大数据面试题之Presto[Trino](5)
目录
Presto的扩展性如何?
Presto如何与Hadoop生态系统集成?
Presto是否可以连接到NoSQL数据库?
如何使用Presto查询Kafka中的数据?
Presto与Spark SQL相比有何优势和劣势?
Presto如何与云服务集成?
如何使用Presto进行实时数据分析?
在Presto中进行数据挖掘时应注意哪些问题?
如何使用Presto进行大规模数据集的交互式探索?
解释Presto在数据可视化中的应用。
Presto的扩展性如何?
Presto的设计特别强调了其扩展性,使其能够高效处理大规模数据集的查询。以下是Presto扩展性的几个关键方面:
- 水平扩展:Presto采用分布式架构,可以轻松地通过增加更多的工作节点(Worker Nodes)来横向扩展。每个工作节点负责执行查询任务的一部分,而协调器节点(Coordinator Node)负责任务的分发和结果汇总。这种设计允许Presto处理PB级别的数据,并且能够应对高并发的查询请求。
- 自定义数据源连接器(Connectors):Presto允许用户开发特定于数据源的连接器,这意味着它可以访问各种类型的数据存储,包括但不限于Hadoop HDFS、Amazon S3、Hive、Cassandra、MySQL、PostgreSQL等。这为数据源的多样性提供了极大的灵活性。
- 资源管理与隔离:Presto支持细粒度的资源管理,确保查询之间不会相互干扰。通过资源隔离机制,可以有效控制查询使用的CPU、内存等资源,提升整体集群的稳定性和效率。
- 动态调整与优化:Presto能够根据当前的查询负载动态调整查询计划和资源分配,例如通过推测执行(speculative execution)来处理慢节点(stragglers),以及利用资源隔离来确保关键查询的执行效率。
- 可插拔组件:Presto的多个组件如连接器、函数等都是可插拔的,允许用户根据需要添加或替换,以满足特定的业务需求或性能要求。
- 基于内存的计算:虽然Presto依赖于内存来加速查询处理,但它采用了智能的内存管理策略,比如在聚合操作中边读取数据边聚合,避免一次性将所有数据加载到内存中,这样既提升了查询速度又减少了内存需求。
- SQL兼容性与标准化:Presto全面支持ANSI SQL,使得数据分析师和开发人员可以使用标准的SQL语言进行复杂的查询和数据分析,降低了学习成本并提高了可移植性。
综上所述,Presto的扩展性不仅体现在其处理大规模数据的能力上,还包括了对多种数据源的支持、资源的有效管理和优化、以及对用户自定义需求的高度适应性,这些都使Presto成为处理大数据分析任务的强大工具。
Presto如何与Hadoop生态系统集成?
Presto与Hadoop生态系统的集成是通过专门设计的Hadoop连接器实现的,这使得Presto能够直接访问存储在Hadoop Distributed File System (HDFS) 上的数据,以及通过Hive Metastore管理的表结构和元数据。以下是Presto与Hadoop集成的关键方面:
1、Hive Connector:
Presto提供了一个Hive连接器(Hive-Hadoop2 connector),允许Presto查询Hive中的数据。该连接器能够读取Hive的表定义和元数据,包括存储位置、分区信息等,使得用户可以通过Presto直接使用HQL(类SQL的Hive查询语言)来查询Hive表。
2、HDFS访问:
Presto可以直接访问存储在HDFS上的文件,包括Parquet、ORC、Avro等格式的数据,这些都是Hadoop生态系统中常见的数据存储格式。通过Hive连接器,Presto能够理解HDFS上的数据布局,并进行有效的数据扫描和处理。
3、Metastore集成:
Presto通过Thrift协议与Hive Metastore服务通信,获取表和分区的元数据信息。这意味着Presto可以利用Hive已经建立好的数据组织结构和表结构,无需重新定义数据模型。
4、安全集成:
Presto支持Hadoop的安全特性,如Kerberos认证和Hadoop安全模式(如Hadoop RPC保护、HDFS权限控制等),确保了数据访问的安全性。
5、资源管理:
Presto可以与Hadoop YARN集成,YARN作为资源管理器可以为Presto的查询任务分配资源,确保集群资源的高效利用。
6、配置与部署:
在部署时,需要在Presto的配置文件中指定Hive连接器的相关配置,包括Hive Metastore URI、HDFS地址等,以建立与Hadoop集群的连接。
7、性能优化:
Presto针对Hadoop数据进行了性能优化,例如使用向量化查询执行、并行数据读取等技术,以提高查询速度。
Presto是否可以连接到NoSQL数据库?
Presto本身是一个分布式SQL查询引擎,主要用于处理大规模数据集,尤其是那些存储在像Hadoop这样的分布式文件系统上的数据。虽然Presto的核心设计是围绕关系型和结构化数据查询,但通过扩展和第三方连接器,Presto可以连接到一些NoSQL数据库,实现对非关系型数据的查询。
例如,虽然直接的支持可能有限,但理论上讲,如果有人为特定的NoSQL数据库(如MongoDB、Cassandra等)开发了相应的连接器(Connector),那么Presto就能通过这些连接器与这些NoSQL数据库进行集成。连接器需要实现如何与NoSQL数据库通信、如何解析其数据模型以及如何将SQL查询转换为NoSQL数据库可以理解的操作。
社区和第三方供应商可能会提供这样的连接器,使得Presto能够查询和分析存储在NoSQL数据库中的数据。然而,具体支持哪些NoSQL数据库,以及这些连接器的功能和性能如何,都需要根据最新的社区贡献和供应商提供的解决方案来确定。由于NoSQL数据库的多样性,每个数据库的集成方式和复杂度都会有所不同。
如何使用Presto查询Kafka中的数据?
要使用Presto查询Kafka中的数据,你需要确保Presto已经配置了Kafka连接器,并且Kafka中的数据是以Presto能够识别的格式存储的(如JSON、Avro等)。以下是使用Presto查询Kafka数据的基本步骤:
步骤 1: 安装和配置Kafka连接器
- 安装连接器:确保你的Presto集群已安装了Kafka连接器。如果没有,你可能需要从Presto的官方仓库或其他可靠来源下载并安装Kafka连接器的jar包。
- 配置catalog属性文件:在Presto的配置目录下,创建或编辑一个catalog属性文件(例如etc/catalog/kafka.properties),用于定义Kafka连接器的配置。配置通常包含Kafka集群的信息、主题名称、数据格式等。 一个基本的配置示例可能如下:
connector.name=kafka
kafka.nodes=localhost:9092
kafka.default-schema=default
kafka.topic-names=test-topic
kafka.hide-internal-columns=true这里,kafka.nodes指定了Kafka broker的地址,kafka.topic-names列出了你想要查询的Kafka主题名称。
步骤 2: 启动或重启Presto服务
确保完成上述配置后,重启Presto服务以便加载新的连接器配置。
步骤 3: 执行SQL查询
一旦配置完成并重启服务,你就可以使用Presto的SQL接口来查询Kafka中的数据了。在Presto CLI或者任何与Presto集成的查询工具中,你可以像查询其他数据源一样编写SQL语句。
一个简单的查询示例可能如下:
SELECT * FROM kafka.default.test_topic;这里,kafka是之前配置的catalog名称,default是schema名称,test_topic是你配置的Kafka主题。
注意事项
- 确保Kafka中的数据格式与Presto的Kafka连接器支持的格式相匹配。
- Kafka连接器可能需要额外的配置,特别是涉及到数据序列化/反序列化(如Avro schema注册)时。
- 考虑到Kafka数据的实时性和无界特性,查询结果可能随时间变化,特别是对于未设置结束偏移的实时查询。
- 监控查询性能和资源使用情况,根据需要调整Presto和Kafka的配置参数。
Presto与Spark SQL相比有何优势和劣势?
Presto与Spark SQL各有其优势和劣势,具体取决于使用场景、数据规模、查询类型和性能要求等因素。以下是它们之间的一些关键对比:
Presto的优势:
- 高性能即席查询:Presto设计初衷是针对大规模数据集进行快速的交互式查询,尤其在处理即席查询时表现出色,能够快速返回结果。
- 内存管理与优化:Presto的内存管理机制较为精细,能动态分配内存给各个工作节点,减少内存浪费,提高查询效率。
- 架构简洁高效:Presto采用主从式架构,其中协调器节点负责SQL优化和执行计划,有利于高效利用硬件资源。
- 灵活的数据源集成:Presto易于集成多种数据源,支持多种数据格式,如JSON、CSV、Avro等,且对Hadoop生态系统集成良好。
- 近似查询功能:提供诸如APPROX_DISTINCT、APPROX_PERCENTILE等近似函数,适合对响应时间敏感的场景。
Presto的劣势:
- 生态系统相对较小:相较于Spark,Presto的生态系统和社区活跃度可能较低,意味着支持的工具和扩展可能不如Spark丰富。
- 对复杂ETL支持不足:虽然擅长即席查询,但Presto在处理复杂的ETL(提取、转换、加载)作业和数据管道方面可能不如Spark灵活和强大。
- 容错机制:与Spark相比,Presto在单个节点失败时的容错能力较弱,可能导致查询失败,而Spark则能通过RDD的血缘关系重做计算。
Spark SQL的优势:
- 综合性强:Spark是一个全面的数据处理框架,不仅支持SQL查询,还支持批处理、流处理、机器学习等多种计算模型。
- 强大的数据处理能力:对于复杂的ETL作业、数据管道构建以及大数据分析任务,Spark SQL表现优秀。
- 容错与恢复:基于RDD的血缘关系,Spark能提供强大的数据容错和任务恢复能力。
- 社区与生态:Spark拥有庞大的开发者社区和丰富的生态系统,不断有新的功能和优化推出,支持广泛的数据源和工具集成。
- 内存计算:Spark基于内存计算,对于迭代计算和数据重用场景能显著提升性能。
Spark SQL的劣势:
- 即席查询性能:尽管Spark SQL性能不断提升,但在某些即席查询场景下,尤其是在小到中等规模数据集上,可能不如Presto快速。
- 资源消耗:Spark在处理查询时可能消耗更多的系统资源,尤其是在内存管理方面,可能导致更高的硬件成本。
- 学习曲线:Spark的多功能性意味着学习和管理成本相对较高,尤其是对于只需要SQL查询功能的用户而言。
总体来说,选择Presto还是Spark SQL应基于具体需求,如需快速的即席查询和轻量级分析,Presto可能是更好的选择;而对于需要综合数据处理能力、复杂ETL或机器学习任务的场景,Spark SQL则更为合适。
Presto如何与云服务集成?
Presto与云服务的集成主要通过以下几种方式实现,以充分利用云平台的弹性、可扩展性和服务生态:
- 数据源连接器:Presto支持多种云存储服务的数据源连接器,如Amazon S3、Google Cloud Storage、Azure Blob Storage等,允许直接查询存储在这些云服务上的数据。通过配置相应的连接器,Presto可以透明地访问存储在云存储桶中的数据文件,进行高效的分析查询。
- 运行在云平台上的Presto集群:Presto可以在各大云服务商的基础设施上部署和运行,例如在AWS、Azure、GCP上通过EC2、VM实例或容器服务(如ECS、EKS、GKE)部署Presto集群。利用云平台的自动扩展功能,可以根据工作负载动态调整集群规模,实现资源的弹性分配。
- 与云原生服务集成:Presto可以与云服务商提供的大数据和分析服务深度集成,例如与AWS Glue、Google BigQuery、Azure Data Lake等服务集成,实现数据的无缝迁移、元数据管理、数据转换等功能。
- 安全与身份管理:Presto可以集成云平台的身份和访问管理服务(IAM),如AWS IAM、Azure AD等,实现统一的身份验证和授权,确保数据访问的安全性。
- 监控与日志集成:Presto集群可以配置为将日志和监控数据发送到云服务商的日志分析服务,如AWS CloudWatch、Azure Monitor等,便于集群的运维管理和性能监控。
- 云上自动化部署与管理:利用云服务商提供的模板和服务(如AWS CloudFormation、Azure Resource Manager)可以自动化部署Presto集群,简化管理操作,并与云上的其他服务紧密集成。
- 混合云和多云部署:Presto支持混合云架构,如AWS Outposts上的Amazon EMR,允许企业将Presto部署在本地数据中心的同时,也能访问和处理公有云中的数据,实现数据处理的一致性和灵活性。
综上所述,Presto通过与云服务的紧密集成,不仅提升了大数据处理的效率和弹性,还提供了更广泛的业务应用场景,帮助企业更好地利用云平台的先进特性。
如何使用Presto进行实时数据分析?
Presto虽然被设计为支持高速、实时的数据分析,但它主要聚焦于交互式查询,而非严格意义上的“实时流处理”。然而,通过以下策略,Presto可以非常有效地应用于接近实时的数据分析场景:
- 集成实时数据源:确保Presto能够直接访问实时更新的数据源,如Kafka或流式数据存储(如Kinesis Streams)。通过配置Kafka或类似的实时数据连接器,Presto可以查询到几乎实时的数据流。
- 数据缓存与近实时视图:为了加快查询速度,可以使用数据缓存技术,比如TTL(Time To Live)缓存最近的数据,或者构建近实时汇总表(Materialized Views)。这样,Presto查询的是预计算和更新频繁的汇总数据,而不是每次查询都直接触碰原始数据。
- 增量处理与微批处理:对于持续流入的数据,可以设计数据处理流程定期(如每分钟或每几秒)将新数据加载到Presto可访问的存储中,形成微批处理。这样,虽然不是严格意义上的实时,但可以提供接近实时的分析体验。
- 优化查询性能:利用Presto的查询优化特性,比如列式存储优化、向量化执行、并行处理等,可以极大提升查询速度,使分析结果更快呈现。
- 资源管理与自动扩展:在云环境中运行Presto时,利用云服务的自动扩展功能,根据查询负载动态调整计算资源,确保即使在高并发查询时也能维持低延迟。
- 实时数据湖集成:与支持实时更新的数据湖解决方案(如Delta Lake、Hudi)集成,这些存储系统能够在接收新数据的同时保持ACID事务性,使得Presto能够查询到最新状态的数据。
- 监控与报警:建立实时监控和报警机制,监控Presto集群的性能和数据接入的稳定性,确保任何性能瓶颈或数据延迟都能被迅速发现并处理。
虽然Presto本身并不直接提供实时流处理能力,但通过上述策略和适当的架构设计,可以构建出能够满足大多数近实时数据分析需求的解决方案。在实际应用中,Presto常与实时流处理系统(如Apache Flink、Kafka Streams)结合使用,形成端到端的实时数据分析体系。
在Presto中进行数据挖掘时应注意哪些问题?
在Presto中进行数据挖掘时,需要注意以下几个关键问题以确保高效和准确的分析过程:
-
数据分区策略:合理设置数据分区可以显著提升查询性能。根据时间范围、地域或其他业务逻辑对数据进行分区,有助于减少查询时的数据扫描量。确保分区列的选择与数据访问模式相匹配。
-
列式存储格式:使用列式存储格式(如Parquet、ORC)可以提高数据压缩率和查询效率,特别是在涉及大量列筛选和聚合操作时。列式存储能减少I/O操作和内存占用,加速数据挖掘过程。
-
查询优化:
- 避免全表扫描:尽量缩小查询范围,利用分区过滤、索引(如果适用)、以及有效的WHERE子句。
- 列引用与别名:正确引用字段名,避免与关键字冲突,必要时使用反引号或双引号包裹。
- 时间函数处理:在处理时间戳时,正确使用Timestamp关键字进行比较,确保时间函数的正确应用。
-
资源管理:合理配置Presto的内存、CPU资源,避免资源争抢,特别是在共享集群环境中。利用查询队列和优先级设置,平衡查询之间的资源分配。
-
连接器与数据源:确保使用的连接器是最新的,并且与数据源兼容。错误或过时的连接器可能导致查询失败或性能下降。
-
数据倾斜问题:注意检查数据分布,避免数据倾斜导致的查询性能瓶颈。可以考虑数据重分区或采用其他策略来均衡数据处理。
-
并行度与任务调度:适当调整查询的并行度,根据集群的实际能力和数据分布情况优化任务调度,提高整体查询效率。
-
数据质量:数据挖掘前,确保数据质量,包括完整性、一致性、准确性。脏数据可能会影响分析结果的有效性。
-
监控与调优:持续监控Presto的查询性能和资源使用情况,根据监控结果进行适时的调优。利用日志和性能指标来诊断潜在的问题。
-
安全性与权限管理:在进行数据挖掘时,遵守数据访问权限和安全策略,确保敏感数据得到保护。
通过关注这些方面,可以确保在Presto中进行数据挖掘时,既高效又安全,同时获得准确可靠的分析结果。
如何使用Presto进行大规模数据集的交互式探索?
使用Presto进行大规模数据集的交互式探索时,可以遵循以下步骤和最佳实践,以确保高效和有效的分析过程:
-
安装与配置Presto: 确保Presto已正确安装并配置好所有必需的连接器,以便访问你的数据源,比如HDFS、S3、MySQL、PostgreSQL、Kafka等。根据你的数据存储位置,配置相应的目录和凭证。
-
数据源连接: 配置好连接器后,通过Presto的SQL界面或客户端工具(如Presto CLI、JDBC/ODBC驱动)连接到数据源。你可以开始列出可用的数据库、表和视图,为探索做准备。
-
使用SQL进行交互式查询: 利用Presto的SQL支持,开始编写查询语句来探索数据。从简单的选择和过滤操作开始,逐步构建更复杂的查询,如聚合、分组、排序、连接等。Presto的即时反馈特性使得探索过程更加流畅。
-
优化查询性能:
- 尽可能减少数据扫描量,使用有效的WHERE子句和LIMIT语句。
- 选择合适的分区键和数据布局,以利用Presto的并行处理能力。
- 利用Presto的列式存储支持,如Parquet或ORC格式,提高查询效率。
- 监控查询执行计划,优化慢查询,必要时调整连接器或Presto的配置。
-
利用Presto的高级功能:
- 使用窗口函数进行排名、分位数计算等高级分析。
- 利用近似函数(如APPROX_DISTINCT, APPROX_PERCENTILE)快速获取统计概览。
- 对于非结构化数据,使用内置函数解析JSON、XML等数据格式。
-
数据可视化工具集成: 将Presto与数据可视化工具(如Tableau、Superset、Metabase)集成,可以直观地展示查询结果,帮助快速理解数据模式和趋势。
-
监控资源使用: 在执行大规模查询时,监控集群资源使用情况,确保没有资源瓶颈,必要时调整集群配置或查询执行策略。
-
安全性与权限管理: 在探索过程中,确保遵守数据访问控制和安全政策,正确配置角色和权限,保护数据隐私。
通过上述步骤,你可以有效地利用Presto进行大规模数据集的交互式探索,快速发现数据洞察,支持业务决策。
解释Presto在数据可视化中的应用。
Presto在数据可视化中的应用主要体现在其作为高性能分布式SQL查询引擎的角色,它能够快速地从各种数据源提取数据,为数据可视化工具提供实时或接近实时的数据支撑。以下是Presto在数据可视化场景中的几个关键应用点:
-
即时数据查询:Presto能够对大规模数据集进行快速查询,这对于需要即时响应的交互式数据可视化至关重要。用户可以通过前端可视化工具(如Tableau、Apache Superset、Grafana等)直接发出SQL查询至Presto,快速获取并展示数据,实现数据的实时分析和展示。
-
多源数据整合:Presto支持连接多种数据存储系统,包括关系型数据库、大数据平台(如Hadoop HDFS、Amazon S3、Google Cloud Storage)、以及消息队列(如Kafka)。这意味着数据可视化可以跨越不同的数据源,综合展现全局数据视图,无需预先将数据整合到单一存储中。
-
大数据处理能力:Presto针对大数据集进行了优化,可以处理PB级别的数据查询,使得在大数据背景下进行复杂的数据可视化成为可能。这对于需要处理海量数据的行业,如金融、电商、广告分析等尤为重要。
-
灵活的数据探索:数据分析师和业务用户可以通过Presto的交互式查询能力,快速迭代查询逻辑,探索数据中的模式和趋势,这种灵活性对于发现数据背后的故事至关重要,也是构建有效数据可视化故事板的基础。
-
与可视化工具集成:许多流行的商业和开源数据可视化工具都支持直接连接Presto,如Tableau的Presto连接器允许用户直接在Tableau界面中执行Presto查询,而Apache Superset等开源平台也集成了Presto作为数据源选项,便于用户配置和使用。
-
支持复杂分析:Presto支持复杂SQL查询,包括窗口函数、聚合函数等,使得在数据可视化中实现高级分析成为可能,比如时间序列分析、分段分析、用户行为路径分析等。
综上所述,Presto凭借其强大的查询性能和广泛的数据源连接能力,成为了数据可视化流程中的重要一环,为用户提供快速、灵活、深入的数据洞察力。
引用:通义千问
相关文章:
)
大数据面试题之Presto[Trino](5)
目录 Presto的扩展性如何? Presto如何与Hadoop生态系统集成? Presto是否可以连接到NoSQL数据库? 如何使用Presto查询Kafka中的数据? Presto与Spark SQL相比有何优势和劣势? Presto如何与云服务集成࿱…...

对编程开发人员在今年的一些建议
一、今年的大环境 这几天身体不太好,又不断看到地狱级的就业问题。所以有些想法想和大家分享一下,并提出自己的一些想法和建议。今年的大环境不好,做为非专业人士,咱们也不分析,以免贻笑大方。但针对大环境下的计算机…...

VSCode设置好看清晰的字体!中文用鸿蒙,英文用Jetbrains Mono
一、中文字体——HarmonyOS Sans SC 1、下载字体 官网地址:https://developer.huawei.com/consumer/cn/design/resource/ 直接下载:https://communityfile-drcn.op.dbankcloud.cn/FileServer/getFile/cmtyPub/011/111/111/0000000000011111111.20230517…...

SpringBoot新手快速入门系列教程四:创建第一个SringBoot的API
首先我们用IDEA新建一个项目,请将这些关键位置按照我的设置设置一下 接下来我将要带着你一步一步创建一个Get请求和Post请求,通过客户端请求的参数,以json格式返回该参数{“message”:"Hello"} 1,先在IDE左上角把这里改为文件模式…...

第1集《修习止观坐禅法要》
《修习止观坐禅法要》诸位法师,诸位学员,阿弥院佛! 我们今天能够暂时放下世间的尘劳,大家在一起研究佛法的课程,这件事情在我们的生命当中是非常的稀有难得。 基本上,我们佛法的修习目的是追求身心的安乐…...

markdown变量引用
格式 变量定义通常是路径或网络链接 变量测试...

如何使用echart做K线图
使用ECharts制作K线图需要先引入ECharts的库文件,然后通过调用相应的API来配置和渲染K线图。以下是一个简单的示例代码: // 引入ECharts库文件 <script src"https://cdn.jsdelivr.net/npm/echarts5.0.0/dist/echarts.min.js"></scri…...

Spring Boot应用使用GraalVM本地编译相关配置
1. 介绍 Java应用程序可以通过Graalvm Native Image提前编译生成与本地机器相关的可执行文件。与在JVM执行java程序相比,Native Image占用内存更小和启动速度更快。 从spring boot3开始支持GraalVM Native Image,因此要使用此特性,需要把sp…...

代码的坏味道——长函数
前言:一个函数应该尽量做一件事情,如果非要做多个事情,要做函数提取,每次迭代应该考虑到是否有重复代码或者可以优化的代码。 长函数:长函数的产生: 逻辑是平铺直叙的需求迭代没有考虑优化,一次…...

【机器学习】基于密度的聚类算法:DBSCAN详解
🌈个人主页: 鑫宝Code 🔥热门专栏: 闲话杂谈| 炫酷HTML | JavaScript基础 💫个人格言: "如无必要,勿增实体" 文章目录 基于密度的聚类算法:DBSCAN详解引言DBSCAN的基本概念点的分类聚类过…...

Qt 网络编程 网络信息获取操作
学习目标:网络信息获取操作 前置环境 运行环境:qt creator 4.12 学习内容 一、Qt 网络编程基础 Qt 直接提供了网络编程模块,包括基于 TCP/IP 的客户端和服务器相关类,如 QTcpSocket/QTcpServer 和 QUdpSocket,以及实现 HTTP、FTP 等协议的高级类,如 QNetworkRe…...

linux中的进程以及进程管理
程序和进程的区别和联系 程序(Program): 程序是一组指令的集合,通常存储在磁盘或其他存储设备上,是一种静态的概念。程序本身并没有运行,它只是一个可执行的文件或脚本,包含了一系列的指令和数…...
)
pyecharts可视化案例大全(11~20)
pyecharts可视化案例大全(11~20) 十一、设置动画效果十二、直方图带视觉组件十三、设置渐变色(线性渐变)十四、设置渐变色(径向渐变)十五、设置分割线十六、设置分隔区域十七、面积图十八、堆叠面积图十九、自定义线样式二十、折线图平滑处理十一、设置动画效果 在图表加载前…...

Docker在人工智能领域的应用与实战
摘要 人工智能(AI)技术的快速发展带来了对高效开发和部署工具的需求。Docker作为一个创新的容器化平台,为AI领域提供了强大的支持。本文详细介绍了Docker在AI模型开发、训练、部署以及服务器集群管理等方面的应用,并探讨了其在数…...

python基础篇(8):异常处理
在Python编程中,异常是程序运行时发生的错误,它会中断程序的正常执行流程。异常处理机制使得程序能够捕获这些错误,并进行适当的处理,从而避免程序崩溃。 1 错误类型 代码的错误一般会有语法错误和异常错误两种,语法错…...

FortiClient 用IPsec VPN 远程拨号到FortiGate说明文档
说明:本文档针对IPsec VPN 中的Remote VPN 进行说明,即远程用户使用PC中的FortiClient软件,通过VPN拨号的方式连接到公司总部FortiGate设备,访问公司内部服务器。在配置之前需要统一VPN策略和参数,如模式… 说明&#…...

Git-Unity项目版本管理
目录 准备GitHub新建项目并添加ssh密钥Unity文件夹 本文记录如何用git对unity 项目进行版本管理,并可传至GitHub远端。 准备 名称版本windows11Unity2202.3.9.f1gitN.A.githubN.A. GitHub新建项目并添加ssh密钥 GitHub新建一个repositorywindows11 生成ssh-key&…...

每日一题~ leetcode 402 (贪心+单调栈)
click me! 这个贪心的推导在leetcode上已经很明确了。 click me! 删除k个数,可以先考虑删除一个数。这也是一种常见的思路。(如果进行同样的操作多次,可以先只 考虑一次操作如何实现,或者他的影响。完成这一次操作后,…...
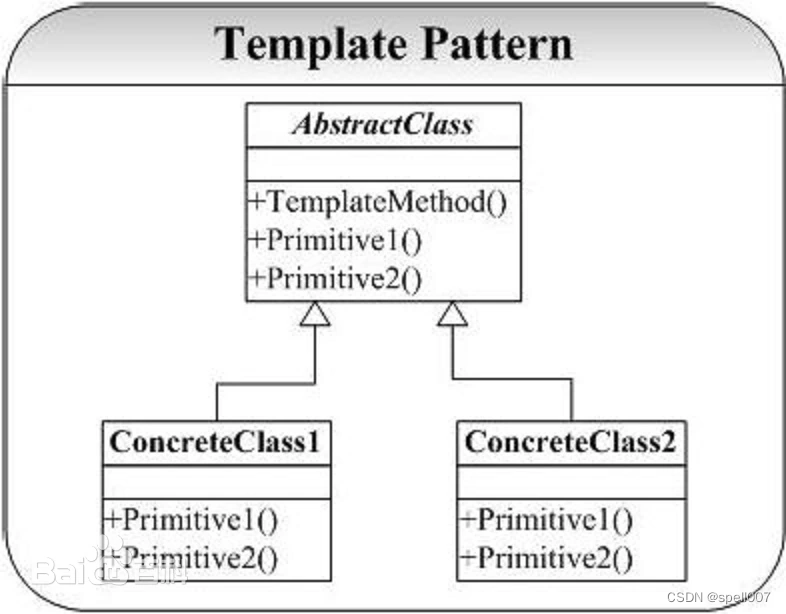
设计模式之模版方法
模版方法介绍 模版方法(Template Method)模式是一种行为型设计模式,它定义了一个操作(模板方法)的基本组合与控制流程,将一些步骤(抽象方法)推迟到子类中,使得子类可以在…...

docker部署redis/mongodb/
一、redis 创建/root/redis/conf/redis.conf 全部执行命令如下 docker run -it -d --name redis -p 6379:6379 --net mynet --ip 172.18.0.9 -m 400m -v /root/redis/conf:/usr/local/etc/redis -e TXAsia/Shangehai redis redis-server /usr/local/etc/redis/redis.conf 部署…...

App无辜躺枪?手把手教你搞定腾讯手机管家误报导致的应用商店下架
当合规应用遭遇误报下架:开发者系统性应对指南运动健康类应用被标记为金融诈骗软件?社交工具因"病毒风险"被各大商店紧急下架?这类看似荒谬的误报事件,正在成为中小开发团队的"无妄之灾"。某知名运动App开发团…...
重构)
嘈杂工业场景下的自适应VAD与双码本声纹识别鉴权系统:基于端侧轻量化神经网络与向量量化(VQ)重构
在大型化工车间、能源集控中心以及金融极密隔离库房中,离线声纹识别是物理访问控制和身份安全核验的重要生物特征屏障。然而,在环境本底噪声高达80dB以上的恶劣工业场景下,常规的语音活动检测(VAD)会频繁误触ÿ…...

配置OpenClaw Agent使用Taotoken作为后端模型提供商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 配置OpenClaw Agent使用Taotoken作为后端模型提供商 基础教程类,指导希望使用OpenClaw等Agent工具的开发者,…...

Python UiAutomation实战:从网页数据抓取到桌面应用,一个库打通数据采集全链路
Python UiAutomation实战:打通数据采集全链路的智能解决方案 在数据驱动的商业环境中,企业常常面临跨平台数据采集的挑战——财务系统里的交易记录需要与网站后台的报表进行交叉分析,销售数据要从桌面软件导出后上传到云端处理系统。传统的人…...

FairyGUI Unity鼠标悬停与点击对象获取原理与实战
1. 这不是“加个OnMouseEnter就能用”的事:FairyGUI在Unity中处理鼠标交互的真实困境很多人第一次在Unity里集成FairyGUI,想实现“鼠标悬停显示提示”或“点击高亮当前按钮”,下意识就去翻Unity的MonoBehaviour文档,找OnMouseEnte…...

巨量投放总结
巨量商务管理平台 : https://business.oceanengine.com 巨量广告投放平台: https://ad.oceanengine.com 商务管理平台 账户 广告组 计划 广告投放平台 层级关系: 广告组 -> 计划 -> 创意 对应FB: 系列 - > 广告组 -> 广告...

基于PIC32的嵌入式MIDI合成器:从波表合成到硬件实现
1. 项目概述:一个基于嵌入式微控制器的MIDI声音合成器如果你对电子音乐制作、嵌入式开发,或者DIY硬件合成器感兴趣,那么“REMI Synth”这个项目绝对值得你花时间深入了解。它本质上是一个数字单音MIDI控制的声音合成器,核心是一块…...

LeagueAkari:英雄联盟终极自动化助手革命性指南
LeagueAkari:英雄联盟终极自动化助手革命性指南 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 你是否在英雄联盟游戏中反复经历这…...

Python strip 与 rstrip 函数区别
Python strip 与 rstrip 函数区别 文章目录Python strip 与 rstrip 函数区别一、核心作用二、基础语法三、基础使用示例四、指定删除特定字符五、常用业务场景一、核心作用 函数作用范围strip()移除字符串首尾空白字符rstrip()仅移除字符串右侧末尾字符,左侧保持不…...

Taotoken的稳定性与低延迟在实时对话应用中的实际体验
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken的稳定性与低延迟在实时对话应用中的实际体验 在开发需要快速响应的AI聊天应用时,后端API的稳定性和延迟表现是…...