吴恩达深度学习笔记:机器学习策略(2)(ML Strategy (2)) 2.3-2.4
目录
- 第三门课 结构化机器学习项目(Structuring Machine Learning Projects)
- 第二周:机器学习策略(2)(ML Strategy (2))
- 2.3 快速搭建你的第一个系统,并进行迭代(Build your first system quickly, then iterate)
- 2.4 使用来自不同分布的数据进行训练和测试(Training and testing on different distributions)
第三门课 结构化机器学习项目(Structuring Machine Learning Projects)
第二周:机器学习策略(2)(ML Strategy (2))
2.3 快速搭建你的第一个系统,并进行迭代(Build your first system quickly, then iterate)
如果你正在开发全新的机器学习应用,我通常会给你这样的建议,你应该尽快建立你的第一个系统原型,然后快速迭代。
让我告诉你我的意思,我在语音识别领域研究了很多年,如果你正在考虑建立一个新的语音识别系统,其实你可以走很多方向,可以优先考虑很多事情。
比如,有一些特定的技术,可以让语音识别系统对嘈杂的背景更加健壮,嘈杂的背景可能是说咖啡店的噪音,背景里有很多人在聊天,或者车辆的噪音,高速上汽车的噪音或者其他类型的噪音。有一些方法可以让语音识别系统在处理带口音时更健壮,还有特定的问题和麦克风与说话人距离很远有关,就是所谓的远场语音识别。儿童的语音识别带来特殊的挑战,挑战来自单词发音方面,还有他们选择的词汇,他们倾向于使用的词汇。还有比如说,说话人口吃,或者说了很多无意义的短语,比如“哦”,“啊”之类的。你可以选择很多不同的技术,让你听写下来的文本可读性更强,所以你可以做很多事情来改进语音识别系统。

一般来说,对于几乎所有的机器学习程序可能会有 50 个不同的方向可以前进,并且每个方向都是相对合理的可以改善你的系统。但挑战在于,你如何选择一个方向集中精力处理。即使我已经在语音识别领域工作多年了,如果我要为一个新应用程序域构建新系统,我还是觉得很难不花时间去思考这个问题就直接选择方向。所以我建议你们,如果你想搭建全新的机器学习程序,就是快速搭好你的第一个系统,然后开始迭代。我的意思是我建议你快速设立开发集和测试集还有指标,这样就决定了你的目标所在,如果你的目标定错了,之后改也是可以的。但一定要设立某个目标,然后我建议你马上搭好一个机器学习系统原型,然后找到训练集,训练一下,看看效果,开始理解你的算法表现如何,在开发集测试集,你的评估指标上表现如何。当你建立第一个系统后,你就可以马上用到之前说的偏差方差分析,还有之前最后几个视频讨论的错误分析,来确定下一步优先做什么。特别是如果错误分析让你了解到大部分的错误的来源是说话人远离麦克风,这对语音识别构成特殊挑战,那么你就有很好的理由去集中精力研究这些技术,所谓远场语音识别的技术,这基本上就是处理说话人离麦克风很远的情况。
建立这个初始系统的所有意义在于,它可以是一个快速和粗糙的实现(quick and dirty implementation),你知道的,别想太多。初始系统的全部意义在于,有一个学习过的系统,有一个训练过的系统,让你确定偏差方差的范围,就可以知道下一步应该优先做什么,让你能够进行错误分析,可以观察一些错误,然后想出所有能走的方向,哪些是实际上最有希望的方向。

所以回顾一下,我建议你们快速建立你的第一个系统,然后迭代。不过如果你在这个应用程序领域有很多经验,这个建议适用程度要低一些。还有一种情况适应程度更低,当这个领域有很多可以借鉴的学术文献,处理的问题和你要解决的几乎完全相同,所以,比如说,人脸识别就有很多学术文献,如果你尝试搭建一个人脸识别设备,那么可以从现有大量学术文献为基础出发,一开始就搭建比较复杂的系统。但如果你第一次处理某个新问题,那我真的不鼓励你想太多,或者把第一个系统弄得太复杂。我建议你们构建一些快速而粗糙的实现,然后用来帮你找到改善系统要优先处理的方向。我见过很多机器学习项目,我觉得有些团队的解决方案想太多了,他们造出了过于复杂的系统。我也见过有限团队想的不够,然后造出过于简单的系统。平均来说,我见到更多的团队想太多,构建太复杂的系统。
所以我希望这些策略有帮助,如果你将机器学习算法应用到新的应用程序里,你的主要目标是弄出能用的系统,你的主要目标并不是发明全新的机器学习算法,这是完全不同的目标,那时你的目标应该是想出某种效果非常好的算法。所以我鼓励你们搭建快速而粗糙的实现,然后用它做偏差/方差分析,用它做错误分析,然后用分析结果确定下一步优先要做的方向。
2.4 使用来自不同分布的数据进行训练和测试(Training and testing on different distributions)
深度学习算法对训练数据的胃口很大,当你收集到足够多带标签的数据构成训练集时,算法效果最好,这导致很多团队用尽一切办法收集数据,然后把它们堆到训练集里,让训练的数据量更大,即使有些数据,甚至是大部分数据都来自和开发集、测试集不同的分布。在深度学习时代,越来越多的团队都用来自和开发集、测试集分布不同的数据来训练,这里有一些微妙的地方,一些最佳做法来处理训练集和测试集存在差异的情况,我们来看看。

假设你在开发一个手机应用,用户会上传他们用手机拍摄的照片,你想识别用户从应用中上传的图片是不是猫。现在你有两个数据来源,一个是你真正关心的数据分布,来自应用上传的数据,比如右边的应用,这些照片一般更业余,取景不太好,有些甚至很模糊,因为它们都是业余用户拍的。另一个数据来源就是你可以用爬虫程序挖掘网页直接下载,就这个样本而言,可以下载很多取景专业、高分辨率、拍摄专业的猫图片。如果你的应用用户数还不多,也许你只收集到 10,000 张用户上传的照片,但通过爬虫挖掘网页,你可以下载到海量猫图,也许你从互联网上下载了超过 20 万张猫图。而你真正关心的算法表现是你的最终系统处理来自应用程序的这个图片分布时效果好不好,因为最后你的用户会上传类似右边这些图片,你的分类器必须在这个任务中表现良好。现在你就陷入困境了,因为你有一个相对小的数据集,只有 10,000 个样本来自那个分布,而你还有一个大得多的数据集来自另一个分布,图片的外观和你真正想要处理的并不一样。但你又不想直接用这 10,000 张图片,因为这样你的训练集就太小了,使用这 20 万张图片似乎有帮助。但是,困境在于,这 20 万张图片并不完全来自你想要的分布,那么你可以怎么做呢?
这里有一种选择,你可以做的一件事是将两组数据合并在一起,这样你就有 21 万张照片,你可以把这 21 万张照片随机分配到训练、开发和测试集中。为了说明观点,我们假设你已经确定开发集和测试集各包含 2500 个样本,所以你的训练集有 205000 个样本。现在这么设立你的数据集有一些好处,也有坏处。好处在于,你的训练集、开发集和测试集都来自同一分布,这样更好管理。但坏处在于,这坏处还不小,就是如果你观察开发集,看看这2500 个样本其中很多图片都来自网页下载的图片,那并不是你真正关心的数据分布,你真正要处理的是来自手机的图片。
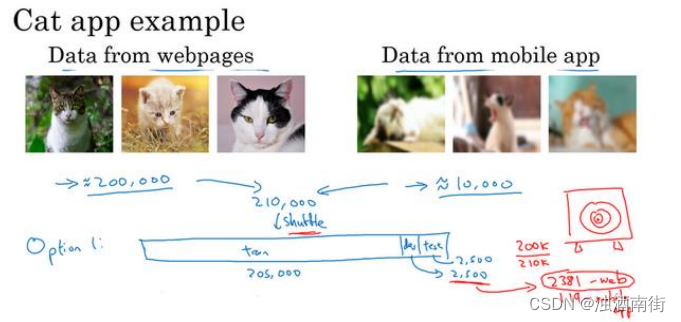
所以结果你的数据总量,这 200,000 个样本,我就用200𝑘缩写表示,我把那些是从网页下载的数据总量写成210𝑘,所以对于这 2500 个样本,数学期望值是: 2500 × 200 k 210 k = 2381 2500 ×\frac{200k}{210k}= 2381 2500×210k200k=2381,有 2381 张图来自网页下载,这是期望值,确切数目会变化,取决于具体的随机分配操作。但平均而言,只有 119 张图来自手机上传。要记住,设立开发集的目的是告诉你的团队去瞄准的目标,而你瞄准目标的方式,你的大部分精力都用在优化来自网页下载的图片,这其实不是你想要的。所以我真的不建议使用第一个选项,因为这样设立开发集就是告诉你的团队,针对不同于你实际关心的数据分布去优化,所以不要这么做。
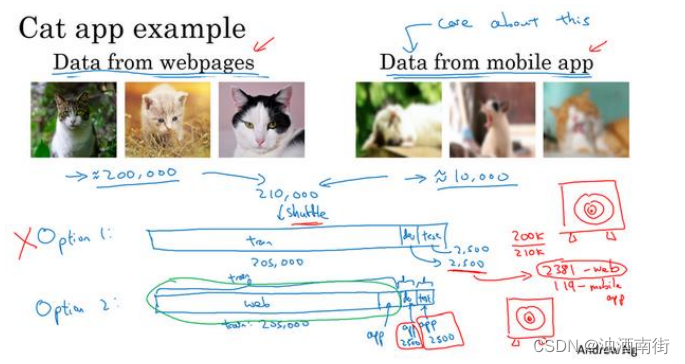
我建议你走另外一条路,就是这样,训练集,比如说还是 205,000 张图片,我们的训练集是来自网页下载的 200,000 张图片,然后如果需要的话,再加上 5000 张来自手机上传的图片。然后对于开发集和测试集,这数据集的大小是按比例画的,你的开发集和测试集都是手机图。而训练集包含了来自网页的 20 万张图片,还有 5000 张来自应用的图片,开发集就是 2500 张来自应用的图片,测试集也是 2500 张来自应用的图片。这样将数据分成训练集、开发集和测试集的好处在于,现在你瞄准的目标就是你想要处理的目标,你告诉你的团队,我的开发集包含的数据全部来自手机上传,这是你真正关心的图片分布。我们试试搭建一个学习系统,让系统在处理手机上传图片分布时效果良好。缺点在于,当然了,现在你的训练集分布和你的开发集、测试集分布并不一样。但事实证明,这样把数据分成训练、开发和测试集,在长期能给你带来更好的系统性能。我们以后会讨论一些特殊的技巧,可以处理 训练集的分布和开发集和测试集分布不一样的情况。
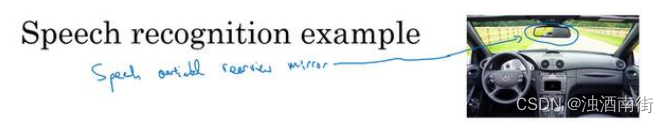
我们来看另一个样本,假设你正在开发一个全新的产品,一个语音激活汽车后视镜,这在中国是个真实存在的产品,它正在进入其他国家。但这就是造一个后视镜,把这个小东西换掉,现在你就可以和后视镜对话了,然后只需要说:“亲爱的后视镜,请帮我找找到最近的加油站的导航方向”,然后后视镜就会处理这个请求。所以这实际上是一个真正的产品,假设现在你要为你自己的国家研制这个产品,那么你怎么收集数据去训练这个产品语言识别模块呢?
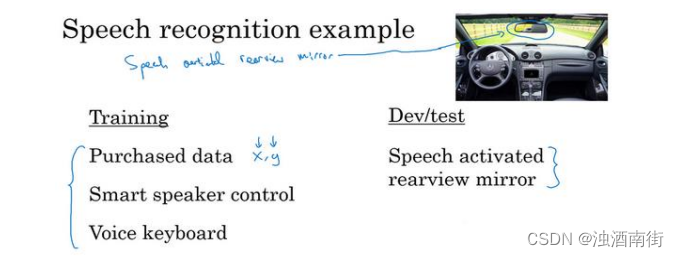
嗯,也许你已经在语音识别领域上工作了很久,所以你有很多来自其他语音识别应用的数据,它们并不是来自语音激活后视镜的数据。现在我讲讲如何分配训练集、开发集和测试集。对于你的训练集,你可以将你拥有的所有语音数据,从其他语音识别问题收集来的数据,比如这些年你从各种语音识别数据供应商买来的数据,今天你可以直接买到成𝑥,𝑦对的数据,其中𝑥是音频剪辑,𝑦是听写记录。或者也许你研究过智能音箱,语音激活音箱,所以你有一些数据,也许你做过语音激活键盘的开发之类的。
举例来说,也许你从这些来源收集了 500,000 段录音,对于你的开发集和测试集也许数据集小得多,比如实际上来自语音激活后视镜的数据。因为用户要查询导航信息或试图找到通往各个地方的路线,这个数据集可能会有很多街道地址,对吧?“请帮我导航到这个街道地址”,或者说:“请帮助我导航到这个加油站”,所以这个数据的分布和左边大不一样,但这真的是你关心的数据,因为这些数据是你的产品必须处理好的,所以你就应该把它设成你的开发和测试集。

在这个样本中,你应该这样设立你的训练集,左边有 500,000 段语音,然后你的开发集和测试集,我把它简写成𝐷和𝑇,可能每个集包含 10,000 段语音,是从实际的语音激活后视镜收集的。或者换种方式,如果你觉得不需要将 20,000 段来自语音激活后视镜的录音全部
放进开发和测试集,也许你可以拿一半,把它放在训练集里,那么训练集可能是 51 万段语音,包括来自那里的 50 万段语音,还有来自后视镜的 1 万段语音,然后开发集和测试集也许各自有 5000 段语音。所以有 2 万段语音,也许 1 万段语音放入了训练集,5000 放入开发集,5000 放入测试集。所以这是另一种将你的数据分成训练、开发和测试的方式。这样你的训练集大得多,大概有 50 万段语音,比只用语音激活后视镜数据作为训练集要大得多。
所以在这个视频中,你们见到几组样本,让你的训练集数据来自和开发集、测试集不同的分布,这样你就可以有更多的训练数据。在这些样本中,这将改善你的学习算法。
现在你可能会问,是不是应该把收集到的数据都用掉?答案很微妙,不一定都是肯定的答案,我们在下段视频看看一个反例。
相关文章:
吴恩达深度学习笔记:机器学习策略(2)(ML Strategy (2)) 2.3-2.4
目录 第三门课 结构化机器学习项目(Structuring Machine Learning Projects)第二周:机器学习策略(2)(ML Strategy (2))2.3 快速搭建你的第一个系统,并进行迭代(Build your first system quickly…...

【软件测试】快速定位bug,编写测试用例
作为一名测试人员如果连常见的系统问题都不知道如何分析,频繁将前端人员问题指派给后端人员,后端人员问题指派给前端人员,那么在团队里你在开发中的地位显而易见 ,口碑、升值、加薪那应该是你遥不可及的梦 但是作为测试人员来说&…...

升级springboot3
坑爹的发版流水线,管天管地,springboot2过了维护期,就催着我们升级。 导致必须上jdk17 记录一下升级需要处理的事情 先升级springboot和cloud,这里定下基调,其他的才好跟着升级 https://spring.io/projects/spring-b…...
视频编解码从H.264到H.266:浅析GB28181安防视频汇聚EasyCVR视频压缩技术
随着信息技术的飞速发展,视频编解码技术也在不断革新,以适应高清、超高清甚至8K视频时代的到来。视频编解码技术作为数字多媒体领域的核心技术之一,也在不断地演进和革新。从早期的H.261到现在的H.265、H.266,每一次技术的升级都极…...

vue项目访问 域名/index.html 空页面问题
很大可能是vue前端没做404页面,在路由不匹配时会跳转到空路由页面。 也可以把所有路由不匹配的网址全部跳转到域名首页。防止出现404或者页面错误。 如果使用docker nginx部署项目,配置文件上会有 try_files $uri $uri/ /index.html; 这段配置会尝试…...

区块链开发入门:基础概念与实施技术详解
区块链开发入门:基础概念与实施技术详解 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿! 引言 随着区块链技术的快速发展,它已经不再局…...
)
Rust破界:前端革新与Vite重构的深度透视(下)
Rust破界:前端革新与Vite重构的深度透视(下) 前端开发者:拥抱 Rust 的策略与时机技能树的扩展 结语:跨界融合的未来展望Vite 重构的深远意义 附录:进一步探索 Rust 的资源指南 前端开发者:拥抱 …...

Android 解决 “Module was compiled with an incompatible version of Kotlin“ 问题
解决 “Module was compiled with an incompatible version of Kotlin” 问题 在Android开发中,有时我们会遇到Kotlin版本不兼容的问题。具体来说,你可能会看到如下错误: D:/.gradle/caches/transforms-3/caf5371a15e0d6ffc362b4a5ece9cd49…...

linux nfs的使用
版权声明:来自百度AI,此处记录是方便日后查看,无任何商业用途 linux网络文件共享服务之nfs NFS(Network File System)是一种允许计算机用户或者操作系统通过网络以类似本地的方式访问文件的协议。以下是一个简单的NF…...
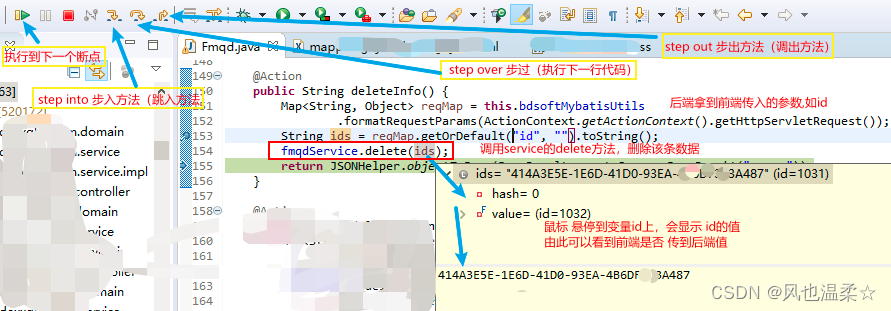
eclipse断点调试(用图说话)
eclipse断点调试(用图说话) debug方式启动项目,后端调试bug调试 前端代码调试,请参考浏览器断点调试(用图说话) 1、前端 选中一条数据,点击删除按钮 2、后端接口打断点 断点按钮 介绍 resum…...
vue的学习--day2
如有错误,烦请指正~ 目录 一、什么是单页面应用程序 二、使用工具:node.js 三、工具链 易错点 一、什么是单页面应用程序 多个组件(例如登录、注册等以vue结尾的都叫做组件)在一个页面显示,叫单页面应用…...

html + css 快速实现订单详情的布局demo
突然安排让速写这样的一个布局,重点就是CSS画一条虚线,并且还要灵活设置虚线的宽度和虚线之间的间隔和虚线的颜色。 注:订单里面的金额都是随意写的 <!DOCTYPE html> <html lang"zh-CN"><head><meta charset"UTF-8&…...
居然这么简单就能实现扫雷游戏!
目录 一.思路 1.成果展示 2.思路 二.具体操作 1.创建"棋盘" 2.初始化雷 3.布置雷 4.打印 5.排除雷 三.代码实现 1.test.c文件 2.thunder.h文件 3.thunder.c文件 Hello,大家好,今天我们来实现扫雷游戏,希望这一篇博客能给带给大家一…...

安装Gitlab+Jenkins
GItlab概述 GitLab概述: 是一个利用 Ruby on Rails 开发的开源应用程序,实现一个自托管的Git项目仓库,可通过Web界面进行访问公开的或者私人项目。 Ruby on Rails 是一个可以使你开发、部署、维护 web 应用程序变得简单的框架。 GitLab拥有与…...

php 命令行模式详解
PHP 的命令行模式(Command Line Interface, CLI)是 PHP 的一个特定版本或运行时配置,它允许 PHP 脚本在没有 Web 服务器的情况下直接在命令行环境中执行。CLI 版本的 PHP 通常不包含 CGI 或者其他 web server 接口,因此更轻量级&a…...

Git 基础-创建版本库 git init、添加到暂存区git add、查看状态git status、查看改动git diff
目录 1.创建版本库 git init 1.创建版本库 git init 在目录中创建新的 Git 仓库。 你可以在任何时候、任何目录中这么做,完全是本地化的。 在目录中执行 git init,就可以创建一个 Git 仓库了。 注意: 没事不要手动修改 .git 目录里面的文件,不…...

Python实现无头浏览器采集应用的反爬虫与反检测功能解析与应对策略
Python实现无头浏览器采集应用的反爬虫与反检测功能解析与应对策略 随着网络数据的快速增长,爬虫技术在数据采集、信息分析和业务发展中扮演着重要的角色。然而,随之而来的反爬虫技术也在不断升级,给爬虫应用的开发和维护带来了挑战。为了应…...
法国工程师IMT联盟 密码学及其应用 2023年期末考试题
1 在 Unix 下的安全性 (30 分钟) 1.1 问题 1 1.1.1 问题 我们注意constat到通过 SMTP 服务器发送“假”电子邮件(垃圾邮件)相对容易。越来越常见的做法是在 SMTP 连接之上部署dployer TLS 协议protocole(即 SMTPS)。这解决了垃圾…...
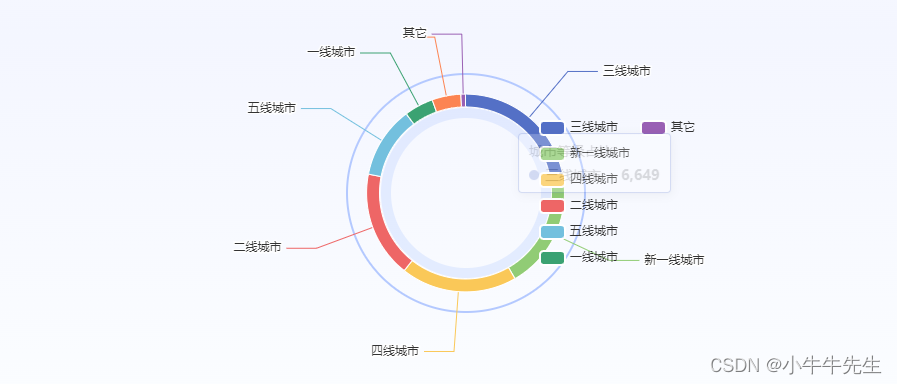
魔行观察-AI数据分析-蜜雪冰城
摘要 本报告旨在评估蜜雪冰城品牌作为投资对象的潜力和价值,基于其经营模式、门店分布、人均消费、覆盖省份等关键指标进行分析。 数据数据源:魔行观察:http://www.wmomo.com/#/brand/brandDetails?code10013603 品牌概览 蜜雪冰城是中国…...

如何在CSS中设置px值
在CSS中设置px(像素)值非常简单。px是CSS中最常用的长度单位之一,用于指定元素的大小、位置、间距等。 以下是一些示例,展示如何在CSS中使用px值: 设置元素宽度和高度 css复制代码 .box { width: 200px; /* 设置元素…...

Buzz音频转录完全指南:3大核心功能+5个实战场景,快速掌握本地语音转文字技术
Buzz音频转录完全指南:3大核心功能5个实战场景,快速掌握本地语音转文字技术 【免费下载链接】buzz Buzz transcribes and translates audio offline on your personal computer. Powered by OpenAIs Whisper. 项目地址: https://gitcode.com/GitHub_Tr…...

告别命令行!用Python脚本批量管理Docker容器,效率提升不止一点点
告别命令行!用Python脚本批量管理Docker容器,效率提升不止一点点每次在终端敲入docker ps、docker stop、docker rm时,你是否想过——当容器数量超过两位数,这种重复劳动是否在消耗你的生命?去年我们团队在迁移微服务架…...

智能检索新范式,让AIAgent自主决策,提升RAG效率100%!
市面上的 RAG 系统,不管叫什么名字,本质上只有两种做法: 第一种,一次性检索。把用户的 query 向量化,从语料库里捞出 Top-K 个文档片段,拼成一个大 prompt 塞给模型。GraphRAG、HippoRAG、LightRAG 都属于…...
 第五篇:声明时的键值设计技巧:结构与内表的主键、非主键配置指南)
SAP-ABAP:变量、常量、结构与内表声明(10篇博客合集) 第五篇:声明时的键值设计技巧:结构与内表的主键、非主键配置指南
变量、常量、结构与内表声明(10篇博客合集) 第五篇:声明时的键值设计技巧:结构与内表的主键、非主键配置指南如果把内表比作一张内存中的“数据库表”,那么键就是这张表的索引甚至主键。键的设计直接决定了数据的唯一性…...

如何高效批量下载音乐歌词:智能歌词管理完整指南
如何高效批量下载音乐歌词:智能歌词管理完整指南 【免费下载链接】ZonyLrcToolsX ZonyLrcToolsX 是一个能够方便地下载歌词的小软件。 项目地址: https://gitcode.com/gh_mirrors/zo/ZonyLrcToolsX ZonyLrcToolsX 是一款专业的跨平台歌词下载工具,…...

全链路压测实战:双十一级别的流量,我是这样扛住的
作为一名在质量保障领域摸爬滚打多年的测试工程师,我深知传统的单接口压测在如今分布式架构下的无力感。当业务流量达到双十一这种脉冲式、高并发的级别时,任何一个非核心链路上的“短板”都可能引发系统性的雪崩。全链路压测不再是选择题,而…...

别被忽悠了!2026亲测靠谱的AI论文网站|避坑精选版
2026 年学术写作工具已高度分化,千笔AI与ThouPen为全流程首选,豆包、DeepSeek 为专项强手;避坑关键:拒绝假文献、严控 AIGC 率、优先国内适配、免费试用先行。 一、TOP3 全流程首选(亲测不踩雷) 1. 千笔AI&…...

当 AI Coding 进入复杂企业系统,为什么提效远没有宣传里那么美好 ?
以 Claude Code、Codex 为代表的自主编码智能体(Coding Agents),正在以惊人的速度席卷软件开发者生态。与此同时,类似“10 倍开发效率”“普通人也能随手构建软件”“程序员即将失业”的说法,也随处可见。这种不分场景…...

从开题到定稿零焦虑:okbiye AI 论文写作,帮你把毕业季的 “大山” 变成坦途
okbiye-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPT毕业论文 - Okbiye智能写作https://www.okbiye.com/ai/bylw 毕业季的深夜,宿舍台灯下的屏幕亮着刺眼的光,文档里的字数停留在三位数,而 deadline 正一天天逼近。你是…...

OpenCore Legacy Patcher完全指南:3步让旧款Mac焕发新生的终极方案
OpenCore Legacy Patcher完全指南:3步让旧款Mac焕发新生的终极方案 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 你是否拥有一台性能尚可但已被…...