[Day 26] 區塊鏈與人工智能的聯動應用:理論、技術與實踐
數據科學與AI的整合應用
數據科學(Data Science)和人工智能(AI)在現代技術世界中扮演著至關重要的角色。兩者的整合應用能夠為企業和研究人員提供強大的工具,以更好地理解、預測和解決各種複雜的問題。本文將深入探討數據科學與AI的整合應用,並通過多個示例和代碼片段來展示其強大的功能和實用性。
一、數據科學與AI的基礎
數據科學是一門利用數學、統計學和計算技術來分析和解釋數據的學科。它包括數據收集、數據處理、數據分析和數據可視化等多個環節。人工智能則是一個更為廣泛的領域,涵蓋了機器學習、深度學習、自然語言處理等多種技術,旨在使機器具有類似於人類的智能。
數據科學與AI的整合應用涉及以下幾個主要步驟:
- 數據收集和準備
- 數據探索和預處理
- 特徵工程
- 模型訓練和評估
- 模型部署和應用
二、數據收集和準備
數據收集是數據科學的第一步。在現代應用中,數據可以來自多種來源,如傳感器、互聯網、企業數據庫等。為了展示數據科學與AI的整合應用,我們將使用一個虛擬的銷售數據集進行分析。
import pandas as pd# 讀取數據
data = pd.read_csv('sales_data.csv')# 顯示前五行數據
print(data.head())
上述代碼讀取了一個名為sales_data.csv的文件,並使用Pandas庫將其加載為數據框。data.head()顯示數據集的前五行。
解釋:
import pandas as pd:導入Pandas庫,這是Python中處理數據的強大工具。pd.read_csv('sales_data.csv'):讀取CSV文件並將其轉換為Pandas數據框。data.head():顯示數據框的前五行,以便我們可以快速查看數據結構。
三、數據探索和預處理
在數據探索階段,我們需要了解數據的基本結構和統計特徵,並處理缺失值和異常值。
# 總覽數據信息
print(data.info())# 統計描述
print(data.describe())# 檢查缺失值
print(data.isnull().sum())# 填補缺失值
data.fillna(method='ffill', inplace=True)
解釋:
data.info():顯示數據框的基本信息,包括數據類型和非空數據數量。data.describe():提供數據的統計摘要,如均值、標準差、最小值和最大值。data.isnull().sum():計算每個列中的缺失值數量。data.fillna(method='ffill', inplace=True):使用前一個有效值填補缺失值。
四、特徵工程
特徵工程是指從原始數據中創建新的特徵,以提高模型的性能。這一過程可以包括數據轉換、特徵選擇和特徵創建等。
# 創建新特徵:銷售總額
data['Total_Sales'] = data['Unit_Price'] * data['Quantity']# 日期轉換
data['Order_Date'] = pd.to_datetime(data['Order_Date'])# 提取年、月、日特徵
data['Year'] = data['Order_Date'].dt.year
data['Month'] = data['Order_Date'].dt.month
data['Day'] = data['Order_Date'].dt.day
解釋:
data['Total_Sales'] = data['Unit_Price'] * data['Quantity']:通過單價和數量創建新的特徵“銷售總額”。data['Order_Date'] = pd.to_datetime(data['Order_Date']):將訂單日期轉換為日期時間格式。data['Year'],data['Month'],data['Day']:從訂單日期中提取年、月、日特徵。
五、模型訓練和評估
在模型訓練階段,我們將數據分為訓練集和測試集,並使用機器學習算法來訓練模型。
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error# 選擇特徵和目標變量
X = data[['Unit_Price', 'Quantity', 'Year', 'Month', 'Day']]
y = data['Total_Sales']# 分割數據集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 初始化並訓練模型
model = LinearRegression()
model.fit(X_train, y_train)# 預測和評估
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
print(f'Mean Squared Error: {mse}')
解釋:
from sklearn.model_selection import train_test_split:導入數據分割函數。from sklearn.linear_model import LinearRegression:導入線性回歸模型。from sklearn.metrics import mean_squared_error:導入均方誤差評估指標。X = data[['Unit_Price', 'Quantity', 'Year', 'Month', 'Day']]:選擇特徵。y = data['Total_Sales']:選擇目標變量。train_test_split:將數據分割為訓練集和測試集。model.fit(X_train, y_train):使用訓練數據訓練模型。model.predict(X_test):使用測試數據進行預測。mean_squared_error(y_test, y_pred):計算均方誤差以評估模型性能。
六、模型部署和應用
模型訓練完成後,可以將其部署到生產環境中,並用於實時預測和決策支持。
import joblib# 保存模型
joblib.dump(model, 'sales_prediction_model.pkl')# 加載模型
loaded_model = joblib.load('sales_prediction_model.pkl')# 使用加載的模型進行預測
new_data = [[20, 15, 2024, 7, 1]] # 單價為20,數量為15,日期為2024年7月1日
prediction = loaded_model.predict(new_data)
print(f'Predicted Total Sales: {prediction[0]}')
解釋:
import joblib:導入Joblib庫,用於保存和加載模型。joblib.dump(model, 'sales_prediction_model.pkl'):將訓練好的模型保存到文件。joblib.load('sales_prediction_model.pkl'):從文件中加載模型。loaded_model.predict(new_data):使用加載的模型進行預測。
七、案例分析與總結
數據科學與AI的整合應用在各行各業中都有廣泛的應用前景。例如,在電子商務中,可以使用這些技術來預測銷售趨勢、優化庫存管理和提升客戶體驗。在金融領域,可以用於風險評估、詐欺檢測和投資策略制定。
總結來說,數據科學與AI的整合應用需要經歷數據收集、數據探索、特徵工程、模型訓練和模型部署等多個步驟。每個步驟都有其重要性,且需要謹慎處理。通過本文中的示例和代碼片段,希望讀者能夠對這一過程有更深入的理解,並能夠應用於實際項目中。
相关文章:

[Day 26] 區塊鏈與人工智能的聯動應用:理論、技術與實踐
數據科學與AI的整合應用 數據科學(Data Science)和人工智能(AI)在現代技術世界中扮演著至關重要的角色。兩者的整合應用能夠為企業和研究人員提供強大的工具,以更好地理解、預測和解決各種複雜的問題。本文將深入探討…...

算法 —— 滑动窗口
目录 长度最小的子数组 无重复字符的最长子串 最大连续1的个数 将x减到0的最小操作数 找到字符串中所有字母异位词 最小覆盖子串 长度最小的子数组 sum比target小就进窗口,sum比target大就出窗口,由于数组是正数,所以相加会使sum变大&…...
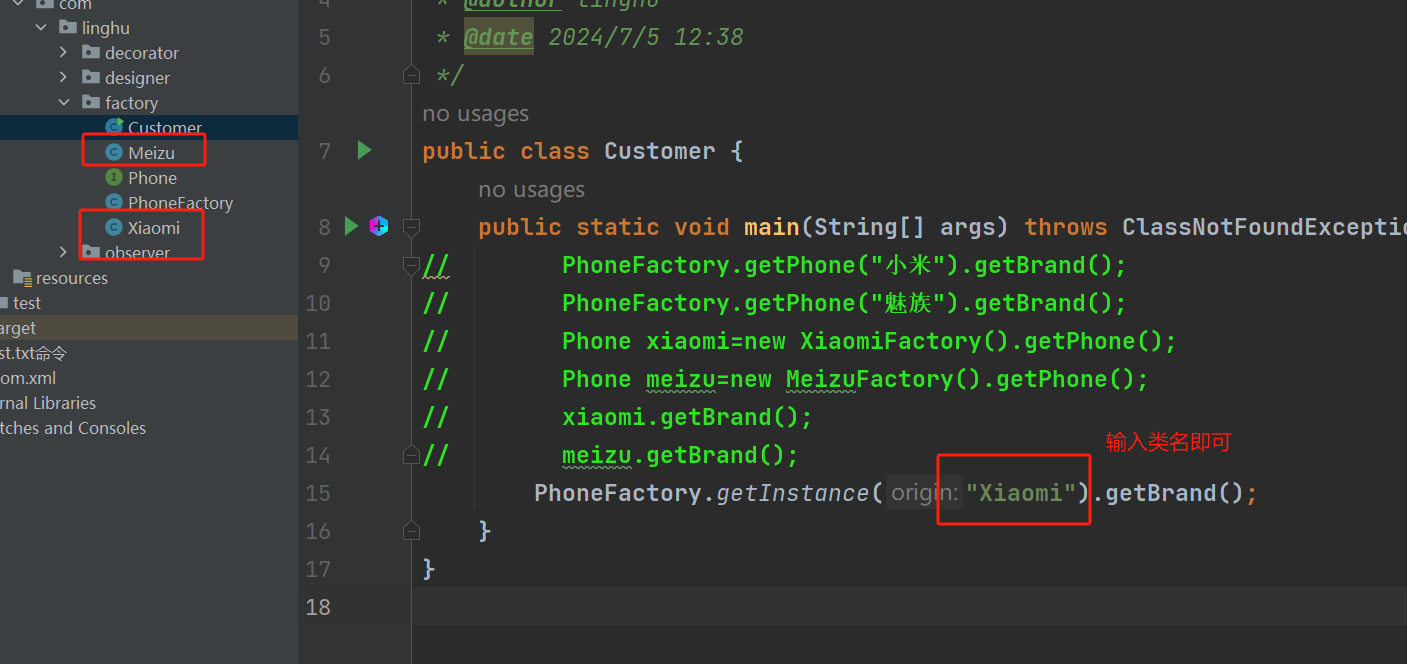
【设计模式】工厂模式(定义 | 特点 | Demo入门讲解)
文章目录 定义简单工厂模式案例 | 代码Phone顶层接口设计Meizu品牌类Xiaomi品牌类PhoneFactory工厂类Customer 消费者类 工厂方法模式案例 | 代码PhoneFactory工厂类 Java高级特性---工厂模式与反射的高阶玩法方案:反射工厂模式 总结 其实工厂模式就是用一个代理类帮…...

Linux之计划和日志
计划任务 计划任务概念解析 在Linux操作系统中,除了用户即时执行的命令操作以外,还可以配置在指定的时间、指定的日期执行预先计划好的系统管理任务(如定期备份、定期采集监测数据)。通过安装at和crontabs这两个系统服务实现一次性、周期性计划任务的功能,并分别通过at、…...

C++ 多态篇
文章目录 1. 多态的概念和实现1.1 概念1.2 实现1.2.1 协变1.2.2 析构函数1.2.3 子类虚函数不加virtual 2. C11 final和override3.1 final3.2 override 3. 函数重载、重写与隐藏4. 多态的原理5. 抽象类6.单继承和多继承的虚表6.1 单继承6.2 多继承 7. 菱形继承的虚表(了解)7.1 菱…...

【LVGL-SquareLine Studio】
LVGL-SquareLine Studio ■ SquareLine Studio-官网下载地址■ SquareLine Studio-参考博客■ SquareLine Studio-安装■ SquareLine Studio-汉化■ SquareLine Studio-■ SquareLine Studio-■ SquareLine Studio-■ SquareLine Studio-■ SquareLine Studio- ■ SquareLine S…...

mysqli 与mysql 区别和联系, 举例说明
mysqli是一种PHP的扩展,用于与MySQL数据库进行交互。它提供了一套面向对象的接口,可以更方便地操作数据库。MySQL是一种关系型数据库管理系统,用于存储和管理数据。 区别: mysqli是MySQL的扩展,而不是单独的数据库管…...

【SpringCloud应用框架】Nacos安装和服务提供者注册
第二章 Spring Cloud Alibaba Nacos之Nacos安装和服务提供者注册 文章目录 Nacos介绍为何使用Nacos?一、Nacos下载和安装1. 下载2. 安装Linux/Unix/MacWindows 二、Nacos服务提供者注册1. Nacos代替Eureka2. Nacos服务注册中心3. 引入Nacos Discovery进行服务注册/发…...
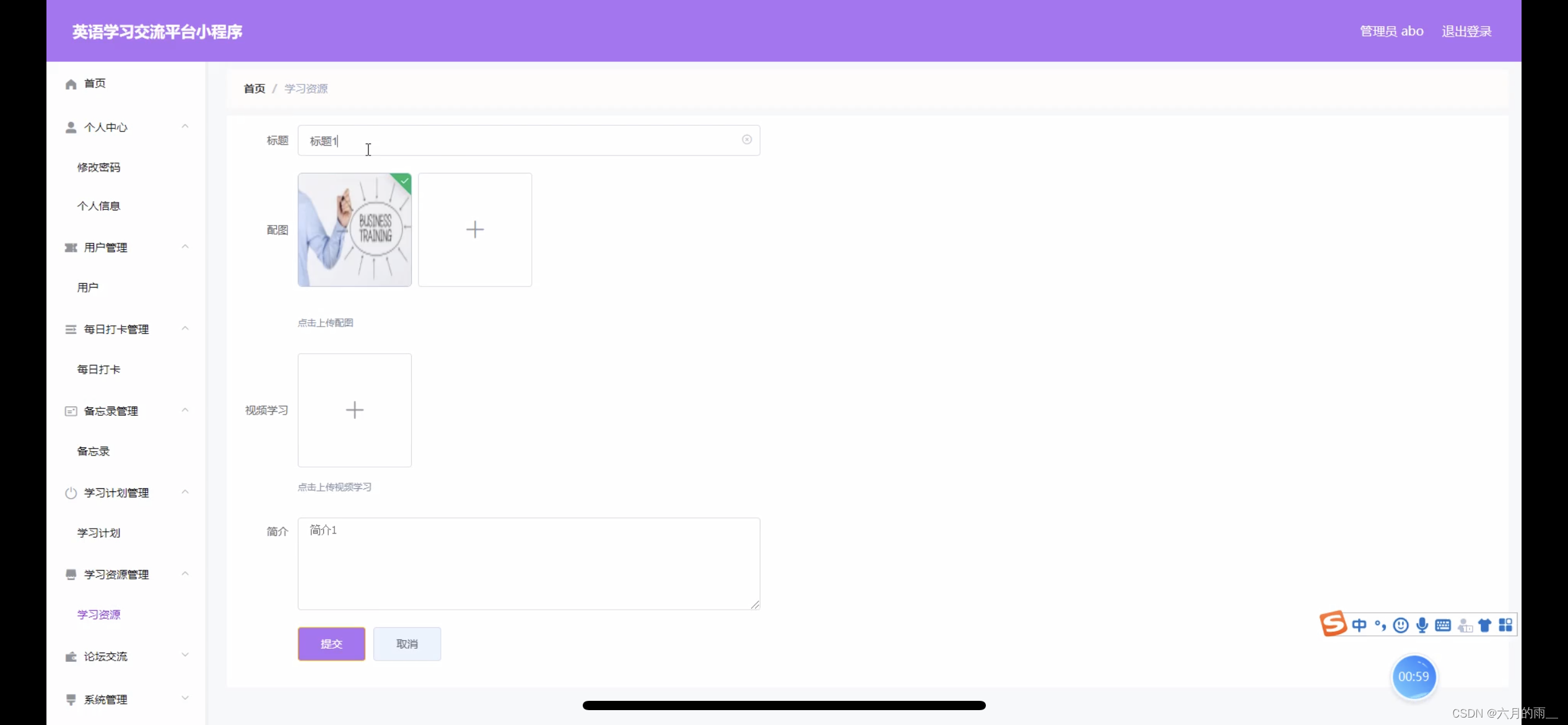
英语学习交流小程序的设计
管理员账户功能包括:系统首页,个人中心,用户管理,每日打卡管理,备忘录管理,学习计划管理,学习资源管理,论坛交流 微信端账号功能包括:系统首页,学习资源&…...

实现Java多线程中的线程间通信
实现Java多线程中的线程间通信 大家好,我是微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿! 1. 线程间通信的基本概念 在线程编程中,线程间通信是指多个线程之间通过共享内存或消息传递的方式进行交…...

C++模板元编程(一)——可变参数模板
这个系列主要记录C模板元编程的常用语法 文章目录 引言语法应用函数模板可变参数的打印可变参数的最小/最大函数 类模板 参考文献 引言 在C11之前,函数模板和类模板只支持含有固定数量的模板参数。C11增强了模板功能,允许模板定义中包含任意个(包括0个)…...

kafka中
Kafka RocketMQ概述 RabbitMQ概述 ActiveMQ概述 ZeroMQ概述 MQ对比选型 适用场景-从公司基础建设力量角度出发 适用场景-从业务场景出发 Kafka配置介绍 运行Kafka 安装ELAK 配置EFAK EFAK界面 KAFKA常用术语 Kafka常用指令 Kafka中消息读取 单播消息 group.id 相同 多播消息 g…...

Android 获取当前电池状态
在 API 级别 23 上获取充电状态 要在 API 级别 23 上获取电池的当前状态,只需使用电池管理器系统服务: BatteryManager batteryManager (BatteryManager) getSystemService(BATTERY_SERVICE); boolean isCharging batteryManager.isCharging();使用 S…...

【JVM 的内存模型】
1. JVM内存模型 下图为JVM内存结构模型: 两种执行方式: 解释执行:JVM是由C语言编写的,其中有C解释器,负责先将Java语言解释翻译为C语言。缺点是经过一次JVM翻译,速度慢一点。JIT执行:JIT编译器…...

【雷丰阳-谷粒商城 】【分布式高级篇-微服务架构篇】【17】认证服务01—短信/邮件/异常/MD5
持续学习&持续更新中… 守破离 【雷丰阳-谷粒商城 】【分布式高级篇-微服务架构篇】【17】认证服务01 环境搭建验证码倒计时短信服务邮件服务验证码短信形式:邮件形式: 异常机制MD5参考 环境搭建 C:\Windows\System32\drivers\etc\hosts 192.168.…...

geom buffer制作
1. auto buffer_geom line_string->buffer(15);//buffer //这个是x和y各扩大段15个单位 auto buffer_geom line_string->buffer(15);//buffer //这个是x和y各扩大段15米 获取buffer坐标 auto boundary buffer_geom->getBoundary(); auto boundary_coords boun…...
微软正在放弃React
最近,微软Edge团队撰写了一篇文章,介绍了微软团队如何努力提升Edge浏览器的性能。但在文中,微软对React提出了批评,并宣布他们将不再在Edge浏览器的开发中使用React。 我将详细解析他们的整篇文章内容,探讨这一决定对…...

U盘非安全退出后的格式化危机与高效恢复策略
在数字化时代,U盘作为数据存储与传输的重要工具,其数据安全备受关注。然而,一个常见的操作失误——U盘没有安全退出便直接拔出,随后再插入时却遭遇“需要格式化”的提示,这不仅让用户措手不及,更可能意味着…...
安卓虚拟位置修改
随着安卓系统的不断更新,确保软件和应用与最新系统版本的兼容性变得日益重要。本文档旨在指导用户如何在安卓14/15系统上使用特定的功能。 2. 系统兼容性更新 2.1 支持安卓14/15:更新了对安卓14/15版本的支持,确保了软件的兼容性。 2.2 路…...
)
大数据面试题之Presto[Trino](5)
目录 Presto的扩展性如何? Presto如何与Hadoop生态系统集成? Presto是否可以连接到NoSQL数据库? 如何使用Presto查询Kafka中的数据? Presto与Spark SQL相比有何优势和劣势? Presto如何与云服务集成࿱…...

③ AI副业第一步:如何找到适合自己的AI赚钱赛道
③ AI副业第一步:如何找到适合自己的AI赚钱赛道选对赛道,努力才有意义。选错赛道,越努力离钱越远。前言:为什么大多数人AI副业做不起来? 我观察了100想做AI副业的人,失败的原因高度一致: 失败路…...
)
别再乱用npm install了!手把手教你用npx only-allow为项目指定包管理器(支持pnpm/yarn/npm)
用only-allow统一团队包管理器:从配置到CI的全流程指南 你是否曾经在拉取一个新项目后,面对npm install、yarn还是pnpm i的抉择感到困惑?或者更糟的是,团队成员混用不同包管理器导致node_modules结构不一致,引发各种诡…...

Python开发者首次使用Taotoken接入大模型API的完整步骤指南
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Python开发者首次使用Taotoken接入大模型API的完整步骤指南 对于Python开发者而言,接入大模型API进行应用开发已成为一…...

BLE蓝牙扫描深度剖析:扫描原理、核心参数、前后台差异
一、前言BLE设备交互分为两大角色:广播端(外设Peripheral)与扫描端(中心Central)。上一篇博客详解了四大广播模式,本文聚焦配套核心能力——BLE扫描机制。绝大多数蓝牙开发疑难问题:前台能扫后台…...

智慧无人机巡检-无人机可见光红外数据集 无人机多模态检测数据集 红外与可见光检测数据集
智慧无人机巡检-无人机可见光红外数据集,已完成标注,可导出各种常用数据集,yolo,voc,coco等格式。可见光33000张,红外16100张,目标一张一个 无人机可见光红外目标数据集项目详细信息数据集名称无…...

广州因特智能:AI视觉软硬结合,打破半导体检测装备“卡脖子”困境
【导语:广州因特智能科技孵化于西安电子科技大学广州研究院,专注用AI视觉技术解决工业场景的“卡脖子”检测难题,为半导体、光通信、新能源三大领域提供高端检测装备。】校地合作孵化,构建完整能力体系广州因特智能科技由西安电子…...
)
告别混乱绑定!在UE5 GAS中优雅管理技能输入(基于GameplayTag)
告别混乱绑定!在UE5 GAS中优雅管理技能输入(基于GameplayTag)当你的UE5 RPG项目发展到中期,技能数量从十几个膨胀到几十个时,最痛苦的莫过于发现InputAction绑定已经变成一团乱麻。每次新增技能都要修改输入绑定逻辑&a…...

【与我学 ClaudeCode】协作篇 之 Worktree + Task Isolation :目录隔离的并行执行通道
作者:逆境不可逃 技术永无止境 希望我的内容可以帮助到你!!!! 大家吼 ! 我是 逆境不可逃 今天给大家带来文章《【与我学 ClaudeCode】协作篇 之 Worktree Task Isolation :目录隔离的并行执行通道》. Le…...

完整解决方案:PL2303 Windows 10驱动快速安装指南
完整解决方案:PL2303 Windows 10驱动快速安装指南 【免费下载链接】pl2303-win10 Windows 10 driver for end-of-life PL-2303 chipsets. 项目地址: https://gitcode.com/gh_mirrors/pl/pl2303-win10 如果你正在Windows 10系统上使用PL-2303HXA或PL-2303XA芯…...

Monkey测试进阶:黑白名单搭配这些隐藏参数,让你的安卓稳定性测试效率翻倍
Monkey测试进阶:黑白名单搭配这些隐藏参数,让你的安卓稳定性测试效率翻倍在持续集成和自动化测试成为标配的今天,Monkey测试早已不再是简单的随机事件生成工具。当你的测试场景从单次手动执行升级到夜间批量测试或CI流水线时,如何…...