【Linux进阶】文件系统5——ext2文件系统(inode)
1.再谈inode
(1) 理解inode,要从文件储存说起。
文件储存在硬盘上,硬盘的最小存储单位叫做"扇区"(Sector)。每个扇区储存512字节(相当于0.5KB)。操作系统读取硬盘的时候,不会一个个扇区地读取,这样效率太低,而是一次性连续读取多个扇区,即一次性读取一个"块"(block)。这种由多个扇区组成的"块",是文件存取的最小单位。“块"的大小,最常见的是4KB,即连续八个 sector组成一个 block。
(2) 通常情况下,文件系统会将文件的实际内容和属性分开存放:
- 文件的属性保存在 inode 中(i 节点)中,每个 inode 都有自己的编号。每个文件各占用一个 inode。不仅如此,inode 中还记录着文件数据所在 block 块的编号;
- 文件的实际内容保存在 data block 中(数据块),类似衣柜的隔断,用来真正保存衣物。每个 block 都有属于自己的编号。当文件太大时,可能会占用多个 block 块。
如图所示:文件系统先格式化出 inode 和 block 块,假设某文件的权限和属性信息存放到 inode 4 号位置,这个 inode 记录了实际存储文件数据的 block 号有 4 个,分别为 2、7、13、15,由此,操作系统就能快速地找到文件数据的存储位置。

note:
每个inode都有一个号码,操作系统用inode号码来识别不同的文件。
Unix/Linux系统内部不使用文件名,而使用inode号码来识别文件。对于系统来说,文件名只是inode号码便于识别的别称或者绰号。
表面上,用户通过文件名,打开文件。
实际上,系统内部这个过程分成三步:
- 首先,系统找到这个文件名对应的inode号码;
- 其次,通过inode号码,获取inode信息;
- 最后,根据inode信息,分析 inode 所记录的权限与用户是否符合,找到文件数据所在的block,读出数据。
(3) 联系平时实践,大家格式化硬盘(U盘)时发现有:快速格式化和底层格式化。快速格式化非常快,格式化一个32GB的U盘只要1秒钟,普通格式化格式化速度慢。这两个的差异?
其实快速格式化就是只删除了U盘中的硬盘内容管理表(其实就是inode),真正存储的内容没有动。这种格式化的内容是有可能被找回的。
由于inode也占用一定的磁盘空间,所以当inode使用空间用完的时候,即使磁盘仍有存储空间也无法使用!所有当磁盘显示仍有可用空间,但使用时却提示空间不足,就有可能是inode使用完毕所造成的。
(4) inode本质上是一个结构体,定义如下
struct inode {struct hlist_node i_hash; /* 哈希表 */struct list_head i_list; /* 索引节点链表 */struct list_head i_dentry; /* 目录项链表 */unsigned long i_ino; /* 节点号 */atomic_t i_count; /* 引用记数 */umode_t i_mode; /* 访问权限控制 */unsigned int i_nlink; /* 硬链接数 */uid_t i_uid; /* 使用者id */gid_t i_gid; /* 使用者id组 */kdev_t i_rdev; /* 实设备标识符 */loff_t i_size; /* 以字节为单位的文件大小 */struct timespec i_atime; /* 最后访问时间 */struct timespec i_mtime; /* 最后修改(modify)时间 */struct timespec i_ctime; /* 最后改变(change)时间 */unsigned int i_blkbits; /* 以位为单位的块大小 */unsigned long i_blksize; /* 以字节为单位的块大小 */unsigned long i_version; /* 版本号 */unsigned long i_blocks; /* 文件的块数 */unsigned short i_bytes; /* 使用的字节数 */spinlock_t i_lock; /* 自旋锁 */struct rw_semaphore i_alloc_sem; /* 索引节点信号量 */struct inode_operations *i_op; /* 索引节点操作表 */struct file_operations *i_fop; /* 默认的索引节点操作 */struct super_block *i_sb; /* 相关的超级块 */struct file_lock *i_flock; /* 文件锁链表 */struct address_space *i_mapping; /* 相关的地址映射 */struct address_space i_data; /* 设备地址映射 */struct dquot *i_dquot[MAXQUOTAS]; /* 节点的磁盘限额 */struct list_head i_devices; /* 块设备链表 */struct pipe_inode_info *i_pipe; /* 管道信息 */struct block_device *i_bdev; /* 块设备驱动 */unsigned long i_dnotify_mask; /* 目录通知掩码 */struct dnotify_struct *i_dnotify; /* 目录通知 */unsigned long i_state; /* 状态标志 */unsigned long dirtied_when; /* 首次修改时间 */unsigned int i_flags; /* 文件系统标志 */unsigned char i_sock; /* 可能是个套接字吧 */atomic_t i_writecount; /* 写者记数 */void *i_security; /* 安全模块 */__u32 i_generation; /* 索引节点版本号 */union {void *generic_ip; /* 文件特殊信息 */} u;
};可以用stat命令,查看某个文件的inode信息:

(5)其他
- 每个 inode 大小均固定为 128 bytes;
- 每个文件都仅会占用一个 inode ;
- 承上,因此文件系统能够创建的文件数量与 inode 的数量有关;
2.ext2文件系统
Linux的文件除了原有的数据内容外,还含有非常多的权限与属性,这些权限与属性是为了保护每个用户所拥有数据的隐密性,而我们知道文件系统里面可能含有的inode、数据区块、超级区块等。为什么要谈这个?
因为标准的ext2就是使用这种inode为基础的Linux 文件系统。
通常情况下,文件系统会将文件的实际内容和属性分开存放:
- 文件的属性保存在 inode 中(i 节点)中,每个 inode 都有自己的编号。每个文件各占用一个 inode。不仅如此,inode 中还记录着文件数据所在 block 块的编号;
- 文件的实际内容保存在 data block 中(数据块),类似衣柜的隔断,用来真正保存衣物。每个 block 都有属于自己的编号。当文件太大时,可能会占用多个 block 块。
而且文件系统一开始就将inode 与数据区块规划好了,除非重新格式化(或利用resize2fs 等命令修改其大小),否则 inode 与数据区块固定后就不再变动。
但是如果仔细考虑一下,如果我的文件系统高达数百GB时,那么将所有的inode与数据区块通通放置在一起将是很不明智的决定,因为inode与数据区块的数量太庞大,不容易管理。
因此,ext2文件系统格式化的时候基本上是区分为多个区块群组(block group),每个区块群组
都有独立的inode、数据区块、超级区块系统。
感觉上就好像我们在当兵时,一个营分成数个连,每个连有自己的联络系统,但最终都向营部汇报信息一样,这样分成一群群的比较好管理。整个来说,ext2格式化后有点像下面这样:
在整体的规划当中,文件系统最前面有一个启动扇区(boot sector),这个启动扇区可以安装启动引导程序,这是个非常重要的设计,因为如此一来我们就能够将不同的启动引导程序安装到别的文件系统最前端,而不用覆盖整块磁盘唯一的MBR,这样也才能够制作出多重引导的环境。

至于每一个区块群组(blockgroup)的六个主要内容如下:
2.1.数据区块(data block)
数据区块是用来放置文件数据地方,在ext2文件系统中所支持的区块大小有1K、2K及4K三种。
在格式化时区块的大小就固定了,且每个区块都有编号,以方便inode的记录。
不过要注意的是,区块大小的差异,会导致该文件系统能够支持的最大磁盘容量与最大单一文件容量并不相同,因为区块大小而产生的ext2文件系统限制如下
Bolck大小 1KB 2KB 4KB 最大单一文件限制 16GB 256GB 2TB 最大文件系统总容量 2TB 8TB 16TB
你需要注意的是,虽然ext2已经能够支持大于2GB以上的单一文件容量,不过某些应用程序依然使用旧的限制,也就是说,某些程序只能够识别小于2GB以下的文件而已,这就跟文件系统无关了。
举例来说,有一个图片编辑软件称为PAVE,这个软件就无法识别在数值模型仿真后产生的大于2GB以上的文件,所以后来只能找更新的软件来替换它。
除此之外ext2文件系统的区块还有什么限制?
有的,基本限制如下:
- 原则上,区块的大小与数量在格式化完就不能够再修改(除非重新格式化);
- 每个区块内最多只能够放置一个文件的数据;
- 承上,如果文件大于区块的大小,则一个文件会占用多个区块数量
- 承上,若文件小于区块,则该区块的剩余容量就不能够再被使用了(磁盘空间会浪费)。
如上第四点所说,由于每个区块仅能容纳一个文件的数据,因此如果你的文件都非常小,但是你的区块在格式化时却使用4K大小时,可能会产生一些空间的浪费。
我们以下面的一个简单例题来算一下空间的浪费吧!
例题
假设你的ext2文件系统使用4K区块,而该文件系统中有10000个小文件,每个文件大小均为50B,请问此时你的磁盘浪费多少容量?答:由于ext2文件系统中一个区块仅能容纳一个文件,因此每个区块会浪费4096-50=4046(字节),系统中总共有一万个小文件,所有文件容量为:50(B)×10000=488.3KB,但此时浪费的容量为:4046(B)×10000=38.6MB 。
想一想,不到1MB的总文件容量却浪费将近40MB的空间,且文件越多将造成越多的磁盘空间浪费。
什么情况会产生上述的状况?
例如 BBS网站的数据。如果 BBS上面的数据使用的是纯文本文件来记录每篇留言,而留言内容如果都写上【如题】时,想一想,是否就会产生很多小文件?
好,既然大的区块可能会产生较严重的磁盘容量浪费,那么我们是否就将区块大小设置为1K即可?
这也不妥,因为如果区块较小的话,那么大型文件将会占用数量更多的区块,而inode也要记录更多的区块号码,此时将可能造成文件系统读写性能不佳。
所以我们可以说,在您进行文件系统的格式化之前,请先想好该文件系统预计使用的情况。以鸟哥来说,我的数值模型仿真平台随便一个文件都好几百MB,那么区块容量当然选择较大的,至少文件系统就不必记录太多的区块号码,读写起来也比较方便。
事实上,现在的磁盘容量都太大了,所以,大概大家都只会选择4K的区块大小吧
2.2.inode table(inode表)
再来讨论一下inode 这个玩意儿吧!
如前所述inode的内容在记录文件的属性以及该文件实际数据是放置在哪几个区块内,基本上,inode 记录的数据至少有下面这些:
- 该文件的读写属性(read、write、excute)
- 该文件的拥有者与用户组(owner、group);
- 该文件的大小;
- 该文件建立或状态改变的时间(ctime);
- 最近一次的读取时间(aumle7,
- 最近修改的时间(mtime);
- 定义文件特性的标识(flag),如 SetUID;
- 该文件真正内容的指向(pointer);
inode的数量与大小也是在格式化时就已经固定了,除此之外inode 还有些什么特色?
- 每个inode 大小均固定为128B(新的ext4与xfS可设置到256B);
- 每个文件都仅会占用一个inode而已,因此文件系统能够建立的文件数量与inode 的数量有关;
- 系统读取文件时需要先找到inode,并分析inode所记录的权限与用户是否符合,若符合才能够读取区块的内容。
我们约略来分析一下ext2的inode、数据区块与文件大小的关系。
inode 要记录的数据非常多但偏偏又只有128B而已,而 inode 记录一个数据区块要使用4B,假设一个文件有400MB且每个区块为4K时,那么至少也要十万个区块的记录。inode哪有这么多可记录的信息?
为此我们的系统很聪明地将inode 记录区块号码的区域定义为12个直接、一个间接、一个双间接与一个三间接记录区。这是什么?
- 所谓“直接块”,是指该块直接用来存储文件的数据,
- 而“一次间接块”是指该块不存 储数据,而是存储直接块的地址,
- 同样,“二次间接块”存储的是“一次间接块”的地址。 这里所说的块,指的都是物理块。
我们将inode的结构图绘制出来看一下。

上图最左边为inode本身(128B),里面有12个直接指向区块号码的对照,这12条记录就能够直接取得区块号码。
至于所谓的间接就是再拿一个区块来当作记录区块号码的记录区,如果文件太大,就会使用间接的区块来记录编号。如图7.1.4所示,间接只是拿一个区块来记录额外的号码而已。
同理,如果文件持续变大,那么就会利用所谓的双间接,第一个区块仅再指出下一个记录编号的区块在那里,实际记录的在第二个区块当中。依此类推,三间接就是利用第三层区块来记录编号。
这样子inode 能够指定多少个区块?我们以较小的1K区块来说明,可以指定的情况如下:
- 12个直接指向:12×1K=12K
由于是直接指向,所以总共可记录12条记录,因此总额大小为如上所示;
- 间接:256×1K=256 K
每条区块号码的记录会使用4B,因此1K的大小能够记录256条记录,因此一个间接可以记录的
文件大小如上;
- 双间接:256×256×1K=256x256 k
第一层区块会指定256个第二层,每个第二层可以指定256个号码,因此总额大小如上;
- 三间接:256×256×256×1K=256x256x256 K
第一层区块会指定256个第二层,每个第二层可以指定256个第三层,每个第三层可以指定256
个号码,因此总额大小如上;
- 总额:将直接、间接、双间接、三间接相加,得到12+256+256×256+256×256×256(K)= 16GB;
此时我们知道当文件系统将区块格式化为1K大小时,能够容纳的最大文件为16GB,比较一下文件系统限制表的结果可发现是一致的。
但这个方法不能用在2K及4K区块大小的计算中,因为大于2K的区块将会受到ext2文件系统本身的限制,所以计算的结果会不太符合。
2.3.Superblock(超级区块)
超级区块是记录整个文件系统相关信息的地方,没有超级区块,就没有这个文件系统,它记录的
信息主要有:
- 数据区块与inode的总量;
- 未使用与已使用的inode与数据区块 数量;
- 数据区块与inode 的大小(block为1、2、4K, inode为128B或256B);
- 文件系统的挂载时间、最近一次写入数据的时间、最近一次检验磁盘(fSck)的时间等文件系统的相关信息;
- 一个有效位数值,若此文件系统已被挂载,则有效位为0,若未被挂载,则有效位为1;
超级区块非常的重要,因为我们这个文件系统的基本信息都存储在这里,因此,如果超级区块损坏,你的文件系统可能就需要花费很多时间去恢复。
一般来说,超级区块的大小为1024B。相关的超级区块信息,我们等一下会使用dumpe2fs命令做说明。
此外,每个区块群组(block group)都可能含有超级区块。但是我们也说一个文件系统应该仅有一个超级区块而已,那是怎么回事?
事实上除了第一个区块群组内会含有超级区块之外,后续的区块群组不一定含有超级区块,而若含有超级区块则该超级区块主要是做为第一个区块群组内超级区块的备份,这样可以进行超级区块的恢复。
2.4.Filesystem Description(文件系统描述说明)
这个区段可以描述每个区块群组的开始与结束的区块,以及说明每个区段(超级区块、对照表、
inode 对照表、数据区块)分别介于哪一个区块之间,这部分也能够用dumpe2fs来观察。
2.5.区块对照表(block bitmap)
新增文件时总会用到区块,那你要使用哪个区块来记录?
当然是选择空区块来记录新文件的数据。
那你怎么知道哪个区块是空的呢?
这就要通过区块对照表的辅助了。从区块对照表当中可以知道哪些区块是空的,因此我们的系统就能够很快速地找到可使用的空间来处理文件。
同样,如果你删除某些文件时,那么那些文件原本占用的区块号码就要释放出来,此时在区块对照表当中对应到该区块号码的标志就要修改成为【未使用中】,这就是对照表的功能。
2.5. inode 对照表(inode bitmap)
这个其实与区块对照表的功能类似,只是区块对照表记录的是使用与未使用的区块号码,inode对照表则是记录使用与未使用的inode号码。
3.dumpe2fs:查询ext系统超级区块信息的命令
了解文件系统之后,我们可以使用dumpe2fs 显示ext2、ext3、ext4文件系统的超级快和块组信息。此命令的适用范围:RedHat、RHEL、Ubuntu、CentOS、SUSE、openSUSE、Fedora。,此命令的基本格式如下:
[root@CncLucZK ~]# dumpe2fs [ -bfhixV ] [ -o superblock=superblock ] [ -o blocksize=blocksize ] device

例如,通过 df 命令找到根目录硬盘的文件名,然后使用 dump2fs 命令观察文件系统的详细信息,执行命令如下:
[root@CncLucZK test]# df #查看目前挂载的装置
Filesystem 1K-blocks Used Available Use% Mounted on
devtmpfs 923060 0 923060 0% /dev
tmpfs 936488 40 936448 1% /dev/shm
tmpfs 936488 420 936068 1% /run
tmpfs 936488 0 936488 0% /sys/fs/cgroup
/dev/vda1 51539404 8826008 40516152 18% /
tmpfs 187296 0 187296 0% /run/user/0#devtmpfs 、tmpfs 、这些是硬盘的驱动程序 , /dev/vdal 是第一个分区,它的后面放了一个/boot是Linux的启动文件 .[root@CncLucZK test]# dumpe2fs /dev/vda1
dumpe2fs 1.45.6 (20-Mar-2020)
Filesystem volume name: <none> #文件系统的名称
Last mounted on: /
Filesystem UUID: 659e6f89-71fa-463d-842e-ccdf2c06e0fe
Filesystem magic number: 0xEF53
Filesystem revision #: 1 (dynamic)
Filesystem features: has_journal ext_attr resize_inode dir_index filetype needs_recovery extent 64bit flex_bg sparse_super large_file huge_file dir_nlink extra_isize metadata_csum
Filesystem flags: signed_directory_hash
Default mount options: user_xattr acl #默认挂载的参数
Filesystem state: clean #系统状态,健康
Errors behavior: Continue
Filesystem OS type: Linux
Inode count: 3276800 #Inode总数
Block count: 13106939 #Block总数
Reserved block count: 545215 #保留Block数
Free blocks: 10697434 #剩余可用blocks数
Free inodes: 3180547 #剩余可用inodes数
First block: 0
Block size: 4096 #Block大小
Fragment size: 4096 #碎片大小
Group descriptor size: 64 #组描述符大小
Reserved GDT blocks: 1017
Blocks per group: 32768
Fragments per group: 32768
Inodes per group: 8192
Inode blocks per group: 512
Flex block group size: 16
Filesystem created: Tue Nov 26 10:11:35 2019
Last mount time: Wed Oct 19 13:29:59 2022
Last write time: Wed Oct 19 13:29:56 2022
Mount count: 35
Maximum mount count: -1
Last checked: Tue Nov 26 10:11:35 2019
Check interval: 0 (<none>)
Lifetime writes: 1335 GB
Reserved blocks uid: 0 (user root)
Reserved blocks gid: 0 (group root)
First inode: 11
Inode size: 256
Required extra isize: 32
Desired extra isize: 32
Journal inode: 8
First orphan inode: 398263
Default directory hash: half_md4
Directory Hash Seed: d8b26e9a-4700-4c2b-8265-e64b94a85bfe
Journal backup: inode blocks
Checksum type: crc32c
Checksum: 0x519e5865
Journal features: journal_incompat_revoke journal_64bit journal_checksum_v3
Journal size: 64M
Journal length: 16384
Journal sequence: 0x00abc5b6
Journal start: 2066
Journal checksum type: crc32c
Journal checksum: 0xaa299391Group 0: (Blocks 0-32767) csum 0x925e [ITABLE_ZEROED] #第一个 data group 内容, 包含 block 的启始/结束号码Primary superblock at 0, Group descriptors at 1-7 #超级区块在 0 号 blockReserved GDT blocks at 8-1024Block bitmap at 1025 (+1025), csum 0x0aff0158Inode bitmap at 1041 (+1041), csum 0xd8b64b84Inode table at 1057-1568 (+1057) #inode table 所在的 block20474 free blocks, 259 free inodes, 1889 directories Free blocks: 10960-11035, 12362-12511, 12520-32767 #剩余未使用的 block 号码#剩余未使用的 inode 号码Free inodes: 1645, 5456-5664, 7507, 7509-7510, 7512, 7514, 7516-7554, 8062, 8080-8083
Group 1: (Blocks 32768-65535) csum 0xe744 [ITABLE_ZEROED] Backup superblock at 32768, Group descriptors at 32769-32775Reserved GDT blocks at 32776-33792Block bitmap at 1026 (bg #0 + 1026), csum 0xc9157de1Inode bitmap at 1042 (bg #0 + 1042), csum 0x6cc48e9fInode table at 1569-2080 (bg #0 + 1569)1 free blocks, 2825 free inodes, 1121 directories, 842 unused inodesFree blocks: 60080Free inodes: 8361-8368, 13523, 13528-13529, 13531, 13559-13908, 13911-14889, 14891-14902, 14907, 14910, 14912-14919, 14923-16384
...剩余输出信息都是data group 内容如上所示,利用dumpe2fs可以查询到非常多的信息,不过依内容主要可以划分为上半部分的超级区块内容,下半部分则是每个区块群组的信息。
从上面的表格中我们可以观察到这个/dev/vda1使用的区块为4K,第一个区块号码为0号,且区块群组内的所有信息都以区块的号码来表示,然后在超级区块中还有谈到目前这个文件系统的可用区块与inode数量。
至于区块群组的内容我们单纯看Group0信息好了,从上表中我们可以发现:
- Group0所占用的区块号码由0到32767,超级区块则在第0号的区块区块内;
- 文件系统描述说明在第1号区块中;
- 区块对照表与inode 对照表 则在129及145的区块中;
- 至于inode table分布于161-672的区块中;
- 由于(1)一个inode占用256字节,(2)总共有672-161+1(161本身)=512个区块,(3)每个区块的大小为4096字节(4K)。由这些数据可以算出inode 的数量共有512*4096/256 =8192 个 inode;
- 这个Group0目前可用的区块有28521个,可用的inode有8181个;
- 剩余的inode号码为12到8192;
相关文章:
【Linux进阶】文件系统5——ext2文件系统(inode)
1.再谈inode (1) 理解inode,要从文件储存说起。 文件储存在硬盘上,硬盘的最小存储单位叫做"扇区"(Sector)。每个扇区储存512字节(相当于0.5KB)。操作系统读取硬盘的时候,不会一个个…...
华为云简介
前言 华为云是华为的云服务品牌,将华为30多年在ICT领域的技术积累和产品解决方案开放给客户,致力于提供稳定可靠、安全可信、可持续创新的云服务,赋能应用、使能数据、做智能世界的“黑土地”,推进实现“用得起、用得好、用得放心…...
Doris数据库---建表、调整表结构操作
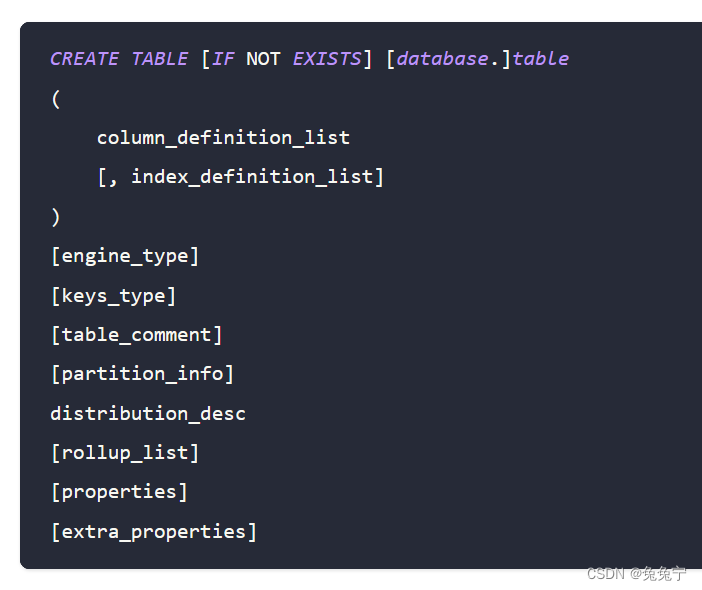
一、简介 本文章主讲创建 Doris 自维护的表的语法,以下为本人最近为数据中台接入doris所踩的坑及其解决方案,欢迎点评。 二、doris建表语法: 官网建表语法网址链接:CREATE-TABLE - Apache Doris 官网建表语法如图所示…...

《昇思 25 天学习打卡营第 11 天 | ResNet50 图像分类 》
《昇思 25 天学习打卡营第 11 天 | ResNet50 图像分类 》 活动地址:https://xihe.mindspore.cn/events/mindspore-training-camp 签名:Sam9029 计算机视觉-图像分类,很感兴趣 且今日精神颇佳,一个字,学啊 上一节&…...

实现多数相加,但是传的参不固定
一、情景 一般实现的加法和减法等简单的相加减函数的话。一般都是写好固定传的参数。比如: function add(a,b) {return a b;} 这是固定的传入俩个,如果是三个呢,有人说当然好办! 这样写不就行了! function add(a…...

Windows环境安装Redis和Redis Desktop Manager图文详解教程
版权声明 本文原创作者:谷哥的小弟作者博客地址:http://blog.csdn.net/lfdfhl Redis概述 Redis是一个开源的高性能键值对数据库,以其卓越的读写速度而著称,广泛用于数据库、缓存和消息代理。它主要将数据存储在内存中࿰…...

SQL Server 2022的组成
《SQL Server 2022从入门到精通(视频教学超值版)》图书介绍-CSDN博客 SQL Server 2022主要由4部分组成,分别是数据库引擎、分析服务、集成服务和报表服务。本节将详细介绍这些内容。 1.2.1 SQL Server 2022的数据库引擎 SQL Server 2022的…...

【大语言模型系列之Transformer】
🎥博主:程序员不想YY啊 💫CSDN优质创作者,CSDN实力新星,CSDN博客专家 🤗点赞🎈收藏⭐再看💫养成习惯 ✨希望本文对您有所裨益,如有不足之处,欢迎在评论区提出…...

操作系统-懒汉式单例模式
懒汉式单例模式的主要好处有以下几点: 1.资源利用效率高: 只有在第一次调用 getInstance() 方法时才创建实例对象,而不是在类加载时就创建。这可以节省系统资源。 2.延迟加载: 实例对象的创建被延迟到第一次使用时,可以减少系统启动时的资源消耗。 3.线程安全: 这种…...

设计模式探索:策略模式
1. 什么是策略模式(Strategy Pattern) 定义 策略模式(Strategy Pattern)的原始定义是:定义一系列算法,将每一个算法封装起来,并使它们可以相互替换。策略模式让算法可以独立于使用它的客户端而…...

提升效能:Symfony 性能优化实用指南
Symfony 是一个功能丰富的 PHP Web 框架,但在构建高性能应用程序时,开发者需要考虑多种性能优化策略。本文将探讨一系列实用的 Symfony 性能优化技巧,帮助开发者提高应用程序的响应速度和整体性能。 1. 了解 Symfony 缓存机制 Symfony 提供…...

1.pwn的汇编基础(提及第一个溢出:整数溢出)
汇编掌握程度 能看懂就行,绝大多数情况不需要真正的编程(shellcode题除外) 其实有时候也不需要读汇编,ida F5 通常都是分析gadget,知道怎么用, 调试程序也不需要分析每一条汇编指令,单步执行然后查看寄存器状态即可 但…...

迎接AI新时代:GPT-5即将登场的巨大变革与应用前瞻
迎接AI新时代:GPT-5即将登场的巨大变革与应用前瞻 💎1. GPT-5 一年半后发布:AI新时代的来临1.1 GPT-5的飞跃:从高中生到博士生 💎2. GPT-5的潜在应用场景💎2.1 医疗诊断和健康管理💎2.2 教育领域…...

封锁-封锁模式(共享锁、排他锁)、封锁协议(两阶段封锁协议)
一、引言 1、封锁技术是目前大多数商用DBMS采用的并发控制技术,封锁技术通过在数据库对象上维护锁来实现并发事务非串行调度的冲突可串行化 2、基于锁的并发控制的基本思想是: 当一个事务对需要访问的数据库对象,例如关系、元组等进行操作…...
跨境干货|最新注册Google账号方法分享
谷歌账号对做跨境外贸业务的人来说是刚需,目前来说大部分的海外社媒平台、工具都可以用谷歌账号来注册。但是仍然有很多朋友并不知道如何注册这个谷歌账号,今天就来给大家分享2个注册谷歌账号的方法,一个是手机号注册,一个是如何跳…...

MySQL第三天作业
一、在数据库中创建一个表student,用于存储学生信息 CREATE TABLE student( id INT PRIMARY KEY, name VARCHAR(20) NOT NULL, grade FLOAT ); 1、向student表中添加一条新记录 记录中id字段的值为1,name字段的值为"monkey"…...

网络安全应急处理流程
网络安全应急处理流程是指在发生网络安全事件时,组织应采取的一系列措施,以快速响应、控制、恢复和调查网络安全事件,确保业务连续性和数据安全。以下是一个详细的网络安全应急处理流程: 1. 准备阶段 目标:建立和维护…...

昇思25天学习打卡营第12天 | LLM原理和实践:MindNLP ChatGLM-6B StreamChat
1. MindNLP ChatGLM-6B StreamChat 本案例基于MindNLP和ChatGLM-6B实现一个聊天应用。 ChatGLM-6B应该是国内第一个发布的可以在消费级显卡上进行推理部署的国产开源大模型,2023年3月就发布了。我在23年6月份的时候就在自己的笔记本电脑上部署测试过,当…...
)
中英双语介绍加拿大多伦多(Toronto)
中文版 多伦多概述 多伦多(Toronto)是加拿大最大的城市,也是北美地区重要的经济、文化和金融中心。以下是对多伦多的详细介绍,包括其经济地位、金融中心、人口、地理位置、高等教育、移民政策、著名景点和居住的名人等方面的信息…...

【YOLOv9教程】如何使用YOLOv9进行图像与视频检测
《博主简介》 小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。 ✌更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~ 👍感谢小伙伴们点赞、关注! 《------往期经典推…...

Visual C++运行库修复工具:彻底解决DLL依赖故障的全方位方案
Visual C运行库修复工具:彻底解决DLL依赖故障的全方位方案 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 当启动专业设计软件时弹出"无法定位程…...
)
HBase Shell 新手必知的10个高效命令(附实战示例)
HBase Shell 高效命令实战指南:从入门到精通 第一次接触HBase Shell时,那种面对命令行界面的茫然感我还记忆犹新。作为HBase数据库的交互式接口,Shell命令看似简单,实则蕴含着强大的数据处理能力。本文将分享我在实际项目中总结出…...

构建专业级Android投屏控制平台:QtScrcpy虚拟按键映射与多设备群控实践
构建专业级Android投屏控制平台:QtScrcpy虚拟按键映射与多设备群控实践 【免费下载链接】QtScrcpy Android real-time display control software 项目地址: https://gitcode.com/GitHub_Trending/qt/QtScrcpy 在移动应用开发、手游体验优化和自动化测试领域&…...
用C++实现信奥题 P6862 [RC-03] 随机树生成器)
打卡信奥刷题(3062)用C++实现信奥题 P6862 [RC-03] 随机树生成器
P6862 [RC-03] 随机树生成器 题目描述 小 R 有一个随机树生成器,其工作原理如下: 输入 nnn,则对于每个 1<i≤n1<i\le n1<i≤n,随机选择一个 [1,i)[1,i)[1,i) 中的节点作为其父亲。返回这棵树。 给定 n,kn,kn,k࿰…...

同事在字节干了 6 年,攒了不少钱但身体垮了。体检查出一堆毛病,医生说得休息。请了一个月假,以前觉得赚钱重要,现在觉得活着重要!
最近刷到一个扎心帖子:贴主的前同事在字节干了 6 年,攒下了不少钱,却也熬垮了身体。一次体检查出一堆问题,医生直接下了“必须休息”的最后通牒。他请了一个月长假,在医院躺了几天后彻底想通了:以前觉得赚钱…...

创新BLDC无刷电机无霍尔无感控制方案:采用脉冲注入法结合持续注入、低速启动动态注入与电感法、...
脉冲注入法,持续注入,启动低速运行过程中注入,电感法,ipd,力矩保持,无霍尔无感方案,媲美有霍尔效果。bldc控制器方案,无刷电机。 。提供源码,原理图。一、代码核心定位 本…...

OpenClaw+Qwen3-32B-Chat镜像:自媒体内容生产全流程自动化
OpenClawQwen3-32B-Chat镜像:自媒体内容生产全流程自动化 1. 为什么需要自动化内容生产? 作为一个自媒体创作者,我每天要花大量时间在重复性工作上:追踪热点、构思选题、撰写大纲、生成初稿、设计封面、多平台发布...这些工作占…...

STM32开发必备的C语言核心技巧与实战解析
1. STM32开发中的C语言核心知识点解析作为一名嵌入式开发者,我经常遇到初学者询问如何快速掌握STM32开发所需的C语言知识。今天我就结合自己多年的实战经验,整理出一份STM32开发中最关键的C语言知识点指南。这些内容不仅适合初学者系统学习,也…...

Thrust事件处理机制:全面解析窗口、键盘和鼠标事件响应
Thrust事件处理机制:全面解析窗口、键盘和鼠标事件响应 【免费下载链接】thrust Chromium-based cross-platform / cross-language application framework 项目地址: https://gitcode.com/gh_mirrors/thru/thrust Thrust作为基于Chromium的跨平台应用框架&am…...

2026 AI简历工具排行榜:写出专业简历,助你直通面试
求职市场对人才的要求日益精细化,一份高质量的简历已成为开启职业大门的“敲门砖”。然而,对于许多求职者而言,“不会排版”、“不擅措辞”依然是制作简历时面临的两大难题。幸运的是,AI技术的飞速发展为我们带来了福音——AI简历…...