人工智能--目标检测

欢迎来到 Papicatch的博客

文章目录
🍉引言
🍉概述
🍈目标检测的主要流程通常包括以下几个步骤
🍍数据采集
🍍数据预处理
🍍特征提取
🍍目标定位
🍍目标分类
🍈目标检测在许多领域都有广泛的应用
🍍自动驾驶
🍍安防监控
🍍工业检测
🍈目标检测技术仍面临一些挑战
🍉 区域卷积神经网络
🍈介绍
🍈R-CNN 的详细工作原理
🍍工作流程
🍌候选区域生成
🍌特征提取
🍈关键技术要点
🍈R-CNN 的优点详细分析
🍍高精度检测
🍍 灵活性和通用性
🍍推动技术发展
🍈R-CNN 的局限性
🍍计算效率低下
🍍训练流程复杂
🍍候选区域质量依赖
🍍检测速度慢
🍈R-CNN 的影响和发展
🍍影响
🍌检测效果好
🍌奠定研究基础
🍍发展
🍉YOLO 卷积神经网络
🍈YOLO 的主要工作原理如下
🍈YOLO 系列算法在不断发展和改进。例如,YOLO v3 相比之前的版本有一些改进和特点
🍈YOLO 算法的优点包括
🍈YOLO 算法的局限性包括
🍉 单发多框架检测SSD
🍈其主要流程如下
🍍特征提取
🍍生成锚框
🍍类别和边界框预测
🍍筛选和调整
🍈SSD 算法的一些优点包括
🍈SSD 算法的一些局限性包括
🍉 示例
🍈代码分析
🍉总结
🍉引言
在当今科技飞速发展的时代,人工智能正以前所未有的速度改变着我们的生活和工作方式。其中,目标检测作为人工智能领域中一个关键且极具应用价值的方向,吸引了众多研究者的目光。它不仅为我们打开了理解和处理视觉信息的新大门,也为解决各种实际问题提供了强大的技术支持。
🍉概述
目标检测是计算机视觉和人工智能领域中的一项重要任务,其目的是在图像或视频中准确地识别和定位感兴趣的目标对象。
🍈目标检测的主要流程通常包括以下几个步骤
🍍数据采集
收集大量包含目标对象的图像或视频数据,这些数据应具有多样性和代表性,以涵盖各种可能的场景和情况。
- 例如,在检测汽车时,需要收集不同品牌、颜色、角度、光照条件下的汽车图像。
🍍数据预处理
对采集到的数据进行清洗、标注和增强等处理。标注是指为图像中的目标对象添加边界框和类别标签,以便模型学习。
- 数据增强技术如翻转、旋转、缩放等,可以增加数据的数量和多样性,减少过拟合的风险。
🍍特征提取
使用深度学习模型自动从图像中提取有意义的特征。常见的模型架构如卷积神经网络(CNN)能够有效地捕捉图像的局部和全局特征。
- 例如,ResNet、VGG 等网络在特征提取方面表现出色。
🍍目标定位
确定目标对象在图像中的位置,通常通过预测边界框的坐标来实现。
🍍目标分类
确定目标对象的类别,例如人、车、动物等。
🍈目标检测在许多领域都有广泛的应用
🍍自动驾驶
检测道路上的车辆、行人、交通标志等,为车辆的行驶决策提供依据。
🍍安防监控
实时监测监控画面中的异常情况,如入侵人员、异常行为等。
🍍工业检测
检测产品的缺陷、尺寸等,提高生产质量和效率。
🍈目标检测技术仍面临一些挑战
- 小目标检测:对于尺寸较小的目标,由于其特征不明显,检测难度较大。
- 复杂场景:在背景复杂、光照变化剧烈、目标遮挡等情况下,准确检测目标具有挑战性。
- 实时性要求:在一些实时应用场景中,需要在短时间内完成检测任务,对算法的效率要求较高。
🍉 区域卷积神经网络
🍈介绍
区域卷积神经网络(Region-based Convolutional Neural Network,R-CNN)是目标检测领域的一个重要里程碑,为后续更先进的目标检测算法奠定了基础。
🍈R-CNN 的详细工作原理
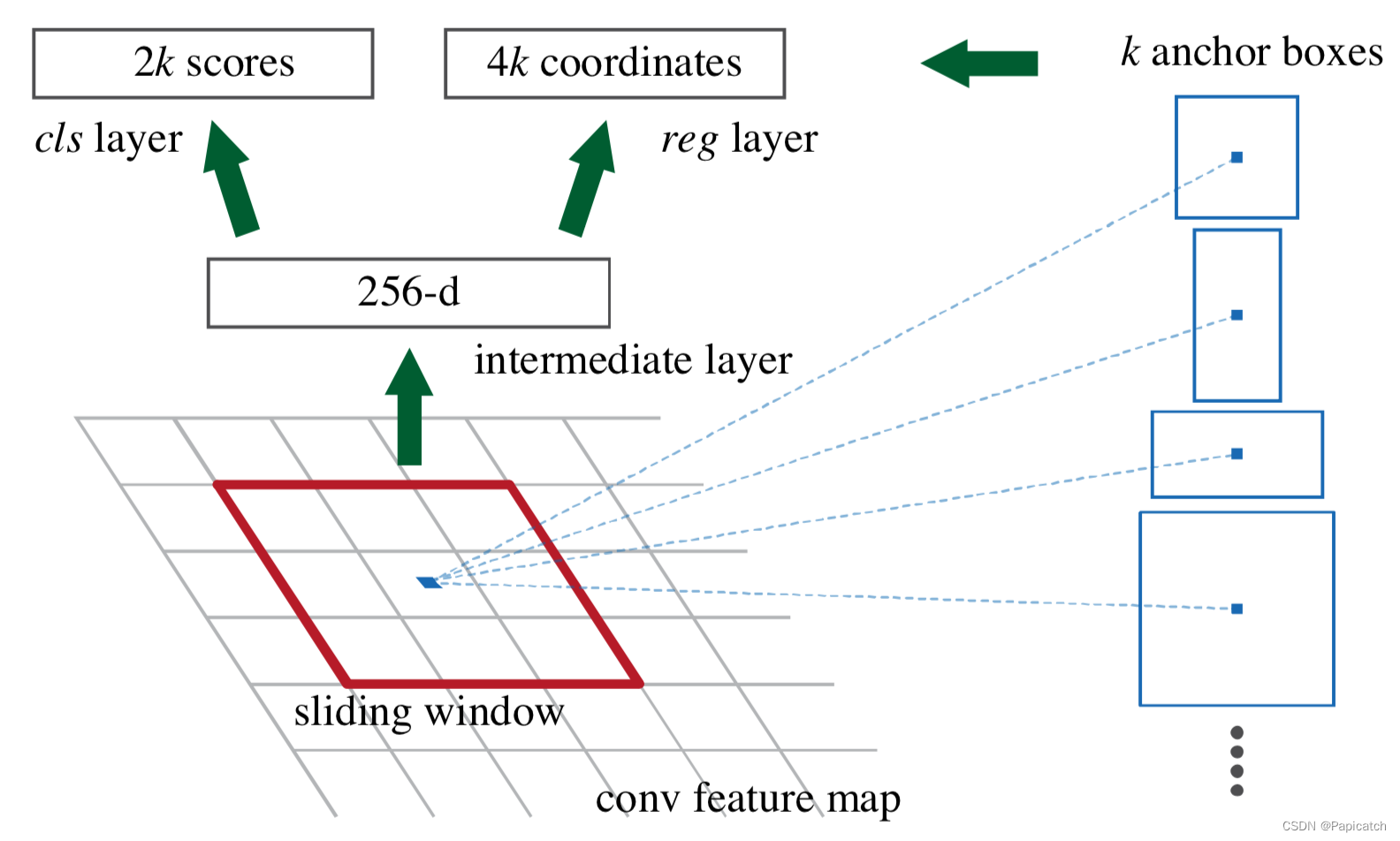
R-CNN(Region-based Convolutional Neural Network)是目标检测领域的一项开创性工作,其独特的方法为后续的目标检测算法提供了重要的思路和基础。
🍍工作流程
🍌候选区域生成
- 运用选择性搜索(Selective Search)算法,基于图像的颜色、纹理、形状等特征,将图像分割成多个可能包含目标的区域。
- 例如,对于一张包含猫和狗的图像,选择性搜索可能会生成多个矩形框,其中一些框可能准确地覆盖了猫和狗的区域。
🍌特征提取
- 将生成的候选区域调整为固定大小(例如 227×227),以适应预训练的卷积神经网络(如 AlexNet)的输入要求。
- 将调整后的候选区域输入到卷积神经网络中,提取 4096 维的特征向量。
🍌分类
- 使用为每个类别训练的支持向量机(SVM)对提取的特征向量进行分类。
- 例如,如果有猫、狗、鸟三个类别,就会有三个对应的 SVM 分类器,分别判断候选区域属于哪个类别。
🍌边界框回归
- 对于每个被分类为目标的候选区域,使用线性回归模型对其边界框进行微调,以得到更精确的位置。
- 例如,初始的候选区域可能不完全准确地框住目标,通过回归可以对边界框的坐标进行修正。
🍈关键技术要点
利用预训练的卷积神经网络进行特征提取,充分利用了深度网络学习到的强大特征表示能力。
选择性搜索算法能够生成质量较高的候选区域,为后续的检测提供了良好的基础。
分类和回归的分开处理,使得每个步骤可以专注于其特定的任务,提高了检测的准确性。
🍈R-CNN 的优点详细分析
🍍高精度检测
深度特征学习:R-CNN 引入了卷积神经网络(CNN)进行特征提取,相比于传统的手工设计特征,CNN 能够自动学习到更具代表性和判别性的特征。这些深度特征能够捕捉图像中目标的复杂结构和语义信息,从而显著提高了检测的准确性。
- 例如,对于形状不规则的物体或在复杂背景下的目标,传统方法可能难以准确识别,但 R-CNN 学习到的深度特征能够更好地区分目标和背景。
候选区域筛选:通过选择性搜索等方法生成候选区域,能够覆盖可能包含目标的各种位置和尺度,增加了检测到目标的可能性。
- 例如,在一张包含多个不同大小和位置物体的图像中,R-CNN 能够全面地考虑各种可能的区域,减少漏检的情况。
🍍 灵活性和通用性
可迁移学习:可以利用在大规模图像分类数据集(如 ImageNet)上预训练好的 CNN 模型,并在目标检测数据集上进行微调。这种迁移学习的策略使得 R-CNN 能够受益于已有的大规模数据训练成果,并且能够应用于各种不同的目标检测任务。
- 比如,原本在 ImageNet 上训练用于识别猫的模型,经过微调可以用于检测汽车等其他目标。
适应多种目标类别:R-CNN 对于不同类型的目标检测任务具有较好的通用性,无论是常见的物体(如人、车、动物)还是特定领域的目标(如医学图像中的病变区域),都可以通过适当的训练来实现检测。
🍍推动技术发展
启发后续研究:R-CNN 的出现为后续的目标检测算法提供了重要的思路和基础,激发了大量的研究工作,推动了整个目标检测领域的快速发展。
- 例如,后续的 Fast R-CNN、Faster R-CNN 等算法都是在 R-CNN 的基础上进行改进和创新的。
促进算法融合:R-CNN 的成功促使研究者将其与其他技术(如增强学习、注意力机制等)相结合,进一步提升了目标检测的性能和灵活性。
🍈R-CNN 的局限性
🍍计算效率低下
重复计算:对每个候选区域都要单独进行卷积神经网络(CNN)的前向传播,存在大量的重复计算。这导致处理一幅图像的时间非常长,难以满足实时性要求。
- 例如,对于 2000 个候选区域,就需要进行 2000 次完整的 CNN 计算。
特征存储:提取的特征需要大量的存储空间来保存,增加了硬件成本和处理的复杂性。
🍍训练流程复杂
多阶段训练:R-CNN 的训练分为多个阶段,包括 CNN 的微调、SVM 的训练以及边界框回归器的训练。每个阶段都需要单独的优化和调整,流程繁琐且难以优化。
- 不同阶段的训练数据和优化目标不同,需要精心设计和协调。
数据需求大:每个阶段都需要大量的标注数据,增加了数据准备的难度和工作量。
🍍候选区域质量依赖
选择性搜索的不足:生成候选区域的选择性搜索算法并非完美,可能会产生过多的无效候选区域,或者遗漏一些关键区域。
- 例如,对于一些紧密相邻的目标,可能会生成一个包含多个目标的大候选区域,影响检测精度。
区域大小固定:在特征提取阶段,将候选区域调整为固定大小可能会导致信息丢失或变形,影响检测效果。
🍍检测速度慢
实时性差:由于上述的计算效率和训练复杂性问题,R-CNN 在实际应用中的检测速度非常慢,难以应用于实时场景,如自动驾驶、视频监控等。
🍈R-CNN 的影响和发展
🍍影响
🍌检测效果好
R-CNN在VOC2007数据集上的检测效果相比传统方法有很大提升,其mAP(平均精度均值)达到了53.3%,相较于之前的最佳结果提高了30%以上。
🍌奠定研究基础
R-CNN算法的出现,为目标检测领域的研究奠定了基础。后续的很多研究工作都是基于R-CNN算法进行的,例如Fast R-CNN、Faster R-CNN等。
🍌推动技术发展
R-CNN算法的成功应用,推动了深度学习技术在目标检测领域的发展。它证明了深度学习方法在目标检测任务中的有效性,促使更多的研究人员投入到这个领域的研究中。
🍍发展
- R-CNN:R-CNN算法首先使用选择性搜索等方法提取图像中的候选区域,然后对这些区域使用CNN提取特征,最后通过SVM进行分类。
- Fast R-CNN:为了解决R-CNN的计算量大、训练过程复杂的问题,Fast R-CNN被提出。它在R-CNN的基础上进行了改进,直接在特征图上进行边框回归和分类,减少了计算量,并提高了检测速度。
- Faster R-CNN:Faster R-CNN进一步改进了物体检测流程,它引入了区域建议网络(RPN),该网络与检测网络共享卷积特征,实现了端到端的训练。RPN的引入不仅提高了检测的速度,还提升了检测的准确性。
🍉YOLO 卷积神经网络
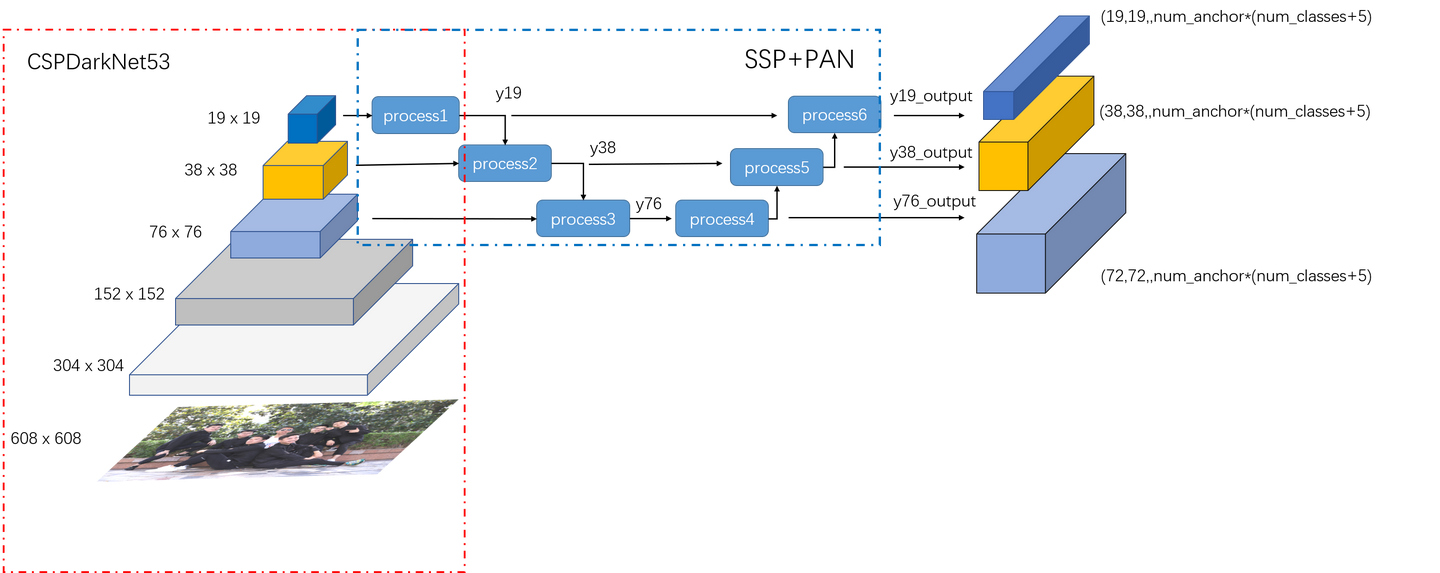
🍈YOLO 的主要工作原理如下
- 输入图像:将整幅图像作为网络的输入。
- 划分网格:YOLO 将输入图像划分成多个网格。
- 预测边界框:每个网格单元负责预测一定数量的边界框(bounding box)。这些边界框包含了目标的位置信息(如中心坐标、宽度和高度)。
- 类别预测:同时,每个边界框还会预测相关的类别概率,即该边界框内包含某类目标的可能性。
- 输出:通过对每个网格单元的预测结果进行综合分析,得到最终的目标检测结果,包括目标的类别和其对应的边界框。
YOLO 仅利用卷积层,是一个全卷积网络(FCN)。例如在 YOLO v3 中,作者提出了名为 Darknet-53 的特征提取器架构,它包含 53 个卷积层,每个卷积层后跟随批量归一化层和 Leaky ReLU 激活函数,使用带有步长 2 的卷积层来降采样特征图,有助于防止池化导致的低级特征丢失。
🍈YOLO 系列算法在不断发展和改进。例如,YOLO v3 相比之前的版本有一些改进和特点
- 边界框预测:使用维度集群作为锚框(anchor boxes),通过预测 4 个坐标(tx、ty、tw、th)来确定边界框的位置。采用逻辑回归预测每个边界框的目标性得分。
- 类别预测:使用多标签分类预测边界框可能包含的类别,不使用 softmax,而是采用独立的逻辑分类器,训练时使用二元交叉熵损失进行类预测。这种方法在处理存在重叠标签的数据集(如 Open Images Dataset)时更有效。
- 多尺度预测:在不同尺度上进行预测,以更好地检测不同大小的目标。
🍈YOLO 算法的优点包括
- 速度快:能够快速处理图像并实时给出检测结果。
- 全局特征推理:利用全局上下文信息,对背景的判断更准确。
- 泛化性较好:训练好的模型在新的领域或不期望的输入情况下仍有较好的效果。
🍈YOLO 算法的局限性包括
- 对小目标检测不够好:虽然 YOLO 系列算法在小目标检测方面相对其他一些算法有改进,但在检测极小目标时,仍可能出现误检或漏检的情况;
- 对密集目标检测效果欠佳:由于其采用网格化的方式进行检测,对于相互靠近或密集的目标,检测效果可能不太理想,容易造成重叠检测或遗漏检测;
- 对目标形状变化不太敏感:YOLO 算法通常采用固定大小的输入图像,对于形状变化较大或非正常宽长比的目标,其识别效果可能受到一定影响;
- 定位精度问题:YOLO 算法在损失函数中对大边框和小边框的误差同等对待,但实际上同一损失对于不同尺寸边框的交并比(IOU)影响不同,这可能导致定位误差较大;
- 每个网格单元的限制:每个格点单元仅预测固定数量的边界框,并且只能预测一类目标,具有较强的空间局限性,当同一单元格内存在多个物体的中心时,可能只检测出其中某一种;
- 分类精度有限:作为一种端到端的检测方法,其分类结果的精度可能不及专业的分类模型。
🍉 单发多框架检测SSD
SSD(Single Shot MultiBox Detector,单发多框检测器)是一种基于深度学习的目标检测算法,具有检测速度快、精度较高等优点。
🍈其主要流程如下
🍍特征提取
将输入的图像通过一个卷积神经网络(CNN)进行特征提取,得到一系列特征图。常用的基础网络可以是 VGG、ResNet 等。
🍍生成锚框
对于每个特征图上的每个位置,生成一组预测框(anchor boxes),这些预测框具有不同的宽高比和尺度。生成锚框时,会考虑多种尺度和长宽比,以适应不同形状和大小的目标。
🍍类别和边界框预测
- 类别卷积:把特征图放入单 CNN 卷积层,预测每个锚框的类别。使用卷积层的通道来表示类别预测,通道数为锚框数量乘以类别数加 1(包含背景类)。
- 边界框卷积:同样把特征图放入单 CNN 卷积层,预测每个锚框的边界框,用左上右下的 x、y 坐标表示边界框。输出通道数为锚框数量乘以 4。
🍍筛选和调整
根据预测结果进行筛选和调整,得到最终的检测结果。通过非极大值抑制(NMS)等方法移除相似的预测边界框,找到预测概率最大的边界框 B,并移除和 B 交并比大于某阈值的其他边界框,直到所有边界框都完成筛选。
🍈SSD 算法的一些优点包括
- 检测速度快:采用单发多框的检测方式,不需要像一些两阶段检测算法那样进行区域提议等复杂操作,提高了检测效率。
- 多尺度检测:在不同尺度的特征图上进行预测,能够较好地检测不同大小的目标。
- 精度较高:通过合理设置锚框和使用卷积进行预测,在保持一定检测速度的同时,也能获得较好的检测精度。
🍈SSD 算法的一些局限性包括
- 对小目标的检测效果仍有待提高:虽然它在多尺度检测方面有一定优势,但在检测极小目标时,可能还是会出现一些困难。
- 锚框的设计需要经验和技巧:锚框的尺度和长宽比等参数的选择对检测结果有较大影响,需要进行适当的调整和优化。
- 可能会产生一些冗余的预测框:由于生成的锚框数量较多,可能会存在一些不必要的预测框,需要通过后处理进行筛选。
🍉 示例
以下是一个基于 YOLOv3 的目标检测的简单示例代码
import torch
import cv2
import numpy as np# 加载预训练的 YOLOv3 模型
model = torch.hub.load('ultralytics/yolov3', 'yolov3')# 读取图像
image = cv2.imread('image.jpg')# 进行目标检测
results = model(image)# 解析检测结果
labels = results.pandas().xyxy[0]['name']
boxes = results.pandas().xyxy[0][['xmin', 'ymin', 'xmax', 'ymax']].values# 绘制检测框和标签
for label, box in zip(labels, boxes):xmin, ymin, xmax, ymax = boxcv2.rectangle(image, (int(xmin), int(ymin)), (int(xmax), int(ymax)), (0, 255, 0), 2)cv2.putText(image, label, (int(xmin), int(ymin) - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)# 显示结果
cv2.imshow('Detection Result', image)
cv2.waitKey(0)
cv2.destroyAllWindows()🍈代码分析
model = torch.hub.load('ultralytics/yolov3', 'yolov3'):使用torch.hub加载预训练的YOLOv3模型。
cv2.imread('image.jpg'):读取要进行目标检测的图像。
results = model(image):将图像输入模型进行检测,得到检测结果。解析结果部分,从
results中提取出检测到的目标的标签和边界框坐标。通过循环,使用
cv2.rectangle和cv2.putText函数在图像上绘制检测框和标签。最后显示检测结果图像。
🍉总结
- 目标检测是计算机视觉领域的重要任务,旨在从图像或视频中准确识别和定位感兴趣的目标对象。
- 目标检测技术的发展经历了从传统方法到基于深度学习的方法的重大转变。传统方法通常基于手工设计的特征和分类器,如 Haar 特征、HOG 特征结合 SVM 等,但其检测精度和泛化能力相对有限。
- 随着深度学习的兴起,基于卷积神经网络(CNN)的目标检测算法取得了显著的成果。如 R-CNN 系列算法,引入了深度特征学习和区域建议的概念,大幅提高了检测精度。YOLO 和 SSD 等算法则采用单阶段检测方式,实现了更快的检测速度。
- 目标检测在众多领域有着广泛的应用,包括自动驾驶、安防监控、工业检测、医疗影像分析等。然而,目前的目标检测技术仍面临一些挑战,例如对小目标和密集目标的检测效果有待提升,在复杂场景下的准确性和鲁棒性需要增强,以及如何在保证精度的同时进一步提高检测速度以满足实时应用的需求。
- 未来,目标检测技术有望通过不断改进网络架构、融合多模态数据、优化训练策略等方式,取得更出色的性能,为各种实际应用提供更可靠和高效的解决方案。

相关文章:
人工智能--目标检测
欢迎来到 Papicatch的博客 文章目录 🍉引言 🍉概述 🍈目标检测的主要流程通常包括以下几个步骤 🍍数据采集 🍍数据预处理 🍍特征提取 🍍目标定位 🍍目标分类 🍈…...

Java基础之List实现类
文章目录 一、基本介绍二、常见方法三、ArrayList注意事项四、ArrayList底层结构我的理解 五、ArrayList扩容机制无参构造器有参构造器 六、LinkedList介绍底层操作机制 七、ArrayList 与 LinkedListArrayListLinkedList tip:以下是正文部分 一、基本介绍 List集合…...

java List接口介绍
List 是 Java 集合框架中的一个接口,它继承自 Collection 接口,代表一个有序的元素集合。List 允许重复的元素,并且可以通过索引来访问元素。Java 提供了多种 List 的实现,如 ArrayList、LinkedList、Vector 和 CopyOnWriteArrayList。 List接口概述 List 接口提供了一些…...
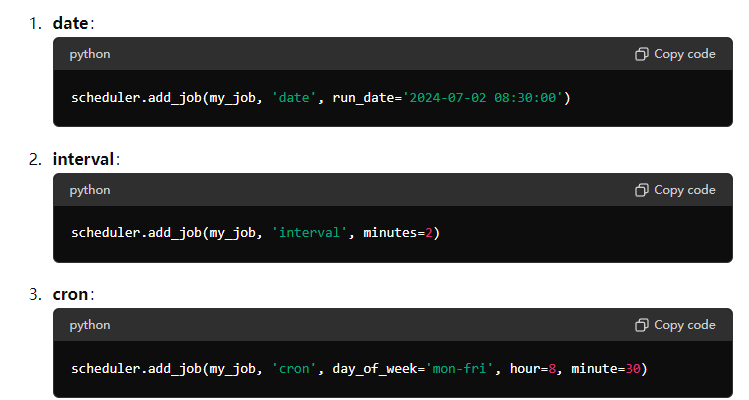
调度器APScheduler定时执行任务
APScheduler(Advanced Python Scheduler)是一个Python库,用于调度任务,使其在预定的时间间隔或特定时间点执行。它支持多种调度方式,包括定时(interval)、日期(date)和Cr…...

git合并分支的疑问
今天遇到一个奇怪的问题: 1、后端从master拉了三个分支。分别为dev、test、和stage。 2、研发1从dev拉了分支feature1,然后commit、commit、commit……。最后request merge到dev、test和stage。成功了。 3、研发2从dev拉了分支feature2,注意,feature2…...

catia数控加工仿真Productlist无法添加部件或零件
这种情况是没有把NCSetup显示 在工具中勾选即可...
关于Pycharm右下角不显示解释器interpreter的问题解决
关于Pycharm右下角不显示解释器interpreter的问题 在安装新的Pycharm后,发现右下角的 interpreter 的选型消失了: 觉得还挺不习惯的,于是网上找解决办法,无果。 自己摸索了一番后,发现解决办法如下: 勾…...

为什么word生成的PDF内容显示不全?
在现代办公环境中,将文档从一个格式转换为另一个格式是一个常见的任务。然而,有时候我们可能会遇到意想不到的问题,比如使用Word转换成PDF时,生成的PDF文件只显示了整个界面的四分之一内容。这种问题不仅令人困扰,也可…...

JVM专题十三:总结与整理(持续更新)
图解JVM JVM与Java体系结构 JVM垃圾回收算法 JVM垃圾回收器 图解JVM主要是放了前面12个章节的我们给大家画的图,做了整体的汇总,大家可以根据图区回忆我们所说的内容,查缺补漏。 实战经验 1、项目中数据量多少,QPS与TPS最高多少…...
MobPush iOS端海外推送最佳实现
推送注册 在AppDelegate里进行SDK初始化(也可以在Info.plist文件中进行AppKey,AppSecret的配置)并对通知功能进行注册以及设置推送的环境和切换海外服务器等,参考如下步骤代码: <span style"background-colo…...
商家团购app微信小程序模板
手机微信商家团购小程序页面,商家订餐外卖小程序前端模板下载。包含:团购主页、购物车订餐页面、我的订单、个人主页等。 商家团购app微信小程序模板...

探索AudioLM:音频生成技术的未来
目录 2. AudioLM的基础理论 2.1. 音频生成的基本概念 2.2. 语言模型在音频生成中的应用 2.3. 深度学习在音频生成中的作用 3. AudioLM的架构与实现 3.1. AudioLM的基本架构 3.1.1 编码器 3.1.2 解码器 3.1.3 生成模块 3.2. 训练过程 3.2.1 数据预处理 3.2.2 损失函…...

计算机视觉:深入了解图像分类、目标检测和图像分割的核心技术
计算机视觉是什么? 计算机视觉是一门致力于让计算机“看懂”图像和视频的技术,它旨在通过模拟人类视觉系统来理解和解释数字化视觉信息。这一领域涉及图像的获取、处理、分析和理解,最终用于从视觉数据中提取有用信息并做出决策。计算机视觉的…...

Django 安装 Zinnia 后出现故障
在Django中安装和配置Zinnia时遇到故障可能有多种原因,通常包括版本兼容性、依赖关系或配置问题。这里提供一些常见的解决方法和调试步骤,帮助大家解决问题。 首先,确保您安装的Zinnia版本与Django版本兼容。查看Zinnia的官方文档或GitHub页…...
.net 8 集成 MinIO文件存储服务,实现bucket管理,以及文件对象的基本操作
一、准备工作 1、本地部署MinIO服务 2、创建MinIO的Access Key 3、创建.net 项目 4、下载MinIO sdk 5、相关文档 二、编写MinIO工具类 三、管理存储桶 1、MyBucket类 (1)判断bucket是否存在 (2)新建bucket (…...
Three.js机器人与星系动态场景:实现3D渲染与交互式控制
内容摘要:使用Three.js库构建了一个交互式的3D场景。组件中创建了一个机器人模型,包括头部、眼睛、触角、身体和四肢,以及两个相同的机器人实例以实现动态效果。场景中还加入了粒子效果,模拟星系环境,增强了视觉效果。…...
Android系统集成和使用FFmpeg
文章目录 前言FFmpeg源码下载交叉编译NDK下载x264编译源码下载编译 FFmpeg编译脚本 AOSP继承FFmpeg 前言 原生AOSP中并未继承FFmpeg,所以要想在android上使用,需要自己编译集成。 FFmpeg源码下载 git clone https://git.ffmpeg.org/ffmpeg.git目前最新…...
水果商城外卖微信小程序模板
手机微信水果外卖,水果电商,水果商城网页小程序模板。包含:主页、列表页、详情页、购物车、个人中心。 水果商城外卖小程序模板...

【前端】面试八股文——输入URL到页面展示的过程
【前端】面试八股文——输入URL到页面展示的过程 1. DNS解析 当用户在浏览器中输入URL并按下回车时,首先需要将域名转换为IP地址,这个过程称为DNS(域名系统)解析。具体步骤如下: 浏览器缓存:浏览器首先检…...
什么是应用安全态势管理 (ASPM):综合指南
软件开发在不断发展,应用程序安全也必须随之发展。 传统的应用程序安全解决方案无法跟上当今开发人员的工作方式或攻击者的工作方式。 我们需要一种新的应用程序安全方法,而ASPM在该方法中发挥着关键作用。 什么是 ASPM? 应用程序安全…...

基于Function Calling的智能对话客户端:让大语言模型从“能说”到“会做”
1. 项目概述:一个能“动手”的智能对话客户端 最近在折腾大语言模型应用的时候,我发现了一个挺有意思的开源项目:chat-xiuliu。它本质上是一个本地运行的LLM客户端,但和那些只能“动嘴皮子”的聊天工具不同,它的核心亮…...

OpenUsage:一站式AI订阅用量监控工具的设计与实战
1. 项目概述:为什么我们需要一个AI订阅用量监控器? 如果你和我一样,是个重度依赖AI编程工具的开发者,那你肯定对下面这个场景不陌生:为了搞清楚自己这个月还剩多少Claude的会话额度,得先打开浏览器&#x…...

终极开源ZPL虚拟打印机:告别物理设备,高效调试条码标签
终极开源ZPL虚拟打印机:告别物理设备,高效调试条码标签 【免费下载链接】Virtual-ZPL-Printer An ethernet based virtual Zebra Label Printer that can be used to test applications that produce bar code labels. 项目地址: https://gitcode.com/…...

解锁MapleStory游戏资源编辑的终极指南:Harepacker-resurrected深度解析
解锁MapleStory游戏资源编辑的终极指南:Harepacker-resurrected深度解析 【免费下载链接】Harepacker-resurrected All in one .wz file/map editor for MapleStory game files 项目地址: https://gitcode.com/gh_mirrors/ha/Harepacker-resurrected 你是否曾…...

有话直说可以解决90%的误解的庖丁解牛
它的本质是:将高维度的、模糊的、充满噪声的 心理潜台词 (Subtext/Implicit Context),强制降维并编码为低维度的、精确的、无歧义的 显性语言 (Explicit Language)。这是一种 去序列化 (Deserialization) 的过程,旨在消除接收端因“猜测”、“…...

OneFileLLM:自动化多源信息聚合工具,提升LLM工作效率
1. 项目概述与核心价值如果你经常和大型语言模型打交道,无论是做研究、写代码还是分析文档,最头疼的事情之一可能就是“喂料”。你需要把分散在本地文件、GitHub仓库、网页、PDF论文甚至YouTube视频里的信息,一股脑儿地塞给LLM,让…...
)
保姆级教程:用ISO镜像给Vcenter 6.7 U3e无损升级到7.0(附每一步截图和注意事项)
从vCenter 6.7 U3e到7.0的无损升级实战指南 在虚拟化运维领域,vCenter的版本迭代往往意味着性能提升和功能增强。对于仍在使用6.7版本的管理员而言,升级到7.0不仅能获得更高效的资源管理能力,还能体验更直观的操作界面。本文将详细解析从6.7 …...

基于向量检索的代码语义搜索:从原理到CodeIndexer实战部署
1. 项目概述:一个为代码库建立语义索引的利器最近在折腾一个老项目的代码重构,面对几十万行混杂着不同语言和框架的代码,想快速定位一个特定功能的实现逻辑,或者查找所有使用了某个第三方库的模块,简直像大海捞针。传统…...

ChatTTS开源对话式语音合成:情感控制与实战部署指南
1. 项目概述:从文本到语音的“情感”革命最近在语音合成圈子里,一个名为ChatTTS的项目热度持续攀升。作为一个长期关注语音技术发展的从业者,我最初也被它“高质量、多语言、可控性强”的描述所吸引。但真正上手后才发现,这个项目…...

Tree of Thoughts详解:思维树搜索算法
🌳 多路径探索 | 广度优先 深度优先搜索 | 自我评估 回溯机制 | LangChain实现 | 完整项目代码 📖 什么是Tree of Thoughts? 核心思想 ToT Tree of Thoughts(思维树) 传统LLM: 输入 → 线性思考 → 输出…...