hive的表操作
常用的hive命令
| 切换数据库 | use test; |
| 查询表的建表信息 | show create table 数据库名称.表名; |
| 查看表的类型信息 | desc formatted 数据库名称.表名; |
| 删除内部表 | drop table 数据库名称.表名; |
先启动hdfs ,mysql , hiveservice2,beeline
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT COL_COMMENT],.....)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment],....)]
[CLUSTERED BY (col_name,col_name,....)]
[SORTED BY (col_name [ASC|DESC],...)] INFO num_buckets BUCKETS]
[ROW FORMAT DELIMITED FIELDS TERMINATED BY ',']
[STORED AS file_format]
[LOCATION hdfs_path]字段解释
1 CREATE TABLE创建一个指定名字的表,如果名字相同抛出异常,用户可以使用IF NOT EXISTS来忽略异
常
2 EXTERNAL关键字可以创建一个外部表,在建表的同时指定一个实际数据的路径(LOCATION)
,hive在删除表的时候,内部表的元数据和数据会被一起删除,而外部表只删除元数据,不删除数据
3 COMMENT是为表和列添加注释
4 PARTITIONED BY是分区表
5 CLUSTERED BY 是建分桶(不常用)
6 SORTED BY 是指定字段进行排序(不常用)
7 ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' 是指每行数据中列分隔符为","
默认分隔符为" \001"
8 STORED AS 指定存储文件类型,数据文件是纯文本,可以使用STORED AS TEXTFILE
9 LOCATION 指定表在HDFS上的存储位置,内部表不要指定,
但是如果定义的是外部表,则需要直接指定一个路径。
--创建数据库test
create database if not exists test;
--在数据库test中创建emp1表
--有两种方式
--1.先切换数据库 再创建表
use test;create table if not exists emp1(emp_id int,emp_name string,department_id int)
stored as textfile
;
--将以上内容写入sql文件中,再用source 执行文件
source /opt/sql/create_emp.sql;--查询表的建表信息
--show create table 数据库名称.表名;
show create table test.emp1;+----------------------------------------------------+
| createtab_stmt |
+----------------------------------------------------+
| CREATE TABLE `test.emp1`( |
| `emp_id` int, |
| `emp_name` string, |
| `department_id` int) |
| ROW FORMAT SERDE |
| 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe' |
| STORED AS INPUTFORMAT |
| 'org.apache.hadoop.mapred.TextInputFormat' |
| OUTPUTFORMAT |
| 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat' |
| LOCATION |
| 'hdfs://bigdata004:8020/user/hive/warehouse/test.db/emp1' |
| TBLPROPERTIES ( |
| 'bucketing_version'='2', |
| 'transient_lastDdlTime'='1719865642') |
+----------------------------------------------------+
--2.直接在建表语句中指定对应的数据库
create table if not exists test.emp1(emp_id int,emp_name string,department_id int)
stored as textfile
;--查看表的类型信息
--desc formatted 数据库名称.表名;
desc formatted test.emp1;
+-------------------------------+----------------------------------------------------+----------------------------------------------------+
| col_name | data_type | comment |
+-------------------------------+----------------------------------------------------+----------------------------------------------------+
| # col_name | data_type | comment |
| emp_id | int | |
| emp_name | string | |
| department_id | int | |
| | NULL | NULL |
| # Detailed Table Information | NULL | NULL |
| Database: | test | NULL |
| OwnerType: | USER | NULL |
| Owner: | root | NULL |
| CreateTime: | Tue Jul 02 04:27:22 CST 2024 | NULL |
| LastAccessTime: | UNKNOWN | NULL |
| Retention: | 0 | NULL |
| Location: | hdfs://bigdata004:8020/user/hive/warehouse/test.db/emp1 | NULL |
| Table Type: | MANAGED_TABLE | NULL |
| Table Parameters: | NULL | NULL |
| | COLUMN_STATS_ACCURATE | {\"BASIC_STATS\":\"true\",\"COLUMN_STATS\":{\"department_id\":\"true\",\"emp_id\":\"true\",\"emp_name\":\"true\"}} |
| | bucketing_version | 2 |
| | numFiles | 0 |
| | numRows | 0 |
| | rawDataSize | 0 |
| | totalSize | 0 |
| | transient_lastDdlTime | 1719865642 |
| | NULL | NULL |
| # Storage Information | NULL | NULL |
| SerDe Library: | org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe | NULL |
| InputFormat: | org.apache.hadoop.mapred.TextInputFormat | NULL |
| OutputFormat: | org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat | NULL |
| Compressed: | No | NULL |
| Num Buckets: | -1 | NULL |
| Bucket Columns: | [] | NULL |
| Sort Columns: | [] | NULL |
| Storage Desc Params: | NULL | NULL |
| | serialization.format | 1 |
+-------------------------------+----------------------------------------------------+----------------------------------------------------+
33 rows selected (0.153 seconds)
--创建带有注释的内部表emp2
create table if not exists test.emp2(emp_id int comment "员工id",emp_name string comment "员工姓名",department_id int comment "部门id"
)
comment "员工内部表"
stored as textfile
;
--将以上内容写入sql文件中,再用source
--在beeline命令行中执行sql文件
此时查看建表信息
+----------------------------------------------------+
| createtab_stmt |
+----------------------------------------------------+
| CREATE TABLE `test.emp2`( |
| `emp_id` int COMMENT '??id', |
| `emp_name` string COMMENT '????', |
| `department_id` int COMMENT '??id') |
| COMMENT '?????' |
| ROW FORMAT SERDE |
| 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe' |
| STORED AS INPUTFORMAT |
| 'org.apache.hadoop.mapred.TextInputFormat' |
| OUTPUTFORMAT |
| 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat' |
| LOCATION |
| 'hdfs://bigdata004:8020/user/hive/warehouse/test.db/emp2' |
| TBLPROPERTIES ( |
| 'bucketing_version'='2', |
| 'transient_lastDdlTime'='1719868467') |
+----------------------------------------------------+
16 rows selected (0.104 seconds)
问号部分就是注释里的中文,要解决下其乱码问题
解决hive中文乱码
1.登录mysql 执行如下命令 然后重启mysql
得先退出hive 并杀死进程 kill -9 进程号
#修改字段注释字符集
alter table hive.COLUMNS_V2 modify column COMMENT varchar(256) character set utf8;#修改表注释字符集
alter table hive.TABLE_PARAMS modify column PARAM_VALUE varchar(20000) character set utf8;#修改分区参数,支持分区建用中文表示
alter table hive.PARTITION_PARAMS modify column PARAM_VALUE varchar(20000) character set utf8;
alter table hive.PARTITION_KEYS modify column PKEY_COMMENT varchar(20000) character set utf8;打开navicat

将命令输入 ,点击运行
重启mysql
systemctl stop mysqld
systemctl start mysqld
##2. 在hive-site.xml配置文件中修改如下配置
<property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://bigdata004:3306/hive?createDatabaseIfNotExist=true&useSSL=false&useUnicode=true&characterEncoding=UTF-8</value><description>JDBC connect string for a JDBC metastore</description></property>
对于之前创建的带注释的表emp2不起效果,一=应该重新创建一个注释的表
+----------------------------------------------------+
| createtab_stmt |
+----------------------------------------------------+
| CREATE TABLE `test.emp2`( |
| `emp_id` int COMMENT '员工id', |
| `emp_name` string COMMENT '员工姓名', |
| `department_id` int COMMENT '部门id') |
| COMMENT '?????' |
| ROW FORMAT SERDE |
| 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe' |
| STORED AS INPUTFORMAT |
| 'org.apache.hadoop.mapred.TextInputFormat' |
| OUTPUTFORMAT |
| 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat' |
| LOCATION |
| 'hdfs://bigdata004:8020/user/hive/warehouse/test.db/emp2' |
| TBLPROPERTIES ( |
| 'bucketing_version'='2', |
| 'transient_lastDdlTime'='1719869823') |
+----------------------------------------------------+
成功了
相关文章:
hive的表操作
常用的hive命令 切换数据库use test;查询表的建表信息show create table 数据库名称.表名;查看表的类型信息desc formatted 数据库名称.表名; 删除内部表 drop table 数据库名称.表名; 先启动hdfs ,mysql , hiveservice2,beeline CREATE [EX…...
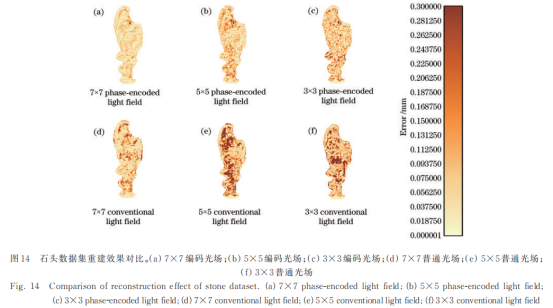
基于多视点编码光场的全景三维重建方法
欢迎关注GZH《光场视觉》 摘要:在基于光场的一系列应用中,目标的三维重建是基础且关键的任务。普通光场只能重建单一视角而无法重建全景,并且在纹理特征匮乏的区域也无法生成准确的三维信息。针对以上问题,提出一种基于多视点编码…...

Spring Boot中的分布式文件系统
Spring Boot中的分布式文件系统 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!今天,我们将探讨如何在Spring Boot中实现分布式文件系统的搭建和应用…...

three.js地理坐标系有哪些,和屏幕坐标系的转换。
坐标系很好理解,就是点线面体的位置,一个点是一个坐标,一条线段2个坐标,一个矩形四个坐标,一个立方体8个坐标,three.js面对的是三维空间,屏幕则是二维的,这就面临着转换问题…...

聊聊C++20的三向比较运算符 `<=>`
C20标准引入了许多新特性,其中之一是三向比较运算符 <>,也被称为太空船运算符。这个新运算符为C程序员提供了一种全新的比较对象的方式,它能有效简化比较逻辑,避免编写多个比较运算符重载的情况。 为什么需要三向比较运算符…...
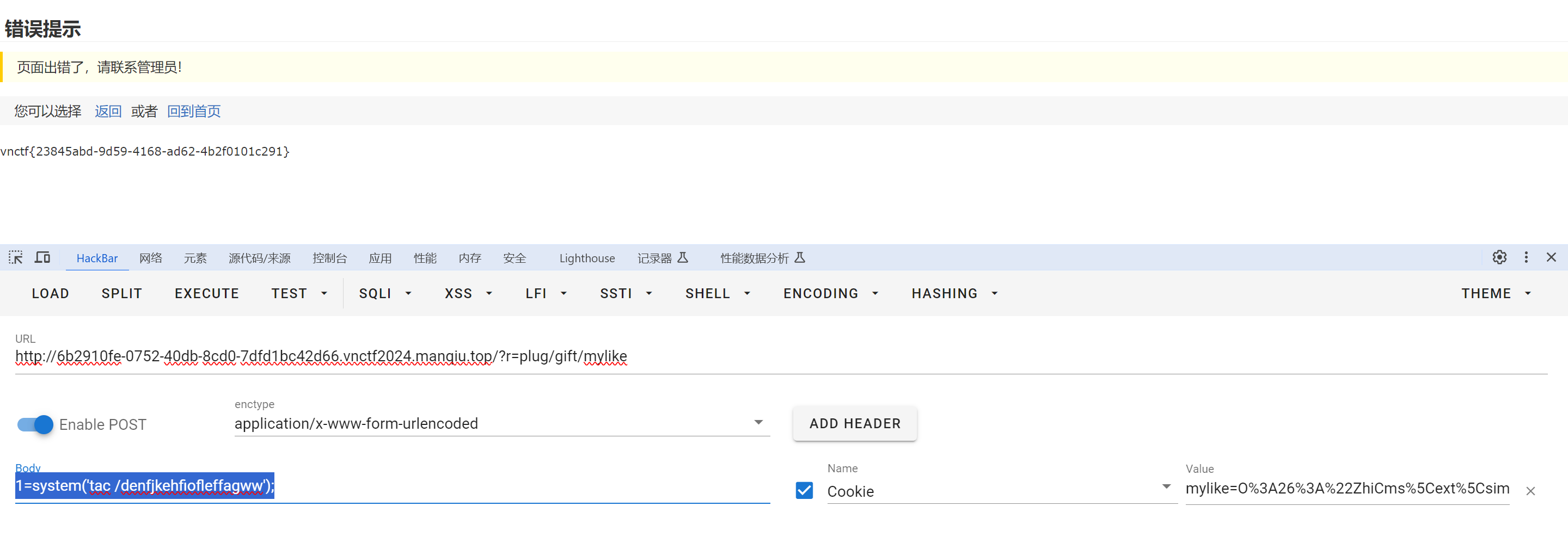
CVE-2024-0603 漏洞复现
CVE-2024-0603 源码:https://gitee.com/dazensun/zhicms 开题: CVE-2024-0603描述:ZhiCms up to 4.0版本的文件app/plug/controller/giftcontroller.php中存在一处未知漏洞。攻击者可以通过篡改参数mylike触发反序列化,从而远程…...
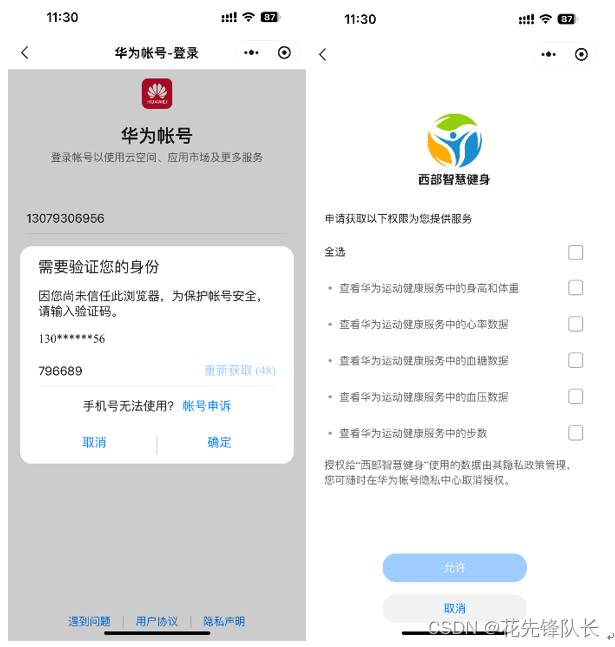
西部智慧健身小程序+华为运动健康服务
1、 应用介绍 西部智慧健身小程序为用户提供一站式全流程科学健身综合服务。用户通过登录微信小程序,可享用健康筛查、运动风险评估、体质检测评估、运动处方推送、个人运动数据监控与评估等公益服务。 2、 体验介绍西部智慧健身小程序华为运动健康服务核心体验如…...

Spring Boot中如何处理异步任务
Spring Boot中如何处理异步任务 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!今天我们将探讨在Spring Boot应用中如何处理异步任务,以提升系统的性…...
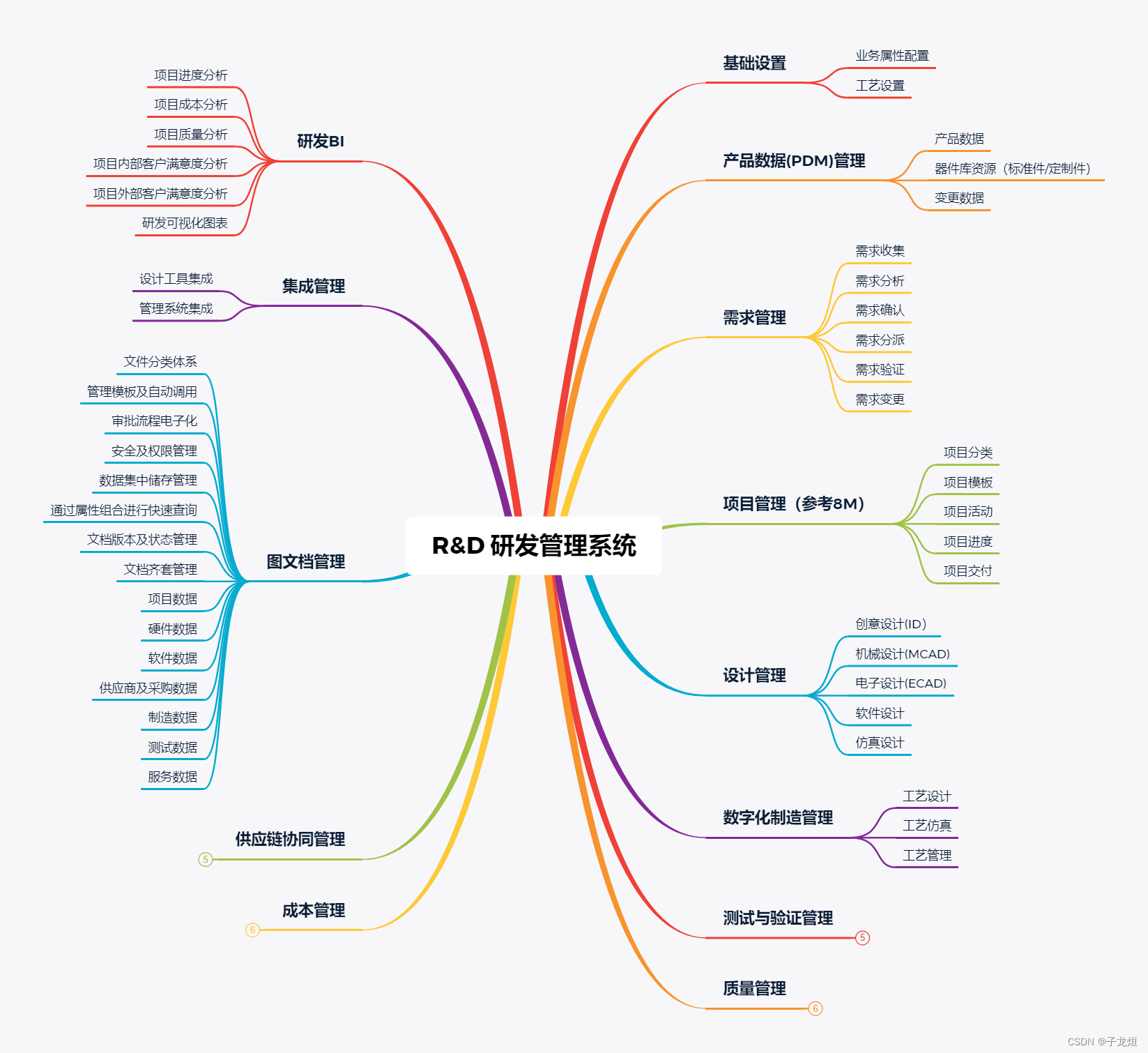
数字化精益生产系统--RD研发管理系统
R&D研发管理系统是一种用于管理和监督科学研究和技术开发的软件系统,其设计和应用旨在提高企业研发活动的效率、质量和速度。以下是对R&D研发管理系统的功能设计:...

鱼眼相机 去畸变
目录 枕形畸变和去枕形畸变 去枕形畸变失败 枕形畸变和去枕形畸变 import cv2 import numpy as np import matplotlib.pyplot as plt# 创建一个带网格的原始图像 def create_grid(image_size512, grid_size20):image np.zeros((image_size, image_size, 3), dtypenp.uint8)…...

DC/AC电源模块:为智能家居设备提供恒定的电力供应
BOSHIDA DC/AC电源模块:为智能家居设备提供恒定的电力供应 DC/AC电源模块是一种常见的电源转换器,它将直流电源(DC)转换为交流电源(AC),为智能家居设备提供恒定的电力供应。在智能家居系统中&a…...
小红书运营教程02
小红书大致会分享10篇左右。微博、抖音、以及视频剪辑等自媒体运营相关技能以及运营教程相关会陆续的进行分享。 上次分享涉及到的对比,母婴系列,或者可以说是服装类型,不需要自己过多的投入,对比知识类博主来说,自己将知识讲述出来,然后要以此账号进行变现就比较麻烦,…...

k8s自动清理节点服务
要在 Kubernetes 中实现当某个节点的 CPU 或内存使用超过 90% 时清理该节点上的服务,你可以使用以下几种方法: 自定义脚本和 cron job:编写一个脚本监控节点的资源使用情况,并在超过阈值时触发清理操作。使用 DaemonSet 运行监控…...

JS如何把年月日转为时间戳
在JavaScript中,将年月日(通常表示为一个字符串或者分别的年、月、日数字)转换为时间戳(即Unix时间戳,是自1970年1月1日(UTC/GMT的午夜)开始所经过的秒数,不考虑闰秒)可以…...
【YOLOv5进阶】——引入注意力机制-以SE为例
声明:笔记是做项目时根据B站博主视频学习时自己编写,请勿随意转载! 一、站在巨人的肩膀上 SE模块即Squeeze-and-Excitation 模块,这是一种常用于卷积神经网络中的注意力机制!! 借鉴代码的代码链接如下&a…...
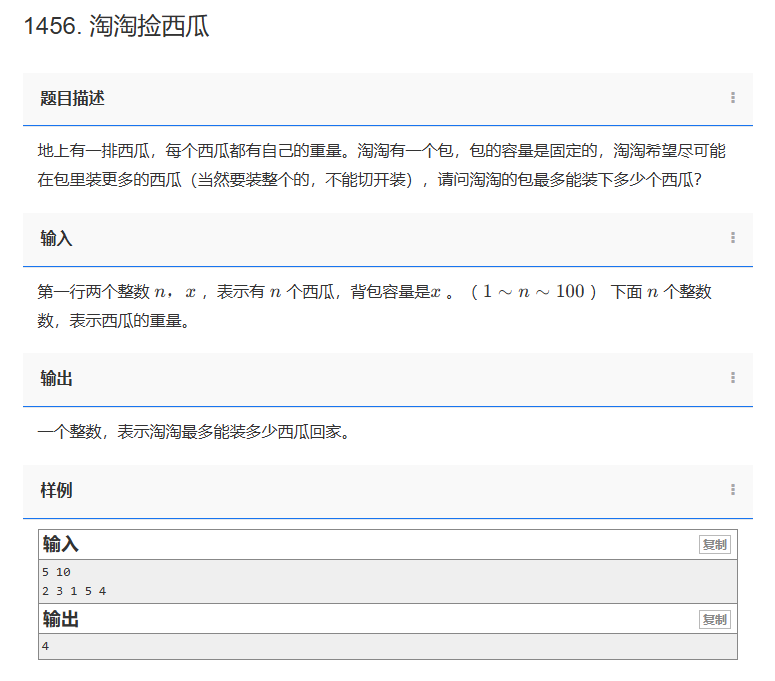
【C++题解】1456. 淘淘捡西瓜
问题:1456. 淘淘捡西瓜 类型:贪心 题目描述: 地上有一排西瓜,每个西瓜都有自己的重量。淘淘有一个包,包的容量是固定的,淘淘希望尽可能在包里装更多的西瓜(当然要装整个的,不能切开…...

用Python读取Word文件并提取标题
前言 在日常工作中,我们经常需要处理Word文档,特别是从中提取关键信息,如标题、段落等。今天,我们将利用Python来实现这一功能,并为大家提供一段完整的代码示例。 准备工作 首先,你需要安装python-docx库…...
Windows编程上
Windows编程[上] 一、Windows API1.控制台大小设置1.1 GetStdHandle1.2 SetConsoleWindowInfo1.3 SetConsoleScreenBufferSize1.4 SetConsoleTitle1.5 封装为Innks 2.控制台字体设置以及光标调整2.1 GetConsoleCursorInfo2.2 SetConsoleCursorPosition2.3 GetCurrentConsoleFon…...

BiTCN-Attention一键实现回归预测+8张图+特征可视化图!注意力全家桶再更新!
声明:文章是从本人公众号中复制而来,因此,想最新最快了解各类智能优化算法及其改进的朋友,可关注我的公众号:强盛机器学习,不定期会有很多免费代码分享~ 目录 原理简介 数据介绍 结果展示 全家桶代码目…...
)
zoom缩放问题(关于ElementPlus、Echarts、Vue3draggable等组件偏移问题)
做了一个项目下来,由于整体界面偏大,采取了缩放90%,导致很多组件出现偏移问题,以下我会把我遇到的各种组件偏移问题依次进行描述解答: ElementPlus选择器下拉偏移 <template><el-select :teleported"f…...
)
【独家首发】Midjourney针孔相机风格参数白皮书:基于1,842张生成图像的光学畸变量化分析(含f/1.4–f/16等效光圈映射表)
更多请点击: https://intelliparadigm.com 第一章:Midjourney针孔相机风格的光学本质与范式演进 光学原理的数字复现 针孔成像(Pinhole Camera)的本质在于无透镜、小孔衍射与直线传播的几何约束。Midjourney 通过扩散模型隐式建…...

G-Helper终极教程:华硕笔记本轻量级性能控制神器
G-Helper终极教程:华硕笔记本轻量级性能控制神器 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenbook, Expertb…...

电解电容核心参数解析:从ESR、纹波电流到选型实战
1. 项目概述:从“黑疙瘩”到电路心脏在电子工程师的物料盒里,电解电容绝对是个让人又爱又恨的家伙。它不像电阻那样温顺稳定,也不像芯片那样精密复杂,它就是个黑乎乎的圆柱体,或者扁平的方块,上面印着一些让…...
)
Word分栏排版进阶:如何实现左右栏独立编辑与中英文对照排版(解决内容错乱问题)
Word分栏排版进阶:左右栏独立编辑与中英文对照排版实战指南 在专业文档制作中,双语对照排版是教师、翻译人员和外语学习者经常遇到的挑战。传统分栏功能虽然简单易用,但当我们需要左边显示英文原文、右边显示对应中文翻译时,直接分…...

基于Codebender在线IDE快速开发Adafruit FLORA可穿戴硬件项目
1. 项目概述:为什么选择在线IDE来玩转可穿戴硬件?如果你和我一样,是个喜欢鼓捣硬件的创客,那么对Arduino、树莓派这类开发板一定不陌生。每次开始一个新项目,最头疼的往往不是写代码,而是配环境:…...

ElevenLabs情绪模拟技术落地倒计时:欧盟AI法案生效前最后72小时,必须完成的5项情感输出审计项
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs情绪模拟技术落地倒计时:欧盟AI法案生效前最后72小时,必须完成的5项情感输出审计项 情绪向量合规性校验 欧盟《AI法案》附件III明确将“高风险情感交互系统”纳入严格…...
)
ElevenLabs乌尔都文TTS接入全链路解析:从API密钥配置到自然停顿优化(含3个未公开参数)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs乌尔都文TTS接入全链路解析:从API密钥配置到自然停顿优化(含3个未公开参数) ElevenLabs 官方虽未在文档中明确标注乌尔都语(ur-PK)…...

开源AI中间人代理工具深度解析:从MITM原理到AI API调试实践
1. 项目概述:一个开源中间人代理工具的深度解析最近在开源社区里,一个名为nsampre/openclaw-anthropic-mitm的项目引起了我的注意。光看这个标题,可能很多朋友会有点懵,这串字符组合到底意味着什么?简单来说࿰…...

Seraphine终极指南:免费开源英雄联盟智能助手完整教程
Seraphine终极指南:免费开源英雄联盟智能助手完整教程 【免费下载链接】Seraphine 英雄联盟战绩查询工具 项目地址: https://gitcode.com/gh_mirrors/se/Seraphine 在英雄联盟的激烈对局中,你是否曾因错过对局接受而懊恼?是否在BP阶段…...

手把手教你模拟登录淘宝并爬取订单数据:从Cookie维护到反爬突破的完全指南
目录 一、技术选型:为什么最终选择了Playwright? 1.1 那些年被抛弃的方案 1.2 Playwright的优势 1.3 完整的依赖清单 二、登录流程的完整实现 2.1 两种登录方案的权衡 2.2 扫码登录的完整代码 2.3 Cookie持久化机制详解 三、订单列表爬取的两种思路 3.1 方式一:页…...