DisFormer:提高视觉动态预测的准确性和泛化能力
最新的研究进展已经显示出目标中心的表示方法在视觉动态预测任务中可以显著提升预测精度,并且增加模型的可解释性。这种表示方法通过将视觉场景分解为独立的对象,有助于模型更好地理解和预测场景中的变化。
尽管在静态图像的解耦表示学习方面已经取得了一些进展,但在视频领域,尤其是在没有对对象可能具有的属性类型做出具体假设的一般性设置中,这方面的工作还相对欠缺。解耦表示通过将对象的不同属性(例如颜色、形状、大小等)分离,可能进一步提高模型对视觉动态的预测能力。
当前的视觉动态预测方法在处理对象动态时,通常需要依赖于对象属性的显式监督信息,或者在静态图像上进行解耦表示学习。这些方法在处理视频数据时可能存在局限性。
为了克服现有方法的局限性,并充分利用解耦表示在视频动态预测中的潜力,本文提出了一种新的架构——DisFormer。这一架构旨在通过无监督的方式学习目标中心模型中的解耦表示,并利用这些表示来提高视觉动态预测的准确性和泛化能力。
1 相关工作
1.1 对象中心图像和视频模型
对象中心模型旨在将图像或视频分解为对象和背景,并对每个对象进行单独建模。这类模型通常使用空间注意力机制来发现对象,并使用生成模型或自回归模型来重建图像或视频。例如:
- AIR:基于空间注意力机制的对象中心模型,通过迭代细化学习对象的表示。AIR模型结合了空间注意力机制和对象中心的学习方法,通过自适应地选择和处理关键区域的信息,提高了模型在计算机视觉任务中的性能和泛化能力
- MONet:基于空间注意力机制的对象中心模型,通过分解对象和背景来重建图像。
- SPACE:基于空间注意力机制的对象中心模型,通过分解对象和背景来重建图像,并学习对象的动态。
- IODINE:基于空间混合模型的对象中心模型,通过分解对象和背景来重建图像,并学习对象的动态。
- GENESIS:基于空间混合模型的对象中心模型,通过分解对象和背景来重建图像,并学习对象的动态。
- SLATE:基于空间混合模型的对象中心模型,通过分解对象和背景来重建图像,并学习对象的动态。
1.2 动态预测模型
动态预测模型旨在预测视频帧序列的未来状态。这类模型通常使用自回归模型或生成模型来预测未来帧。例如:
- Interaction Networks:基于交互网络的对象中心模型,通过学习对象之间的关系来预测其动态。
- Billiards:基于物理模型的动态预测模型,通过学习物体的运动规律来预测其未来状态。
- Galileo:基于深度学习和物理引擎的动态预测模型,通过整合物理引擎和深度学习来预测物体的物理属性。
- GSWM:对象中心生成模型,通过学习对象的表示来预测其动态。
- SlotFormer:基于槽位注意力的对象中心动态模型,将视频分解为对象和背景,并分别进行建模。
1.3 对象解耦模型
对象解耦模型旨在将对象分解为多个属性,并学习每个属性的表示。这类模型通常使用迭代细化或自编码器来学习解耦表示。例如:
- Scalor:基于分解和组合的对象解耦模型,通过分解对象和背景来学习解耦表示。
- SimOne:基于视图不变性和时间抽象的对象解耦模型,通过无监督视频分解来学习解耦表示。
- Simple Unsupervised Object-Centric Learning:基于简单无监督对象中心学习的解耦模型,通过无监督学习来学习解耦表示。
- Neural Systematic Binder:基于线性组合的对象解耦模型,通过学习对象属性的概念向量来学习解耦表示。
1.4 DisFormer 与现有方法的区别
与现有方法相比,DisFormer 具有以下特点:
- 解耦表示: 通过迭代细化将对象分解为多个“块”,每个块代表对象的一个潜在属性,从而学习解耦表示。
- Transformer 动态预测:利用 Transformer 预测对象未来状态,并能够捕捉对象之间的交互关系。
- 对象中心表示:直接使用对象表示,而不依赖于特定的对象提取器,因此具有更好的泛化能力。
2 DisFormer模型
DisFormer 是一种基于 Transformer 的视觉动态预测模型,其主要目标是学习解耦的对象表示,并利用该表示来预测对象的未来状态。DisFormer 模型主要由以下四个模块组成:

2.1 遮罩提取器 (Mask Extractor)
遮罩提取器负责提取视频帧中的对象遮罩。DisFormer 使用 SAM (Segment Anything) 模型和 SAVi (Slot Attention for Video) 模型联合提取对象遮罩。
- SAVi 模型:首先使用 SAVi 模型对视频帧进行对象发现,并生成对象遮罩的粗略估计。
- SAM 模型:然后使用 SAM 模型对 SAVi 模型生成的遮罩进行细化,生成更精确的对象遮罩。
2.2 块提取器 (Block Extractor)
块提取器负责将对象分解为多个“块”,每个块代表对象的一个潜在属性。块提取器使用迭代细化的方法来学习解耦表示。
- 初始化:每个对象的块表示初始化为对象表示的线性组合。
- 迭代细化:块表示通过自注意力机制与对象表示进行交互,并更新其表示,直到收敛。
- 解耦表示:每个块表示最终表示为一个固定数量的可学习概念向量的线性组合,从而实现解耦表示。
2.3 动态预测器 (Dynamics Predictor)
动态预测器负责预测对象未来状态。动态预测器使用 Transformer 模型来捕捉对象之间的交互关系,并预测对象的未来状态。
- 线性投影:将每个块表示投影到高维空间。
- 自注意力机制:使用自注意力机制捕捉对象之间的交互关系。
- 解码:将预测的对象状态解码为图像。
2.4 解码器 (Decoder)
解码器负责将解耦的对象表示解码为图像。解码器使用空间混合模型来生成图像。
- 空间广播解码器:将每个块表示解码为 2D 特征图。
- 卷积神经网络:将 2D 特征图解码为图像。
3实验部分
3.1 数据集
在四个不同的数据集上进行了一系列实验,以评估DisFormer的性能。这些数据集包括两个2D数据集和两个3D数据集,涵盖了从简单的玩具环境到更复杂的3D动态:
- 2D Bouncing Circles (2D-BC):一个包含三个不同颜色球体在 2D 空间中自由运动和碰撞的合成数据集。
- 2D Bouncing Shapes (2D-BS):一个包含两个圆形和两个正方形在 2D 空间中自由运动和碰撞的合成数据集。
- OBJ3D:一个包含一个弹性球体进入场景并与其他静止物体碰撞的合成数据集。
- CLEVRER:一个包含各种形状、颜色和材质的物体在 3D 空间中运动和交互的合成数据集。
3.2 基线模型
本文将 DisFormer 与以下两种基线模型进行了比较:
- GSWM:对象中心生成模型,通过学习对象的表示来预测其动态。模型的目标是提高生成想象力,并且可以通过PyTorch实现。
- SlotFormer:基于槽位注意力的对象中心动态模型,将视频分解为对象和背景,并分别进行建模。使用Transformer网络来建模视频中对象的空间-时间动态关系,并生成未来帧。
3.3 评价指标
使用的评估指标包括像素均方误差(PErr)、峰值信噪比(PSNR)、感知损失(LPIPS)和结构相似性指数(SSIM)。
- 像素均方误差(PErr):指均方误差(MSE),用于衡量图像处理前后的质量变化。
- 峰值信噪比(PSNR):PSNR是“Peak Signal to Noise Ratio”的缩写,即峰值信噪比,是一种评价图像的客观标准。PSNR的单位是dB,数值越大表示失真越小。
- 感知损失(LPIPS):LPIPS,也称为“感知损失”,用于度量两张图像之间的差别。这个指标通过深度学习模型来评估两个图像之间的感知差异。
- 结构相似性指数(SSIM):SSIM是“Structural Similarity Index”的缩写,即结构相似性指数,用于衡量两幅图像之间的相似度。SSIM考虑了图像的亮度、对比度和结构三个方面,取值范围在-1到1之间,1表示两幅图像完全相同,-1表示两幅图像完全不同。
3.4 实验结果
实验结果表明,DisFormer 在所有数据集上均取得了优于 GSWM 和 SlotFormer 的性能,尤其是在 OOD 设置下。

- 2D 数据集:DisFormer 在 PErr 和 PSNR 指标上均优于 GSWM 和 SlotFormer,在 OOD 设置下性能提升更为显著。

- 3D 数据集:DisFormer 在 PSNR 和 SSIM 指标上优于 GSWM 和 SlotFormer,在 OOD 设置下性能提升更为显著。
4 未来方向和局限性
4.1 未来工作方向
- 更复杂的场景: 将 DisFormer 扩展到更复杂的场景,例如具有更多对象和背景交互的场景。
- 更复杂的 3D 场景: 将 DisFormer 扩展到更复杂的 3D 场景,并解决 3D 数据集中属性解耦不完全的问题。
- 动作条件预测: 将 DisFormer 扩展到动作条件视频预测,以便模型能够根据动作预测视频动态。
- 超参数分析: 深入分析概念数量和块数量等超参数对模型性能的影响,并找到最佳的超参数设置。
- 真实世界数据集: 在真实世界数据集上进行实验,以评估 DisFormer 在真实场景中的性能。
4.2 局限性
- 3D 数据集的属性解耦: DisFormer 在 3D 数据集上的属性解耦效果不如 2D 数据集,这可能是由于 3D 场景的复杂性更高。
- 真实世界数据集的实验: 目前还没有在真实世界数据集上进行实验,因此 DisFormer 在真实场景中的性能还有待验证
相关文章:
DisFormer:提高视觉动态预测的准确性和泛化能力
最新的研究进展已经显示出目标中心的表示方法在视觉动态预测任务中可以显著提升预测精度,并且增加模型的可解释性。这种表示方法通过将视觉场景分解为独立的对象,有助于模型更好地理解和预测场景中的变化。 尽管在静态图像的解耦表示学习方面已经取得了一…...
)
Android SurfaceFlinger——Surface和Layer介绍(十九)
按照前面系统开机动画的流程继续分析,在获取到显示屏信息后,下一步就是开始创建 Surface和设置 Layer 层级,这里就出现了两个新的概念——Surface 和 Layer。 一、基本概念 1、Surface介绍 在 Android 系统中,Surface 是一个非常核心的概念,它是用于显示图像的生产者-消…...

C++基础(七):类和对象(中-2)
上一篇博客学的默认成员函数是类和对象的最重要的内容,相信大家已经掌握了吧,这一篇博客接着继续剩下的内容,加油! 目录 一、const成员(理解) 1.0 引入 1.1 概念 1.2 总结 1.2.1 对象调用成员函数 …...

对秒杀的思考
一、秒杀的目的 特价商品,数量有限,先到先得,售完为止 二、优惠券的秒杀 和特价商品的秒杀是一样的,只不过秒杀的商品是优惠券 三、秒杀的需求 秒杀前:提前将秒杀商品,存放到Redis秒杀中:使…...
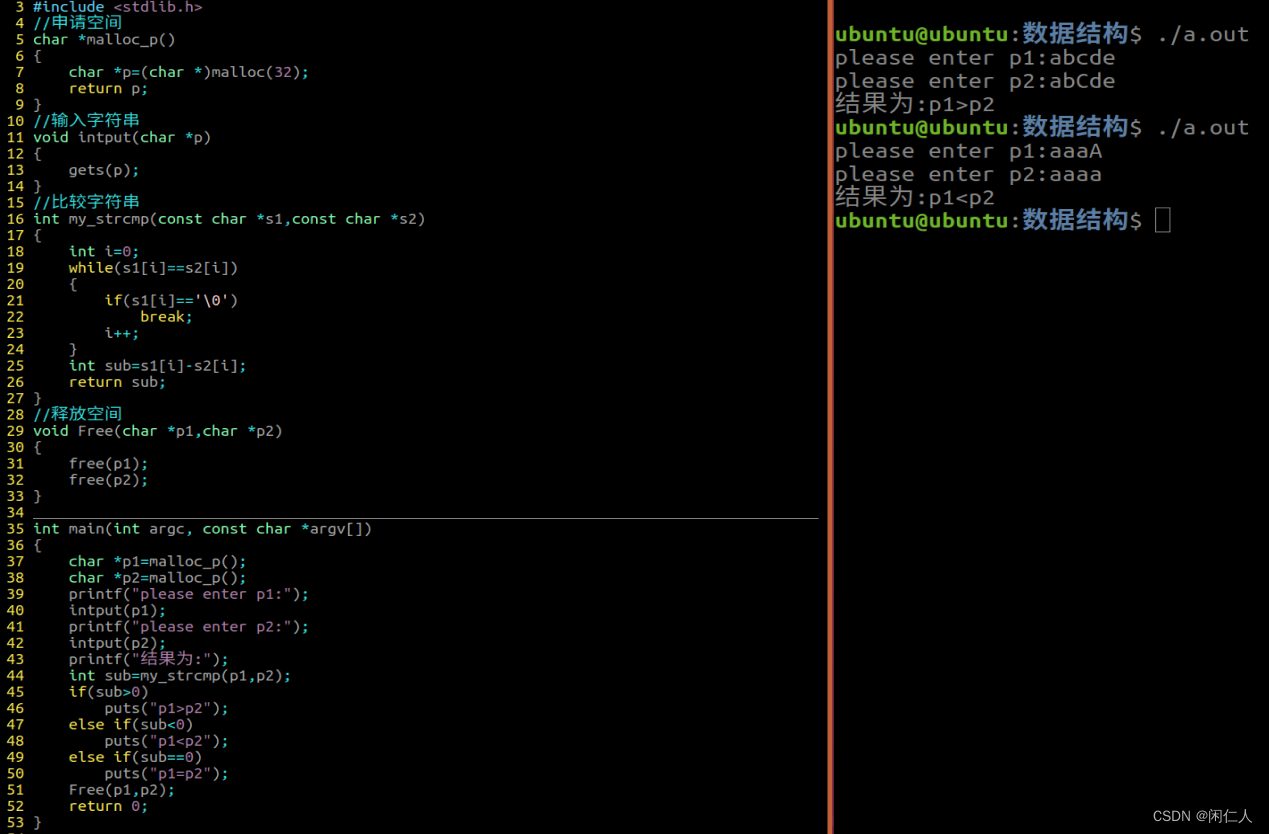
数据结构预科
在堆区申请两个长度为32的空间,实现两个字符串的比较【非库函数实现】 要求: 1> 定义函数,在对区申请空间,两个申请,主函数需要调用2次 2> 定义函数,实现字符串的输入,void input(char …...

想做亚马逊测评技术需要解决哪些问题,有哪些收益?
现在真正有亚马逊测评技术的人赚的盆满钵满,有些人看到别人赚取就自己盲目去做,买完了账号和设备就感觉自己懂了,却不知里面的水深着,花了钱却没有掌握真正的技术,号莫名其妙就封完了,而每一次大风控注定要…...

1117 数字之王
solution 判断现有数字是否全为个位数 全为个位数,找出出现次数最多的数字,并首行输出最多出现次数,第二行输出所有出现该次数的数值不全为个位数 若当前位数值为0,无需处理若当前位数值非0,则每位立方相乘࿰…...

关于ORACLE单例数据库中的logfile的切换、删除以及添加
一、有关logfile的状态解释 UNUSED: 尚未记录change的空白group(一般会出现在loggroup刚刚被添加,或者刚刚使用了reset logs打开数据库,或者使用clear logfile后) CURRENT: 当前正在被LGWR使用的gro…...

Linux高并发服务器开发(十三)Web服务器开发
文章目录 1 使用的知识点2 http请求get 和 post的区别 3 整体功能介绍4 基于epoll的web服务器开发流程5 服务器代码6 libevent版本的本地web服务器 1 使用的知识点 2 http请求 get 和 post的区别 http协议请求报文格式: 1 请求行 GET /test.txt HTTP/1.1 2 请求行 健值对 3 空…...

人工智能系列-NumPy(二)
🌈个人主页:羽晨同学 💫个人格言:“成为自己未来的主人~” 链接数组 anp.array([[1,2],[3,4]]) print(第一个数组:) print(a) print(\n) bnp.array([[5,6],[7,8]]) print(第二个数组:) print(b) print(\n) print…...

[单master节点k8s部署]19.监控系统构建(四)kube-state-metrics
kube-state-metrics 是一个Kubernetes的附加组件,它通过监听 Kubernetes API 服务器来收集和生成关于 Kubernetes 对象(如部署、节点和Pod等)的状态的指标。这些指标可供 Prometheus 进行抓取和存储,从而使你能够监控和分析Kubern…...

字符串函数5-9题(30 天 Pandas 挑战)
字符串函数 1. 相关知识点1.5 字符串的长度条件判断1.6 apply映射操作1.7 python大小写转换1.8 正则表达式匹配2.9 包含字符串查询 2. 题目2.5 无效的推文2.6 计算特殊奖金2.7 修复表中的名字2.8 查找拥有有效邮箱的用户2.9 患某种疾病的患者 1. 相关知识点 1.5 字符串的长度条…...

【C语言题目】34.猜凶手
文章目录 作业标题作业内容2.解题思路3.具体代码 作业标题 猜凶手 作业内容 日本某地发生了一件谋杀案,警察通过排查确定杀人凶手必为4个嫌疑犯的一个。 以下为4个嫌疑犯的供词: A说:不是我。 B说:是C。 C说:是D。 D说ÿ…...

C++ 多进程多线程间通信
目录 一、进程间通信 1、管道(Pipe) 2、消息队列(Message Queue) 3、共享内存(Shared Memory) 4、信号量(Semaphore) 5、套接字(Socket) 6、信号&…...

怎么做防御系统IPS
入侵防御系统(IPS)是入侵检测系统(IDS)的增强版本,它不仅检测网络流量中的恶意活动,还能自动采取措施阻止这些活动。实现IPS的主要工具包括Snort和Suricata。以下是使用Snort和Suricata来实现IPS的详细步骤…...

达梦数据库的系统视图v$auditrecords
达梦数据库的系统视图v$auditrecords 在达梦数据库(DM Database)中,V$AUDITRECORDS 是专门用来存储和查询数据库审计记录的重要系统视图。这个视图提供了对所有审计事件的访问权限,包括操作类型、操作用户、时间戳、目标对象等信…...

Spring Boot与MyBatis-Plus:代码逆向生成指南
在Spring Boot项目中使用MyBatis-Plus进行代码逆向生成,可以通过MyBatis-Plus提供的代码生成器来快速生成实体类、Mapper接口、Service接口及其实现类等。以下是一个简单的示例步骤: 代码逆向生成 1.添加依赖: 在pom.xml文件中添加MyBati…...
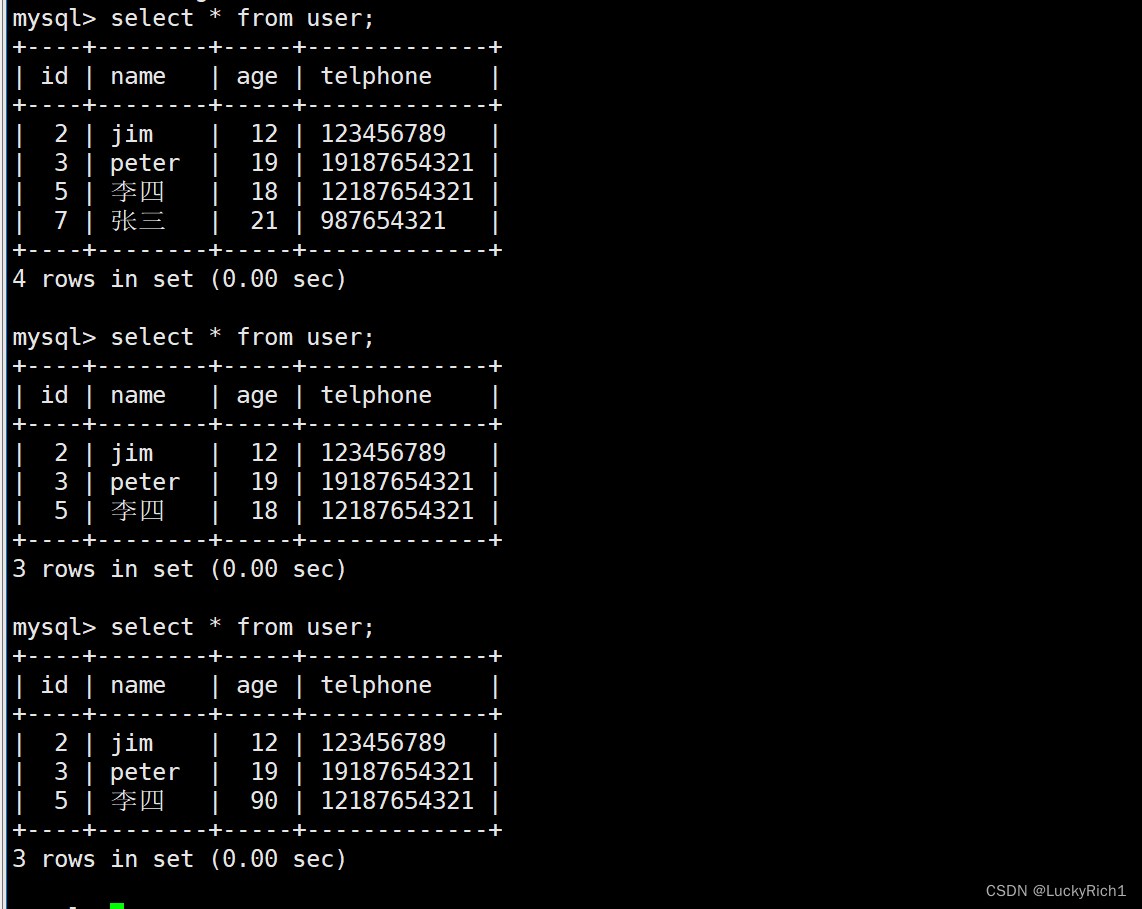
【MySQL】mysql访问
mysql访问 1.引入MySQL 客户端库2.C/C 进行增删改3.查询的处理细节4.图形化界面访问数据库4.1下载MYSQL Workbench4.2MYSQL Workbench远程连接数据库 点赞👍👍收藏🌟🌟关注💖💖 你的支持是对我最大的鼓励&a…...
(1)Jupyter Notebook 下载及安装
目录 1. Jupyter Notebook是什么?2. Jupyter Notebook特征3. 组成部分3.1 网页应用3.2 文档 4. 适用场景5. 利用Google Colab安装Jupyter Notebook3.1 什么是 Colab?3.2 访问 Google Colab3.3 新建笔记本 1. Jupyter Notebook是什么? 百度百科…...
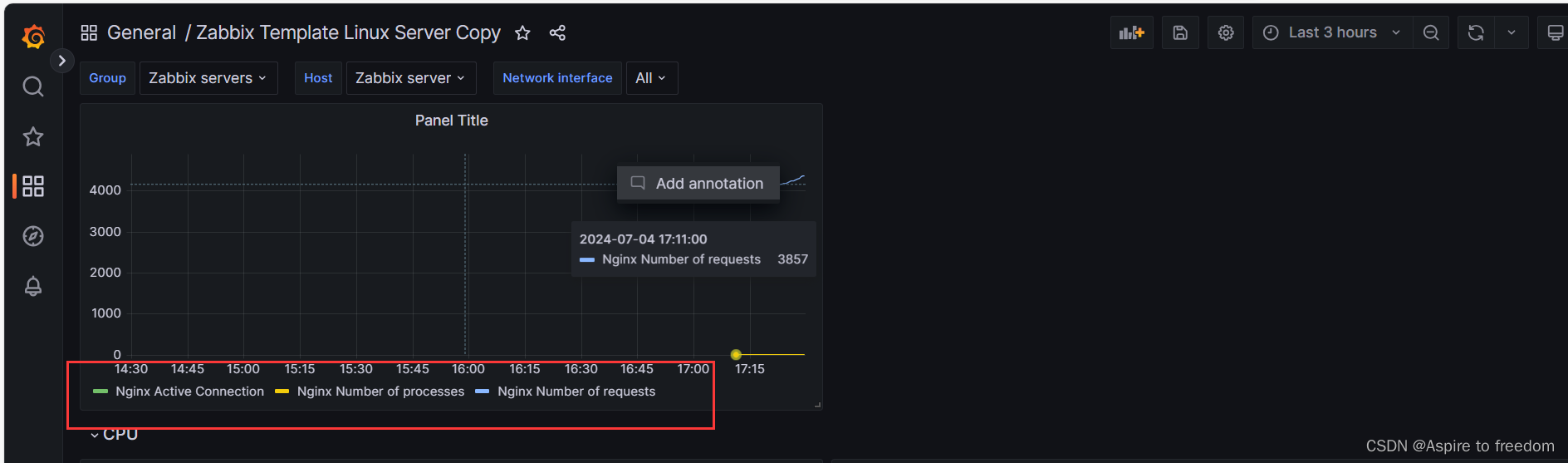
监控平台zabbix对接grafana
本次博客基于监控平台zabbix介绍与部署-CSDN博客的环境下进行的 1、安装grafana并启动 添加一台虚拟机20.0.0.30 (1)系统初始化 [rootzx3 ~]# systemctl stop firewalld [rootzx3 ~]# setenforce 0 [rootzx3 ~]#(2)安装并启动…...

API接口签名验证实战
API接口签名验证实战 一、接口签名概述 API签名验证是保护接口安全的重要手段,防止请求被篡改或伪造。 1.1 签名机制原理 ┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐ │ 客…...

显卡驱动彻底清理解决方案:Display Driver Uninstaller专业使用指南
显卡驱动彻底清理解决方案:Display Driver Uninstaller专业使用指南 【免费下载链接】display-drivers-uninstaller Display Driver Uninstaller (DDU) a driver removal utility / cleaner utility 项目地址: https://gitcode.com/gh_mirrors/di/display-drivers…...

终极指南:无需微软账户离线启用Windows Insider预览计划的完整方案
终极指南:无需微软账户离线启用Windows Insider预览计划的完整方案 【免费下载链接】offlineinsiderenroll OfflineInsiderEnroll - A script to enable access to the Windows Insider Program on machines not signed in with Microsoft Account 项目地址: http…...

计算机网络基础:TCP/IP 与 HTTP 核心知识
摘要:计算机网络是后台开发和 AI 基础设施面试的重要考点。本文从 OSI 七层模型出发,重点讲解 TCP 三次握手/四次挥手、HTTP/HTTPS 协议、以及 WebSocket 和 RESTful API 设计,并结合 Python 代码展示 Socket 编程和简单的 HTTP 服务器实现。…...

独立开发者如何利用 Taotoken 的 Token Plan 套餐以更优成本启动 AI 项目
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何利用 Taotoken 的 Token Plan 套餐以更优成本启动 AI 项目 对于独立开发者或小型工作室而言,在项目启动…...

认知殖民的几何级放大器:论概率拟合AI范式的内生危机、利益锁定与公理驱动的范式跃迁
认知殖民的几何级放大器:论概率拟合AI范式的内生危机、利益锁定与公理驱动的范式跃迁 摘要 当前,以大语言模型为核心的生成式人工智能掀起全球技术热潮,“涌现特性”“通用人工智能”等概念持续主导行业舆论与研发风向。然而剥离技术表象与…...

ARM嵌入式C#开发实战:基于SkiaSharp的低延迟GUI实现
1. 这不是玩具,是ARM嵌入式系统能力的“压力测试仪”很多人第一次听说“在ARM开发板上跑C#游戏”,第一反应是:这能行?C#不是Windows桌面和服务器的语言吗?Mono?.NET Core?ARM板子连图形驱动都配…...

windows VS工具判断动态库是32位还是64位
dumpbin /headers yourfile.dll | findstr "machine"...

22. 与 React 集成
22. 与 React 集成 1. 概述 TypeScript 与 React 的集成是现代前端开发的标准实践。TypeScript 为 React 组件提供了类型安全,帮助在编译时发现错误,提升开发体验和代码质量。 ┌───────────────────────────────────…...

Beyond Compare 5密钥生成器:从评估到期到永久授权的完整解决方案
Beyond Compare 5密钥生成器:从评估到期到永久授权的完整解决方案 【免费下载链接】BCompare_Keygen Keygen for BCompare 5 项目地址: https://gitcode.com/gh_mirrors/bc/BCompare_Keygen 你是否在使用Beyond Compare 5进行文件对比时,遇到了30…...