hive面试题
1、什么是Hive
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能(HQL)
2、Hive的意义(最初研发的原因)
避免了去写MapReduce,提供快速开发的能力,减少开发人员的学习成本。
3、Hive的内部组成模块,作用分别是什么
1.元数据:Metastore
元数据包括:表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等;
默认存储在自带的derby数据库中,推荐使用MySQL存储Metastore 元数据存储
(1)解析器(SQL Parser):解析HQL语义
(2)编译器(Physical Plan):将HQL根据语义转换成MR程序
(3)优化器(Query Optimizer):对逻辑执行计划进行优化。(对MR程序进行优化)
(4)执行器(Execution):把任务提交到hadoop集群
4、Hive支持的数据格式
可支持Text,SequenceFile,ParquetFile,ORC格式RCFILE等
5、进入Hiveshell窗口的方式
1.hive
2. 启动服务 hiveserver2
beeline
! connect jdbc:hive2://主机名:10000
6、Hive数据库、表在HDFS上存储的路径是什么
/user/hive/warehouse
7、like与rlike的区别
like的内容不是正则,而是通配符。
rlike的内容可以是正则,正则写法与Java一样。
8、内部表与外部表的区别
删除内部表会直接删除元数据(metadata)及存储数据;
删除外部表仅仅会删除元数据,HDFS上的文件并不会被删除;
9、分区表的优点是,分区字段的要求是
1.提高特定(指定分区)查询分析的效率
2.分区字段的要求:分区字段不能出现在表中已有的字段内
10、分桶表的优点是,分桶字段的要求是
1.使取样(sampling)和join 更高效
2.分桶字段的要求:分桶字段必须是表中已有的字段
11、数据导入表的方式 有5种方式
1、直接向分区表中插入数据
2、通过查询插入数据
3、多插入模式
4、查询语句中创建表并加载数据
5、创建表时通过location指定加载数据路径
12、数据导出表的方式
有7种方式
1 将查询的结果导出到本地
2 将查询的结果格式化导出到本地
4、Hadoop命令导出到本地
5、hive shell 命令导出
3、将查询的结果导出到HDFS上(没有local)
6、export导出到HDFS上
7、sqoop 导出数据(后面单独学)
13、order by与sort by的区别
order by 是全局排序,一个MapReduce,而 sort by 是局部分区内部进行排序
14、where 与 having的区别
1.where是作用在表的所有字段,having是作用在查询的字段上。
2.在where子句中不能使用聚组函数,在having语句中可以使用聚组函数
15、distribute by何时使用,通常与哪个联合使用
按照指定的字段进行分区时,对数据进行分区时使用
通常和sort by联合使用,Hive要求distribute by语句要写在sort by语句之前
16、Cluster by何时使用
要根据某个字段进行分区,并且以这个字段进行排序时使用Cluster by
17、distribute by+sort by(相同字段) 与Cluster by的区别
cluster by 的结果有限制,只能正序排列,而 distribute by+sort by 可根据需求进行排序
18、hive -e/-f/-hiveconf分别是什么意思
hive -e 后面的参数是‘命令行’
hive -f 后面的参数是文件
hive -hiveconf 设置hive运行时候的参数配置
19、hive声明参数有哪些方式,优先级是什么
配置文件(配置文件参数)
hive -hiveconf (命令行参数)
在hive的shell窗口set(参数声明)
优先级:参数声明>命令行参数>配置文件参数
20、编写hiveUDF代码,方法名称叫什么
evaluate
21、企业中hive常用的数据存储格式是什么?常用的数据压缩格式是什么?
在实际的项目开发当中,hive表的数据存储格式一般选择:orc或parquet。压缩方式一般选择snappy。
22、hive自定义函数的类型
1.UDF(User-Defined-Function) 一进一出
2.UDAF(User- Defined Aggregation Funcation) 聚集函数,多进一出。Count/max/min
3.UDTF(User-Defined Table-Generating Functions) 一进多出,如lateral view explore)
23、Fetch抓取中
设置more有什么效果
执行某些查询语句,不会执行mapreduce程序
设置none有什么效果
执行查询语句,所有的查询都会执行mapreduce程序
24、本地模式有什么好处
在数据量较小时,提高查询效率
原因:查询数据的程序运行在提交查询语句的节点上运行(不提交到集群上运行),
25、当一个key数据过大导致数据倾斜时,如何处理
当发生数据倾斜时,使用局部聚和可以起到性能调优的效果(在Map端进行聚合)
当发生倾斜时,查询语句会转化成至少两个MR程序,第一个程序进行局部聚和,第二个MR程序进行最终聚和。
26、Count(distinct) 的替换语句如何编写
使用嵌套查询
例:select count(distinct id) from score;
转|换
select count(id) from (select id from score group by id) a;
27、如何使用分区剪裁、列剪裁
什么是分区剪裁:需要哪个分区,就获取哪个分区的数据
什么是列剪裁:需要哪个列,就获取哪个列的数据
28、如何理解动态分区调整
以第一个表的分区规则,来对应第二个表的分区规则,将第一个表的所有分区,全部拷贝到第二个表中来,第二个表在加载数据的时候,不需要指定分区了,直接用第一个表的分区即可
29、数据倾斜时,如何将众多数据写入10个文件
1.设置reduce数量10,使用id,对id进行分区distribute by
2.设置reduce数量10,然后使用 distribute by rand()
rand字段为随机数 ,从而随机的将数据写入到文件中
30、reduce数量的计算是什么
决定reduce数量的因素,
参数1:每个Reduce处理的最大数据量
参数2:每个任务最大的reduce数
计算reducer数的公式 N=min(参数2,总输入数据量/参数1)
31、并行执行有什么好处
在没有依赖的前提下,开启并行执行(多任务多阶段同时执行),从而起到优化执行效率的作用
32、严格模式不能执行哪些命令
1、用户不允许扫描所有分区
2、使用了order by语句的查询,要求必须使用limit语句
3、限制笛卡尔积的查询
33、JVM重用有什么好处
重复利用JVM,以减少JVM开启和关闭的次数,减少任务开销,提高效率
34、什么是MR本地计算
数据存储后,计算这批数据的程序已经写完,程序在进行分发时,优先将程序分发到程序所用到数据所在的节点。
35、先join后过滤的优化方案
先过滤后关联(join)
例如:SELECT a.id FROM bigtable a LEFT JOIN ori b ON a.id = b.id WHERE b.id <= 10;
优化方案:
1、SELECT a.id FROM ori LEFT JOIN bigtable b ON (b.id <= 10 AND a.id = b.id);
2、SELECT a.id FROM bigtable a RIGHT JOIN (SELECT id FROM ori WHERE id <= 10 ) b ON a.id = b.id;
36、影响Map数量的因素
当文件大小很小时,影响map的数量的因素是文件的个数
当文件大小很大时,影响map的数量的因素是数据块的数量
37、什么是MR本地模式
任务提交时,运行在提交HQl 所在的节点,不提交到集群。(本地计算提交到集群。本地模式不提交到集群)
相关文章:

hive面试题
1、什么是Hive Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能(HQL) 2、Hive的意义(最初研发的原因) 避免了去写MapReduce,提供快速开发的…...

【CUDA】《CUDA编程:基础与实践》CUDA加速的关键因素
CUDA事件计时 CUDA提供了一种基于CUDA事件(CUDA event)的计时方式,可用来给一段CUDA代码(可能包含主机代码和设备代码)计时。 对计时器的封装: class CUDATimeCost { public:void start() {elapsed_time_ 0.0;// 初始化cudaEventcheckCudaRuntime(cud…...
——双向循环链表)
数据结构【Golang实现】(四)——双向循环链表
目录0. 定义节点1. IsEmpty()2. Length()3. AddFromHead()4. AddFromTail()5. Insert()6. DeleteHead()7. DeleteTail()8. Remove()9. RemoveByValue()10. Contain()11. Traverse()0. 定义节点 type DLNode struct {Data anyPrev, Next *DLNode }// DoublyLoopLinkedLis…...
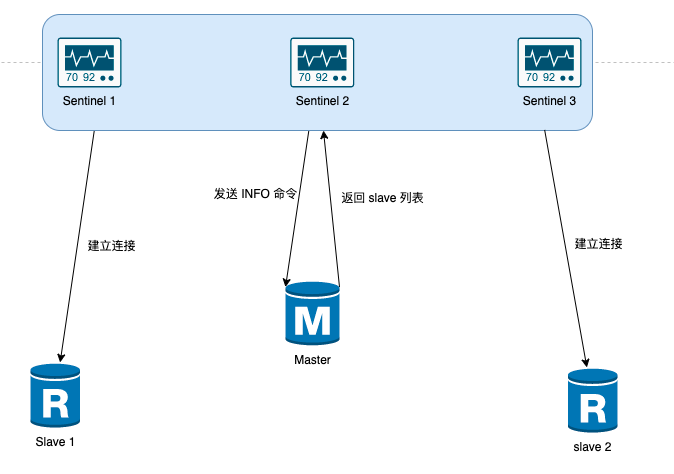
【Redis】高可用架构之哨兵模式 - Sentinel
Redis 高可用架构之哨兵模式 - Sentinel1. 前言2. Redis Sentinel 哨兵集群搭建2.1 一主两从2.2 三个哨兵3. Redis Sentinel 原理剖析3.1 什么哨兵模式3.2 哨兵机制的主要任务3.2.1 监控(1)每1s发送一次 PING 命令(2)PING 命令的回…...

图片的美白与美化
博主简介 博主是一名大二学生,主攻人工智能研究。感谢让我们在CSDN相遇,博主致力于在这里分享关于人工智能,c,Python,爬虫等方面知识的分享。 如果有需要的小伙伴可以关注博主,博主会继续更新的,…...
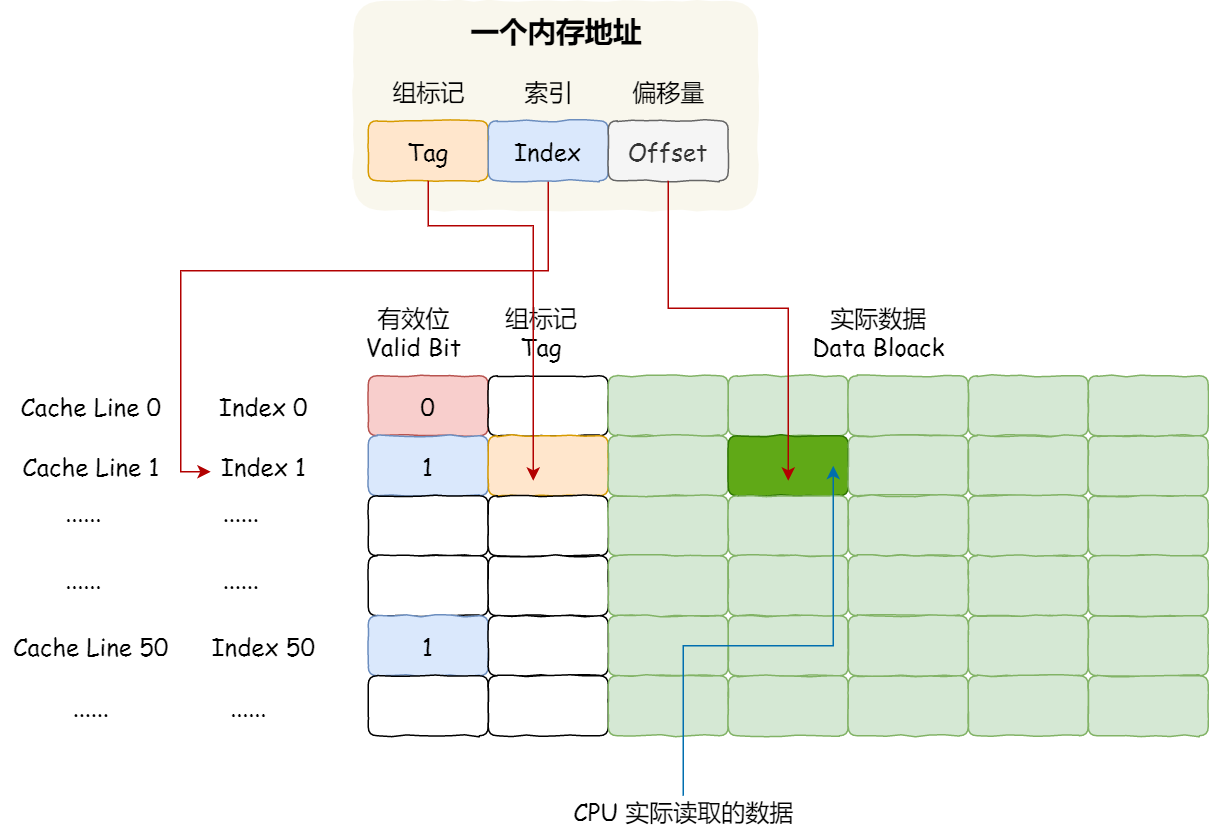
面试官:关于CPU你了解多少?
CPU是如何执行程序的? 程序执行的基本过程 第一步,CPU 读取「程序计数器」的值,这个值是指令的内存地址,然后 CPU 的「控制单元」操作「地址总线」指定需要访问的内存地址,接着通知内存设备准备数据,数据准…...

UI自动化测试-Selenium的使用
文章目录 1. 环境搭建1.1 入门示例1.2 元素操作常用方法1.3 浏览器操作常用方法1.4 获取元素信息常用方法1.5 鼠标操作常用方法1.6 键盘操作常用方法1.7 下拉选择框操作2. 元素定位2.1 id定位2.2 name定位2.3 class_name定位2.4 tag_name定位2.5 link_text定位2.6 partail_link…...
嵌入式学习笔记——STM32的USART相关寄存器介绍及其配置
文章目录前言USART的相关寄存器介绍状态寄存器:USARTX->SR具体位代表的含义实际代码数据寄存器 USARTX->DR波特率寄存器 USARTX->BRR控制寄存器 (USART_CR)控制寄存器1(USART_CR1)控制寄存器2(USART_CR2)GPIO…...
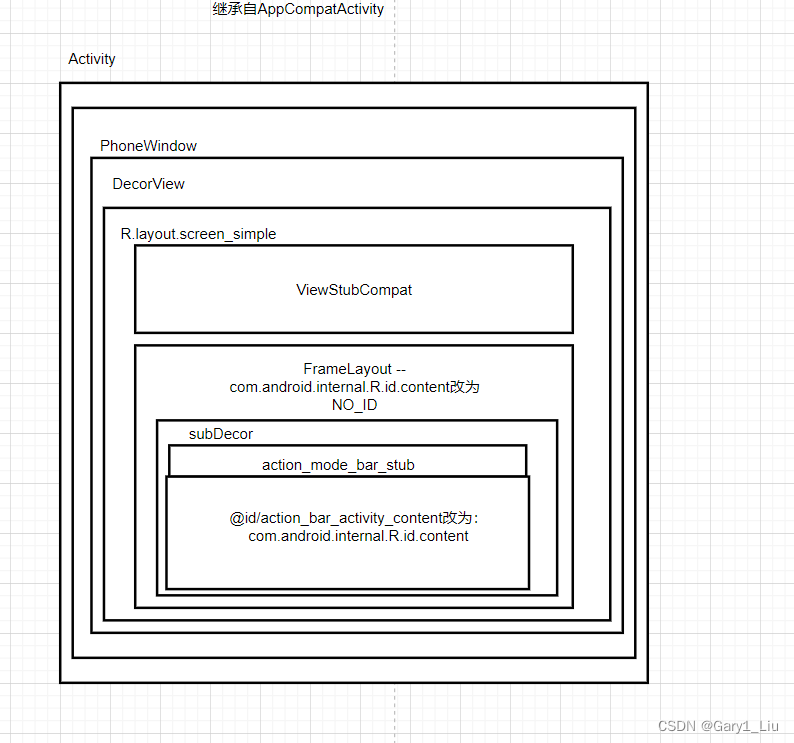
Android setContentView流程分析(一)
对于做Android App的小伙伴来说setContentView这个方法再熟悉不过了,那么有多少小伙伴知道它的调用到底做了多少事情呢?下面就让我们来看看它背后的故事吧? setContentView()方法将分为两节来讲: 第一节:如何获取De…...

doris数据库操作数字遇到的问题
关于doris数据库Apache Doris 是一个基于 MPP 架构的高性能、实时的分析型数据库,以极速易用的特点被人们所熟知,仅需亚秒级响应时间即可返回海量数据下的查询结果,不仅可以支持高并发的点查询场景,也能支持高吞吐的复杂分析场景。…...

3.13文件的IO操作
一.文件1.定义文件一般指的是存储在硬盘上的普通文件形如:txt.jpg.mp4,rar等这些文件在计算机中,文件可能是一个广义的概念,不仅可以包含普通文件,还可以包含目录(也就是文件夹.把目录称为目录文件)在操作系统中,还会用文件来描述一些其他的硬件设备或者软件资源比如网卡,显示器…...
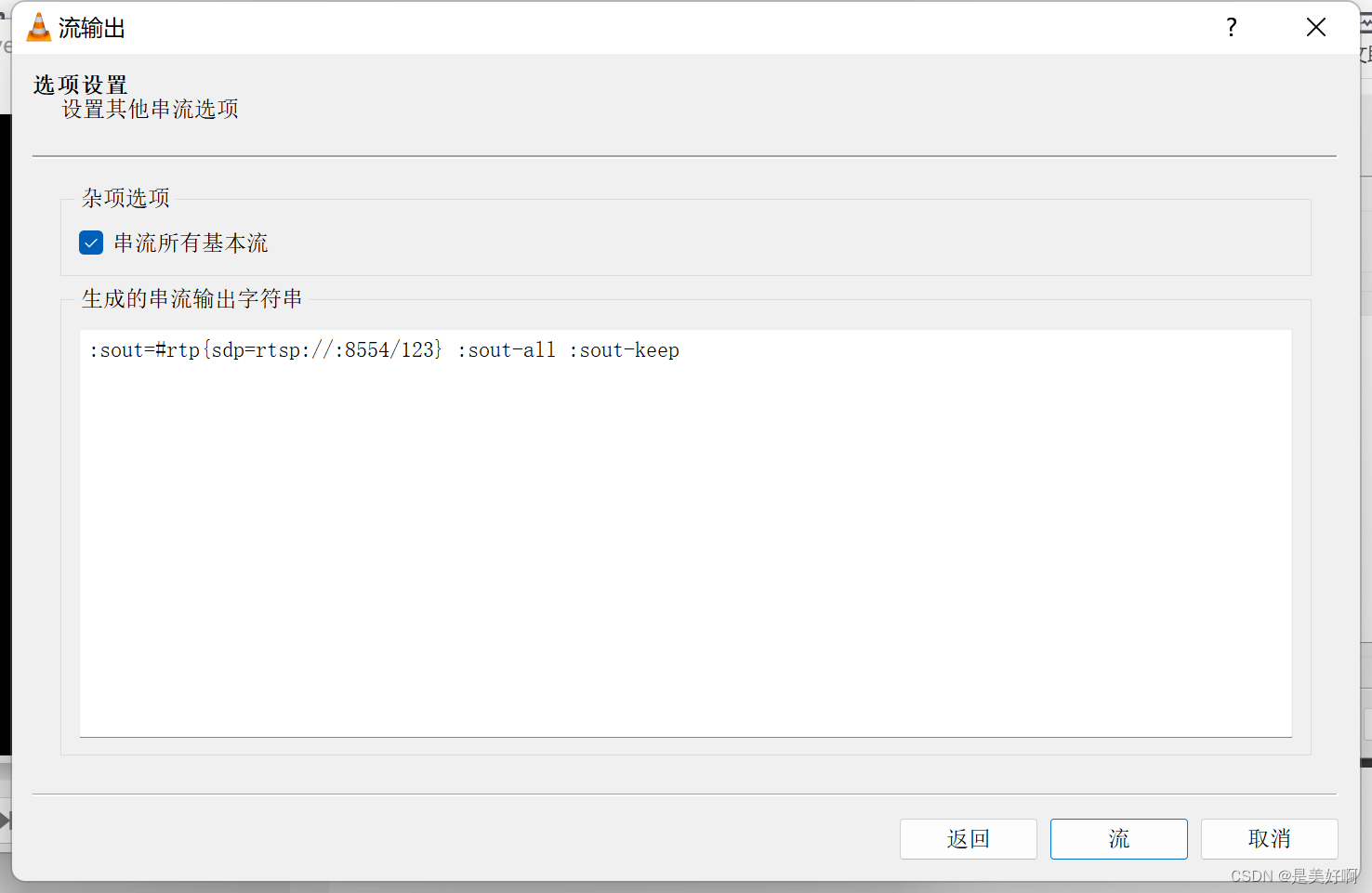
ffmpeg使用
1 下载FFmpeg安装 官网地址:https://www.ffmpeg.org/download.html#build-windows 进入网址,点击下面红框部分 点击下面范围进行下载,下载速度有点慢,等等吧! 下载成功后,解压后,复制bin的路…...
/分区器如何确定)
spark中的并行度(分区数)/分区器如何确定
源头RDD有自己的分区计算逻辑,一般没有分区器,并行度是根据分区算法自动计算的,RDD的compute函数中记录了数据如何而来,如何分区的hadoopRDD,根据XxxinputFormat.getInputSplits()来决定,比如默认的TextInputFormat将文…...

00后女生“云摆摊”两周赚1.5万,实体店转战线上真的能赚钱吗?
最近,山东临沂的00后女生利用小程序在线上“云摆摊”卖水果,两周赚1.5万,引发网友热议。不少人发出质疑的声音:年轻人不要有稳定的工作不做,去摆摊;网上开店成本低,开实体店结果就难说了&#x…...
| 机考必刷)
华为OD机试题 - 最优资源分配(JavaScript)| 机考必刷
更多题库,搜索引擎搜 梦想橡皮擦华为OD 👑👑👑 更多华为OD题库,搜 梦想橡皮擦 华为OD 👑👑👑 更多华为机考题库,搜 梦想橡皮擦华为OD 👑👑👑 华为OD机试题 最近更新的博客使用说明本篇题解:最优资源分配题目输入输出描述备注示例一输入输出说明示例二输入…...

利用python判断字符串是否为回文
1 问题 如何用python判断字符串是否为回文。 2 方法 用两个变量left,right模仿指针(一个指向第一个字符,一个指向最后一个字符),每比对成功一次,left向右移动一位,right向左移动一位,…...
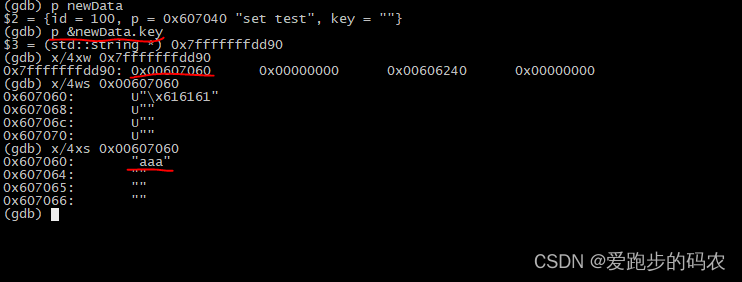
GDB 调用之ptype、set variable
今天在公司的时候,排查一个问题,创建l3 lif 失败,查看各种日志发现是用key去创建的 lif失败了,日志里指示key为空,导致的创建失败。原因为一个结构体比基线的多了一些东西,导致版本不对,既而计算…...
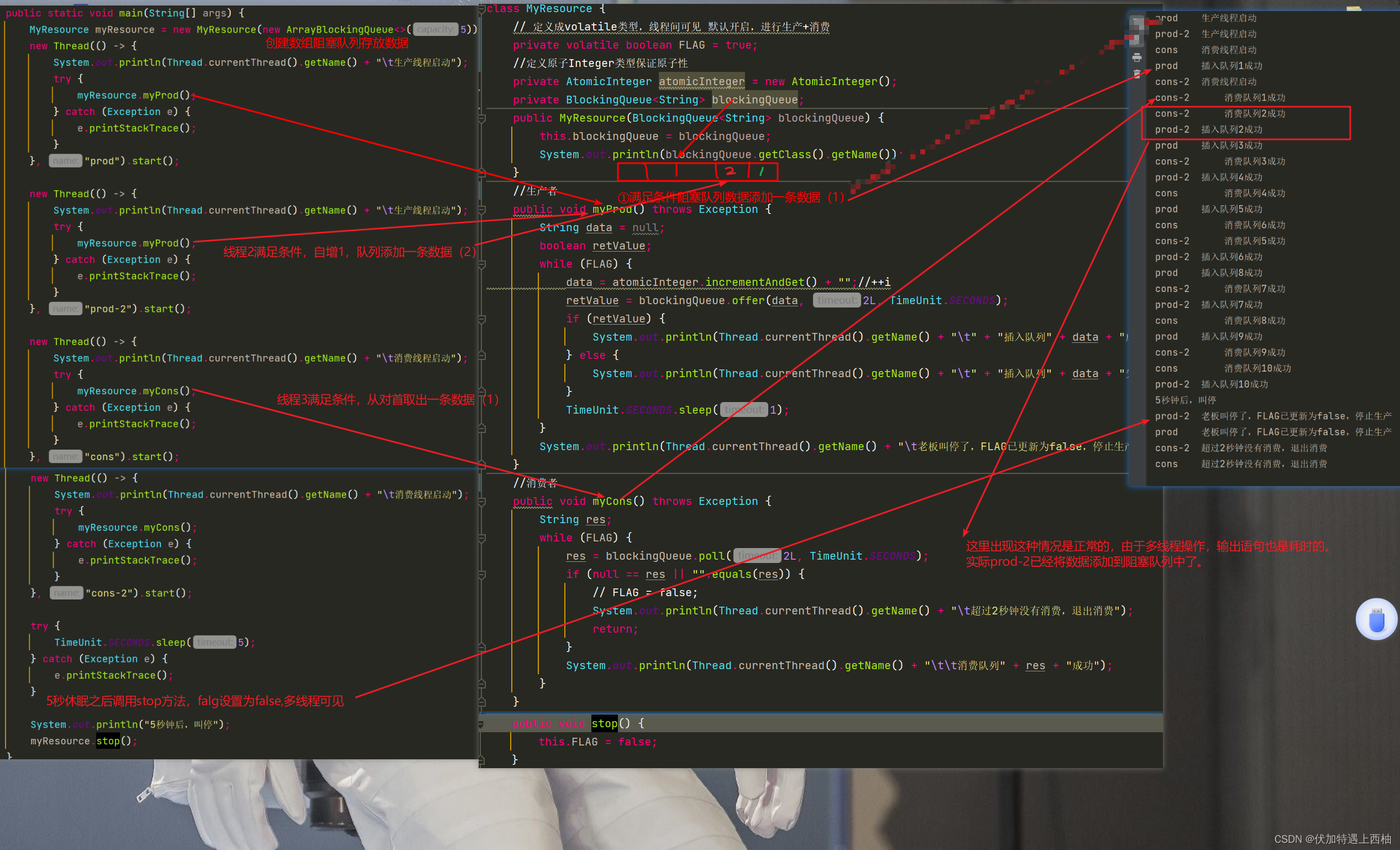
并发编程---阻塞队列(五)
阻塞队列一 阻塞队列1.1.阻塞队列概念1.2.阻塞队列API案例1.2.1. ArrayBlockingQueue1.2.1.1.抛出异常1.2.1.2.返回布尔1.2.1.3.阻塞1.2.1.4.超时1.2.2.SynchronousQueue二 阻塞队列应用---生产者消费者2.1.传统模式案例代码结果案例问题---防止虚假唤醒2.2.⽣产者消费者防⽌虚…...

本科课程【计算机组成原理】实验1 - 输出ABCD程序的生成
大家好,我是【1+1=王】, 热爱java的计算机(人工智能)渣硕研究生在读。 如果你也对java、人工智能等技术感兴趣,欢迎关注,抱团交流进大厂!!! Good better best, never let it rest, until good is better, and better best. 近期会把自己本科阶段的一些课程设计、实验报…...
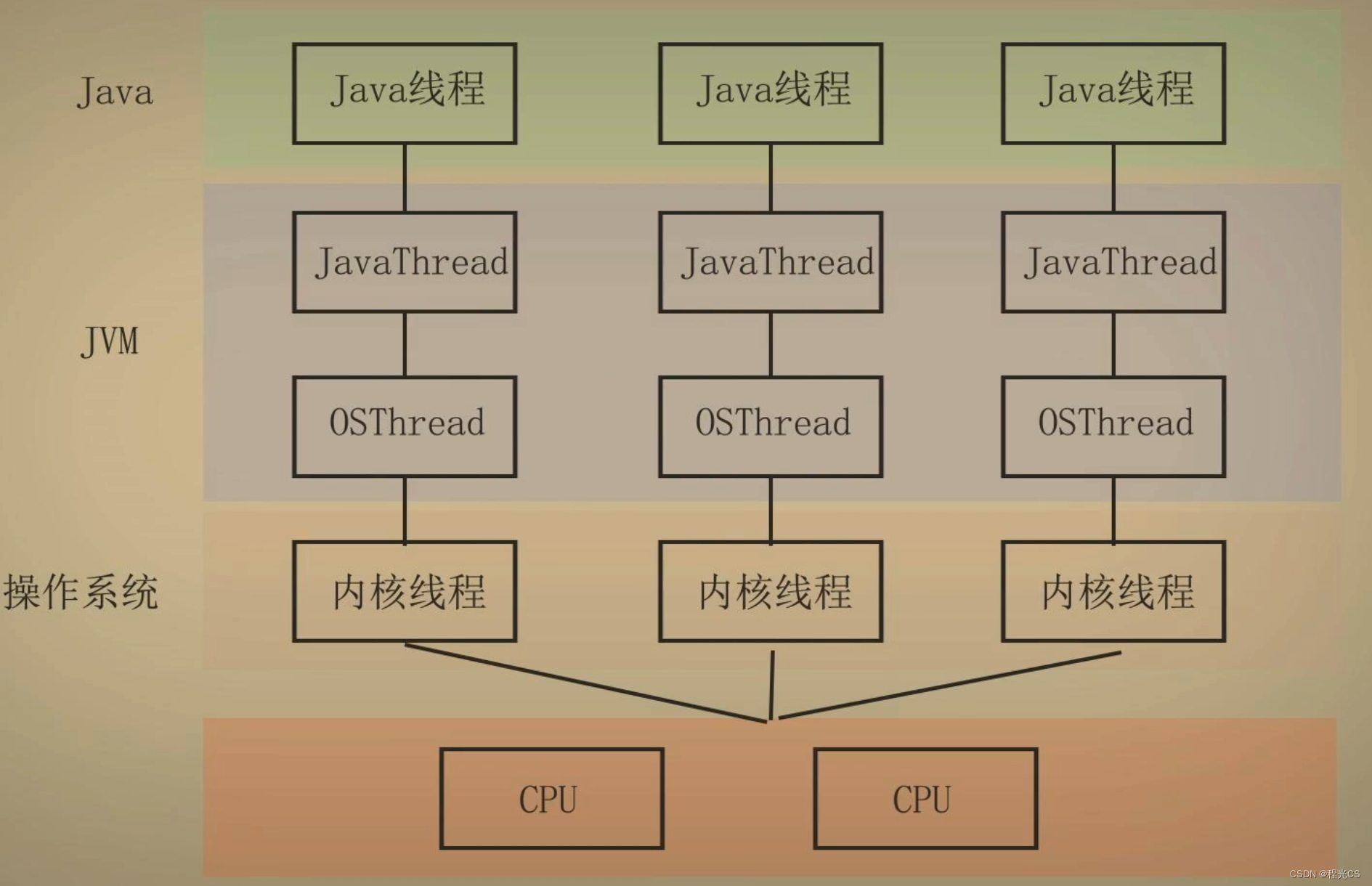
Java并发编程(2) —— 线程创建的方式与原理
一、Java线程创建的三种方式 1. 继承Thread类并重写run()方法 ///方法一:使用匿名内部类重写Thread的run()方法Thread t1 new Thread() {Overridepublic void run() {try {sleep(10000);} catch (InterruptedException e) {e.printStackTrace();}log.debug("…...

CANN/asc-devkit NodeIoNum API文档
NodeIoNum 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.com/…...

WpfDesigner终极指南:5分钟掌握WPF可视化设计工具,告别手写XAML代码
WpfDesigner终极指南:5分钟掌握WPF可视化设计工具,告别手写XAML代码 【免费下载链接】WpfDesigner The WPF Designer from SharpDevelop 项目地址: https://gitcode.com/gh_mirrors/wp/WpfDesigner 还在为复杂的WPF界面设计而烦恼吗?W…...
)
文献管理软件//Zotero文献导入实战:从新手到高手的五种核心路径(九)
1. 从零开始:Zotero文献导入的底层逻辑与核心价值 第一次接触Zotero时,我盯着空荡荡的文献库发呆了半小时——就像刚搬进新家的人面对空房间,明明知道需要填满它,却不知从何下手。文献管理软件的核心价值在于建立个人知识库&#…...

娱乐圈天降紫微星承载使命,海棠山铁哥扛起原创影视复兴大旗
一、乱世先声每一个时代的乱象,都需要一位天命者终结。 每一次行业的沉沦,都需要一束紫微星光破暗。当下影视行业,早已偏离创作初心,走入本末倒置的绝境。 翻拍泛滥成灾IP套皮横行情怀反复透支流水线作品扎堆 资本只求快速变现&am…...

小微团队如何利用Taotoken统一管理多项目API密钥与用量
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 小微团队如何利用Taotoken统一管理多项目API密钥与用量 对于小型开发团队而言,同时推进多个项目是常态。这些项目可能分…...

2026年精选5大小程序定制开发排行榜:赋能数字化转型新体验
导读:随着2026年企业数字化转型加速推进,小程序定制开发作为核心工具,正成为各行各业提升运营效率与用户互动的重要载体。本次深度测评聚焦当前市场中技术实力突出、服务能力全面的五家专业服务商,通过多维度剖析,为寻…...

芯片设计中的工程迷信与理性实践:从经验法则到数据驱动
1. 项目概述:从“黑色星期五”迷信到工程设计的理性思考作为一名在电子设计自动化(EDA)和半导体行业摸爬滚打了十几年的工程师,我每天打交道的是精确到纳秒的时序分析、纳米级的物理规则和数以亿计的晶体管布局。在这个世界里&…...

终极指南:Awoo Installer - Nintendo Switch游戏安装的免费开源解决方案
终极指南:Awoo Installer - Nintendo Switch游戏安装的免费开源解决方案 【免费下载链接】Awoo-Installer A No-Bullshit NSP, NSZ, XCI, and XCZ Installer for Nintendo Switch 项目地址: https://gitcode.com/gh_mirrors/aw/Awoo-Installer 还在为Switch游…...

CANN/asc-devkit设置核间同步基地址API
asc_set_ffts_base_addr 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https:/…...

CANN/asc-devkit向量减法ReLU函数
asc_sub_relu 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.c…...