【Linux进阶】文件系统6——理解文件操作
目录
1.文件的读取
1.1.目录
1.2.文件
1.3.目录树读取
1.4.文件系统大小与磁盘读取性能
2.增添文件
2.1.数据的不一致(Inconsistent)状态
2.2.日志式文件系统(Journaling filesystem)
3.Linux文件系统的运行
4、文件的删除
4.1. 删除文件
4.2.为什么拷贝文件的时候很慢,而删除文件的时候很快?
4.3.、文件误删后的解决方案
5、大文件存储
1.文件的读取
我们知道在Linux系统下,每个文件(不管是一般文件还是目录文件)都会占用一个inode,且可依据文件内容的大小来分配多个区块给该文件使用。
目录的内容在记录文件名,一般文件才是实际记录数据内容的地方。
我们现在已经了解了Linux的文件系统,那么Linux是如何对文件进行读取的呢?
1.1.目录
当我们在Linux下的文件系统建立一个目录时,文件系统会分配一个inode与至少一块区块给该目录。
其中,inode记录该目录的相关权限与属性,并可记录分配到的那块区块号码,而区块则是记录在这个目录下的文件名与该文件名占用的inode号码数据,也就是说目录所使用的区块记录如下的信息:

如果想要实际观察root 根目录内的文件所占用的inode号码时,可以使用Is-i这个选项来处理:

由于每个人所使用的计算机并不相同,系统安装时选择的项目与磁盘分区都不一样,因此你的环境不可能与我的inode号码一模一样,上表的左边所列出的inode仅是我的系统所显示的结果而已。
而由这个目录的区块结果我们现在就能够知道,当你使用【|| /】时,出现的目录几乎都是1024的倍数,为什么?因为每个区块的数量都是1K、2K、4K,看一下我的环境:
由于我的根目录使用的区块大小为4K,因此每个目录几乎都是4K的倍数,其中由于/usr/sbin的内容比较复杂因此占用了3个区块。
至于奇怪的/proc我们在讲过该目录不占磁盘容量所以当然使用的区块就是0。
由上面的结果我们知道目录并不只会占用一个区块而已,也就是说:在目录下面的文件数如果太多而导致一个区块无法记录得下所有的文件名与inode对照表时,Linux会多给该目录一个区块来继续记录相关的数据。
1.2.文件
当我们在Linux下的ext2建立一个一般文件时,ex2会分配一个inode与相对于该文件大小的区块数量给该文件。
例如:假设我的一个区块为4KB,而我要建立一个100KB的文件,那么Linux将分配一个inode与25个区块来存储该文件。但同时请注意,由于inode仅有12个直接指向,因此还要需要一个区块来记录区块号码。
1.3.目录树读取
好了,经过上面的说明你也应该要很清楚地知道inode本身并不记录文件名,文件名的记录是在目录的区块当中。
那么因为文件名是记录在目录的区块当中,因此当我们要读取某个文件时,就务必会经过目录的inode与区块,然后才能够找到那个待读取文件的inode号码,最终才会读取到该文件的区块中的数据。
由于目录树是由根目录开始读起,因此系统通过挂载的信息可以找到挂载点的inode号码,此时就能够得到根目录的inode内容,并依据该inode 读取根目录的区块内的文件名数据,再一层一层的往下读到正确的文件名。
举例来说,如果我想要读取/etc/passwd这个文件时,系统是如何读取的呢?
在我系统上面与/etc/passwd有关的目录与文件数据如上表所示,该文件的读取流程为(假
设读取者身份为dmtsai 这个一般身份用户):
- 1. /的inode:
通过挂载点的信息找到inode号码为2的根目录inode,且 inode 规范的权限让我们可以读取
该区块的内容(有r与x);
- 2./ 的区块:
经过上个步骤取得区块的号码,并找到该内容有etc/目录的inode 号码(1310721);
- 3. etc/ 的inode:
读取1310721号inode 得知zs_108具有r与x的权限,因此可以读取etc/的区块内容;
- 4. etc/的区块:
经过上个步骤取得区块号码,并找到该内容有passwd 文件的inode 号码(1311648);
- 5. passwd 的 inode:
读取1311648号inode 得知zs_108具有r的权限,因此可以读取passwd的区块内容;
- 6. passwd的区块:
最后将该区块内容的数据读出来;

1.4.文件系统大小与磁盘读取性能
另外,关于文件系统的使用效率,当你的一个文件系统规划得很大时,例如100GB这么大时,由于磁盘上面的数据总是来来去去的,所以,整个文件系统上面的文件通常无法连续写在一起(区块号码不会连续的意思),而是填入式地将数据写入没有被使用的区块当中。
如果文件写入的区块真的很分散,此时就会有所谓的文件数据离散的问题发生了。
如前所述,虽然我们的ext2在inode处已经将该文件所记录的区块号码都记上了,所以数据可以一次性读取,但是如果文件真的太过离散,确实还是会发生读取效率下降的问题,因为磁头还是得要在整个文件系统中来来去去地频繁读取。
果真如此,那么可以将整个文件系统内的数据全部复制出来,将该文件系统重新格式化,再将数据给它复制回去即可解决这个问题。
此外,如果文件系统真的太大,那么当一个文件分别记录在这个文件系统的最前面与最后面的区块号码中,此时会造成磁盘的机械手臂移动幅度过大,也会造成数据读取性能的下降。
而且磁头在查找整个文件系统时,也会花费比较多的时间去查找。
因此,磁盘分区的规划并不是越大越好,而是要针对您的主机用途来进行规划才行。
2.增添文件
上一小节谈到的仅是读取而已,那么如果是新建一个文件或目录时,我们的文件系统是如何处理的呢?
这个时候就得要区块对照表及inode 对照表的帮忙了。
假设我们想要新增一个文件,此时文件系统的操作是:
- 1.先确定用户对于欲新增文件的目录是否具有w与x的权限,若有的话才能新增;
- 2.根据inode 对照表找到没有使用的inode号码,并将新文件的权限/属性写入;
- 3.根据区块对照表找到没有使用中的区块号码,并将实际的数据写入区块中,且更新inode的区块指向数据;
- 4.将刚刚写入的inode与区块数据同步更新inode对照表与区块对照表,并更新超级区块的内容。
一般来说,
- 我们将inode 对照表与数据区块称为数据存放区域,
- 至于其他例如超级区块、区块对照表与inode 对照表等区段就被称为元数据(metadata)
因为超级区块、inode对照表及区块对照表的数据是经常变动的,每次新增、删除、编辑时都可能会影响到这三个部分的数据,因此才被称为元数据。
2.1.数据的不一致(Inconsistent)状态
在一般正常的情况下,上述的新增操作当然可以顺利的完成。
但是如果有个万一怎么办?
例如你的文件在写入文件系统时,因为某些原因导致系统中断(例如突然的停电、系统内核发生错误等的怪事发生时),所以写入的数据仅有inode对照表及数据区块而已,最后一个同步更新元数据的步骤并没有完成,此时就会发生元数据的内容与实际数据存放区产生不一致(Inconsistent)的情况。
既然有不一致当然就得要解决。
在早期的ext2文件系统中,如果发生这个问题,那么系统在重新启动的时候,就会借由超级区块当中记录的有效位(是否有挂载)与文件系统状态(正确卸载与否)等状态来判断是否强制进行数据一致性的检查,若有需要检查时则以e2fsck这个程序来进行。
不过,这样的检查真的是很费时,因为要针对元数据区域与实际数据存放区来进行比对,呵呵,得要查找整个文件系统,如果你的文件系统有100GB以上,而且里面的文件数量又多时,哇,系统真忙碌,而且在对提供网络服务的服务器主机上面,这样的检查真的会造成主机恢复时间的拉长,真是麻烦,这也就造成后来所谓日志式文件系统的兴起。
2.2.日志式文件系统(Journaling filesystem)
为了避免上述提到的文件系统不一致的情况发生,我们的前辈们想到一个方式,如果在我们的文件系统当中规划出一个区块,该区块专门记录写入或修改文件时的步骤,那不就可以简化一致性检查的步骤了?
也就是说:
- 1.预备:当系统要写入一个文件时,会先在日志记录区块中记录某个文件准备要写入的信息;
- 2.实际写入:开始写入文件的权限与数据;开始更新metadata的数据;
- 3.结束:完成数据与metadata的更新后,在日志记录区块当中完成该文件的记录;
在这样的程序当中,万一数据的记录过程当中发生了问题,那么我们的系统只要去检查日志记录区块,就可以知道哪个文件发生了问题,针对该问题来做一致性的检查即可,而不必针对整个文件系统进行检查,这样就可以达到快速修复文件系统的目的,这就是日志式文件最基础的功能。
那么我们的ext2可实现这样的功能吗?
当然可以,使用ext3与ext4即可。ext3与ext4是ex的升级版本,并且可向下兼容ext2版本。所以,目前我们才建议大家,可以直接使用ext4这个文件系统,如果你还记得dumpe2fs 输出的信息,可以发现超级区块里面含有下面这样的信息:
看到了吧!通过inode 8号记录日志区块的区块指向,而且该日志区块具有32MB的容量来记录
日志信息。这样对于所谓的日志式文件系统有没有一点概念呢?
3.Linux文件系统的运行
我们现在知道了目录树与文件系统的关系,但我们也知道,所有的数据要加载到内存后CPU才能够进行处理。
想一想,如果你常常编辑一个好大的文件,在编辑的过程中又频繁地要系统来写入到磁盘中,由于磁盘写入的速度要比内存慢很多,因此你会常常耗在等待磁盘的读写上真没效率。
为了解决这个效率的问题,Linux使用一个称为异步处理(asynchronously)的方式。所谓的异步处理是这样的:
当系统加载一个文件到内存后,如果该文件没有被修改过,则在内存区段的文件数据会被设置为【干净(clean)】。但如果内存中的文件数据被更改过了(例如你用nano去编辑过这个文件),此时该内存中的数据会被设置为【脏的(Dirty)】,此时所有的操作都还在内存中执行,并没有写入到磁盘中。系统会不定时的将内存中设置为【Dirty】的数据写回磁盘,以保持磁盘与内存数据的一致性。你也可以利用sync命令来手动强制写入磁盘。
我们知道内存的速度要比磁盘快得多,因此如果能够将常用的文件放置到内存当中,这不就会提高系统性能了吗?
没错,是有这样的想法。
因此我们Linux系统上面的文件系统与内存有非常大的关系:
- 系统会将常用的文件数据放置到内存的缓冲区,以加速文件系统的读写操作;
- 因此 Linux的物理内存最后都会被用光,这是正常的情况,可加速系统性能;你可以手动使用sync来强制内存中设置为Dirty的文件回写到磁盘中;
- 若正常关机时,关机命令会主动调用sync来将内存的数据回写入磁盘内;
- 但若不正常关机(如断电、宕机或其他不明原因),由于数据尚未回写到磁盘内,因此重新启动后可能会花很多时间在进行磁盘校验,甚至可能导致文件系统的损坏(非磁盘损坏)
4、文件的删除
文件创建后,如何删除?
删除并不是真删除,而是将 inode 对照表 和 Block对照表 中位图信息进行修改即可(只要访问不到,就是删除)
- 根据文件名找到 inode 编号
- 再根据 inode 属性中的映射关系,设置 Block 对照表对应的比特位,设置为 0 (删内容)
- 最后根据 inode 编号设置 inode对照表中对应的比特位为 0 (删属性)
将位图信息置为 0 后,创建新文件时,系统可以直接使用
至于文件的查找与修改,通过 inode 修改其内部属性即可
注意: inode 和 Data blcok 可能存在失衡的情况
- 一直创建空文件,导致 inode 满载,而 Data block 空余很多
- 不断往同一个文件中写入数据,导致 Data block 被占用,后续创建文件时,inode 无法再分配到 Data block
4.1. 删除文件
删除文件的步骤
- 首先根据文件名找到
inode编号 - 再将该文件对应的
inode,在inode位图当中置为无效(置0) - 最后将该文件申请的数据块,在块位图当中置为无效(置0)
此删除操作并不会真正将文件对应的信息删除,而只是将其inode号和数据块号置为了无效,起到了访问不到就等于删除的效果
当我们删除文件后短时间内是可以恢复的
为什么说是短时间内呢,
因为该文件对应的inode号和数据块号已经被置为了无效,因此后续创建其他文件或是对其他文件进行写入操作申请inode号和数据块号时,可能会将该置为无效了的inode号和数据块号分配出去,此时删除文件的数据就会被覆盖,也就无法恢复文件了。
4.2.为什么拷贝文件的时候很慢,而删除文件的时候很快?
- 因为拷贝文件需要先创建文件,然后再对该文件进行写入操作,该过程需要先申请inode号并填入文件的属性信息,之后还需要再申请数据块号,最后才能进行文件内容的数据拷贝,
- 而删除文件只需将对应文件的inode号和数据块号置为无效即可,无需真正的删除文件,因此拷贝文件是很慢的,而删除文件是很快的。
4.3.、文件误删后的解决方案
磁盘中的数据被删除后,还可以再恢复吗?
答案是可以的,但不能完全恢复,并且越早断电、送修越好
前面说过,删除并不是真删除,访问不到就行了,所以只要在删除后,根据 inode 找到 Data block,其中的内容没有被覆盖,数据就可以找回来
应急方案:
- 不要轻举妄动,避免 Data block 被覆盖
- 通过 inode 将 inode 位图 中的位图置 1,使文件复活,再根据属性进行数据恢复
- 如果自己不知道 inode,那就尽早断电,送给厂家恢复(专业)
如何避免误删文件?
- 学习 Windows 中的回收站,删除不是真删除,而是先将文件移入回收站(目录)中,留给用户反悔的时间
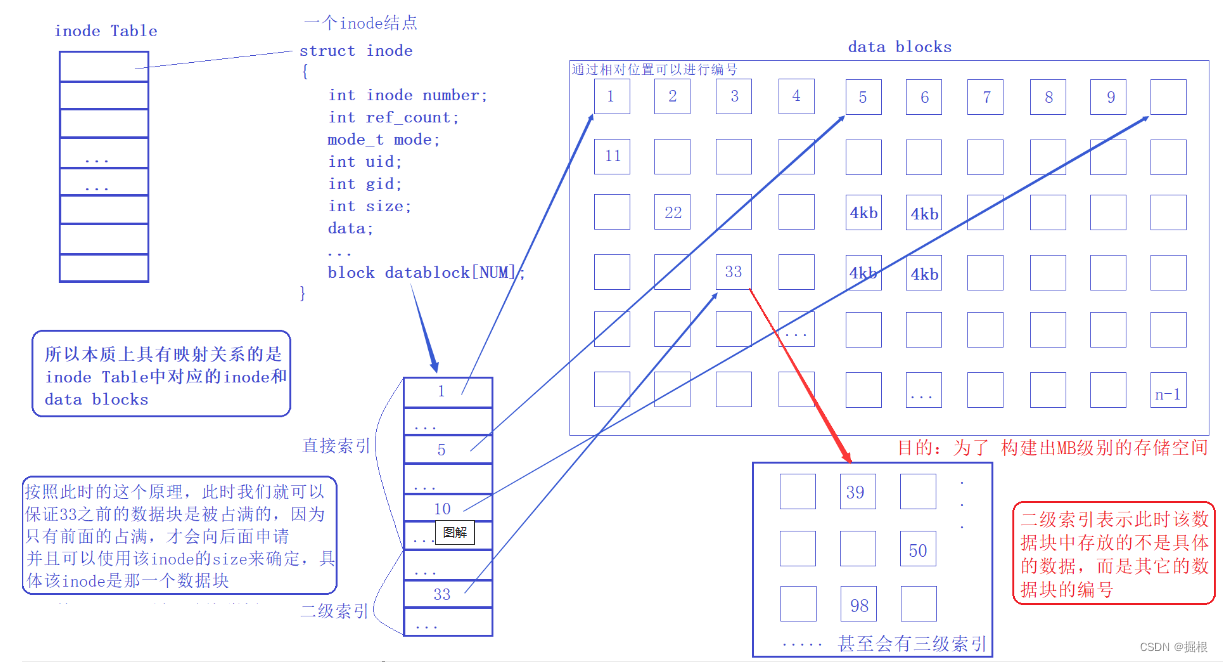
5、大文件存储
单个数据块大小有限(4 kb),如何做到一个数据块存储大量数据?
答案是 套娃,Data block 中存储其他 Data block 信息,此时称为多级索引,可以做到一个数据块中存储大量数据
相关文章:
【Linux进阶】文件系统6——理解文件操作
目录 1.文件的读取 1.1.目录 1.2.文件 1.3.目录树读取 1.4.文件系统大小与磁盘读取性能 2.增添文件 2.1.数据的不一致(Inconsistent)状态 2.2.日志式文件系统(Journaling filesystem) 3.Linux文件系统的运行 4、文件的删…...

Python编译器的选择
了解如何使用一个集成开发环境(IDE)对于 Python 编程是非常重要的。IDE 提供了代码编辑、运行、调试、版本控制等多种功能,可以极大地提升开发效率。以下是一些流行的 Python IDE 和代码编辑器的介绍,以及如何开始使用它们&#x…...

Java | Leetcode Java题解之第217题存在重复元素
题目: 题解: class Solution {public boolean containsDuplicate(int[] nums) {Set<Integer> set new HashSet<Integer>();for (int x : nums) {if (!set.add(x)) {return true;}}return false;} }...

python基础语法 006 内置函数
1 内置函数 材料参考:内置函数 — Python 3.12.4 文档 Python 解释器内置了很多函数和类型,任何时候都能直接使用 内置函数有无返回值,是python自己定义,不能以偏概全说都有返回值 以下为较为常用的内置函数,欢迎补充…...

ABAP中BAPI_CURRENCY_CONV_TO_EXTERNAL函数详细的使用方法
在ABAP(SAP的应用程序开发语言)中,BAPI_CURRENCY_CONV_TO_EXTERNAL函数用于将SAP系统内部存储的货币金额转换为外部显示的格式。这个函数在处理财务报告、用户界面显示或与其他系统集成时非常有用。以下是该函数的详细使用方法: …...

Mac本地部署大模型-单机运行
前些天在一台linux服务器(8核,32G内存,无显卡)使用ollama运行阿里通义千问Qwen1.5和Qwen2.0低参数版本大模型,Qwen2-1.5B可以运行,但是推理速度有些慢。 一直还没有尝试在macbook上运行测试大模型…...
Qt:8.QWidget属性介绍(focuspolicy属性-控件焦点、stylesheet属性-为控件设置样式)
目录 一、focuspolicy属性-控件焦点: 1.1focuspolicy属性介绍: 1.2设置焦点策略——setFocusPolicy(): 1.3获取控件的焦点策略——focusPolicy(): 二、stylesheet属性——为控件设置样式: 2.1 stylesheet属性介绍…...
R可视化数据必要格式——长格式
一、引言 我们在对数据进行可视化时遇到最头疼、最常见的问题是什么?数据问题。 因为我们往往不会从零自己编程进行可视化,往往是现有模板或积累,而正确的数据格式对应正确的图形包要求,一定会正确出图,所以只有一个问…...

Android计算器界面的设计——表格布局TableLayout实操
目录 任务目标任务分析任务实施 任务目标 使用TextView、Button等实现一个计算器界面,界面如图1所示。 图1 计算器界面效果图 任务分析 界面整体使用表格布局,第一行使用一个TextView控件,横跨4列,中间4行4列,最后一…...

【数据结构】经典链表题目详解集合(反转链表、相交链表、链表的中间节点、回文链表)
文章目录 一、反转链表1、程序详解2、代码 二、相交链表1、程序详解2、代码 三、链表的中间节点1、程序详解2、代码 四、回文链表1、程序详解2、代码 一、反转链表 1、程序详解 题目:给定单链表的头节点 head ,请反转链表,并返回反转后的链…...

人工智能在软件开发中的角色:助手还是取代者?
人工智能在软件开发中的角色:助手还是取代者? 随着科技的飞速发展,生成式人工智能(AIGC)在软件开发领域的应用越来越广泛。从代码生成、错误检测到自动化测试,AI工具正成为开发者的重要助手。然而…...

qt播放视频
在Qt中播放视频,通常可以使用QMediaPlayer和QVideoWidget这两个类。QMediaPlayer用于控制视频的播放,而QVideoWidget则用于显示视频。 以下是一个简单的示例,展示了如何使用Qt播放视频: cpp复制代码 #include <QApplication…...

搭建论坛和mysql数据库安装和php安装
目录 概念 步骤 安装mysql8.0.30 安装php 安装Discuz 概念 搭建论坛的架构: lnmpDISCUZ l 表示linux操作系统 n 表示nginx前端页面的web服务 m 表示 mysql 数据库 用来保存用户和密码以及论坛的相关内容 p 表示php 动态请求转发的中间件 步骤 ÿ…...
[护网训练]原创应急响应靶机整理集合
前言 目前已经出了很多应急响应靶机了,有意愿的时间,或者正在准备国护的师傅,可以尝试着做一做已知的应急响应靶机。 关于后期: 后期的应急响应会偏向拓扑化,不再是单单一台机器,也会慢慢完善整体制度。…...

【Linux】:程序地址空间
朋友们、伙计们,我们又见面了,本期来给大家解读一下有关Linux程序地址空间的相关知识点,如果看完之后对你有一定的启发,那么请留下你的三连,祝大家心想事成! C 语 言 专 栏:C语言:从…...

c++ 学习面试之路
引用与指针有什么区别? 指针和引用都是地址的概念,指针指向一块内存,它的内容是所指内存的地址;引用是某块内存的别名。 程序为指针变量分配内存区域,而不为引用分配内存区域。 指针使用时要在前加 * ,引…...

Linux文件结构
与Windows下的文件组织结构不同,Linux不使用磁盘分区符号来访问文件系统,而是将整个文件系统表示成树状结构,Linux系统每增加一个文件系统都会将其加入到这个树中。 操作系统文件结构的开始只有一个单独的顶级目录结构,叫做根目录…...

【简单介绍下Memcached】
🌈个人主页: 程序员不想敲代码啊 🏆CSDN优质创作者,CSDN实力新星,CSDN博客专家 👍点赞⭐评论⭐收藏 🤝希望本文对您有所裨益,如有不足之处,欢迎在评论区提出指正,让我们共…...
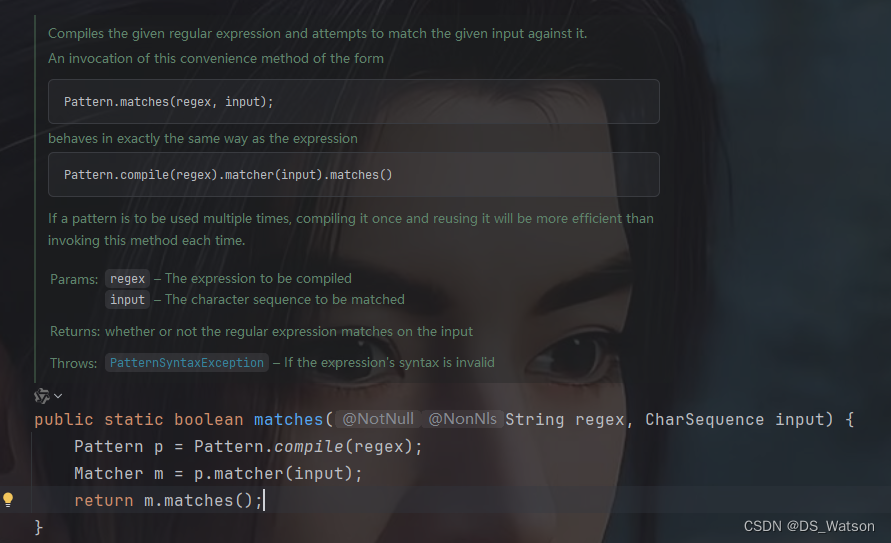
字符串和正则表达式踩坑
// 中石化加油卡号格式:以 100011 开头共19位public static final String ZHONGSHIYOU_OIL_CARD_PATTERN "^100011\\d{13}$";// 中石油加油卡号格式:以90、95、70开头共16位public static final String ZHONGYOU_OIL_CARD_PATTERN "^(9…...

LLM4Decompile——专门用于反编译的大规模语言模型
概述 论文地址:https://arxiv.org/abs/2403.05286 反编译是一种将已编译的机器语言或字节码转换回原始高级编程语言的技术。该技术用于分析软件的内部工作原理,尤其是在没有源代码的情况下;Ghidra 和 IDA Pro 等专用工具已经开发出来&#…...

收藏 | RAG核心认知:从“检索+生成”到“实时智能”,小白也能秒懂大模型技术范式!
收藏 | RAG核心认知:从“检索生成”到“实时智能”,小白也能秒懂大模型技术范式! RAG(检索增强生成)通过动态联动外部知识库与大语言模型(LLM),构建“实时信息输入-精准内容输出”闭…...

应收账款管理:从“被动应对”到“主动管理”的思维转变
“应收账款管理真的太难了!”这是许多企业管理者的心声。中小型企业尤其容易陷入资金回笼慢、坏账风险高的困境,甚至因此影响现金流健康,拖累企业发展。传统管理模式中,信息孤岛、流程繁琐和决策滞后等问题屡见不鲜,让…...

C 里面如何使用链表 list
1. 学生时代, 那会学习 C 数据结构, 比较简单 struct person {int id;char name[641];struct person * next; }; 类似上面这样, 需要什么依赖 next 指针来回调整, 然后手工 print F5 去 debug 熬. 2. 刚工作青年时代, 主要花活, 随大流类似 #pragma once#include "stru…...

Lux编译器完整指南:如何将用户意图智能转化为可视化规范
Lux编译器完整指南:如何将用户意图智能转化为可视化规范 【免费下载链接】lux Automatically visualize your pandas dataframe via a single print! 📊 💡 项目地址: https://gitcode.com/gh_mirrors/lux/lux Lux编译器是Lux数据可视…...

面向对象AI启示下的软件设计新范式
当物理世界成为对象网络,我们的软件架构该如何进化? 核心理念:软件作为“对象生态”的模拟器 从面向对象AI的启示中,我们得到的核心洞见是:优秀的软件应该像智能体理解物理世界一样,理解自己的问题域。这意味着软件不再仅仅是数据处理管道,而是一个动态的、对象化的生态…...

@Value赋值踩的坑
Spring Boot 配置文件中的科学计数法陷阱 ⚠️ 警惕:YAML 配置中的字符串被误解析为数字的问题 📋 问题场景 1. 配置文件示例 # 测试环境配置 ✅ xunfei:appid: 0e1d789dapisecret: NzE5ZmExxxxxxxTFkNmY1ZWJjZTA1apikey: d228r7t8xxxxxxxc0bebb17e377…...

Baichuan-7B代码生成能力:编程助手的最佳选择 - 7B参数大模型的终极指南
Baichuan-7B代码生成能力:编程助手的最佳选择 - 7B参数大模型的终极指南 【免费下载链接】Baichuan-7B A large-scale 7B pretraining language model developed by BaiChuan-Inc. 项目地址: https://gitcode.com/gh_mirrors/ba/Baichuan-7B Baichuan-7B是由…...

vLLM-v0.17.1详细步骤:启用CUDA Graph提升GPU利用率至98%操作指南
vLLM-v0.17.1详细步骤:启用CUDA Graph提升GPU利用率至98%操作指南 1. vLLM框架简介 vLLM是一个专为大型语言模型(LLM)设计的高性能推理和服务库,以其出色的吞吐量和易用性著称。这个项目最初由加州大学伯克利分校的天空计算实验室开发,现在…...

降低OpenClaw Token消耗的三大实战策略,省钱后随便花,再也不用担心不够了
让AI“跑得更快、花得更少”:OpenClaw降本增效的终极实战手册 想象一下,你雇佣了一位才华横溢、但收费高昂的顶尖顾问。每次咨询,你都不厌其烦地把过去一整年的会议记录、所有项目文档、甚至茶水间的闲聊纪要都一股脑儿塞给他,然…...

Fish Speech 1.5镜像免配置指南:3步启动WebUI生成高自然度语音
Fish Speech 1.5镜像免配置指南:3步启动WebUI生成高自然度语音 想给视频配音,但找不到合适的声音?想制作有声书,又觉得录音太麻烦?或者,你只是想体验一下用AI生成一段媲美真人的语音? 今天&am…...