Java [ 基础 ] HashMap详解 ✨
目录
✨探索Java基础 HashMap详解✨
总述
主体
1. HashMap的基本概念
2. HashMap的工作原理
3. HashMap的常用操作
4. HashMap的优缺点
总结
常见面试题
常见面试题解答
1. HashMap的底层实现原理是什么?
2. 如何解决HashMap中的哈希冲突?
3. HashMap和Hashtable的区别是什么?
4. 在什么情况下HashMap会发生扩容?
5. 为什么HashMap不是线程安全的?如何实现线程安全的HashMap?
HashMap源码
1 put方法流程
2 扩容
3 get方法
✨探索Java基础 HashMap详解✨
总述
在Java中,HashMap 是一个常用的数据结构,它实现了Map接口,允许我们通过键值对的形式存储和快速查找数据。HashMap的底层是基于哈希表(hash table)的实现,它的高效性和灵活性使其在各种编程场景中广受欢迎。本文将详细介绍HashMap的原理、使用方法、优缺点,并提供一些常见的面试题。
主体
1. HashMap的基本概念

HashMap是一个散列表,它存储键值对(key-value pairs),每个键对应一个唯一的值。HashMap不保证顺序,并且允许null值作为键或值。
import java.util.HashMap;public class Main {public static void main(String[] args) {HashMap<String, Integer> map = new HashMap<>();map.put("one", 1);map.put("two", 2);map.put("three", 3);System.out.println(map.get("one")); // 输出: 1}
}
2. HashMap的工作原理
HashMap使用哈希表来存储数据。键的哈希值通过hash()方法计算,然后通过哈希函数将哈希值映射到数组的索引位置上。通过链地址法(chaining)来解决哈希冲突,即在每个数组索引处存储一个链表(Java 8及之后版本采用红黑树以提高性能)。
public int hash(Object key) {int h;return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
3. HashMap的常用操作
-
添加元素: 使用
put()方法。
-
map.put("four", 4); -
获取元素: 使用
get()方法。int value = map.get("two"); -
移除元素: 使用
remove()方法。map.remove("three"); -
遍历元素:
for (Map.Entry<String, Integer> entry : map.entrySet()) {System.out.println(entry.getKey() + ": " + entry.getValue()); }
4. HashMap的优缺点
优点:
- 快速查找: 平均时间复杂度为O(1)。
- 灵活: 可以存储不同类型的对象,允许
null键和值。
缺点:
- 非线程安全: 多线程情况下需要手动同步。
- 不保证顺序: 插入顺序和遍历顺序可能不同。
总结
HashMap是Java中一个强大且高效的集合类,用于快速查找和存储键值对。理解其工作原理和常用操作对于提高编程效率和解决复杂问题非常有帮助。
常见面试题
HashMap的底层实现原理是什么?- 如何解决
HashMap中的哈希冲突? HashMap和Hashtable的区别是什么?- 在什么情况下
HashMap会发生扩容? - 为什么
HashMap不是线程安全的?如何实现线程安全的HashMap?
常见面试题解答
1. HashMap的底层实现原理是什么?
HashMap的底层是基于哈希表(hash table)实现的。它内部使用一个数组来存储元素,每个数组的元素被称为“桶”(bucket)。当我们向HashMap中插入一个键值对时,会先根据键的hashCode()方法计算出哈希值,然后通过哈希函数将哈希值映射到数组的索引位置上。HashMap通过链地址法(chaining)来解决哈希冲突,即每个桶中存储一个链表(Java 8及之后版本采用红黑树以提高性能)。
public int hash(Object key) {int h;return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
2. 如何解决HashMap中的哈希冲突?
HashMap采用链地址法(chaining)来解决哈希冲突。具体方法是,每个桶中存储一个链表(或者在Java 8及之后版本中,当链表长度超过一定阈值时,会转换成红黑树),所有映射到同一索引位置的键值对都会存储在这个链表或红黑树中。
当插入一个新的键值对时,如果该键值对的哈希值映射到的索引位置已经存在其它元素,则会将新的键值对添加到该位置的链表或红黑树中。
3. HashMap和Hashtable的区别是什么?
- 线程安全性:
Hashtable是线程安全的,所有方法都是同步的,而HashMap不是线程安全的,适用于单线程环境或通过外部同步来保证线程安全。 - null键和值:
HashMap允许一个null键和多个null值,而Hashtable不允许null键和值。 - 性能: 由于
Hashtable的方法是同步的,因此在单线程环境下性能比HashMap差。 - 遗产:
Hashtable是基于较老的Dictionary类实现的,而HashMap是从Java 1.2开始作为Map接口的实现类。
4. 在什么情况下HashMap会发生扩容?
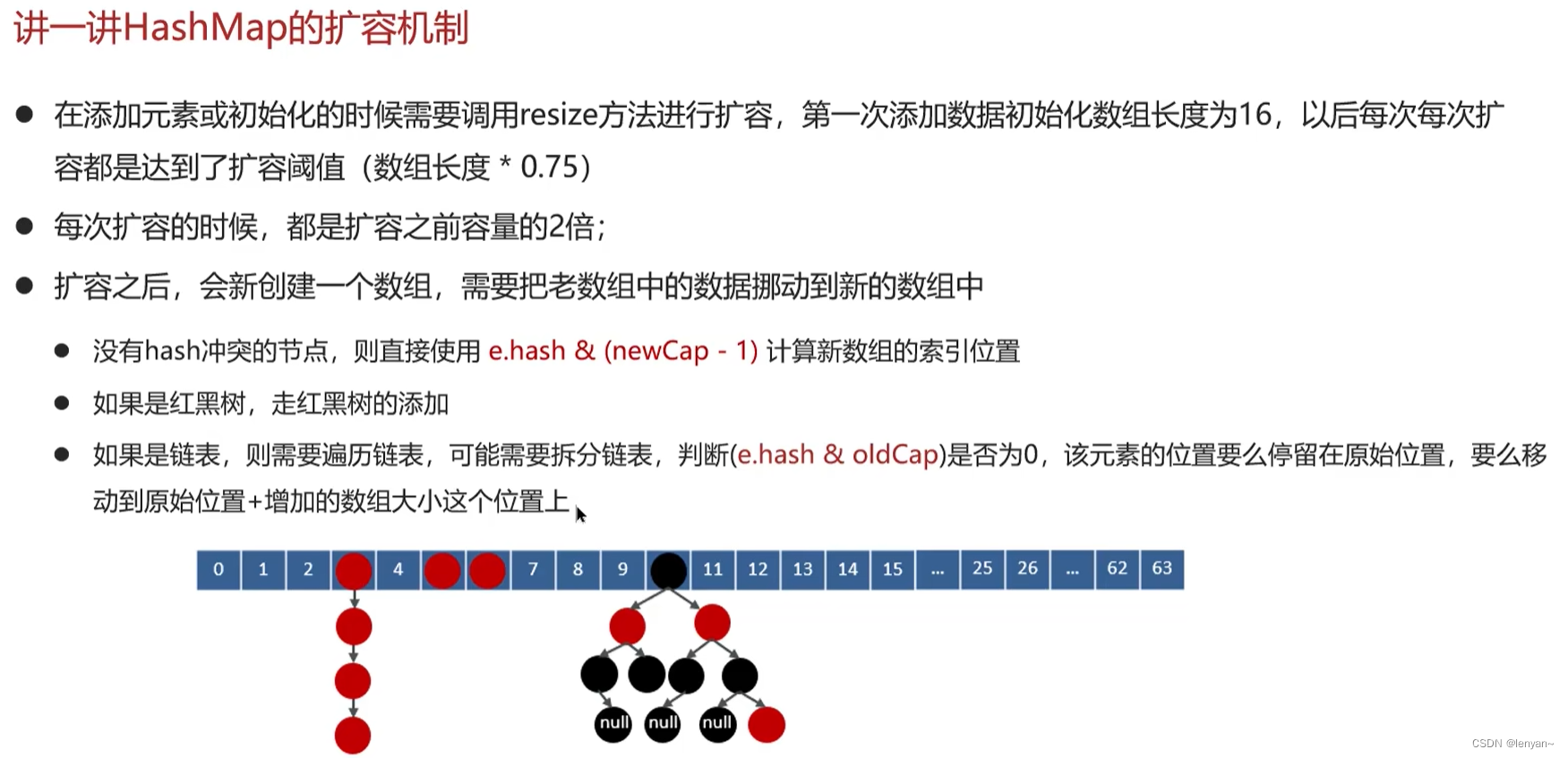
HashMap会在容量达到阈值(默认是当前容量的0.75倍)时发生扩容。扩容时,HashMap的容量会变为原来的两倍,并重新哈希已有的键值对,重新分配到新的桶中。扩容可以避免哈希冲突,保持HashMap的高效性。
5. 为什么HashMap不是线程安全的?如何实现线程安全的HashMap?
HashMap不是线程安全的,因为它的所有方法都不是同步的。在多线程环境下,多个线程同时修改HashMap的结构可能导致数据不一致或出现死循环。
要实现线程安全的HashMap,可以通过以下方法:
-
使用
Collections.synchronizedMap(Map<K, V> m)方法: 这个方法返回一个线程安全的Map。Map<String, Integer> synchronizedMap = Collections.synchronizedMap(new HashMap<>()); -
使用
ConcurrentHashMap: 这是Java提供的线程安全的Map实现,适用于高并发环境。它通过分段锁机制(Segmented Locking)来提高并发性能。ConcurrentHashMap<String, Integer> concurrentMap = new ConcurrentHashMap<>();
HashMap源码
1 put方法流程
public V put(K key, V value) {return putVal(hash(key), key, value, false, true);
}final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {Node<K,V>[] tab; Node<K,V> p; int n, i;//判断数组是否未初始化if ((tab = table) == null || (n = tab.length) == 0)//如果未初始化,调用resize方法 进行初始化n = (tab = resize()).length;//通过 & 运算求出该数据(key)的数组下标并判断该下标位置是否有数据if ((p = tab[i = (n - 1) & hash]) == null)//如果没有,直接将数据放在该下标位置tab[i] = newNode(hash, key, value, null);//该数组下标有数据的情况else {Node<K,V> e; K k;//判断该位置数据的key和新来的数据是否一样if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))//如果一样,证明为修改操作,该节点的数据赋值给e,后边会用到e = p;//判断是不是红黑树else if (p instanceof TreeNode)//如果是红黑树的话,进行红黑树的操作e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);//新数据和当前数组既不相同,也不是红黑树节点,证明是链表else {//遍历链表for (int binCount = 0; ; ++binCount) {//判断next节点,如果为空的话,证明遍历到链表尾部了if ((e = p.next) == null) {//把新值放入链表尾部p.next = newNode(hash, key, value, null);//因为新插入了一条数据,所以判断链表长度是不是大于等于8if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st//如果是,进行转换红黑树操作treeifyBin(tab, hash);break;}//判断链表当中有数据相同的值,如果一样,证明为修改操作if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))break;//把下一个节点赋值为当前节点p = e;}}//判断e是否为空(e值为修改操作存放原数据的变量)if (e != null) { // existing mapping for key//不为空的话证明是修改操作,取出老值V oldValue = e.value;//一定会执行 onlyIfAbsent传进来的是falseif (!onlyIfAbsent || oldValue == null)//将新值赋值当前节点e.value = value;afterNodeAccess(e);//返回老值return oldValue;}}//计数器,计算当前节点的修改次数++modCount;//当前数组中的数据数量如果大于扩容阈值if (++size > threshold)//进行扩容操作resize();//空方法afterNodeInsertion(evict);//添加操作时 返回空值return null;
}2 扩容
//扩容、初始化数组
final Node<K,V>[] resize() {Node<K,V>[] oldTab = table;//如果当前数组为null的时候,把oldCap老数组容量设置为0int oldCap = (oldTab == null) ? 0 : oldTab.length;//老的扩容阈值int oldThr = threshold;int newCap, newThr = 0;//判断数组容量是否大于0,大于0说明数组已经初始化if (oldCap > 0) {//判断当前数组长度是否大于最大数组长度if (oldCap >= MAXIMUM_CAPACITY) {//如果是,将扩容阈值直接设置为int类型的最大数值并直接返回threshold = Integer.MAX_VALUE;return oldTab;}//如果在最大长度范围内,则需要扩容 OldCap << 1等价于oldCap*2//运算过后判断是不是最大值并且oldCap需要大于16else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&oldCap >= DEFAULT_INITIAL_CAPACITY)newThr = oldThr << 1; // double threshold 等价于oldThr*2}//如果oldCap<0,但是已经初始化了,像把元素删除完之后的情况,那么它的临界值肯定还存在, 如果是首次初始化,它的临界值则为0else if (oldThr > 0) // initial capacity was placed in thresholdnewCap = oldThr;//数组未初始化的情况,将阈值和扩容因子都设置为默认值else { // zero initial threshold signifies using defaultsnewCap = DEFAULT_INITIAL_CAPACITY;newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);}//初始化容量小于16的时候,扩容阈值是没有赋值的if (newThr == 0) {//创建阈值float ft = (float)newCap * loadFactor;//判断新容量和新阈值是否大于最大容量newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?(int)ft : Integer.MAX_VALUE);}//计算出来的阈值赋值threshold = newThr;@SuppressWarnings({"rawtypes","unchecked"})//根据上边计算得出的容量 创建新的数组 Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];//赋值table = newTab;//扩容操作,判断不为空证明不是初始化数组if (oldTab != null) {//遍历数组for (int j = 0; j < oldCap; ++j) {Node<K,V> e;//判断当前下标为j的数组如果不为空的话赋值个e,进行下一步操作if ((e = oldTab[j]) != null) {//将数组位置置空oldTab[j] = null;//判断是否有下个节点if (e.next == null)//如果没有,就重新计算在新数组中的下标并放进去newTab[e.hash & (newCap - 1)] = e;//有下个节点的情况,并且判断是否已经树化else if (e instanceof TreeNode)//进行红黑树的操作((TreeNode<K,V>)e).split(this, newTab, j, oldCap);//有下个节点的情况,并且没有树化(链表形式)else {//比如老数组容量是16,那下标就为0-15//扩容操作*2,容量就变为32,下标为0-31//低位:0-15,高位16-31//定义了四个变量// 低位头 低位尾Node<K,V> loHead = null, loTail = null;// 高位头 高位尾Node<K,V> hiHead = null, hiTail = null;//下个节点Node<K,V> next;//循环遍历do {//取出next节点next = e.next;//通过 与操作 计算得出结果为0if ((e.hash & oldCap) == 0) {//如果低位尾为null,证明当前数组位置为空,没有任何数据if (loTail == null)//将e值放入低位头loHead = e;//低位尾不为null,证明已经有数据了else//将数据放入next节点loTail.next = e;//记录低位尾数据loTail = e;}//通过 与操作 计算得出结果不为0else {//如果高位尾为null,证明当前数组位置为空,没有任何数据if (hiTail == null)//将e值放入高位头hiHead = e;//高位尾不为null,证明已经有数据了else//将数据放入next节点hiTail.next = e;//记录高位尾数据hiTail = e;}} //如果e不为空,证明没有到链表尾部,继续执行循环while ((e = next) != null);//低位尾如果记录的有数据,是链表if (loTail != null) {//将下一个元素置空loTail.next = null;//将低位头放入新数组的原下标位置newTab[j] = loHead;}//高位尾如果记录的有数据,是链表if (hiTail != null) {//将下一个元素置空hiTail.next = null;//将高位头放入新数组的(原下标+原数组容量)位置newTab[j + oldCap] = hiHead;}}}}}//返回新的数组对象return newTab;}3 get方法
public V get(Object key) {Node<K,V> e;//hash(key),获取key的hash值//调用getNode方法,见下面方法return (e = getNode(hash(key), key)) == null ? null : e.value;
}final Node<K,V> getNode(int hash, Object key) {Node<K,V>[] tab; Node<K,V> first, e; int n; K k;//找到key对应的桶下标,赋值给first节点if ((tab = table) != null && (n = tab.length) > 0 &&(first = tab[(n - 1) & hash]) != null) {//判断hash值和key是否相等,如果是,则直接返回,桶中只有一个数据(大部分的情况)if (first.hash == hash && // always check first node((k = first.key) == key || (key != null && key.equals(k))))return first;if ((e = first.next) != null) {//该节点是红黑树,则需要通过红黑树查找数据if (first instanceof TreeNode)return ((TreeNode<K,V>)first).getTreeNode(hash, key);//链表的情况,则需要遍历链表查找数据do {if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))return e;} while ((e = e.next) != null);}}return null;
}觉得有用的话可以点点赞 (*/ω\*),支持一下。
如果愿意的话关注一下。会对你有更多的帮助。
每天都会不定时更新哦 >人< 。
相关文章:
Java [ 基础 ] HashMap详解 ✨
目录 ✨探索Java基础 HashMap详解✨ 总述 主体 1. HashMap的基本概念 2. HashMap的工作原理 3. HashMap的常用操作 4. HashMap的优缺点 总结 常见面试题 常见面试题解答 1. HashMap的底层实现原理是什么? 2. 如何解决HashMap中的哈希冲突?…...

vue2项目迁移vue3与gogocode的使用
#背景 公司有个项目使用vue2jswebpack框架开发的,由于该项目内部需要安扫,导致很多框架出现了漏洞需要升级,其中主要需要从vue2升vue3,但是重新搭框架推翻重做成本太高,于是找到了gogocode。 #升级步骤踩坑 1. 安装 gogocode插…...
 #正负交错数列前n项和 #求数列前n项的平方和)
【Python123题库】#数列求和 #百分制成绩转换五分制(循环) #正负交错数列前n项和 #求数列前n项的平方和
禁止转载,原文:https://blog.csdn.net/qq_45801887/article/details/140079866 参考教程:B站视频讲解——https://space.bilibili.com/3546616042621301 有帮助麻烦点个赞 ~ ~ Python123题库 数列求和百分制成绩转换五分制(循环)正负交错数列…...
Edge浏览器选中后,出现AI智能生成 AI专业写作
这个是扩展里边的“ 网页万能复制 & ChatGPT AI写作助手”造成的,这个拓展增加了AI写作功能。关闭这个拓展就解决了。...

c++习题08-计算星期几
目录 一,问题 二,思路 三,代码 一,问题 二,思路 首先,需要注意到的是3^2000这个数值很大,已经远远超过了long long 数据类型能够表示的范围,如果想要使用指定的数据类型来保存…...

单目相机减速带检测以及测距
单目相机减速带检测以及测距项目是一个计算机视觉领域的应用,旨在使用一个摄像头(单目相机)来识别道路上的减速带,并进一步估计车辆与减速带之间的距离。这样的系统对于智能驾驶辅助系统(ADAS)特别有用&…...
Xilinx FPGA:vivado实现乒乓缓存
一、项目要求 1、用两个伪双端口的RAM实现缓存 2、先写buffer1,再写buffer2 ,在读buffer1的同时写buffer2,在读buffer2的同时写buffer1。 3、写端口50M时钟,写入16个8bit 的数据,读出时钟25M,读出8个16…...

解决 VM 虚拟机网络连接异常导致的 Finalshell 无法连接及 ifconfig 中 ens33 丢失问题
在使用 VM 虚拟机的过程中,遇到了一个颇为棘手的网络连接问题。平时虚拟机都能够正常启动并使用,但昨天在启用虚拟机时更换了一下网络节点,结果今天打开虚拟机后。Finalshell 无法连接上虚拟机,并且输入 ifconfig 命令后也没有 en…...
)
深入Django(三)
Django视图(Views)详解 引言 在前两天的博客中,我们介绍了Django的基本概念和模型系统。今天,我们将深入探讨Django的视图(Views),它们是处理用户请求和返回响应的地方。 什么是Django视图&a…...

观测云赋能「阿里云飞天企业版」,打造全方位监控观测解决方案
近日,观测云成功通过了「阿里云飞天企业版」的生态集成认证测试,并荣获阿里云颁发的产品生态集成认证证书。作为监控观测领域的领军者,观测云一直专注于提供统一的数据视角,助力用户构建起全球范围内的端到端全链路可观测服务。此…...

51单片机第27步_单片机工作在睡眠模式
重点学习51单片机工作在睡眠模式。 1、进入“睡眠模式”的方法 通过将PCON寄存器中的PDWN置1,则CPU会进入“睡眠模式”。在“睡眠模式”中,晶振将停止工作,因此,定时器和串口都将停止工作,只有外部中断继续工作。如果单片机电源…...
互联网应用主流框架整合之SpringCloud微服务治理
微服务架构理念 关于微服务的概念、理念及设计相关内容,并没有特别严格的边界和定义,某种意义上说,适合的就是最好的,在之前的文章中有过详细的阐述,微服务[v1.0.0][Spring生态概述]、微服务[设计与运行]、微服务[v1.…...
超快的 Python 包管理工具「GitHub 热点速览」
天下武功,无坚不破,唯快不破! 要想赢得程序员的欢心,工具的速度至关重要。仅需这一优势,即可使其在众多竞争对手中脱颖而出,迅速赢得开发者的偏爱。以这款号称下一代极速 Python 包管理工具——uv 为例&…...

网络基础:OSPF 协议
OSPF(Open Shortest Path First)是一种广泛使用的链路状态路由协议,用于IP网络中的内部网关协议(IGP)。OSPF通过在网络中的所有路由器之间交换路由信息,选择从源到目的地的最优路径。OSPF工作在OSI模型的第…...

1456.定长子串中元音的最大数目
思路: 首次是滑动窗口, 然后遍历子字符串,这样复杂度太高,没过测试 改进,滑动窗口先求出第一个窗口中元音数量, 然后利用滑动式,一进一出方式判断首尾是否是原因即可 给你字符串 s 和整数 k 。 …...

基于xilinx FPGA的GTX/GTH/GTY位置信息查看方式(如X0Y0在bank几)
目录 1 概述2 参考文档3 查看方式4查询总结: 1 概述 本文用于介绍如何查看xilinx fpga GTX得位置信息(如X0Y0在哪个BANK/Quad)。 2 参考文档 《ug476_7Series_Transceivers》 《pg156-ultrascale-pcie-gen3-en-us-4.4》 3 查看方式 通过…...

JAVA小知识30:JAVA多线程篇1,认识多线程与线程安全问题以及解决方案。(万字解析)
来 多线程,一个学起来挺难但是实际应用不难的一个知识点,甚至在很多情况下都不需要考虑,最多就是写测试类的时候模拟一下并发,现在我们就来讲讲基础的多线程知识。 一、线程和进程、并发与并行 1.1、线程和进程 线程&am…...
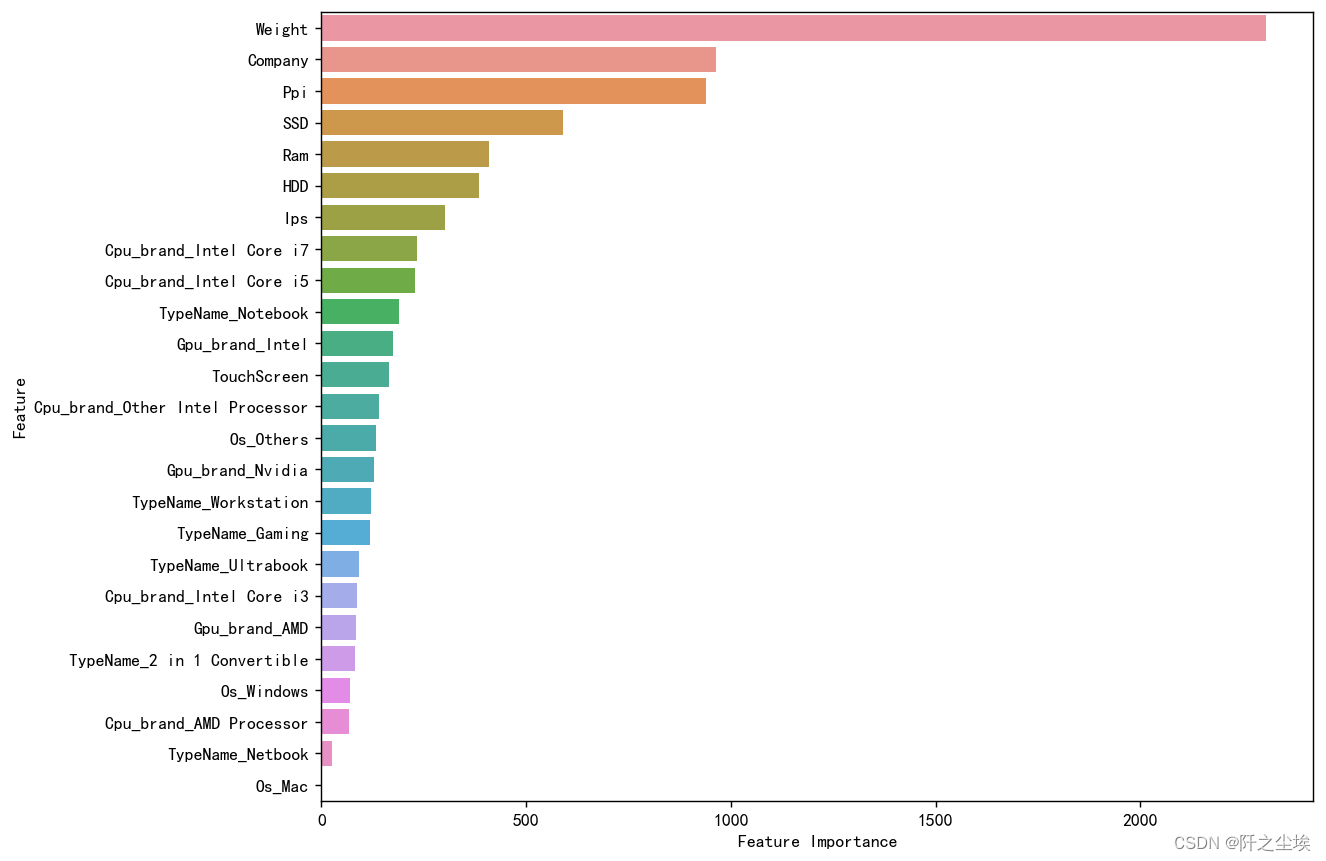
Python数据分析案例47——笔记本电脑价格影响因素分析
案例背景 博主对电脑的价格和配置一直略有研究,正好最近也有笔记本电脑相关的数据,想着来做点分析吧,写成一个案例。基本上描述性统计,画图,分组聚合,机器学习,交叉验证,搜索超参数…...

【加密与解密】【09】GPG Client签名流程
什么是GPG客户端 GPG客户端是实现PGP加密协议的一套客户端程序,可用于加密或签名 下载GPG客户端 建议安装命令行工具,图形工具一般不具备完整功能 https://gnupg.org/download/index.html生成私钥 此时会要求你输入名称,邮箱,…...

“2024软博会” 为软件企业提供集展示、交流、合作一站式平台
随着全球科技浪潮的涌动,软件行业正迎来前所未有的发展机遇,成为了全球新一轮竞争的“制高点”,以及未来经济发展的“增长点”。在当前互联网、大数据、云计算、人工智能、区块链等技术加速创新的背景下,数字经济已经渗透到经济社…...

Unity主题系统设计:状态驱动的主题抽象与自动注入方案
1. 这不是换个颜色那么简单:为什么Unity项目里“换肤”总在发布前夜崩盘?你有没有经历过这样的场景:美术同学凌晨两点发来一套新主题资源包,UI设计师说“这次配色更符合品牌调性”,产品说“上线前必须支持深色模式”&a…...

为内部知识库问答机器人接入Taotoken多模型增强回答效果
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为内部知识库问答机器人接入Taotoken多模型增强回答效果 构建一个高效的企业内部知识库问答机器人,核心挑战在于如何让…...

METSO A413248自动化系统
METSO A413248 自动化系统模块产品特点: 品牌归属:芬兰METSO(美卓)工业自动化系统原装备件。 产品类型:工业级自动化控制模块/接口模块。 核心功能:用于控制信号处理、数据采集及系统集成。 系统兼容&am…...

解密高校教师必会的Gemini 3.1 Pro五大科研隐藏技能:从论文评估到创新点锁定
各位同仁好,我是七哥。一个在高校里从事人工智能相关领域研究,钻研用大模型AI实操的学术人。可以和七哥交流学术写作或Gemini、GPT、Claude等大模型学术实操相关问题,多多交流,相互成就,共同进步。 科研路上,有人发完顶刊顺利晋升,有人还在为创新点抓耳挠腮。 大多数教…...

Spring Security OAuth2 /oauth/token 401原因与Content-Type规范
1. 问题现场还原:一个看似简单却让开发停摆两小时的/oauth/token请求刚接手一个老项目做安全加固,第一件事就是验证OAuth2密码模式的token获取流程。我照着文档写了一条curl命令:curl -X POST http://localhost:8080/oauth/token回车执行&…...

LVGL多页面开发避坑:用内部Timer替代轮询,解决页面切换时的内存踩踏问题
LVGL多页面开发中的内存安全实践:用Timer机制替代轮询的工程解决方案 在嵌入式UI开发中,LVGL因其轻量级和跨平台特性成为热门选择。但当项目复杂度提升到多页面交互时,开发者往往会遇到一个棘手问题:如何在频繁切换页面的同时保证…...

如何快速解锁中兴光猫权限:zteOnu工具完整使用指南
如何快速解锁中兴光猫权限:zteOnu工具完整使用指南 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 中兴光猫作为家庭网络的核心设备,其强大的硬件性能常常被默认…...

如何快速掌握MPC视频渲染器:面向初学者的完整教程
如何快速掌握MPC视频渲染器:面向初学者的完整教程 【免费下载链接】VideoRenderer Внешний видео-рендерер 项目地址: https://gitcode.com/gh_mirrors/vi/VideoRenderer 想要在Windows系统上获得影院级的视频播放体验吗?MPC…...

PlayAI实时翻译如何重构跨国协作效率?揭秘2024企业级应用的3个关键转折点
更多请点击: https://codechina.net 第一章:PlayAI实时翻译如何重构跨国协作效率?揭秘2024企业级应用的3个关键转折点 在远程办公常态化与全球供应链深度耦合的背景下,PlayAI 实时翻译已从辅助工具跃升为协同基础设施。其核心突破…...

机器学习势函数在高温超导材料缺陷与相变研究中的应用
1. 项目概述:当机器学习“遇见”高温超导的微观世界高温超导体,尤其是像YBa2Cu3O7(YBCO)这样的铜氧化物,一直是凝聚态物理和材料科学领域的“明星”材料。它们能在相对较高的温度下实现零电阻,为能源传输、…...