Beats:使用 Filebeat 从 Python 应用程序中提取日志
本指南演示了如何从 Python 应用程序中提取日志并将其安全地传送到 Elasticsearch Service 部署中。你将设置 Filebeat 来监控具有标准 Elastic Common Schema (ECS) 格式字段的 JSON 结构日志文件,然后你将在 Kibana 中查看日志事件发生的实时可视化。虽然此示例使用的是 Python,但这种监控日志输出的方法适用于多种客户端类型。查看可用的 ECS 日志记录插件列表。

在今天的展示中,我将使用 Elastic Stack 8.14.1 来进行展示。
前提
要完成这些步骤,你需要在系统上安装 Python 以及 Python 日志库的 Elastic Common Schema (ECS) 记录器。
要安装 ecs-logging-python,请运行:
python -m pip install ecs-logging准备
Elasticsearch 及 Kibana 安装
如果你还没有安装好自己的 Elasticsearch 及 Kibana,请参考如下的文章来进行安装:
-
如何在 Linux,MacOS 及 Windows 上进行安装 Elasticsearch
-
Kibana:如何在 Linux,MacOS 及 Windows 上安装 Elastic 栈中的 Kibana
在安装的时候,我们选择 Elastic Stack 8.x 来进行安装。特别值得指出的是:ES|QL 只在 Elastic Stack 8.11 及以后得版本中才有。你需要下载 Elastic Stack 8.11 及以后得版本来进行安装。
在首次启动 Elasticsearch 的时候,我们可以看到如下的输出:
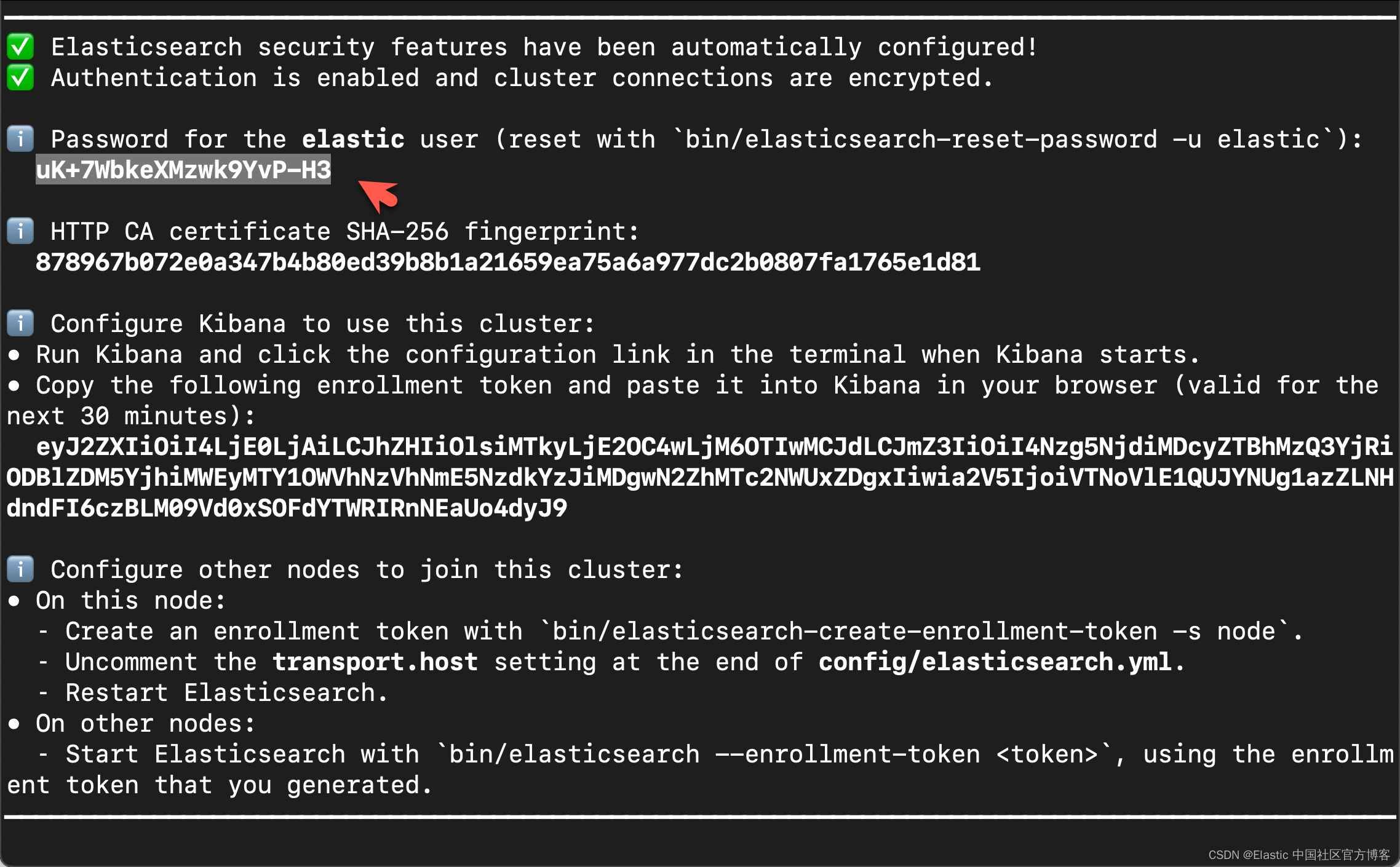
在上面,我们可以看到 elastic 超级用户的密码。我们记下它,并将在下面的代码中进行使用。
我们还可以在安装 Elasticsearch 目录中找到 Elasticsearch 的访问证书:
$ pwd
/Users/liuxg/elastic/elasticsearch-8.14.1/config/certs
$ ls
http.p12 http_ca.crt transport.p12在上面,http_ca.crt 是我们需要用来访问 Elasticsearch 的证书。
生成 API key
在今天的配置中,我们将使用 API key 来配置 Filebeat。我们来在 Kibana 中申请一个 key:
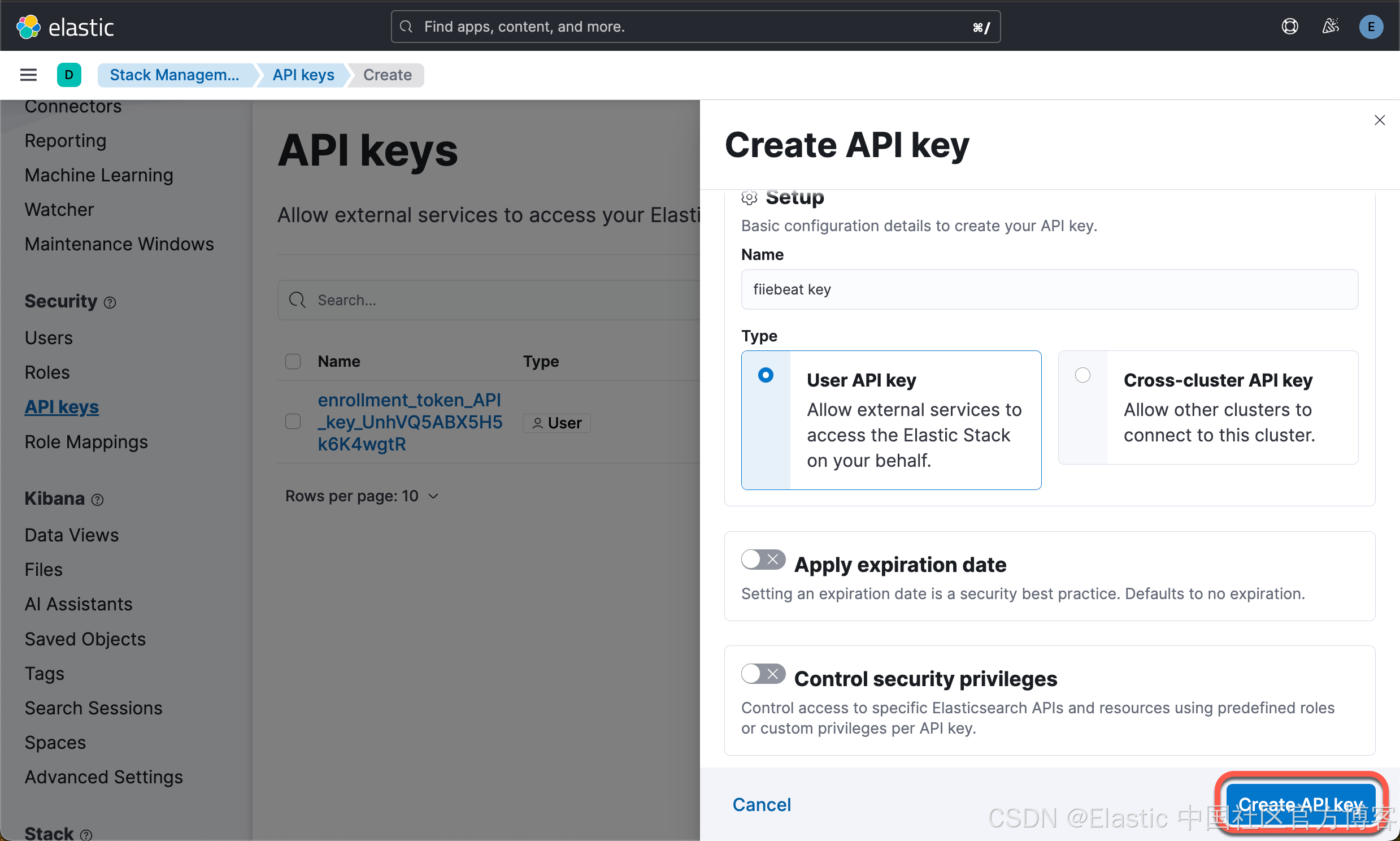
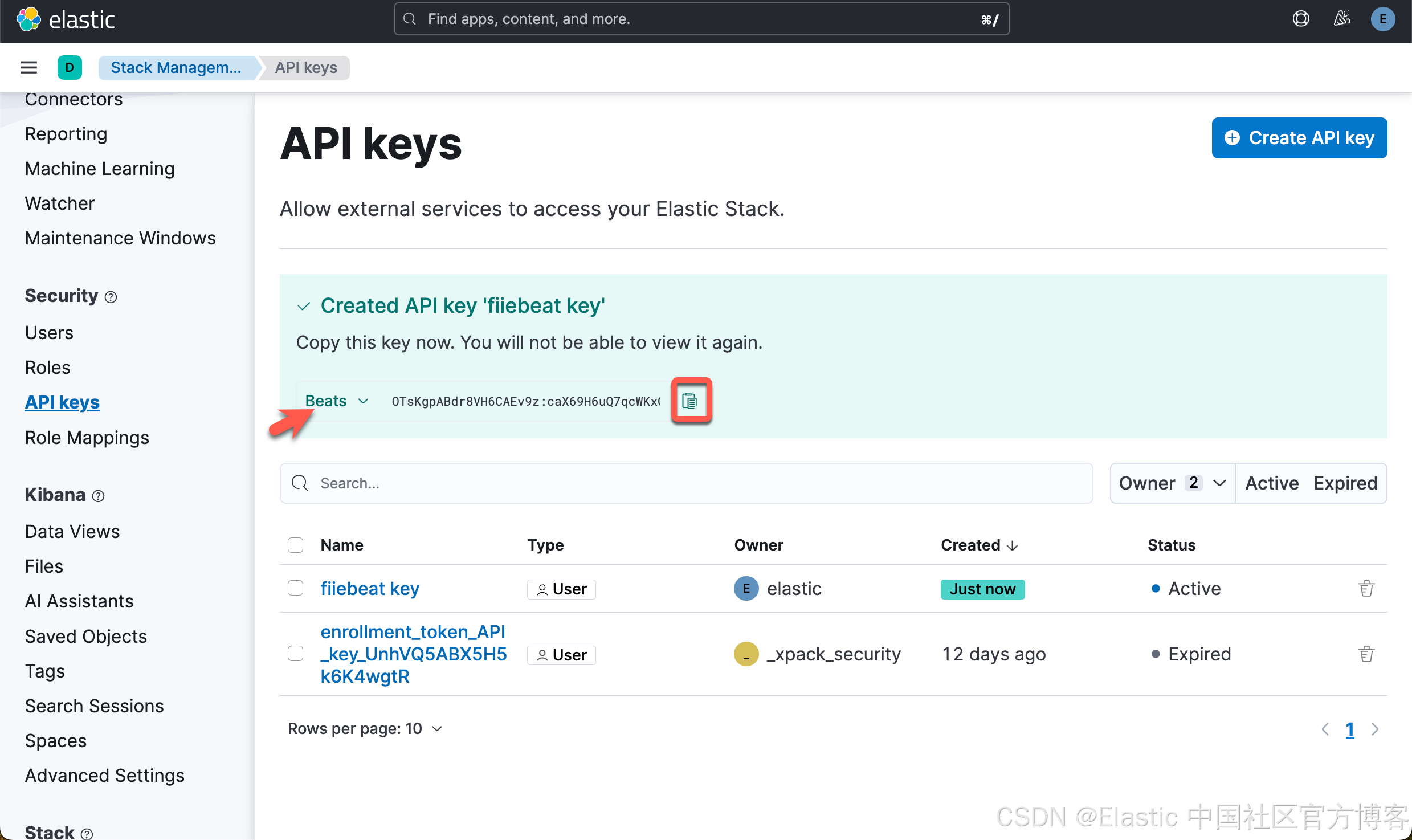
我们点击上面的 copy 按钮来拷贝 API key:OTsKgpABdr8VH6CAEv9z:caX69H6uQ7qcWKxQxeopuQ
我们也可以使用如下的命令来活动 API key:
POST /_security/api_key
{"name": "filebeat-api-key","role_descriptors": {"logstash_read_write": {"cluster": ["manage_index_templates", "monitor"],"index": [{"names": ["filebeat-*"],"privileges": ["create_index", "write", "read", "manage"]}]}}
}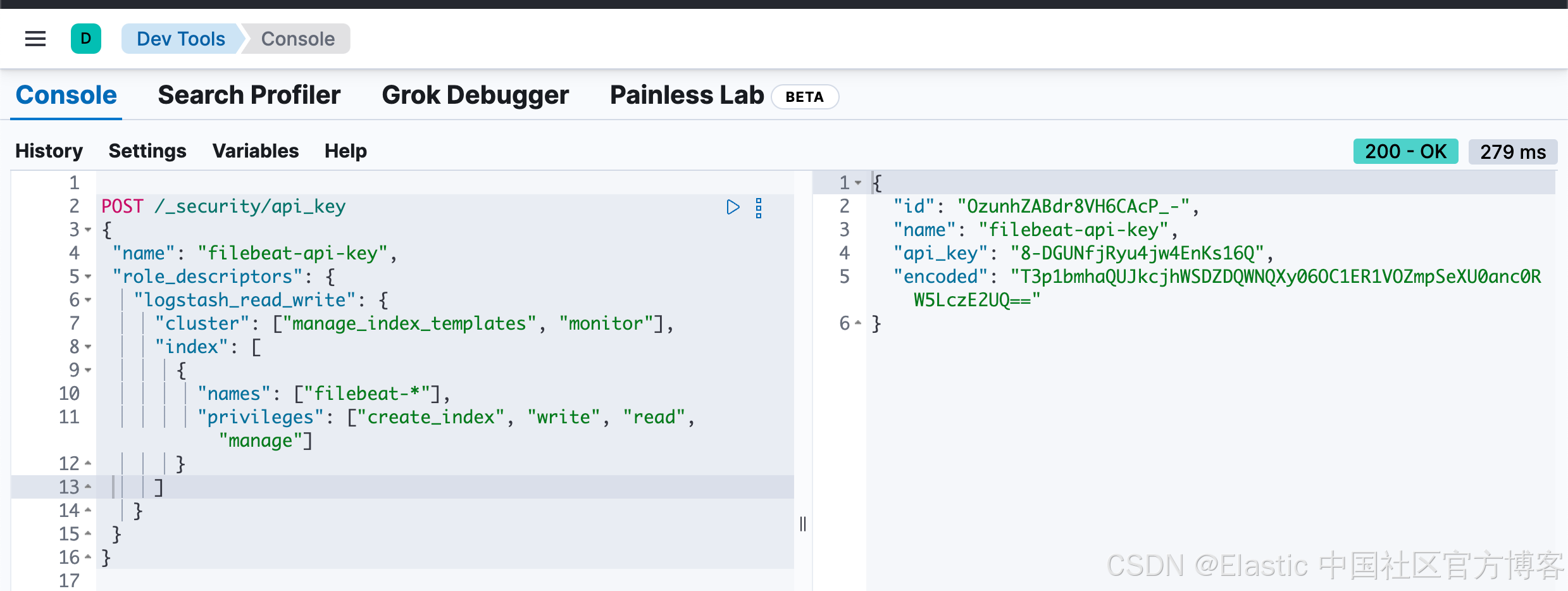
上面的命令将会得到如下所示的回复:
{"id": "OzunhZABdr8VH6CAcP_-","name": "filebeat-api-key","api_key": "8-DGUNfjRyu4jw4EnKs16Q","encoded": "T3p1bmhaQUJkcjhWSDZDQWNQXy06OC1ER1VOZmpSeXU0anc0RW5LczE2UQ=="
}安装 Filebeat
我们可以到地址下载 Filebeat,并加压缩来进行安装:
$ pwd
/Users/liuxg/elastic
$ ls
elasticsearch-8.14.1 kibana-8.14.1-darwin-aarch64.tar.gz
elasticsearch-8.14.1-darwin-aarch64.tar.gz logstash-8.14.1-darwin-aarch64.tar.gz
filebeat-8.14.1-darwin-aarch64.tar.gz metricbeat-8.14.1-darwin-aarch64.tar.gz
kibana-8.14.1
$ tar xzf filebeat-8.14.1-darwin-aarch64.tar.gz
$ cd filebeat-8.14.1-darwin-aarch64
$ ls
LICENSE.txt fields.yml filebeat.yml modules.d
NOTICE.txt filebeat kibana
README.md filebeat.reference.yml module安装命令如上所示,我们可以看到一个关于 Filebeat 的配置文件 filebeat.yml 文件。在下面的步骤中,我们将对它进行配置。
创建 Python 脚本来生成日志
在此步骤中,你将使用 Python 的标准日志模块创建一个以 JSON 格式生成日志的 Python 脚本。
1)在本地目录中,创建一个新文件 elvis.py 并保存以下内容:
$ pwd
/Users/liuxg/python
$ cd python-logs
$ ls
$ code elvis.py我们把如下的内容粘贴到 elvis.py 文件中去:
elvis.py
#!/usr/bin/pythonimport logging
import ecs_logging
import time
from random import randint#logger = logging.getLogger(__name__)
logger = logging.getLogger("app")
logger.setLevel(logging.DEBUG)
handler = logging.FileHandler('elvis.json')
handler.setFormatter(ecs_logging.StdlibFormatter())
logger.addHandler(handler)print("Generating log entries...")messages = ["Elvis has left the building.",#"Elvis has left the oven on.","Elvis has two left feet.","Elvis was left out in the cold.","Elvis was left holding the baby.","Elvis left the cake out in the rain.","Elvis came out of left field.","Elvis exited stage left.","Elvis took a left turn.","Elvis left no stone unturned.","Elvis picked up where he left off.","Elvis's train has left the station."]while True:random1 = randint(0,15)random2 = randint(1,10)if random1 > 11:random1 = 0if(random1<=4):logger.info(messages[random1], extra={"http.request.body.content": messages[random1]})elif(random1>=5 and random1<=8):logger.warning(messages[random1], extra={"http.request.body.content": messages[random1]})elif(random1>=9 and random1<=10):logger.error(messages[random1], extra={"http.request.body.content": messages[random1]})else:logger.critical(messages[random1], extra={"http.request.body.content": messages[random1]})time.sleep(random2)此 Python 脚本会随机生成十二条日志消息中的一条,连续生成,间隔为 1 到 10 秒。日志消息会写入文件 elvis.json,每条消息都带有时间戳、日志级别(信息、警告、错误或严重)和其他数据。为了给日志数据添加一些变化,Info 消息 "Elvis has left the building" 被设置为最可能的日志事件。在代码中,如果 random1 > 11,那么 random1 就被设置为 0。从这里我们可以看出来。
为简单起见,只有一个日志文件,它会写入 elvis.py 所在的本地目录。在生产环境中,你可能有多个日志文件,与不同的模块和记录器相关联,并且可能存储在 /var/log 或类似目录中。要了解有关在 Python 中配置日志的更多信息,请查看 Python 的日志记录工具。
使用带有 ECS 字段的 JSON 格式编写日志可以轻松解析和分析,并与其他应用程序实现标准化。随着日志中捕获的数据量和类型随时间推移而扩大,标准、易于解析的格式变得越来越重要。
除了每个日志条目所包含的标准字段外,还有一个额外的 http.request.body.content 字段。这个额外的字段只是为了给你提供一些额外的、有趣的数据,同时也是为了演示如何向日志数据添加可选字段。查看 ECS 字段参考以获取可用字段的完整列表。
2)让我们测试一下 Python 脚本。在保存 elvis.py 的位置打开一个终端实例并运行以下命令:
python elvis.py$ pwd
/Users/liuxg/python/python-logs
$ python elvis.py
Generating log entries...
脚本运行约 15 秒后,输入 CTRL + C 停止它。查看新生成的 elvis.json。它应该包含一个或多个类似这样的条目:

3)确认 elvis.py 按预期运行后,可以删除 elvis.json。
配置 Filebeat
在 <localpath>/filebeat-<version>/(其中 <localpath> 是 Filebeat 安装的目录,<version> 是 Filebeat 版本号)中打开 filebeat.yml 配置文件进行编辑。我们可以参考文章 “Elastic Stack 8.0 安装 - 保护你的 Elastic Stack 现在比以往任何时候都简单” 中描述的配置 Metricbeat 来配置 Filebeat。
配置 Filebeat inputs
Filebeat 有多种收集日志的方法。在本例中,你将手动配置日志收集。
在 filebeat.yml 的 filebeat.inputs 部分中,将 enabled: 设置为 true,并将 paths: 设置为日志文件的位置。在本例中,设置你保存 elvis.py 的同一目录:
filebeat.yml

你可以指定通配符 (*) 来表示应读取指定目录中的所有日志文件。你还可以使用通配符从多个目录读取日志。例如 /var/log/*/*.log。
在上面,你需要根据自己的配置进行相应的修改。
添加 JSON 输入选项
Filebeat 的输入配置选项包括几个用于解码 JSON 消息的设置。日志文件是逐行解码的,因此每行包含一个 JSON 对象非常重要。
对于此示例,Filebeat 使用以下四个解码选项。
json.keys_under_root: truejson.overwrite_keys: truejson.add_error_key: truejson.expand_keys: true要了解有关这些设置的更多信息,请查看 Filebeat 参考中的 JSON 输入配置选项和解码 JSON 字段。
将四个 JSON 解码选项附加到 filebeat.yml 的 Filebeat 输入部分,以便该部分现在如下所示:
filebeat.yml

配置 Elasticsearch
我们需要为 Filebeat 的 output 进行配置。我们的配置如下:
filebeat.yml

我们需要根据自己的配置修改上面的值。为了验证修改的正确性,我们可以使用如下的命令进行验证:
$ pwd
/Users/liuxg/elastic/filebeat-8.14.1-darwin-aarch64
$ ./filebeat test config
Config OK
上面表明,我们的配置(yml 文件的格式)都是没有任何问题的。
我们使用如下的命令来测试和 Elasticsearch 的链接是否有问题:
$ pwd
/Users/liuxg/elastic/filebeat-8.14.1-darwin-aarch64
$ ./filebeat test output
elasticsearch: https://localhost:9200...parse url... OKconnection...parse host... OKdns lookup... OKaddresses: 127.0.0.1dial up... OKTLS...security: server's certificate chain verification is enabledhandshake... OKTLS version: TLSv1.3dial up... OKtalk to server... OKversion: 8.14.1
上面显示,我们的链接是成功的。
注意:如果你是使用 API 命令获得的,你也可以使用如下的格式来修改上面的 API key 配置格式。将你的 API 密钥信息添加到 filebeat.yml 的 Elasticsearch 输出部分,就在 output.elasticsearch: 下方。使用格式 <id>:<api_key>。如果你的结果如本例所示,请输入 OzunhZABdr8VH6CAcP_-:8-DGUNfjRyu4jw4EnKs16Q。

完成 Filebeat 的设置
Filebeat 附带预定义资产,用于解析、索引和可视化数据。要加载这些资产,请从 Filebeat 安装目录运行以下命令:
截止此时,我们已经配置了我们所需要的一切。在下面,我们可以开始我们的展示了。
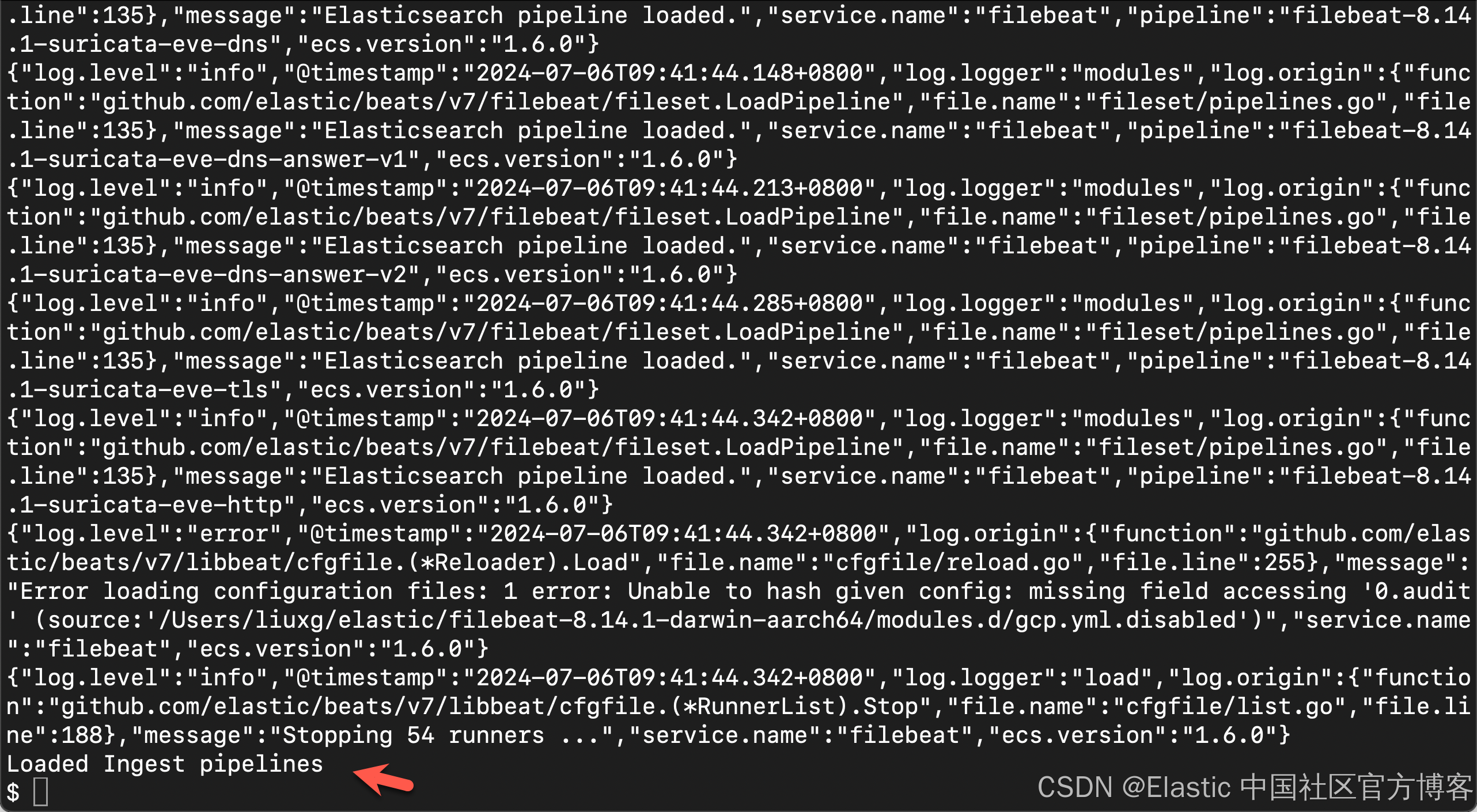
./filebeat setup -e
重要:根据安装位置、环境和本地权限等变量,你可能需要更改 filebeat.yml 的所有权。你还可以尝试以 root 身份运行该命令:sudo ./filebeat setup -e,或者你可以通过运行带有 --strict.perms=false 选项的命令来禁用严格权限检查。
设置过程需要几分钟。如果一切顺利,你将收到一条确认消息:
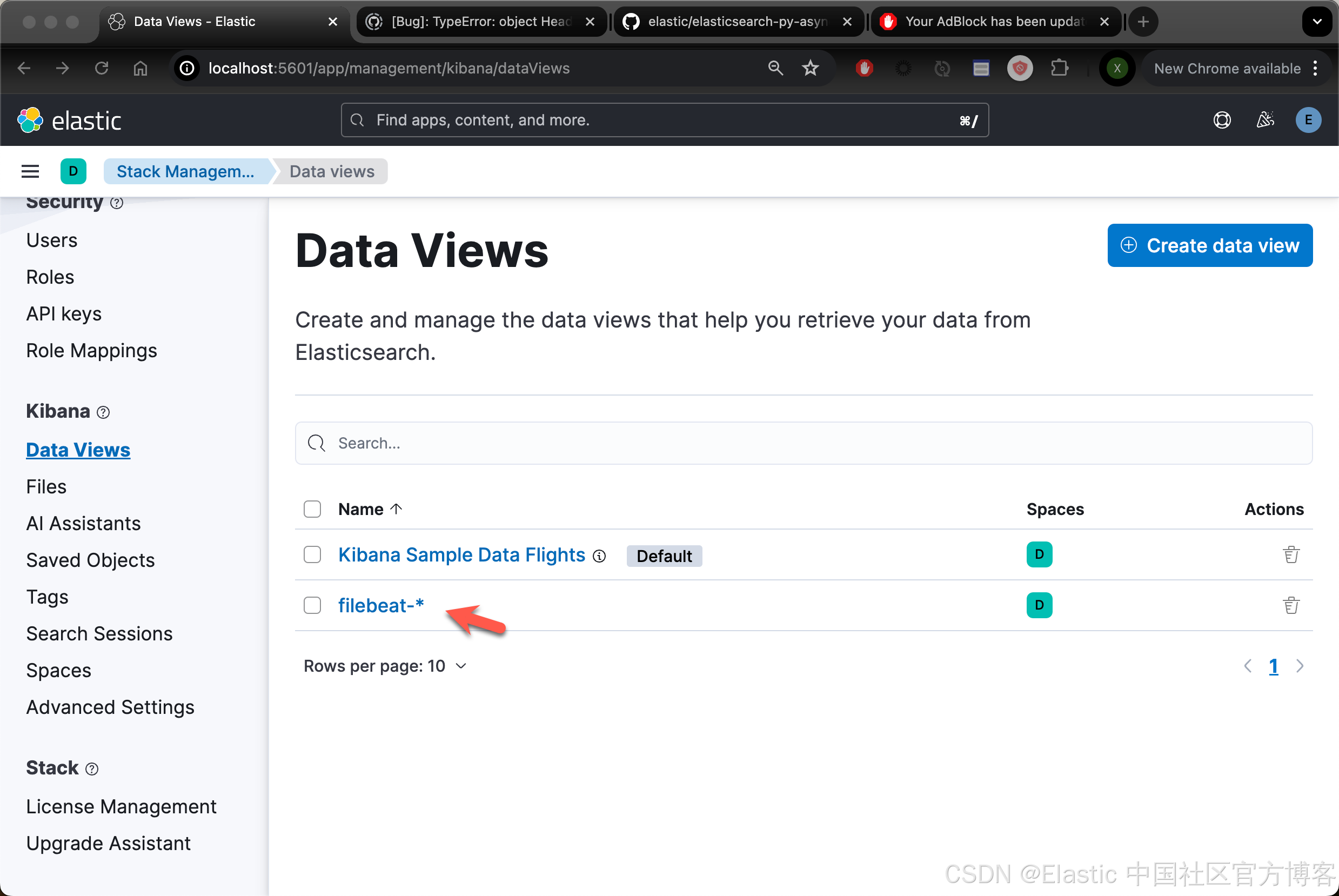
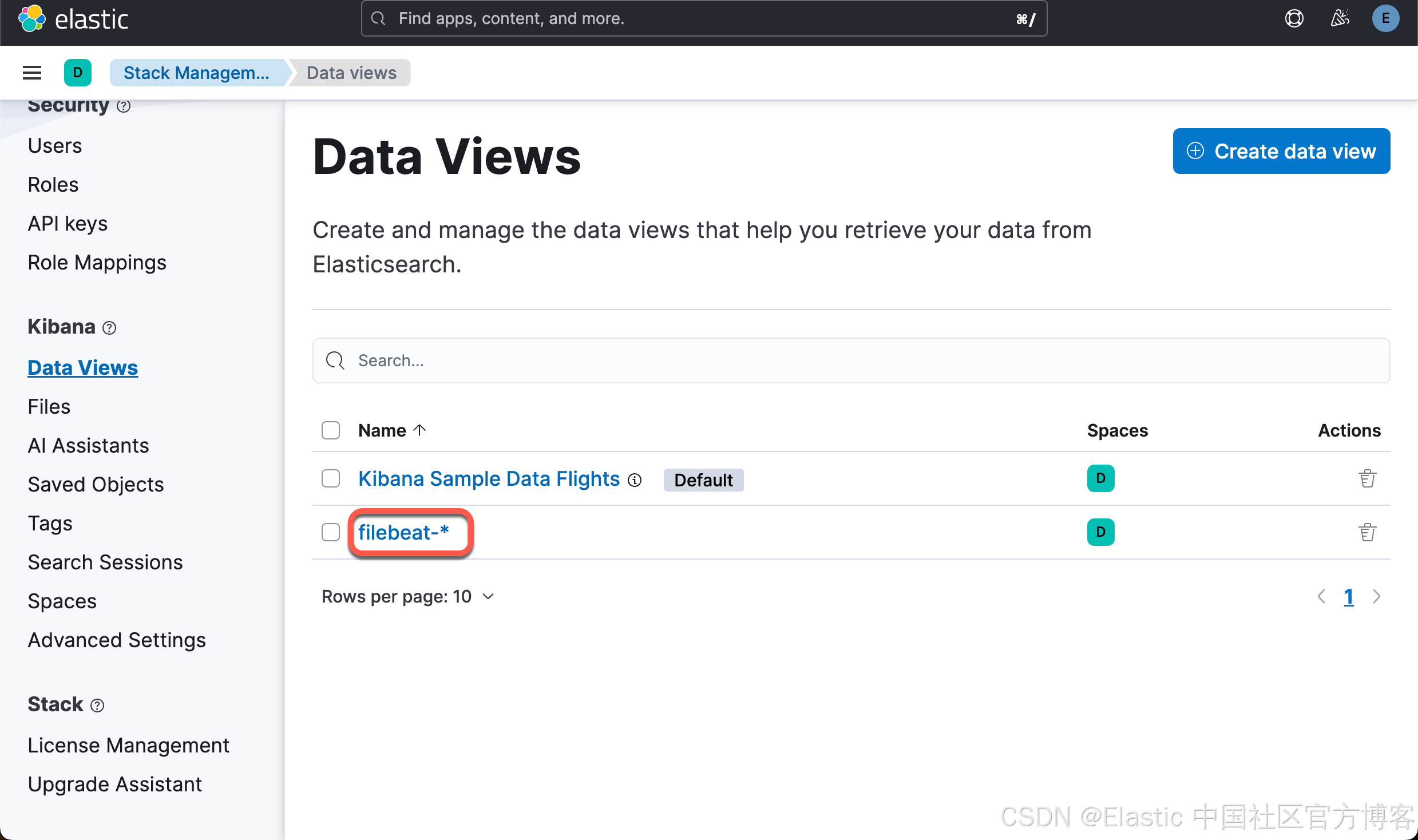
Loaded Ingest pipelinesFilebeat data view(以前称为 index pattern)现在可在 Elasticsearch 中使用。我们可以在 Kibana 中进行查看:
开始演示
启动 Python 应用
我们在 Python 应用的根目录下打入如下的命令:
python elvis.py$ pwd
/Users/liuxg/python/python-logs
$ python elvis.py
Generating log entries...在当前目录下,我们可以查看到新生成的 elvis.json 文件:
$ pwd
/Users/liuxg/python/python-logs
$ ls
elvis.json elvis.py启动 Filebeat
我们使用如下的命令来启动 Filebeat:
./filebeat -e -c filebeat.yml
在上面的命令中:
- -e 标志将输出发送到标准错误而不是配置的日志输出。
- -c 标志指定 Filebeat 配置文件的路径。
为了验证我们已经收到数据,我们可以做如下的检查:
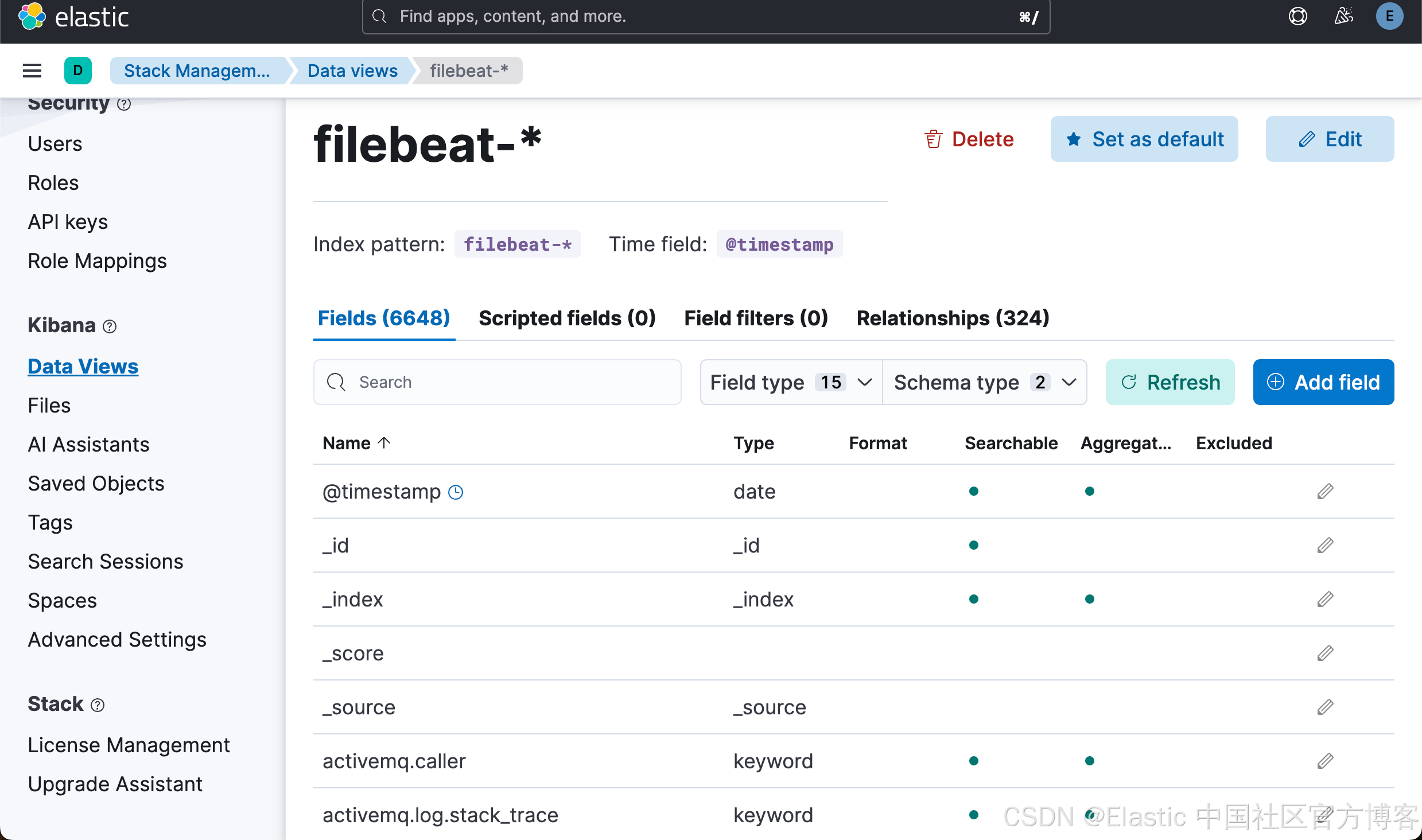
我们可以看到所有的字段。
我们可以在 Kibana DevTools 中查看收集到的数据:

我们可以看到日志数量的编辑已经日志的一些相关信息。
可视化数据
在这里,我们可以针对数据来做一下简单的可视化:






这样我们就生成了第一个可视化图。我们选择保存:

在上面,我们点击 “Create visualization” 按钮:






这样,我们就生成了我们的第二个可视化图。我们按照同样的方法来做第三个可视化图:





最终的可视化图如上所示。
在本篇文章中,我们从零开始从一个 Python 应用使用 Filebeat 来采集数据,并对它进行可视化。希望对大家有所帮助。
相关文章:
Beats:使用 Filebeat 从 Python 应用程序中提取日志
本指南演示了如何从 Python 应用程序中提取日志并将其安全地传送到 Elasticsearch Service 部署中。你将设置 Filebeat 来监控具有标准 Elastic Common Schema (ECS) 格式字段的 JSON 结构日志文件,然后你将在 Kibana 中查看日志事件发生的实时可视化。虽然此示例使…...
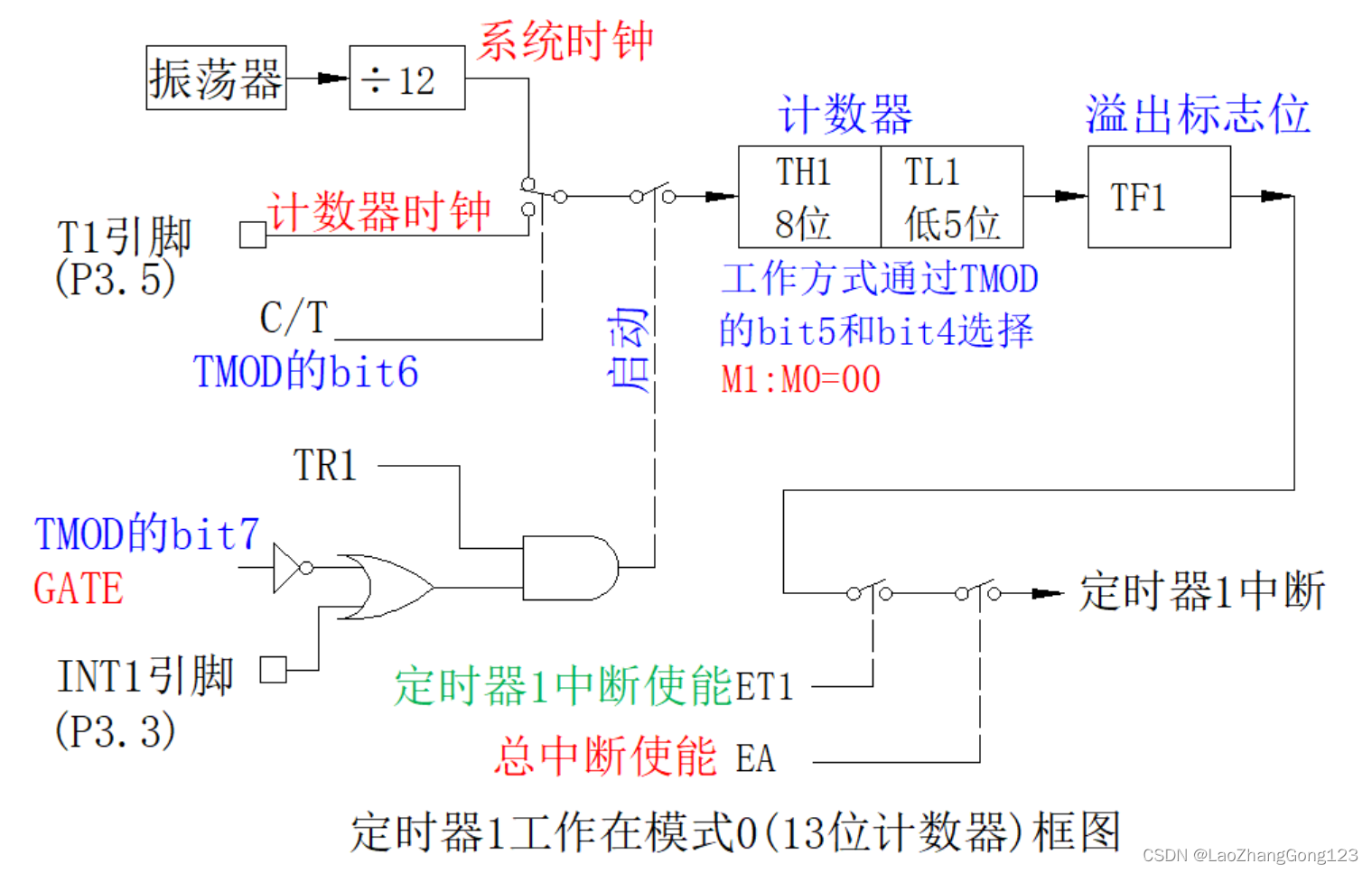
51单片机第23步_定时器1工作在模式0(13位定时器)
重点学习51单片机定时器1工作在模式0的应用。 在51单片机中,定时器1工作在模式0,它和定时器0一样,TL1占低5位,TH1占高8位,合计13位,也是向上计数。 1、定时器1工作在模式0 1)、定时器1工作在模式0的框图…...

linux的服务管理
systemd systemd 是一个系统和服务管理器,用于Linux操作系统中,旨在替代传统的Unix系统V初始化系统(SysV init)。 不一定所有使用 yum 安装的软件都可以通过 systemctl start 来管理。能否通过 systemctl start 管理取决于软件包…...

动手学深度学习(Pytorch版)代码实践 -循环神经网络-53语言模型和数据集
53语言模型和数据集 1.自然语言统计 引入库和读取数据: import random import torch from d2l import torch as d2l import liliPytorch as lp import numpy as np import matplotlib.pyplot as plttokens lp.tokenize(lp.read_time_machine())一元语法…...
)
Python 学习之自动化运维技术(八)
Python 的自动化运维技术 Python的自动化运维技术是指利用Python编程语言和相关工具实现运维工作的自动化,以提高效率、减轻工作负担。以下是对Python自动化运维技术的清晰归纳和详细介绍: 一、自动化运维的核心优势 ● 提高效率:通过自动化脚…...

【python】PyQt5可视化开发,如何设计鼠标显示的形状?
✨✨ 欢迎大家来到景天科技苑✨✨ 🎈🎈 养成好习惯,先赞后看哦~🎈🎈 🏆 作者简介:景天科技苑 🏆《头衔》:大厂架构师,华为云开发者社区专家博主,…...

利用大模型知识库,优化智能客服问答效果 | 创新场景
ITValue 痛点 SSC( Share Service Center ,共享服务中心)是企业日常接触最多的场景之一,更多是对内服务,包括 HR 、财务、IT 等。该场景对专业度要求非常高,知识点非常多,对于知识的使用者或者查…...

物联网协议都包含哪些协议?
物联网协议是物联网生态系统中不可或缺的组成部分,它们负责处理和协调物联网设备之间的通信。具体介绍如下: Ethernet:以太网是一种有线网络协议,广泛应用于局域网络(LAN)中,提供稳定的高速数据传输。Wi-Fi࿱…...
】)
面试专区|【52道微服务架构高频题整理(附答案背诵版)】
简述什么是微服务? 微服务是一种软件架构风格,它将应用程序拆分成一系列小型、独立的服务,每个服务都运行在其自己的进程中,通过轻量级通信机制进行通信。每个服务都具有明确的业务能力,并且可以独立开发、测试、部署…...

数据结构之算法的时间复杂度
1.时间复杂度的定义 在计算机科学中,算法的时间复杂度是一个函数,它定量描述了算法的运行时间。一个算法所花费的时间与其中语句的执行次数成正比列,算法中的基本操作的执行次数,为算法的时间复杂度 例1: 计算Func1…...

unity中物体被激活自动执行挂载代码
在Unity中,如果希望当物体被激活时自动执行特定的函数,可以利用 MonoBehaviour 的生命周期函数 OnEnable()。这个方法会在对象被激活时调用,可以用来执行初始化或者处理其他逻辑。以下是如何在脚本中使用 OnEnable() 方法: using UnityEngine;public class ActivateFuncti…...

Pandas数据可视化详解:大案例解析(第27天)
系列文章目录 Pandas数据可视化解决不显示中文和负号问题matplotlib数据可视化seaborn数据可视化pyecharts数据可视化优衣库数据分析案例 文章目录 系列文章目录前言1. Pandas数据可视化1.1 案例解析:代码实现 2. 解决不显示中文和负号问题3. matplotlib数据可视化…...

Redis基础教程(七):redis列表(List)
💝💝💝首先,欢迎各位来到我的博客,很高兴能够在这里和您见面!希望您在这里不仅可以有所收获,同时也能感受到一份轻松欢乐的氛围,祝你生活愉快! 💝Ὁ…...
鸿蒙开发:Universal Keystore Kit(密钥管理服务)【生成密钥(C/C++)】
生成密钥(C/C) 以生成ECC密钥为例,生成随机密钥。具体的场景介绍及支持的算法规格。 注意: 密钥别名中禁止包含个人数据等敏感信息。 开发前请熟悉鸿蒙开发指导文档:gitee.com/li-shizhen-skin/harmony-os/blob/master/README.md点击或者复…...

ssm“落雪”动漫网站-计算机毕业设计源码81664
目 录 摘要 1 绪论 1.1 研究背景 1.2 研究意义 1.3论文结构与章节安排 2系统分析 2.1 可行性分析 2.2 系统流程分析 2.2.1 数据新增流程 3.2.2 数据删除流程 2.3 系统功能分析 2.3.1 功能性分析 2.3.2 非功能性分析 2.4 系统用例分析 2.5本章小结 3 系统总体设…...

【面试题】Reactor模型
Reactor模型 定义 Reactor模型是一种事件驱动的设计模式,用于处理服务请求。它通过将事件处理逻辑与事件分发机制解耦,实现高性能、可扩展的并发处理。Reactor模型适用于高并发、事件驱动的程序设计,如网络服务器等。 特点 事件驱动&#…...

RedHat9 | kickstart无人值守批量安装
一、知识补充 kickstart Kickstart是一种用于Linux系统安装的自动化工具,它通过一个名为ks.cfg的配置文件来定义Linux安装过程中的各种参数和设置。 kickstart的工作原理 Kickstart的工作原理是通过记录典型的安装过程中所需人工干预填写的各种参数,…...

k8s-第五节-StatefulSet
StatefulSet StatefulSet 是用来管理有状态的应用,例如数据库。 前面我们部署的应用,都是不需要存储数据,不需要记住状态的,可以随意扩充副本,每个副本都是一样的,可替代的。 而像**数据库、Redis **这类…...

ai机器狗
ai机器狗的代码很早就开源了,相当于核心,最难东西美国人公开了,开源了,如果有钱,有足够资源的,造出东西有可能比公开这些核心代码的公司或者组织还好。没有技术含量,技术含量别人都解决了&#…...

数据库关键字执行顺序
在 SQL 中,关键字的执行顺序通常如下: FROM:确定要查询的表或数据源,并执行表之间的连接操作(如 INNER JOIN、LEFT JOIN 等)。FROM 子句执行顺序为从后往前、从右到左。ON:应用连接条件…...

网络配置工具类详解
CNet 网络配置工具类详解平台:仅支持 Linux,大量使用 ioctl 系统调用一、概述 CNet 是一个 纯静态方法的网络配置工具类,封装了 Linux 下常用的网络操作:功能类别涵盖内容IP 地址读取/设置本机 IP、子网掩码网关读取/添加/删除/设…...

别急着扔!12年老ThinkPad X230升级SSD和内存后,Win10流畅得像新电脑
12年老ThinkPad X230重生指南:极简升级打造流畅办公利器每次打开抽屉看到那台积灰的ThinkPad X230,总有种说不出的情感。这款2012年问世的经典商务本,曾陪伴无数人度过加班到凌晨的夜晚。如今性能确实有些力不从心,但直接丢弃又觉…...
用Azure Kinect DK和Body Tracking SDK,5分钟实现一个实时人体骨骼点检测Demo(C++版)
5分钟实战:用Azure Kinect DK实现实时人体骨骼点追踪(C版) 当你第一次拿到Azure Kinect DK时,最令人兴奋的莫过于它强大的人体追踪能力。这款深度相机不仅能捕捉高清彩色图像,更能通过AI算法实时重建人体骨骼关节点。本…...

榨干Codex!OpenAI工程师亲授Codex真正用法
你可能把 Codex 当编程助手用,改改代码,跑跑测试。但它的能力远不止于此。OpenAI 的客户支持工程师 Jason(jxnlco)告诉你,Codex 其实是一套完整的电脑工作系统,从语音输入到自动化,从浏览器操控…...

如何快速定制Office界面:终极开源工具使用指南
如何快速定制Office界面:终极开源工具使用指南 【免费下载链接】office-ribbonx-editor An overhauled fork of the original Custom UI Editor for Microsoft Office, built with WPF 项目地址: https://gitcode.com/gh_mirrors/of/office-ribbonx-editor O…...

5步彻底解决Windows DLL加载冲突:UE4SS系统故障排查指南
5步彻底解决Windows DLL加载冲突:UE4SS系统故障排查指南 【免费下载链接】RE-UE4SS Injectable LUA scripting system, SDK generator, live property editor and other dumping utilities for UE4/5 games 项目地址: https://gitcode.com/gh_mirrors/re/RE-UE4SS…...

8款网盘直链下载助手:彻底告别限速烦恼,实现高速下载自由
8款网盘直链下载助手:彻底告别限速烦恼,实现高速下载自由 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移…...
函数的计算原理(附绘图代码))
从复平面几何到Python代码:可视化理解NumPy中angle()函数的计算原理(附绘图代码)
从复平面几何到Python代码:可视化理解NumPy中angle()函数的计算原理(附绘图代码) 在数学和工程领域,复数不仅是抽象的概念,更是解决实际问题的有力工具。当我们谈论复数68j时,它不仅仅是一个符号组合——在…...
如何在macOS上免费安装HSTracker:终极炉石传说套牌追踪器完整指南
如何在macOS上免费安装HSTracker:终极炉石传说套牌追踪器完整指南 【免费下载链接】HSTracker A deck tracker and deck manager for Hearthstone on macOS 项目地址: https://gitcode.com/gh_mirrors/hs/HSTracker 还在为炉石传说对局中记不住对手出牌而烦恼…...

机器学习预测关税冲击下的股市波动:随机森林、SVR、kNN与线性回归实战对比
1. 项目概述与核心问题拆解做量化研究的朋友们,尤其是关注宏观事件对市场冲击的,应该都对“黑天鹅”事件不陌生。政策变动,特别是像关税这种直接影响国际贸易成本和公司利润的宏观变量,往往会在短期内引发市场剧烈波动。传统的做法…...