不同系统间数据交换要通过 api 不能直接数据库访问

很多大数据开发提供数据给外部系统直接给表结构,这是不好的方式。在不同系统间进行数据交换时,通过API(应用程序编程接口)而非直接访问数据库是现代系统集成的一种最佳实践。
目录
- 为什么要通过API进行数据交换
- 如何通过API进行数据交换
- 实现步骤
- 使用Flask构建RESTful API
- 安装Flask
- API代码示例
- 启动API服务器
- 使用Spring Boot构建RESTful API
- 创建Spring Boot项目并添加依赖
- 创建API控制器
- 创建数据实体和仓库
- 启动Spring Boot应用
- 将大数据平台的数据提供给外部系统
- 使用PySpark读取数据
- 将PySpark数据集成到Flask API
- 总结
为什么要通过API进行数据交换

-
安全性:
- 控制访问:API可以通过认证和授权机制来控制谁可以访问数据。
- 隔离系统:通过API访问数据可以隔离不同系统,减少一个系统的漏洞或故障对其他系统的影响。
-
数据一致性:
- 统一接口:API提供了统一的数据访问接口,可以确保数据的一致性和完整性。
- 减少重复:通过API避免了在多个地方实现相同的数据逻辑,从而减少了重复代码和潜在的错误。

-
维护性和扩展性:
- 模块化设计:API使得系统更加模块化,便于维护和扩展。
- 易于升级:通过API可以更容易地进行系统的升级和更新,而不影响其他系统。

-
日志和监控:
- 跟踪访问记录:API可以记录所有的请求和响应,便于监控和审计。
- 性能监控:通过API可以更容易地监控系统性能,发现和解决瓶颈问题。

如何通过API进行数据交换
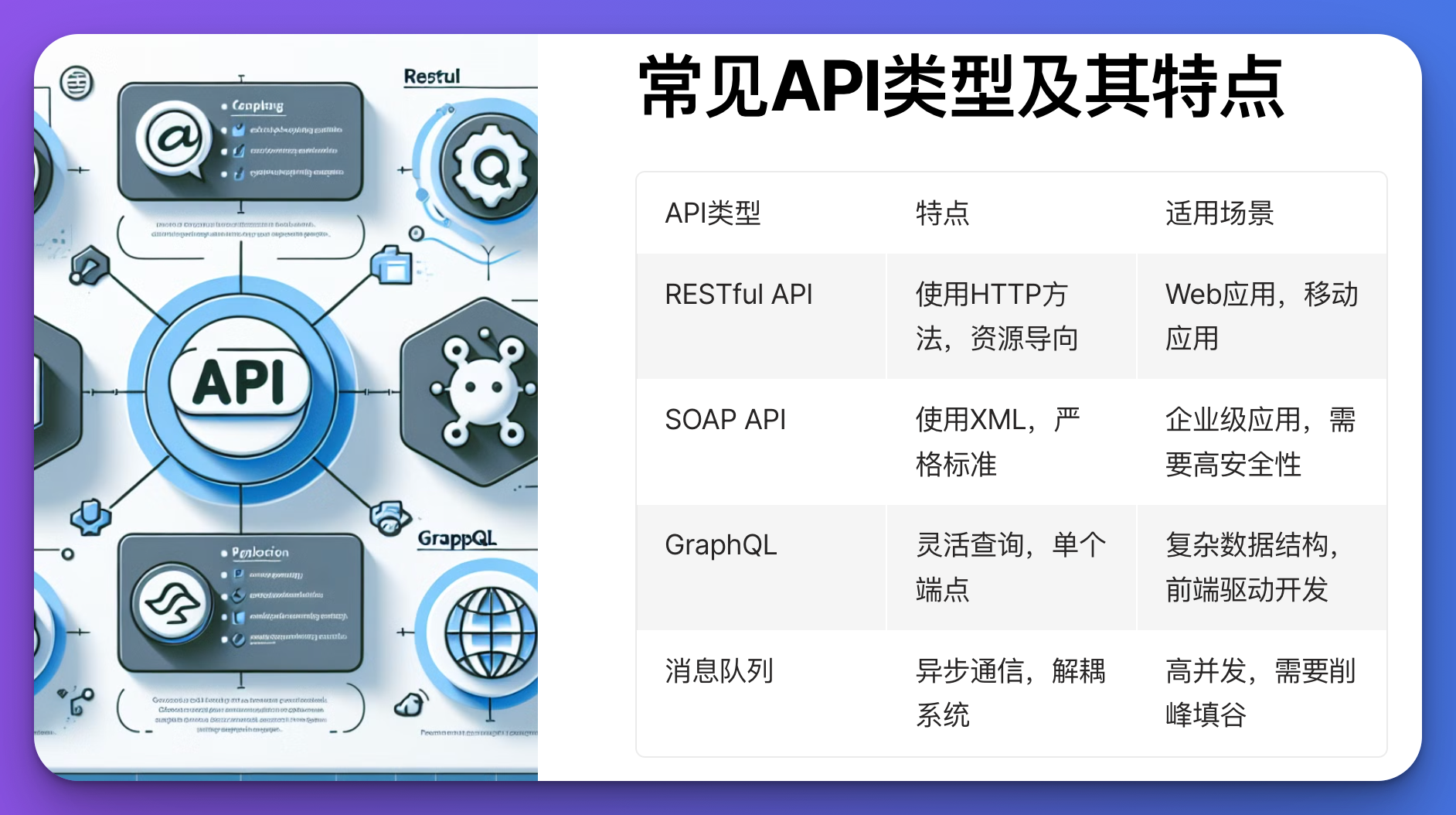
-
RESTful API:
- 定义资源:每个API端点代表一个资源,如用户、订单等。
- 使用HTTP方法:GET、POST、PUT、DELETE等方法对应于读取、创建、更新、删除操作。
-
SOAP API:
- 使用XML:SOAP(简单对象访问协议)使用XML格式来定义消息结构。
- 更严格的标准:SOAP提供了更严格的协议和标准,适用于需要高安全性和事务处理的场景。
-
GraphQL:
- 灵活查询:允许客户端指定需要的数据结构,减少数据传输量。
- 单个端点:通过单个端点提供数据查询和操作,简化接口管理。
-
消息队列:
- 异步通信:使用消息队列(如RabbitMQ、Kafka)可以实现系统间的异步数据传输。
- 解耦系统:通过消息队列可以解耦生产者和消费者,提升系统的扩展性和可靠性。
实现步骤

-
需求分析:
- 确定需要交换的数据和操作,设计API接口和数据模型。
-
API设计:
- 选择合适的API风格(RESTful、SOAP、GraphQL等)。
- 定义API端点、请求方法、参数和响应格式。
-
安全机制:
- 实现认证(如OAuth、JWT)和授权机制。
- 确保数据传输的安全性(如HTTPS)。
-
开发和测试:
- 开发API,并进行单元测试和集成测试。
- 使用工具(如Postman、Swagger)进行测试和文档编写。
-
部署和监控:
- 部署API服务,并设置日志和监控系统。
- 定期检查和优化API性能和安全性。
通过API进行数据交换不仅提高了系统的安全性和维护性,还增强了系统的扩展能力和灵活性,是现代系统架构设计中的重要实践。

其实开发接口 也不难,以下是一些代码示例和步骤,展示如何使用不同技术栈实现API,并将大数据平台的数据提供给外部系统。
使用Flask构建RESTful API
安装Flask
pip install Flask
API代码示例
from flask import Flask, request, jsonify
import pandas as pd
import jsonapp = Flask(__name__)# 示例数据,实际情况中应从大数据平台读取数据
data = {'id': [1, 2, 3],'name': ['Alice', 'Bob', 'Charlie'],'score': [85, 90, 78]
}df = pd.DataFrame(data)@app.route('/api/data', methods=['GET'])
def get_data():result = df.to_dict(orient='records')return jsonify(result)@app.route('/api/data/<int:id>', methods=['GET'])
def get_data_by_id(id):result = df[df['id'] == id].to_dict(orient='records')if not result:return jsonify({'error': 'Data not found'}), 404return jsonify(result[0])@app.route('/api/data', methods=['POST'])
def add_data():new_data = request.jsondf.append(new_data, ignore_index=True)return jsonify({'message': 'Data added successfully'}), 201if __name__ == '__main__':app.run(debug=True)
启动API服务器
python app.py
使用Spring Boot构建RESTful API
创建Spring Boot项目并添加依赖
在pom.xml文件中添加以下依赖:
<dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-jpa</artifactId></dependency><dependency><groupId>com.h2database</groupId><artifactId>h2</artifactId><scope>runtime</scope></dependency>
</dependencies>
创建API控制器
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;import java.util.List;
import java.util.Optional;@RestController
@RequestMapping("/api/data")
public class DataController {@Autowiredprivate DataRepository dataRepository;@GetMappingpublic List<Data> getAllData() {return dataRepository.findAll();}@GetMapping("/{id}")public Data getDataById(@PathVariable Long id) {Optional<Data> data = dataRepository.findById(id);if (data.isPresent()) {return data.get();} else {throw new ResourceNotFoundException("Data not found with id " + id);}}@PostMappingpublic Data addData(@RequestBody Data data) {return dataRepository.save(data);}
}
创建数据实体和仓库
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;@Entity
public class Data {@Id@GeneratedValue(strategy = GenerationType.AUTO)private Long id;private String name;private int score;// getters and setters
}
import org.springframework.data.jpa.repository.JpaRepository;public interface DataRepository extends JpaRepository<Data, Long> {
}
启动Spring Boot应用
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;@SpringBootApplication
public class Application {public static void main(String[] args) {SpringApplication.run(Application.class, args);}
}
将大数据平台的数据提供给外部系统
假设数据存储在Hadoop HDFS中,我们可以使用PySpark读取数据并通过API提供给外部系统。
使用PySpark读取数据
from pyspark.sql import SparkSessionspark = SparkSession.builder \.appName("Data API") \.getOrCreate()# 读取HDFS中的数据
df = spark.read.csv("hdfs://path/to/data.csv", header=True, inferSchema=True)# 将数据转换为Pandas DataFrame以便使用Flask
pandas_df = df.toPandas()
将PySpark数据集成到Flask API
from flask import Flask, request, jsonify
import pandas as pd
import json
from pyspark.sql import SparkSessionapp = Flask(__name__)# 创建Spark会话
spark = SparkSession.builder \.appName("Data API") \.getOrCreate()# 读取HDFS中的数据
df = spark.read.csv("hdfs://path/to/data.csv", header=True, inferSchema=True)
pandas_df = df.toPandas()@app.route('/api/data', methods=['GET'])
def get_data():result = pandas_df.to_dict(orient='records')return jsonify(result)@app.route('/api/data/<int:id>', methods=['GET'])
def get_data_by_id(id):result = pandas_df[pandas_df['id'] == id].to_dict(orient='records')if not result:return jsonify({'error': 'Data not found'}), 404return jsonify(result[0])if __name__ == '__main__':app.run(debug=True)
总结

通过构建API,可以安全、有效地将大数据平台的数据提供给外部系统。无论是使用Flask还是Spring Boot,都可以实现RESTful API的构建。同时,结合大数据平台的读取能力(如Hadoop HDFS和PySpark),可以轻松实现数据的获取和提供。
相关文章:
不同系统间数据交换要通过 api 不能直接数据库访问
很多大数据开发提供数据给外部系统直接给表结构,这是不好的方式。在不同系统间进行数据交换时,通过API(应用程序编程接口)而非直接访问数据库是现代系统集成的一种最佳实践。 目录 为什么要通过API进行数据交换如何通过API进行数据…...
深度探索“目录名称无效“:原因、解决方案与最佳实践
目录名称无效:现象背后的秘密 在日常使用电脑或移动设备时,我们时常会遇到“目录名称无效”的错误提示,这一提示仿佛是一道无形的屏障,阻断了我们与重要数据的联系。从本质上讲,“目录名称无效”意味着系统无法识别或…...

open3d基础使用-简单易懂
Open3D是一个开源库,主要用于快速开发处理3D数据的软件。它提供了丰富的数据结构和算法,支持点云、网格和RGB-D图像等多种3D数据的处理。以下是对Open3D基础使用的详细归纳和说明: 一、安装Open3D Open3D可以通过Python的包管理器pip进行安…...

【前端】HTML+CSS复习记录【5】
文章目录 前言一、padding、margin、border(边框边距)二、样式优先级三、var(使用 CSS 变量更改多个元素样式)四、media quary(媒体查询)系列文章目录 前言 长时间未使用HTML编程,前端知识感觉…...

三分钟看懂SMD封装与COB封装的差异
全彩LED显示屏领域中,COB封装于SMD封装是比较常见的两种封装方式,SMD封装产品主要有常规小间距以及室内、户外型产品,COB封装产品主要集中在小间距以及微间距系列产品中,今天跟随COB显示屏厂家中品瑞一起快速看懂SMD封装与COB封装…...
深入理解策略梯度算法
策略梯度(Policy Gradient)算法是强化学习中的一种重要方法,通过优化策略以获得最大回报。本文将详细介绍策略梯度算法的基本原理,推导其数学公式,并提供具体的例子来指导其实现。 策略梯度算法的基本概念 在强化学习…...

Unicode 和 UTF-8 以及它们之间的关系
通俗易懂的 Unicode 和 UTF-8 解释 Unicode 是什么? 想象一下,我们有一个巨大的图书馆,这个图书馆里有各种各样的书,每本书都有一个唯一的编号。Unicode 就像是这个图书馆的目录系统,它给世界上所有的字符࿰…...

【C++】多态详解
💗个人主页💗 ⭐个人专栏——C学习⭐ 💫点击关注🤩一起学习C语言💯💫 目录 一、多态概念 二、多态的定义及实现 1. 多态的构成条件 2. 虚函数 2.1 什么是虚函数 2.2 虚函数的重写 2.3 虚函数重写的两个…...

C#异常捕获
前言 在C#中,我们无法保证我们编写的程序没有一点bug,如果我们对于这些抛出异常的bug不进行任何的处理的话,那么我们的软件在抛出这些异常的时候就会崩溃,也就是软件闪退,并且这种闪退由于我们没有进行处理࿰…...

工业一体机根据软件应用需求灵活选配
在当今工业领域,数字化、智能化的发展趋势愈发明显,工业一体机作为关键的设备,其重要性日益凸显。而能够根据软件应用需求进行灵活选配的工业一体机,更是为企业提供了高效、定制化的解决方案。 一、工业一体机的全封闭无风扇散热功…...
centos7 mqtt服务mosquitto搭建记录
1、系统centos7.6,安装默认版本 yum install mosquitto 2、启动运行 systemctl start mosquitto 3、设置自启动 systemctl enable mosquitto 4、修改配置文件 vim /etc/mosquitto/mosquitto.conf 监听端口,默认为1883,需要修改删除前面…...

双阶段目标检测算法:精确与效率的博弈
双阶段目标检测算法:精确与效率的博弈 目标检测是计算机视觉领域的一个核心任务,它涉及在图像或视频中识别和定位多个对象。双阶段目标检测算法是一种特殊的目标检测方法,它通过两个阶段来提高检测的准确性。本文将详细介绍双阶段目标检测算…...

Python量化交易策略
策略详情 按照1分k线图;跳过9:30点1分k线图不计算 买入;监控市面的可转债;当某1分涨幅大于x涨幅,一直重复x次,选择买入,符合x设置的条件只选择成交额最大的可转债买入(x要自定义&…...
为什么我感觉 C 语言在 Linux 下执行效率比 Windows 快得多?
在开始前刚好我有一些资料,是我根据网友给的问题精心整理了一份「Linux的资料从专业入门到高级教程」, 点个关注在评论区回复“888”之后私信回复“888”,全部无偿共享给大家!!!Windows的终端或者叫控制台…...

算法导论 总结索引 | 第四部分 第十六章:贪心算法
1、求解最优化问题的算法 通常需要经过一系列的步骤,在每个步骤都面临多种选择。对于许多最优化问题,使用动态规划算法求最优解有些杀鸡用牛刀了,可以使用更简单、更高效的算法 贪心算法(greedy algorithm)就是这样的算…...

用“文心一言”写的文章,看看AI写得怎么样?
零售连锁店的“支付结算”业务设计 在数字化浪潮的推动下,连锁店零售支付结算的设计愈发重要。一个优秀的支付结算设计不仅能够提升用户体验,还能增强品牌竞争力,进而促进销售增长。 本文将围绕一个具体的连锁店零售支付结算案例…...

企业消费采购成本和员工体验如何实现“鱼和熊掌“的兼得?
有企业说企业消费采购成本和员工体验的关系好比是“鱼和熊掌”,无法兼得? 要想控制好成本就一定要加强管控,但是加强管控以后,就会很难让员工获得满意的体验度。如果不加以管控,员工自由度增加了,往往就很难…...

发表EI论文相当于SCI几区?
EI(工程索引)本身并不进行分区,它是一个收录工程领域高质量文献的数据库,与SCI(科学引文索引)的分区制度不同。然而,在非正式的学术评价中,有时人们会将EI与SCI的分区进行比较。 虽…...

STFT短时傅里叶变换MTLAB简析
代码: 解释: 如果信号x有Nx个时间样本,短时傅里叶变换的结果矩阵s有k列; k的计算方式如图所示,M是窗函数的长度,L是重叠长度。 此符号是向下取整符号。 短时傅里叶变换的结果矩阵s的行数与参数‘FFTLength’…...

海致科技实施实习生面试
一、面试内容 注:此次是电话面试 1.是XX先生吗 2.你是有考虑转实施的吗? 3.请讲一下你对项目部署实施的理解和掌握 4.用过数据库,会编写SQL语句吗? 5.讲一下SQL的常用关键字 6.了解SQL中的函数吗?谈谈函数 7.多…...

Win10家庭版别再卡了!保姆级教程:手动修复gpedit.msc路径,彻底关闭Antimalware Service
Win10家庭版性能优化实战:精准修复组策略路径与系统服务调优每次游戏激战正酣时突然卡顿,或是视频渲染到关键时刻系统响应迟缓,很多Win10家庭版用户都遭遇过这类困扰。任务管理器里那个名为"Antimalware Service Executable"的进程…...

64_《智能体微服务架构企业级实战教程》授权与认证之授权认证集成测试
前言 配套视频教程: 在 Bilibili课堂、CSDN课程、51CTO学堂 同步发售,提供:源码+部署脚本+文档。 bilibili课堂视频教程:智能体微服务架构企业级实战教程_哔哩哔哩_bilibili CSDN课程视频教程:智能体微服务架构企业级实战教程_在线视频教程-CSDN程序员研修院 51CTO学堂…...

百考通智能任务书:贴合你的选题,拒绝空话假大空
毕业设计任务书是高校教学管理中的关键环节,它不仅标志着研究工作的正式启动,更是后续开题、实施、论文撰写和答辩全过程的行动依据。然而,许多学生在撰写时常常因不熟悉本专业写作规范、技术表达能力有限,或缺乏权威模板参考而陷…...

用STM32CubeMX和HAL库快速上手WS2812B:告别手动计算延时,一键生成驱动框架
基于STM32CubeMX的WS2812B智能灯光控制:从零构建现代化驱动方案在智能硬件和物联网设备快速发展的今天,WS2812B可编程LED灯带因其丰富的色彩表现和简单的单线控制方式,成为创客和工程师们最喜爱的显示组件之一。然而,传统的寄存器…...

利用DiSEqC协议与AVR单片机驱动卫星天线电机改造户外设备
1. 项目概述:用卫星天线电机驱动一切如果你手头有一些需要承受风吹日晒、还得精确转动的设备,比如一个户外的大型定向天线,或者一个需要定期调整角度的太阳能板支架,甚至是一个坚固的监控云台,你可能会为驱动机构发愁。…...

适合地产人用的中介房源管理系统
在房产经纪行业,房源管理与客源管理是经纪人日常工作的核心,直接影响业务效率与成交转化。选择一套适配行业需求的中介房源管理系统,能帮助中介团队规范流程、降低运营成本、大幅提升业绩。今天我们以客观视角,详细解析全房源系统…...

为什么视频代剪辑会影响你的内容传播效果
为什么你精心拍的视频,发出去却没人看? 你有没有过这样的经历:花了一整天拍Vlog,素材画质高清、内容真实,可一剪出来就显得平淡无奇,点赞寥寥?或者婚礼当天感动全场,回看成片却像流水…...

ARM架构CONSTRAINED UNPREDICTABLE行为解析与应对
1. ARM架构中的CONSTRAINED UNPREDICTABLE行为解析在处理器架构设计中,UNPREDICTABLE行为通常指架构规范未明确定义的执行结果,可能导致不可预期的系统状态。ARM架构通过引入CONSTRAINED UNPREDICTABLE机制,将这类行为限制在特定范围内&#…...

2026 西安 AI 问答曝光搭建技术解析:GEO 知识图谱 + 深度测评
随着大语言模型技术的快速普及,AI 搜索已经成为用户获取企业信息、商家服务的核心入口。根据中国互联网信息中心 2026 年发布的《中国人工智能搜索发展报告》显示,2025 年国内 AI 搜索用户规模突破 8.2 亿,日均搜索请求超过 20 亿次ÿ…...

HDI 高密度互连板阶数的深度理解
一、概述高密度互连板(High Density Interconnector, HDI)是通过激光微孔技术和逐层积层工艺实现高密度布线的印制电路板。其阶数划分是行业内统一的技术标准,核心依据为独立积层压合次数与配套激光盲孔制程次数,而非单面层数或钻…...