「多模态大模型」解读 | 突破单一文本模态局限
编者按:理想状况下,世界上的万事万物都能以文字的形式呈现,如此一来,我们似乎仅凭大语言模型(LLMs)就能完成所有任务。然而,理想很丰满,现实很骨感——数据形态远不止文字一种,大多数数据也不是以文本的形式呈现的,我们日常接触到的数据涵盖了图像、视频、音频、语音(images or video, audio, speech)等多种形态,形式丰富多元。因此,能够同时理解和处理多种数据形式的多模态大语言模型(Multimodal Large Language Model,MLLM)应运而生。
构建 MLLM 的关键在于将大语言模型与各种模态的编码器(如图像编码器)相结合,实现跨模态的语义一致性映射。著名的 CLIP 模型就是一个典范,它能将语义相似的图像和文本映射到向量空间中的相邻位置。通过这种方式,机器不仅能够“读懂”图像、视频的内容,更能在多模态数据的基础上展开复杂的推理、创作等高级认知活动。
本文阐述了多模态技术的重要意义,深入剖析了 MLLM 的核心架构和运作原理,并盘点了三种主流的多模态系统构建方式。无疑,这是一篇观点透彻,内容丰富,极具科普价值的佳作。相信通过这篇文章,各位读者一定能够对 MLLM 有更加全面深入的了解。
作者 | Ignacio de Gregorio
编译 | 岳扬
尽管 AGI 可能不会很快出现,但大语言模型确实正通过一种名为“多模态”的形式迎来革新。这一进展使前沿模型从单一的文字处理模型进化为能够同时处理多种数据类型的全能模型,即所谓的多模态大语言模型(MLLMs)。
当下,诸如 ChatGPT、Gemini、Claude 等许多模型,已不再局限于大语言模型(LLMs)范畴,而是升级为多模态大语言模型(MLLMs),因为它们具备处理文本、图像的能力,甚至部分情况下还能处理视频。
然而,在进一步探讨之前,我们有必要思考:我们为什么需要多模态模型?
01 为何我们需要多模态?
理想状况下,世界上的万事万物都能以文字的形式呈现,如此一来,我们似乎仅凭大语言模型(LLMs)就能完成所有任务。然而,理想很丰满,现实很骨感——数据形态远不止文字一种,大多数数据也不是以文本的形式呈现的,我们日常接触到的数据涵盖了图像、视频、音频、语音(images or video, audio, speech)等多种形态,形式丰富多元。
事实上,使用 AI 解决那些最具挑战性的问题时,恰恰需要依赖多模态的处理能力。
试想一下,当我们使用虚拟助手(virtual assistant)时,可能希望它能识别并解答手部新出现的划痕或炎症问题;或是当我们在亚洲旅行途中偶遇一道陌生美食,期待它能生动描述这道佳肴的具体细节。

source: https://github.com/kohjingyu/gill?tab=readme-ov-file
那么,究竟如何才能搭建出一个多模态大语言模型(MLLM)呢?
02 深入解析多模态模型架构
简而言之,目前大多数多模态大语言模型(MLLMs)的核心构成包括两大部分:大语言模型(LLM)及另一种模态的编码器。让我们逐步揭开其神秘面纱。
2.1 大语言模型(LLMs),AI 领域的中流砥柱
LLMs 这类模型属于 sequence-to-sequence 架构,其工作原理为接收文本输入,然后输出统计学上最有可能的后续序列。
换言之,它们通过不断预测下一个词汇,生成流畅且文采斐然的文本。自 2022 年 ChatGPT 发布以来,大语言模型迅速成为了全球逾 2 亿用户手中的生产力利器,同名应用程序也一举创下了史上增长速度最快的 C 端应用记录。
尤其值得一提的是,它们卓越的模拟逻辑推理(imitate reasoning)和激发创新思维(enhance creative processes)的能力,激起了业界关于能否将此类系统作为基础架构,应用于更为复杂多变、不局限纯文本处理场景的广泛讨论。
然而,要实现这一目标,还需引入一个关键的辅助模块。
2.2 编码器:连接至多元数据世界的桥梁
大语言模型(LLMs)主要处理文本(在某些情况下也会处理代码,因其与自然语言有相似的性质)。因此,要处理图像甚至视频等其他数据类型,模型需引入另一个新部件 —— 编码器(encoder)。
其原因在于,LLMs 属于纯解码器架构的 Transformer,意味着它们会采用一种特殊手法来对数据进行编码。
但,“对数据进行编码”是什么意思呢?
无论处理的是文本里的字词(words)或是图像中的像素点(pixels),对输入序列进行编码的核心思想是将其转化为一系列数字,即所谓的向量嵌入(vector embeddings)。这种向量形式的表征(representation),能够捕捉输入序列的语义信息。
特别是 LLMs 拥有 embedding look-up matrices(译者注:就像是一个巨大的字典,每个词汇对应着一个在高维空间中的向量表征。例如,假设有一个包含 10000 个词汇的词汇表,每个词汇都有一个 50 维的向量表征,那么这个 embedding look-up matrices 就会是一个 10000 行、50 列的矩阵。每一行对应词汇表中的一个词,存储了该词的 50 维向量。在模型处理文本时,它会根据输入内容的词汇索引在这个矩阵中查找相应的向量,作为该词的嵌入表征。)。这些矩阵的作用是从输入序列的令牌中,提取出对应的词嵌入。换言之,模型在训练阶段会学习如何将输入的词(或tokems)转换为向量表征(即嵌入),这一过程是通过优化模型参数完成的,在推理阶段,当新的输入序列传入模型时,模型会直接使用已学习到的参数来产生相应的嵌入向量,而不需要再经历一个单独的、显式的编码步骤。
这是一种经济高效的数据编码方式,无需每次处理都启动编码网络(encoder network)。
对数据进行编码(Encoding data)有两种基本形式:独热编码(one-hot)或稠密编码(dense)。独热编码(One-hot encoding)的原理是,把每个词汇转换成一串数字,其中大部分数字为‘0’,而唯一的一个数字标记为‘1’:

source: https://medium.com/intelligentmachines/word-embedding-and-one-hot-encoding-ad17b4bbe111
但就 MLLMs 而言,嵌入是 “稠密(dense)” 的,这意味着,现实生活中相近的概念在向量空间中也会拥有相近的向量表征,包括向量的大小和方向,反之亦然:

source: https://arize.com/blog-course/embeddings-meaning-examples-and-how-to-compute/
为了达成目标,我们需要编码器 —— 一种基于 Transformer 设计的工具,它的任务是接收各种输入数据,并巧妙地将其转化为向量嵌入。举个例子,当编码器面对的是图像时,它能够将图像信息转换为“图像嵌入(image embedding)”形式。
不管处理的是何种数据模态,我们的目标始终一致:构建出一个向量空间,在这里,现实中意义相近的概念会被映射为接近的向量,而意义迥异的概念则会转化成相距甚远的向量。 通过这种方式,我们把对世界语义的理解转变成了一项数学问题;向量间的距离越短,意味着它们代表的概念含义越接近。
最关键的是,这种处理方法并不局限于文本领域,图像等其他数据模态也同样适用,这正是其独特魅力所在。

Encoding images. Image generated by author
但对于图像来说,事情就变得棘手了。
我们不仅希望图像的嵌入过程(image embedding)能将相似的图像(比如哈士奇的图像)归类到相似的向量类别中,而且还希望这些向量与同一图像的文字描述也保持相似性。例如,如下图所示,一幅描绘波浪的图像和一段描述相同场景的文本,尽管来自不同的模态,但应该具有相似的向量嵌入。
为了达到这一目的,OpenAI 等实验室开发了像 CLIP 这样的模型,这些模型创建了 mixed embedding spaces(译者注:在 mixed embedding spaces 中,不同模态的输入数据通过特定的编码器映射到同一向量空间内,这样即使数据的原始模态不同,也可以基于其内在的语义相似性进行比较。),在这个向量空间中,描述语义(text describing semantically)上概念相似的图像和文本会被赋予相似的向量,从而实现了跨模态的语义一致性。

source: https://blog.dataiku.com/leveraging-joint-text-image-models-to-search-and-classify-images
由于 CLIP 这类模型的出现,如今的机器已经具备了处理图像并洞察其含义的能力。
Masked AutoEncoders(MAEs)是另一种训练图像编码器(image encoders)的主流方法。在这种情况下,模型接收到的是一幅部分信息被掩盖的图像,模型需要重建完整图像。这些编码器之所以强大,是因为它们必须学会从残缺的信息中推断出“遮挡之下”的真相(what’s hiding behind the masked parts),即识别出“被隐藏的部分”是什么(what’s missing)。
不过,对于多模态语言模型(MLLMs)而言,CLIP 编码器的应用更为广泛,主要是由于其与文本处理之间存在着天然的联系。
然而,如果我们希望建立一个像 ChatGPT 那样,能够同时处理图像和文本的模型,我们又该如何着手搭建这样一个系统呢?
03 多模态系统的主要类型
创建多模态系统主要有三种方法。
3.1 从通过工具实现多模态系统到真正的多模态大语言模型(MLLM)
有三类方法构建 MLLM 系统,但仅两类可称得上是真正的多模态大语言模型。
- Tool-Augmented LLMs:这类方案是将大语言模型(LLMs)与可以处理其他类型数据的外部系统相结合。这些系统并不算作多模态大语言模型,因为我们仅仅是通过集成另一个模型或工具来扩展大语言模型的功能。以 ChatGPT 的语音/音频处理功能为例,实际上它是将大语言模型与语音转文本(Speech-to-Text)及文本转语音(Text-to-Speech)两个独立模型相连。这样,每当模型接收到音频,就将其转交给这些系统处理,而非真正的多模态大语言模型直接处理数据。
- Grafting:该方法是指将两个已经训练完成的组件 —— 编码器(encoder)和大语言模型(LLMs) —— 拼接起来形成多模态大语言模型。因为它具有很高的成本效益比,这种方法在开源社群中极为流行,通常只需训练一个适配器(adapter)来连接这两个预训练模型。
- Native MLLM(Generalist Systems):此途径为那些最热门且财力充足的人工智能研究机构所采纳。其核心在于一开始就将大语言模型和编码器连接在一起,从零开始进行训练。虽然这种方式能带来最优效果,但同时也是最烧钱的。GPT-4V(ChatGPT)、Grok 1.5V、Claude 3 与 Gemini 等皆属此类方法的应用实例。
我们或许还可以考虑另一种方法,那就是在不使用 separate encoder(译者注:在多模态或多任务学习架构中独立处理不同类型输入数据的编码器。) 的情况下构建MLLM,Adept 的 MLLMs 就属于这种情况。不过,使用这种方法构建的多模态模型相当罕见。
不论是选择第二种还是第三种方案(再次强调一次,第一种方案其实并非纯粹的 MLLM 模型,而是一套 MLLM 系统),它们的工作原理是什么呢?
3.2 The MLLM pipeline
我们将重点讨论最常见的 MLLM 方案(即结合图像编码器(image encoder)和 LLMs 的第二种方案)构建能同时处理图像与文本的多模态模型。有一点需要在此强调,这种方案只要更换编码器,也能处理其他模态的数据,比如使用音频编码器处理音频信号。 LLMs 因其具备与用户交流及在某些特定情形下处理复杂问题的能力,始终是不可或缺的组成部分。
向 MLLM 输入数据,通常遵循两种模式:
- 纯文本:在这种情况下,我们仅向模型输入文本信息,因此我们只希望让模型如同常规 LLM 一样运行。若想深入了解这一过程的具体细节,请阅读此处有关 Transformers 的博文(https://thewhitebox.ai/transformers-the-great-paradigm-shift/ )。
- 图文并茂:在此情形下,模型接收到的是一张图片及其相关的文本描述。接下来,我们将重点探讨这种情况。
以 Sphinx 为例,这是一个开源的多模态 LLM,让我们以此为参照。

source: https://arxiv.org/pdf/2311.07575.pdf
- 目前,我们手头的数据是一幅描绘狮身人面像的卡通图像,以及对该图像的文本描述,我们希望 MLLM 能够同时解析这两部分内容,并能够描述图像所描绘的内容。
- 随后,图像被划分为若干小块(本例中,他们还额外生成了一个低分辨率的小块(patch),以较低的分辨率表示完整的图像)
- 这些小块随后被送入图像编码器,由其进行处理并生成相应的嵌入向量(patch embeddings)。每一项嵌入都精准地反映了其所代表图像区域的含义。
此时,会有两种情况发生。如果采用的是先分别预训练图像编码器和 LLM,后续再结合的方法,一般会使用一个适配器(adapter),将图像嵌入转化为与 LLM 嵌入空间相匹配的形式。而如果使用的是通用方法,图像编码器在设计之初就已具备为 LLM 生成有效嵌入的能力。
- 与此同时,图像的文本描述同样被输入至模型中。在本例中,文本序列(text sequences)遵循了我们之前在介绍 Transformer LLMs 时所述的流程(分词、查找嵌入向量、拼接位置嵌入(positional embedding)以及执行插入(insertion)操作)
- 至此,LLM 将所有输入整合为单一序列,并依据图像与文本输入共同提供的信息,生成新的序列。
04 Final Thoughts
多模态大语言模型(Multimodal Large Language Models,简称 MLLMs)是当前生成式人工智能最先进技术的重要组成部分。MLLMs 凭借单一模型即可实现多种模态数据的处理,开启了以前只能想象的许多前景广阔的应用场景。
多模态也拉近了机器与人类的距离,因为人类生来就是通过多种感官实现多模态的。所以,机器迟早会模仿人类的这一特性。
在追求构建通用人工智能(Artificial General Intelligence,简称 AGI)或超人工智能(Artificial Super Intelligence,简称 ASI)的过程中,多模态起着至关重要的作用。因为人类之所以能够成为今天的智能生物,很大程度上归功于我们具备处理和理解多种模态数据的能力,这让我们能够适应并驾驭周遭的生存环境。
因此,多模态对于机器人而言是进入物理世界的关键要素,它使得机器能够像人类一样观察、感知、聆听并和我们所处的物理世界进行互动。
Thanks for reading!
Ignacio de Gregorio
I break down frontier AI systems in easy-to-understand language for you. Sign up to my newsletter here: https://thetechoasis.beehiiv.com/subscribe
END
原文链接:
https://thewhitebox.ai/mllm-multiple-modalities-one-model/
相关文章:
「多模态大模型」解读 | 突破单一文本模态局限
编者按:理想状况下,世界上的万事万物都能以文字的形式呈现,如此一来,我们似乎仅凭大语言模型(LLMs)就能完成所有任务。然而,理想很丰满,现实很骨感——数据形态远不止文字一种&#…...

Redis深度解析:核心数据类型与键操作全攻略
文章目录 前言redis数据类型string1. 设置单个字符串数据2.设置多个字符串类型的数据3.字符串拼接值4.根据键获取字符串的值5.根据多个键获取多个值6.自增自减7.获取字符串的长度8.比特流操作key操作a.查找键b.设置键值的过期时间c.查看键的有效期d.设置key的有效期e.判断键是否…...
C语言 指针和数组——指针的算术运算
目录 指针的算术运算 指针加上一个整数 指针减去一个整数 指针相减 指针的关系比较运算 小结 指针的算术运算 指针加上一个整数 指针减去一个整数 指针相减 指针的关系比较运算 小结 指针变量 – 指针类型的变量,保存地址型数据 指针变量与其他类型…...

[C++][CMake][CMake基础]详细讲解
目录 1.CMake简介2.大小写?3.注释1.注释行2.注释块 4.日志 1.CMake简介 CMake是一个项目构建工具,并且是跨平台的 问题 – 解决 如果自己动手写Makefile,会发现,Makefile通常依赖于当前的编译平台,而且编写Makefile的…...

CCD技术指标
CCD尺寸,即摄象机靶面。原多为1/2英寸,现在1/3英寸的已普及化,1/4英寸和1/5英寸也已商品化。CCD像素,是决定了显示图像的清晰程度,。CCD是由面阵感光元素组成,每一个元素称为像素,像素越多&…...
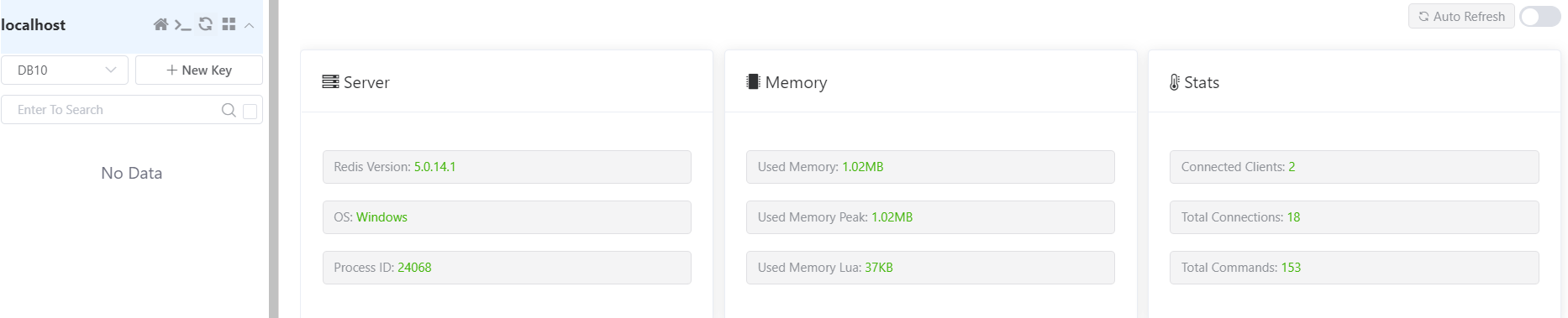
SpringBoot系列——使用Spring Cache和Redis实现查询数据缓存
文章目录 1. 前言2. 缓存2.1 什么是缓存2.2 使用缓存的好处2.3 缓存的成本2.4 Spring Cache和Redis的优点 3. Spring Cache基础知识3.1 Spring Cache的核心概念3.2 Spring Cache的注解3.2.1 SpEL表达式3.2.2 Cacheable3.2.3 CachePut3.2.4 CacheEvict 4. 实现查询数据缓存4.1 准…...

【算法】(C语言):冒泡排序、选择排序、插入排序
冒泡排序 从第一个数据开始到第n-1个数据,依次和后面一个数据两两比较,数值小的在前。最终,最后一个数据(第n个数据)为最大值。从第一个数据开始到第n-2个数据,依次和后面一个数据两两比较,数值…...

iOS项目怎样进行二进制重排
什么是二进制重排 ? 在iOS项目中,二进制重排(Binary Reordering 或者 Binary Rearrangement)是一种优化技术,主要目的是通过重新组织应用程序的二进制文件中的代码和数据段,来提高应用程序的性能ÿ…...
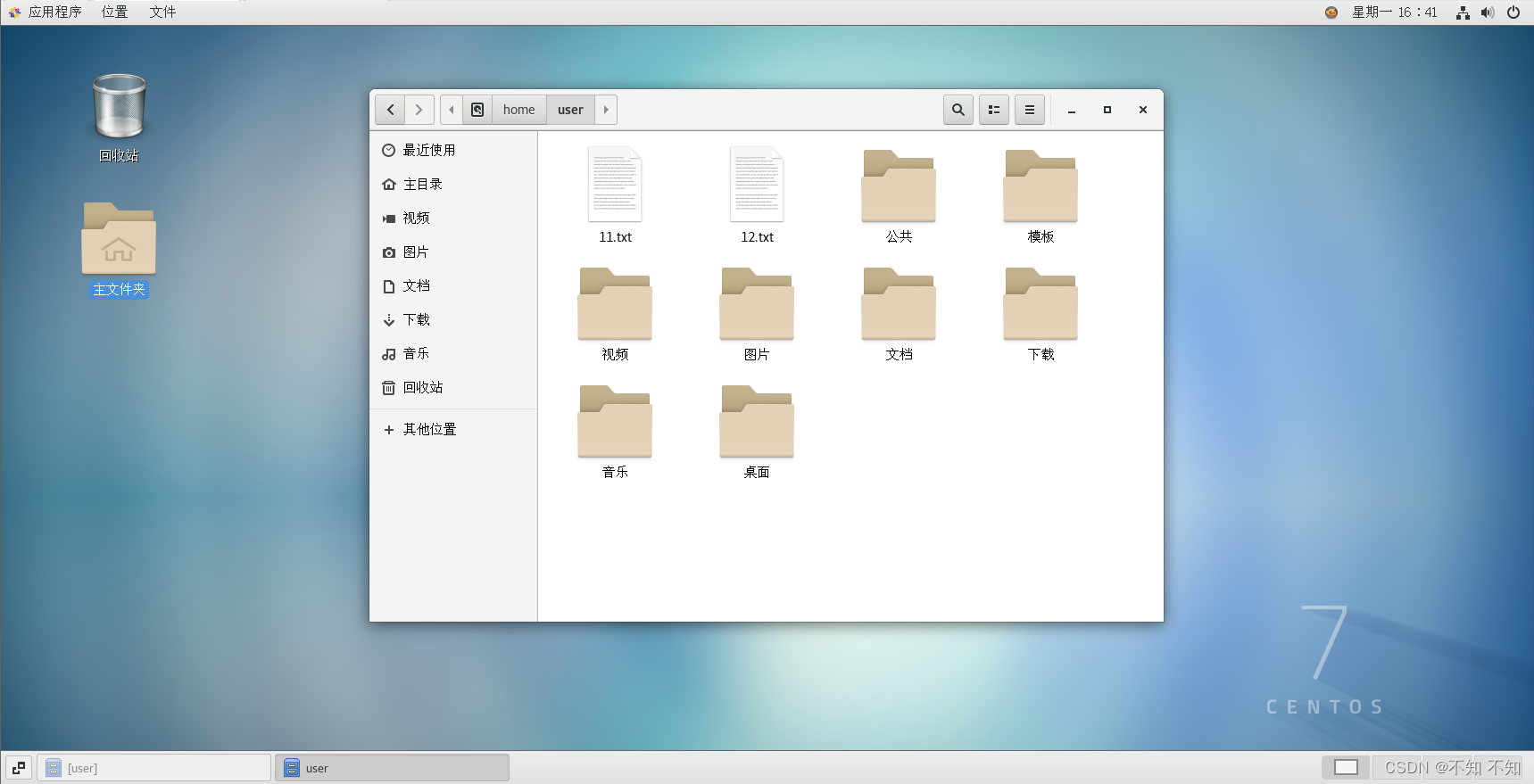
CentOS中使用SSH远程登录
CentOS中使用SSH远程登录 准备工作SSH概述SSH服务的安装与启动建立SSH连接SSH配置文件修改SSH默认端口SSH文件传输 准备工作 两台安装CentOS系统的虚拟机 客户机(192.168.239.128) 服务器(192.168.239.129) SSH概述 Secure S…...

spring @Autowire注解作用
终于有人把Autowired注解讲清楚了,赞!!!_autowired-CSDN博客...

密码学原理精解【5】
这里写目录标题 移位密码概述代码 希尔密码( Z 256 Z_{256} Z256)待加密长度被3整除待加密长度不一定被3整除加解密文件 移位密码 概述 以 z 26 运算为例 , k 为密钥 加密: e k ( x ) ( x k ) m o d 26 解密: d k ( x ) ( x − k ) m o d 26 以z_{…...

Unity3D 资源管理YooAsset原理分析与详解
引言 Unity3D 是一款广泛应用于游戏开发、虚拟现实(VR)、增强现实(AR)等领域的强大游戏开发引擎。在开发过程中,资源管理是一项至关重要的任务,它直接影响到游戏的性能和用户体验。YooAsset 是一个基于 Un…...

npm install puppeteer 报错 npm ERR! PUPPETEER_DOWNLOAD_HOST is deprecated解决办法
npm install puppeteer 报错如下: npm ERR! PUPPETEER_DOWNLOAD_HOST is deprecated. Use PUPPETEER_DOWNLOAD_BASE_URL instead. npm ERR! Error: ERROR: Failed to set up Chrome v126.0.6478.126! Set "PUPPETEER_SKIP_DOWNLOAD" env variable to sk…...

浙大版PTA《Python 程序设计》题目集 参考答案
浙大版PTA《Python 程序设计》题目集 参考答案 本答案配套详解教程专栏,欢迎订阅: PTA浙大版《Python 程序设计》题目集 详解教程_少侠PSY的博客-CSDN博客 01第1章-1 从键盘输入两个数,求它们的和并输出 aint(input()) # 输入a的值 bint(…...

“拆分盘投资:机遇与风险并存
一、引言 随着互联网技术的日新月异,金融投资领域迎来了前所未有的变革,其中拆分盘作为一种新兴的投资模式,正逐渐进入公众的视野。其独特的价值增长逻辑和创新的投资机制,为投资者开辟了新的财富增值渠道。本文旨在深入探讨拆分…...

Java面试题系列 - 第2天
题目:Java中的线程池模型及其配置策略 背景说明:在Java多线程编程中,线程池是一种高效的线程复用机制,能够有效管理和控制线程的创建与销毁,避免频繁创建和销毁线程带来的性能开销。理解和掌握线程池的配置策略对于优…...

AGI|Transformer自注意力机制超全扫盲攻略,建议收藏!
一、前言 2017年,谷歌团队推出一篇神经网络的论文,首次提出将“自注意力”机制引入深度学习中,这一机制可以根据输入数据各部分重要性的不同而分配不同的权重。当ChatGPT震惊世人时,Transformer也随之进入大众视野。一夜之间&…...
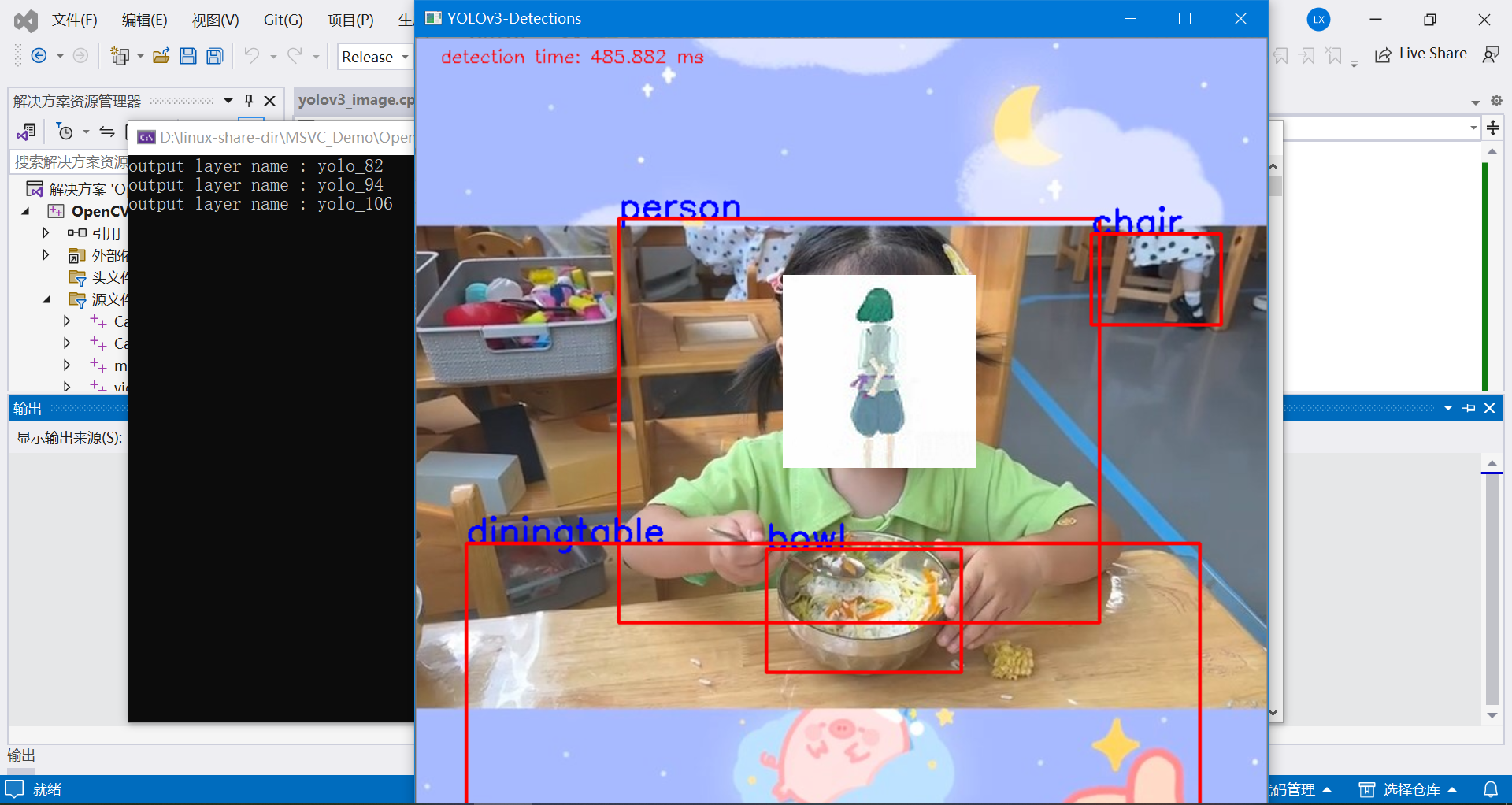
QT+OpenCV在Android上实现人脸实时检测与目标检测
一、功能介绍 在当今的移动应用领域,随着技术的飞速发展和智能设备的普及,将先进的计算机视觉技术集成到移动平台,特别是Android系统中,已成为提升用户体验、拓展应用功能的关键。其中,目标检测与人脸识别作为计算机视…...

常见网络攻击方式及防御方法
1. DDOS攻击(分布式拒绝服务攻击) 概念:借助于C/S(客户端/服务器)技术,将多个计算机联合起来作为攻击平台,对一个或多个目标发动DDOS攻击,从而成倍地提高拒绝服务攻击的威力。防护方…...

使用 ESP32 实现无线对讲机功能涉及音频采集、音频传输以及音频播放等多个方面。实现无线对讲机功能的基本步骤和示例代码。
硬件准备 两个 ESP32 开发板两个 MAX9814 麦克风模块(或其他兼容的模拟麦克风模块)两个 MAX98357A DAC 模块(或其他兼容的音频放大器模块)扬声器 接线 麦克风模块 -> ESP32 ADC 引脚ESP32 DAC 引脚 -> 音频放大器模块 -&…...

文档自动化下载革命:30+平台一键下载解决方案
文档自动化下载革命:30平台一键下载解决方案 【免费下载链接】kill-doc 看到经常有小伙伴们需要下载一些免费文档,但是相关网站浏览体验不好各种广告,各种登录验证,需要很多步骤才能下载文档,该脚本就是为了解决您的烦…...

昇腾CANN ops-nn 交叉熵损失的融合优化:从三次 Kernel Launch 到一次
语言模型每一层的损失计算:logits → softmax → log → 取 target 位置的负值。标准做法三次 kernel launch:softmax kernel → log kernel → NLL kernel。三次 HBM 往返,中间存两个 NV 矩阵(V 是词表大小,LLaMA 是 …...

Google 广告场景下 Uniswap 钓鱼攻击机理与 Web3 防御体系研究
摘要 2026 年 5 月 22 日,GoPlus 安全团队发布预警,针对 Web3 领域头部去中心化交易平台 Uniswap 的搜索引擎钓鱼攻击呈规模化爆发态势。攻击者通过购买 Google Ads 关键词广告,将高仿钓鱼网站置顶于搜索结果前列,结合视觉相似域名…...

如何在SketchUp中实现STL文件导入导出:完整3D打印解决方案指南
如何在SketchUp中实现STL文件导入导出:完整3D打印解决方案指南 【免费下载链接】sketchup-stl A SketchUp Ruby Extension that adds STL (STereoLithography) file format import and export. 项目地址: https://gitcode.com/gh_mirrors/sk/sketchup-stl 你…...
)
AI开发~OpenAI专家之路:构建企业级AI应用(第三部分·上)
第七部分:LLM应用测试与评估——确保质量的关键7.1 为什么需要测试LLM应用?大白话解释: 想象你开了一家餐厅,请了一位大厨(AI模型)来做菜。但是这位大厨有个特点——每次做出来的菜味道可能不太一样。有时候…...
)
为什么92%的团队部署DeepSeek失败?火山引擎vLLM+Triton加速方案(2024最新生产级验证)
更多请点击: https://codechina.net 第一章:为什么92%的团队部署DeepSeek失败?火山引擎vLLMTriton加速方案(2024最新生产级验证) 92%的团队在部署DeepSeek-R1或DeepSeek-V2时遭遇推理延迟超标、OOM崩溃、吞吐骤降等问…...

基于双机器学习的大规模因果推断:从理论到Spark工程实践
1. 项目概述:从观察到决策,量化客户行为的真实价值在数据驱动的商业决策中,我们常常面临一个核心挑战:如何区分“相关性”与“因果关系”?例如,我们观察到购买了高级会员的客户,其后续消费显著高…...

看长视频懒得逐字记?2026这3款AI工具,一键转文字还能出总结
做内容创作和自媒体两年,我日常最频繁的工作,就是拆解各类长视频素材。不管是学习行业课程、拆解对标账号的干货视频,还是整理线上讲座、培训回放,都需要把视频里的口述内容变成文字笔记和总结概要。以前真的太煎熬了,…...

如何在Hermes Agent中自定义配置Taotoken提供商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 如何在Hermes Agent中自定义配置Taotoken提供商 基础教程类,为使用Hermes Agent的开发者提供配置指南,详细…...

终极指南:如何使用WarcraftHelper彻底解决魔兽争霸3兼容性问题
终极指南:如何使用WarcraftHelper彻底解决魔兽争霸3兼容性问题 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为魔兽争霸3在现代Wind…...