【机器学习】在【Pycharm】中的应用:【线性回归模型】进行【房价预测】


专栏:机器学习笔记
pycharm专业版免费激活教程见资源,私信我给你发
python相关库的安装:pandas,numpy,matplotlib,statsmodels
1. 引言
线性回归(Linear Regression)是一种常见的统计方法和机器学习算法,用于根据一个或多个特征变量(自变量)来预测目标变量(因变量)的值。在许多实际应用中,线性回归因其简单性和有效性而被广泛使用,例如预测房价、股票市场分析、市场营销和经济学等领域。
在这篇文章中,我们将详细介绍如何使用Pycharm这个集成开发环境(IDE)来进行线性回归建模。通过一个具体的房价预测案例,从数据导入、预处理、建模、评估到结果可视化的完整流程,一步步指导你如何实现和理解线性回归模型。无论你是数据科学新手还是有经验的程序员,希望通过本文,你能掌握使用Pycharm进行机器学习项目的基本方法和步骤。
2. 环境设置
在开始之前,确保你已经安装了Pycharm以及必要的Python库。接下来我们将介绍如何安装和设置这些工具和库。
2.1 安装Pycharm
Pycharm是由JetBrains公司开发的一款专业的Python集成开发环境(IDE),特别适合数据科学和机器学习项目。它提供了丰富的功能,如代码补全、调试、测试和版本控制等,使开发过程更加高效和便捷。
下载与安装:
- 访问Pycharm官网。
- 根据你的操作系统选择合适的版本下载。Pycharm有两个版本:社区版(Community)和专业版(Professional)。社区版是免费的,适合一般的Python开发需求;专业版则提供更多高级功能,适合数据科学和Web开发等高级应用。
- 下载完成后,按照安装向导进行安装。以Windows系统为例,下载后运行安装程序,按照默认设置一步步点击“下一步”(Next),直到完成安装。Mac和Linux系统的安装步骤也类似。
启动Pycharm:
- 安装完成后,启动Pycharm。在欢迎界面上,选择“Create New Project”以创建一个新的项目。你可以为你的项目选择一个合适的名称和存储位置。
- 在创建项目的过程中,Pycharm会提示你选择Python解释器。通常情况下,选择系统默认的Python解释器即可。如果你还没有安装Python,可以前往Python官网下载并安装。
2.2 安装必要的库
在Pycharm中安装库非常方便。你可以通过Pycharm的Terminal终端直接使用pip命令进行安装,也可以通过Pycharm的图形界面安装库。
1.使用Terminal安装库:
- 打开Pycharm,进入项目。
- 在Pycharm界面的底部找到Terminal选项并点击打开。
- 在Terminal中输入以下命令来安装所需的Python库:
pip install numpy pandas scikit-learn matplotlib
2.使用图形界面安装库:
- 打开Pycharm,进入项目。
- 在顶部菜单栏找到File选项并点击,选择Settings(或Preferences)。
- 在设置窗口左侧找到Project: 项目名称,点击展开,然后选择Python Interpreter。
- 在右侧窗口中,点击+号按钮,搜索并安装所需的库。
numpy:用于数值计算,提供支持多维数组对象。pandas:用于数据处理,特别是数据集的加载和预处理。scikit-learn:用于构建和评估机器学习模型。
这些库是进行数据科学和机器学习不可或缺的工具。
安装完成后,你可以在Pycharm的Terminal中输入以下命令,检查这些库是否安装成功:
python -c "import numpy, pandas, sklearn, matplotlib; print('All libraries are installed successfully')"
如果一切正常,你会看到相应的成功提示信息。
3. 数据准备
数据准备是机器学习项目中非常重要的一步。在这个例子中,我们将使用一个包含房价相关信息的数据集。首先,需要创建一个CSV文件并将其导入到Pycharm项目中。
3.1 创建CSV文件
你可以使用任何文本编辑器(如Notepad、Sublime Text、VS Code等)创建一个house_prices.csv文件,并将以下数据粘贴进去:
square_footage,number_of_bedrooms,price
1500,3,300000
1700,4,360000
1300,2,250000
2000,3,400000
1600,3,330000
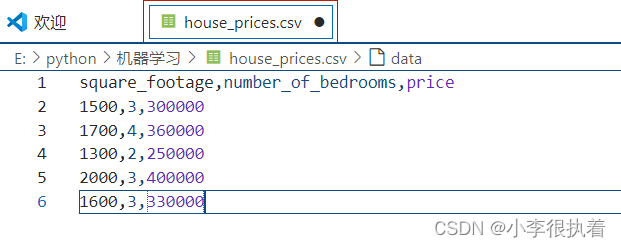
将该文件保存到Pycharm项目的根目录中。这些数据表示每个房产的面积(平方英尺)、卧室数量和价格(美元)。
3.2 加载数据
接下来,编写Python代码来加载并查看数据。确保你的文件路径正确且文件格式无误。
首先,在Pycharm中创建一个新的Python文件(例如,house_price_prediction.py),并编写以下代码:
import pandas as pd# 加载数据集
data = pd.read_csv('house_prices.csv')# 查看数据集的前几行
print(data.head())
这段代码使用Pandas库加载CSV文件中的数据并显示前几行。确保你的house_prices.csv文件路径正确。如果你将文件保存到Pycharm项目的根目录中,那么直接使用文件名即可。如果文件在其他路径中,你需要提供相对或绝对路径。
保存并运行这段代码,你应该会看到数据集的前几行输出:
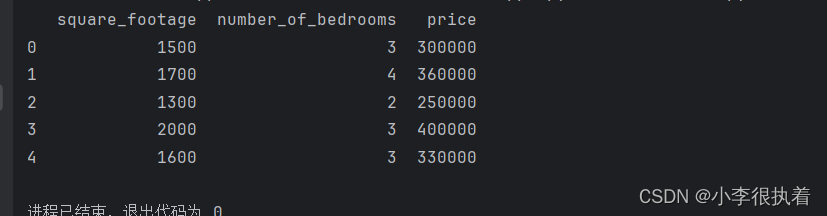
通过以上步骤,我们成功地将数据集加载到了Pandas DataFrame中,接下来可以对数据进行预处理。
4. 数据预处理
在构建机器学习模型之前,需要对数据进行预处理,以确保数据的质量和模型的性能。数据预处理包括检查缺失值、处理异常值、特征工程等步骤。
4.1 检查缺失值
首先,检查数据集中是否存在缺失值。缺失值会影响模型的性能,因此需要处理。
# 检查是否有缺失值
print(data.isnull().sum())
这段代码会输出每个列中缺失值的数量。如果输出结果为零,表示没有缺失值;否则,需要对缺失值进行处理。

如果存在缺失值,可以选择删除包含缺失值的行,或者用其他值进行填充(例如,平均值、中位数等)。
# 删除缺失值
data = data.dropna()# 或者用平均值填充缺失值
# data.fillna(data.mean(), inplace=True)
4.2 特征和标签分离
接下来,将数据集中的特征和标签分离。特征是用于预测的输入变量,而标签是我们希望预测的输出变量。在这个例子中,square_footage和number_of_bedrooms是特征,price是标签。
# 特征和标签分离
X = data[['square_footage', 'number_of_bedrooms']]
y = data['price']
X是一个包含特征的DataFrame,而y是一个包含标签的Series。
4.3 数据标准化
在有些情况下,对数据进行标准化处理可以提高模型的性能和收敛速度。标准化是将数据转换为均值为0、标准差为1的形式。
from sklearn.preprocessing import StandardScalerscaler = StandardScaler()
X = scaler.fit_transform(X)
这里我们使用了Scikit-Learn库中的StandardScaler类对特征进行标准化。首先,创建一个StandardScaler对象,然后使用fit_transform方法对特征进行标准化处理。
到此,我们完成了数据预处理的基本步骤,数据集已经准备好用于模型训练。
5. 构建和训练线性回归模型
在预处理完数据后,我们可以开始构建和训练线性回归模型。
5.1 划分训练集和测试集
为了评估模型的性能,我们需要将数据集划分为训练集和测试集。训练集用于训练模型,测试集用于评估模型的泛化能力。
from sklearn.model_selection import train_test_split# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
在这段代码中,我们将20%的数据作为测试集,其余80%的数据作为训练集。random_state参数用于保证结果的可重复性。通过这种划分方式,我们可以在保持数据整体分布一致的前提下,确保训练集和测试集具有相似的特性。
5.2 创建线性回归模型
使用Scikit-Learn库中的LinearRegression类来创建线性回归模型。
from sklearn.linear_model import LinearRegression# 创建线性回归模型
model = LinearRegression()
线性回归模型是一种线性方法,用于拟合线性关系。它假设特征与标签之间存在线性关系,即标签可以通过特征的线性组合来表示。
5.3 训练模型
将训练集的特征和标签传递给模型,进行训练。
# 训练模型
model.fit(X_train, y_train)
训练完成后,模型已经学到了特征和标签之间的关系,可以用来进行预测。
为了得到更准确的结果,我将扩展数据集至600个数据点
6. 评估模型
训练完成后,我们需要评估模型的性能。常用的评估指标包括均方误差(Mean Squared Error, MSE)和决定系数(R²)。
from sklearn.metrics import mean_squared_error, r2_score# 预测测试集
y_pred = model.predict(X_test)# 计算均方误差和R²
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)print(f"Mean Squared Error: {mse}")
print(f"R² Score: {r2}")

- 均方误差(MSE):度量预测值与真实值之间的平均平方误差,值越小越好。MSE的公式为:
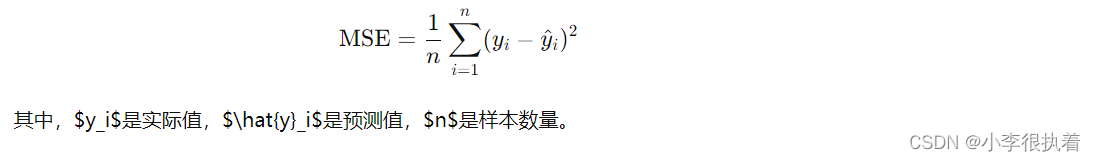
- 决定系数(R²):度量模型解释变量的比例,取值范围为0到1,值越接近1越好。R²的公式为:

7. 可视化结果
为了更直观地了解模型的表现,我们可以将预测值和真实值进行对比,使用Matplotlib库进行可视化。
import matplotlib.pyplot as plt# 绘制散点图
plt.scatter(y_test, y_pred)
plt.xlabel("Actual Prices")
plt.ylabel("Predicted Prices")
plt.title("Actual vs Predicted Prices")
plt.show()

散点图可以帮助我们观察模型的预测值与真实值之间的关系。如果模型表现良好,散点图中的点将接近对角线,说明预测值与实际值高度相关。
此外,我们还可以绘制残差图(Residual Plot)来进一步评估模型的性能。残差图是实际值与预测值之间差异的图表,有助于检测模型的误差模式和数据中可能存在的异常点。
# 绘制残差图
residuals = y_test - y_pred
plt.scatter(y_pred, residuals)
plt.xlabel("Predicted Prices")
plt.ylabel("Residuals")
plt.title("Residuals vs Predicted Prices")
plt.axhline(y=0, color='r', linestyle='--')
plt.show()
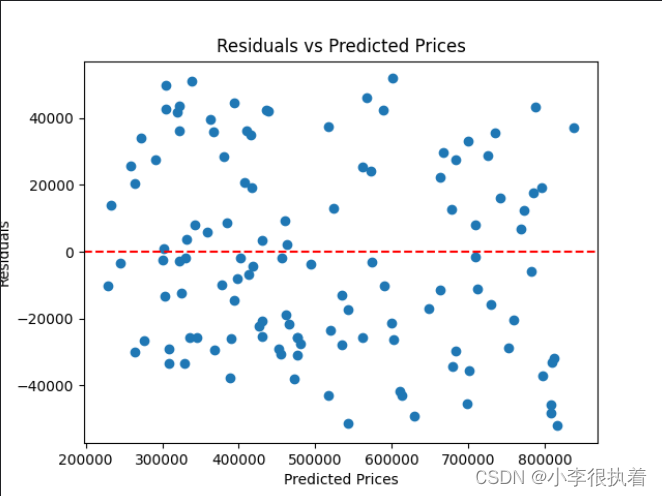
在残差图中,理想情况下,残差应随机分布且均匀分布在0轴的两侧。如果残差图中出现明显的模式或趋势,可能表明模型未能很好地捕捉数据中的关系,或者存在某些特征未被考虑在内。
8. 完整代码
以下是上述步骤的完整代码,整合在一起,方便复制和运行。
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler# 加载数据集
data = pd.read_csv('house_prices.csv')# 数据预处理
data = data.dropna()
X = data[['square_footage', 'number_of_bedrooms']]
y = data['price']# 数据标准化
scaler = StandardScaler()
X = scaler.fit_transform(X)# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建和训练模型
model = LinearRegression()
model.fit(X_train, y_train)# 评估模型
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)print(f"Mean Squared Error: {mse}")
print(f"R² Score: {r2}")# 可视化结果
plt.scatter(y_test, y_pred)
plt.xlabel("Actual Prices")
plt.ylabel("Predicted Prices")
plt.title("Actual vs Predicted Prices")
plt.show()# 绘制残差图
residuals = y_test - y_pred
plt.scatter(y_pred, residuals)
plt.xlabel("Predicted Prices")
plt.ylabel("Residuals")
plt.title("Residuals vs Predicted Prices")
plt.axhline(y=0, color='r', linestyle='--')
plt.show()
通过运行这段完整代码,你将能够加载数据、预处理数据、构建和训练线性回归模型、评估模型性能并进行结果可视化。这是一个完整的机器学习工作流,可以帮助你了解和掌握线性回归模型在实际项目中的应用。
9. 结论
在Pycharm中使用线性回归模型时,需要注意以下几点:
- 环境设置:确保安装正确版本的Pycharm和必要的Python库。
- 数据质量:确保数据集没有缺失值和异常值,且数据类型正确。
- 数据标准化:在训练模型之前对特征进行标准化处理。
- 数据集划分:合理划分训练集和测试集,确保模型的评估结果公正。
- 模型评估:使用适当的评估指标(如MSE和R²)评估模型性能,并确保预测值有效。
- 结果可视化:通过散点图和残差图直观展示模型的预测效果和误差分布。
通过遵循这些注意事项,你可以确保在Pycharm中顺利构建和应用线性回归模型进行房价预测。
本文详细介绍了如何在Pycharm中使用线性回归模型进行房价预测。从环境设置、数据导入与预处理、模型构建与训练,到结果评估与可视化,每一步都进行了详细的剖析和代码展示。通过这个案例,希望你能更好地理解线性回归的基本原理和实操步骤,并能够应用到其他类似的预测问题中。
线性回归是机器学习中的基础算法之一,尽管它简单,但在很多实际应用中依然非常有效。通过本文的学习,你不仅掌握了如何在Pycharm中实现线性回归,还提升了对数据科学项目的整体把握能力。如果你有任何问题或建议,欢迎在评论区留言讨论。

相关文章:
【机器学习】在【Pycharm】中的应用:【线性回归模型】进行【房价预测】
专栏:机器学习笔记 pycharm专业版免费激活教程见资源,私信我给你发 python相关库的安装:pandas,numpy,matplotlib,statsmodels 1. 引言 线性回归(Linear Regression)是一种常见的统计方法和机器学习算法&a…...
如何在 Linux 中后台运行进程?
一、后台进程 在后台运行进程是 Linux 系统中的常见要求。在后台运行进程允许您在进程独立运行时继续使用终端或执行其他命令。这对于长时间运行的任务或当您想要同时执行多个命令时特别有用。 在深入研究各种方法之前,让我们先了解一下什么是后台进程。在 Linux 中…...

软考-软件设计师
软考 软考科目 软考分为初级、中级、高级,初级含金量相对不够,高级考试有难度,所以大多数人都在考中级,中级也分很多科目,我考的是软件设计师(已经通过)。 合格标准 考试分为上午题和下午题…...
UOS系统中JavaFx笔锋功能
关于笔锋功能,网上找了很久,包括Java平台客户端,Android端,相关代码资料比较少,找了很多经过测试效果都差强人意,自己也搓不出来,在UOS平台上JavaFX也获取不到压力值,只能用速度的变…...
后端加前端Echarts画图示例全流程(折线图,饼图,柱状图)
本文将带领读者通过一个完整的Echarts画图示例项目,演示如何结合后端技术(使用Spring Boot框架)和前端技术(使用Vue.js或React框架)来实现数据可视化。我们将实现折线图、饼图和柱状图三种常见的数据展示方式ÿ…...
ValidateAntiForgeryToken、AntiForgeryToken 防止CSRF(跨网站请求伪造)
用途:防止CSRF(跨网站请求伪造)。 用法:在View->Form表单中: aspx:<%:Html.AntiForgeryToken()%> razor:Html.AntiForgeryToken() 在Controller->Action动作上:[ValidateAntiForge…...

《昇思25天学习打卡营第5天 | mindspore 网络构建 Cell 常见用法》
1. 背景: 使用 mindspore 学习神经网络,打卡第五天; 2. 训练的内容: 使用 mindspore 的 nn.Cell 构建常见的网络使用方法; 3. 常见的用法小节: 支持一系列常用的 nn 的操作 3.1 nn.Cell 网络构建&…...
SQLServer:从数据类型 varchar 转换为 numeric 时出错。
1.工作要求 计算某两个经纬度距离 2.遇到问题 从数据类型 varchar 转换为 numeric 时出错。 3.解决问题 项目版本较老,使用SQLServer 2012 计算距离需执行视图,如下: SET QUOTED_IDENTIFIER ON SET ANSI_NULLS ON GO ALTER view vi_ord…...

探索迁移学习:通过实例深入理解机器学习的强大方法
探索迁移学习:通过实例深入理解机器学习的强大方法 🍁1. 迁移学习的概念🍁2. 迁移学习的应用领域🍁2.1 计算机视觉🍁2.2 自然语言处理(NLP)🍁2.3 医学图像分析🍁2.4 语音…...
:trace)
【Linux】性能分析器 perf 详解(四):trace
上一篇:【Linux】性能分析器 perf 详解(三) 1、trace 1.1 简介 perf trace 类似于 strace 工具:用于对Linux系统性能分析和调试的工具。 原理是:基于 Linux 性能计数器(Performance Counters for Linux, PCL),监控和记录系统调用和其他系统事件。 可以提供关于硬件…...

信息安全体系架构设计
对信息系统的安全需求是任何单一安全技术都无法解决的,要设计一个信息安全体系架构,应当选择合适的安全体系结构模型。信息系统安全设计重点考虑两个方面;其一是系统安全保障体系;其二是信息安全体系架构。 1.系统安全保障体系 安…...

GPT-5即将登场:AI赋能下的未来工作与日常生活新图景
随着OpenAI首席技术官米拉穆拉蒂在近期采访中的明确表态,GPT-5的发布已不再是遥不可及的梦想,而是即将在一年半后与我们见面的现实。这一消息无疑在科技界乃至全社会引发了广泛关注和热烈讨论。从GPT-4到GPT-5的飞跃,被形容为从高中生到博士生…...
RocketMQ实战:一键在docker中搭建rocketmq和doshboard环境
在本篇博客中,我们将详细介绍如何在 Docker 环境中一键部署 RocketMQ 和其 Dashboard。这个过程基于一个预配置的 Docker Compose 文件,使得部署变得简单高效。 项目介绍 该项目提供了一套 Docker Compose 配置,用于快速部署 RocketMQ 及其…...
前端项目vue3/React使用pako库解压缩后端返回gzip数据
pako仓库地址:https://github.com/nodeca/pako 文档地址:pako 2.1.0 API documentation 外部接口返回一个直播消息或者图片数据是经过zip压缩的,前端需要把这个数据解压缩之后才可以使用,这样可以大大降低网络数据传输的内容&…...

C++专业面试真题(1)学习
TCP和UDP区别 TCP 面向连接。在传输数据之前,通信双方需要先建立一个连接(三次握手)。可靠性。TCP提供可靠的数据传输,它通过序列号、确认应答、重传机制和校验和等技术确保数据的正确传输。数据顺序:TCP保证数据按发…...

2024 年人工智能和数据科学的五个主要趋势
引言 2023年,人工智能和数据科学登上了新闻头条。生成性人工智能的兴起无疑是这一显著提升曝光度的驱动力。那么,在2024年,该领域将如何继续占据头条,并且这些趋势又将如何影响企业的发展呢? 在过去几个月,…...

GPU云渲染平台到底怎么选?这六点要注意!
随着对高效计算和图像处理需求的增加,GPU云渲染平台成为许多行业的关键工具。尤其是对影视动画制作领域来说,选择一个合适的GPU云渲染平台可以大大提升工作效率。然而,面对市场上众多的选择,如何找到适合自己的GPU云渲染平台呢&am…...
【区块链+基础设施】国家健康医疗大数据科创平台 | FISCO BCOS应用案例
在医疗领域,疾病数据合法合规共享是亟待解决的难题。一方面,当一家医院对患者实施治疗后,若患者转到其 他医院就医,该医院就无法判断诊疗手段是否有效。另一方面,医疗数据属于个人敏感数据,一旦被泄露或被恶…...

redis压测和造数据方式
一、redis 压测工具 1、压测命令 1、对3000字节的数据进行get set的操作 redis-benchmark -h 10.166.15.36 -p 7001 -t set,get -n 100000 -q -d 3000 2、100个并发连接,100000个请求,检测host为localhost 端口为6379的redis服务器性能 redis-benchma…...

数据存储方案选择:ES、HBase、Redis、MySQL与MongoDB的应用场景分析
一、概述 1.1 背景 在当今数据驱动的时代,选择合适的数据存储技术对于构建高效、可靠的信息系统至关重要。随着数据量的爆炸式增长和处理需求的多样化,市场上涌现出了各种数据存储解决方案,每种技术都有其独特的优势和适用场景。Elasticsear…...

Unity主题系统设计:状态驱动的主题抽象与自动注入方案
1. 这不是换个颜色那么简单:为什么Unity项目里“换肤”总在发布前夜崩盘?你有没有经历过这样的场景:美术同学凌晨两点发来一套新主题资源包,UI设计师说“这次配色更符合品牌调性”,产品说“上线前必须支持深色模式”&a…...

炉石传说自动对战助手:5分钟上手,彻底解放双手的终极指南
炉石传说自动对战助手:5分钟上手,彻底解放双手的终极指南 【免费下载链接】Hearthstone-Script Hearthstone script(炉石传说脚本) 项目地址: https://gitcode.com/gh_mirrors/he/Hearthstone-Script 还在为每天重复的炉石…...

Gofile批量下载自动化工具:5步实现高效文件管理解决方案
Gofile批量下载自动化工具:5步实现高效文件管理解决方案 【免费下载链接】gofile-downloader Download files from https://gofile.io 项目地址: https://gitcode.com/gh_mirrors/go/gofile-downloader 在当今数字化工作环境中,技术团队经常需要从…...

观察Taotoken在多模型聚合调用下的路由与失败重试效果
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察Taotoken在多模型聚合调用下的路由与失败重试效果 在构建依赖大模型能力的应用时,服务的稳定性是开发者关注的核心…...

基于Arduino Uno与MQ-2传感器的智能气体检测报警系统DIY全攻略
1. 项目概述与核心思路最近在捣鼓家里的智能安防,琢磨着能不能自己做一个成本可控、反应灵敏的气体检测报警装置。市面上成品烟雾报警器虽然成熟,但要么功能单一,要么价格不菲,而且很难根据自己的需求进行定制化调整,比…...

UE5 GPU崩溃终极解决方案:Windows TDR注册表调优指南
1. 这不是玄学,是显卡驱动与UE引擎的底层握手失败 你刚点下Play,编辑器还没完全加载完场景,屏幕突然黑一下,然后弹出“GPU has stopped responding and has recovered”——或者更糟,直接蓝屏、黑屏死机、编辑器无响应…...

安全多方计算中稀疏矩阵乘法优化:原理、实现与隐私保护应用
1. 项目概述:当稀疏矩阵遇上安全多方计算在机器学习、推荐系统这些我们每天都会接触到的技术背后,数据往往以一种“稀疏”的形式存在。想象一下一个拥有百万用户和十万本书籍的在线书店,每个用户可能只读过其中几十本,那么构建一个…...

模型越强,Bug越隐?DeepSeek代码生成评测:12个真实项目踩坑案例,速查避雷清单
更多请点击: https://kaifayun.com 第一章:模型越强,Bug越隐?DeepSeek代码生成评测:12个真实项目踩坑案例,速查避雷清单 当大模型在代码补全、函数生成和单元测试编写中表现愈发惊艳,一个反直觉…...

机器学习赋能分子模拟:从数据驱动CV到自适应采样破解采样瓶颈
1. 项目概述与核心价值在分子模拟的世界里,我们常常面临一个根本性的困境:我们想理解一个复杂系统(比如一个蛋白质如何折叠,或者一个催化剂表面如何发生反应)的微观机理,但系统的相空间维度高得吓人——动辄…...

机器学习进化算法与新奇性搜索在暗物质模型参数空间扫描中的应用
1. 项目概述与核心挑战在粒子物理和宇宙学的前沿,寻找暗物质候选者是一场旷日持久的“寻宝”游戏。我们面对的“藏宝图”是各种理论模型,比如二重希格斯模型(2HDM)及其扩展,而“宝藏”则是那些能让模型预言与所有实验观…...