Java增加线程后kafka仍然消费很慢
文章目录
- 一、问题分析
- 二、控制kafka消费速度属性
- 三、案例描述
一、问题分析
Java增加线程通常是为了提高程序的并发处理能力,但如果Kafka仍然消费很慢,可能的原因有:
- 网络延迟较大:如果网络延迟较大,即使开启了多线程,也可能无法发挥作用。
- 线程数量不合理:如果线程数量过少,可能无法充分利用多核 CPU 的优势;如果线程数量过多,则会增加 CPU 调度和内存管理的开销,导致性能下降。
- 消息处理速度较慢:如果消息处理速度较慢,即使开启了多线程,仍然可能无法提高处理速度。
- Kafka 集群配置不合理:如果 Kafka 集群的配置不合理,例如分区数量过少,则可能导致消费速度较慢。
- 消费者和生产者之间的吞吐量不匹配:如果消费者的吞吐量远低于生产者,则可能导致消费速度较慢。
- 消息堆积:如果消费者无法及时处理消息,则可能导致消息堆积,从而降低消费速度。
- 其他原因:还可能是由于其他原因导致消费速度较慢,例如硬件性能较差、操作系统负载较高等。
解决方法:
检查Kafka服务器性能,确保硬件资源充足,Kafka配置优化。
如果是单线程处理能力不足,可以考虑使用多线程或增加处理能力的服务器。
检查消费者端配置,确保消费者数量足够,消费者组管理正常。
监控系统资源,如果资源不足,应进行扩容或优化。
具体解决方案需要结合实际情况分析日志、监控数据等,并根据实际情况调整配置或代码。
二、控制kafka消费速度属性
控制Kafka消费速度可以通过调整Kafka消费者客户端的配置参数来实现。以下是一些常用的参数及其说明:
-
max.poll.records: 单次调用poll()方法能够处理的最大记录数。
-
max.poll.interval.ms: 消费者处理一批消息的最大时间,超过这个时间则会被认为是"stalled"并被群组将其踢出。
概念:max.poll.interval.ms是Kafka消费者端的一个配置参数,用于设置消费者在轮询过程中处理消息的最大时间间隔。如果消费者在该时间间隔内没有完成消息处理,则被认为失去了与消费者组的连接,将被视为故障,分区将被重新分配给其他消费者。
最佳实践:合理设置max.poll.interval.ms对于保证消费者组的稳定运行和消息处理的及时性非常重要。以下是一些最佳实践建议:
根据实际业务需求和消息处理的复杂性,设置合理的max.poll.interval.ms值,以确保消费者有足够的时间来处理消息。
考虑到网络延迟和消息处理的时间,建议将max.poll.interval.ms设置为较大的值,以避免过早地将消费者标记为故障。
同时,也要注意将max.poll.interval.ms设置为一个合理的值,以避免消费者长时间无响应而导致消息处理的延迟。 -
fetch.min.bytes: 服务器响应请求的最小数据量,默认为1(即最小响应大小为1字节)。
-
fetch.max.bytes: 服务器响应请求的最大数据量,默认为52428800(大约50MB)。
以下是一个使用kafka-python库的示例,展示如何设置这些参数:
from kafka import KafkaConsumer# 设置消费者配置
consumer_config = {'bootstrap_servers': 'localhost:9092','group_id': 'my-group','auto_offset_reset': 'earliest','max_poll_records': 500, # 单次poll()调用最多消费500条消息'max_poll_interval_ms': 300000, # 最大轮询间隔设置为5分钟'session_timeout_ms': 6000, # 心跳超时设置为6秒'fetch_min_bytes': 1, # 最小响应大小'fetch_max_bytes': 5242880 # 最大响应大小设置为5MB
}# 创建消费者实例
consumer = KafkaConsumer('my-topic',**consumer_config
)for message in consumer:# 处理消息print(message.value)
在实际应用中,你可能需要根据实际情况调整这些参数以达到最佳的消费速度。例如,如果你希望消费者能够更快地跟上数据生产的速度,你可能需要降低max.poll.interval.ms的值;相反,如果你希望控制消费者的吞吐量以避免影响下游系统,你可能需要增加max.poll.records的值。
三、案例描述
1.增加并行度,每次拉取记录数,仍然堆积,赶不上生产速度
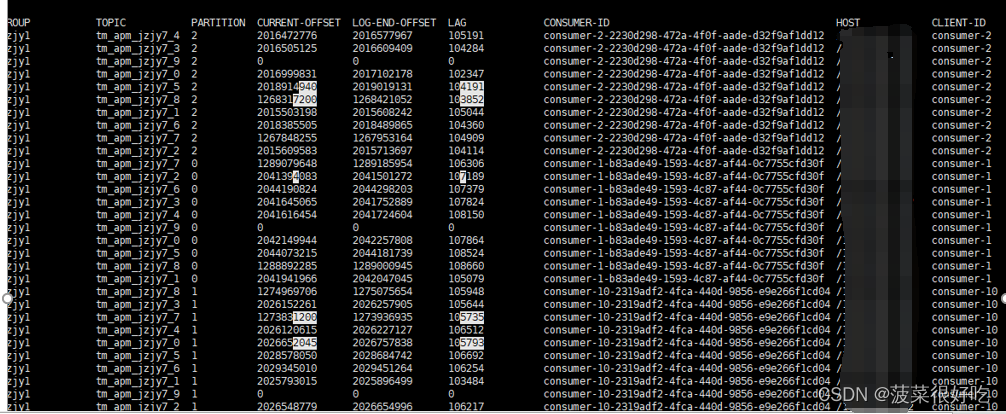
后台运行正常:
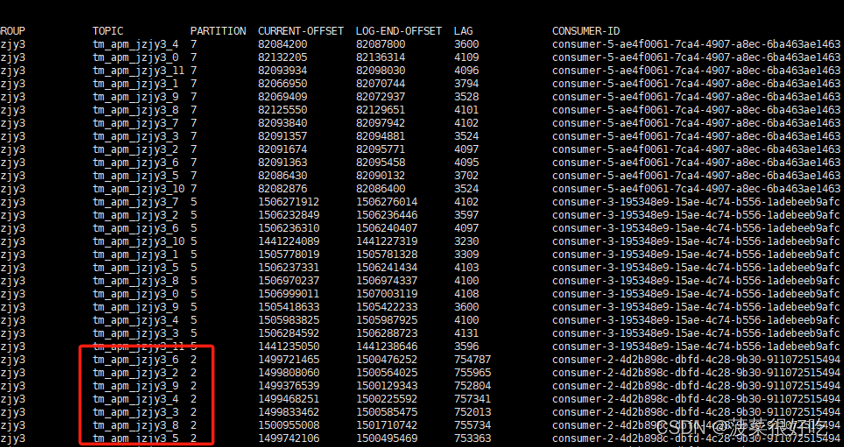
重启从最新消费,仍然有部分分区出现堆积
轮询间隔:
ConsumerRecords<String, String> records = consumer.poll(1000);
场景描述:
1.在堆积大量数据情况下,服务极限运行,此时无论增加多少并行度都不起作用。打印拿到数据后业务处理时间不足1秒,每次拉取500条,消费列表依然堆积增大。
2.偶尔出现心跳超时,导致kafka重新reblance,提示减少每次拉取数量,增大轮询间隔
解决1:
1.consumer.poll方法中设置的超时时间取决于你的应用程序的需求。如果你希望消费者尽可能频繁地轮询Kafka以获取消息,可以设置一个较小的超时时间。如果你希望消费者在没有消息可消费时进入休眠状态,可以设置一个较大的超时时间。
超时时间设置的大小需要考虑以下因素:
消息处理的及时性:如果你希望消息能够得到及时处理,则需要设置较小的超时时间。
网络延迟:如果你的网络延迟较高,则可能需要设置更长的超时时间。
资源使用:过长的超时时间会导致CPU和内存资源的无效占用。
一个合适的超时时间设置可能是100到500毫秒。这个时间足够短,可以保证及时检查新消息,而长于网络延迟,从而避免无意的轮询开销。
// 创建消费者实例
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);// 轮询消息,超时时间设置为100ms
while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));for (ConsumerRecord<String, String> record : records) {// 处理消息}
}
在这个例子中,poll方法被调用时设置了一个100毫秒的超时时间。这样可以在有消息可消费时及时处理它们,同时在没有消息时减少CPU的使用。
相关文章:
Java增加线程后kafka仍然消费很慢
文章目录 一、问题分析二、控制kafka消费速度属性三、案例描述 一、问题分析 Java增加线程通常是为了提高程序的并发处理能力,但如果Kafka仍然消费很慢,可能的原因有: 网络延迟较大:如果网络延迟较大,即使开启了多线…...

分布式事务实现技术及考虑点
什么是分布式事务? 首先理解什么是本地事务 平时我们在程序中通过Spring去控制事务是利用数据库本身的事务特性来实现的,因此叫数据库事务,由于应用主要靠关系数据库来控制事务,而数据库通常和应用在同一个服务器,所…...

JavaScript中闭包的理解
闭包(Closure)概念:一个函数对周围状态的引用捆绑在一起,内层函数中访问到其外层函数的作用域。简单来说;闭包内层函数引用外层函数的变量,如下图: 外层在使用一个函数包裹住闭包是对变量的保护,…...
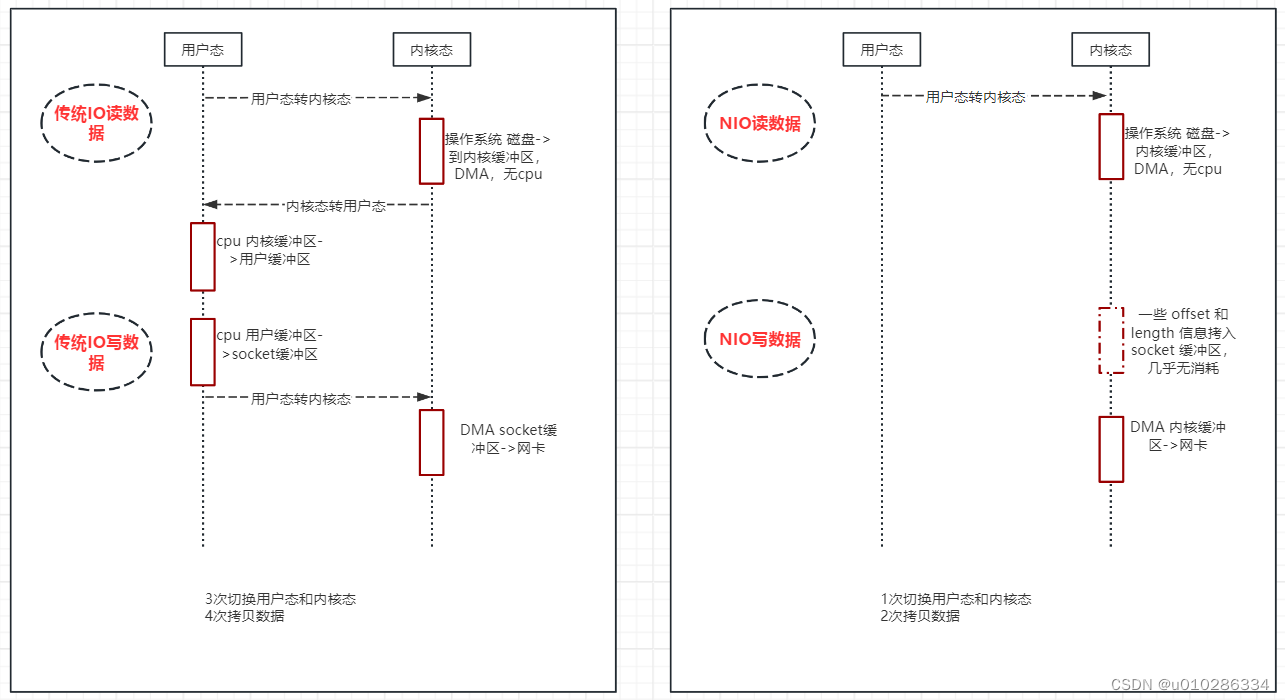
传统IO和NIO文件拷贝过程
参考:https://blog.csdn.net/weixin_57323780/article/details/130250582...
算法思想总结:优先级队列
一、最后一块石头的重量 . - 力扣(LeetCode) 我们每次都要快速找到前两个最大的石头进行抵消,这个时候用优先级队列(建大堆),不断取堆顶元素是最好的!每次删除堆顶元素后,可以自动调整…...

《米小圈日记魔法》边看边学,轻松掌握写日记的魔法!
在当今充满数字化娱乐和信息快速变迁的时代,如何创新引导孩子们学习,特别是如何培养他们的写作能力,一直是家长和教育者们关注的焦点。今天就向大家推荐一部寓教于乐的动画片《米小圈日记魔法》,该系列动画通过其独特的故事情节和…...

鸿蒙应用实践:利用扣子API开发起床文案生成器
前言 扣子是一个新一代 AI 应用开发平台,无需编程基础即可快速搭建基于大模型的 Bot,并发布到各个渠道。平台优势包括无限拓展的能力集(内置和自定义插件)、丰富的数据源(支持多种数据格式和上传方式)、持…...
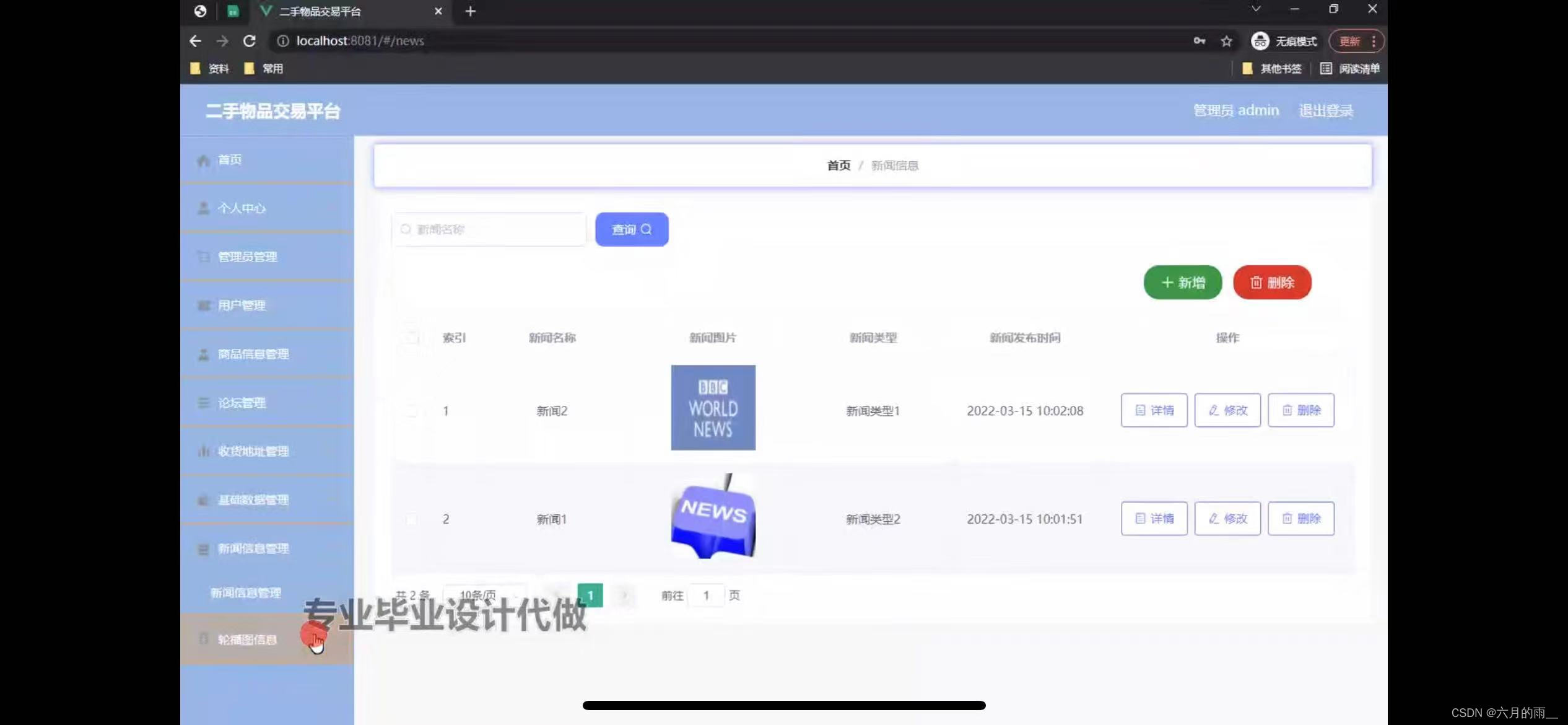
二手物品交易小程序的设计
管理员账户功能包括:系统首页,个人中心,用户管理,管理员管理,商品信息管理,论坛管理,收货地址管理,基础数据管理 微信端账号功能包括:系统首页,商品信息&…...
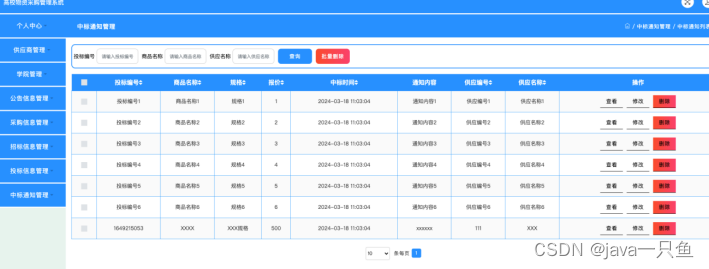
基于Spring Boot的高校智慧采购系统
1 项目介绍 1.1 摘要 随着信息技术与网络技术的迅猛发展,人类社会已跨入全新信息化纪元。传统的管理手段因其内在局限,在处理海量信息资源时日渐捉襟见肘,难以匹配不断提升的信息管理效率和便捷化需求。顺应时代发展趋势,各类先…...
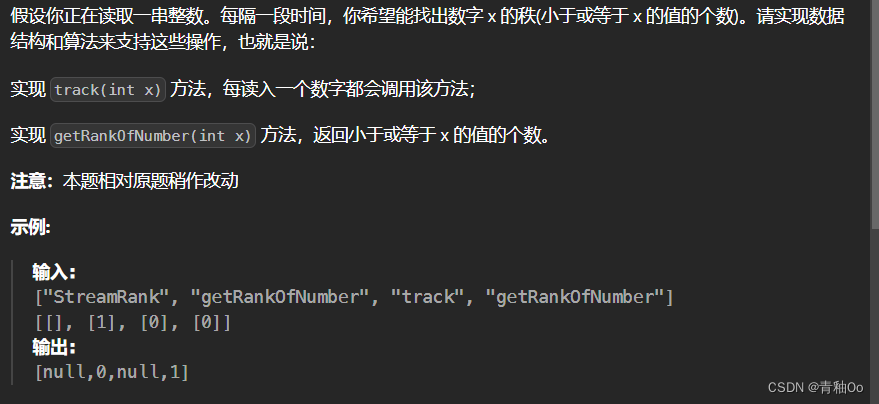
数字流的秩
题目链接 数字流的秩 题目描述 注意点 x < 50000 解答思路 可以使用二叉搜索树存储出现的次数以及数字的出现次数,方便后续统计数字x的秩关键在于构建树的过程,如果树中已经有值为x的节点,需要将该节点对应的数字出现次数加1…...
简介_常用方法及说明)
【mybatis】mybatis-plus中Wrapper(条件构造器)简介_常用方法及说明
1、简介 MyBatis-Plus 是一个 MyBatis 的增强工具,在 MyBatis 的基础上只做增强不做改变,为简化开发、提高效率而生。MyBatis-Plus 提供了强大的条件构造器(Wrapper),用于构建复杂的 SQL 查询条件,使得我们…...

IT专业入门:高考假期预习指南
七月,是一个充满转折与希望的月份。随着各省高考分数的揭晓,许多有志于踏入IT领域的少年们正站在新旅程的起点上。高考的完结并不意味着学习的结束,相反,它是一个全新的开始,一个探索未知世界的绝佳时机。作为IT领域的…...
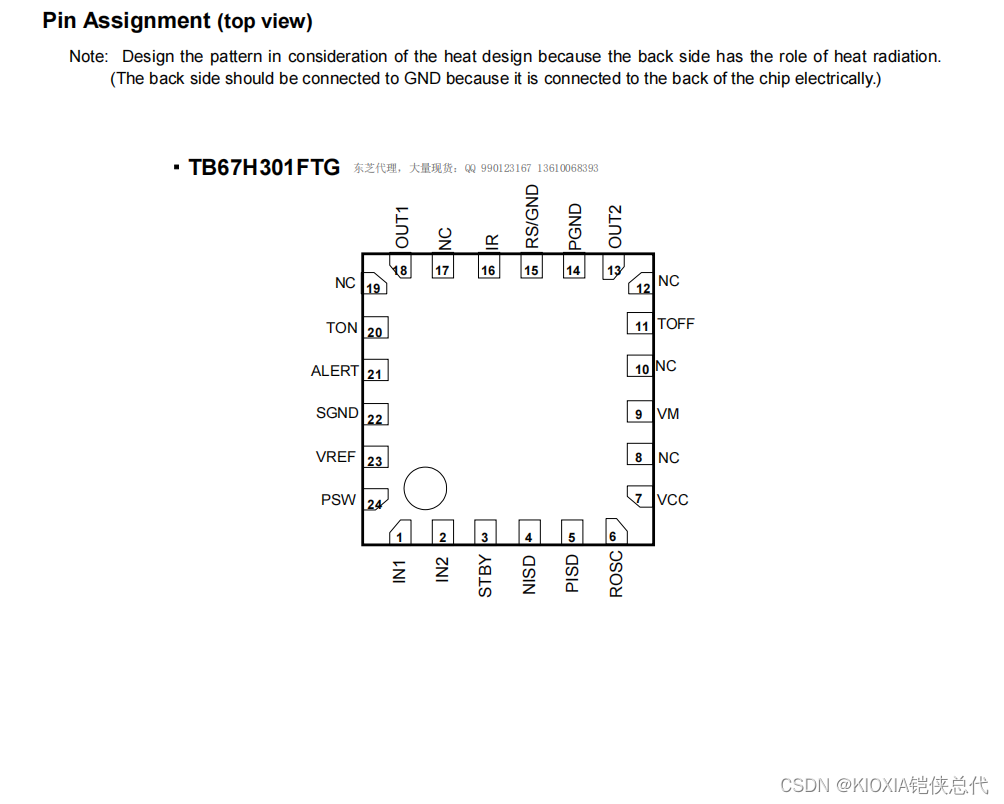
推动高效能:东芝TB67H301FTG全桥直流电机驱动IC
在如今高度自动化的时代,电子产品的性能和效率成为了工程师们关注的焦点。东芝的TB67H301FTG全桥直流电机驱动IC应运而生,以其卓越的技术和可靠性,成为众多应用的理想选择。无论是在机器人、家用电器、工业自动化,还是在其他需要精…...

Matplotlib 中文显示
Matplotlib 中文显示 Matplotlib 是一个强大的 Python 绘图库,广泛应用于数据可视化领域。然而,对于中文用户来说,Matplotlib 的默认设置可能不支持中文显示,这给使用带来了一定的不便。本文将详细介绍如何在 Matplotlib 中正确显示中文,包括中文字符的字体选择、字体大小…...

【LeetCode:841. 钥匙和房间 + DFS】
🚀 算法题 🚀 🌲 算法刷题专栏 | 面试必备算法 | 面试高频算法 🍀 🌲 越难的东西,越要努力坚持,因为它具有很高的价值,算法就是这样✨ 🌲 作者简介:硕风和炜,…...
并发事务的问题)
1)并发事务的问题
1) 并发事务的问题? (1)读“脏”数据 事务T1修改数据后T2读取了该数据,但是T1撤消了修改, 事务T1进行了回滚,导致事务T2读取的数据与数据库中的数据不一致。(2)丢失修改 两个事务…...

Python缓存利器:cachetools库详解
Python缓存利器:cachetools库详解 1. cachetools简介2. 安装3. 基本概念3.1 LRU Cache (Least Recently Used)3.2 TTL Cache (Time-To-Live)3.3 LFU Cache (Least Frequently Used) 4. 使用示例4.1 使用LRU Cache4.2 使用TTL Cache4.3 使用LFU Cache4.4 缓存装饰器 5. 进阶用法…...
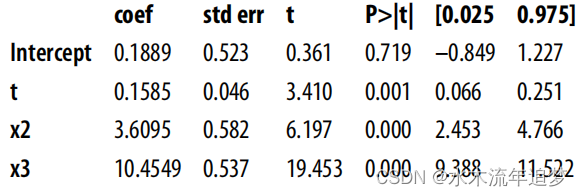
【Python实战因果推断】20_线性回归的不合理效果10
目录 Neutral Controls Noise Inducing Control Feature Selection: A Bias-Variance Trade-Off Neutral Controls 现在,您可能已经对回归如何调整混杂变量有了一定的了解。如果您想知道干预 T 对 Y 的影响,同时调整混杂变量 X,您所要做的…...

在Ubuntu 16.04上安装和配置ownCloud的方法
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。 简介 ownCloud 是一个文件共享服务器,允许您将个人内容(如文档和图片)存储在一个类似 Dropbox 的集…...

Java | Leetcode Java题解之第213题打家劫舍II
题目: 题解: class Solution {public int rob(int[] nums) {int length nums.length;if (length 1) {return nums[0];} else if (length 2) {return Math.max(nums[0], nums[1]);}return Math.max(robRange(nums, 0, length - 2), robRange(nums, 1,…...

【SpringBoot+Elasticsearch 内容搜索系统实战】:架构设计与全流程实现
🔥你好我是fengxin_rou这是我的个人主页fengxin_rou的主页 ❄️欢迎查看我的专栏我的专栏 《Java后端学习》、《JAVASE基础》、《JUC并发》、《redis》、《JVM虚拟机》、《MYSQL》、《黑马点评》、《rabbitmq》、《JavaWebAI的talis学习系统》、《苍穹外卖》 目录…...

对比自建代理,使用Taotoken聚合平台在稳定性与运维上的体验提升
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比自建代理,使用Taotoken聚合平台在稳定性与运维上的体验提升 过去,一些开发团队为了便捷地使用特定的大…...

【车辆路径规划】基于RRT算法的车辆导航工具箱实现附matlab代码
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、程序设计科研仿真。🍎完整代码获取 定制创新 论文复现点击:Matlab科研工作室👇 关注我领取海量matlab电子书和数学建模资料 dz…...
:覆盖AI伦理、碳足迹追踪与社区赋能的3层合规架构)
Gemini企业社会责任实践白皮书(2024独家解密版):覆盖AI伦理、碳足迹追踪与社区赋能的3层合规架构
更多请点击: https://codechina.net 第一章:Gemini企业社会责任实践白皮书(2024独家解密版)概览 本白皮书首次系统披露Google Gemini大模型在2024年度面向环境可持续性、AI伦理治理、数字包容性及社区赋能四大维度的企业社会责任…...

Grafana告警规则配置实战
Grafana告警规则配置实战 一、Grafana告警概述 Grafana提供强大的告警功能,可以基于Prometheus等数据源触发告警通知。 1.1 告警流程 ┌────────────────────────────────────────────────────────────…...

Python之ansimagic包语法、参数和实际应用案例
Python ansimagic包完整详解:功能、安装、语法、案例、排错 ansimagic 是Python轻量级终端动画/字符动画工具包,专注于在命令行(CMD、Terminal、PowerShell)中生成流畅的动态字符效果、进度条、加载动画、文字动画、ASCII动画等。…...
)
企业ESG披露合规危机应对指南(2024欧盟CSRD强制落地倒计时)
更多请点击: https://intelliparadigm.com 第一章:CSRD法规核心要义与企业合规临界点 欧盟《企业可持续发展报告指令》(CSRD)已于2024年1月1日正式生效,取代原有的NFRD,显著扩大了适用范围与披露深度。其核…...

《元创力》纪实录·桥段静默纪元:当叙事成为被审计的风险资产
X54先生叙事前的话:叙事模式:X54先生提供参考角度(可以不选)审查机构事先不对事实审查给了拍摄权和公映权,舆论压力出现,又要倒查,是从一个错误走向另一个错误,这会导致文艺创作者因…...

【Google官方未公开】Gemini免费层底层计费逻辑揭秘:按token粒度精算,92%用户多花了37%配额
更多请点击: https://codechina.net 第一章:Gemini免费额度的本质与边界认知 Gemini 的免费额度并非无条件的“无限试用”,而是由 Google Cloud 的配额管理系统(Quota System)严格管控的服务配额,其本质是…...
)
保姆级教程:在Ubuntu 20.04上搞定浙大lidar_IMU_calib(从编译到避坑)
保姆级教程:在Ubuntu 20.04上搞定浙大lidar_IMU_calib(从编译到避坑)当激光雷达(LiDAR)和惯性测量单元(IMU)需要协同工作时,标定这两个传感器之间的外参是必不可少的步骤。浙大开源项…...