大数据开发语言 Scala(四):面向对象编程
目录
1. 概述
2. 面向对象编程的基本概念
2.1 类和对象
2.2 继承和多态
2.3 封装和访问控制
3. 面向对象编程在大数据开发中的应用
3.1 Spark中的面向对象编程
3.2 面向对象编程在数据清洗和预处理中
3.3 面向对象编程在机器学习中的应用
4. 面向对象编程的高级特性
4.1 抽象类和特质
4.2 高阶函数和闭包
5. 总结
在当今的数据驱动世界中,大数据技术变得越来越重要。为了处理海量数据,开发者需要掌握高效的编程语言和工具。Scala作为一种强大的多范式编程语言,因其在大数据开发中的表现而备受瞩目。本文将深入探讨Scala中的面向对象编程,揭示其在大数据开发中的应用和优势。
1. 概述
Scala是“scalable language”的缩写,意为“可扩展的语言”,它结合了面向对象编程(OOP)和函数式编程的特性。这使得Scala不仅适用于小型脚本和应用程序,同时也能胜任复杂的大数据处理任务。在Scala中,面向对象编程占有重要地位,它通过类和对象的设计来实现代码的模块化和重用性,从而提高开发效率和代码质量。
2. 面向对象编程的基本概念
2.1 类和对象
在面向对象编程中,类是对象的蓝图。类定义了对象的属性和行为,而对象是类的实例。在Scala中,定义一个类非常简单:
class Person(var name: String, var age: Int) {def greet(): Unit = {println(s"Hello, my name is $name and I am $age years old.")}
}
上述代码定义了一个名为Person的类,包含两个属性name和age,以及一个方法greet。
对象是类的实例,可以这样创建:
val person = new Person("Alice", 30)
person.greet() // 输出:Hello, my name is Alice and I am 30 years old.
2.2 继承和多态
继承是面向对象编程中的重要概念,它允许一个类继承另一个类的属性和方法,从而实现代码的重用。多态性则允许不同的类以统一的方式使用,这增强了代码的灵活性和可扩展性。
class Employee(name: String, age: Int, var salary: Double) extends Person(name, age) {def work(): Unit = {println(s"$name is working.")}
}val employee = new Employee("Bob", 25, 50000)
employee.greet() // 输出:Hello, my name is Bob and I am 25 years old.
employee.work() // 输出:Bob is working.
在上述代码中,Employee类继承了Person类,并增加了一个新属性salary和一个新方法work。
2.3 封装和访问控制
封装是指将对象的状态和行为隐藏起来,只通过公开的方法访问,从而保护对象的完整性。在Scala中,可以使用private关键字来实现封装:
class Account(private var balance: Double) {def deposit(amount: Double): Unit = {if (amount > 0) balance += amount}def withdraw(amount: Double): Unit = {if (amount > 0 && amount <= balance) balance -= amount}def getBalance: Double = balance
}val account = new Account(1000)
account.deposit(500)
account.withdraw(200)
println(account.getBalance) // 输出:1300
上述代码中的balance属性是私有的,只能通过deposit、withdraw和getBalance方法访问。
3. 面向对象编程在大数据开发中的应用
3.1 Spark中的面向对象编程
Apache Spark是一个流行的大数据处理框架,它利用Scala作为主要编程语言。在Spark中,面向对象编程的概念被广泛应用。例如,Spark的核心抽象RDD(Resilient Distributed Dataset)就是一个类,通过它,开发者可以使用丰富的操作来处理分布式数据。
val conf = new SparkConf().setAppName("Simple Application").setMaster("local")
val sc = new SparkContext(conf)
val data = Array(1, 2, 3, 4, 5)
val distData = sc.parallelize(data)
val result = distData.map(_ * 2).collect()
println(result.mkString(", ")) // 输出:2, 4, 6, 8, 10
在上述代码中,SparkContext是Spark的核心类,用于初始化Spark应用程序。parallelize方法将一个普通集合转换为RDD,而map方法则是对RDD进行操作的一种方式。
3.2 面向对象编程在数据清洗和预处理中
大数据开发中,数据清洗和预处理是至关重要的步骤。面向对象编程可以帮助开发者构建模块化、可重用的代码,从而提高数据处理的效率。例如,可以定义一个数据清洗类,将常用的数据清洗操作封装起来:
class DataCleaner {def removeNulls(data: Array[String]): Array[String] = {data.filter(_ != null)}def trimWhitespace(data: Array[String]): Array[String] = {data.map(_.trim)}
}val cleaner = new DataCleaner()
val rawData = Array(" data1 ", null, "data2 ", " data3")
val cleanedData = cleaner.trimWhitespace(cleaner.removeNulls(rawData))
println(cleanedData.mkString(", ")) // 输出:data1, data2, data3
3.3 面向对象编程在机器学习中的应用
在机器学习领域,面向对象编程也发挥着重要作用。Scala结合Spark MLlib提供了强大的机器学习库,开发者可以利用面向对象编程构建机器学习管道。例如,定义一个简单的线性回归模型类:
import org.apache.spark.ml.regression.LinearRegressionclass LinearRegressionModel {def train(data: DataFrame): LinearRegressionModel = {val lr = new LinearRegression().setMaxIter(10).setRegParam(0.3).setElasticNetParam(0.8)val lrModel = lr.fit(data)lrModel}def predict(model: LinearRegressionModel, data: DataFrame): DataFrame = {val predictions = model.transform(data)predictions}
}val lrModel = new LinearRegressionModel()
val trainedModel = lrModel.train(trainingData)
val predictions = lrModel.predict(trainedModel, testData)
4. 面向对象编程的高级特性
4.1 抽象类和特质
Scala中,抽象类和特质(Traits)是实现代码重用和多态性的高级工具。抽象类不能被实例化,只能被继承;而特质则是类似接口的结构,可以被多个类混入。
abstract class Animal {def makeSound(): Unit
}trait Flyable {def fly(): Unit = {println("I can fly!")}
}class Bird extends Animal with Flyable {def makeSound(): Unit = {println("Tweet tweet")}
}val bird = new Bird()
bird.makeSound() // 输出:Tweet tweet
bird.fly() // 输出:I can fly!
4.2 高阶函数和闭包
Scala结合了函数式编程的特性,高阶函数和闭包是其中的重要组成部分。高阶函数是指可以接受函数作为参数或返回函数的函数,而闭包是指函数可以捕获其外部作用域的变量。
def applyFunction(f: Int => Int, x: Int): Int = f(x)
val increment = (x: Int) => x + 1
println(applyFunction(increment, 5)) // 输出:6def createMultiplier(factor: Int): Int => Int = {(x: Int) => x * factor
}
val multiplyByTwo = createMultiplier(2)
println(multiplyByTwo(3)) // 输出:6
5. 总结
Scala中的面向对象编程为大数据开发提供了强大的工具和灵活的编程范式。通过类和对象的设计,开发者可以实现代码的模块化和重用性;通过继承和多态,增强代码的灵活性和可扩展性;通过封装和访问控制,保护对象的完整性和安全性。此外,Scala结合函数式编程的特性,使得大数据处理更加高效和简洁。
在实际应用中,面向对象编程广泛应用于Spark等大数据框架中,帮助开发者高效地处理和分析海量数据。通过面向对象编程,开发者可以构建模块化、可重用和可扩展的代码,提高开发效率和代码质量,从而应对复杂的大数据处理任务。
Scala作为大数据开发的重要语言,其面向对象编程特性为开发者提供了强大的工具和灵活的编程范式。掌握Scala中的面向对象编程,将为大数据开发带来更多可能性和机会。
相关文章:
:面向对象编程)
大数据开发语言 Scala(四):面向对象编程
目录 1. 概述 2. 面向对象编程的基本概念 2.1 类和对象 2.2 继承和多态 2.3 封装和访问控制 3. 面向对象编程在大数据开发中的应用 3.1 Spark中的面向对象编程 3.2 面向对象编程在数据清洗和预处理中 3.3 面向对象编程在机器学习中的应用 4. 面向对象编程的高级特性 …...

C++ //练习 14.31 我们的StrBlobPtr类没有定义拷贝构造函数、赋值运算符及析构函数,为什么?
C Primer(第5版) 练习 14.31 练习 14.31 我们的StrBlobPtr类没有定义拷贝构造函数、赋值运算符及析构函数,为什么? 环境:Linux Ubuntu(云服务器) 工具:vim 解释: 因为…...

通配符和正则表达式之间的关系
通配符和正则表达式(正则)都是用于匹配字符串的工具,但它们的复杂性和用途有所不同。下面是它们之间的主要关系和区别: 通配符 通配符主要用于简单的模式匹配,常见于文件系统操作中,例如在命令行中查找文…...

GY-30光照传感器软件I2C方式驱动代码,基于STM32Cube
GY-30光照传感器的具体资料可以去淘宝搜索然后问卖家要,网上也有,所以这里我就不多嘴了。 VCC连接3到5伏电压,根据文件开头的描述在STM32CubeMX中配置好外设。 STM32Cube开发方式就是4个字“简单直接”,直接上代码。 gy30.h #…...

双相元编程:一种新语言设计方法
本文讨论了编程语言的一种趋势,即允许相同的语法表达 在两个不同阶段或环境(上下文)中执行的计算同时保持跨阶段(上下文)的一致行为。这些阶段通常在时间上(运行时间)或空间上(运行…...

基于SpringBoot校园外卖配送系统设计和实现(源码+LW+调试文档+讲解等)
💗博主介绍:✌全网粉丝10W,CSDN作者、博客专家、全栈领域优质创作者,博客之星、平台优质作者、专注于Java、小程序技术领域和毕业项目实战✌💗 🌟文末获取源码数据库🌟 感兴趣的可以先收藏起来,…...
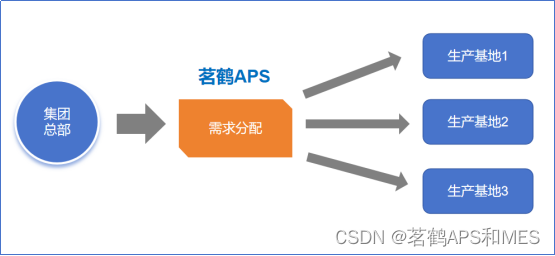
茗鹤APS高级计划排程系统,在集团多工厂协同生产下的应用
随着业务规模的扩大和市场的全球化,越来越多的企业选择“总部多工厂基地”的模式,此种模式大幅提升企业的产能与产量,有效分散风险。然后,与之而来的是对企业的管理提出更高的管理要求。多个生产基地不仅面临集团下发的周期性计划…...
分享六款免费u盘数据恢复工具,U盘恢复工具集合【工具篇】
U盘里面的数据丢失了怎么找回?随着数字化时代的深入发展,U盘已成为我们日常生活中不可或缺的数据存储工具。然而,由于各种原因,如误删除、格式化、病毒攻击等,U盘中的数据可能会丢失,给用户带来极大的困扰。…...
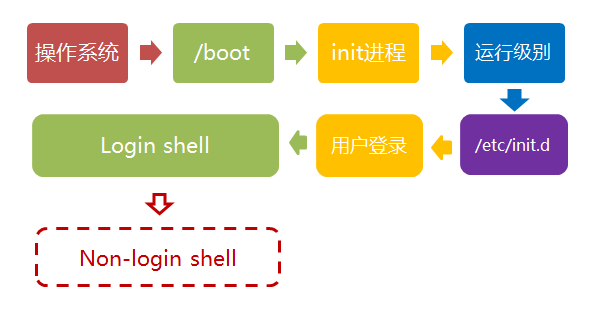
Linux 的启动流程
第一步、加载内核 操作系统接管硬件以后,首先读入 /boot 目录下的内核文件。 以我的电脑为例,/boot 目录下面大概是这样一些文件: $ ls /bootconfig-3.2.0-3-amd64config-3.2.0-4-amd64grubinitrd.img-3.2.0-3-amd64initrd.img-3.2.0-4-amd6…...
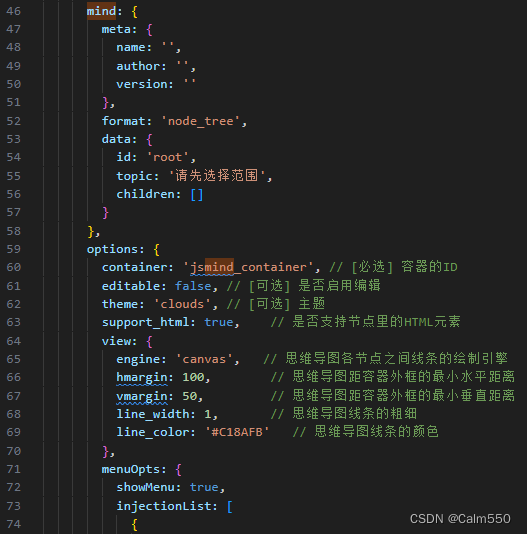
思维导图插件--jsMind的使用
vue引入jsmind(右键菜单)_jsmind.menu.js-CSDN博客 第一版 vue-JsMind思维导图实现(包含鼠标右键自定义菜单)_jsmind 右键菜单-CSDN博客 // 新增节点addNode() {console.log(this.get_selected_nodeid());this.get_selected_…...
mac上使用finder时候,显示隐藏的文件或者文件夹
默认在finder中是不显示隐藏的文件和文件夹的,但是想创建.gitignore文件,并向里面写入内容,即便是打开xcode也是不显示这几个隐藏文件的,那有什么办法呢? 使用快捷键: 使用finder打开包含隐藏文件的文件夹…...

泰雷茲具有首个通过FIPS 140-3 三级认证的HSMs
泰雷兹LunaHsm是业界首款通过FIPS140-33级认证的解决方案,安策引进泰雷兹HSM产品可以帮助您满足您的数据安全合规性需求,阻力企业提高竞争力。 安策提供泰雷茲ThalesLunaHSMs成为首个通过FIPS140-3三级认证的硬件安全模块图 我们很高兴地宣布,…...
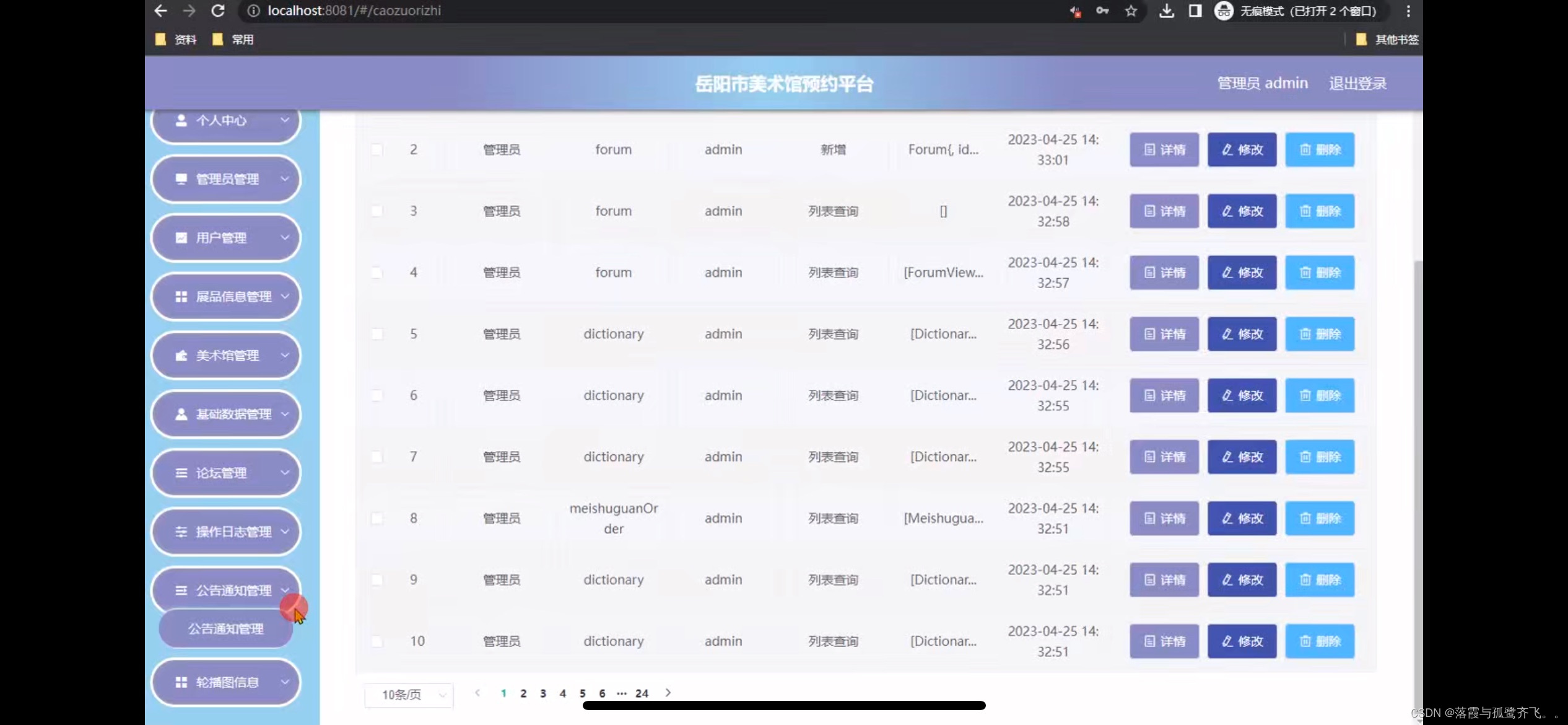
美术馆预约小程序的设计
管理员账户功能包括:系统首页,个人中心,展品信息管理,管理员管理,用户管理,美术馆管理,基础数据管理,论坛管理 微信端账号功能包括:系统首页,美术馆ÿ…...
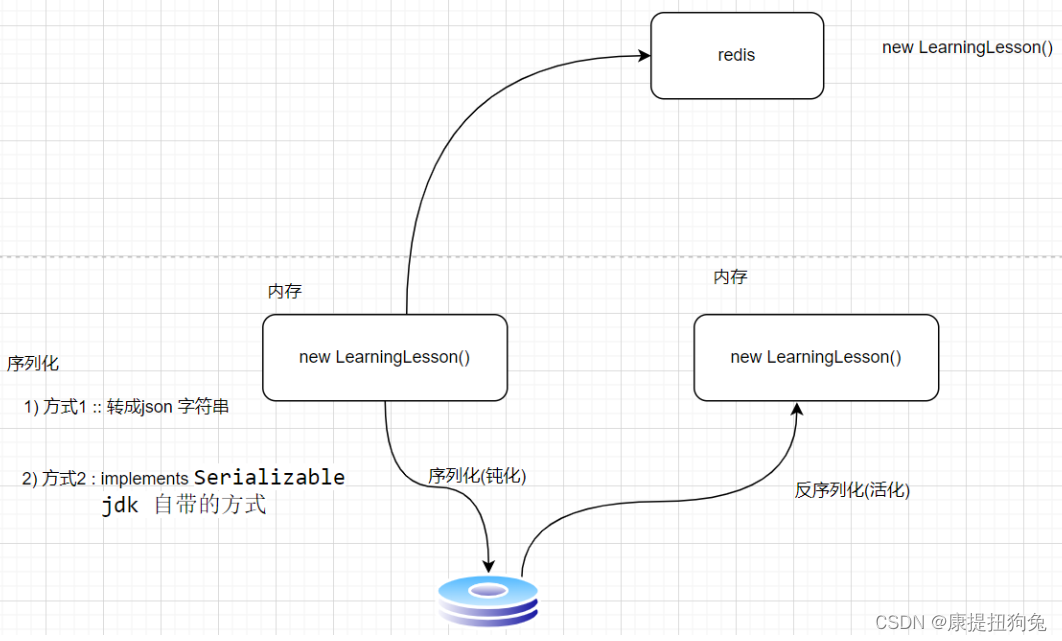
序列化Serializable
一、传输对象的方式 将对象从内存传输到磁盘进行保存,或者进行网络传输,有两种方式: 实现Serializable接口,直接传输对象转成json字符串后,进行字符串传输 二、直接传输对象 implements Serializable Data Equal…...

编写静态库
一、静态库 1.制作完成整体目录结构 2.首先创建mymath.c和mymath.h 3.编写Makefile 4.创建测试的main函数 test文件夹 先把lib移到test文件夹里面 4.编译链接 gcc main.c -I ./lib/include/ -L ./lib/mymathlib/ -l mymath 5.形成可执行程序a.out 要是不想执行第四步那么麻烦…...

hive的表操作
常用的hive命令 切换数据库use test;查询表的建表信息show create table 数据库名称.表名;查看表的类型信息desc formatted 数据库名称.表名; 删除内部表 drop table 数据库名称.表名; 先启动hdfs ,mysql , hiveservice2,beeline CREATE [EX…...
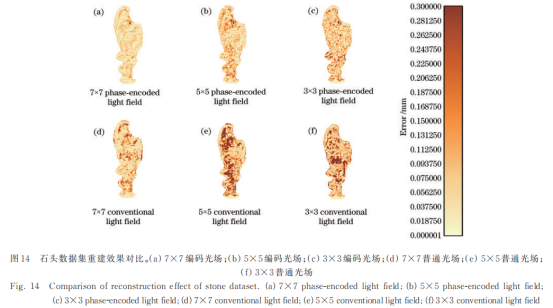
基于多视点编码光场的全景三维重建方法
欢迎关注GZH《光场视觉》 摘要:在基于光场的一系列应用中,目标的三维重建是基础且关键的任务。普通光场只能重建单一视角而无法重建全景,并且在纹理特征匮乏的区域也无法生成准确的三维信息。针对以上问题,提出一种基于多视点编码…...

Spring Boot中的分布式文件系统
Spring Boot中的分布式文件系统 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!今天,我们将探讨如何在Spring Boot中实现分布式文件系统的搭建和应用…...

three.js地理坐标系有哪些,和屏幕坐标系的转换。
坐标系很好理解,就是点线面体的位置,一个点是一个坐标,一条线段2个坐标,一个矩形四个坐标,一个立方体8个坐标,three.js面对的是三维空间,屏幕则是二维的,这就面临着转换问题…...

聊聊C++20的三向比较运算符 `<=>`
C20标准引入了许多新特性,其中之一是三向比较运算符 <>,也被称为太空船运算符。这个新运算符为C程序员提供了一种全新的比较对象的方式,它能有效简化比较逻辑,避免编写多个比较运算符重载的情况。 为什么需要三向比较运算符…...

嘎嘎降AI和率零哪个更适合毕业论文:2026年性价比达标率用户口碑完整横评测试报告
嘎嘎降AI和率零哪个更适合毕业论文:2026年性价比达标率用户口碑完整横评测试报告 帮几个不同专业的同学处理过论文AI率,用过的工具加起来也有六七款了。 综合看,嘎嘎降AI(www.aigcleaner.com)是最稳的选择࿰…...

深度神经网络参数安全与Hessian-aware训练防御技术
1. 深度神经网络参数安全威胁现状深度神经网络(DNN)在内存中的参数面临着严重的比特翻转安全威胁。这种威胁主要来自两个方面:自然发生的硬件故障和人为发起的攻击行为。在IEEE-754 32位浮点数表示中,一个比特的翻转可能导致参数值发生灾难性变化。例如&…...

Harness 中的请求标识染色:端到端追踪
1. 标题选项(核心关键词:Harness、请求标识染色、端到端追踪、可观测性、CI/CD) 「Harness 可观测性实战:请求标识染色实现全链路端到端追踪」 「从0到1搞定Harness请求染色:让微服务调用链路+变更链路无所遁形」 「告别排查黑洞:Harness请求标识染色的端到端追踪落地指南…...

ARM虚拟化中VTCR寄存器详解与地址转换优化
1. VTCR寄存器概述与虚拟化地址转换背景在ARM架构的虚拟化环境中,内存管理单元(MMU)通过两阶段地址转换机制实现虚拟机内存隔离。VTCR(Virtualization Translation Control Register)作为第二阶段地址转换的核心控制寄…...

基于RP2040 PIO与CircuitPython的IBM Model F键盘USB转接方案
1. 项目概述:让经典IBM键盘在现代电脑上重生如果你和我一样,对老式机械键盘那种扎实、清脆的“咔嗒”声和独特手感念念不忘,同时又对它们无法直接插在现代电脑上感到惋惜,那么这个项目就是为你准备的。我最近从朋友的一堆旧物里淘…...

深入GD32 CAN FD驱动层:从寄存器配置到ISO 15765协议栈的实战解析
深入GD32 CAN FD驱动层:从寄存器配置到ISO 15765协议栈的实战解析 在车载电子与工业控制领域,CAN FD协议正逐步取代传统CAN总线,成为高速数据传输的新标准。GD32系列MCU凭借其出色的性价比和丰富的外设资源,成为许多嵌入式开发者的…...

5分钟掌握英雄联盟国服换肤:R3nzSkin完整解决方案
5分钟掌握英雄联盟国服换肤:R3nzSkin完整解决方案 【免费下载链接】R3nzSkin-For-China-Server Skin changer for League of Legends (LOL) 项目地址: https://gitcode.com/gh_mirrors/r3/R3nzSkin-For-China-Server 你是否曾在游戏中羡慕别人的稀有皮肤&…...

C++ 约束模板参数Concepts详解
一、Concepts的概念与用法1、概念是什么C Concepts 是 C20 引入的一套“模板参数约束机制”。它的核心作用是:明确描述模板参数必须满足什么能力让模板报错更早、更清晰让重载选择更符合直觉替代很多过去用 SFINAE、enable_if、检测惯用法硬凑出来的写法一句话理解&…...

Cursor Free VIP:解锁AI编程助手完整功能的技术解决方案
Cursor Free VIP:解锁AI编程助手完整功能的技术解决方案 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your t…...

探索OpenBoardView:硬件工程师的PCB分析利器
探索OpenBoardView:硬件工程师的PCB分析利器 【免费下载链接】OpenBoardView View .brd files 项目地址: https://gitcode.com/gh_mirrors/op/OpenBoardView 在现代电子硬件开发与维修领域,面对复杂的电路板设计文件,工程师们常常需要…...