k8s 中间件
1. zookeeper
是的,Zookeeper 和 Kafka 经常一起使用,Zookeeper 在 Kafka 中扮演了关键角色。以下是 Zookeeper 和 Kafka 在实际项目中的结合使用及其作用的详细说明。
项目背景
假设我们有一个分布式数据处理系统,该系统需要高吞吐量的实时消息处理能力。Kafka 被选作消息队列系统,用于接收、存储和传输大量实时数据。Zookeeper 被用作集群管理工具,以确保 Kafka 集群的高可用性和一致性。
Kafka 与 Zookeeper 的结合
1. Kafka Broker 管理
Kafka 使用 Zookeeper 来管理 Kafka brokers(代理)。Zookeeper 维护了所有 broker 的元数据和状态信息,确保每个 broker 都可以发现和通信其他 brokers。
- Broker 注册:当一个 Kafka broker 启动时,它会向 Zookeeper 注册自己,这样其他 brokers 可以知道集群中的所有成员。
- Leader 选举:Kafka 分区的 leader 选举是通过 Zookeeper 来完成的。每个分区有一个 leader 和多个 follower,leader 负责所有读写操作,而 followers 复制 leader 的数据。
2. Topic 和 Partition 管理
Zookeeper 维护 Kafka 集群中所有 topic 和分区的元数据,包括分区的位置、replicas 和 leader 信息。
- Topic 配置:创建一个 topic 时,Kafka 会将其配置信息(如分区数、副本数)存储在 Zookeeper 中。
- 分区信息:每个分区的 leader 和 followers 信息也存储在 Zookeeper 中,确保集群的元数据一致性。
3. 消费者组协调
Zookeeper 协调 Kafka 消费者组,确保每个消费者实例在集群中唯一且不重复地消费消息。
- 消费者注册:消费者启动时会向 Zookeeper 注册自己,并通过 Zookeeper 获取分配给它的分区。
- 分区再均衡:当消费者实例加入或离开时,Zookeeper 负责触发分区再均衡,确保分区分配在消费者组中保持均衡。
实际项目示例
项目描述
假设我们有一个实时日志处理系统,该系统收集来自多个应用程序的日志数据,进行实时处理和分析。
使用 Kafka 和 Zookeeper
-
数据收集和传输:
- 应用程序将日志数据发送到 Kafka topic。每个应用程序对应一个或多个 Kafka topics。
-
消息队列管理:
- Kafka 集群由多个 brokers 组成,Zookeeper 管理这些 brokers 的元数据和状态,确保集群的高可用性。
- Zookeeper 协助 Kafka 进行分区 leader 选举,确保每个分区都有一个 leader 负责处理读写请求。
-
实时处理:
- 一个 Kafka 消费者组(如 Spark Streaming、Flink 或自定义的消费者应用)从 Kafka topics 中消费日志数据进行实时处理。
- Zookeeper 协调消费者组中的消费者,确保每个分区的数据都被唯一的消费者处理。
-
故障恢复:
- 如果一个 Kafka broker 崩溃,Zookeeper 协助进行 leader 选举,将分区的 leader 转移到其他可用的 brokers。
- 消费者实例崩溃时,Zookeeper 触发分区再均衡,将分区重新分配给其他消费者实例,确保系统继续稳定运行。
结论
Zookeeper 在 Kafka 集群中起到了关键的协调和管理作用,确保了 Kafka 的高可用性和一致性。在实际项目中,Kafka 和 Zookeeper 的结合使用能够处理大量实时数据,提供可靠的消息传输和处理能力。这种架构在大数据、日志处理、实时分析等领域广泛应用,能够满足高吞吐量和低延迟的需求。
zookeeper headless
在yaml文件中 clusterIP: None 代表它是headless svc
10.96.0.10 是k8s 集群内的 dns 解析
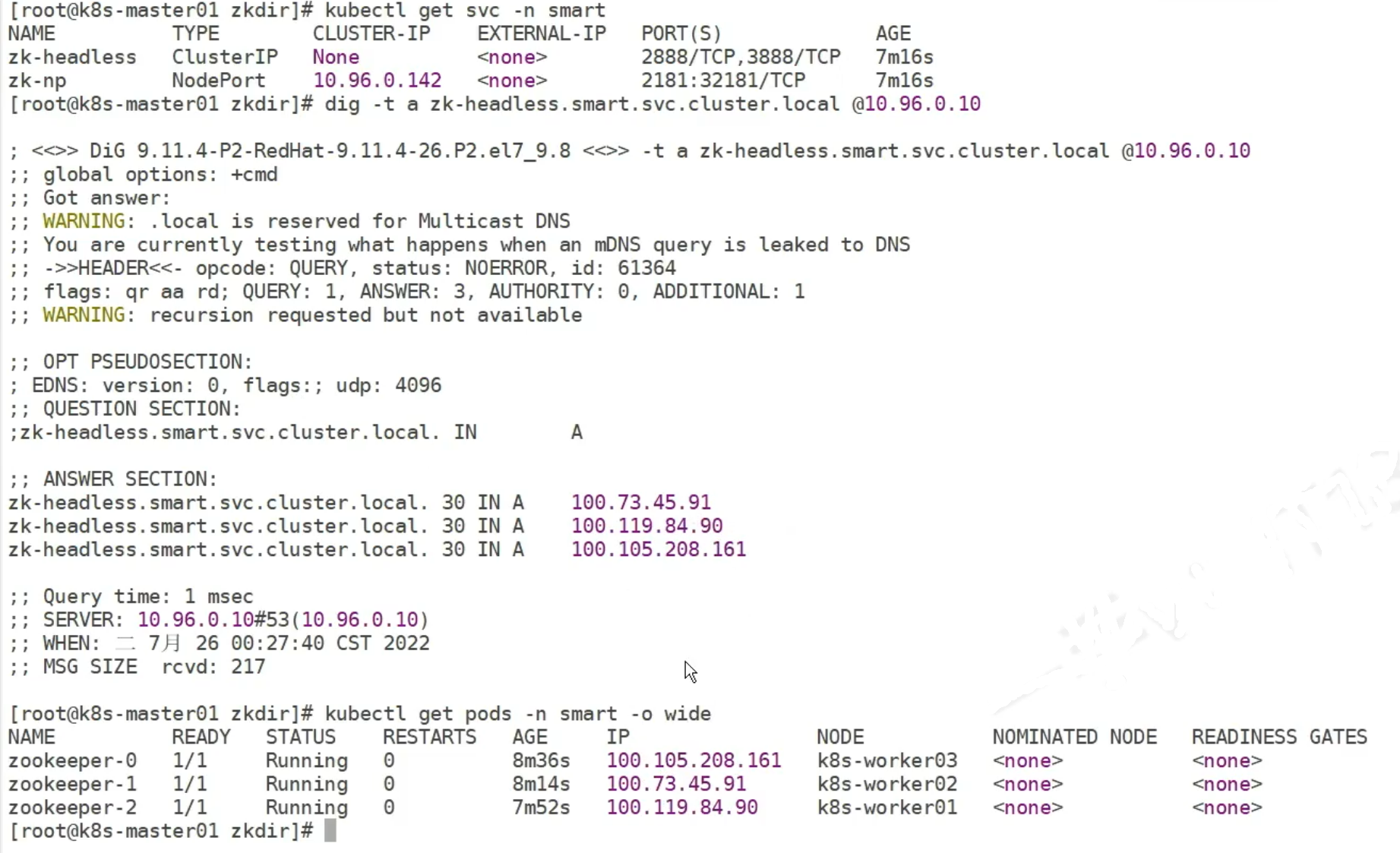
应用验证
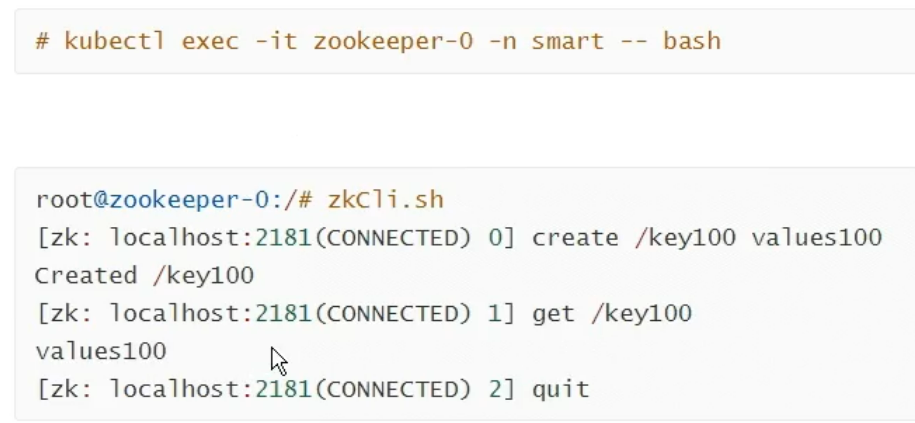
可以获得键值说明zookeeper正常,这是在集群内访问
下面是安装客户端,从外面通过port 访问zookeeper
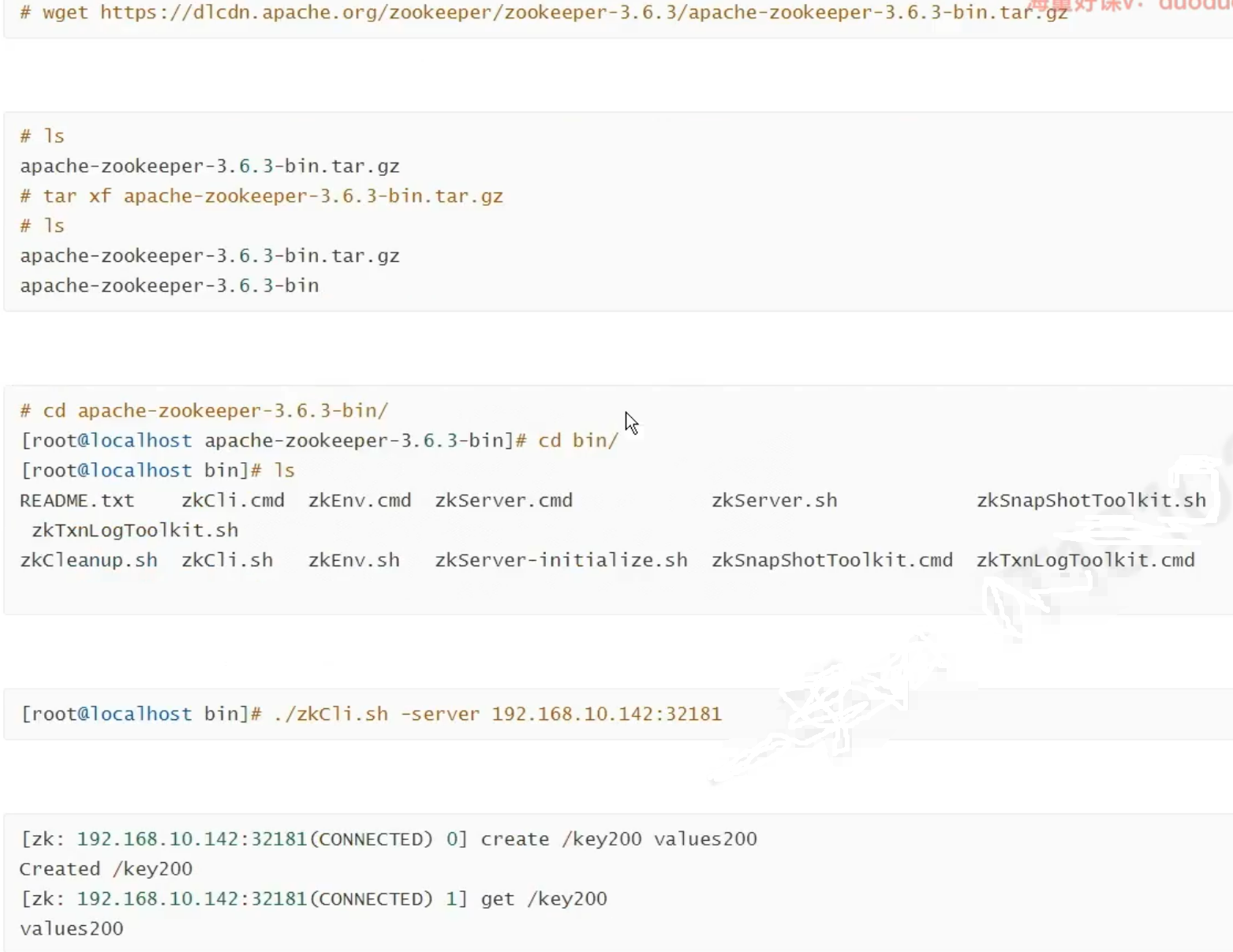
zookeeper的存储可以接nfs
2. kafka
kafka 生产者将数据写入到分区主题, 这些主题通过可配置的副本存储到broker集群上。消费者消费存储在broker 分区生成的数据
示例项目说明
假设你有一个在线零售网站,你希望使用Kafka来处理用户订单数据。以下是如何使用Broker、Topic和分区来实现这一需求的示例:
1. 创建Kafka集群
你创建了一个Kafka集群,包含3个Broker(Broker 0, Broker 1, Broker 2)。
2. 创建Topic
你创建了一个名为orders的Topic,用于存储用户订单数据。为了提高系统的性能和可靠性,你决定将这个Topic分成3个分区,并设置副本因子为2。
kafka-topics.sh --create --topic orders --partitions 3 --replication-factor 2 --zookeeper localhost:2181
3. 分区和副本分布
Kafka会自动在Broker之间分配分区和副本。例如:
- 分区 0 可能分布在Broker 0和Broker 1上,其中Broker 0是Leader,Broker 1是Follower。
- 分区 1 可能分布在Broker 1和Broker 2上,其中Broker 1是Leader,Broker 2是Follower。
- 分区 2 可能分布在Broker 2和Broker 0上,其中Broker 2是Leader,Broker 0是Follower。
4. 数据生产和消费
- 生产者(Producer): 你的订单服务会将每个订单消息发送到
ordersTopic。Kafka根据某种分区策略(如订单ID的哈希值)将消息分配到不同的分区。 - 消费者(Consumer): 你的订单处理服务会从
ordersTopic中消费消息。消费者可以并行地从不同的分区读取数据,从而提高处理速度。
数据流示例
- 用户A在网站上下单,订单数据被发送到
ordersTopic,Kafka将其放入分区0。 - 用户B在网站上下单,订单数据被发送到
ordersTopic,Kafka将其放入分区1。 - 用户C在网站上下单,订单数据被发送到
ordersTopic,Kafka将其放入分区2。
优点
- 高可用性和容错性: 如果一个Broker宕机,Kafka可以自动切换到其他Broker上的副本,保证数据的可用性。
- 高吞吐量: 多个分区使得生产者和消费者可以并行工作,提高了系统的处理能力。
- 可扩展性: 你可以通过增加分区数和Broker数量来扩展Kafka集群的容量和性能。
kafka高可用集群部署
可以使用helm,或者和zookeeper一起部署,还可以自己的yaml
也可以使用storageclass来持久化存储
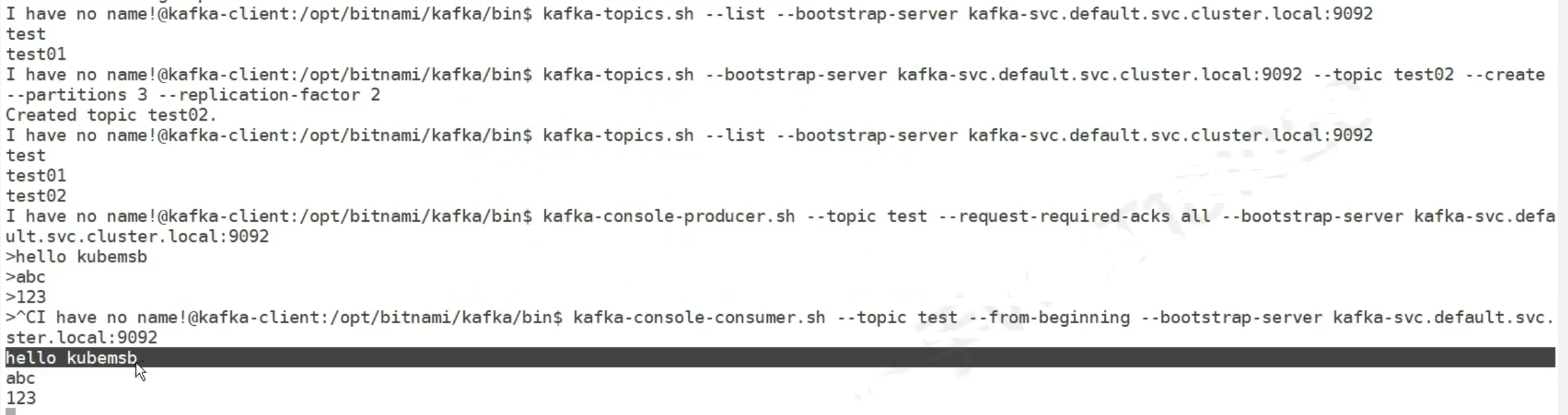
在k8s内部验证Kafka的使用test,生产环境不这样用kafka
创建一个pod客户端

进入后,如果没有topic,创建topic,然后生产,消费

这个topic名字是test01 topic被分成3个分区,分区使Kafka能够并行处理数据,因为不同的消费者可以消费不同的分区。
副本 2个代表每个分区的数据会被复制到两个不同的 Broker上。
副本是分区的一个副本,存储在不同的Broker上。
Kafka使用主副本(Leader)和从副本(Follower)来管理数据复制。
Leader负责所有读写请求,而Follower被动地复制Leader的数据。
如果Leader宕机,Kafka会自动选举一个新的Leader,从而保证数据的高可用性。Broker 是实际存储和管理数据的服务器节点。
Topic 是消息的分类和逻辑分组。
分区 是Topic的子集,每个分区是一个独立的、有序的消息日志,使Kafka能够并行处理和分发消息。


3.rokectmq
分布式消息传递,万亿级别
相关文章:
k8s 中间件
1. zookeeper 是的,Zookeeper 和 Kafka 经常一起使用,Zookeeper 在 Kafka 中扮演了关键角色。以下是 Zookeeper 和 Kafka 在实际项目中的结合使用及其作用的详细说明。 项目背景 假设我们有一个分布式数据处理系统,该系统需要高吞吐量的实…...

如何 提升需求确定性
提升需求确定性是确保项目成功的关键之一。以下是一些方法和策略可以帮助你提升需求的确定性: 积极的利益相关者参与: 确保所有关键利益相关者(包括最终用户、业务所有者、开发团队等)参与需求收集和确认过程。他们的参与可以提供…...

探索Sui的面向对象模型和Move编程语言
Sui区块链作为一种新兴的一层协议(L1),采用先进技术来解决常见的一层协议权衡问题。Cointelegraph Research详细剖析了这一区块链新秀。 Sui使用Move编程语言,该语言专注于资产表示和访问控制。本文探讨了Sui的对象中心数据存储模…...

【vue动态组件】VUE使用component :is 实现在多个组件间来回切换
VUE使用component :is 实现在多个组件间来回切换 component :is 动态父子组件传值 相关代码实现: <component:is"vuecomponent"></component>import componentA from xxx; import componentB from xxx; import componentC from xxx;switch(…...
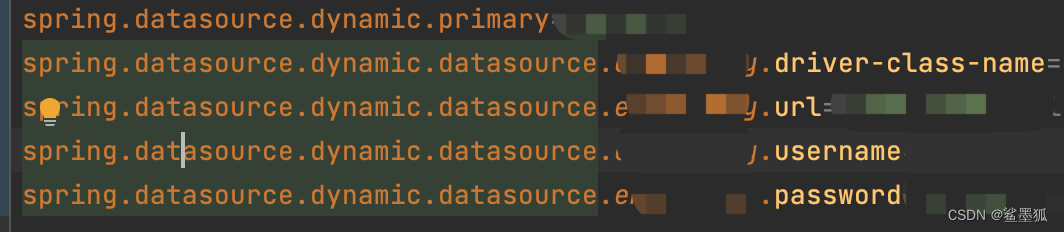
springboot dynamic配置多数据源
pom.xml引入jar包 <dependency><groupId>com.baomidou</groupId><artifactId>dynamic-datasource-spring-boot-starter</artifactId><version>3.5.2</version> </dependency> application配置文件配置如下 需要主要必须配置…...
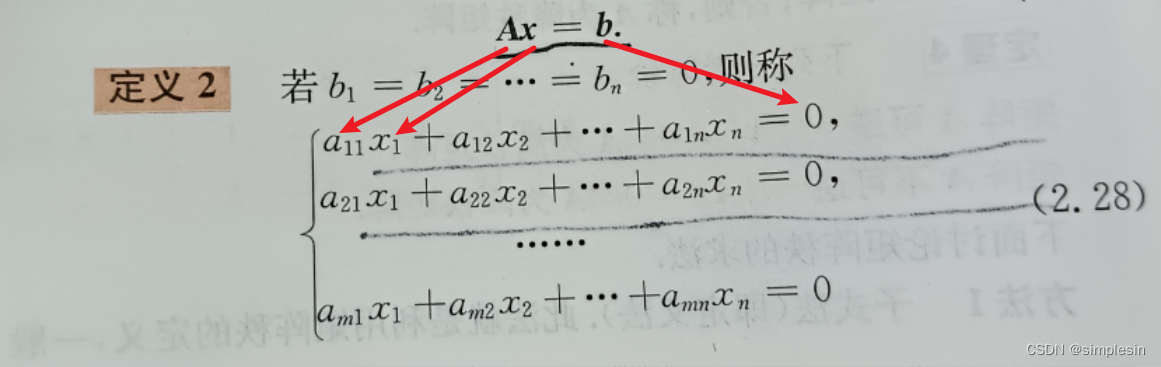
线性代数知识点搜刮
求你别考太细... 目录 异乘变零定理 行列式转置 值不变 重要关系 中间相等,取两头 特征值公式 向量正交 点积为0 拉普拉斯定理 矩阵的秩 特征值和特征向量 |A|特征值的乘积 & tr(A)特征值的和 要记要背 增广矩阵 异乘变零定理 某行(…...

景区智能厕所系统,打造智能化,人性化公共空间
在智慧旅游的大潮中,景区智能厕所系统正逐渐成为提升公共空间智能化、人性化水平的关键载体。作为智慧城市建设的重要组成部分,智能厕所系统不仅解决了传统公厕存在的诸多问题,更通过科技的力量,为游客创造了更加舒适、便捷的如厕…...

Windows中Git的使用(2024最新版)
Windows中Git的使用 获取ssh keys本地绑定邮箱初始化本地仓库添加到本地缓存区提交到本地缓存区切换本地分支为main关联远程分支推送到GitHub查看推送日志 Git 2020年发布了新的默认分支名称"main",取代了"master"作为主分支的名称。操作有了些…...
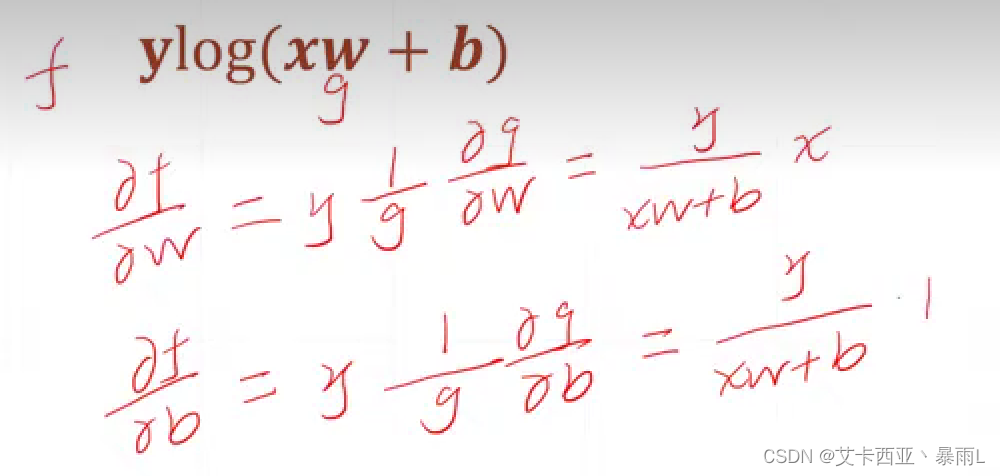
【pytorch12】什么是梯度
说明 导数偏微分梯度 梯度:是一个向量,向量的每一个轴是每一个方向上的偏微分 梯度是有方向也有大小,梯度的方向代表函数在当前点的一个增长的方向,然后这个向量的长度代表了这个点增长的速率 蓝色代表比较小的值,红色…...

南京,协同开展“人工智能+”行动
南京,作为江苏省的省会城市,一直以来都是科技创新和产业发展的高地。近日,南京市政府正式印发了《南京市进一步促进人工智能创新发展行动计划(2024—2026 年)》和《南京市促进人工智能创新发展若干政策措施》的“11”文…...
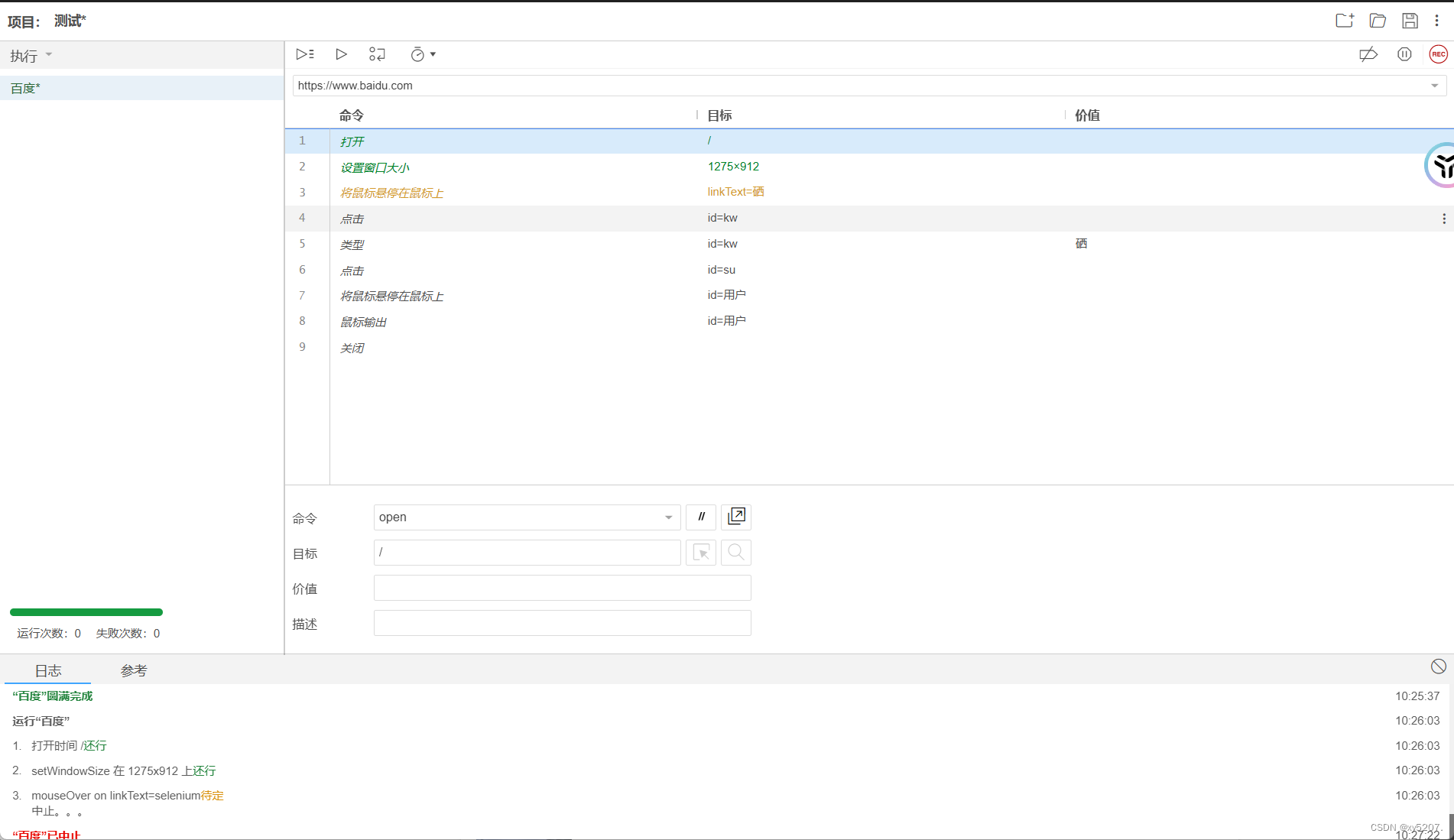
Selenium IDE 的使用指南
Selenium IDE 的使用指南 在自动化测试的领域中,Selenium 是一个广为人知且强大的工具集。而 Selenium IDE 作为其中的一个组件,为测试人员提供了一种便捷且直观的方式来创建和执行自动化测试脚本。 一、Selenium IDE 简介 Selenium IDE 是一个用于录…...

vue配置sql规则
vue配置sql规则 实现效果组件完整代码父组件 前端页面实现动态配置sql条件,将JSON结构给到后端,后端进行sql组装。 这里涉及的分组后端在组装时用括号将这块规则括起来就行,分组的sql连接符(并且/或者)取组里的第一个。…...

面试官:Redis执行lua脚本能保证原子性吗?
核心问题 Redis执行lua脚本是否能确保原子性? 面试经历 面试者在面试中自信回答Redis执行lua脚本能保证原子性,但未能深入解释原因。 原子性概念 原子性:一个事务的所有命令要么全部执行成功,要么全部执行失败。 Redis官方说…...

基于Chrome扩展的浏览器可信事件与网页离线PDF导出
基于Chrome扩展的浏览器可信事件与网页离线PDF导出 Chrome扩展是一种可以在浏览器中添加新功能和修改浏览器行为的软件程序,我们可以基于Manifest规范的API实现对于浏览器和Web页面在一定程度上的修改,例如广告拦截、代理控制等。Chrome DevTools Proto…...
马拉松报名小程序的设计
管理员账户功能包括:系统首页,个人中心,用户管理,赛事信息管理,赛事报名管理,活动商城管理,留言板管理,系统管理 微信端账号功能包括:系统首页,赛事信息&…...
python使用pywebview集成vue3和element-plus开发桌面系统框架
随着web技术越来越成熟,就连QQ的windows客户端都用web技术来开发,所以在未来,web技术来开发windows桌面软件也会越来越多,所以在此发展驱动之下,将最近流程的python与web技术相结合,使用vue3和element-plus…...

C++线程的使用
C11之前,C语言没有对并发编程提供语言级别的支持,这使得我们在编写可移植的并发程序时,存在诸多的不便。现在C11中增加了线程以及线程相关的类,很方便地支持了并发编程,使得编写的多线程程序的可移植性得到了很大的提高…...

算法库应用--寻找最长麦穗
学习贺利坚老师算法库 数据结构例程——串的顺序存储应用_使用顺序串存储身份证号-CSDN博客 本人详细解析博客 串的顺序存储的应用实例二_串的顺序存储应用-CSDN博客 版本更新日志 V1.0: 在原有的基础上, 进行优化名字, 并且有了相应的算法库作为支撑, 我使用了for循环来代替老…...

ython 使用 cx_Freeze 打包,不想要打包文件中能直接看到依赖的代码,如何处理
背景:因为使用 cx_Freeze 打包时,添加需要依赖的文件 cx_Freeze 是一个用于将 Python 程序打包成独立可执行文件的工具,支持多个平台。当你需要打包包含多个 .py 文件的项目时,你可以通过编写一个 setup.py 文件来指定哪些模块应…...

某DingTalk企典 - Token
⚠️前言⚠️ 本文仅用于学术交流。 学习探讨逆向知识,欢迎私信共享学习心得。 如有侵权,联系博主删除。 请勿商用,否则后果自负。 网址 aHR0cHM6Ly9kaW5ndGFsay5jb20vcWlkaWFuLw 浅聊一下 没毛病,就这字段,有效期…...
,第7名99%人从未试过)
【独家实测】12种火焰风格生成成功率排行榜(含燃烧强度/流体轨迹/余烬衰减量化评分),第7名99%人从未试过
更多请点击: https://codechina.net 第一章:火焰风格生成效果的评估体系与实测方法论 火焰风格图像生成质量评估需兼顾视觉感知一致性、物理合理性与算法可复现性。单一指标(如PSNR或LPIPS)无法全面刻画火焰特有的动态纹理、亮度…...

SSH命令行指定密码登录的真相与安全替代方案
1. 这个命令根本不能用:先破除一个广泛流传的误解你是不是在某篇技术笔记、某次运维排查,或者某个深夜赶工的场景里,看到过类似sshpasswd -p paswd ssh username192.168.1.100这样的写法?甚至可能还复制粘贴试过,结果报…...
)
Linux 用户与用户组核心概念详解(零基础必懂)
前言Linux 是典型的多用户、多任务操作系统,支持多人同时登录、各司其职、权限隔离。所有文件、进程、权限都依托用户与用户组实现管控,是Linux权限体系的基石。彻底弄懂用户、用户组概念,是掌握服务器权限管控、账号运维的前提,本…...

[智能体-28]:Python HTTP 请求库:requests 背景、原理、作用 完整版详解
一、全称与字面含义Requests:英文本意「请求、申请」Python 中:HTTP 请求库二、诞生背景Python 原生自带 urllib、urllib2语法冗长、写法繁琐、兼容性差、使用门槛高。2011 年 Kenneth Reitz 开发 requests口号:HTTP for Humans(给…...

如何用OneMore插件让OneNote成为你的高效笔记神器
如何用OneMore插件让OneNote成为你的高效笔记神器 【免费下载链接】OneMore A OneNote add-in with simple, yet powerful and useful features 项目地址: https://gitcode.com/gh_mirrors/on/OneMore 你是否曾经在使用OneNote时感到功能不够用?想要更强大的…...

量子态估计新突破:超越置乱时间,QELM稳健实现高效信息提取
1. 项目概述 量子态估计,简单来说,就是“看清”一个未知量子系统内部状态的过程。这好比在完全黑暗的房间里,你需要通过有限的光线(测量)来推断房间内物体的精确形状和位置。在量子计算、量子通信和量子传感等领域&…...

鸿蒙electron跨端框架PC墨案写作实战:把 Markdown 正文区做成桌面写作的中心
前言 欢迎加入鸿蒙PC开发者社区,共同打造开发者工具生态:鸿蒙PC开发者社区 :https://harmonypc.csdn.net/ 项目开源地址:https://AtomGit.com/lqjmac/ele-moanxiezuo 墨案写作这个小工具看起来轻,但真正落地时要先把…...

在VirtualBox里跑Win10,远程桌面连不上?试试这个被忽略的虚拟机专用配置
VirtualBox虚拟机Win10远程桌面黑屏?这个隐藏配置项可能是关键在混合开发环境中,许多技术从业者习惯使用VirtualBox等虚拟化工具搭建多操作系统平台。一个常见场景是在Windows 7宿主机上运行Windows 10虚拟机,通过远程桌面进行跨系统操作。但…...

Qwen模型 LeetCode 2584. 分割数组使乘积互质 JavaScript实现
哇!JavaScript版本来啦~这道题用JS写起来特别优雅,让我给你展示一个清晰又高效的实现!javascript /*** param {number[]} nums* return {number}*/ var findValidSplit function(nums) {const n nums.length;if (n 1) return -…...

Unity ECS帧同步实战:确定性模拟与Job化网络Tick
1. 这不是“又一个Unity网络教程”,而是帧同步在ECS架构下的真实落地切口很多人一看到“Unity多人对战”就下意识点开,结果发现是PhotonMonoBehaviour的旧路子:对象池、RPC调用、状态同步、插值补偿……代码越写越厚,逻辑越埋越深…...