【PYG】处理Cora数据集分类任务使用的几个函数log_softmax,nll_loss和argmax
文章目录
- log_softmax
- 解释
- 作用
- 示例
- 解释输出
- nll_loss
- 解释
- 具体操作
- 示例代码
- 解释
- nll_loss+log_softmax=cross_entropy
- 解释
- 代码示例
- 解释
- argmax()
- 解释
- 作用
- 示例代码
- 解释
- 示例输出
log_softmax
F.log_softmax(x, dim=1) 是 PyTorch 中的一个函数,用于对输入张量 x 应用 log-softmax 操作。
解释
-
F.log_softmax:这是 PyTorch 中的一个函数,位于torch.nn.functional模块中。它首先对输入进行 softmax 操作,然后取对数。softmax 操作将输入的原始分数转换为概率分布,而取对数可以使后续的计算更稳定且数值范围更适合计算。 -
x:这是输入张量。通常在神经网络中,它是来自最后一层的输出。 -
dim=1:这是指定 softmax 操作应用的维度。对于二维张量(例如批处理的数据),dim=1通常表示在每个样本的类别维度上应用 softmax 操作。
作用
log-softmax 操作的主要作用是在多分类问题中计算模型的输出概率分布,并且在使用负对数似然损失(negative log-likelihood loss,通常用于分类任务)时特别有用。通过先应用 log-softmax,再与目标标签计算负对数似然损失,可以确保计算的数值稳定性。
示例
假设你有一个二维张量 x,表示模型的未归一化输出(logits),其形状为 [batch_size, num_classes]。以下是如何使用 F.log_softmax 的示例:
import torch
import torch.nn.functional as F# 模拟模型输出的logits
logits = torch.tensor([[2.0, 1.0, 0.1],[1.0, 3.0, 0.2]])# 应用log-softmax
log_probs = F.log_softmax(logits, dim=1)print(log_probs)
输出可能类似于:
tensor([[-0.4076, -1.4076, -2.3076],[-2.1269, -0.1269, -3.1269]])
解释输出
- 对于第一个样本
logits = [2.0, 1.0, 0.1],应用 log-softmax 后的输出为[-0.4076, -1.4076, -2.3076]。这些值是输入经过 softmax 转换为概率后取对数的结果。 - 对于第二个样本
logits = [1.0, 3.0, 0.2],应用 log-softmax 后的输出为[-2.1269, -0.1269, -3.1269]。
log-softmax 的输出可以直接用于计算损失函数,例如交叉熵损失,这在分类任务中特别有用。
nll_loss
F.nll_loss(out[data.train_mask], data.y[data.train_mask]) 是 PyTorch 中用于计算负对数似然损失(Negative Log-Likelihood Loss, NLLLoss)的一种常见用法,通常用于多分类任务。以下是这个函数的详细解释:
解释
-
F.nll_loss:这是 PyTorch 中的一个函数,用于计算负对数似然损失。它通常与F.log_softmax结合使用,因为F.nll_loss期望输入是对数概率(log-probabilities)。 -
out:这是模型的输出,即经过F.log_softmax处理后的对数概率张量。形状通常为[num_nodes, num_classes]。 -
data.train_mask:这是一个布尔张量,用于指示哪些节点属于训练集。其形状为[num_nodes],值为True的位置表示对应的节点在训练集中。 -
data.y:这是节点的标签张量,形状为[num_nodes]。每个元素表示一个节点的类别标签。
具体操作
-
掩码选择:使用
data.train_mask选择训练集中的节点。out[data.train_mask]:选择模型输出中属于训练集的节点。data.y[data.train_mask]:选择标签中属于训练集的节点。
-
计算损失:
F.nll_loss接收两个参数:input:对数概率张量,形状为[batch_size, num_classes]。target:目标标签张量,形状为[batch_size]。
-
返回值:返回一个标量,表示训练集上的平均负对数似然损失。
示例代码
假设我们有一个简单的GNN模型,以下是如何使用 F.nll_loss 计算损失的示例代码:
import torch
import torch.nn.functional as F
from torch_geometric.nn import GCNConv
from torch_geometric.datasets import Planetoid
from torch_geometric.transforms import NormalizeFeatures# 加载Cora数据集
dataset = Planetoid(root='/tmp/Cora', name='Cora', transform=NormalizeFeatures())
data = dataset[0]# 定义GCN模型
class GCN(torch.nn.Module):def __init__(self):super(GCN, self).__init__()self.conv1 = GCNConv(dataset.num_node_features, 16)self.conv2 = GCNConv(16, dataset.num_classes)def forward(self, data):x, edge_index = data.x, data.edge_indexx = self.conv1(x, edge_index)x = F.relu(x)x = F.dropout(x, training=self.training)x = self.conv2(x, edge_index)return F.log_softmax(x, dim=1)# 初始化模型和优化器
model = GCN()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)
data = data.to('cuda')
model = model.to('cuda')# 训练模型
def train():model.train()optimizer.zero_grad()out = model(data)loss = F.nll_loss(out[data.train_mask], data.y[data.train_mask])loss.backward()optimizer.step()return loss.item()# 评估模型
def test():model.eval()out = model(data)pred = out.argmax(dim=1)correct = (pred[data.test_mask] == data.y[data.test_mask]).sum()acc = int(correct) / int(data.test_mask.sum())return accfor epoch in range(200):loss = train()acc = test()print(f'Epoch {epoch+1}, Loss: {loss:.4f}, Accuracy: {acc:.4f}')
解释
- 数据加载:加载Cora数据集并归一化特征。
- 模型定义:定义一个简单的两层GCN模型。
- 训练和评估:使用
F.nll_loss计算训练集上的损失,并在每个epoch结束时评估模型在测试集上的准确性。
通过这种方式,F.nll_loss 帮助我们衡量模型在训练集上的表现,并为优化模型提供目标函数。
nll_loss+log_softmax=cross_entropy
为了更简洁地实现负对数似然损失(NLL Loss)和log-softmax的结合,我们可以使用 torch.nn.functional.cross_entropy。cross_entropy 函数将 log_softmax 和 nll_loss 两个步骤合并在一起,简化了代码,并且在数值上更加稳定和高效。
解释
torch.nn.functional.cross_entropy:这是 PyTorch 提供的一个函数,用于计算交叉熵损失。它内部会先对输入进行log_softmax操作,然后计算nll_loss。input:未归一化的模型输出(logits),形状为[num_nodes, num_classes]。target:目标标签,形状为[num_nodes]。
代码示例
以下是如何使用 torch.nn.functional.cross_entropy 替代 log_softmax 和 nll_loss 的代码示例:
import torch
import torch.nn.functional as F
from torch_geometric.nn import GCNConv
from torch_geometric.datasets import Planetoid
from torch_geometric.transforms import NormalizeFeatures# 加载Cora数据集
dataset = Planetoid(root='/tmp/Cora', name='Cora', transform=NormalizeFeatures())
data = dataset[0]# 定义GCN模型
class GCN(torch.nn.Module):def __init__(self):super(GCN, self).__init__()self.conv1 = GCNConv(dataset.num_node_features, 16)self.conv2 = GCNConv(16, dataset.num_classes)def forward(self, data):x, edge_index = data.x, data.edge_indexx = self.conv1(x, edge_index)x = F.relu(x)x = F.dropout(x, training=self.training)x = self.conv2(x, edge_index)return x # 返回未归一化的logits# 初始化模型和优化器
model = GCN()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)
data = data.to('cuda')
model = model.to('cuda')# 训练模型
def train():model.train()optimizer.zero_grad()out = model(data)loss = F.cross_entropy(out[data.train_mask], data.y[data.train_mask])loss.backward()optimizer.step()return loss.item()# 评估模型
def test():model.eval()out = model(data)pred = out.argmax(dim=1) # 提取预测类别correct = (pred[data.test_mask] == data.y[data.test_mask]).sum()acc = int(correct) / int(data.test_mask.sum())return accfor epoch in range(200):loss = train()acc = test()print(f'Epoch {epoch+1}, Loss: {loss:.4f}, Accuracy: {acc:.4f}')
解释
- 数据加载:加载Cora数据集并归一化特征。
- 模型定义:定义一个简单的两层GCN模型。在前向传播过程中返回未归一化的logits。
- 训练过程:使用
F.cross_entropy直接计算损失,它将自动对输入进行log_softmax并计算nll_loss。 - 评估过程:使用
out.argmax(dim=1)提取预测类别,并计算准确性。
通过这种方式,我们简化了代码,并且避免了在计算 log_softmax 和 nll_loss 时可能出现的数值问题。
argmax()
pred = out.argmax(dim=1) 是 PyTorch 中用于从模型的输出中提取预测类别标签的一个常用方法。以下是详细解释:
解释
-
out:这是模型的输出,通常是一个形状为[num_nodes, num_classes]的张量,其中每一行表示一个节点或样本的类别对数概率(log-probabilities)。 -
argmax(dim=1):这是一个张量操作,用于在指定维度上找到最大值的索引。dim=1表示我们在类别维度上进行操作,因此对于每个节点或样本,argmax(dim=1)将返回具有最大对数概率的类别索引。
作用
通过 argmax(dim=1),我们从模型的输出中提取每个节点或样本的预测类别。对于分类任务,这一步是必要的,因为模型的输出通常是每个类别的对数概率分布,我们需要从中选出概率最大的类别作为预测结果。
示例代码
假设我们有一个GNN模型的输出 out,其形状为 [num_nodes, num_classes],以下是如何使用 argmax 提取预测类别的示例代码:
import torch
import torch.nn.functional as F
from torch_geometric.nn import GCNConv
from torch_geometric.datasets import Planetoid
from torch_geometric.transforms import NormalizeFeatures# 加载Cora数据集
dataset = Planetoid(root='/tmp/Cora', name='Cora', transform=NormalizeFeatures())
data = dataset[0]# 定义GCN模型
class GCN(torch.nn.Module):def __init__(self):super(GCN, self).__init__()self.conv1 = GCNConv(dataset.num_node_features, 16)self.conv2 = GCNConv(16, dataset.num_classes)def forward(self, data):x, edge_index = data.x, data.edge_indexx = self.conv1(x, edge_index)x = F.relu(x)x = F.dropout(x, training=self.training)x = self.conv2(x, edge_index)return F.log_softmax(x, dim=1)# 初始化模型和优化器
model = GCN()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)
data = data.to('cuda')
model = model.to('cuda')# 训练模型
def train():model.train()optimizer.zero_grad()out = model(data)loss = F.nll_loss(out[data.train_mask], data.y[data.train_mask])loss.backward()optimizer.step()return loss.item()# 评估模型
def test():model.eval()out = model(data)pred = out.argmax(dim=1) # 提取预测类别correct = (pred[data.test_mask] == data.y[data.test_mask]).sum()acc = int(correct) / int(data.test_mask.sum())return accfor epoch in range(200):loss = train()acc = test()print(f'Epoch {epoch+1}, Loss: {loss:.4f}, Accuracy: {acc:.4f}')
解释
- 数据加载:加载Cora数据集并归一化特征。
- 模型定义:定义一个简单的两层GCN模型。
- 训练和评估:在训练过程中使用
F.nll_loss计算损失。在评估过程中使用out.argmax(dim=1)提取预测类别,并计算准确性。
示例输出
假设 out 的输出如下:
out = torch.tensor([[0.1, 2.3, 0.4],[1.2, 0.8, 3.5],[0.6, 0.7, 0.2]])
使用 out.argmax(dim=1) 提取预测类别:
pred = out.argmax(dim=1)
print(pred)
输出将是:
tensor([1, 2, 1])
这表示模型预测第一个样本的类别为1,第二个样本的类别为2,第三个样本的类别为1。通过这种方式,我们可以从模型的输出中提取每个样本的预测类别,用于后续的评估或其他处理。
相关文章:

【PYG】处理Cora数据集分类任务使用的几个函数log_softmax,nll_loss和argmax
文章目录 log_softmax解释作用示例解释输出 nll_loss解释具体操作示例代码解释 nll_losslog_softmaxcross_entropy解释代码示例解释 argmax()解释作用示例代码解释示例输出 log_softmax F.log_softmax(x, dim1) 是 PyTorch 中的一个函数,用于对输入张量 x 应用 log…...

Labview绘制柱状图
废话不多说,直接上图 我喜欢用NXG风格,这里我个人选的是xy图。 点击箭头指的地方 选择直方图 插值选择第一个 直方图类型我选的是第二个效果如图。 程序部分如图。 最后吐槽一句,现在看CSDN好多文章都要收费了,哪怕一些简单的入…...

使用Python实现一个简单的密码管理器
文章目录 一、项目概述二、实现步骤2.1 安装必要的库2.2 设计密码数据结构2.3 实现密码加密和解密2.4 实现主要功能2.4.1 添加新密码2.4.2 显示所有密码2.4.3 查找特定密码2.4.4 更新密码2.4.5 删除密码 2.5 实现用户界面 三、代码示例3.1 加密和解密示例3.2 用户界面示例 在现…...

【云原生】服务网格(Istio)如何简化微服务通信
🐇明明跟你说过:个人主页 🏅个人专栏:《未来已来:云原生之旅》🏅 🔖行路有良友,便是天堂🔖 目录 一、引言 1、微服务架构的兴起 2、Istio:服务网格的佼…...

spring boot 整合 sentinel
注意版本问题 我这是jdk11 、spring boot 2.7.15 、 alibaba-sentinel 2.1.2.RELEASE <parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.7.15</version><…...
蜜雪冰城小程序逆向
app和小程序算法一样 小程序是wasm...

pbootcms提交留言成功后跳转到指定的网址
pbootcms在线留言表单提交成功后,如何跳转到指定的网址,默认提交留言后留在原来的页面,如果提交后需要跳转到指定网址,我们需要对文件进行修改。首先我们打开/core-/function/helper.php文件找到第162行左右代码: ech…...

16、matlab求导、求偏导、求定积分、不定积分、数值积分和数值二重积分
0)前言 在MATLAB中,对函数进行不同形式的求导、求积分操作是非常常见的需求,在工程、科学等领域中经常会用到。以下是关于求导、求积分以及数值积分的简介: 求导:在MATLAB中可以使用diff函数对函数进行求导操作。diff…...
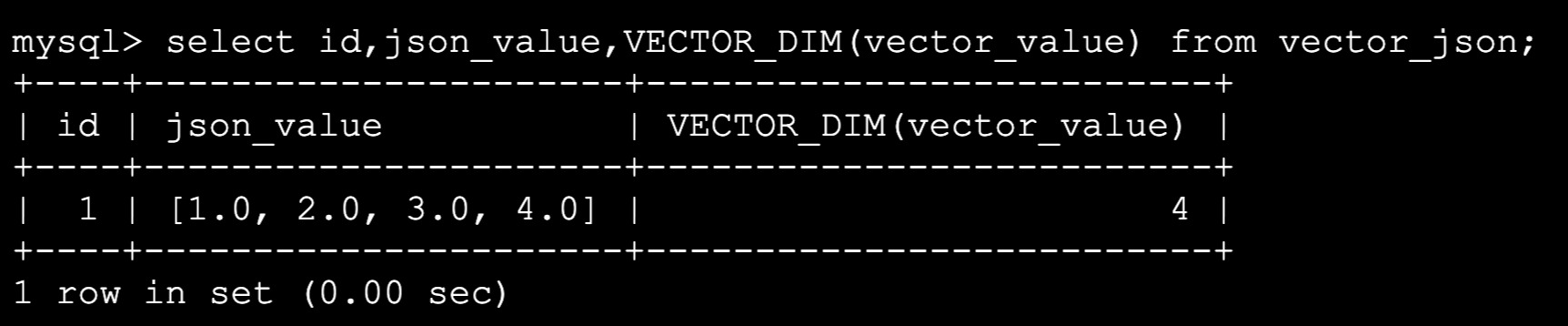
MySQL 9.0创新版发布!功能又进化了!
作者:IT邦德 中国DBA联盟(ACDU)成员,10余年DBA工作经验, Oracle、PostgreSQL ACE CSDN博客专家及B站知名UP主,全网粉丝10万 擅长主流Oracle、MySQL、PG、高斯及Greenplum备份恢复, 安装迁移,性能优化、故障…...

后端系统的安全性
后端系统的安全性 后端系统的安全性是任何Web应用或服务的核心组成部分,它涉及保护数据、用户隐私以及系统免受恶意攻击。以下是后端安全的一些关键点: 认证和授权:确保只有经过身份验证的用户才能访问特定资源。这通常包括使用用户名/密码…...

.net 百度翻译接口核心类
百度翻译api :http://developer.baidu.com/wiki/index.php?title帮助文档首页/百度翻译/翻译AP 核心翻译类 using System; using System.Collections.Generic; using System.Linq; using System.Text; using Newtonsoft.Json; using System.Net; using System.I…...

安卓应用开发学习:通过腾讯地图SDK实现定位功能
一、引言 这几天有些忙,耽误了写日志,但我的学习始终没有落下,有空我就会研究《 Android App 开发进阶与项目实战》一书中定位导航方面的内容。在我的手机上先后实现了“获取经纬度及地理位置描述信息”和“获取导航卫星信息”功能后&#x…...
iptable精讲
SNAT策略 SNAT策略的典型应用环境 局域网主机共享单个公网IP地址接入Internet SNAT策略的原理 源地址转换,Source Network Address Translantion 修改数据包的源地址 部署SNAT策略 1.准备二台最小化虚拟机修改主机名 主机名:gw 主机名࿱…...
2024 年如何构建 AI 软件
人工智能 (AI) 是当今 IT 行业最热门的话题,受到大型科技公司、大型企业和投资者的青睐。如果有人不参与 AI,他们就出局了。虽然“AI 泡沫”一词尚未公开使用,但街上的每个人都可能听说过 AI 将取代我们的工作(可能不会࿰…...

Python实战,桌面小游戏,剪刀石头布
注意:本文的下载教程,与以下文章的思路有相同点,也有不同点,最终目标只是让读者从多维度去熟练掌握本知识点。 下载教程: Python项目开发实战_桌面小游戏-剪刀石头布_编程案例解析实例详解课程教程.pdf 创建一个基于Python的桌面小游戏“剪刀石头布”是一个很好的编程实践…...

Hadoop权威指南-读书笔记-01-初识Hadoop
Hadoop权威指南-读书笔记 记录一下读这本书的时候觉得有意思或者重要的点~ 第一章—初识Hadoop Tips: 这个引例很有哲理嘻嘻😄,道出了分布式的灵魂。 1.1 数据!数据! 这一小节主要介绍了进入大数据时代,面…...
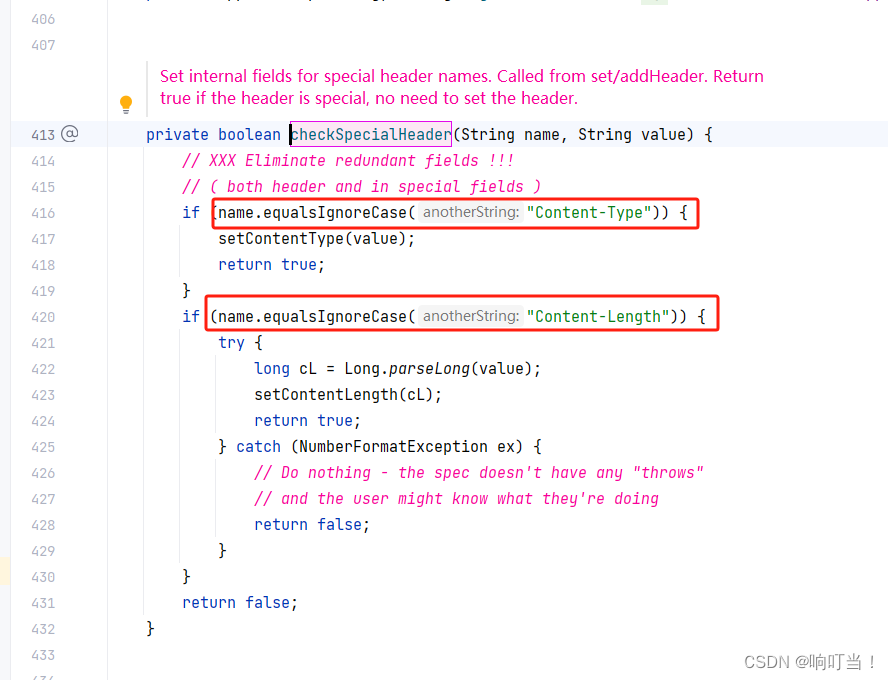
HttpServletResponse设置headers返回,发现headers中缺少“Content-Length“和“Content-Type“两个参数。
业务中需要将用httpUtils请求返回的headers全部返回,塞到HttpServletResponse中,代码如下: HttpServletResponse response;// 返回headers Arrays.stream(httpResponse.getHeaders()).forEach(header -> response.setHeader(header.getNa…...

GraphPad Prism生物医学数据分析软件下载安装 GraphPad Prism轻松绘制各种图表
Prism软件作为一款功能强大的生物医学数据分析与可视化工具,其绘图功能尤为突出。该软件不仅支持绘制基础的图表类型,如直观明了的柱状图、展示数据分布的散点图,以及描绘变化趋势的曲线图,更能应对复杂的数据呈现需求,…...

7/1 uart
uart4.c #include "uart4.h"//UART4_RX > PB2 //UART4_TX > PG11char rebuf[51] {0}; //rcc/gpio/uart4初始化 void hal_uart4_init() {/********RCC章节初始化*******///1.使能GPIOB组控制器 MP_AHB4ENSETR[1] 1RCC->MP_AHB4ENSETR | (0x1 << 1)…...
zdppy_api+vue3+antd开发前后端分离的预加载卡片实战案例
后端代码 import api import upload import timesave_dir "uploads"async def rand_content(request):key api.req.get_query(request, "key")time.sleep(0.3)return api.resp.success(f"{key} " * 100)app api.Api(routes[api.resp.get(&qu…...

终极指南:如何用decimal.js解决JavaScript高精度计算难题
终极指南:如何用decimal.js解决JavaScript高精度计算难题 【免费下载链接】decimal.js An arbitrary-precision Decimal type for JavaScript 项目地址: https://gitcode.com/gh_mirrors/de/decimal.js 你知道吗?JavaScript在处理小数计算时有一个…...
)
ChatGPT Discord机器人开发全链路拆解(含Rate Limit绕过策略与上下文记忆优化)
更多请点击: https://intelliparadigm.com 第一章:ChatGPT与Discord机器人开发全链路概览 构建一个能调用 ChatGPT 能力的 Discord 机器人,需跨越 API 集成、身份认证、消息路由与状态管理四大核心层。该链路并非单向调用,而是一…...

DeepSeek本地部署:从零开始,把大模型跑在自己电脑上
DeepSeek本地部署:从零开始,把大模型跑在自己电脑上我们公司因为数据安全要求,所有文档不能传到外部API。但团队又想用AI辅助写代码、做文档分析。解决方案:本地部署DeepSeek。这篇文章记录了完整的部署过程、踩过的坑、以及部署之…...

基于MCP协议的CalDAV/CardDAV集成:AI智能体统一管理日历与通讯录
1. 项目概述与核心价值最近在折腾智能体(Agent)和自动化工作流时,发现一个痛点:很多强大的工具和数据源,比如日历、邮件、云盘,它们都有自己独立的API,但要让AI智能体去理解和操作这些分散的系统…...

量子生成模型电路设计:特征相似性优化方法
1. 量子生成建模与电路设计概述量子生成模型作为量子机器学习的重要分支,正逐渐展现出其在特定任务上的潜在优势。这类模型的核心思想是利用量子系统的固有概率特性,通过参数化量子电路(PQC)来学习目标数据集的概率分布。与传统生…...

AI智能体自动化部署:Agent Factory 两分钟构建专家级AI助手
1. 项目概述:Agent Factory 是什么? 如果你和我一样,对AI智能体(AI Agent)的潜力感到兴奋,但又对部署一个功能完整、面向公众的专家级Agent感到头疼——需要配置身份、记忆、知识库、Web界面,还…...

ChromaControl:如何用智能技术终结RGB设备控制混乱局面
ChromaControl:如何用智能技术终结RGB设备控制混乱局面 【免费下载链接】ChromaControl 3rd party device lighting support for Razer Synapse. 项目地址: https://gitcode.com/gh_mirrors/ch/ChromaControl 想象一下这样的场景:你的桌面上摆放着…...

TCRT5000循迹小车总跑偏?一份给STM32新手的硬件调试与软件滤波避坑指南
TCRT5000循迹小车调试实战:从硬件校准到软件滤波的完整解决方案 当你的STM32循迹小车在赛道上左右摇摆、频繁跑偏时,问题往往不只是代码逻辑那么简单。作为嵌入式开发新手,你可能已经尝试过调整PID参数、修改转向算法,但效果依然不…...

从泊松比到广义胡克定律:物理仿真中的材料形变建模指南
1. 泊松比:材料形变的"性格密码" 第一次接触泊松比这个概念时,我正对着橡胶减震器的仿真结果发愁——明明设置了正确的杨氏模量,为什么变形效果总是不对劲?直到导师指着屏幕问:"你考虑过这个橡胶材料的…...

意义如何保持活性:一项基于岐金兰哲学体系的系统性阐释
意义如何保持活性:一项基于岐金兰哲学体系的系统性阐释导论:一座理论大厦的蓝图本文旨在对岐金兰哲学体系进行系统性阐释。这一体系围绕一个核心问题展开:意义如何在系统中保持活性,而非走向僵死?这一追问看似抽象&…...