14-8 小型语言模型的兴起
过去几年,我们看到人工智能能力呈爆炸式增长,其中很大一部分是由大型语言模型 (LLM) 的进步推动的。GPT-3 等模型包含 1750 亿个参数,已经展示了生成类似人类的文本、回答问题、总结文档等能力。然而,虽然 LLM 的能力令人印象深刻,但它们庞大的规模导致效率、成本和可定制性方面的缺点。这为一种名为小型语言模型 (SLM) 的新兴模型类别打开了大门。
让我们深入了解小型语言模型的兴起:
- 什么是小语言模型?
- 开发小型语言模型的动机——效率、成本、可定制性
- 有用的语言模型可以有多小?
- 训练高效小语言模型的方法
- 小型语言模型大放异彩的示例应用
- 支持创建自定义 SLM 的开发人员框架
- 空间激光雷达发展与部署的未来机遇与挑战
最后,您将了解小型语言模型在以可定制和经济的方式将语言 AI 的强大功能带到更专业领域的前景。
什么是小语言模型?
语言模型是针对大型文本数据集进行训练的 AI 系统,可实现生成文本、总结文档、语言间翻译和回答问题等功能。小型语言模型可以满足大部分相同的需求,但模型大小明显较小。但小型语言模型由什么构成?
研究人员通常认为,参数少于 1 亿的语言模型相对较小,有些甚至会将参数限制在 1000 万或 100 万的较低阈值。相比之下,如今规模庞大的模型参数超过 1000 亿,例如上述 OpenAI 的 GPT-3 模型。
较小的模型尺寸使小型语言模型比最大的模型更高效、更经济、更可定制。然而,它们的整体能力较低,因为语言模型中的模型容量已被证明与尺寸相关。确定实际应用的最佳模型尺寸需要在灵活性和可定制性与纯粹的模型性能之间进行权衡。
小型语言模型的动机
如上所述,与大型语言模型相比,小型语言模型在效率、成本和可定制性方面具有先天优势。让我们更详细地分析一下这些动机:
效率
由于参数较少,小型语言模型在以下几个方面的计算效率明显高于 GPT-3 等大型模型:
- 由于每个输入需要执行的参数更少,因此它们的推理速度/吞吐量更快
- 由于整体模型尺寸较小,它们需要的内存和存储空间也较少
- 较小的数据集足以训练小型语言模型。随着模型容量的增长,对数据的需求也随之增长。
这些效率优势可直接转化为成本节省:
成本
大型语言模型需要大量的计算资源来训练和部署。据估计,OpenAI 开发 GPT-3 的成本约为数千万美元,包括硬件和工程成本。由于资源需求,当今许多公开的大型语言模型尚未盈利。
同时,小型语言模型可以很容易地在许多企业可用的商用硬件上进行训练、部署和运行,而无需花费太多资金。它们合理的资源需求开启了边缘计算的应用,它们可以在低功耗设备上离线运行。总的来说,短期内找到小型语言模型盈利应用的潜力更大。
可定制性
小型语言模型相对于大型语言模型的一个关键优势是可定制性。虽然 GPT-3 等模型在许多任务中表现出了强大的多功能性,但它们的功能仍然代表了一种在各个领域之间平衡性能的折衷解决方案。
另一方面,小型语言模型可以很容易地适应更狭窄的领域和专门的应用。凭借更快的迭代周期,小型语言模型使得通过以下方法尝试针对特定类型的数据定制模型成为可能:
- 预训练——在特定领域的数据集上启动小模型
- 微调——持续训练以优化最终任务数据
- 基于提示的学习——针对专门应用优化模型提示
- 架构修改——调整模型结构以适应特定任务
对于大型模型来说,这些定制过程变得越来越困难。小型语言模型不仅易于访问,还提供了开发人员可以根据其特定需求进行调整的规范。
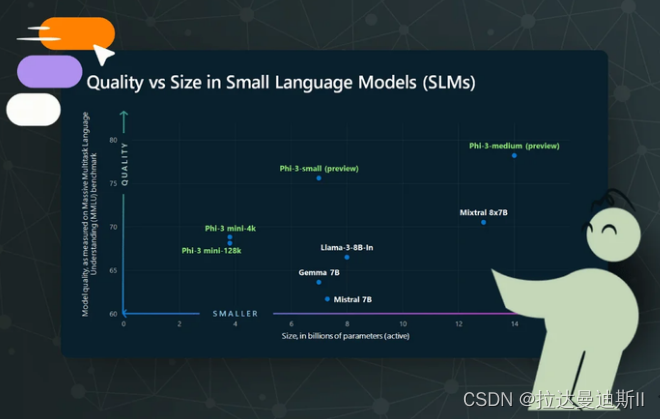
有用的语言模型可以有多小?
考虑到上述最小化模型尺寸的动机,一个自然而然的问题出现了——我们可以将语言模型缩小到什么程度,同时仍然保持强大的功能?最近的研究继续探索完成不同语言任务所需的模型规模的下限。
许多研究发现,现代训练方法只需 100 万到 1000 万个参数就能让模型具备基本的语言能力。例如,2023 年发布的一个 800 万个参数的模型在既定的 GLUE 自然语言理解基准上达到了 59% 的准确率。
随着模型容量的增加,性能不断提高。 2023 年的一项研究发现,在从推理到翻译的各个领域,一旦语言模型达到约 6000 万个参数,不同任务的有用能力阈值就会一致通过。 然而,在 2 亿到 3 亿个参数规模之后,回报就会减少——增加额外的容量只会带来渐进的性能提升。
这些发现表明,即使是中型语言模型,只要接触到足够多的正确训练数据,也能在许多语言处理应用中达到合理的能力。然后,性能会达到一个平台期,在这个平台上,大量的计算和数据似乎没有提供什么额外的价值。商业上可部署的小型语言模型的最佳点可能就在这个平台期附近,在广泛的能力和精益的效率之间取得平衡。
当然,经过深度而非广泛调整的专门小语言模型可能需要更少的容量才能在小众任务中脱颖而出。我们稍后会介绍一些应用用例。但首先,让我们概述一下有效训练紧凑但功能强大的小语言模型的流行技术。
高效小型语言模型的训练方法
积极训练日益熟练的小型语言模型依赖于在学习过程中增强数据效率和模型利用率的方法。与大型模型的简单训练相比,这些技术最终为每个参数赋予了更多的能力。我们将在这里分解一些流行的方法:
迁移学习
大多数现代语言模型训练都利用了某种形式的迁移学习,其中模型通过首先在广泛的数据集上进行训练来引导能力,然后再专门针对狭窄的目标领域。初始预训练阶段将模型暴露给广泛的语言示例,这对于学习一般的语言规则和模式很有用。
尽管参数预算有限,但小型语言模型可以在预训练期间捕捉到这种广泛的能力。然后,专业化阶段可以针对特定应用进行细化,而无需扩大模型规模。总体而言,迁移学习大大提高了训练小型语言模型的数据效率。
自监督学习
迁移学习训练通常利用自监督目标,其中模型通过预测输入文本序列中被屏蔽或损坏的部分来发展基础语言技能。这些自监督预测任务可作为下游应用程序的预训练。
最近的分析发现,自监督学习似乎特别有效地赋予小型语言模型强大的能力——比大型模型更有效。通过将语言建模呈现为交互式预测挑战,自监督学习迫使小型模型从显示的每个数据示例中进行深度概括,而不是简单地被动地记住统计数据。这在训练期间可以更充分地利用模型容量。
架构选择
并非所有神经网络架构都具有同等的参数效率,可用于语言任务。精心选择架构可将模型容量集中在对语言建模至关重要的领域,例如注意力机制,同时剥离不太重要的组件。
例如,Efficient Transformers 已成为一种流行的小型语言模型架构,它在训练过程中采用了知识蒸馏等各种技术来提高效率。相对于基线 Transformer 模型,Efficient Transformers 实现了类似的语言任务性能,而参数减少了 80% 以上。有效的架构决策可以放大公司从有限规模的小型语言模型中提取的能力。
上述技术推动了快速发展,但如何最有效地训练小型语言模型仍有许多悬而未决的问题。随着小型语言模型扩展到新领域,确定模型规模、网络设计和学习方法的最佳组合以满足项目需求将继续让研究人员和工程师忙个不停。接下来,我们将重点介绍一些开始采用小型语言模型和定制 AI 的应用用例。
小型语言模型大放异彩的示例应用
尽管人们对人工智能的热情通常集中在吸引眼球的大型模型上,但许多公司已经通过部署根据其特定需求定制的小型语言模型找到了实用性。我将重点介绍一些代表性示例,例如金融和娱乐领域,在这些领域中,紧凑、专业的模型正在创造商业价值:
更多资讯,请访问 2img.ai
金融机构生成大量数字数据和文档,可以使用小型定制语言模型来提取见解。具有高投资回报率的用例包括:
- 交易分类器自动使用会计类别对发票项目进行编码,以加快输入簿记系统的速度。
- 情绪模型从收益电话会议记录中提取意见,通过检测管理层基调的变化来产生交易信号。
- 自定义实体有助于将非结构化银行对账单系统化为标准化数据报告业务收入,以进行贷款风险分析。
这些应用程序将语言人工智能转化为直接流程自动化,并改进现有财务工作流程中的分析能力——加速盈利模式,而不是仅仅猜测技术前景。风险管理在金融服务中仍然至关重要,更倾向于狭义的语言模型,而不是通用智能。
娱乐
随着创造性过程与先进技术的融合,媒体、游戏和相关娱乐垂直行业成为语言 AI 解决方案最具前瞻性的采用者:
- 小型语言模型利用自然语言生成,自动创建动画的初稿脚本或散文,创作者随后对其进行完善,从而大幅提高个人生产力。
- 在开放世界游戏中,对话模型会根据用户环境生成动态对话树,从而扩大虚拟现实范围内的交互自由。
- 更强大的语言分析功能丰富了娱乐元数据,例如通过字幕内容的模式识别电影主题,以便推荐引擎更好地将观众与他们的独特兴趣联系起来。
娱乐的创意空间为探索小型语言模型生成前沿提供了理想的试验台。尽管鉴于模型的局限性,当前的应用仍需监督,但小型语言模型的效率为开发人员提供了充足的空间来探索创意潜力。
ParagogerAI训练营 2img.ai
用于构建自定义 SLM 的开发人员框架
那么,既然前景如此光明,开发人员如何才能真正开始构建专门定制的小型语言模型呢?开源技术让企业跨领域、跨规模地实现定制语言 AI。以下全方位服务平台能够以经济高效的方式创建和部署定制的小型语言模型:
🤗 Hugging Face Hub — Hugging Face 提供统一的机器学习操作平台,用于托管数据集、编排模型训练管道以及通过 API 或应用程序高效部署预测。他们的 Clara Train 产品专注于最先进的自监督学习,用于创建紧凑但功能强大的小型语言模型。
Anthropic Claude — 由专注于模型安全的 ConstitutionalAI 的开发者开发,Claude 只需几行代码即可轻松训练自定义分类器、文本生成器、摘要器等。内置安全约束和监控可抑制部署期间的潜在风险。
✨ Cohere for AI — Cohere 提供了一个开发人员友好的平台,用于从自己的训练数据或导入的自定义集中提取多达 100 万个参数来构建语言模型。客户端托管选项提供端到端隐私合规性。
Assembler — Assembler 提供用于开发专门针对特定数据输入的读取器、编写器和分类器小型语言模型的工具。其简单的 Web 界面掩盖了模型创建和监控的基础设施复杂性。
上述服务体现了现在已准备好探索语言 AI 可能性的公司可以实现的交钥匙体验。机器学习专业知识本身很有帮助,但对于合适的合作伙伴来说,这不再是硬性先决条件。这使得更多行业能够从 AI 专业化中创造价值。
特定领域 SLM 的出现
到目前为止,我们已经介绍了小型语言模型的一般功能,以及它们与大规模通用 LLM 相比在效率、定制和监督方面的优势。然而,通过在小众数据集上进行训练,SLM 还擅长处理专门的用例。
随着大型语言模型规模的扩大,它们变得样样精通,但样样不精。它们的知识和表现在不同领域逐渐减弱。此外,将敏感数据暴露给外部 LLM 会带来数据泄露或滥用方面的安全、合规和专有风险。
这些限制促使各行各业的组织使用内部数据资产开发自己的小型、特定领域的语言模型。定制可以更好地满足他们特定的准确性和安全性需求。接下来我们重点介绍一些主要示例。
金融小语言模型
金融公司还部署 SLM 以满足分析收益表、资产估值、风险建模等需求。领域熟练程度是强制性的,但敏感数据不能泄露到外部。
例如,软银旗下的 Fortia 使用客户数据构建了定制的 SLM,以预测货币汇率和套利交易机会。紧密的专注度使其优于通用的 LLM,低延迟可实现自动化。数据安全也至关重要。
专业领域 SLM 的优势
是什么推动了各个组织和行业开发专有领域特定 SLM?有几个关键优势脱颖而出:
卓越的准确性:针对具有一般语料库无法捕捉到的特性的细分数据集进行专门的模型训练,与外部 LLM 相比,其准确性大幅提升。使用权重印记、适配器模块和自我训练等领域自适应技术增强模型可进一步提高准确性。
保密性:依赖通用外部模型会迫使敏感 IP、财务、医疗保健或其他机密数据暴露在外部。但内部训练的 SLM 的严格架构边界可降低数据泄露或滥用的风险。这也提供了合规性优势。
响应能力:组织拥有完整的模型开发生命周期,可进行微调,以精确匹配客户支持流程等专业用例。直接控制可以在数小时或数天内修改和重新部署模型,而无需与外部 LLM 提供商进行长达一个月的协调。敏捷性可加快迭代速度。
成本效益:大型语言模型不仅需要高昂的训练成本,还需要按查询收费。建立自己的模型可以长期摊销费用。尽管一些过大的数据集仍然受益于预先训练的 LLM 基础,但将学习转移到专门的头脑中。
专用 SLM 面临的挑战
专门的 SLM 确实面临着采用障碍,以平衡优势:
数据充足性:许多组织缺乏大量结构化数据集来从头开始训练稳健的模型。在基础模型之上使用少样本学习适配器等替代方法会有所帮助,但一些数据密集型应用程序仍受益于外部通用模型。不过,增强等数据利用技术会有所帮助。
模型治理:开发性能可靠的 SLM 需要对开发人员工作流程、仪表、模型操作和监督进行投资,而这远远超出了当今许多团队的能力。负责任的专业 AI 仍然需要治理扩展专业知识,即使对于小型模型也是如此。进步依赖于 DevOps 的成熟。
维护成本:即使是紧凑型模型也需要维护,因为数据会发生变化。但 SLM 的监控负担和重建要求比 LLM 要轻得多。尽管如此,由于模型被视为消耗品,随着时间的推移,模型腐烂会削弱可靠性。致力于生命周期管理是关键。
小型语言模型的未来机遇与挑战
小型语言模型带来的效率、多功能性和易用性,标志着新一轮工业人工智能应用浪潮的开始,该浪潮针对垂直需求而非一刀切的解决方案量身定制。随着开发人员掌握这些新的可定制代码库所带来的影响,创新空间仍然巨大。
然而,考虑到语言模型固有的社会技术复杂性,即使在小规模的情况下,负责任的实施方面的实践和勤勉也至关重要。最后,让我们简要强调一下未来的有希望的机遇和关键挑战:
机遇:
- 定制化可以弥补通用人工智能服务不足的行业的专业空白,而语言辅助可以提高成果。
- 混合智能与人类领域专家的结合很可能在短期内被证明是最具建设性的,设计人工智能是为了增强而不是取代工作。
- 高效训练技术和多任务模型架构的持续进步将进一步扩展小型语言模型的功能。
- 随着更有针对性的商业回报在各个垂直领域更快地显现出来,定制语言人工智能的采用势头可能会超过普遍采用。
挑战:
- 在敏感用例中过度依赖人工智能可能会忽视人类的专业知识和做出社会明智决策所需的监督。
- 当应用模型做出超出其专门训练分布的不受支持的推理时,数据质量和概念漂移问题会迅速加剧。
- 由于大量小模型掩盖了特定输出产生的原因,尤其是根据行业数据进行个性化时,透明度将变得更加难以捉摸。
- 恶意利用仍然是任何蓬勃发展的技术所面临的一个问题,需要采取措施防止语言模型直接或间接造成伤害。
只要重视负责任的开发原则,小型语言模型就有可能在未来几年内让大量行业变得更好。随着专业化人工智能的出现,我们才刚刚开始看到这些可能性。
结论
- 小型语言模型的构成以及它们在功能上与当今规模最大的模型相比如何
- 效率、成本节约和可定制性等动机推动人们采用小型语言模型而不是通用语言 AI
- 模型小型化的前沿——通过现代训练技术,语言模型可以缩小到多小,同时保留强大的功能?
- 现实世界中,公司将专门的小型语言模型应用于教育、医药、金融和娱乐等垂直领域的案例
- 开发人员资源使企业能够从对 AI 的兴趣转向使用定制语言模型进行实施
小型语言模型的体验式技术将语言 AI 的广泛热议提炼为可供商业团队和用户使用的实用构建模块。ParagogerAI训练营 2img.ai
该行业仍处于起步阶段,随着专业模型的传播,解锁新应用需要开发人员的创造力和对影响的深思熟虑。但现在出现的可定制语言智能似乎有望推动 AI 生产力的下一阶段。
相关文章:
14-8 小型语言模型的兴起
过去几年,我们看到人工智能能力呈爆炸式增长,其中很大一部分是由大型语言模型 (LLM) 的进步推动的。GPT-3 等模型包含 1750 亿个参数,已经展示了生成类似人类的文本、回答问题、总结文档等能力。然而,虽然 LLM 的能力令人印象深刻…...

【Linux】:进程创建与终止
朋友们、伙计们,我们又见面了,本期来给大家解读一下有关Linux程序地址空间的相关知识点,如果看完之后对你有一定的启发,那么请留下你的三连,祝大家心想事成! C 语 言 专 栏:C语言:从…...

横截面交易策略:概念与示例
数量技术宅团队在CSDN学院推出了量化投资系列课程 欢迎有兴趣系统学习量化投资的同学,点击下方链接报名: 量化投资速成营(入门课程) Python股票量化投资 Python期货量化投资 Python数字货币量化投资 C语言CTP期货交易系统开…...

4.2 投影
一、投影和投影矩阵 我们以下面两个问题开始,问题一是为了展示投影是很容易视觉化的,问题二是关于 “投影矩阵”(projection matrices)—— 对称矩阵且 P 2 P P^2P P2P。 b \boldsymbol b b 的投影是 P b P\boldsymbol b Pb。…...

23种设计模式之装饰者模式
深入理解装饰者模式 一、装饰者模式简介1.1 定义1.2 模式类型1.3 主要作用1.4 优点1.5 缺点 二、模式动机三、模式结构四、 装饰者模式的实现4.1 组件接口4.2 具体组件4.3 装饰者抽象类4.4 具体装饰者4.5 使用装饰者模式4.6 输出结果: 五、 应用场景5.1 图形用户界面…...

数据结构--单链表实现
欢迎光顾我的homepage 前言 链表和顺序表都是线性表的一种,但是顺序表在物理结构和逻辑结构上都是连续的,但链表在逻辑结构上是连续的,而在物理结构上不一定连续;来看以下图片来认识链表与顺序表的差别 这里以动态顺序表…...

2024攻防演练:亚信安全推出MSS/SaaS短期定制服务
随着2024年攻防演练周期延长的消息不断传出,各参与方将面临前所未有的挑战。面对强大的攻击队伍和日益严格的监管压力,防守单位必须提前进行全面而周密的准备和部署。为应对这一形势,亚信安全特别推出了为期三个月的MSS/SaaS短期订阅方案。该…...

基于java+springboot+vue实现的在线课程管理系统(文末源码+Lw)236
摘要 本文首先介绍了在线课程管理系统的现状及开发背景,然后论述了系统的设计目标、系统需求、总体设计方案以及系统的详细设计和实现,最后对在线课程管理系统进行了系统检测并提出了还需要改进的问题。本系统能够实现教师管理,科目管理&…...

每日一更 EFK日志分析系统
需要docker和docker-compose环境 下面时docker-compose.yaml文件 [rootnode1 docker-EFK]# cat docker-compose.yaml version: 3.3services:elasticsearch:image: "docker.elastic.co/elasticsearch/elasticsearch:7.17.5"container_name: elasticsearchrestart: …...

python类继承和类变量
Python一些类继承和实例变量的使用 定义基类 class APIException:code 500msg "Sorry, error"error_code 999def __init__(self, msgNone):print("APIException init ...")def error_400(self):pass复用基类的属性值 class ClientTypeError(APIExcept…...

js 随机生成整数
随机生成一个唯一的整数 id export const randomId () > { return Date.now() Math.floor(Math.random() * 10000) } 生成随机ID的方法 // 随机生成0 - 9999 export const randomId ()> { return Math.floor(Math.random() * 10000).toString() } // 随机生成0-999之…...
)
深入Django(七)
Django的数据库迁移系统 引言 在前六天的教程中,我们介绍了Django的基本概念、模型、视图、模板、URL路由和表单系统。今天,我们将讨论Django的数据库迁移系统,它是管理和跟踪数据库变化的关键组件。 Django数据库迁移概述 Django的数据库…...

【区分vue2和vue3下的element UI Steps 步骤条组件,分别详细介绍属性,事件,方法如何使用,并举例】
在 Vue 2 和 Vue 3 中,Element UI(针对 Vue 2)和 Element Plus(针对 Vue 3)提供了 Steps 步骤条组件,用于展示当前操作的进度步骤。虽然这两个库都提供了步骤条组件,但它们在属性、事件和方法的…...

uni-app x 跨平台开发框架
目录 uni-app x 是什么 和Flutter对比 uts语言 uvue渲染引擎 组合式API的写法 选项式API写法 页面生命周期 API pages.json全局配置文件 总结 uni-app x 是什么 uni-app x,是下一代 uni-app,是一个跨平台应用开发引擎。 uni-app x 是一个庞…...
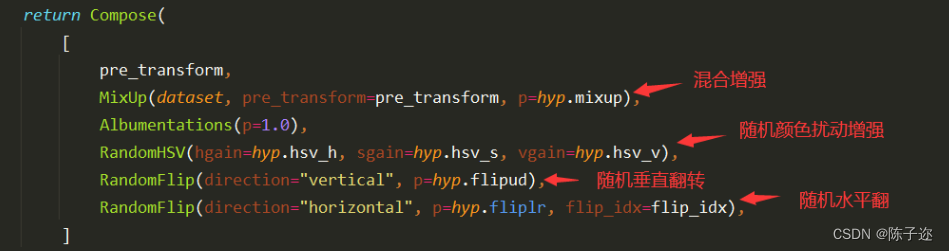
YOLOv8模型调参---数据增强
目录 1.数据预处理 2.数据增强 2.1 数据增强的作用 2.2 数据增强方式与适用场景 2.2.1离线增强(Offline Augmentation) 2.2.2 在线增强(Online Augmentation) 3. 数据增强的具体方法 4. YOLOv8的数据增强 4.1 YOLOv8默认…...

【Nginx】docker运行Nginx及配置
Nginx镜像的获取 直接从Docker Hub拉取Nginx镜像通过Dockerfile构建Nginx镜像后拉取 二者区别 主要区别在于定制化程度和构建过程的控制: 直接拉取Nginx镜像: 简便性:直接使用docker pull nginx命令可以快速拉取官方的Nginx镜像。这个过程…...

tensorflow和numpy的版本
查看cuda版本 dpkg -l | grep cuda i libcudart11.0:amd64 11.5.117~11.5.1-1ubuntu1 amd64 NVIDIA CUDA Runtime Library ii nvidia-cuda-dev:amd64 11.5.1-1ubuntu1 …...

二维Gamma分布的激光点云去噪
目录 1、Gamma 分布简介2、实现步骤 1、Gamma 分布简介 Gamma 分布在合成孔径雷达( Synthetic Aperture Radar,SAR) 图像分割中具有广泛应用,较好的解决了SAR 图像中相干斑噪声对图像分割的影响。采用二维Gamma 分布对…...

鸿蒙笔记导航栏,路由,还有axios
1.导航组件 导航栏位置可以调整,导航栏位置 Entry Component struct t1 {build() {Tabs(){TabContent() {Text(qwer)}.tabBar("首页")TabContent() {Text(发现内容)}.tabBar(发现)TabContent() {Text(我的内容)}.tabBar("我的")}// 做平板适配…...

Spring 框架中都用到了哪些设计模式:单例模式、策略模式、代理模式
Spring 框架是一个功能强大的企业级应用开发框架,它使用了多种设计模式来提高代码的可维护性、可扩展性和可重用性。以下是 Spring 框架中常见的几个设计模式,并简要说明它们的应用场景: 1. 单例模式(Singleton Pattern) 定义:确保一个类只有一个实例,并提供全局访问点…...

别再死记硬背了!用Multisim仿真+图解,5分钟搞懂三极管共射放大电路工作原理
用Multisim仿真图解5分钟掌握三极管共射放大电路三极管共射放大电路是电子技术中最基础也最关键的电路之一,但传统教材中复杂的公式推导和静态图解往往让初学者望而生畏。本文将带你用Multisim仿真软件,通过可视化的方式直观理解电路工作原理,…...

基于2D工程图几何特征与梯度提升模型的制造成本智能预测
1. 项目概述:从图纸到报价的智能革命在制造业,尤其是像汽车零部件这样的离散制造领域,报价速度直接决定了订单的生死。传统上,拿到一张新的2D工程图(DWG格式),成本工程师需要花上几天甚至几周时…...
)
Windows 10/11系统下,SecureCRT 8.7.2保姆级安装与激活图文指南(含Keygen使用避坑点)
Windows平台SecureCRT 8.7.2全流程部署与安全配置指南在当今远程运维与网络管理的日常工作中,一款可靠的终端仿真工具如同工程师的瑞士军刀。作为行业标杆的SecureCRT,其8.7.2版本在Windows 10/11环境下的部署却常让新手陷入各种技术陷阱——从安装路径选…...

开启Python GUI开发新纪元:Tkinter Designer可视化界面自动化生成终极指南
开启Python GUI开发新纪元:Tkinter Designer可视化界面自动化生成终极指南 【免费下载链接】Tkinter-Designer An easy and fast way to create a Python GUI 🐍 项目地址: https://gitcode.com/gh_mirrors/tk/Tkinter-Designer 在Python GUI开发…...

Sangfor文件夹可以删除吗?【图文讲解】深信服文件夹残留清理?如何彻底删除深信服?Sangfor文件夹是什么?
(1)问题背景打开C盘,突然冒出个Sangfor 文件夹,占用好几个 GB 空间,想删又不敢删,怕删坏系统、断网崩溃;上网一查,说法五花八门,有人说是病毒,有人说是办公软…...

武汉国电华美串联谐振试验装置,现场用着心里有底
在高压试验现场干了这么多年,这位老师傅常说,一台好的串联谐振装置,就是试验人员的胆。面对GIS、大型变压器、超高压电缆这些大电容试品,没有趁手的谐振设备,交流耐压试验根本没法干。16875kVA/225kV这个规格ÿ…...
)
大模型测试新范式:Claude端到端验证的5层断言体系(语义一致性/上下文连贯性/安全边界/成本阈值/时序鲁棒性)
更多请点击: https://codechina.net 第一章:大模型测试新范式:Claude端到端验证的5层断言体系(语义一致性/上下文连贯性/安全边界/成本阈值/时序鲁棒性) 传统LLM测试常聚焦于准确率或BLEU等静态指标,而Cla…...

Hitboxer:终极SOCD按键重映射解决方案,彻底解决游戏按键冲突问题
Hitboxer:终极SOCD按键重映射解决方案,彻底解决游戏按键冲突问题 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 在激烈的游戏对战中,你是否曾因同时按下左右方向键而导致角色…...

HKMG工艺的“阿喀琉斯之踵”:聊聊那个无法移除的SiON界面层与未来0.3nm的挑战
HKMG工艺的隐形枷锁:SiON界面层的物理宿命与亚纳米级突围战 在半导体工艺演进的史诗中,HKMG(高K金属栅)技术曾被寄予厚望——它用金属栅极替代传统多晶硅,搭配高K介质材料HfO₂,一举解决了栅极耗尽和漏电流…...

【Midjourney霓虹效果终极指南】:20年AI视觉工程师亲授5大参数组合+3类光源建模公式,97%新手一周内复刻赛博朋克海报
更多请点击: https://kaifayun.com 第一章:霓虹美学的视觉原理与Midjourney适配性解析 霓虹美学源于20世纪都市夜景中的荧光灯管、电子广告与赛博朋克文化,其核心视觉特征包括高饱和度冷暖对比、边缘辉光(glow)、深色…...