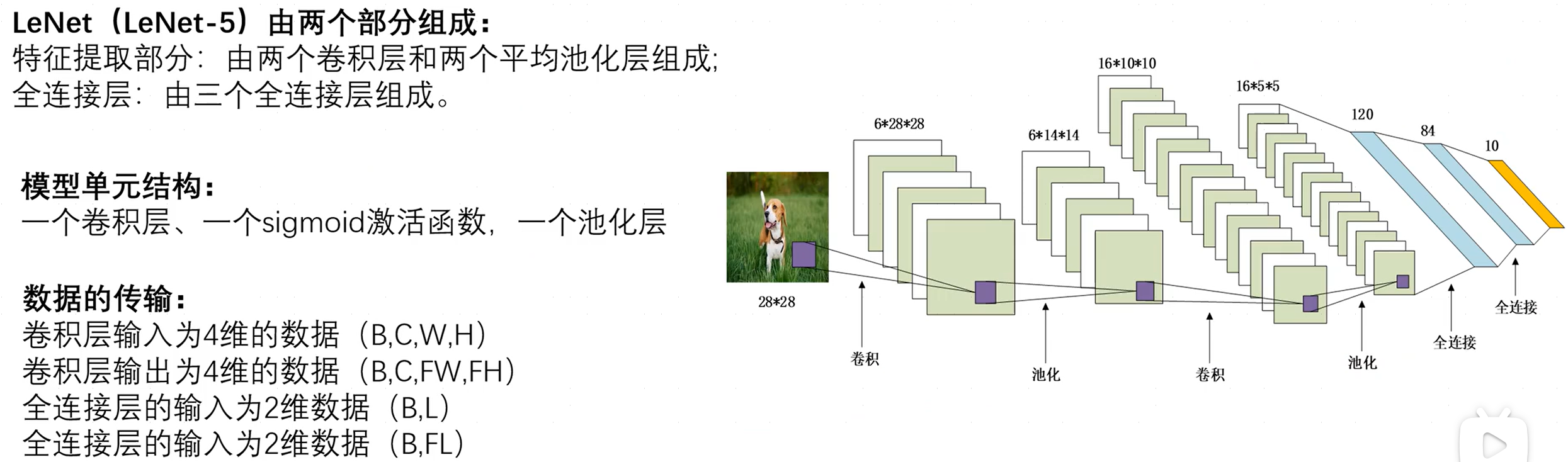
1.2LeNet网络参数
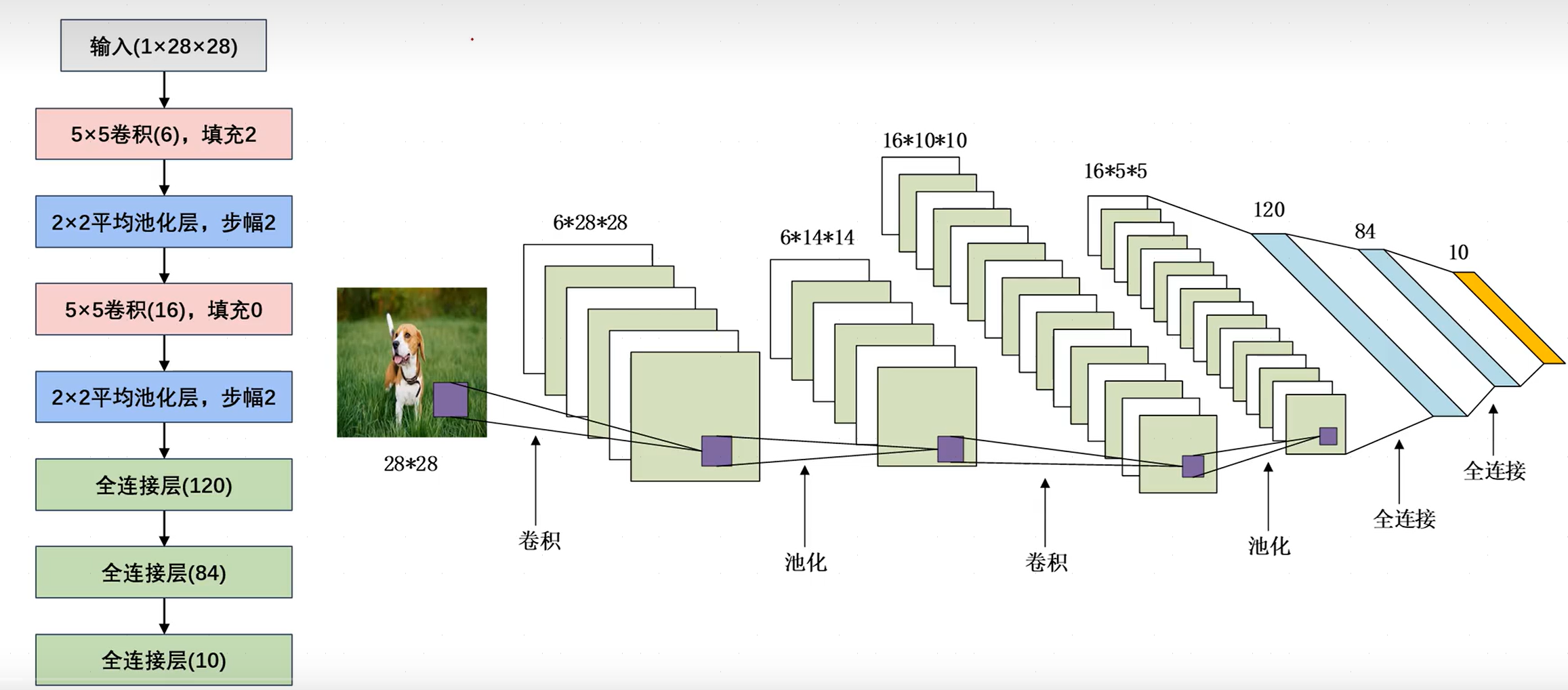
- 输入层:输入大小为(28,28)、通道数为1的灰度图像。
- 卷积层:卷积核尺寸为(6,5,5),即六个5x5大小的卷积核,填充为2,故输出特征图尺寸为(6,28,28)。
- 池化层:使用平均池化,步幅为2,故输出特征图尺寸为(6,14,14)。
- 卷积层:卷积核尺寸为(16,6,5,5),即16个6x5x5大小的卷积核,故输出特征图为(16,10,10).
- 池化层:使用平均池化,步幅为2,输出特征图为(16,5,5)。
- 全连接层:将所有特征图均展平为一维向量并进行拼接(通过调用
nn.Flatten完成,输出为二维矩阵,每一行向量都是一张图片的展平形式),对应120个神经元。 - 全连接层:将上一全连接层120个神经元映射为84个神经元。
- 全连接层:将上一全连接层84个神经元映射为10个神经元。
可知,卷积层往往会使通道数变大,而池化层往往会使特征图尺寸变小。
1.3LeNet5网络总结

二、AlexNext

2.1AlexNet网络结构
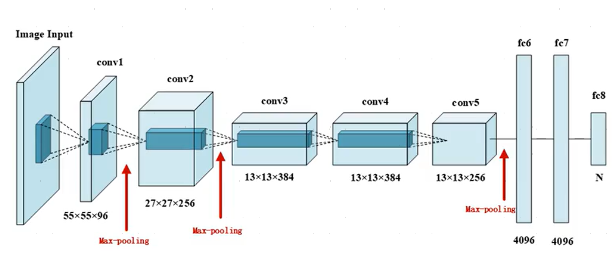
AlexNet与LeNet设计理念相似,但有如下差异:
- AlexNet比LeNet要深很多。
- AlexNet由八层组成,包括五个卷积层,两个全连接隐藏层和一个全连接输出层。
- AlexNet使用ReLUctant而非sigmoid作为激活函数。
2.2AlexNet网络参数
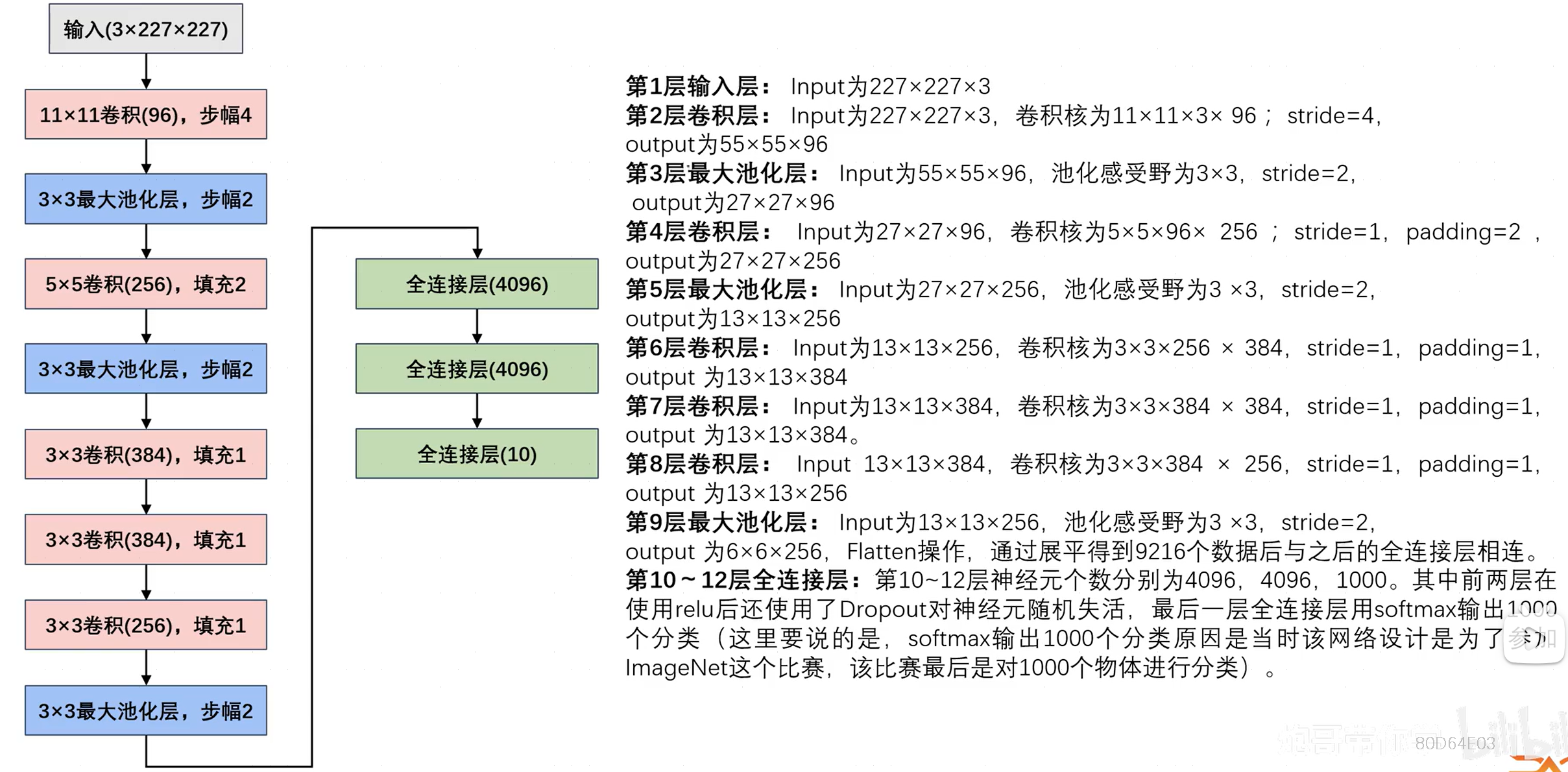
注意:
- 图中的数据格式为(H,W,C,N),且最后全连接层的10是因为之后的案例输出为10个分类。
- 网络参数过多时容易出现过拟合的情况(全连接层存在大量参数 w 、 b w、b w、b),使用Dropout随机失活神经元。
2.3Dropout操作
Dropout用于缓解卷积神经网络CNN过拟合而被提出的一种正则化方法,它确实能够有效缓解过拟合现象的发生,但是Dropout带来的缺点就是可能会减缓模型收敛的速度,因为每次迭代只有一部分参数更新,可能导致梯度下降变慢。

其中,神经元的失活仅作用于一轮训练,在下一轮训练时又会随机选择神经元失活。每一轮都会有随机的神经元失活,以此降低缓解过拟合并提高模型训练速度。
2.4PCA图像增强
图像增强是采用一系列技术去改善图像的视觉效果,或将图像转换成一种更适合于人或机器进行分析和处理的形式。例如采用一系列技术有选择地突出某些感兴趣的信息,同时抑制一些不需要的信息,提高图像的使用价值。

2.5LRN正则化
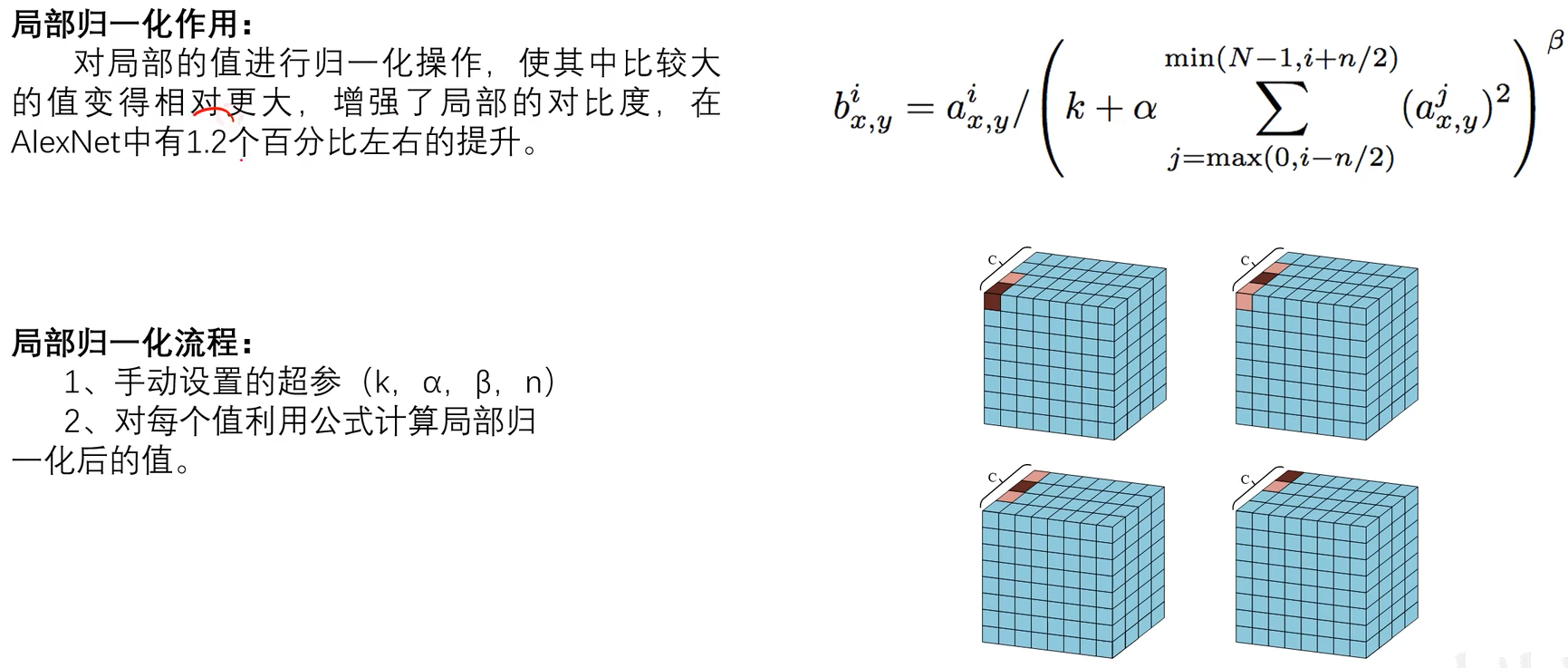
2.6AlexNet总结
三、LeNet实战
3.1LeNet5模型搭建

import torch
from torch import nn
from torchvision.datasets import FashionMNIST
from torchvision import transforms
import matplotlib.pyplot as plt
import numpy as np
import torch.utils.data as Datadevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")class LeNet(nn.Module):def __init__(self):super(LeNet, self).__init__()self.model = nn.Sequential(nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, padding=2),nn.Sigmoid(),nn.AvgPool2d(kernel_size=2, stride=2),nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5),nn.AvgPool2d(kernel_size=2, stride=2),nn.Flatten(),nn.Linear(in_features=16 * 5 * 5, out_features=120),nn.Linear(in_features=120, out_features=84),nn.Linear(in_features=84, out_features=10),)def forward(self, x):return self.model(x)myLeNet = LeNet().to(device)
print(summary(myLeNet,input_size=(1, 28, 28)))
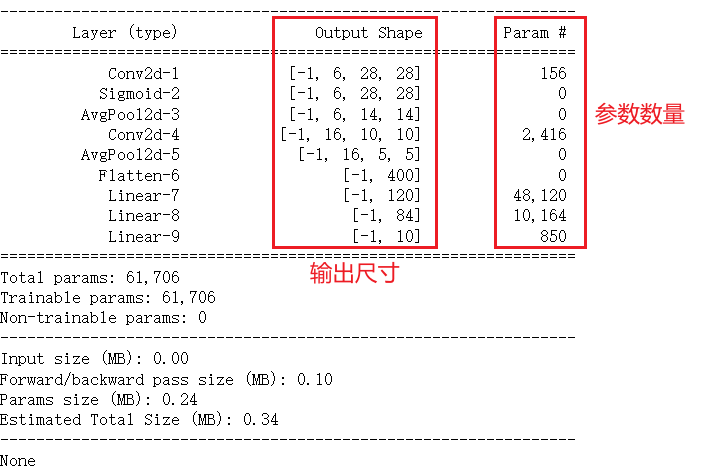
注意,此处在卷积层后使用了sigmoid激活函数,事实上,卷积操作本质仍是一种线性操作,而若只有线性变换,那无论多少层神经元,都能简化层一层神经元,那神经网络只是简单多元线性回归而已,不能拟合更加复杂的函数。此时使用激活函数就可将神经网络非线性化,即提升神经网络的拟合能力,能拟合更复杂的函数。
3.2可视化数据
加载模型,取出一个batch的数据及标签用于可视化:
train_data = FashionMNIST(root="./", train=True, transform=transforms.ToTensor(), download=True) # FashionMNIST图像大小为28x28,无需调整
train_loader = Data.DataLoader(dataset=train_data, batch_size=64, shuffle=True)
# 数据可视化
def show_img(train_loader):for step, (x, y) in enumerate(train_loader):if step > 0: # 恒成立breakbatch_x = x.squeeze().numpy()batch_y = y.numpy()class_label = train_data.classes# 可视化fig = plt.figure(figsize=(8, 8))for i in range(64):ax = fig.add_subplot(8, 8, i + 1, xticks=[], yticks=[])ax.imshow(batch_x[i], cmap=plt.cm.binary)ax.set_title(class_label[batch_y[i]])
show_img(train_loader)

3.3加载训练、验证数据集
训练模型:
def train_val_process(train_data, batch_size=128):train_data, val_data = Data.random_split(train_data,lengths=[round(0.8 * len(train_data)), round(0.2 * len(train_data))])train_loader = Data.DataLoader(dataset=train_data,batch_size=batch_size,shuffle=True,num_workers=8)val_loader = Data.DataLoader(dataset=val_data,batch_size=batch_size,shuffle=True,num_workers=8)return train_loader, val_loadertrain_dataloader, val_dataloader = train_val_process(train_data)
3.4模型训练
import copy
import timeimport torch
from torch import nn
from torchvision.datasets import FashionMNIST
from torchvision import transforms
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import torch.utils.data as Data
def train(model, train_dataloader, val_dataloader, epochs=30, lr=0.001):device = torch.device("cuda" if torch.cuda.is_available() else "cpu")optimizer = torch.optim.Adam(model.parameters(), lr=lr)criterion = nn.CrossEntropyLoss()model = model.to(device)# 复制当前模型的参数best_model_params = copy.deepcopy(model.state_dict())# 最高准确率best_acc = 0.0# 训练集损失函数列表train_loss_list = []# 验证集损失函数列表val_loss_list = []# 训练集精度列表train_acc_list = []# 验证集精度列表val_acc_list = []# 记录当前时间since = time.time()for epoch in range(epochs):print("Epoch {}/{}".format(epoch + 1, epochs))print("-" * 10)# 当前轮次训练集的损失值train_loss = 0.0# 当前轮次训练集的精度train_acc = 0.0# 当前轮次验证集的损失值val_loss = 0.0# 当前轮次验证集的精度val_acc = 0.0# 训练集样本数量train_num = 0# 验证集样本数量val_num = 0# 按批次进行训练for step, (x, y) in enumerate(train_dataloader): # 取出一批次的数据及标签x = x.to(device)y = y.to(device)# 设置模型为训练模式model.train()out = model(x)# 查找每一行中最大值对应的行标,即为对应标签pre_label = torch.argmax(out, dim=1)# 计算损失函数loss = criterion(out, y)optimizer.zero_grad()loss.backward()optimizer.step()# 累计损失函数,其中,loss.item()是一批次内每个样本的平均loss值(因为x是一批次样本),乘以x.size(0),即为该批次样本损失值的累加train_loss += loss.item() * x.size(0)# 累计精度(训练成功的样本数)train_acc += torch.sum(pre_label == y.data)# 当前用于训练的样本数量(对应dim=0)train_num += x.size(0)# 按批次进行验证for step, (x, y) in enumerate(val_dataloader):x = x.to(device)y = y.to(device)# 设置模型为验证模式model.eval()torch.no_grad()out = model(x)# 查找每一行中最大值对应的行标,即为对应标签pre_label = torch.argmax(out, dim=1)# 计算损失函数loss = criterion(out, y)# 累计损失函数val_loss += loss.item() * x.size(0)# 累计精度(验证成功的样本数)val_acc += torch.sum(pre_label == y.data)# 当前用于验证的样本数量val_num += x.size(0)# 计算该轮次训练集的损失值(train_loss是一批次样本损失值的累加,需要除以批次数量得到整个轮次的平均损失值)train_loss_list.append(train_loss / train_num)# 计算该轮次的精度(训练成功的总样本数/训练集样本数量)train_acc_list.append(train_acc.double().item() / train_num)# 计算该轮次验证集的损失值val_loss_list.append(val_loss / val_num)# 计算该轮次的精度(验证成功的总样本数/验证集样本数量)val_acc_list.append(val_acc.double().item() / val_num)# 打印训练、验证集损失值(保留四位小数)print("轮次{} 训练 Loss: {:.4f}, 训练 Acc: {:.4f}".format(epoch+1, train_loss_list[-1], train_acc_list[-1]))print("轮次{} 验证 Loss: {:.4f}, 验证 Acc: {:.4f}".format(epoch+1, val_loss_list[-1], val_acc_list[-1]))# 如果当前轮次验证集精度大于最高精度,则保存当前模型参数if val_acc_list[-1] > best_acc:# 保存当前最高准确度best_acc = val_acc_list[-1]# 保存当前模型参数best_model_params = copy.deepcopy(model.state_dict())print("保存当前模型参数,最高准确度: {:.4f}".format(best_acc))# 训练耗费时间time_use = time.time() - sinceprint("当前轮次耗时: {:.0f}m {:.0f}s".format(time_use // 60, time_use % 60))# 加载最高准确率下的模型参数,并保存模型torch.save(best_model_params, "LeNet5_best_model.pth")train_process = pd.DataFrame(data={'epoch': range(epochs),'train_loss_list': train_loss_list,'train_acc_list': train_acc_list,'val_loss_list': val_loss_list,'val_acc_list': val_acc_list})train_process.to_csv("LeNet5_train_process.csv", index=False)return train_process
train_process = train(myLeNet, train_dataloader, val_dataloader, epochs=30, lr=0.001)
查看LeNet5_train_process.csv:

注意,需要使用.double().item(),否则报错TypeError: can‘t convert cuda:0 device type tensor to numpy. Use Tensor.cpu() to copy the tensor。
3.5可视化训练结果
# 训练结果可视化
def train_process_visualization(train_process):plt.figure(figsize=(12, 4))plt.subplot(1, 2, 1)plt.plot(train_process['epoch'], train_process['train_loss_list'], 'ro-', label='train_loss')plt.plot(train_process['epoch'], train_process['val_loss_list'], 'bs-', label='val_loss')plt.legend()plt.xlabel('epoch')plt.ylabel('loss')plt.subplot(1, 2, 2)plt.plot(train_process['epoch'], train_process['train_acc_list'], 'ro-', label='train_acc')plt.plot(train_process['epoch'], train_process['val_acc_list'], 'bs-', label='val_acc')plt.legend()plt.xlabel('epoch')plt.ylabel('acc')plt.legend()plt.show()
train_process_visualization(train_process)
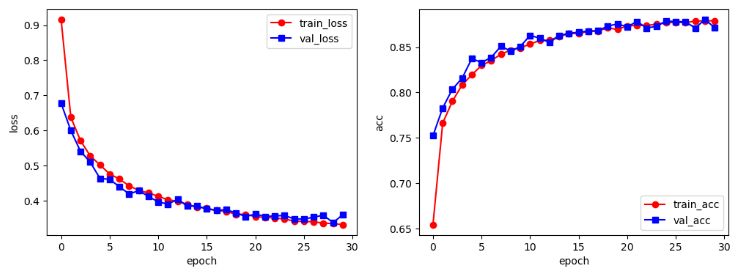
左图为loss与训练轮次的对应图,右图为acc与训练轮次的对应图。可见,随着训练轮次的增加,损失值不断降低、精确度不断提高。
3.6模型测试
def test(model, test_dataloader, device):model.eval()test_acc = 0.0test_num = 0# 推理过程中只前向传播,不用反向传播更新参数,清空梯度节省内存torch.no_grad()for step, (x, y) in enumerate(test_dataloader):x = x.to(device)y = y.to(device)out = model(x)pre_label = torch.argmax(out, dim=1)test_acc += torch.sum(pre_label == y.data)test_num += x.size(0)# 测试集精度test_acc = test_acc.double().item() / test_numprint("测试集精度: {:.4f}".format(test_acc))model = LeNet()
model = model.to(device)
# 加载模型参数
model.load_state_dict(torch.load("LeNet5_best_model.pth"))
test_data = FashionMNIST(root="./", train=False, transform=transforms.ToTensor(), download=True)
test_dataloader = Data.DataLoader(dataset=test_data, batch_size=64, shuffle=True)
test(model, test_dataloader, device)
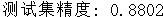
四、AlexNet实战
相关文章:
Pytorch实战(二)
文章目录 前言一、LeNet5原理1.1LeNet5网络结构1.2LeNet网络参数1.3LeNet5网络总结 二、AlexNext2.1AlexNet网络结构2.2AlexNet网络参数2.3Dropout操作2.4PCA图像增强2.5LRN正则化2.6AlexNet总结 三、LeNet实战3.1LeNet5模型搭建3.2可视化数据3.3加载训练、验证数据集3.4模型训…...

wordpress 付费主题modown分享,可实现资源付费
该主题下载地址 下载地址 简介 Modown是基于Erphpdown 会员下载插件开发的付费下载资源、付费下载源码、收费附件下载、付费阅读查看隐藏内容、团购下载的WordPress主题,一款针对收费付费下载资源/付费查看内容/付费阅读/付费视频/VIP会员免费下载查看/虚拟资源售…...
】NIOS II调试器中的重新启动按钮不起作用)
【INTEL(ALTERA)】NIOS II调试器中的重新启动按钮不起作用
目录 说明 解决方法 说明 在 Nios II SBT 调试Eclipse时,如果单击 重新启动 图标, 执行被暂停, 以下错误消息: Dont know how to run. Try "help target." 解决方法 终止程序,再次下载,并启…...

Hive On Spark语法
内层对象定义之特殊数据类型 Array DROP TABLE IF EXISTS test_table_datatype_array; CREATE TABLE test_table_datatype_array (ids array<INT> ) LOCATION test/test_table_datatype_array;SELECTnames,names[1]array(names[2],names[3])names[5],names[-1],array_c…...

利用 fail2ban 保护 SSH 服务器
利用 fail2ban 保护 SSH 服务器 一、关于 fail2ban1. 基本功能与特性2. 工作原理 二、安装与配置1. Debian/Ubuntu系统:2. CentOS/RHEL系统: 三、保护 SSH四、启动 fail2ban 服务五、测试和验证六、查看封禁的 IP 地址七、一些配置八、注意事项 作者&…...
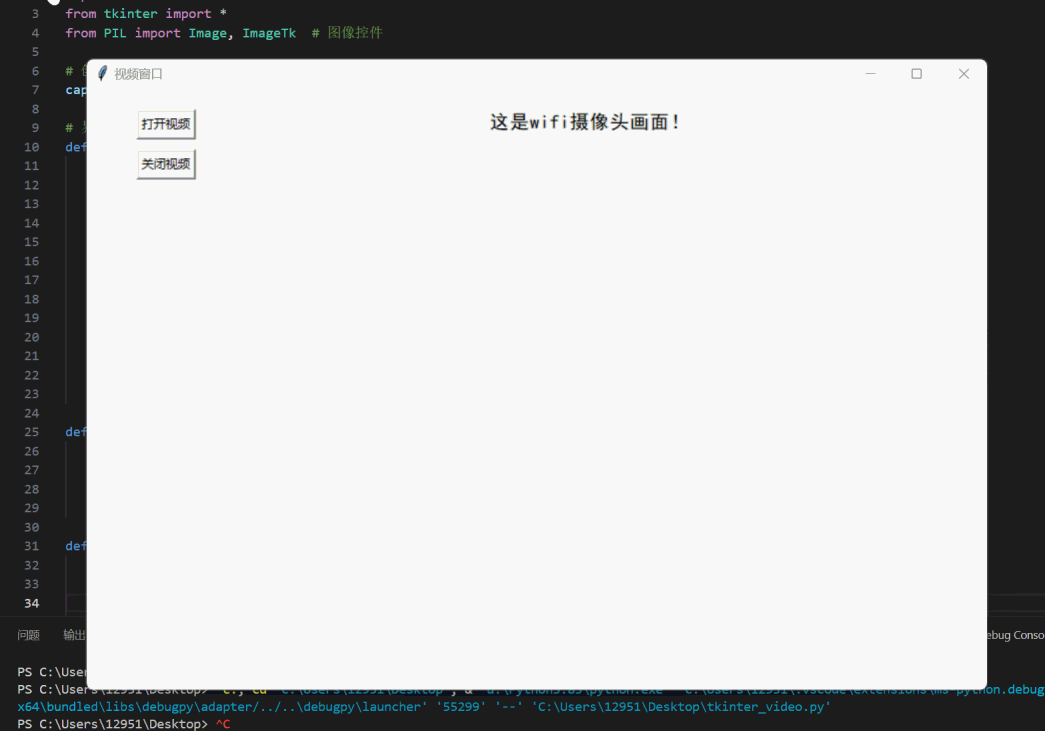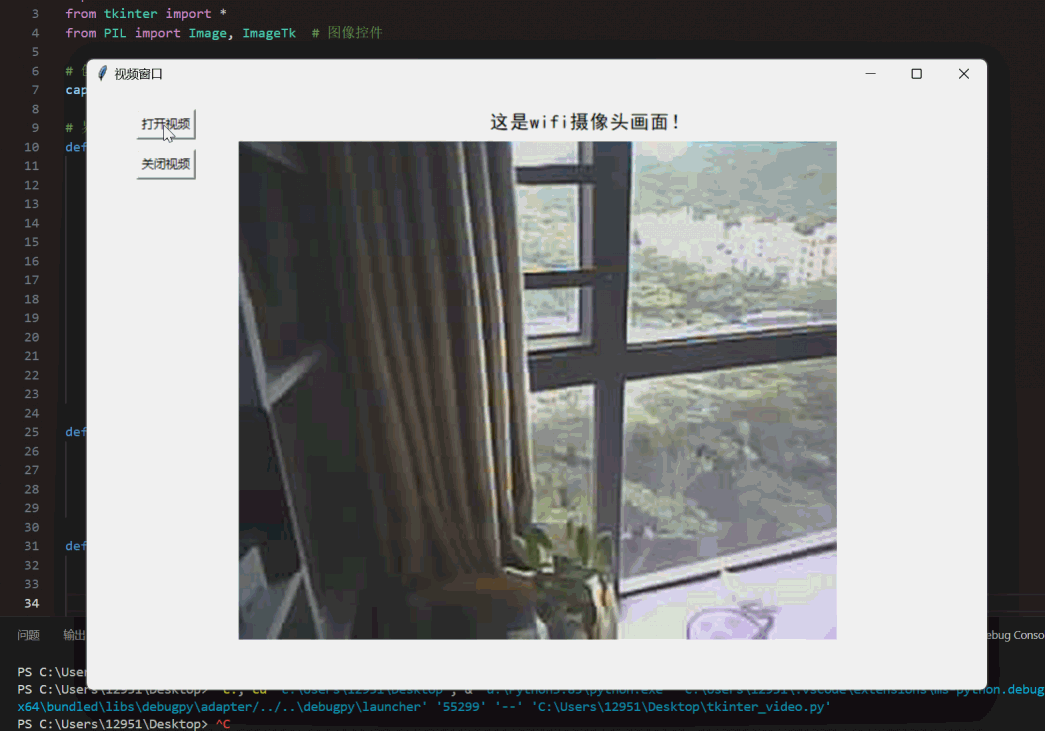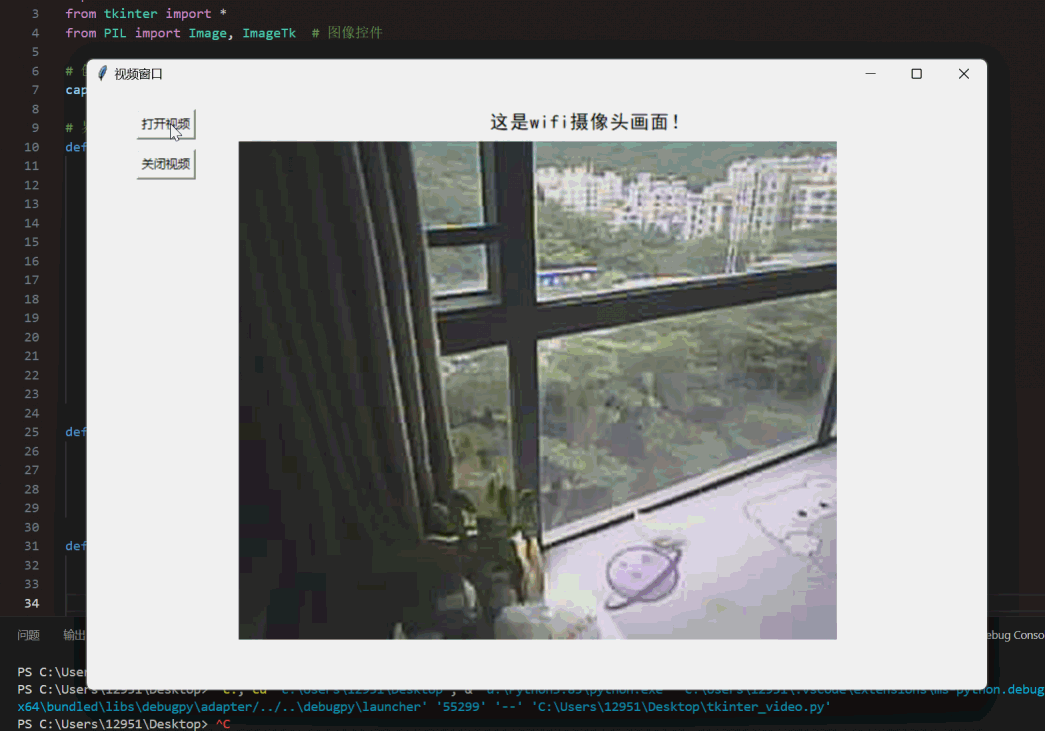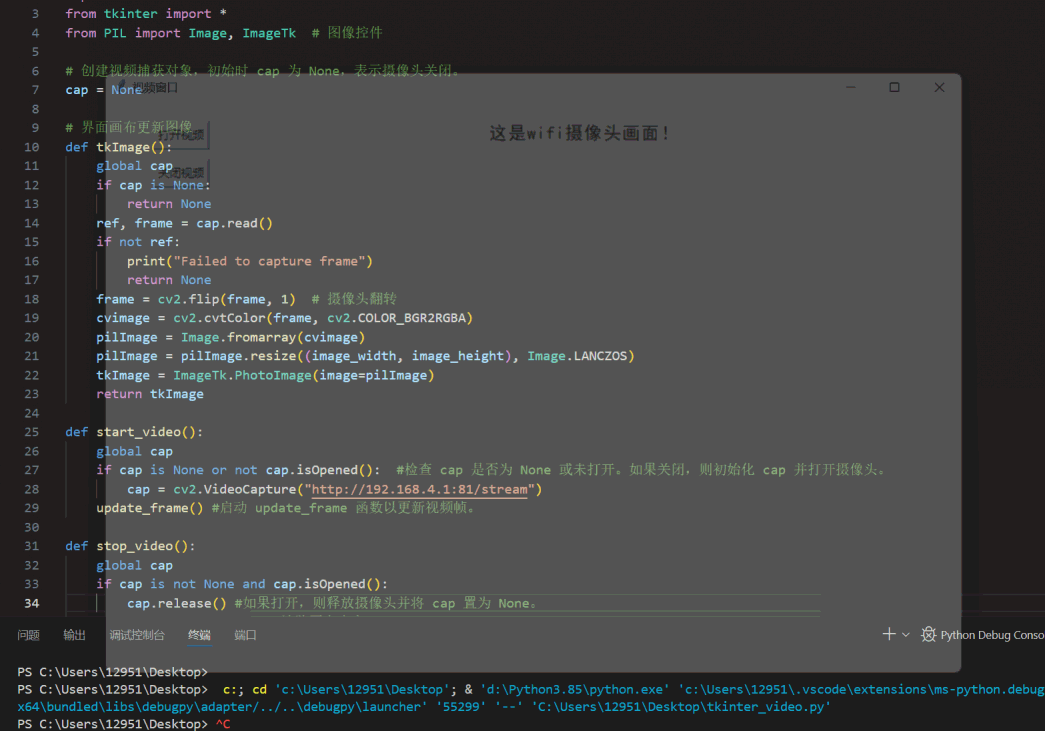
在TkinterGUI界面显示WIFI网络摄像头(ESP32s3)视频画面
本实验结合了之前写过的两篇文章Python调用摄像头,实时显示视频在Tkinter界面以及ESP32 S3搭载OV2640摄像头释放热点(AP)工作模式–Arduino程序,当然如果手头有其他可以获得网络摄像头的URL即用于访问摄像头视频流的网络地址&…...

Yolov8训练时遇到报错SyntaxError: ‘image_weights‘ is not a valid YOLO argument.等问题解决方案
报错说明 line 308, in check_dict_alignmentraise SyntaxError(string CLI_HELP_MSG) from e SyntaxError: image_weights is not a valid YOLO argument. v5loader is not a valid YOLO argument. fl_gamma is not a valid YOLO argument. 解决方法 将训练文件中model.tr…...
javaweb(四)——过滤器与监听器
文章目录 过滤器Filter基本概念滤波器的分类: 时域和频域表示滤波器类型1. 低通滤波器(Low-Pass Filter)2. 高通滤波器(High-Pass Filter)3. 带通滤波器(Band-Pass Filter)4. 带阻滤波器(Band-Stop Filter) 滤波器参数1. 通带频率(Passband Frequency)2. 截止频率(Cutoff Frequ…...

冗余电源的应用,哪些工作站支持冗余电源
冗余电源是一种通过多组电源模块进行备份的技术手段,采用热备插拔式设计,使备用电源在主要电源失效时自动启动,从而确保电源供应不间断。 冗余电源通常应用于对电力要求极高的关键设备和系统,如医疗设备、核电站、数据中心等。在…...

[信号与系统]IIR滤波器与FIR滤波器相位延迟定量的推导。
IIR滤波器与FIR滤波器最大的不同:相位延迟 IIR滤波器相位延迟分析 相位响应和延迟 这里讨论一下理想延迟系统的相位延迟。 对于一个给定的系统频率响应 H ( e j w ) H(e^{jw}) H(ejw)可以表示为 H ( e j w ) ∣ H ( e j w ) ∣ e Φ ( w ) H(e^{jw}) |H(e^{jw…...

Python海量数据处理脚本大集合:pyWhat
pyWhat:精简海联数据,直达数据弱点要害- 精选真开源,释放新价值。 概览 pyWhat是Github社区上一款比较实用的开源Python脚本工具。它能够快速提取信息中的 IP 地址、邮箱、信用卡、数字货币钱包地址、YouTube 视频等内容。当你遇到了一串莫名…...

postgresql搭建
搭建postgresql-11.3,和客户端工具 1,准备对应的包,右键直接下一步安装完即可, 将postgresql设置为本地服务,方便启动, 2,用对应客户端软件连接,新建一个数据库controlDB 新建用户…...

Web 品质标准
Web 品质标准 引言 随着互联网的快速发展,Web应用已经渗透到我们生活的方方面面。为了确保Web应用的质量,提高用户体验,Web品质标准应运而生。这些标准涵盖了多个方面,包括性能、安全性、可访问性、用户体验等。本文将详细介绍这些标准,并探讨它们在实际开发中的应用。 …...

深入理解PyTorch:原理与使用指南
文章目录 引言一、PyTorch的原理1. 动态计算图2. 自动微分3. 张量计算4. 高效的并行计算 二、PyTorch的使用1. 环境配置2. 加载数据3. 构建模型4. 训练模型5. 验证和测试模型 三、PyTorch的安装与配置四、PyTorch的使用示例总结 引言 在深度学习和机器学习的广阔领域中&#x…...
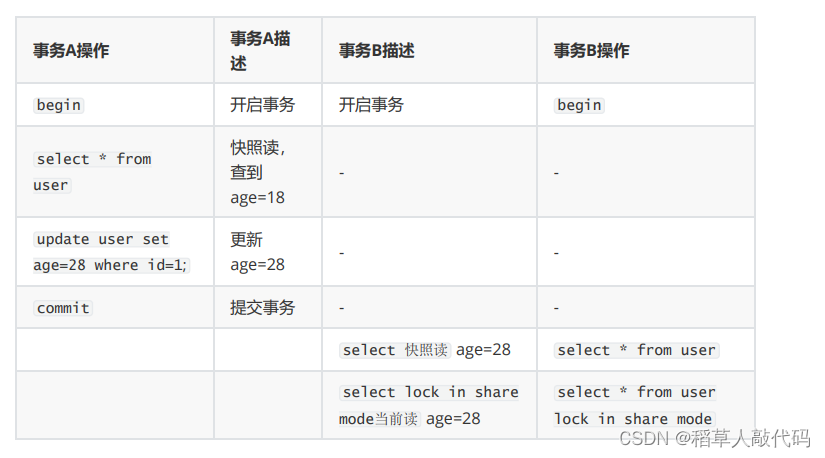
【MySQL事务】深刻理解事务隔离以及MVCC
文章目录 什么叫事务事务的提交方式常见的事务操作方式事务的开始与回滚总结 事务的隔离设置隔离级别解释脏读解释幻读解释不可重复读为什么可重复读不能解决幻读问题?总结 数据库并发的场景MVCC隐藏列字段undo日志Read view RR和RC的本质区别总结 什么叫事务 在My…...

关于Mac mini 10G网口的问题
问题: 购入一个10G网口的Mac mini M2,将其和自己的2.5G交换机连接,使用共享屏幕进行远程操作的过程中出现了频率极高的卡顿,几乎是几秒钟卡一下,使用ping进行测试发现卡的时候就ping不通了。测试使用Mac mini的无线网和雷电转2.5G…...

计算机网络-第4章 网络层
4.1网络层的几个重要概念 4.1.1网络层提供的两种服务 电信网面向连接通信方式,虚电路VC。 互联网设计思路:网络层要设计得尽量简单,向其上层只提供简单灵活的,尽最大努力交付的数据报服务。 网络层不提供服务质量的承诺&#…...

pytorch跑手写体实验
目录 1、环境条件 2、代码实现 3、总结 1、环境条件 pycharm编译器pytorch依赖matplotlib依赖numpy依赖等等 2、代码实现 import torch import torch.nn as nn import torch.optim as optim import torchvision import torchvision.transforms as transforms import matpl…...

利用Java的`java.util.concurrent`包优化多线程性能
利用Java的java.util.concurrent包优化多线程性能 一、引言 在Java的多线程编程中,性能优化是一个永恒的话题。随着多核CPU的普及和计算任务的日益复杂,多线程编程已经成为提高应用程序性能的重要手段。然而,多线程编程也带来了一系列的问题…...

软件著作权申请:开发者的重要保障与助力
一、引言 随着信息技术的飞速发展,软件产业已成为推动经济增长的重要动力。然而,在软件开发过程中,保护创作者的权益、防止抄袭和侵权行为显得尤为重要。软件著作权作为保护软件开发者权益的重要法律工具,其申请和登记流程对于软…...

MusePublic显存利用率提升方案:CPU卸载+自动清理策略详解
MusePublic显存利用率提升方案:CPU卸载自动清理策略详解 1. 项目背景与显存挑战 MusePublic是一款专为艺术感时尚人像创作设计的轻量化文本生成图像系统。基于专属大模型和safetensors格式封装,系统针对艺术人像的优雅姿态、细腻光影和故事感画面进行了…...
)
Lattice Diamond 3.11安装到实战:一个FPGA小白的避坑血泪史(附完整问题清单)
Lattice Diamond 3.11安装到实战:一个FPGA小白的避坑血泪史(附完整问题清单) 如果你正准备踏入Lattice FPGA的世界,手里攥着Diamond 3.11安装包,既兴奋又忐忑——这篇文章就是为你准备的。作为过来人,我深知…...

提示工程架构师用Agentic AI,为智能城市提升品质生活
提示工程架构师:借助Agentic AI提升智慧城市品质生活 一、引言 (Introduction) 钩子 (The Hook) 想象一下,你生活在这样一个城市:每天清晨,你的智能设备会根据当天的天气、你的日程安排,精准推荐最适宜的衣物和出行方式…...

Vue3 + Cornerstone3D:从零构建支持本地Nifti文件上传与四视图联动的医学影像查看器
1. 为什么选择Vue3Cornerstone3D开发医学影像查看器 医学影像处理一直是前端开发中颇具挑战性的领域,特别是当需要处理专业格式如Nifti时。我在实际项目中尝试过多种技术方案后,发现Vue3和Cornerstone3D的组合特别适合快速构建高性能的医学影像应用。 …...
)
Polars 2.0快速接入全链路拆解(含Benchmark实测:比Pandas快42.6×,比Dask低68%内存)
第一章:Polars 2.0快速接入全链路概览Polars 2.0 是一个高性能、内存友好的 DataFrame 库,专为现代多核 CPU 和列式分析场景设计。它通过 Rust 编写核心引擎,Python 接口(polars-py)提供零拷贝数据交互能力,…...

OpenClaw技能开发入门:为百川2-13B模型定制专属自动化模块
OpenClaw技能开发入门:为百川2-13B模型定制专属自动化模块 1. 为什么选择OpenClaw开发技能? 去年冬天,我为了每天早晨能自动获取天气信息并推送到飞书,尝试了不下五种自动化方案。要么需要复杂的服务器部署,要么灵活…...

海尔智能家居无缝接入HomeAssistant:打破品牌壁垒的终极指南
海尔智能家居无缝接入HomeAssistant:打破品牌壁垒的终极指南 【免费下载链接】haier 项目地址: https://gitcode.com/gh_mirrors/ha/haier 还在为家中海尔设备无法与其他智能设备联动而烦恼吗?想象一下,炎热的夏天回家前就能远程开启…...

技术深度解析:ER-Save-Editor如何实现跨平台艾尔登法环存档编辑
技术深度解析:ER-Save-Editor如何实现跨平台艾尔登法环存档编辑 【免费下载链接】ER-Save-Editor Elden Ring Save Editor. Compatible with PC and Playstation saves. 项目地址: https://gitcode.com/GitHub_Trending/er/ER-Save-Editor 艾尔登法环存档编辑…...

RC滤波器设计原理与工程实践指南
1. RC滤波器设计原理与工程实践1.1 滤波器在嵌入式系统中的作用在嵌入式系统设计中,传感器信号普遍存在噪声干扰问题。典型场景中,5kHz有效信号常伴随500kHz高频噪声,此时RC无源滤波器凭借低成本、易实现等优势成为首选方案。其硬件设计可直接…...
)
EfficientNet实战:如何在移动端部署B0-B7模型(附显存优化技巧)
EfficientNet移动端部署实战:从模型选型到显存优化全解析 在移动端和边缘计算场景中部署深度学习模型,就像给一辆跑车装上节能引擎——既要保持性能,又要极致压缩资源消耗。EfficientNet系列模型正是这种平衡艺术的代表作,但当开发…...