【Python机器学习】处理文本数据——将文本数据表示为词袋
用于机器学习的文本有一种最简单的方法,也是最有效且最常用的方法,就是使用词袋表示。使用这种表示方法时,我们舍弃了输入文本中的大部分结构,比如章节、段落、句子和格式,只计算语料库中,只计算语料库中每个单词在每个文本中出现的频次。舍弃结构并仅计算单词出现的次数,这会让脑海中出现将文本表示为“袋”的画面。
对于文档语料库,计算词袋表示包括以下三个步骤:
1、分词。将每个文档划分为出现在其中的单词(称为词例 token),比如按空格和标点划分。
2、构建词表。收集一个词表,里面包含出现在任意文档中的所有词,并对它们进行编号。
3、编码。对于每个文档,计算词表中每个单词在该文档中出现的频次。
在步骤1和步骤2涉及一些细微之处。我们来看一下如何利用scikit-learn来应用词袋处理过程。词袋的输出是包含每个文档中单词计数的一个向量。对于词表中的每个单词,我们都有它在每个文档中出现的次数。也就是说,整个数据集中的每个唯一单词都对应于这中数值表示的一个特征。要注意,原始字符串中的单词顺序与词袋特征表示完全无关。
将词袋应用于玩具数据集:
词袋表示是在CountVectorizer中实现的,它是一个变换器(transformer)。我们首先将它应用于包含两个样本的玩具数据集,来看一下它的工作原理:
bards_words=['the fool doth think he is wise','but then wise man knows himself to be a fool']我们导入CountVectorizer并将其实例化,然后对玩具数据进行拟合,如下所示:
bards_words=['the fool doth think he is wise','but then wise man knows himself to be a fool']
vect=CountVectorizer()
vect.fit(bards_words)拟合CountVectorizer包括训练数据的分词与词表的构建,我们可以通过vocabulary_属性来访问词表:
print('词表大小:{}'.format(len(vect.vocabulary_)))
print('词表:{}'.format(vect.vocabulary_))
词表一个包含14个单词,从“be”到“wise”。
我们可以调用transform方法来创建训练数据的词袋表示:
bag_of_words=vect.transform(bards_words)
print('词袋表示:{}'.format(repr(bag_of_words)))
词袋表示保存在一个SciPy系数矩阵中,这种数据格式只保存非零元素。这个矩阵的形状为2*13,每行对应于两个数据点之一,每个特征对应于词表中的一个单词。这里使用稀疏矩阵,是因为大多数文档斗志包含次表中的一小部分单词,也就是说特征数组的大部分元素都为0,因为保存0的代价很高,也浪费内存。要想查看稀疏矩阵的实际内容,可以使用toarray方法将其转换为“密集的”NumPy数组(保存所有0元素):
但是这里之所以可行,是因为我们使用的是仅包含13个单词的小型数据集。对于任何真实数据集来说,这将会导致内存报错。
print('矩阵实际数组内容:{}'.format(bag_of_words.toarray()))
我们可以看到,每个单词的计数都是0或1.bards_words中的两个字符串都没有包含相同的单词。
我们来看一下如何阅读这些特征向量:第一个字符串被视为第一行,对于词表中第一个单词“be”,出现0次,第二个词0次,第三个次1次,以此类推。
访问词表的另一种方法是使用向量器的get_funture_name方法,它将返回一个列表,每个元素对应一个特征:
feature_name=vect.get_feature_names_out()
print('特征数量:{}'.format(len(feature_name)))
print('前20个特征:{}'.format(feature_name[:20]))
相关文章:
【Python机器学习】处理文本数据——将文本数据表示为词袋
用于机器学习的文本有一种最简单的方法,也是最有效且最常用的方法,就是使用词袋表示。使用这种表示方法时,我们舍弃了输入文本中的大部分结构,比如章节、段落、句子和格式,只计算语料库中,只计算语料库中每…...

论文写作全攻略:Kimi辅助下的高效学术写作技巧
学境思源,一键生成论文初稿: AcademicIdeas - 学境思源AI论文写作 完成论文写作是一个多阶段的过程,涉及到不同的任务和技能。以下是按不同分类总结的向Kimi提问的prompt,以帮助你在论文写作过程中取得成功: 1. 选题与…...

通证经济重塑经济格局
在数字化转型的全球浪潮中,通证经济模式犹如一股新兴力量,以其独特的价值传递与共享机制,重塑着经济格局,引领我们步入数字经济的新纪元。 通证,作为这一模式的核心,不仅是权利与权益的数字化凭证…...

linux - cp 命令
问:cp -r ./src/. ./dst 与 cp -r ./src/* ./dst 有什么区别? 1.隐藏文件和目录:cp -r ./src/* ./dst 不会复制隐藏文件和目录。cp -r ./src/. ./dst 会复制所有文件和目录,包括隐藏文件和目录。 2.通配符和当前目录:* 是一个通…...

基于Qt实现的PDF阅读、编辑工具
记录一下实现pdf工具功能 语言:c、qt IDE:vs2017 环境:win10 一、功能演示: 二、功能介绍: 1.基于saribbon主体界面框架,该框架主要是为了实现类似word导航项 2.加载PDF放大缩小以及预览功能 3.pdf页面跳转…...

Linux 内核 GPIO 用户空间接口
文章目录 Linux 内核 GPIO 接口旧版本方式:sysfs 接口新版本方式:chardev 接口 gpiod 库及其命令行gpiod 库的命令行gpiod 库函数的应用 GPIO(General Purpose Input/Output,通用输入/输出接口),是微控制器…...

Hive数据倾斜--处理方法
1. 什么是数据倾斜? 在分布式计算场景下,大量的数据集中在某一个节点而导致一个任务的执行时间变长。而大量的节点只处理了小部分的数据,大数据组件处理海量数据的特点就是不患多,而患不均。 2. 怎么发现任务出现了数据倾斜现象 …...

k8s流控平台apiserver详解
一、简单理解认识apiserver 1.主要功能 认证 鉴权 准入 mutating validating admission 限流 2.概念 apiserver保护etcd,缓存机制,有缓存直接返回,没缓存再去查看etcd,apiserver是担任和其他平台同信并认证 3.访问控制概览…...

unity对于文件夹的操作
1、获取目标文件夹内所有文件夹 string[] directories Directory.GetDirectories(Path);for (int i 0; i < directories.Length; i){print(directories[i]);}2、获取目标文件夹内指定文件 public List<string> GetAllTxt(string path){//只获取文件名string[] files…...

[Redis]哨兵机制
哨兵机制概念 在传统主从复制机制中,会存在一些问题: 1. 主节点发生故障时,进行主备切换的过程是复杂的,需要人工参与,导致故障恢复时间无法保障。 2. 主节点可以将读压力分散出去,但写压力/存储压力是无法…...

Vue3--Watch、Watcheffect、Computed的使用和区别
Vue3–Watch、Watcheffect、Computed的使用和区别 一、watch 1.功能 watch 用于监听响应式数据的变化,并在数据变化时执行特定的回调函数。适合在响应式数据变化时执行异步操作或复杂逻辑。 2.主要特点 指定数据监听:可以精确地监听一个或多个响应式…...

hive调优原理详解:案例解析参数配置(第17天)
系列文章目录 一、Hive常问面试函数(掌握) 二、Hive调优如何配置(重点) 文章目录 系列文章目录前言一、Hive函数(掌握)11、JSON数据处理12、炸裂函数13、高频面试题13.1 行转列13.2 列转行 14、开窗函数&a…...

华为机试HJ15求int型正整数在内存中存储时1的个数
华为机试HJ15求int型正整数在内存中存储时1的个数 题目: 输入一个 int 型的正整数,计算出该 int 型数据在内存中存储时 1 的个数。 数据范围:保证在 32 位整型数字范围内 想法: 将输入的十进制数转为二进制,遍历记…...

NLP - Softmax与层次Softmax对比
Softmax Softmax是神经网络中常用的一种激活函数,用于多分类任务。Softmax函数将未归一化的logits转换为概率分布。公式如下: P ( y i ) e z i ∑ j 1 N e z j P(y_i) \frac{e^{z_i}}{\sum_{j1}^{N} e^{z_j}} P(yi)∑j1Nezjezi 其中&#…...
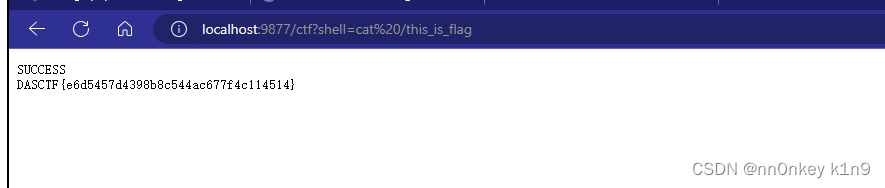
HttpServer内存马
HttpServer内存马 基础知识 一些基础的方法和类 HttpServer:HttpServer主要是通过带参的create方法来创建,第一个参数InetSocketAddress表示绑定的ip地址和端口号。第二个参数为int类型,表示允许排队的最大TCP连接数,如果该值小…...
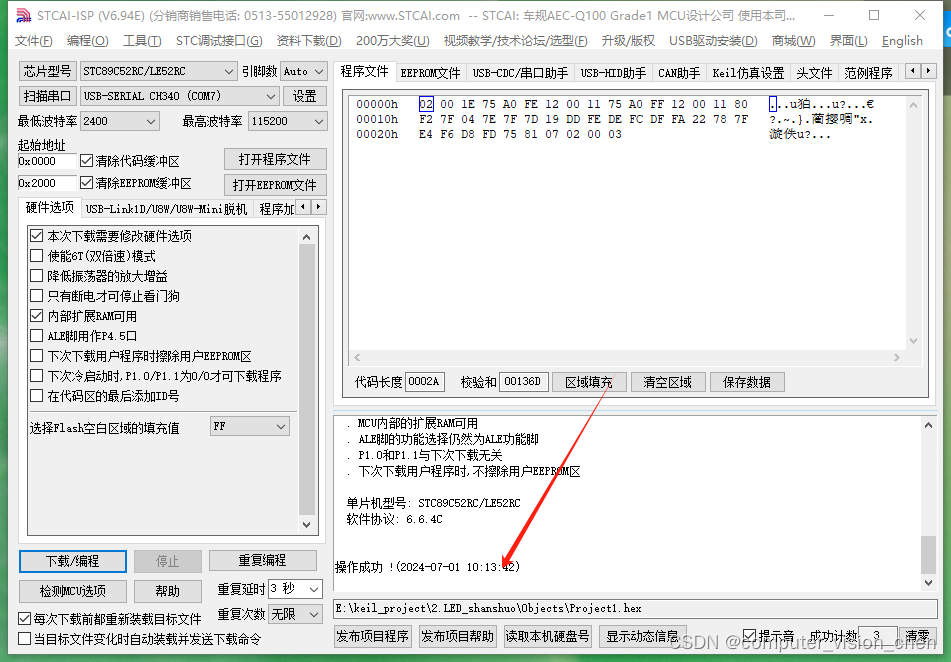
51单片机-让一个LED灯闪烁、流水灯(涉及:自定义单片机的延迟时间)
目录 设置单片机的延迟(睡眠)函数查看单片机的时钟频率设置系统频率、定时长度、指令集 完整代码生成HEX文件下载HEX文件到单片机流水灯代码 (自定义延迟时间) 设置单片机的延迟(睡眠)函数 查看单片机的时钟频率 检测前单片机必…...

MYSQL原理、设计与应用
概述 数据库(Database,DB)是按照数据结构来组织、存储和管理数据的仓库,其本身可被看作电子化的文件柜,用户可以对文件中的数据进行增删改查等操作。 数据库系统是指在计算机系统中引入数据库后的系统,除了数据库,还…...

flask项目部署总结
这个部署的时候要用虚拟环境,cd进项目文件夹 python3 -m venv myenv source myenv/bin/activate激活 之后就安装一些库包之类的,(flask,requests,bs4,等等) 最重要的是要写.flaskenv文件并且pip install 一个能运行…...

【总线】AXI4第八课时:介绍AXI的 “原子访问“ :独占访问(Exclusive Access)和锁定访问(Locked Access)
大家好,欢迎来到今天的总线学习时间!如果你对电子设计、特别是FPGA和SoC设计感兴趣,那你绝对不能错过我们今天的主角——AXI4总线。作为ARM公司AMBA总线家族中的佼佼者,AXI4以其高性能和高度可扩展性,成为了现代电子系统中不可或缺的通信桥梁…...

Java面试八股之MYISAM和INNODB有哪些不同
MYISAM和INNODB有哪些不同 MyISAM和InnoDB是MySQL数据库中两种不同的存储引擎,它们在设计哲学、功能特性和性能表现上存在显著差异。以下是一些关键的不同点: 事务支持: MyISAM 不支持事务,没有回滚或崩溃恢复的能力。 InnoDB…...

渗透测试学习路线:从原生终端到实战靶场的系统路径
1. 这不是“速成课”,而是一张你真正能踩出脚印的地图很多人点开“渗透测试学习路线”时,心里想的是:学三个月能不能接单?能不能进红队?能不能年薪30万?我试过在2019年用两周时间刷完某平台全部CTF入门题&a…...

低查重AI写教材秘诀大揭秘!高效工具助你快速生成专业教材
一、AI教材写作的现状与需求 在编写教材之前,选择合适的工具常常让人感到无比纠结!如果用普通的办公软件,功能显得太过于简单,想要搭建框架或者规范格式,都只能依靠手工操作;而如果选择了专业的教材编写工…...

2026年AI写作辅助网站盘点:12款神器助你高效完成初稿生成、排版和降AI率
随着 AI 技术的持续突破,2026 年的论文写作辅助工具市场已进入“智能化、定制化、合规化”的新阶段。从本科生的课程论文到研究生的学位论文,再到科研人员的期刊投稿,AI 工具正在为不同层次的学术需求提供高效、精准的解决方案。本文基于权威…...

ChatGPT账号被封怎么办?20年合规架构师给出终极答案:1套可审计的账号生命周期管理SOP
更多请点击: https://codechina.net 第一章:ChatGPT账号被封怎么办 当您的ChatGPT账号突然无法登录、提示“Account suspended”或跳转至封禁通知页时,需冷静判断原因并采取合规应对措施。OpenAI官方明确指出,封禁通常源于违反《…...
)
别再乱装WinPcap了!手把手教你为华为eNSP Cloud正确配置虚拟网卡(Win7/Win10兼容方案)
华为eNSP Cloud虚拟网卡配置全指南:从原理到避坑实践 当你第一次打开华为eNSP Cloud功能时,是否也遇到过网卡显示不全的困扰?这个问题困扰过无数网络学习者和备考者,而90%的根源都指向同一个错误——WinPcap的安装方式。本文将彻底…...

ContextMenuManager:Windows右键菜单终极优化指南
ContextMenuManager:Windows右键菜单终极优化指南 【免费下载链接】ContextMenuManager 🖱️ 纯粹的Windows右键菜单管理程序 项目地址: https://gitcode.com/gh_mirrors/co/ContextMenuManager 我们每天都要和Windows右键菜单打交道几十次&#…...

WechatDecrypt终极指南:3步解锁你的微信聊天记忆
WechatDecrypt终极指南:3步解锁你的微信聊天记忆 【免费下载链接】WechatDecrypt 微信消息解密工具 项目地址: https://gitcode.com/gh_mirrors/we/WechatDecrypt 你是否曾经有过这样的经历?换了新手机,却发现珍贵的微信聊天记录无法完…...

3步搞定全平台资源下载:res-downloader终极使用指南
3步搞定全平台资源下载:res-downloader终极使用指南 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader 还在为下载视…...

3分钟掌握ZeroOmega:让浏览器代理切换变得轻松高效
3分钟掌握ZeroOmega:让浏览器代理切换变得轻松高效 【免费下载链接】ZeroOmega Manage and switch between multiple proxies quickly & easily. 项目地址: https://gitcode.com/gh_mirrors/ze/ZeroOmega ZeroOmega 是一款强大的浏览器代理管理工具&…...

如何用本地工具在千万级图片库中快速找到相似图片
如何用本地工具在千万级图片库中快速找到相似图片 【免费下载链接】ImageSearch 基于.NET10的本地硬盘千万级图库以图搜图案例Demo和图片exif信息移除小工具分享 项目地址: https://gitcode.com/gh_mirrors/im/ImageSearch 在数字时代,你的电脑里可能积累了成…...