科普文:一文搞懂jvm原理(四)运行时数据区
概叙
科普文:一文搞懂jvm(一)jvm概叙-CSDN博客
科普文:一文搞懂jvm原理(二)类加载器-CSDN博客
科普文:一文搞懂jvm原理(三)执行引擎-CSDN博客
前面我们介绍了jvm,jvm主要包括两个子系统和两个组件: Class loader(类装载器) 子系统,Execution engine(执行引擎) 子系统;Runtime data area (运行时数据区域)组件, Native interface(本地接口)组件。
这里我们主要讲解Runtime data area (运行时数据区域)组件,讲到这个就和jvm优化相关。
java代码编译和运行流程

主要是两个阶段:编译和执行。
编译:javac编译器将源代码*.java编译成class文件,即java字节码文件。
执行:jvm虚拟机,即java命令执行class文件时,通过加载器加载class文件,并通过执行引擎中的解释器翻译成汇编语言(机器指令+符号表+辅助信息)执行。
JVM组织架构
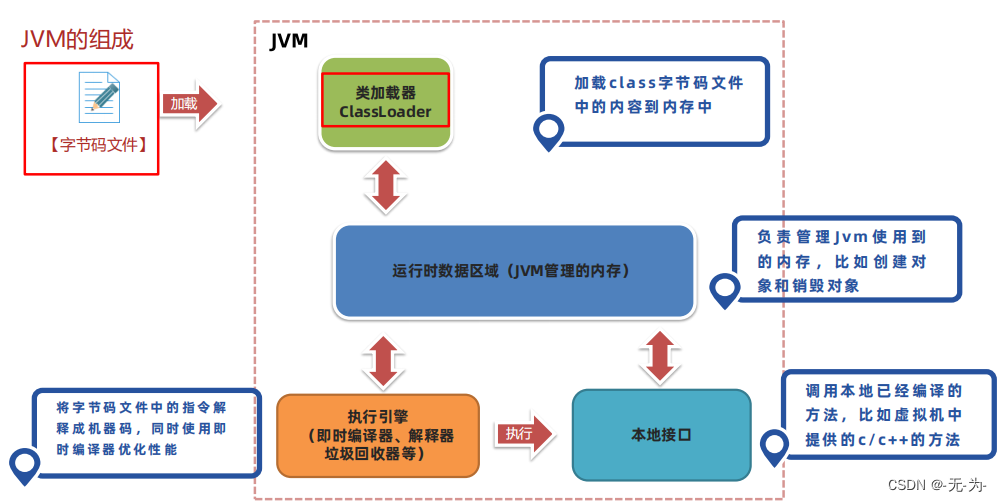
图一:jvm的运行时区、执行引擎、本地方法接口和库
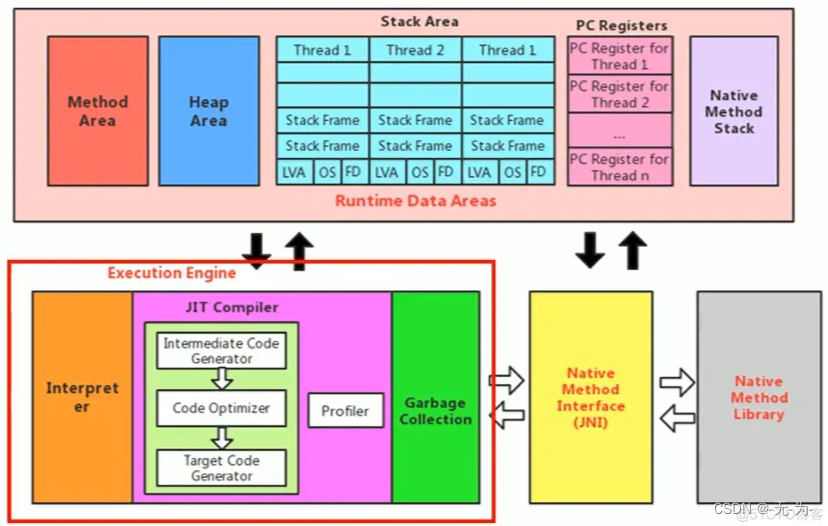
图二:这个是前面文中多次出现的jvm详细图,
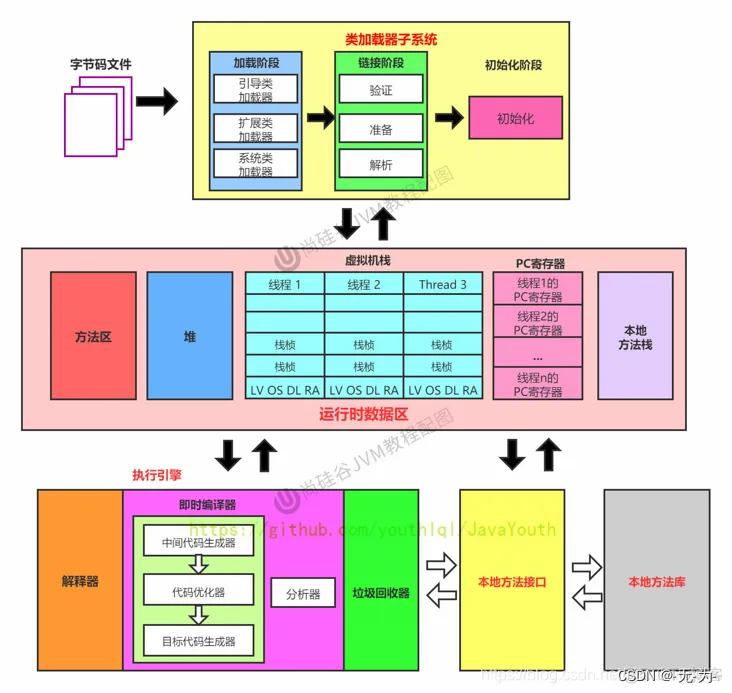
前面我们说过我们的类会经过类加载器进行的加载 –> 验证 –> 准备 –> 解析 –> 初始化,这几个阶段完成后就会用到执行引擎对我们的类进行使用,同时执行引擎将会使用到我们运行时数据区。
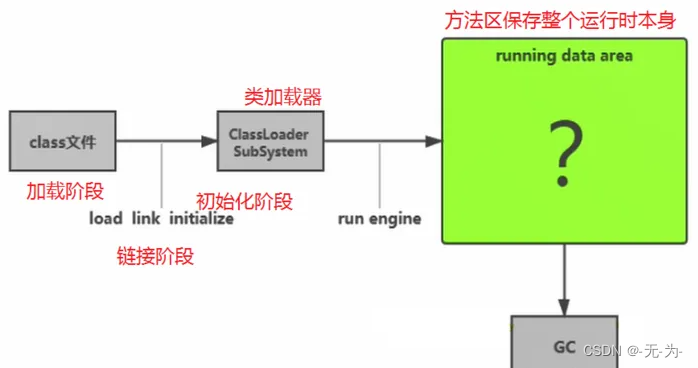
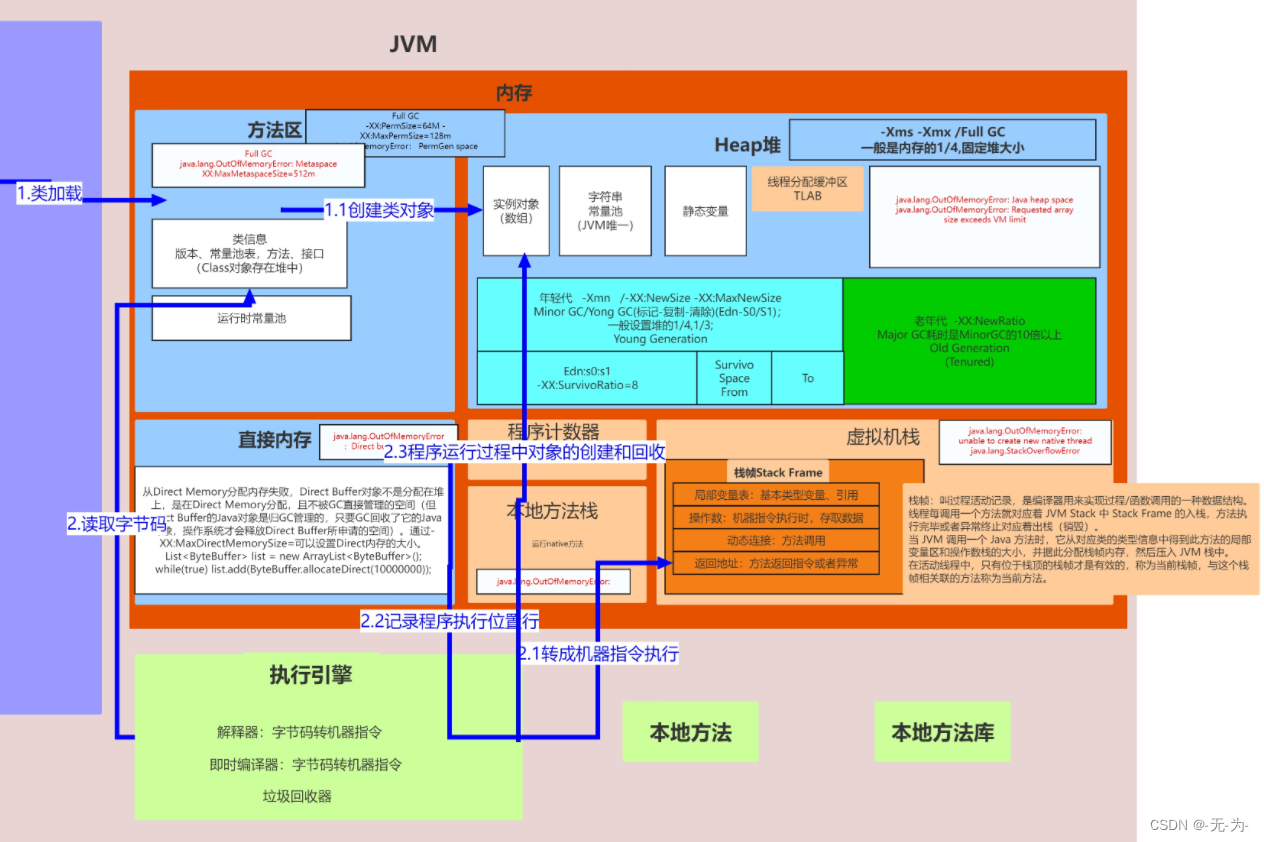
运行时数据区其实用的就是内存,而内存是非常重要的系统资源,是硬盘和CPU的中间仓库及桥梁,承载着操作系统和应用程序的实时运行。JVM内存布局规定了Java在运行过程中内存申请、分配、管理的策略,保证了JVM的高效稳定运行,以及不同的JVM对于内存的划分方式和管理机制存在着部分差异。
jvm内存划分
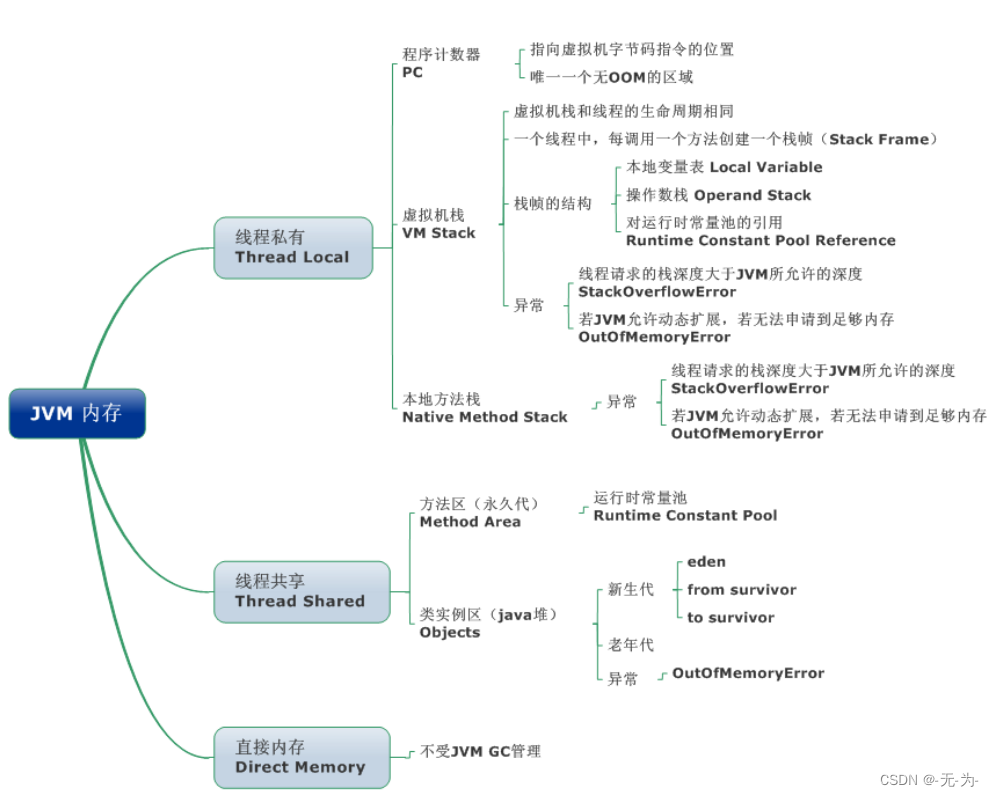
JVM 内存区域主要分为线程私有区域【程序计数器、虚拟机栈、本地方法区】、线程共享区
域【JAVA 堆、方法区】、直接内存。
- 线程私有数据区域生命周期与线程相同, 依赖用户线程的启动/结束 而 创建/销毁(在 Hotspot VM 内, 每个线程都与操作系统的本地线程直接映射, 因此这部分内存区域的存/否跟随本地线程的生/死对应)。
- 线程共享区域随虚拟机的启动/关闭而创建/销毁。
1、JVM内存模型:
线程独占:栈,本地方法栈,程序计数器
线程共享:堆,方法区
2、栈:(线程独占)
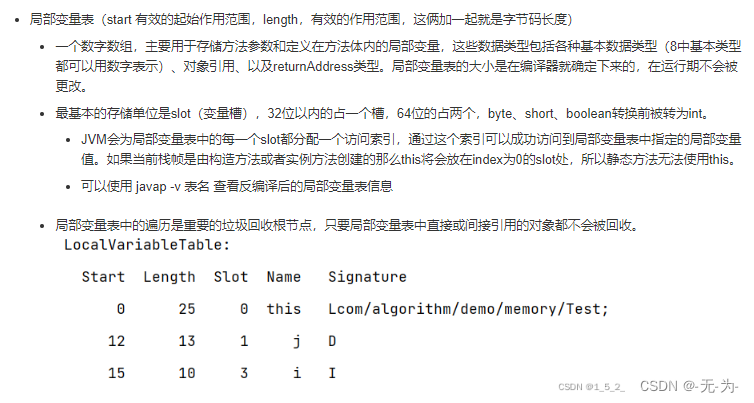
又称方法栈,线程私有的,线程执行方法是都会创建一个栈阵,用来存储局部变量表,操作栈,动态链接,方 法出口等信息.调用方法时执行入栈,方法返回式执行出栈.
3、本地方法栈(线程独占)
与栈类似,也是用来保存执行方法的信息.执行Java方法是使用栈,执行Native方法时使用本地方法栈.
4、程序计数器(线程独占)
保存着当前线程执行的字节码位置,每个线程工作时都有独立的计数器,只为执行Java方法服务,执行 Native方法时,程序计数器为空.
5、堆(线程共享)
JVM内存管理最大的一块,对被线程共享,目的是存放对象的实例,几乎所欲的对象实例都会放在这里, 当堆没有可用空间时,会抛出OOM异常.根据对象的存活周期不同,JVM把对象进行分代管理,由垃圾回 收器进行垃圾的回收管理
5、堆上的TLAB线程分配缓冲区(线程独享)
堆中的线程私有缓存区域TLAB(Thread Local Allocation Buffer)是Java虚拟机(JVM)中用于提高对象分配性能的一种优化技术。
在多线程的Java应用程序中,对象的分配通常是并发的操作。为了避免不同线程之间频繁地竞争堆内存的分配问题,JVM引入了TLAB这个概念。
TLAB是为每个线程分配的一块私有的内存区域,用于存放该线程分配的新对象。每个线程都有自己的TLAB,它们在堆中是独立的,不会被其他线程访问。这样可以减少不同线程之间因为对象分配而造成的竞争,提高了对象分配的效率。
6、方法区:(线程共享)
又称非堆区,用于存储已被虚拟机加载的类信息,常量,静态变量,即时编译器优化后的代码等数据.1.7 的永久代和1.8的元空间都是方法区的一种实现。
7、直接内存:(线程共享)
直接内存并不是 JVM 运行时数据区的一部分, 但也会被频繁的使用: 在 JDK 1.4 引入的 NIO 提供了基于 Channel 与 Buffer 的 IO 方式, 它可以使用 Native 函数库直接分配堆外内存, 然后使用
DirectByteBuffer 对象作为这块内存的引用进行操作(详见: Java I/O 扩展), 这样就避免了在 Java
堆和 Native 堆中来回复制数据, 因此在一些场景中可以显著提高性能。
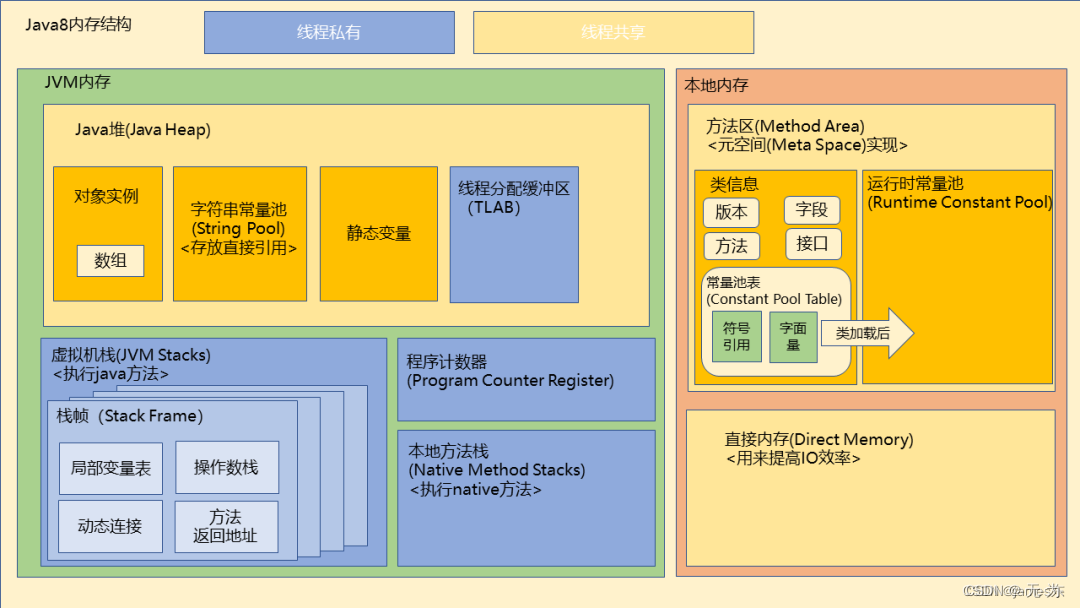
JVM内存
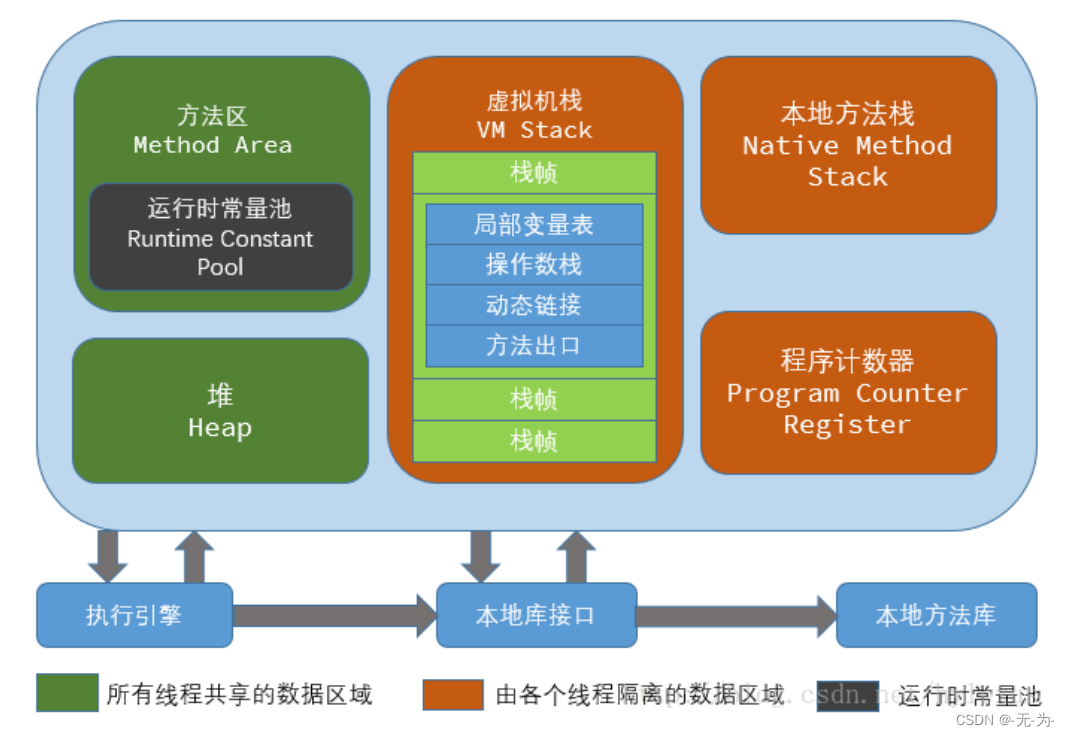
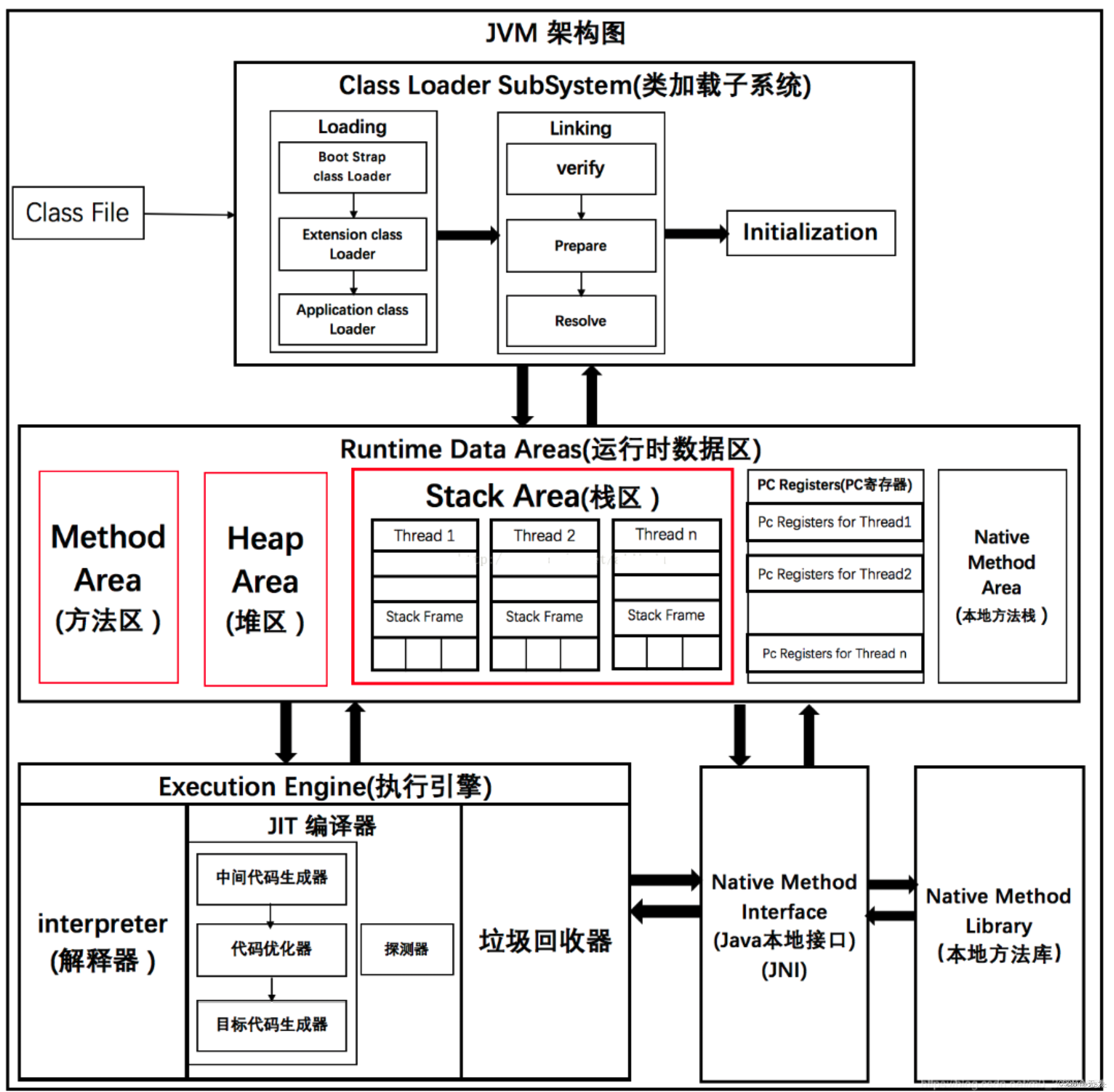
线程与jvm内存之间的关系
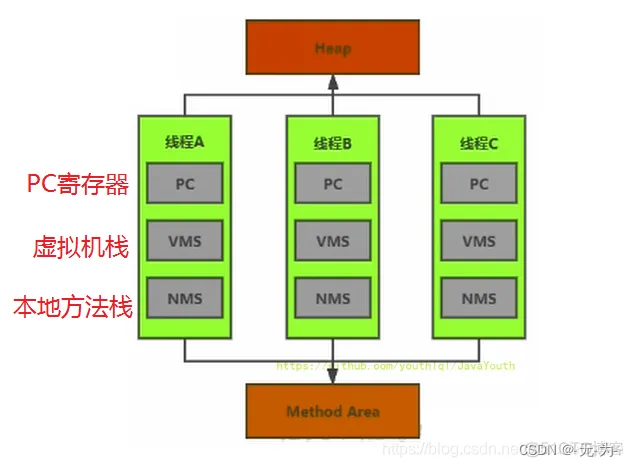
java线程操作线程独占内存、共享内存、直接内存。
关于Runtime类
每个JVM只有一个Runtime实例。即为运行时环境,相当于内存结构的中间的那个框框:运行时环境。
Hotspot JVM里面的系统线程
使用jconsole、jvisualvm或者是任何一个调试工具,都能看到在后台有许多线程在运行。
不过这些线程不包括调用public static void main(String[])的main线程以及所有这个main线程自己创建的线程。
而这些后台系统线程在Hotspot JVM主要有以下几种:
- 虚拟机线程:这种线程的操作是需要JVM达到安全点才会出现。这些操作必须在不同的线程中发生的原因是他们都需要JVM达到安全点,这样堆才不会变化。这种线程的执行类型括”stop-the-world”的垃圾收集,线程栈收集,线程挂起以及偏向锁撤销
- 周期任务线程:这种线程是时间周期事件的体现(比如中断),他们一般用于周期性操作的调度执行
- GC线程:这种线程对在JVM里不同种类的垃圾收集行为提供了支持
- 编译线程:这种线程在运行时会将字节码编译成到本地代码
- 信号调度线程:这种线程接收信号并发送给JVM,在它内部通过调用适当的方法进行处理
1、栈VM Stack(虚拟机栈):(线程独占)
又称方法栈,线程私有的,线程执行方法是都会创建一个栈阵,用来存储局部变量表,操作栈,动态链接,方 法出口等信息.调用方法时执行入栈,方法返回式执行出栈.

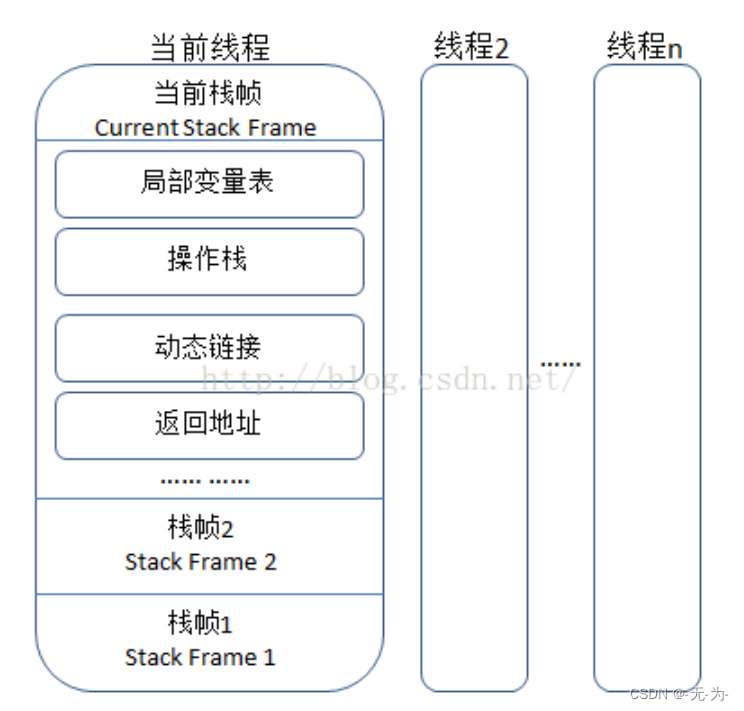
每个方法的运行都对应的入栈出栈的过程 这是一种快速有效的分配存储方式。栈中存储栈帧 每个栈帧就对应一个方法。
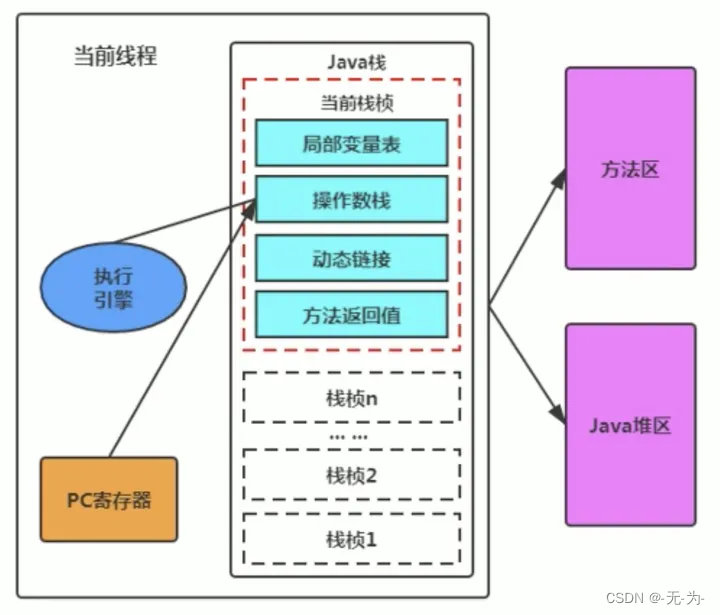
栈大小配置:-Xss参数指定线程的栈大小 默认是1MB,可以视情况而定128kb
执行引擎在执行的过程中究竟需要执行什么样子的字节码指令完全依赖于 PC 寄存器。
每当执行一项指令操作以后,PC 寄存器(即程序计数器)就会更新下一条需要被执行的指令地址。
当然方法在执行的过程中,执行引擎有可能会通过存储在局部变量表中的对象引用准确定位到存储在 Java 堆区中的对象实例信息,以及通过对象头中的元数据指针定位到目标对象的类型信息。
从外观上来看,所有的 Java 虚拟机的执行引擎输入、输出都是一致的:输入的是字节码二进制流,处理过程是字节码解释执行的等效过程,输出的是执行结果。


2、Native Method Stack本地方法栈(线程独占)
与栈类似,也是用来保存执行方法的信息.执行Java方法是使用栈,执行Native方法时使用本地方法栈。
本地方法栈(Native Method Stack)是Java虚拟机(JVM)内存模型中的一部分,用于支持Java程序中调用本地方法(Native Method)的执行过程(System.load方法, System.loadLibrary方法)。本地方法是使用其他编程语言(如C、C++等)编写的,通过JNI(Java Native Interface)技术与Java代码进行交互。本地方法栈主要用于管理本地方法的执行。
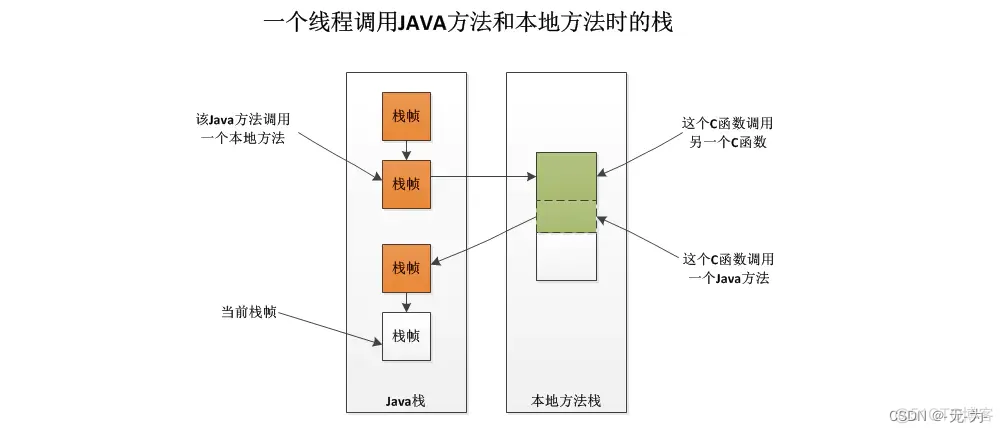
功能:
本地方法栈为每个线程提供了一个独立的内存区域,用于管理本地方法的调用和执行过程。
当Java程序调用本地方法时,本地方法栈用于保存本地方法的局部变量、参数、返回值和临时数据。
线程私有:
与Java虚拟机栈类似,本地方法栈也是线程私有的。每个线程都拥有自己独立的本地方法栈,不与其他线程共享。
在线程切换时,本地方法栈也会随着线程的切换而变化,保证线程之间的本地方法调用不会相互影响。
与Java虚拟机栈的区别:
本地方法栈与Java虚拟机栈(也称为Java栈)是两个不同的栈,分别用于管理Java方法和本地方法的调用。
Java虚拟机栈用于执行Java方法的调用和返回,而本地方法栈用于执行本地方法的调用和返回。
栈帧结构:
本地方法栈的栈帧结构与Java虚拟机栈的栈帧结构类似。每个栈帧包含了本地方法的相关信息,包括局部变量表、操作数栈、返回地址等。
栈帧中的局部变量表用于存储本地方法的局部变量和参数。
操作数栈用于执行本地方法中的操作指令。
栈帧大小:
本地方法栈的栈帧大小是固定的,由本地方法的实现语言和编译器决定。
在调用本地方法时,JVM会预先为本地方法分配一块足够大的栈帧空间,确保本地方法的执行能够正常进行。
异常处理:
与Java虚拟机栈类似,本地方法栈也可以捕获和处理异常。当本地方法抛出异常时,JVM会在本地方法栈上找到相应的异常处理器并进行处理。
常用的本地方法
Object作为所有类的父类,其所有的方法都被Java对象所共享,
这些方法包括hashcode(),equals(),clone(),toString(),
getClass(),wait(),notify(),nptifyAll()Object这些类的实现很多都调用了系统底层的本地方法,所以有必要在这里先说明一下关于本地方法的情况:
1.本地方法的概念本地方法是指用本地程序设计语言,比如:c或者c++,来编写的特殊方法。在java语言中通过native关键字来修饰,通过Java Native Interface(JNI)技术来支持java应用程序来调用本地方法,本地方法在本地语言中可以执行任意的计算任务,并返回到java程序设计语言中
2.本地方法的用途
从历史上看本地方法主要有三种用途:
1) 提供“访问特定于平台的机制”的能力,比如:访问注册表和文件锁
2) 提供访问遗留代码库的能力,从而可以访问遗留数据
3) 可以通过本地语言,编写应用程序中注重性能的部分,以提高系统的性能
3.使用本地方法的优缺点
优点:
1) 访问特定于平台的机制
2) 提高系统性能
缺点:
1) 本地代码中的一个bug就有可能破坏掉整个应用程序
2) 本地语言是不安全的,所以,使用本地方法的应用程序也不能免受内存毁坏错误的影响
3) 本地语言是与平台相关的,使用本地方法的应用程序也不再是可自由移植的
4) 使用本地方法的应用程序更难调试
5) 在进入和退出本地代码时,需要相关的固定开销,所以,如果本地代码时做的少量的工作,本地方法就可能降低性能
6) 需要“胶合代码”的本地方法编写起来单调乏味,并且难以阅读如何优化本地方法栈?
优化本地方法栈可以提高程序的性能和稳定性。以下是一些优化建议:
- 尽量减少native方法的调用:过多的native方法调用会导致本地方法栈的频繁创建和销毁,从而增加程序的开销。因此,尽量减少不必要的native方法调用可以提高程序的性能。
- 合理设置本地方法栈的大小:如果本地方法栈的大小设置得太小,可能会导致StackOverflowError异常;如果设置得太大,则会浪费内存资源。因此,需要根据程序的实际情况合理设置本地方法栈的大小。
- 使用JIT编译器优化native方法:JIT编译器可以将热点代码编译成本地代码,从而提高程序的执行效率。对于频繁调用的native方法,可以使用JIT编译器进行优化。
- 避免在native方法中使用复杂的算法和数据结构:复杂的算法和数据结构可能导致本地方法栈的快速增长和收缩,从而影响程序的性能和稳定性。因此,在编写native方法时,应尽量使用简单、高效的算法和数据结构。
- 确保native方法的正确性:由于native方法是使用非Java语言编写的,因此需要特别注意其正确性和稳定性。在编写和测试native方法时,应确保其功能正确、性能良好且稳定可靠。
总结:本地方法栈是JVM中用于支持native方法执行的重要组件。通过深入理解本地方法栈的作用、结构、工作原理以及与Java堆栈的区别,我们可以更好地理解JVM的工作机制,并为编写高效、稳定的程序提供重要支持。
3、程序计数器Program Counter Register(线程独占)
程序计数寄存器(Program Counter Register)中,Register的命名源于CPU的寄存器,寄存器存储指令相关的现场信息。CPU只有把数据装载到寄存器才能够运行。
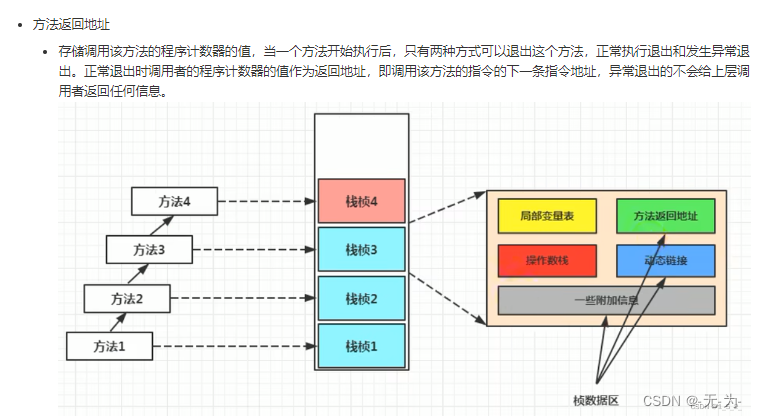
程序计数器用来存储指向下一条指令的地址,也即将要执行的指令代码。由执行引擎读取下一条指令,并执行该指令。
保存着当前线程执行的字节码位置,每个线程工作时都有独立的计数器,只为执行Java方法服务,执行 Native方法时,程序计数器为空.
- 它是一块很小的内存空间,几乎可以忽略不记。也是运行速度最快的存储区域。
- 在JVM规范中,每个线程都有它自己的程序计数器,是线程私有的,生命周期与线程的生命周期保持一致。
- 任何时间一个线程都只有一个方法在执行,也就是所谓的当前方法。
- 程序计数器会存储当前线程正在执行的Java方法的JVM指令地址;或者如果是在执行native(本地方法栈)方法,则是未指定值(undefined)。
- 它是程序控制流的指示器,分支、循环、跳转、异常处理、线程恢复等基础功能都需要依赖这个计数器来完成。
- 字节码解释器工作时就是通过改变这个计数器的值来选取下一条需要执行的字节码指令。
- 它是唯一一个在Java虚拟机规范中没有规定任何OutofMemoryError情况的区域。
使用程序计数器存储字节码指令地址有什么用?
因为CPU运行时需要在各个线程间切换,切换回来后就得知道需要从哪开始接着执行。JVM的字节码解释器就需要通过改变程序计数器的值来明确下一条应该执行什么样的字节码指令。JVM中的PC寄存器是对物理PC寄存器的一种抽象模拟。
举例体会PC寄存器
public class PCRegisterTest {public static void main(String[] args) {int i = 10;int j = 20;int k = i + j;String s = "abc";System.out.println(i);System.out.println(k);}
}先通过字节码来看看信息
public static void main(java.lang.String[]);descriptor: ([Ljava/lang/String;)Vflags: ACC_PUBLIC, ACC_STATICCode:stack=2, locals=5, args_size=10: bipush 102: istore_13: bipush 205: istore_26: iload_17: iload_28: iadd9: istore_310: ldc #2 // String abc12: astore 414: getstatic #3 // Field java/lang/System.out:Ljava/io/PrintStream;17: iload_118: invokevirtual #4 // Method java/io/PrintStream.println:(I)V21: getstatic #3 // Field java/lang/System.out:Ljava/io/PrintStream;24: iload_325: invokevirtual #4 // Method java/io/PrintStream.println:(I)V28: returnLineNumberTable:line 10: 0line 11: 3line 12: 6line 14: 10line 15: 14line 16: 21line 18: 28LocalVariableTable:Start Length Slot Name Signature0 29 0 args [Ljava/lang/String;3 26 1 i I6 23 2 j I10 19 3 k I14 15 4 s Ljava/lang/String;
左边的数字代表指令地址(指令偏移),即 PC 寄存器中可能存储的值,然后执行引擎读取 PC 寄存器中的值,并执行该指令。
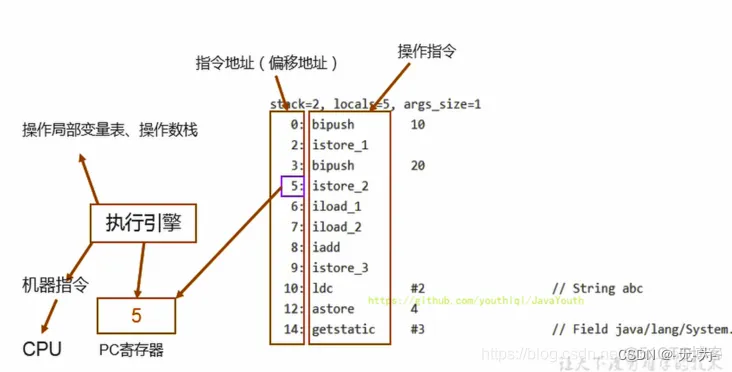
比如说PC寄存器存放指令地址:5,而执行引擎会看到PC寄存器存放的是5,那么会去对应的操作指令:instore_2,将它放到操作局部变量表、操作数栈保存,并且讲字节码指令翻译成机器指令让CPU执行。
常见面试题
================================使用PC寄存器存储字节码指令地址有什么用呢?
为什么使用 PC 寄存器来记录当前线程的执行地址呢?
因为CPU需要不停的切换各个线程,这时候切换回来以后,就得知道接着从哪开始继续执行JVM的字节码解释器就需要通过改变PC寄存器的值来明确下一条应该执行什么样的字节码指令PC寄存器为什么被设定为私有的?
因为我们知道所谓的多线程是在一个特定的时间段内只会执行其中某一个线程的方法而CPU会不停地做任务切换,这样必然导致经常中断或恢复,如何保证分毫无差呢?最好的办法自然是为每一个线程都分配一个PC寄存器,准确地记录各个线程正在执行的当前字节码指令地址。这样一来各个线程之间便可以进行独立计算,从而不会出现相互干扰的情况。CPU 时间片
================================
CPU时间片即CPU分配给各个程序的时间,每个线程被分配一个时间段,称作它的时间片在宏观上:我们可以同时打开多个应用程序,每个程序并行不悖,同时运行但在微观上:由于只有一个CPU,一次只能处理程序要求的一部分,如何处理公平,一种方法就是引入时间片,每个程序轮流执行并发和并行的区别
================================
这里我们讲解一下并发与并行的区别并行(Parallel):当系统有一个以上CPU时,当一个CPU执行一个进程时,另一个CPU可以执行另一个进程,两个进程互不抢占CPU资源,可以同时进行,这种方式我们称之为并行并发(Concurrent):在操作系统中,是指一个时间段中有几个程序都处于已启动运行到运行完毕之间,且这几个程序都是在同一个处理机上运行用网吧的机子来说我们有十台电脑,晚上可以让十个人同时上机,这叫并行同时进行,互不争抢假如我们只有一台电脑但是有五个人来上机,可能就是每个人玩一段时间或者干脆等待别人下机再到你4、堆Heap(线程共享)
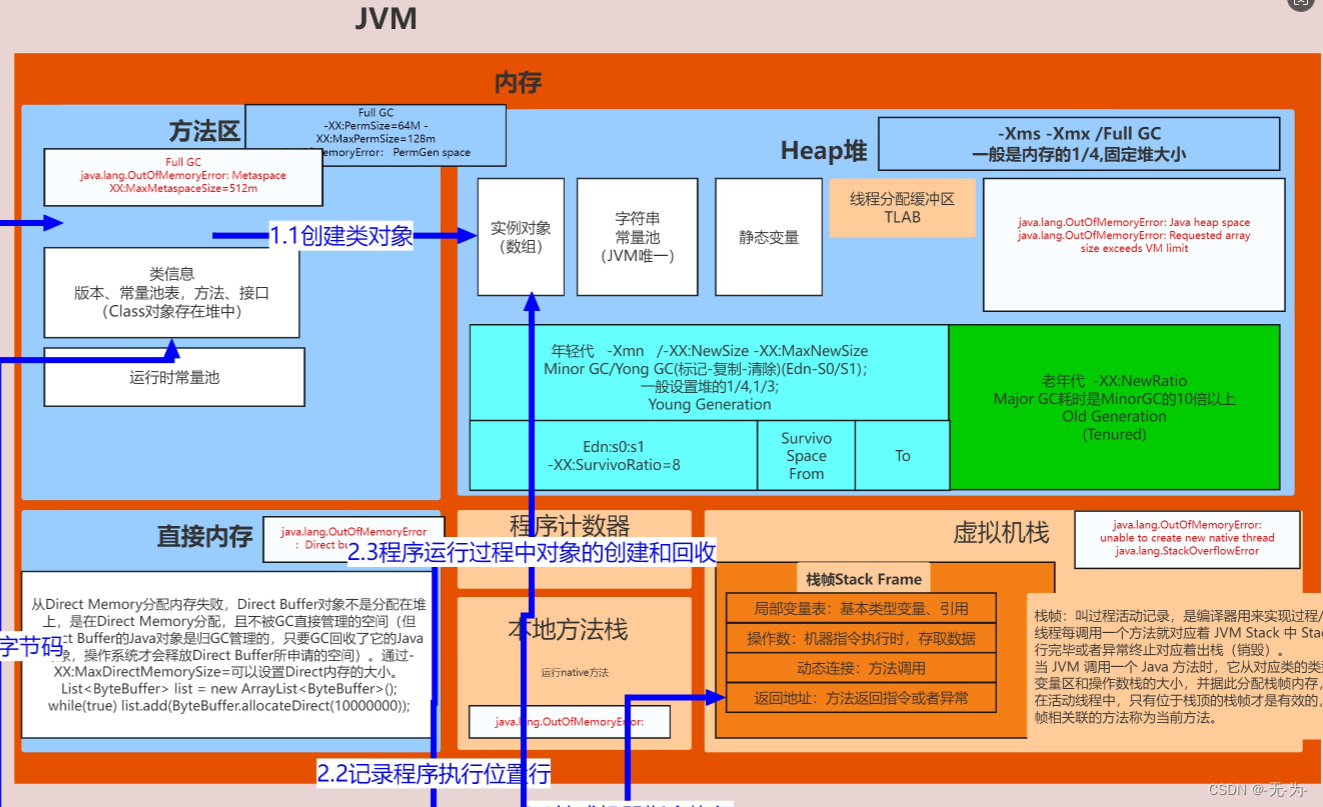
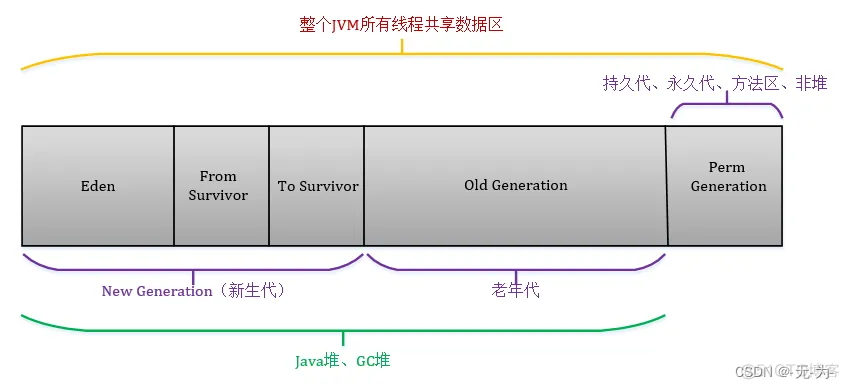
JVM内存管理最大的一块,对被线程共享,目的是存放对象的实例,几乎所欲的对象实例都会放在这里, 当堆没有可用空间时,会抛出OOM异常.根据对象的存活周期不同,JVM把对象进行分代管理,由垃圾回 收器进行垃圾的回收管理.。
堆内存参数配置
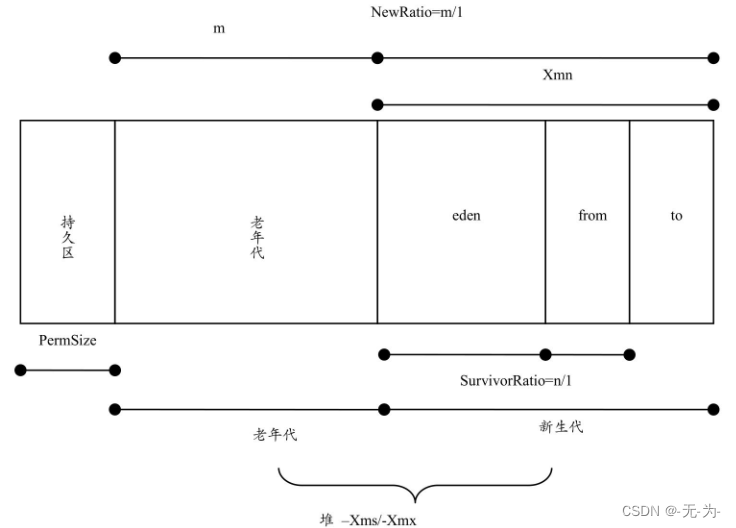
1.1 堆的配置参数
-Xms -Xmx 设置初始堆和最大堆内存
-Xmn 设置新生代内存大小
-XX:NewRatio 。可以设置老年代与新生代的比例。设置一个较大的新生代会减小老年代的大小,这个参数对系统性能及GC行为有很大的影响。新生代的大小一般设置为整个堆空间的1/3到1/4。默认值为设置老年代和新生代内存占比,默认值为2:1。默认-XX:NewRatio=2新生代占1,老年代占2,年轻代占整个堆的1/3
假如
-XX:NewRatio=4新生代占1,老年代占4,年轻代占整个堆的1/5 NewRatio值就是设置老年代的占比,剩下的1给新生代-XX:SurvivorRatio用来设置新生代中eden区和from/to区的比例,
JVM参数中有一个比较重要的参数SurvivorRatio,它定义了新生代中Eden区域和Survivor区域(From幸存区或To幸存区)的比例,默认值为8:1:1(Eden:From:To),也就是说Eden占新生代的8/10,From幸存区和To幸存区各占新生代的1/10-XX:SurvivorRatio
可参考以下计算公式:Eden = (R*Y)/(R+1+1)
From = Y/(R+1+1)
To = Y/(R+1+1)
1
2
3
其中:
R:SurvivorRatio比例
Y:新生代空间大小这里举个例子,如果我们通过设置-Xmn60M来指定新生代分配的空间大小,那么Eden则会分配60M * 0.8 = 48M,Survivor一共分配60M * 0.2 = 12M的内存空间
启动参数配置-Xmn60M
-XX:SurvivorRatio=8
-XX:+PrintFlagsFinal
1
2
3
控制台输出uintx NewSize := 62914560 {product}
uintx MaxNewSize := 62914560 {product}
————————————————-XX:MaxTenuringThreshold,从年轻代到老年代,最大晋升年龄。CMS 下默认为 6,G1 下默认为 15-XX:MaxDirectMemorySize,用于设置直接内存的最大值,限制通过 DirectByteBuffer 申请的内存
-XX:ReservedCodeCacheSize,用于设置 JIT 编译后的代码存放区大小,如果观察到这个值有限制,可以适当调大,一般够用即可1.2 堆OOM 导出堆的参数配置
参数-XX: +HeapDumpOnOutOfMemoryError 配置堆异常时导出
-XX:HeapDumpPath=./dumplog/dumplog.log 配置都出 堆 dump文件的路径nohup java -Xms768m -Xmx768m -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=./dumplog/dumplog.log -jar xxxxxx.jar > logs/xxxxxx.log 2>&1 &堆上存储的数据:字符串常量池、静态变量、java对象。

堆上内存分配

逃逸分析

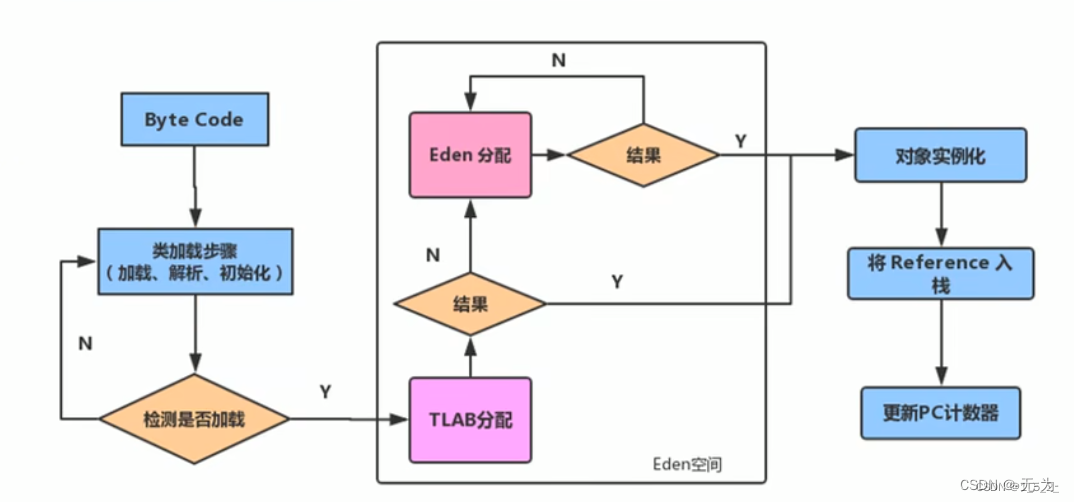
5、堆上的TLAB线程分配缓冲区(线程独享)
堆中的线程私有缓存区域TLAB(Thread Local Allocation Buffer)是Java虚拟机(JVM)中用于提高对象分配性能的一种优化技术。
在多线程的Java应用程序中,对象的分配通常是并发的操作。为了避免不同线程之间频繁地竞争堆内存的分配问题,JVM引入了TLAB这个概念。
TLAB是为每个线程分配的一块私有的内存区域,用于存放该线程分配的新对象。每个线程都有自己的TLAB,它们在堆中是独立的,不会被其他线程访问。这样可以减少不同线程之间因为对象分配而造成的竞争,提高了对象分配的效率。
6、方法区:(线程共享)
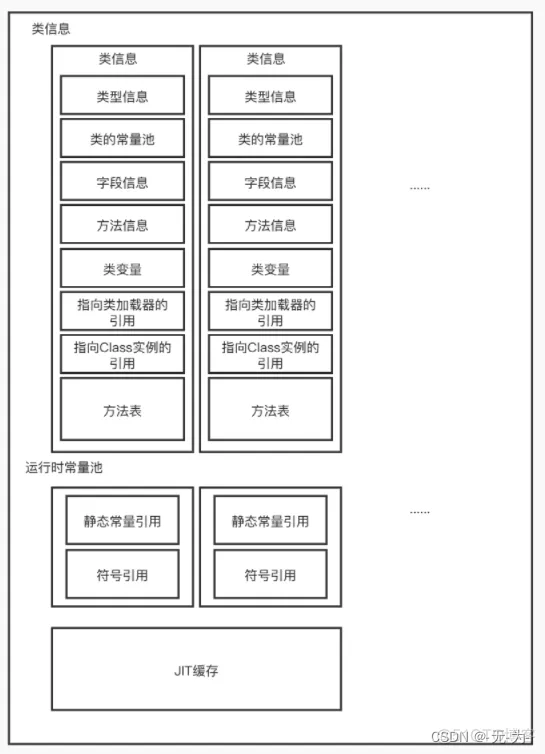
又称非堆区,用于存储已被虚拟机加载的类信息,常量,静态变量,即时编译器优化后的代码等数据.1.7 的永久代和1.8的元空间都是方法区的一种实现。
方法区参数配置
在JDK 1.6、JDK 1.7中,方法区可以理解为永久区(Perm)。在JDK 1.8、JDK1.9、JDK1.10中,永久区已经被彻底移除。取而代之的是元数据区,元数据区大小可以使用参数-XX:MaxMetaspaceSize指定(一个大的元数据区可以使系统支持更多的类),这是一块堆外的直接内存Perm区域的参数配置由-XX:MaxMetaspaceSize 替换-XX:MaxMetaspaceSize指定永久区的最大可用值
在JDK1.6和JDK1.7等版本中,可以使用-XX:PermSize和-XX:MaxPermSize配置永久区大小-XX:MetaspaceSize 参数的理解那么-XX:MetaspaceSize=256m的含义到底是什么呢?其实,这个JVM参数是指Metaspace扩容时触发FullGC的初始化阈值,也是最小的阈值。这里有几个要点需要明确:如果没有配置-XX:MetaspaceSize,那么触发FGC的阈值是21807104(约20.8m),可以通过jinfo -flag MetaspaceSize pid得到这个值;如果配置了-XX:MetaspaceSize,那么触发FGC的阈值就是配置的值;
Metaspace由于使用不断扩容到-XX:MetaspaceSize参数指定的量,就会发生FGC;且之后每次Metaspace扩容都可能会发生FGC(至于什么时候会,比较复杂,跟几个参数有关);
如果Old区配置CMS垃圾回收,那么扩容引起的FGC也会使用CMS算法进行回收;如果MaxMetaspaceSize设置太小,可能会导致频繁FullGC,甚至OOM;任何一个JVM参数的默认值可以通过java -XX:+PrintFlagsFinal -version |grep JVMParamName获取,例如:java -XX:+PrintFlagsFinal -version |grep MetaspaceSize
————————————————
Metaspace使用的是本地内存,而不是堆内存,也就是说在默认情况下Metaspace的大小只与本地内存大小有关。当然你也可以通过以下的几个参数对Metaspace进行控制:-XX:MetaspaceSize=N
这个参数是初始化的Metaspace大小,该值越大触发Metaspace GC的时机就越晚。随着GC的到来,虚拟机会根据实际情况调控Metaspace的大小,可能增加上线也可能降低。在默认情况下,这个值大小根据不同的平台在12M到20M浮动。使用java -XX:+PrintFlagsInitial命令查看本机的初始化参数,-XX:Metaspacesize为21810376B(大约20.8M)。-XX:MaxMetaspaceSize=N
这个参数用于限制Metaspace增长的上限,防止因为某些情况导致Metaspace无限的使用本地内存,影响到其他程序。在本机上该参数的默认值为4294967295B(大约4096MB)。-XX:MinMetaspaceFreeRatio=N
当进行过Metaspace GC之后,会计算当前Metaspace的空闲空间比,如果空闲比小于这个参数,那么虚拟机将增长Metaspace的大小。在本机该参数的默认值为40,也就是40%。设置该参数可以控制Metaspace的增长的速度,太小的值会导致Metaspace增长的缓慢,Metaspace的使用逐渐趋于饱和,可能会影响之后类的加载。而太大的值会导致Metaspace增长的过快,浪费内存。-XX:MaxMetasaceFreeRatio=N
当进行过Metaspace GC之后, 会计算当前Metaspace的空闲空间比,如果空闲比大于这个参数,那么虚拟机会释放Metaspace的部分空间。在本机该参数的默认值为70,也就是70%。-XX:MaxMetaspaceExpansion=N
Metaspace增长时的最大幅度。在本机上该参数的默认值为5452592B(大约为5MB)。-XX:MinMetaspaceExpansion=N
Metaspace增长时的最小幅度。在本机上该参数的默认值为340784B(大约330KB为)。以前只认为,Metaspace区是保存在本地内存中,是没有上限的,经查阅资料才发现,原来JDK8中,XX:MaxMetaspaceSize确实是没有上限的,最大容量与机器的内存有关;但是XX:MetaspaceSize是有一个默认值的:21M-XX:CompressedClassSpaceSize 设置方法区类信息加载空间的大小,因为 CompressedClassSpaceSize的大小是由:MaxMetaspaceSize,InitialBootClassLoaderMetaspaceSize,CompressedClassSpaceSize这三个参数共同影响的结果。具体就是:min_metaspace_sz 加CompressedClassSpaceSize大于 MaxMetaspaceSize的时候,CompressedClassSpaceSize就强制被设置为(MaxMetaspaceSize - min_metaspace_sz)。64位下默认4M,32位下默认2200K-XX:InitialBootClassLoaderMetaspaceSize 设置类信息区,引导类的元空间大小查看类加载与卸载时候的信息
我增加了如下两个JVM启动参数来观察类的加载、卸载信息:-XX:TraceClassLoading -XX:TraceClassUnloading
1
nohup java -Xms1g -Xmx1g -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=./dumplog/dumplog.log -Xloggc:./dumplog/gc.log -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=1500m -XX:MaxMetaspaceExpansion=50M -XX:MinMetaspaceExpansion=10M -XX:CompressedClassSpaceSize=1200m -XX:+TraceClassUnloading -XX:+TraceClassLoading -jar xxxx.jar > logs/xxx.log 2>&1 &7、直接内存:(线程共享)
直接内存并不是 JVM 运行时数据区的一部分, 但也会被频繁的使用: 在 JDK 1.4 引入的 NIO 提供了基于 Channel 与 Buffer 的 IO 方式, 它可以使用 Native 函数库直接分配堆外内存, 然后使用
DirectByteBuffer 对象作为这块内存的引用进行操作(详见: Java I/O 扩展), 这样就避免了在 Java
堆和 Native 堆中来回复制数据, 因此在一些场景中可以显著提高性能。
-XX:MaxDirectMemorySize,用于设置直接内存的最大值,限制通过 DirectByteBuffer 申请的内存
-XX:ReservedCodeCacheSize,用于设置 JIT 编译后的代码存放区大小,如果观察到这个值有限制,可以适当调大,一般够用即可
相关文章:
科普文:一文搞懂jvm原理(四)运行时数据区
概叙 科普文:一文搞懂jvm(一)jvm概叙-CSDN博客 科普文:一文搞懂jvm原理(二)类加载器-CSDN博客 科普文:一文搞懂jvm原理(三)执行引擎-CSDN博客 前面我们介绍了jvm,jvm主要包括两个子系统和两个组件: Class loader(类…...
《昇思25天学习打卡营第5天|数据变换 Transforms》
文章目录 前言:今日所学:1. Common Transforms2. Vision Transforms3. Text Transforms 前言: 我们知道在进行神经网络训练的时候,通常要将原始数据进行一系列的数据预处理操作才会进行训练,所以MindSpore提供了不同类…...

详细分析Oracle修改默认的时间格式(四种方式)
目录 前言1. 会话级别2. 系统级别3. 环境配置4. 函数格式化5. 总结 前言 默认的日期和时间格式由参数NLS_DATE_FORMAT控制 如果需要修改默认的时间格式,可以通过修改会话级别或系统级别的参数来实现 1. 会话级别 在当前会话中设置日期格式,这只会影响…...

以 Vue 3 项目为例,你是否经常遇到 import 语句顺序混乱的问题?要想解决它其实很容易!
大家好,我是CodeQi! 在项目开发过程中,我们经常会遇到项目中的 import 语句顺序混乱的问题。 这不仅会影响代码的可读性,还可能使我们代码在提交的时候产生不必要的冲突。 面对这种情况,要想解决它其实很容易。 通过合理的规范和自动化工具,我们可以确保 import 语句…...

mysql数据库ibdata文件被误删后恢复数据的方法
使用mysql数据库的时候不小心误删除了ibdata和ib_logfile文件,但是幸好.ibd文件还在。这种情况下其实数据还在并未丢失,丢失的是表结构。查询表数据时会报错:ERROR 1146 (42S02): Table ‘testdb.test’ doesn’t exist,其实是说表…...
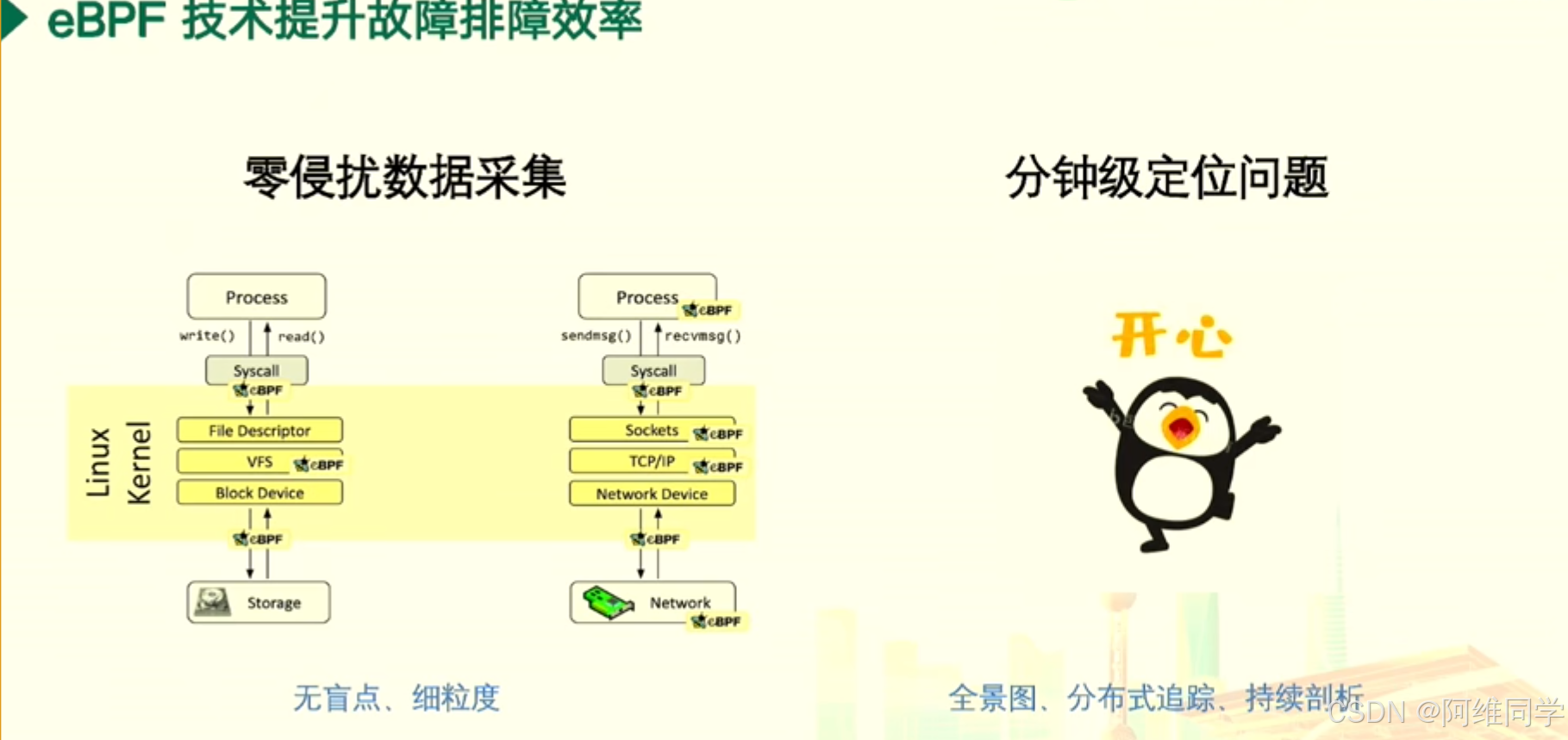
eBPF技术揭秘:DeepFlow如何引领故障排查,提升运维效率
DeepFlow 实战:eBPF 技术如何提升故障排查效率 目录 DeepFlow 实战:eBPF 技术如何提升故障排查效率 微服务架构系统中各个服务、组件及其相互关系的全景 零侵扰分布式追踪(Distributed Tracing)的架构和工作流程 关于零侵扰持…...

C++视觉开发 三.缺陷检测
一.距离变换 1.概念和功能 距离变换是一种图像处理技术,用于计算图像中每个像素到最近的零像素(背景像素)的距离。它常用于图像分割、形态学操作和形状分析等领域。它计算图像中每个像素到最近的零像素(背景像素)的距…...

使用 Amazon Bedrock Converse API 简化大语言模型交互
本文将介绍如何使用 Amazon Bedrock 最新推出的 Converse API,来简化与各种大型语言模型的交互。该 API 提供了一致的接口,可以无缝调用各种大型模型,从而消除了需要自己编写复杂辅助功能函数的重复性工作。文中示例将展示它相比于以前针对每…...
)
第二十一章 函数(Python)
文章目录 前言一、定义函数二、函数参数三、参数类型四、函数返回值五、函数类型1、无参数,无返回值2、无参数,有返回值3、有参数,无返回值4、有参数,有返回值 六、函数的嵌套七、全局变量和局部变量1、局部变量2、全局变量 前言 …...
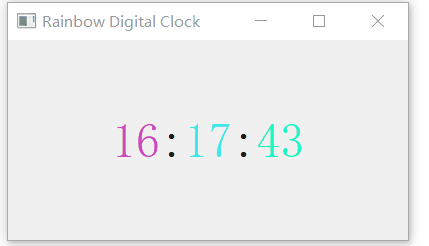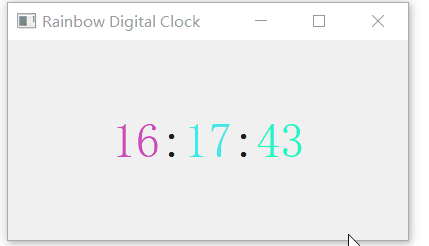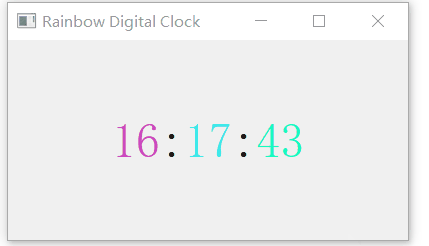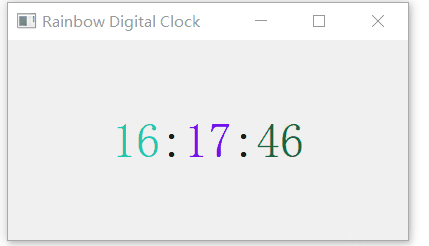
使用pyqt5编写一个七彩时钟
使用pyqt5编写一个七彩时钟 效果代码解析定义 RainbowClockWindow 类初始化用户界面显示时间方法 完整代码 在这篇博客中,我们将使用 PyQt5 创建一个简单的七彩数字时钟。 效果 代码解析 定义 RainbowClockWindow 类 class RainbowClockWindow(QMainWindow):def _…...

【Linux】:命令行参数
朋友们、伙计们,我们又见面了,本期来给大家解读一下有关Linux命令行参数的相关知识点,如果看完之后对你有一定的启发,那么请留下你的三连,祝大家心想事成! C 语 言 专 栏:C语言:从入…...
高考假期预习指南,送给迷茫的你
高考结束,离别了熟悉的地方,踏上远方。 你,,迷茫吗? 大学是什么?到了大学我该怎样学习?真像网上说的毕业即失业吗? 大学是一个让你学会一技之长的地方,到了大学找到自…...

独孤思维:负债了,还可以翻身吗
01 其实独孤早年也负债。 负债并不可怕。 可怕的是因为负债而催生的想要快速赚钱的心态。 越是有这种心态,越是不可能赚到钱。 相反,可能会让你陷入恶性循环中。 盲目付费,盲目寄希望于某个项目或者某个人。 当成唯一的救命稻草。 这…...
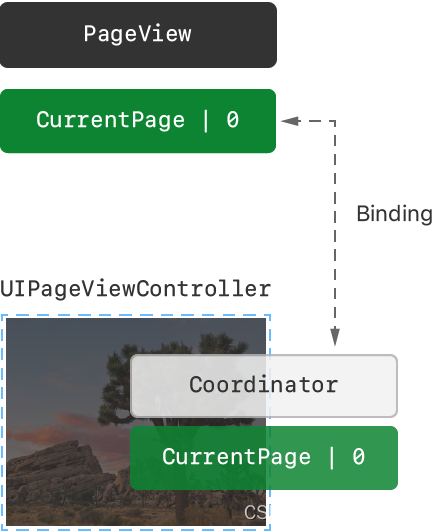
SwiftUI八与UIKIT交互
代码下载 SwiftUI可以在苹果全平台上无缝兼容现有的UI框架。例如,可以在SwiftUI视图中嵌入UIKit视图或UIKit视图控制器,反过来在UIKit视图或UIKit视图控制器中也可以嵌入SwiftUI视图。 本文展示如何把landmark应用的主页混合使用UIPageViewController和…...
RedHat9 | 内部YUM本地源服务器搭建
服务器参数 标识公司内部YUM服务器主机名yum-server网络信息192.168.37.1/24网络属性静态地址主要操作用户root 一、基础环境信息配置 修改主机名 [rootyum-server ~]# hostnamectl hostname yum-server添加网络信息 [rootyum-server ~]# nmcli connection modify ens160 …...
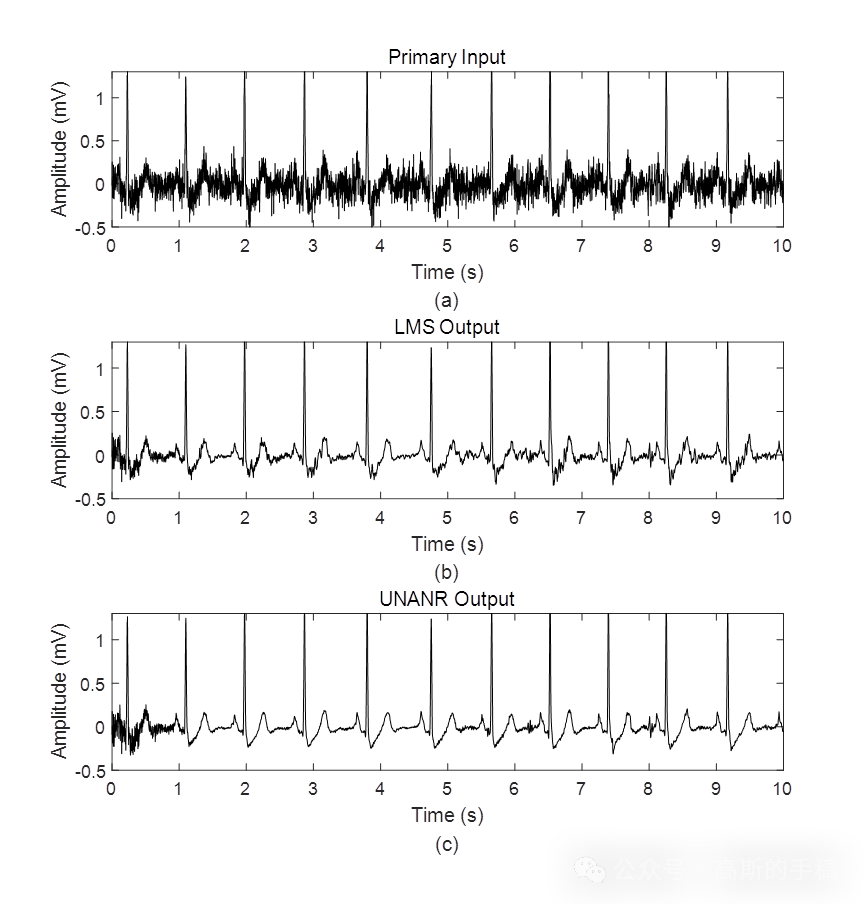
无偏归一化自适应心电ECG信号降噪方法(MATLAB)
心电信号作为一种生物信号,含有大量的临床应用价值的信息,在现代生命医学研究中占有重要的地位。但心电信号低频、低幅值的特点,使其在采集和传输的过程中经常受到噪声的干扰,使心电波形严重失真,从而影响后续的病情分…...

AI基本概念(人工智能、机器学习、深度学习)
人工智能 、 机器学习、 深度学习的概念和关系 人工智能 (Artificial Intelligence)AI- 机器展现出人类智慧机器学习 (Machine Learning) ML, 达到人工智能的方法深度学习 (Deep Learning)DL,执行机器学习的技术 从范围…...
LabVIEW幅频特性测试系统
使用LabVIEW软件开发的幅频特性测试系统。该系统整合了Agilent 83732B信号源与Agilent 8563EC频谱仪,通过LabVIEW编程实现自动控制和数据处理,提供了成本效益高、操作简便的解决方案,有效替代了昂贵的专用仪器,提高了测试效率和设…...

校园卡手机卡怎么注销?
校园手机卡的注销流程可以根据不同的运营商和具体情况有所不同,但一般来说,以下是注销校园手机卡的几种常见方式,我将以分点的方式详细解释: 一、线上注销(通过手机APP或官方网站) 下载并打开对应运营商的…...

logback自定义规则脱敏
自定义规则conversionRule public class LogabckMessageConverter extends MessageConverter {Overridepublic String convert(ILoggingEvent event) {String msg event.getMessage();if ("INFO".equals(event.getLevel().toString())) {msg .....脱敏实现}return …...

别再死记硬背了!我用700多页图解八股文,帮你把Java面试考点画成故事
用视觉叙事重构Java面试:700页图解背后的认知科学实践 翻开任何一本Java面试指南,你大概率会看到密密麻麻的文字罗列——"JVM内存结构分为哪几部分?""Synchronized和ReentrantLock有什么区别?"这些被称为&quo…...

使用 Taotoken 后 API 调用延迟与稳定性体验分享
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用 Taotoken 后 API 调用延迟与稳定性体验分享 作为一名日常需要频繁调用大模型 API 的开发者,服务的稳定性和响应速…...
)
别再怕Windows桌面软件测试了!用Python+UIAutomation手把手搭建自动化框架(附完整源码)
从零构建Windows GUI自动化测试框架:Python与UIAutomation实战指南 Windows桌面应用的自动化测试常被视为测试领域的"硬骨头",但当你拆解其核心逻辑后,会发现它与你熟悉的Web自动化测试有着惊人的相似架构。本文将彻底打破技术恐惧…...

档案数字化最后一公里难题,已被NotebookLM破解:3类高危误判场景及防御模型
更多请点击: https://intelliparadigm.com 第一章:档案数字化最后一公里难题,已被NotebookLM破解:3类高危误判场景及防御模型 档案数字化进程在OCR识别与元数据标引环节已趋成熟,但“最后一公里”——即非结构化文本语…...
:滤波)
彩色血流成像(三):滤波
文章目录1回波信号1.1 杂波信号1.2血流信号1.3噪声信号1.4回波信号模拟方法2滤波目的3滤波限制4滤波算法5高通数字滤波器5.1单一回波抵消器5.2FIR滤波器5.3IIR滤波器 无限冲激响应滤波器定义:实现缺点:5.4回归滤波器5.5优化6参数化方法7非参数化方法7.1特…...

为什么你的“Château Margaux”印相总像海报?——深度拆解顶级酒庄视觉DNA:橡木桶纹理采样率、标签压纹深度与AI光影映射函数
更多请点击: https://intelliparadigm.com 第一章:为什么你的“Chteau Margaux”印相总像海报?——视觉失真现象的本体论诊断 高保真图像输出失败,常被归咎于打印机或纸张——但真正症结往往潜伏在色彩管理的底层逻辑中。当一张承…...
)
告别手动!用Windows批处理脚本批量搞定MKVToolNix音轨修改(附完整代码)
告别手动!用Windows批处理脚本批量搞定MKVToolNix音轨修改(附完整代码) 每次下载完一整季剧集或动漫,最头疼的就是音轨标签乱七八糟——日语、英语、中文混在一起,默认音轨设置也不对。手动在MKVToolNix里一集集调整&a…...

从Arduino AVR到ARM开发板迁移:选型、代码移植与无线通信实战指南
1. 开发板选型:从AVR到ARM的跨越与抉择当你第一次打开Arduino IDE,面对Boards Manager里琳琅满目的选项,是不是有点懵?从经典的Uno R3到各种带“Feather”、“M0”、“M4”后缀的板子,选错了可不是简单的“编译不通过”…...

从零构建轻量级爬虫框架:模块化设计与异步实现详解
1. 项目概述:从零构建一个轻量级数据爬取框架最近在做一个需要从多个公开数据源定期抓取结构化信息的小项目,一开始图省事,直接上requests加BeautifulSoup写脚本。但随着数据源增加到五六个,每个源的页面结构、反爬策略、数据清洗…...

悬而未决:Nacos 与 Apollo 能否终结“改配置就要重启”的诅咒?
写在前面“你把 log-level 从 INFO 改成 DEBUG 了?行,我记一下。等下次发布的时候一起上线。”这句话,是不是很熟悉?在一个超过 5 年的大型微服务项目中,我见过太多这样的场景:开发团队在线上环境排查问题时…...