摸鱼大数据——Spark SQL——DataFrame详解一
1.DataFrame基本介绍
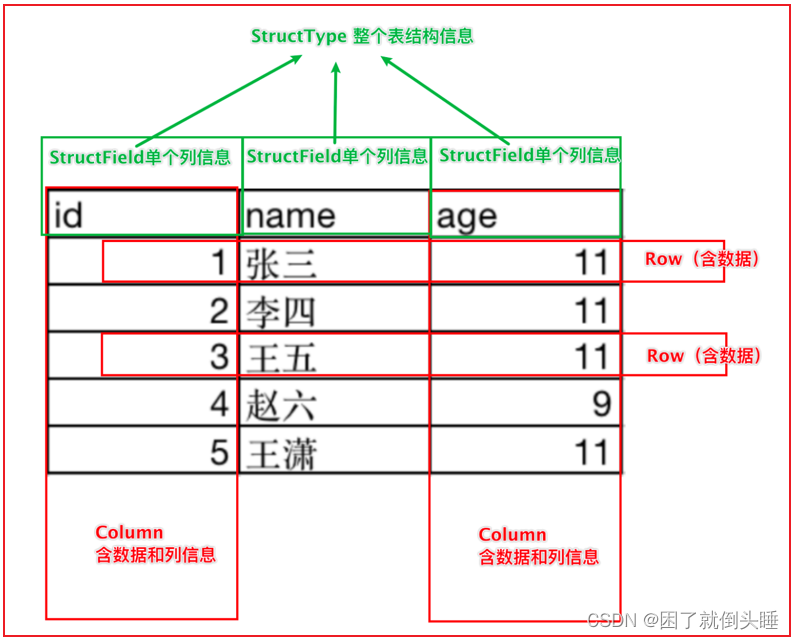
DataFrame表示的是一个二维的表。二维表,必然存在行、列等表结构描述信息表结构描述信息(元数据Schema): StructType对象字段: StructField对象,可以描述字段名称、字段数据类型、是否可以为空行: Row对象列: Column对象,包含字段名称和字段值在一个StructType对象下,由多个StructField组成,构建成一个完整的元数据信息
如何构建表结构信息数据:

2.DataFrame的构建方式
方式1: 使用SparkSession的createDataFrame(data,schema)函数创建data参数1.基于List列表数据进行创建2.基于RDD弹性分布式数据集进行创建3.基于pandas的DataFrame数据进行创建schema参数1: 字符串格式一 :“字段名1 字段类型,字段名2 字段类型”格式二(推荐):“字段名1:字段类型,字段名2:字段类型”2: List格式: ["字段名1","字段名2"] 3: DataType(推荐,用的最多)格式一:schema=StructType().add('字段名1',字段类型).add('字段名2',字段类型)格式二:schema=StructType([StructField('字段名1',类型),StructField('字段名1',类型)])方式2: 使用DataFrame的toDF(colNames)函数创建DataFrame的toDF方法是一个在Apache Spark的DataFrame API中用来创建一个新的DataFrame的方法。这个方法可以将一个RDD转换为DataFrame,或者将一个已存在的DataFrame转换为另一个DataFrame。在Python中,你可以使用toDF方法来指定列的名字。如果你不指定列的名字,那么默认的列的名字会是_1, _2等等。 格式: rdd.toDF([列名])方式3: 使用SparkSession的read()函数创建在 Spark 中,SparkSession 的 read 是用于读取数据的入口点之一,它提供了各种方法来读取不同格式的数据并将其加载到 Spark 中进行处理。统一API格式: spark.read.format('text|csv|json|parquet|orc|...') : 读取外部文件的方式.option('k','v') : 选项 可以设置相关的参数 (可选).schema(StructType | String) : 设置表的结构信息.load('加载数据路径') : 读取外部文件的路径, 支持 HDFS 也支持本地简写API格式:注意: 以上所有的外部读取方式,都有简单的写法。spark内置了一些常用的读取方案的简写格式: spark.read.文件读取方式()注意: parquet:是Spark中常用的一种列式存储文件格式和Hive中的ORC差不多, 他俩都是列存储格式
2.1 createDataFrame()创建
场景:一般用在开发和测试中。因为只能处理少量的数据
2.1.1 基于列表
# 导包import osfrom pyspark.sql import SparkSession# 绑定指定的python解释器os.environ['SPARK_HOME'] = '/export/server/spark'os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'# 创建main函数if __name__ == '__main__':# 1.创建SparkContext对象spark = SparkSession.builder.appName('pyspark_demo').master('local[*]').getOrCreate()# 2.创建DF对象data = [(1, '张三', 18), (2, '李四', 28), (3, '王五', 38)]df1 = spark.createDataFrame(data,schema=['id','name','age'])# 展示数据df1.show()# 查看结构信息df1.printSchema()print('---------------------------------------------------------')df2 = spark.createDataFrame(data,schema='id int,name string,age int')# 展示数据df2.show()# 查看结构信息df2.printSchema()print('---------------------------------------------------------')df3 = spark.createDataFrame(data,schema='id:int,name:string,age:int')# 展示数据df3.show()# 查看结构信息df3.printSchema()# 3.关闭资源spark.stop()
2.1.2 基于RDD普通方式
场景:RDD可以存储任意结构的数据;而DataFrame只能处理二维表数据。在使用Spark处理数据的初期,可能输入进来的数据是半结构化或者是非结构化的数据,那么可以先通过RDD对数据进行ETL处理成结构化数据,再使用开发效率高的SparkSQL来对后续数据进行处理分析。
Schema选择StructType对象来定义DataFrame的“表结构”转换RDD
# 导包import osfrom pyspark.sql import SparkSession# 绑定指定的python解释器from pyspark.sql.types import StructType, StringType, StructFieldos.environ['SPARK_HOME'] = '/export/server/spark'os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'# 创建main函数if __name__ == '__main__':# 1.创建SparkContext对象spark = SparkSession.builder.appName('pyspark_demo').master('local[*]').getOrCreate()sc = spark.sparkContext# 2.读取生成rddtextRDD = sc.textFile('file:///export/data/spark_project/spark_sql/data/data1.txt')print(type(textRDD)) # <class 'pyspark.rdd.RDD'>etlRDD = textRDD.map(lambda line:line.split(',')).map(lambda l:(l[0],l[1]))# 3.定义schema结构信息schema1 = StructType().add('name',StringType(),True).add('age',StringType(),True)schema2 = StructType([StructField('name',StringType(),True),StructField('age',StringType(),True)])schema3 = ['name','age']schema4 = 'name string,age string'schema5 = 'name:string,age:string'# 4.创建DF对象dfpeople = spark.createDataFrame(etlRDD,schema5)# 5.df展示结构信息dfpeople.show()dfpeople.printSchema()# 6.拓展: 创建临时视图,方便sql查询dfpeople.createTempView('peoples')r = spark.sql('select * from peoples')r.show()# 7.关闭资源sc.stop()spark.stop()
2.1.3 基于RDD反射方式
Schema使用反射方法来推断Schema模式Spark SQL 可以将 Row 对象的 RDD 转换为 DataFrame,从而推断数据类型。
# 导包import osfrom pyspark.sql import SparkSession# 绑定指定的python解释器from pyspark.sql.types import StructType, StringType, StructField, Rowos.environ['SPARK_HOME'] = '/export/server/spark'os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'# 创建main函数if __name__ == '__main__':# 1.创建SparkContext对象spark = SparkSession.builder.appName('pyspark_demo').master('local[*]').getOrCreate()sc = spark.sparkContext# 2.读取生成rdd# 3.定义schema结构信息textRDD = sc.textFile('file:///export/data/spark_project/spark_sql/data/data1.txt')etlRDD_schema = textRDD.map(lambda line:line.split(',')).map(lambda l:Row(name=l[0],age=l[1]))# 4.创建DF对象dfpeople = spark.createDataFrame(etlRDD_schema)# 5.df展示结构信息dfpeople.show()dfpeople.printSchema()# 6.拓展: 创建临时视图,方便sql查询dfpeople.createTempView('peoples')r = spark.sql('select * from peoples')r.show()# 7.关闭资源sc.stop()spark.stop()
2.2 toDF()创建
schema模式编码在字符串中,toDF参数用于指定列的名字。如果你不指定列的名字,那么默认的列的名字会是_1, _2等等。
# 导包import osfrom pyspark.sql import SparkSession# 绑定指定的python解释器from pyspark.sql.types import StructType, StringType, StructField, Rowos.environ['SPARK_HOME'] = '/export/server/spark'os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'# 创建main函数if __name__ == '__main__':# 1.创建SparkContext对象spark = SparkSession.builder.appName('pyspark_demo').master('local[*]').getOrCreate()sc = spark.sparkContext# 2.读取生成rdd# 3.定义schema结构信息textRDD = sc.textFile('file:///export/data/spark_project/spark_sql/data/data1.txt')etlRDD = textRDD.map(lambda line:line.split(','))# 4.创建DF对象dfpeople = etlRDD.toDF(['name','age'])# 5.df展示结构信息dfpeople.show()dfpeople.printSchema()# 6.拓展: 创建临时视图,方便sql查询dfpeople.createTempView('peoples')r = spark.sql('select * from peoples')r.show()# 7.关闭资源sc.stop()spark.stop()
2.3 read读取外部文件
复杂API
统一API格式: spark.read.format('text|csv|json|parquet|orc|avro|jdbc|.....') # 读取外部文件的方式.option('k','v') # 选项 可以设置相关的参数 (可选).schema(StructType | String) # 设置表的结构信息.load('加载数据路径') # 读取外部文件的路径, 支持 HDFS 也支持本地
简写API
请注意: 以上所有的外部读取方式,都有简单的写法。spark内置了一些常用的读取方案的简写格式: spark.read.读取方式()例如: df = spark.read.csv(path='file:///export/data/_03_spark_sql/data/stu.txt',header=True,sep=' ',inferSchema=True,encoding='utf-8',)
2.3.1 Text方式读取
text方式读取文件:1- 不管文件中内容是什么样的,text会将所有内容全部放到一个列中处理2- 默认生成的列名叫value,数据类型string3- 只能够在schema中修改字段value的名称,其他任何内容不能修改
# 导包import osfrom pyspark.sql import SparkSession# 绑定指定的python解释器from pyspark.sql.types import StructType, StringType, StructField, Rowos.environ['SPARK_HOME'] = '/export/server/spark'os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'# 创建main函数if __name__ == '__main__':# 1.创建SparkContext对象spark = SparkSession.builder.appName('pyspark_demo').master('local[*]').getOrCreate()# 2.读取数据# 注意: 读取text文件默认只有1列,且列名交value,可以通过schema修改df = spark.read\.format('text')\.schema('info string')\.load('file:///export/data/spark_project/spark_sql/data/data1.txt')# 5.df展示结构信息df.show()df.printSchema()# 6.拓展: 创建临时视图,方便sql查询df.createTempView('peoples')r = spark.sql('select * from peoples')r.show()# 6.关闭资源spark.stop()
2.3.2 CSV方式读取
csv格式读取外部文件:1- 复杂API和简写API都必须掌握2- 相关参数作用说明:2.1- path:指定读取的文件路径。支持HDFS和本地文件路径2.2- schema:手动指定元数据信息2.3- sep:指定字段间的分隔符2.4- encoding:指定文件的编码方式2.5- header:指定文件中的第一行是否是字段名称2.6- inferSchema:根据数据内容自动推断数据类型。但是,推断结果可能不精确
# 导包import osfrom pyspark.sql import SparkSession# 绑定指定的python解释器from pyspark.sql.types import StructType, StringType, StructField, Rowos.environ['SPARK_HOME'] = '/export/server/spark'os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'# 创建main函数if __name__ == '__main__':# 1.创建SparkContext对象spark = SparkSession.builder.appName('pyspark_demo').master('local[*]').getOrCreate()# 2.读取数据# 注意: csv文件可以识别多个列,可以使用schema指定列名,类型# 原始方式# df = spark.read\# .format('csv')\# .schema('name string,age int')\# .option('sep',',')\# .option('encoding','utf8')\# .option('header',False)\# .load('file:///export/data/spark_project/spark_sql/data/data1.txt')# 简化方式df = spark.read.csv(schema='name string,age int',sep=',',encoding='utf8',header=False,path='file:///export/data/spark_project/spark_sql/data/data1.txt')# 5.df展示结构信息df.show()df.printSchema()# 6.拓展: 创建临时视图,方便sql查询df.createTempView('peoples')r = spark.sql('select * from peoples')r.show()# 7.关闭资源spark.stop()
2.3.3 JSON方式读取
json读取数据:1- 需要手动指定schema信息。如果手动指定的时候,字段名称与json中的key名称不一致,会解析不成功,以null值填充2- csv/json中schema的结构,如果是字符串类型,那么字段名称和字段数据类型间,只能以空格分隔
json的数据内容
{'id': 1,'name': '张三','age': 20}{'id': 2,'name': '李四','age': 23,'address': '北京'}{'id': 3,'name': '王五','age': 25}{'id': 4,'name': '赵六','age': 29}
代码实现
# 导包import osfrom pyspark.sql import SparkSession# 绑定指定的python解释器from pyspark.sql.types import StructType, StringType, StructField, Rowos.environ['SPARK_HOME'] = '/export/server/spark'os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'# 创建main函数if __name__ == '__main__':# 1.创建SparkContext对象spark = SparkSession.builder.appName('pyspark_demo').master('local[*]').getOrCreate()# 2.读取数据# 注意: json的key和schema指定的字段名不一致,会用null补充,如果没有数据也是用null补充# 简化方式df = spark.read.json(schema='id int,name string,age int,address string',encoding='utf8',path='file:///export/data/spark_project/spark_sql/data/data2.txt')# 5.df展示结构信息df.show()df.printSchema()# 6.拓展: 创建临时视图,方便sql查询df.createTempView('peoples')r = spark.sql('select * from peoples')r.show()# 关闭资源spark.stop()
相关文章:
摸鱼大数据——Spark SQL——DataFrame详解一
1.DataFrame基本介绍 DataFrame表示的是一个二维的表。二维表,必然存在行、列等表结构描述信息表结构描述信息(元数据Schema): StructType对象字段: StructField对象,可以描述字段名称、字段数据类型、是否可以为空行: Row对象列: Column对象ÿ…...

【Java探索之旅】初识多态_概念_实现条件
文章目录 📑前言一、多态1.1 概念1.2 多态的实现条件 🌤️全篇总结 📑前言 多态作为面向对象编程中的重要概念,为我们提供了一种灵活而强大的编程方式。通过多态,同一种操作可以应用于不同的对象,并根据对象…...

[Day 26] 區塊鏈與人工智能的聯動應用:理論、技術與實踐
數據科學與AI的整合應用 數據科學(Data Science)和人工智能(AI)在現代技術世界中扮演著至關重要的角色。兩者的整合應用能夠為企業和研究人員提供強大的工具,以更好地理解、預測和解決各種複雜的問題。本文將深入探討…...

算法 —— 滑动窗口
目录 长度最小的子数组 无重复字符的最长子串 最大连续1的个数 将x减到0的最小操作数 找到字符串中所有字母异位词 最小覆盖子串 长度最小的子数组 sum比target小就进窗口,sum比target大就出窗口,由于数组是正数,所以相加会使sum变大&…...
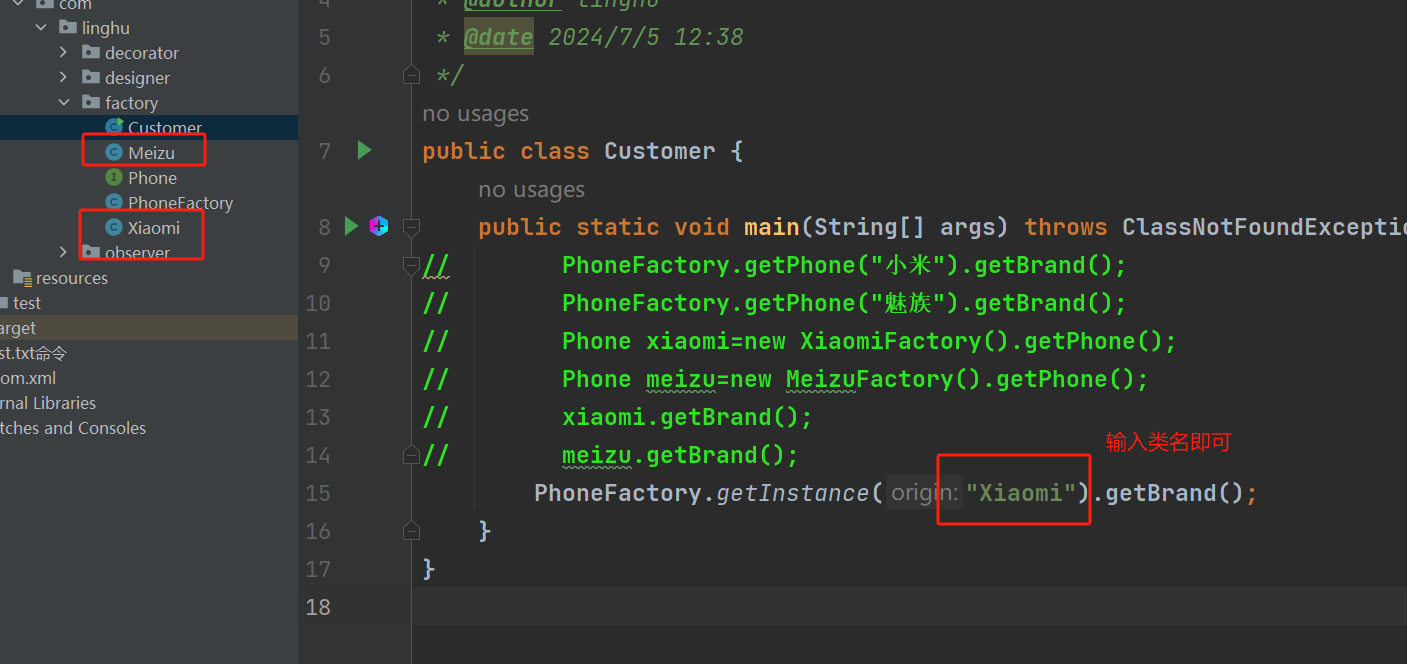
【设计模式】工厂模式(定义 | 特点 | Demo入门讲解)
文章目录 定义简单工厂模式案例 | 代码Phone顶层接口设计Meizu品牌类Xiaomi品牌类PhoneFactory工厂类Customer 消费者类 工厂方法模式案例 | 代码PhoneFactory工厂类 Java高级特性---工厂模式与反射的高阶玩法方案:反射工厂模式 总结 其实工厂模式就是用一个代理类帮…...

Linux之计划和日志
计划任务 计划任务概念解析 在Linux操作系统中,除了用户即时执行的命令操作以外,还可以配置在指定的时间、指定的日期执行预先计划好的系统管理任务(如定期备份、定期采集监测数据)。通过安装at和crontabs这两个系统服务实现一次性、周期性计划任务的功能,并分别通过at、…...

C++ 多态篇
文章目录 1. 多态的概念和实现1.1 概念1.2 实现1.2.1 协变1.2.2 析构函数1.2.3 子类虚函数不加virtual 2. C11 final和override3.1 final3.2 override 3. 函数重载、重写与隐藏4. 多态的原理5. 抽象类6.单继承和多继承的虚表6.1 单继承6.2 多继承 7. 菱形继承的虚表(了解)7.1 菱…...

【LVGL-SquareLine Studio】
LVGL-SquareLine Studio ■ SquareLine Studio-官网下载地址■ SquareLine Studio-参考博客■ SquareLine Studio-安装■ SquareLine Studio-汉化■ SquareLine Studio-■ SquareLine Studio-■ SquareLine Studio-■ SquareLine Studio-■ SquareLine Studio- ■ SquareLine S…...

mysqli 与mysql 区别和联系, 举例说明
mysqli是一种PHP的扩展,用于与MySQL数据库进行交互。它提供了一套面向对象的接口,可以更方便地操作数据库。MySQL是一种关系型数据库管理系统,用于存储和管理数据。 区别: mysqli是MySQL的扩展,而不是单独的数据库管…...

【SpringCloud应用框架】Nacos安装和服务提供者注册
第二章 Spring Cloud Alibaba Nacos之Nacos安装和服务提供者注册 文章目录 Nacos介绍为何使用Nacos?一、Nacos下载和安装1. 下载2. 安装Linux/Unix/MacWindows 二、Nacos服务提供者注册1. Nacos代替Eureka2. Nacos服务注册中心3. 引入Nacos Discovery进行服务注册/发…...
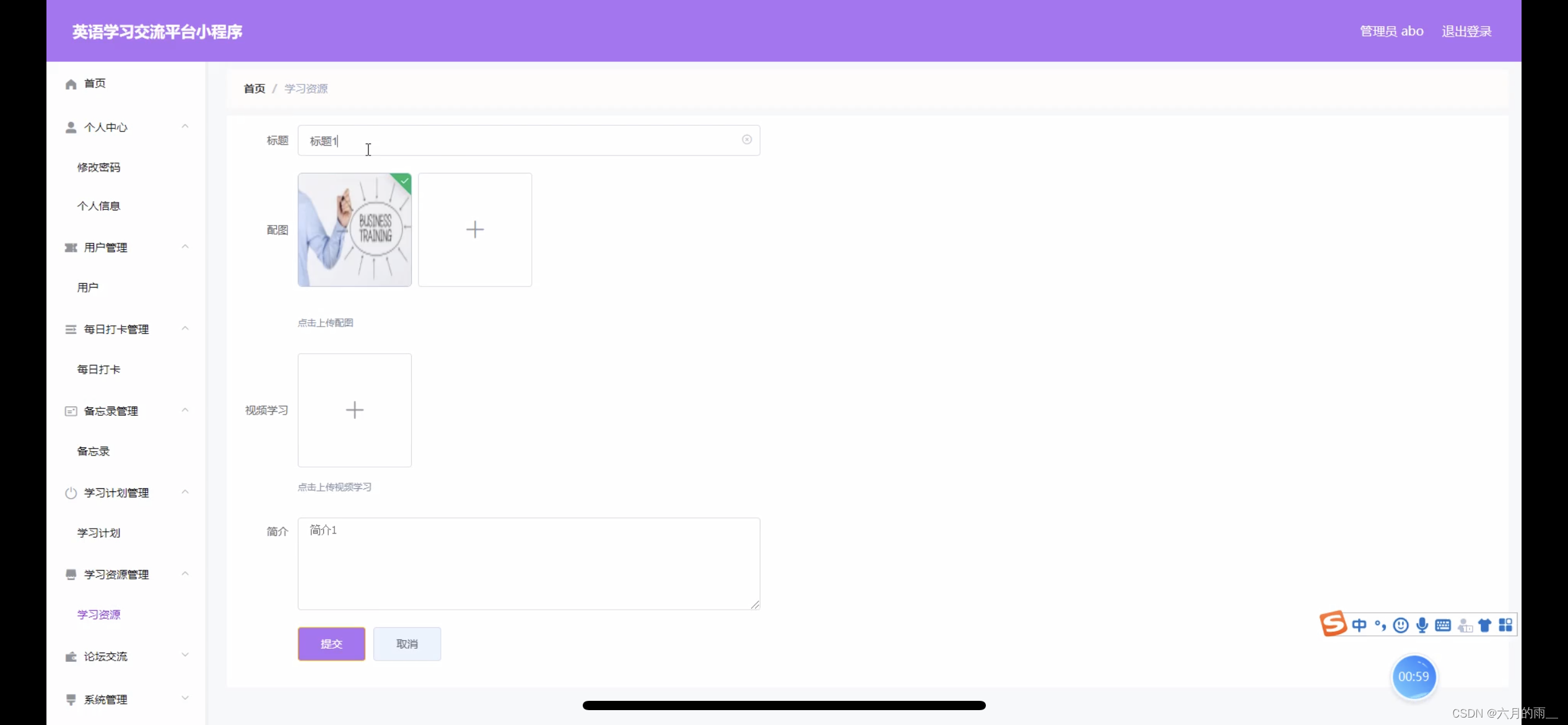
英语学习交流小程序的设计
管理员账户功能包括:系统首页,个人中心,用户管理,每日打卡管理,备忘录管理,学习计划管理,学习资源管理,论坛交流 微信端账号功能包括:系统首页,学习资源&…...

实现Java多线程中的线程间通信
实现Java多线程中的线程间通信 大家好,我是微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿! 1. 线程间通信的基本概念 在线程编程中,线程间通信是指多个线程之间通过共享内存或消息传递的方式进行交…...

C++模板元编程(一)——可变参数模板
这个系列主要记录C模板元编程的常用语法 文章目录 引言语法应用函数模板可变参数的打印可变参数的最小/最大函数 类模板 参考文献 引言 在C11之前,函数模板和类模板只支持含有固定数量的模板参数。C11增强了模板功能,允许模板定义中包含任意个(包括0个)…...

kafka中
Kafka RocketMQ概述 RabbitMQ概述 ActiveMQ概述 ZeroMQ概述 MQ对比选型 适用场景-从公司基础建设力量角度出发 适用场景-从业务场景出发 Kafka配置介绍 运行Kafka 安装ELAK 配置EFAK EFAK界面 KAFKA常用术语 Kafka常用指令 Kafka中消息读取 单播消息 group.id 相同 多播消息 g…...

Android 获取当前电池状态
在 API 级别 23 上获取充电状态 要在 API 级别 23 上获取电池的当前状态,只需使用电池管理器系统服务: BatteryManager batteryManager (BatteryManager) getSystemService(BATTERY_SERVICE); boolean isCharging batteryManager.isCharging();使用 S…...

【JVM 的内存模型】
1. JVM内存模型 下图为JVM内存结构模型: 两种执行方式: 解释执行:JVM是由C语言编写的,其中有C解释器,负责先将Java语言解释翻译为C语言。缺点是经过一次JVM翻译,速度慢一点。JIT执行:JIT编译器…...

【雷丰阳-谷粒商城 】【分布式高级篇-微服务架构篇】【17】认证服务01—短信/邮件/异常/MD5
持续学习&持续更新中… 守破离 【雷丰阳-谷粒商城 】【分布式高级篇-微服务架构篇】【17】认证服务01 环境搭建验证码倒计时短信服务邮件服务验证码短信形式:邮件形式: 异常机制MD5参考 环境搭建 C:\Windows\System32\drivers\etc\hosts 192.168.…...

geom buffer制作
1. auto buffer_geom line_string->buffer(15);//buffer //这个是x和y各扩大段15个单位 auto buffer_geom line_string->buffer(15);//buffer //这个是x和y各扩大段15米 获取buffer坐标 auto boundary buffer_geom->getBoundary(); auto boundary_coords boun…...
微软正在放弃React
最近,微软Edge团队撰写了一篇文章,介绍了微软团队如何努力提升Edge浏览器的性能。但在文中,微软对React提出了批评,并宣布他们将不再在Edge浏览器的开发中使用React。 我将详细解析他们的整篇文章内容,探讨这一决定对…...

U盘非安全退出后的格式化危机与高效恢复策略
在数字化时代,U盘作为数据存储与传输的重要工具,其数据安全备受关注。然而,一个常见的操作失误——U盘没有安全退出便直接拔出,随后再插入时却遭遇“需要格式化”的提示,这不仅让用户措手不及,更可能意味着…...

Unity Il2CppDumper原理与实战:解析元数据与二进制对齐
1. 这不是“破解工具”,而是Unity开发者该懂的二进制真相课 你刚在Unity Asset Store下载了一个功能惊艳的插件,却在打包iOS后发现部分逻辑失效;或者接手一个没有源码的旧项目,只有一堆 .dll 和 .so 文件,连主入口…...

从‘文件夹’到对象列表:手把手教你用MinIO Java Client实现灵活的文件查询与过滤
从‘文件夹’到对象列表:手把手教你用MinIO Java Client实现灵活的文件查询与过滤在当今数据驱动的时代,对象存储已成为现代应用架构中不可或缺的一部分。MinIO作为高性能、兼容S3协议的开源对象存储解决方案,凭借其轻量级和易用性赢得了众多…...

适合地产人用的中介房源管理系统
在房产经纪行业,房源管理与客源管理是经纪人日常工作的核心,直接影响业务效率与成交转化。选择一套适配行业需求的中介房源管理系统,能帮助中介团队规范流程、降低运营成本、大幅提升业绩。今天我们以客观视角,详细解析全房源系统…...

销售怎么通过各种方法获取电话号码
第一种就是那个用爬虫电话号码,然后再打电话给客户。第二种是在别人的挪车电话看车挪车电话,然后再打电话找客户。第三就是。扫楼一顿顿的扫,第四就是这个那种商店,一个个的去问陌拜地推一个个的问店子要不要贷款,去问…...

基于ESP32的AIS转WiFi转换器:实现NMEA 0183数据无线传输
1. 项目概述:从VHF-AIS接收器到iPad的无线桥梁作为一名经常在海上折腾电子设备的航海爱好者,我最近遇到了一个挺实际的需求:我的主力导航设备是iPad上的iSailor应用,它功能强大、界面友好,但有个“硬伤”——它需要通过…...

Keil µVision链接器错误204解决方案
1. 问题现象与背景解析最近在使用Keil Vision进行嵌入式开发时,不少工程师遇到了一个令人头疼的链接器错误。具体表现为编译时出现"FATAL ERROR 204: INVALID KEYWORD"的致命错误,错误位置指向链接器控制文件中的特定行。这个问题在C166和C51两…...

OpenIPC开源固件:5分钟解锁网络摄像头的终极控制权
OpenIPC开源固件:5分钟解锁网络摄像头的终极控制权 【免费下载链接】firmware Alternative IP Camera firmware from an open community 项目地址: https://gitcode.com/gh_mirrors/fir/firmware 还在为网络摄像头的封闭系统而烦恼吗?想要完全掌控…...
)
Unity3D深度纹理实战:手把手教你实现可交互的激光雷达扫描特效(附完整C#/Shader代码)
Unity3D深度纹理实战:手把手教你实现可交互的激光雷达扫描特效(附完整C#/Shader代码)在科幻题材的游戏开发中,激光雷达扫描特效是营造科技感的经典元素。从《赛博朋克2077》的战术目镜到《看门狗》的环境扫描,这种动态…...

Git Bash 中无法启动 Claude Code ?
最近需要在 git bash 中跑 Claude Code 。git bash 是随 git for windows 套件安装的,很久没更新了,结果启动 Claude Code 报错:Warning: no stdin data received in 3s, proceeding without it. If piping from a slow command, redirect st…...

2026数据治理平台选型:五款产品如何赋能数据中台建设?
一、引言:数据中台的成败,关键在治理在数字化浪潮的席卷下,“数据中台”已成为当代企业信息化架构中的核心战略组件。然而,一个悖论正困扰着大量企业:数据中台的基础设施搭建日趋完善,但真正将数据转化为业…...