超越所有SOTA达11%!媲美全监督方法 | UC伯克利开源UnSAM
文章链接:https://arxiv.org/pdf/2406.20081
github链接:https://github.com/frank-xwang/UnSAM

SAM 代表了计算机视觉领域,特别是图像分割领域的重大进步。对于需要详细分析和理解复杂视觉场景(如自动驾驶、医学成像和环境监控)的应用特别有价值。今天和大家一起学习的是无监督SAM(UnSAM),用于能够即时启动并自动进行整体图像分割,而无需人工标注数据的方法。UnSAM利用分而治之的策略来“发现”视觉场景的层次结构。首先,利用自顶向下的聚类方法将未标注的图像分割成实例级和语义级的segments。对于每个segment内的所有像素,采用自底向上的聚类方法来迭代合并它们,从而形成更大的组,建立层次结构。这些无监督的多粒度masks随后用于监督模型训练。
在七个流行数据集上评估结果显示,UnSAM在语义平均召回率(AR)方面与有监督的SAM模型取得了竞争力的结果,并且在无监督分割领域超过了先前的最新技术,提升了11%。此外,还展示了有监督的SAM模型也能从本文的自监督标签中受益。通过将无监督伪masks集成到SA-1B的真实masks中,并仅使用SA-1B的1%进行训练,轻度半监督的UnSAM经常能够分割出有监督SAM忽视的实体,其在SA-1B数据集上的AR提升超过了6.7%,AP提升了3.9%。
整体亮点如下:
UnSAM的能力在七个主要的整体实体和部分分割数据集上进行了严格测试,例如MSCOCO、LVIS、SA-1B、ADE、Entity、PartImageNet和PACO。如下图1所示,展示了一些值得注意的表现:
- 无监督分割模型与SAM之间的性能差距可以显著缩小:通过在SA-1B中仅1%的未标注图像上使用ResNet50骨干网络进行训练,UnSAM不仅将无监督分割的最新技术水平提高了10%,还达到了与劳动密集的全监督SAM相媲美的性能。
- 监督式SAM也可以从我们的自监督标签中受益:将无监督伪mask与SA-1B的真实数据结合并在该组合数据上重新训练UnSAM,使得UnSAM+在AR方面超越SAM 6.7%以上,在AP方面超越3.9%。观察到UnSAM和UnSAM+经常能够发现被SAM遗漏的实体。

UnSAM: 无监督SAM
分而治之的分层图像分割
无监督分割任何内容模型从生成尊重视觉场景分层结构的伪masks开始,无需监督。这种方法受到的启发是,“分而治之”的策略是人类视觉系统用来高效处理和分析自然场景中复杂视觉信息的基本组织原则。伪masks生成pipeline “分而治之”,在算法 1 中总结,并在图 2 中说明,包括两个阶段:

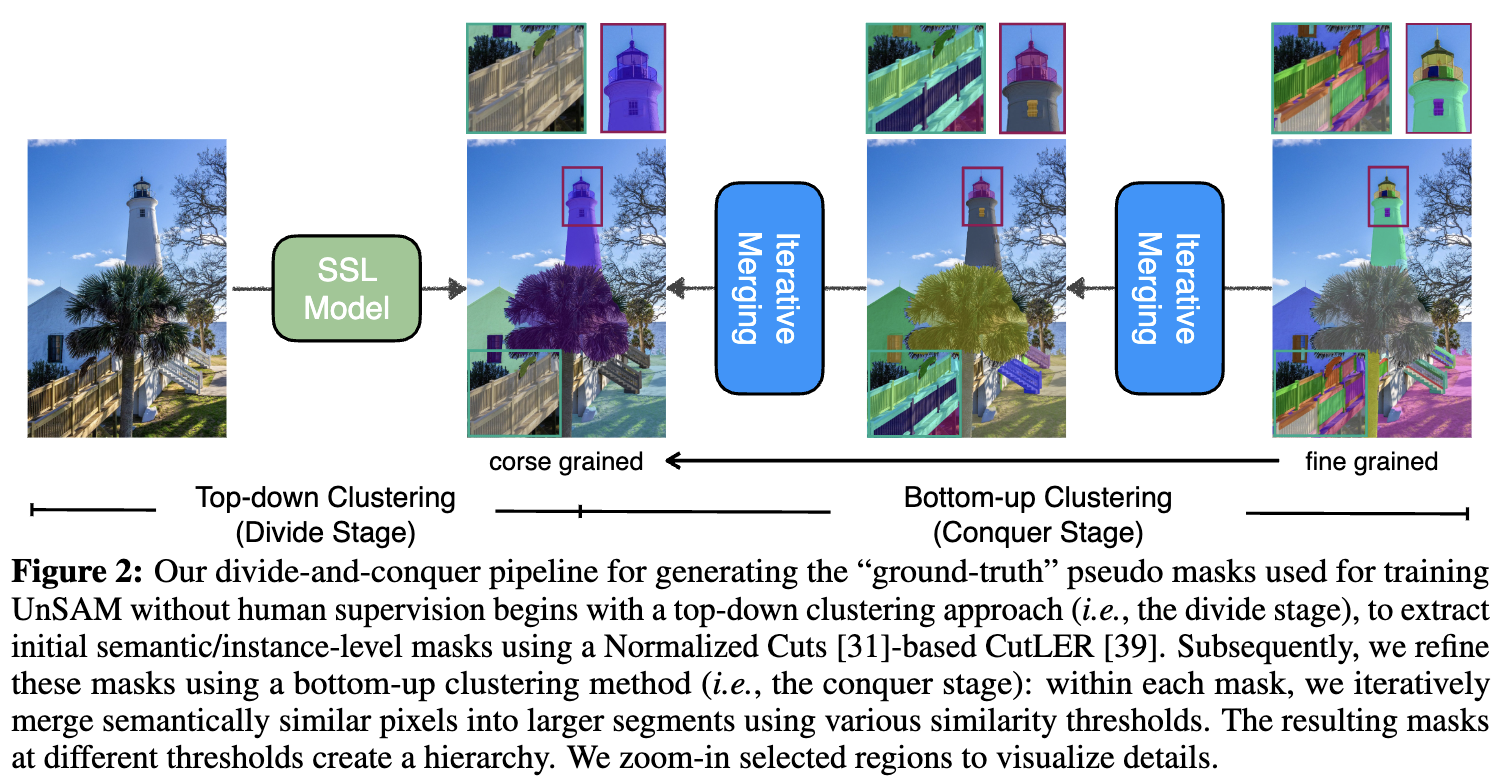
分阶段:利用基于归一化切的方法,即 CutLER,从未标注的原始图像中获取语义和实例级别的masks。然而,由 CutLER 预测的粗粒度masks可能存在噪声。为了减少这种影响,过滤掉置信度低于阈值 τ \tau τ 的masks。经验上,显著的语义和实例级别实体通常包含更丰富的部分级别实体(例如,一个人具有可识别的部分,如腿、手臂和头部,而背景天空则几乎没有或没有子级实体)。为了提取具有分层结构的这些部分级实体,使用Conquer stage。
Conquer阶段:对于在前一阶段发现的每个实例/语义级别masks,采用迭代合并来将粗粒度masks分解为更简单的部分,形成分层结构。
具体而言,首先使用在分阶段获得的masks裁剪局部patches,并双线性插值局部patches至分辨率为 256×256。然后,将它们送到预训练的 DINO ViT-B/8编码器 f(·) 中,并从最后的注意力层提取“关键”特征 k i = f ( p i ) k_i = f(p_i) ki=f(pi) 作为局部patch p i p_i pi 的patch特征。随后,Conquer stage采用迭代合并将patch分组为更大的clusters,具有预定义的余弦相似度阈值 θ ∈ { θ 1 , . . . , θ l } \theta \in \{\theta_1,...,\theta_l\} θ∈{θ1,...,θl},其中 l 是预定义的粒度级别。
在第 t 次迭代中,本文的方法找到两个具有最高余弦相似度的相邻patch ( p i , p j p_i, p_j pi,pj),这两个patch分别来自于两个不同的clusters ( C m t , C n t C^t_m, C^t_n Cmt,Cnt),其余弦相似度为 k i t k j t ∣ ∣ k i t ∣ ∣ 2 ∣ ∣ k j t ∣ ∣ 2 \frac {k^t_ik^t_j} {||k^t_i||_2||k^t_j||_2} ∣∣kit∣∣2∣∣kjt∣∣2kitkjt,将它们合并为一个clusters,并更新 k i t k^t_i kit 和 k j t k^t_j kjt 为 a m k i t + a n k j t a m + a n \frac {a_mk^t_i + a_nk^t_j} {a_m + a_n} am+anamkit+ankjt,其中 a m a_m am 是clusters C m t C^t_m Cmt 中的补丁数目( p i ∈ C m t p_i \in C^t_m pi∈Cmt)。Conquer stage重复这一步骤,直到最大余弦相似度小于 θ t \theta_t θt,将所有合并的clusters收集为新的部分级别伪masks,并使用较小的阈值 θ t + 1 \theta_{t+1} θt+1 再次进行迭代。每个在分阶段发现的粗粒度masks在Conquer stage后可以形成一个分层结构 H。
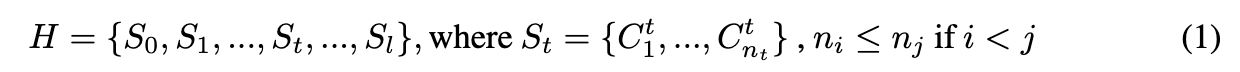
n t n_t nt 是属于粒度级别 t 的clusters/masks数量, n 0 n_0 n0 = 1。
masks合并:在Conquer stage发现的新的部分级别伪masks被添加回到分阶段确定的语义和实例级别伪masks中。然后,使用非极大值抑制(NMS)消除重复。在无监督图像分割的先前工作中,还采用诸如条件随机场(CRF)和CascadePSP等现成的masks精化方法,进一步改善伪masks的边缘。最后,在精化前后的交并比(IoU)显著差异的后处理masks被过滤掉。
初步结果:分而治之pipeline在伪masks池中实现了更多实体、更广泛的粒度级别和优越的质量,与之前的工作(如CutLER、U2Seg和SOHES)相比。如下表3所示,它在从SA-1B数据集中随机选择的1000张验证图像上达到了23.9%的语义平均召回率(AR),比现有技术提升了45.7%。

与先前伪masks生成工作的关键区别:UnSAM采用的分而治之策略使其区别于以往的工作:
[39, 28] 仅依赖于自顶向下的聚类方法,提供实例和语义级别的masks,从而错过了复杂图像中存在的分层结构。相反,本文的pipeline通过识别更细粒度的像素clusters捕捉了这种分层结构。
虽然 [6] 通过自底向上的迭代合并确实结合了一些分层结构,但仍然错过了许多细粒度实例和一些大尺度实例masks。此外,[6] 中的迭代合并专注于低于特定masks尺寸阈值的小区域,主要用于改进噪声小masks,限制了其检测各种实体尺寸的能力。本文的实验结果在质量和数量上表现出与先前工作相比的优越性能,特别是在生成更高质量、更详细的伪masks方面,更好地捕捉视觉场景的分层复杂性。
模型学习和自训练
尽管pipeline生成的伪masks在质量和数量上均优于先前的工作,但它们仍可能存在一定的噪声。自监督pipeline在识别某些类型的实例时存在局限性。例如,迭代合并有时无法正确关联同一实体的断开部分。为了解决这个问题,利用自训练策略进一步提升UnSAM模型的性能。UnSAM 使用分而治之策略发现的masks来学习图像分割模型。观察到自训练使模型能够“清洗”伪masks并预测更高质量的masks。一旦准备好伪masks,UnSAM 可以在模型学习或自训练阶段与任意的整体图像或可提示图像分割模型集成。
整体图像分割
为了简化,选择了基本的Masked Attention Mask Transformer(Mask2Former)。Mask2Former的关键创新在于在Transformer的交叉注意力块中引入了mask注意力机制,定义为 s o f t m a x ( M + Q K T ) V softmax(M + QK^T)V softmax(M+QKT)V,其中注意力mask M在特征位置(x, y)处的定义如下:$M(x, y) =
\begin{cases}
0, M(x, y) = 1 \
-\infty, otherwise
\end{cases}
\tag{1}
$。这种机制限制了在预测mask区域内的注意力。随后,UnSAM 使用以下mask预测损失进行训练:

基于损失函数 L c e L_{ce} Lce 和 L d i c e L_{dice} Ldice,其中 λ c e λ_{ce} λce 和 λ d i c e λ_{dice} λdice 是它们各自的权重。在伪masks上进行一轮自训练后,通过合并高置信度的masks预测(置信度大于 τ s e l f − t r a i n \tau_{self-train} τself−train)作为新的“ground-truth”标注来执行第二轮自训练。为避免重复,过滤掉与预测masks的IoU大于0.5的真值masks。
可提示图像分割
与SAM类似,本文的无监督SAM也可以根据输入提示(如点)生成高质量的对象masks。利用Semantic-SAM作为基础模型,从单击中预测多个粒度级别的masks。在学习过程中,在masks的内部圆圈 (半径 ≤ 0.1 ⋅ m i n ( M a s k w i d t h , M a s k h e i g h t ) (半径 ≤0.1·min(Mask_{width}, Mask_{height}) (半径≤0.1⋅min(Maskwidth,Maskheight))内随机采样点,模拟用户的点击操作。
UnSAM+: 通过无监督分割改进监督SAM
监督SAM模型依赖于人工标注数据,这引入了一个显著的偏见,基于标注人员对“什么构成一个实例”的感知,经常会错过图像中的某些实体。相比之下,由于masks生成pipeline不依赖于人工监督,它通常可以识别SA-1B真值标注忽略的有效对象或部分。
受此观察的启发,利用UnSAM来改进监督SAM的性能,实施一种简单而有效的策略:基于IoU,将SA-1B的真值masks DSA-1B 与无监督分割masks DUnSAM 合并,制定如下:
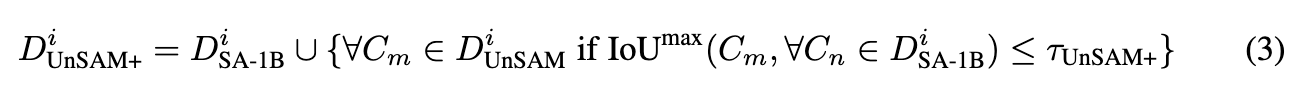
τ U n S A M + \tau_{UnSAM+} τUnSAM+ 是IoU阈值, I o U m a x IoU^{max} IoUmax 是 C m C_m Cm 和 D S A − 1 B i D^i_{SA-1B} DSA−1Bi 中任何masks C n C_n Cn 之间的最大IoU, D S A − 1 B i D^i_{SA-1B} DSA−1Bi 和 D U n S A M + i D^i_{UnSAM+} DUnSAM+i 分别是图像i中的SA-1B和无监督masks集合。
然后,对DUnSAM+ 进行训练,用于可提示图像分割和整体图像分割。融合方法利用了监督和无监督标注的优势,解决了人工注释数据集固有的限制,同时显著丰富了训练数据的多样性和全面性。这导致了更强大、更具普适性的分割模型 UnSAM+,超越了SAM的性能。
实验
模型训练设置
伪masks生成:在分阶段,设置置信度阈值 τ = 0.3 \tau=0.3 τ=0.3;在Conquer 阶段,选择阈值 θ m e r g e = [ 0.6 , 0.5 , 0.4 , 0.3 , 0.2 , 0.1 ] \theta_{merge} = [0.6, 0.5, 0.4, 0.3, 0.2, 0.1] θmerge=[0.6,0.5,0.4,0.3,0.2,0.1]。在将伪masks与真值合并用于训练UnSAM+时,选择 τ U n S A M + = 0.02 \tau_{UnSAM+} = 0.02 τUnSAM+=0.02。
整体图像分割:UnSAM选择DINO预训练的ResNet-50作为骨干网络,Mask2former作为mask解码器。默认学习率为 5 × 1 0 − 5 5 × 10^{-5} 5×10−5,batch大小为16,权重衰减为 5 × 1 0 − 2 5 × 10^{-2} 5×10−2。训练模型8个epochs。
可提示图像分割:UnSAM使用自监督预训练的Swin-Transformer Tiny模型作为骨干网络,并利用Semantic-SAM 作为基础模型。设置层级数为6,这也是UnSAM在推断期间针对每个提示生成的预测masks数。对于所有实验,使用SA-1B数据集的1∼4%未标注图像进行训练。
评估数据集和指标
整体图像分割:以zero-shot方式在各种数据集上测试本文的模型,以评估从所有粒度级别分割实体的性能。选择 COCO、LVIS、ADE20K、EntitySeg、SA-1B(主要包含语义-/实例级别实体)、PartImageNet 和 PACO(覆盖部分级别实体)。SA-1B 测试集包括随机选择的1000张不包含在训练集中的图像。值得注意的是,每个数据集仅涵盖特定层次的实体和特定预定义的类别,而模型从所有层次和所有类别生成masks。因此,COCO 平均精度(AP)指标可能无法反映模型在分割开放世界中所有实体方面的真实性能。遵循之前的工作,主要考虑平均召回率(AR)来与不同模型进行比较。
基于点提示的可提示图像分割:在 COCO Val2017上评估基于点的交互式模型。根据之前关于可提示图像分割的工作,选择两个指标来评估模型:MaxIoU 和 OracleIoU。对于每个点提示,UnSAM 预测6个masks,代表不同的粒度级别。MaxIoU 计算6个masks中具有最高置信度分数的masks与真值之间的IoU,而OracleIoU 选择6个预测masks与真值之间的最高IoU。对于每个测试图像,选择其中心作为点提示。
评估结果
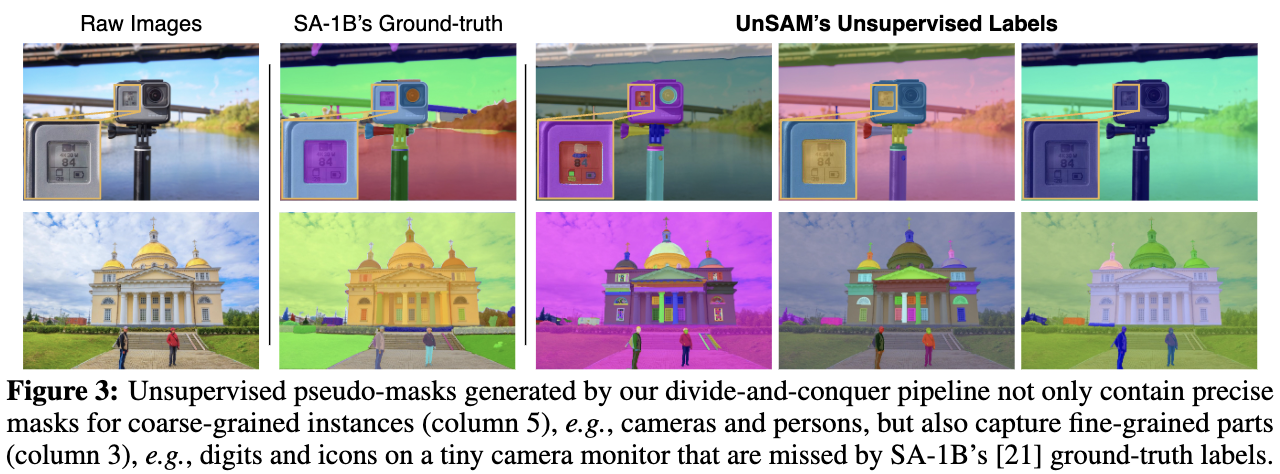
无监督伪masks:分而治之pipeline生成的无监督伪masks不仅包含精确的粗粒度实例masks,还捕获了SA-1B真值标签常常忽略的细粒度部分,如下图3所示。
整体图像分割:UnSAM在所有评估数据集上均优于现有技术,如前面表1所总结的。UnSAM表现出色,即使只使用SA-1B训练数据的1%,并且使用参数为2300万的ResNet-50骨干网络,而现有技术则使用两倍的训练数据和几乎四倍的参数。这表明UnSAM是一个轻量级、更易于训练且对数据需求较少的模型,在分割开放世界中的实体时具有更好的zero-shot性能,如下图4和5所示。
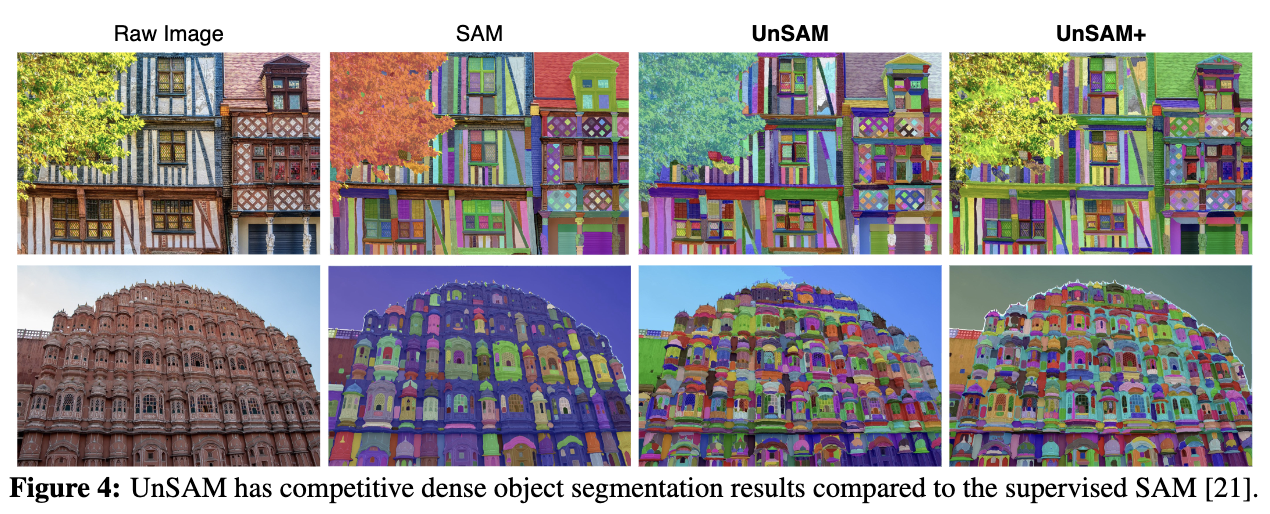

平均而言,UnSAM在AR方面超过先前的SOTA达11.0%。在PartImageNet 和 PACO 上评估时,UnSAM分别超过先前的SOTA达16.6%和12.6%。与监督SAM相比,UnSAM在所有数据集上的AR差距仅为1%。在PartImageNet 和 PACO上,UnSAM分别比SAM超过24.4%和11.6%。这进一步展示了分而治之pipeline在发现人类标注者往往会忽略的细节方面的出色能力。
此外,UnSAM+,通过整合无监督伪masks和SA-1B真值进行训练,表现优于SAM的AR超过6.7%,AP超过3.9%,如前面表2和4所示。UnSAM+ 在所有评估数据集上的平均召回率优于SAM,除了ADE20K,这是由语义级别标注主导的数据集。UnSAM+ 在小实体上显著比SAM高出16.2%的AR进一步证实,伪masks可以有效地补充SA-1B数据集忽略的细节,而UnSAM+ 可以常常发现SAM错过的实体,如上面图4所示。
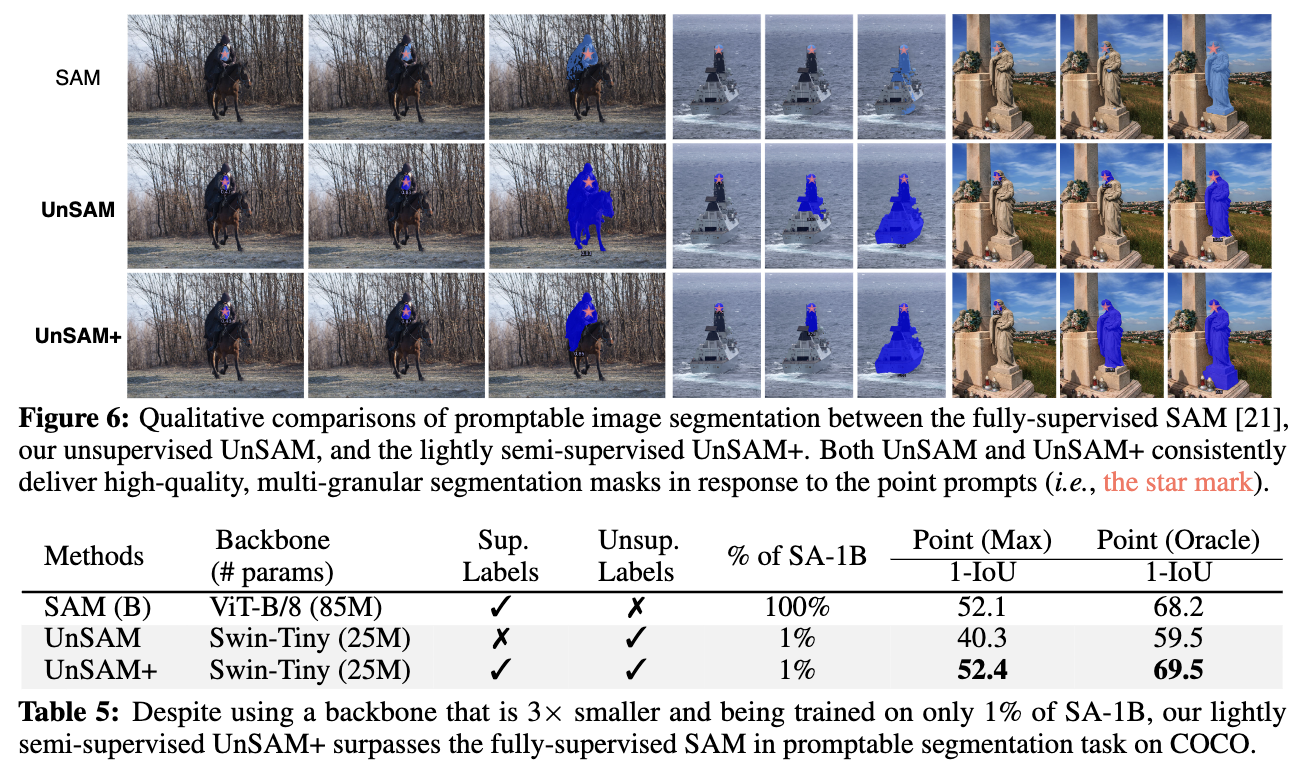
基于点提示的可提示图像分割:如下表5所示,使用伪masks训练的UnSAM在COCO上达到了40.3%的MaxIoU和59.5%的OracleIoU。值得注意的是,只使用了SAM 使用数据的1%以及一个具有4倍少参数的骨干网络进行训练。此外,使用整合的伪masks和SA-1B真值进行训练的UnSAM+ 在MaxIoU和OracleIoU上分别比SAM优于0.3%和1.3%。定性结果见下图6。
总结
图像分割是计算机视觉中的基本任务,传统上依赖于密集的人工标注来详细理解视觉场景。本文提出了UnSAM,一个无监督分割模型,在无监督图像分割的性能上显著超越了先前的最新技术。此外,无监督UnSAM模型取得了令人印象深刻的结果,与领先的监督SAM的性能相媲美,并在某些半监督设置下超越它。
参考文献
[1] Segment Anything without Supervision
相关文章:
超越所有SOTA达11%!媲美全监督方法 | UC伯克利开源UnSAM
文章链接:https://arxiv.org/pdf/2406.20081 github链接:https://github.com/frank-xwang/UnSAM SAM 代表了计算机视觉领域,特别是图像分割领域的重大进步。对于需要详细分析和理解复杂视觉场景(如自动驾驶、医学成像和环境监控)的应用特别有…...
)
享元模式(设计模式)
享元模式(Flyweight Pattern)是一种结构型设计模式,它通过共享细粒度对象来减少内存使用,从而提高性能。在享元模式中,多个对象可以共享相同的状态以减少内存消耗,特别适合用于大量相似对象的场景。 享元模…...
【机器学习】大模型训练的深入探讨——Fine-tuning技术阐述与Dify平台介绍
目录 引言 Fine-tuning技术的原理阐 预训练模型 迁移学习 模型初始化 模型微调 超参数调整 任务设计 数学模型公式 Dify平台介绍 Dify部署 创建AI 接入大模型api 选择知识库 个人主页链接:东洛的克莱斯韦克-CSDN博客 引言 Fine-tuning技术允许用户根…...
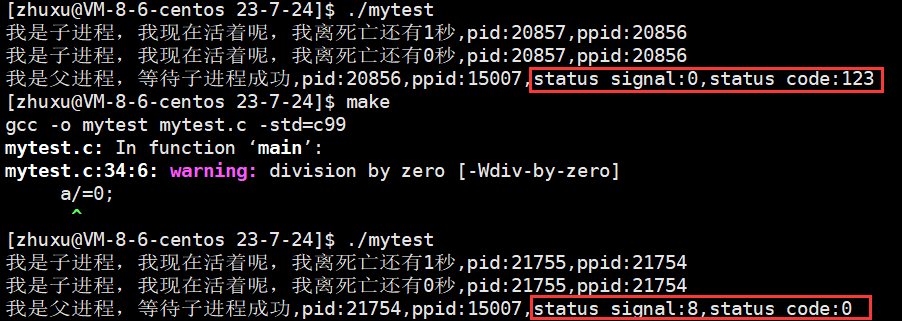
【Linux从入门到放弃】探究进程如何退出以进程等待的前因后果
🧑💻作者: 情话0.0 📝专栏:《Linux从入门到放弃》 👦个人简介:一名双非编程菜鸟,在这里分享自己的编程学习笔记,欢迎大家的指正与点赞,谢谢! 进…...

QT5 static_cast实现显示类型转换
QT5 static_cast实现显示类型转换,解决信号重载情况...
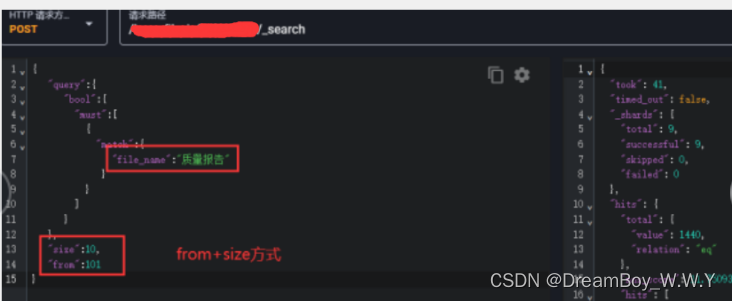
【ES】--Elasticsearch的翻页详解
目录 一、前言二、from+size浅分页1、from+size导致深度分页问题三、scroll深分页1、scroll原理2、scroll可以返回总计数量四、search_after深分页1、search_after避免深度分页问题一、前言 ES的分页常见的主要有三种方式:from+size浅分页、scroll深分页、search_after分页。…...

3.js - 纹理的重复、偏移、修改中心点、旋转
你瞅啥 上字母 // ts-nocheck // 引入three.js import * as THREE from three // 导入轨道控制器 import { OrbitControls } from three/examples/jsm/controls/OrbitControls // 导入lil.gui import { GUI } from three/examples/jsm/libs/lil-gui.module.min.js // 导入twee…...

RS232隔离器的使用
RS232隔离器在通信系统中扮演着至关重要的角色,其主要作用可以归纳如下: 一、保护通信设备 电气隔离:RS232隔离器通过光电隔离技术,将RS-232接口两端的设备电气完全隔离,从而避免了地线回路电压、浪涌、感应雷击、静电…...

一切为了安全丨2024中国应急(消防)品牌巡展武汉站成功召开!
消防品牌巡展武汉站 6月28日,由中国安全产业协会指导,中国安全产业协会应急创新分会、应急救援产业网联合主办,湖北消防协会协办的“一切为了安全”2024年中国应急(消防)品牌巡展-武汉站成功举办。该巡展旨在展示中国应急(消防&am…...

【面试系列】PHP 高频面试题
欢迎来到我的博客,很高兴能够在这里和您见面!欢迎订阅相关专栏: ⭐️ 全网最全IT互联网公司面试宝典:收集整理全网各大IT互联网公司技术、项目、HR面试真题. ⭐️ AIGC时代的创新与未来:详细讲解AIGC的概念、核心技术、…...
JAVA极简图书管理系统,初识springboot后端项目
前提条件: 具备基础的springboot 知识 Java基础 废话不多说! 创建项目 配置所需环境 将application.properties>application.yml 配置以下环境 数据库连接MySQL 自己创建的数据库名称为book_test server:port: 8080 spring:datasource:url:…...

MySQL 重新初始化实例
1、关闭mysql服务 service mysqld stop 2、清理datadir(本例中指定的是/var/lib/mysql)指定的目录下的文件,将该目录下的所有文件删除或移动至其他位置 cd /var/lib/mysql mv * /opt/mysql_back/ 3、初始化实例 /usr/local/mysql/bin/mysqld --initialize --u…...
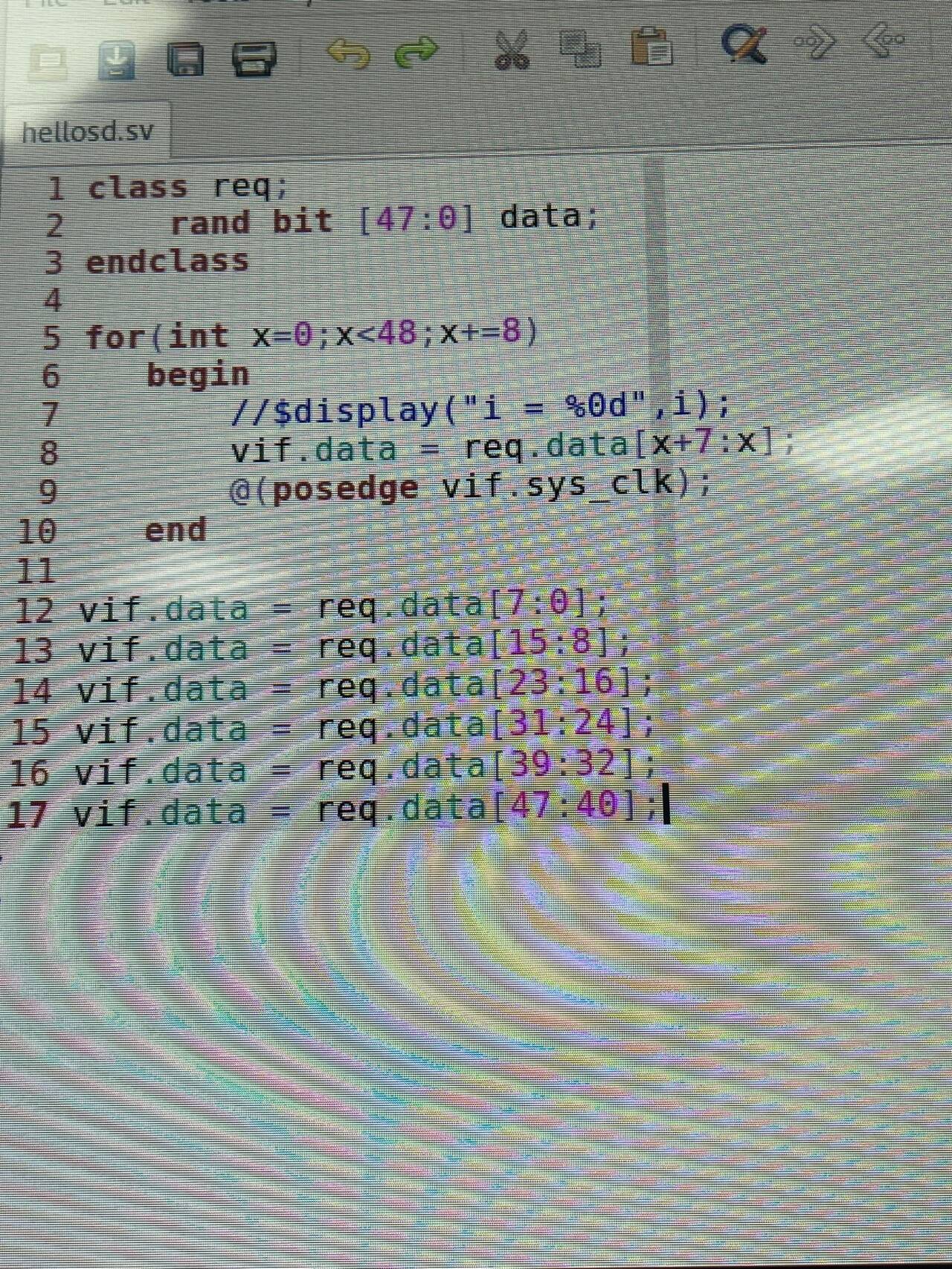
VCS编译bug汇总
‘typedef’ is not expected to be used in this contex 注册前少了分号。 Scope resolution error resolution : 声明指针时 不能与类名同名,即 不能声明为adapter. cannot find member "type_id" 忘记注册了 拼接运算符使用 关键要加上1b࿰…...
?)
【2024LLM应用-数据预处理】之如何从PDF,PPT等非结构化数据提取有效信息(结构化数据JSON)?
🥰大家知道吗,之前在给AI大模型"喂数据"的时候,我们往往需要把非结构化数据(比如PDF、PPT、Excel等)自己手动转成结构化的格式,这可真是太累人儿了。🥵 幸好现在有了Unstructured这个神级库,它内置的数据提取函数可以帮我们快速高效地完成这个…...

冯雷老师:618大退货事件分析
近日冯雷老师受邀为某头部电商36名高管进行培训,其中聊到了今年618退货潮的问题。以下内容整理自冯雷老师的部分授课内容。 一、引言 随着电子商务的蓬勃发展,每年的618大促已成为消费者和商家共同关注的焦点。然而,在销售额不断攀升的同时…...

JAVA基础教程DAY0-基础知识
JAVA语言的特点 简单性、面向对象、安全性、跨平台性、支持多线程、分布性 面向对象编程(Object-Oriented Programming,简称OOP)是一种编程范式,它通过将数据和操作这些数据的方法封装在一起,以创建对象的形式来组织代…...

鸿蒙开发Ability Kit(程序访问控制):【安全控件概述】
安全控件概述 安全控件是系统提供的一组系统实现的ArkUI组件,应用集成这类组件就可以实现在用户点击后自动授权,而无需弹窗授权。它们可以作为一种“特殊的按钮”融入应用页面,实现用户点击即许可的设计思路。 相较于动态申请权限的方式&am…...

【信息系统项目管理师】18年~23年案例概念型知识
文章目录 18上18下19上19下20上20下21上21下22年上22年下23年上 18上 请简述 ISO 9000 质量管理的原则 领导作用、 过程方法、 管理的系统方法、 与供方互利的关系、 基于事实的决策方法、 持续改进、 全员参与、 以顾客为关注焦点 概念 国家标准(GB/T 1 9000 2008)对质量的定…...

什么是字符串常量池?如何利用它来节省内存?
字符串常量池是Java中一个非常重要的概念,尤其对于理解内存管理和性能优化至关重要。想象一下,你正在管理一家大型图书馆,每天都有无数读者来借阅书籍。 如果每本书每次借阅都需要重新印刷一本,那么图书馆很快就会陷入混乱&#…...

Selenium自动化测试20条常见异常+处理方案
常见的Selenium异常 以下是所有Selenium WebDriver代码中可能发生的一些常见Selenium异常。 1、ElementClickInterceptedException 由于以某种方式隐藏了接收到click命令的元素,因此无法正确执行Element Click命令。 2、ElementNotInteractableException 即使目…...

京东自动抢购终极指南:Python脚本帮你告别“手慢无“的烦恼
京东自动抢购终极指南:Python脚本帮你告别"手慢无"的烦恼 【免费下载链接】autobuy-jd 使用python语言的京东平台抢购脚本 项目地址: https://gitcode.com/gh_mirrors/au/autobuy-jd 还在为心仪的商品总是抢不到而烦恼吗?当你看到"…...

半导体行业资本投入与技术创新:英特尔IDM模式解析
1. 半导体行业的资本游戏:为什么持续投入是制胜关键 半导体行业有个不成文的规则:要么大笔投入,要么趁早退出。这个行业的准入门槛之高令人咋舌——建一座先进晶圆厂动辄需要百亿美元起步,而研发新一代制程工艺的投入更是天文数字…...

Overture:一站式AI应用开发框架,快速构建大模型服务
1. 项目概述:一个开箱即用的开源AI应用框架最近在折腾AI应用开发的朋友,估计都绕不开一个核心问题:如何快速、稳定地把一个大语言模型的能力,封装成一个可以对外提供服务的API,甚至是带界面的Web应用。从模型加载、推理…...

自动化安全测试:自动化检测安全漏洞
自动化安全测试:自动化检测安全漏洞 一、自动化安全测试概述 1.1 自动化安全测试的定义 自动化安全测试是指使用自动化工具和脚本对应用程序、基础设施和网络进行安全检测,自动识别安全漏洞和安全风险的过程。 1.2 自动化安全测试的价值 效率提升&#x…...

基于MCP协议构建AI工具调用客户端:原理、实践与Node.js实现
1. 项目概述:MCP生态中的客户端实践最近在折腾AI智能体开发,发现一个挺有意思的现象:大家把大模型的能力吹得天花乱坠,但真要让它们去操作一个具体的系统、查询实时的数据,或者调用一个私有API,往往就卡壳了…...
)
别再被Node版本坑了!手把手教你修改uniCloud云函数的Node.js版本(从8升到12/18)
突破Node.js版本限制:uniCloud云函数升级实战指南 1. 为什么你的云函数在云端运行失败? 许多开发者在使用uniCloud时都遇到过这样的困惑:明明本地测试一切正常,部署到云端却突然报错。最常见的错误信息包括right-hand side of ins…...

ARM调试架构中DBGCLAIMCLR寄存器详解
1. ARM调试架构中的DBGCLAIMCLR寄存器深度解析在嵌入式系统开发领域,ARM架构的调试子系统一直是工程师们需要掌握的核心技术。作为调试功能的关键组成部分,DBGCLAIMCLR寄存器在调试器与目标系统的交互中扮演着重要角色。这个看似简单的32位寄存器&#x…...

StackEdit v6.0.7发布:懒加载、图片查看等功能升级,优化Markdown编辑体验
StackEdit v6.0.7:多维度功能升级StackEdit v6.0.7正式发布,此次更新涵盖了多个重要功能。在组件加载方面,优化非常用的组件为懒加载方式,这能有效提升编辑器的加载速度和性能。在线离线判断也得到调整,让用户在不同网…...

终极指南:如何用AnyKernel3一键创建完美Android内核刷机包
终极指南:如何用AnyKernel3一键创建完美Android内核刷机包 【免费下载链接】AnyKernel3 AnyKernel, Evolved 项目地址: https://gitcode.com/gh_mirrors/an/AnyKernel3 想要为你的Android设备制作内核刷机包,却总是被复杂的设备兼容性搞得焦头烂额…...

GBase 8s 之 dbschema 导出数据库对象定义介绍
在数据库管理和开发过程中,经常需要导出数据库对象的定义,以便进行备份、迁移或分析。GBase 8s 提供了 dbschema 工具,能够方便地导出各种数据库对象的定义。本文将详细介绍 dbschema 的使用方法,帮助你快速掌握这一实用工具。…...