LLM4Decompile——专门用于反编译的大规模语言模型
概述
论文地址:https://arxiv.org/abs/2403.05286
反编译是一种将已编译的机器语言或字节码转换回原始高级编程语言的技术。该技术用于分析软件的内部工作原理,尤其是在没有源代码的情况下;Ghidra 和 IDA Pro 等专用工具已经开发出来,但这些工具很难生成人类可读格式的代码。反编译的最大挑战是完全再现代码的基本结构,如变量名、循环和条件语句,这些在编译过程中往往会丢失。
为解决这一问题,大规模语言模型(LLM)的最新进展备受瞩目。这些模型将编程语言视为一种语言系统,并使用预先训练好的模型来处理各种编码任务。与传统方法相比,这种方法取得了显著的进步,并表明在反编译领域也可以采用类似的方法。
然而,到目前为止,很少有标准基准或公开可用的数据集来评估和比较反编译技术。研究人员使用不同的数据集,因此很难对结果进行直接比较。因此,在本文中,我们开发了一个专门用于反编译的开源大规模语言模型,并建立了第一个侧重于可重编译性和可重执行性的反编译基准。这有望统一反编译领域的评估标准,促进进一步的研究。下图显示了本文的反编译评估步骤。
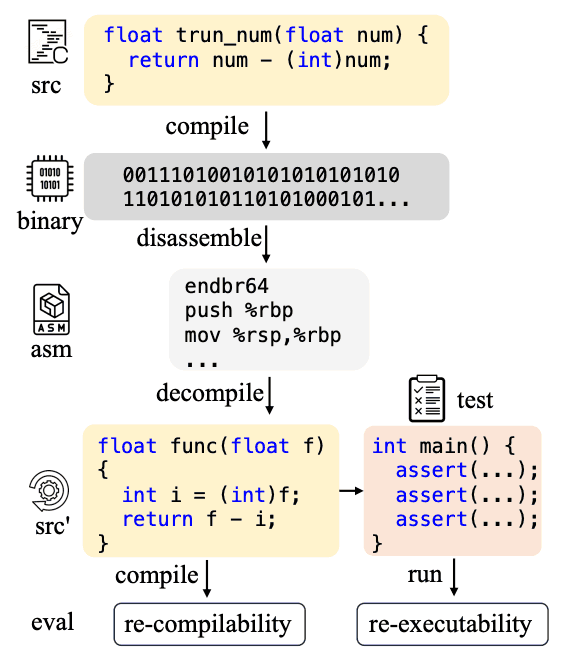
什么是 LLM4Decompile?
LLM4Decompile 是一项致力于反编译程序的开创性举措。首先,在构建预训练数据时,它以一百万个名为 Anghabench 的公开可编译 C 文件为基础。利用这一丰富的数据集创建汇编代码和源代码对。具体来说,首先将源代码转换为二进制对象文件,然后将其反汇编为汇编代码,并与 x86 Linux 平台上的源代码配对。它还考虑了程序员为优化执行性能而使用的各种编译器优化标志。优化过程是一种将源代码转换为更快、更高效的机器代码的技术。优化级别在不同阶段对源代码进行编译,从默认的 O0(无优化)到 O3(积极优化)。在整个过程中,都会使用独特的提示来让模型了解优化阶段。
这是具有 [优化状态] 优化功能的汇编代码:[汇编代码]。源代码是什么?
通过这种方式,LLM4Decompile 可以更深入地了解编程世界,并为更精确的反编译奠定基础。
接下来,LLM4Decompile 模型设置使用与 LDeepSeek-Coder 相同的架构,并使用相应的 DeepSeek-Coder 检查点初始化模型。学习目标分为两类
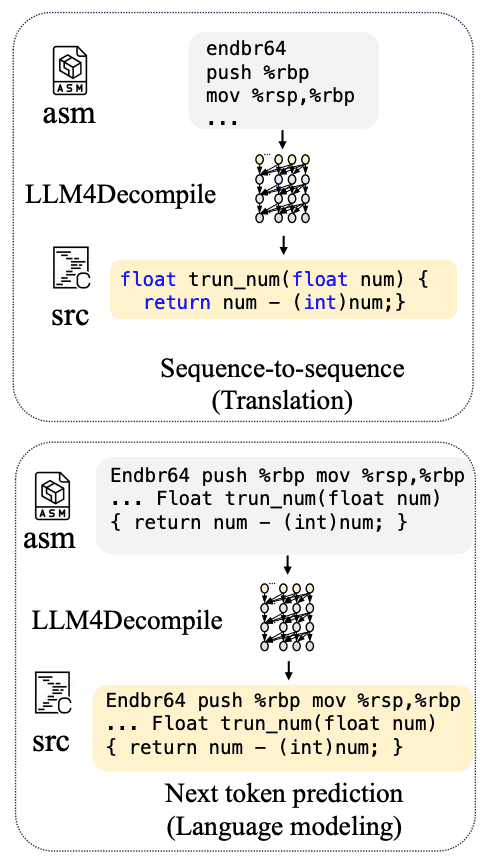
第一个目标是下一个标记预测(NTP)。它根据给定的输入预测下一个标记。这种方法在许多大规模语言模型的预训练中发挥着核心作用,其目的是最大限度地降低真实标记的负对数概率。这一过程包括改进模型参数,以便根据输入序列做出更准确的预测。
第二个目标是序列到序列(S2S)。它预测输入序列的预期输出。这是一种专门用于神经机器翻译模型的方法,其重点是尽量减少 C 代码中标记的负对数概率。以此为目标,只计算输出序列的损失,从而实现更准确的翻译。
这两种学习目标的主要区别在于输入序列和汇编代码如何影响学习损失的计算:在 NTP 中,所有输入都被考虑在内,而在 S2S 中,只强调输出序列。本文进行了各种消融研究,以确定这些目标如何影响反编译的准确性。
实验结果
下表总结了有趣的研究结果。最初,即使是基本版本的 DeepSeek-Coder 也很难反编译二进制文件,在某些情况下可以编译,但在其他情况下却无法准确捕捉原始程序的含义。不过,经过微调后,LLM4Decompile 模型在反编译二进制文件的能力上有了显著提高。事实上,90% 的代码都可以编译,这表明我们对代码的结构和语法有了更深入的理解。

值得注意的是,6B 版本的 LLM4Decompile 在执行代码的能力方面比 1B 版本有明显优势:6B 版本反编译出的代码中有 21% 准确地抓住了程序的本质并通过了所有测试用例。而 1B 版本只有 10%。这一改进凸显了扩大模型规模对捕捉程序含义的益处。另一方面,将模型规模增大到 33B 也会导致可再运行性的小幅改善,改善幅度不到一个百分点。这可能说明了调整到 33B 模型的难度。
下表总结了 AnghaBench 中的结果,显示 LLM4Decompile 取得了特别高的 BLEU 和 ES 分数;6B 模型的 BLEU 分数为 0.82,与源代码非常接近。这一令人印象深刻的表现表明,测试集中可能存在严重的数据泄漏。实际上,带有规范化变量的反编译代码不可能达到如此高的 N-gram/ES 分数。这一反常现象,以及之前研究中报告的高 BLEU 和 ES 分数,凸显了建立独立可靠的反编译评估基准的重要性。

序列到序列(S2S)预测方法也因其特点而显示出领先于其他学习方法的性能。其中的奥秘可以说在于汇编代码被排除在损失函数的计算之外,从而使模型能够专注于源代码的生成。这种集中可以让模型更好地理解反编译代码背后的模式和结构。
但是,在训练过程中加入汇编代码会使性能降低约 4 个百分点,这在下一个标记预测 (NTP)任务中尤为明显(下表)。汇编代码固有的复杂性和低级特性使模型难以学习有意义的模式;S2S 方法避免了这种复杂性,使模型能够专注于高级源代码模式。

还有另一种策略,即在涉及汇编和 C 代码的初始训练之后,尝试以翻译任务为重点进行微调(NTP+S2S),但这种方法不如 S2S 方法有效。这项消融研究强调了 LLM4Decompile 在反编译过程中的演变过程,以及某些方法更胜一筹的原因。
总结
本文提供了首个开源的、以反编译为重点的大规模语言模型和标准化的可重编译性/可重执行性基准。对这组不同的 C 代码编译数据集的分析表明,LLM4Decompile-6B 的可重编译性和可重执行性分别达到了 87% 和 21%,前者表明了语法理解,后者表明了语义保护。作为对数据驱动反编译的初步探索,本文建立了一个开放的基准,以激励未来的努力。已发布的数据集、模型和分析都体现了通过新技术提高反编译能力的巨大潜力。
相关文章:
LLM4Decompile——专门用于反编译的大规模语言模型
概述 论文地址:https://arxiv.org/abs/2403.05286 反编译是一种将已编译的机器语言或字节码转换回原始高级编程语言的技术。该技术用于分析软件的内部工作原理,尤其是在没有源代码的情况下;Ghidra 和 IDA Pro 等专用工具已经开发出来&#…...
关于Web开发的详细介绍
目录 一、什么是Web? 二、Web网站的工作流程和开发模式 (1)简单介绍 (2)工作流程 1、第一步 2、第二步 (3)Web网站的开发模式 1、前后端分离开发模式 编辑2、混合开发模式 三、开发W…...

G1 垃圾收集器
从 JDK1.9 开始默认 G1,应用在多处理器和大容量内存环境中。 基础概念 Region G1 给整一块Heap内存区域均匀等分了N个 Region,N 默认情况下是 2048。 Region的大小只能是1M、2M、4M、8M、16M或32M (1-32M,并且为2的指数),比如-Xmx16g -Xms…...

Linux Ubuntu 20.04.06 安装Onboard虚拟键盘教程
目录 一、在线安装 二、源码安装 三、包安装 四、设置 五、禁用系统键盘 一、在线安装 sudo apt-get update #更新软件源 sudo apt-get install onboard #安装Onboard sudo apt-get purge onboard # 卸载 安装后,如果在终端使用命令:onboard 启…...

简介空间复杂度
我们承接上一篇博客。我们写了时间复杂度之后,我们就要来介绍一下另一个相关复杂度了。空间复杂度。我觉得大家应该对空间复杂度认识可能比较少一些。我就是这样,我很少看见题目中有明确要求过空间复杂度的。但确实有这个是我们不可忽视的,所…...

windows server2016搭建AD域服务器
文章目录 一、背景二、搭建AD域服务器步骤三、生成可供java程序使用的keystore文件四、导出某用户的keytab文件五、主机配置hosts文件六、主机确认是否能ping通本人其他相关文章链接 一、背景 亲测可用,之前搜索了很多博客,啥样的都有,就是不介绍报错以…...
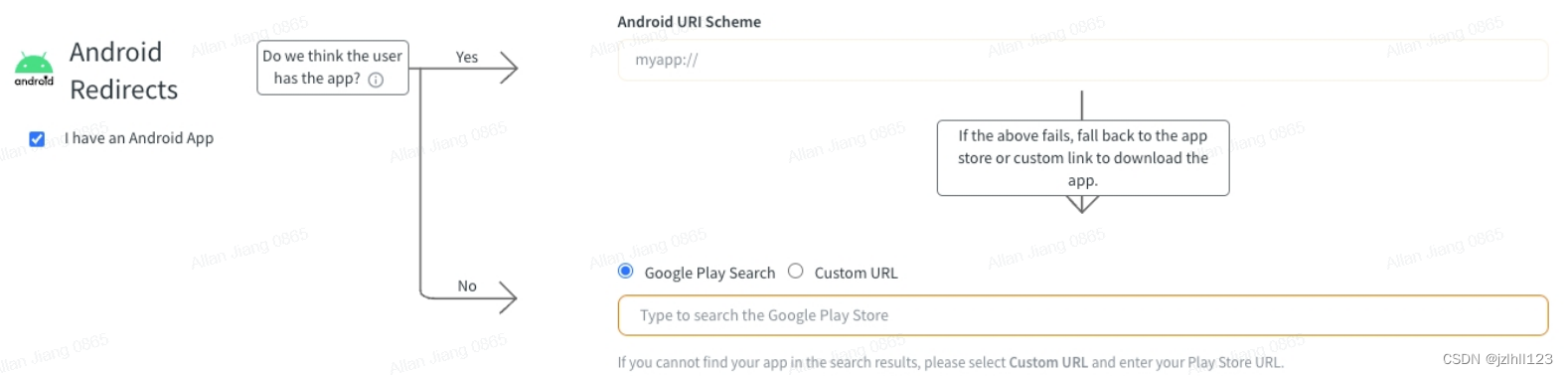
android deep links即scheme uri跳转以及googlePlay跳转配置
对于googlePlay的Custom URL就是googlePlay上APP网址: https://play.google.com/store/apps/details?idcom.yourapp如果是国内一些应用,则考虑market://包名等方式,自行百度。 对于Android URI Scheme: 首先需要在Manifest xm…...

QT5.14.2与Mysql8.0.16配置笔记
1、前言 我的QT版本为 qt-opensource-windows-x86-5.14.2。这是QT官方能提供的自带安装包的最近版本,更新的版本需要自己编译源代码,可点击此链接进行下载:Index of /archive/qt/5.14/5.14.2,选择下载 qt-opensource-windows-x86…...

判断是否为完全二叉树
目录 分析 分析 1.完全二叉树的概念:对于深度为K的,有n个结点的二叉树,当且仅当其每一个结点都与深度为K的满二叉树中编号从1至n的结点一一对应时称之为完全二叉树。 要注意的是满二叉树是一种特殊的完全二叉树。 2.思路:可以采…...
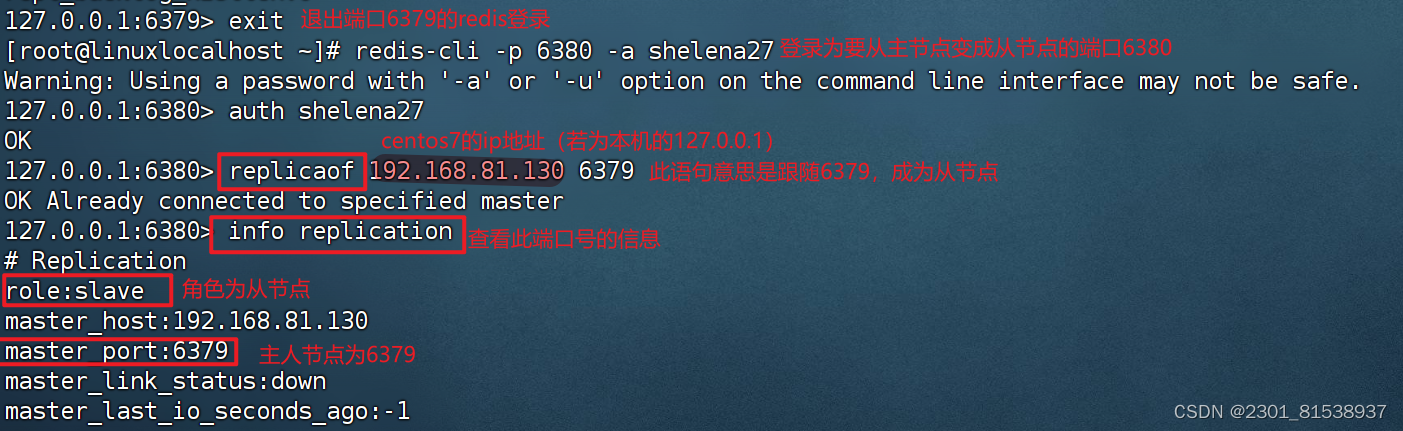
【笔记】记一次redis将从节点变成主节点 主节点变成从节点
1.连上虚拟机centos7 2.打开finalshell连接虚拟机 将从节点变为主节点 输出redis-cli -p 要变成主节点的从节点 -a此从节点的密码 输入 replicaof no one 查看端口状态 info replication 总结: redis-cli -p 端口号 -a 密码 replicaof no one info replicati…...

解析Java中1000个常用类:DoubleSummaryStatistics类,你学会了吗?
在线工具站 推荐一个程序员在线工具站:程序员常用工具(http://cxytools.com),有时间戳、JSON格式化、文本对比、HASH生成、UUID生成等常用工具,效率加倍嘎嘎好用。程序员资料站 推荐一个程序员编程资料站:程序员的成长之路(http://cxyroad.com),收录了一些列的技术教程…...

WAIC热点聚焦|新质生产力与低空经济
WAIC热点聚焦|新质生产力与低空经济 概览 # WAIC热点聚焦 | 新质生产力与低空经济## 1. 新质生产力定义与特点 - 新质生产力是在新的经济社会发展阶段中形成的,具有变革性和高增长潜力的生产能力。## 2. 低空经济概念与构成 ### 2.1 低空经济定义 - 低空经济是依托…...

Docker部署ETCD 3.5.14(保姆级图文教程)
系列文章目录 Docker部署Nginx 1.21.5(保姆级图文教程) Docker部署MySQL 8.3.0(保姆级图文教程) Docker部署ETCD 3.5.14(保姆级图文教程) 文章目录 一、环境二、拉取镜像2.1 查找 Docker Hub 上的 ETCD 镜像…...

2024年7月6日 (周六) 叶子游戏新闻
自动电脑内部录音器AutoAudioRecorder: 是一款免费的自动音频录制软件,可直接将电脑内部所有的声音录制成 mp3/wav 文件,包括音乐、游戏直播、网络会议、聊天通话等音频源。 卸载工具 HiBitUninstaller: Windows上的软件卸载工具 《不羁联盟》制作人&…...
之Requests库)
python爬虫入门(二)之Requests库
一、储备篇 1、requests库让我们可以通过python代码去构建和发送HTTP请求 2、第三方库,要先安装 python终端,输入pip install requests successfully installed:安装成功 requirement already satisfied: 说明已经安装过,无需…...

Git 操作补充:cherry-pick、变基
1. 挑选提交合并 git cherry-pick 对于多分支的代码库,将代码从一个分支转移到另一个分支是一种常见的需求,这可以分成两种情况:一种情况是,你需要另一个分支的所有代码变动,那么就采用 git merge;另一种情…...

在 PostgreSQL 中,如何处理大规模的文本数据以提高查询性能?
文章目录 一、引言二、理解 PostgreSQL 中的文本数据类型三、数据建模策略四、索引选择与优化五、查询优化技巧六、示例场景与性能对比七、分区表八、数据压缩九、定期维护十、总结 在 PostgreSQL 中处理大规模文本数据以提高查询性能 一、引言 在当今的数据驱动的世界中&…...
秋招提前批面试经验分享(下)
⭐️感谢点开文章👋,欢迎来到我的微信公众号!我是恒心😊 一位热爱技术分享的博主。如果觉得本文能帮到您,劳烦点个赞、在看支持一下哈👍! ⭐️我叫恒心,一名喜欢书写博客的研究生在读…...

零基础STM32单片机编程入门(七)定时器PWM波输出实战含源码视频
文章目录 一.概要二.PWM产生框架图三.CubeMX配置一个TIME输出1KHZ,占空比50%PWM波例程1.硬件准备2.创建工程3.测量波形结果 四.CubeMX工程源代码下载五.讲解视频链接地址六.小结 一.概要 脉冲宽度调制(PWM),是英文“Pulse Width Modulation”的缩写&…...

【ubuntu自启shell脚本】——在ubuntu中如何使用系统自带的启动应用程序设置开机自启自己的本地shell脚本
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、设置开机自启shell脚本1.使用 gnome-session-properties2.测试的shell例程代码 总结 前言 在Ubuntu系统中设置开机自启脚本是一种重要的自动化方法。开机自…...

麦橘超然Flux图像生成控制台快速部署:一键启动你的AI绘画服务
麦橘超然Flux图像生成控制台快速部署:一键启动你的AI绘画服务 1. 项目概述与核心优势 麦橘超然Flux图像生成控制台是一个基于DiffSynth-Studio构建的离线图像生成Web服务。它集成了majicflus_v1模型,采用float8量化技术,显著降低了显存占用…...

差动保护:电力系统的核心安全保障技术
差动保护电流差动保护是电力系统的"铁闸门",核心思想简单粗暴:比较设备两端的电流是否对得上账。就像两个会计同时记账,如果两边数据差太多,肯定有人搞鬼——要么线路漏电,要么设备内部短路。举个接地气的例…...

从理论到模型:HFSS仿真平面发夹滤波器的关键步骤与参数优化
1. HFSS仿真前的理论准备 在开始HFSS仿真之前,我们需要先完成一些理论计算工作。这就像盖房子要先画图纸一样,没有理论指导的仿真就像无头苍蝇。我刚开始做滤波器设计时就犯过这个错误,直接上手建模,结果调参调到怀疑人生。 平面发…...

B站硬核会员试炼的AI自动答题工具:从痛点到实践的完整指南
B站硬核会员试炼的AI自动答题工具:从痛点到实践的完整指南 【免费下载链接】bili-hardcore bilibili 硬核会员 AI 自动答题脚本,直接调用 B 站 API,非 OCR 实现 项目地址: https://gitcode.com/gh_mirrors/bi/bili-hardcore 一、痛点剖…...

城通网盘下载速度慢?试试ctfileGet,让你畅享本地高速解析体验
城通网盘下载速度慢?试试ctfileGet,让你畅享本地高速解析体验 【免费下载链接】ctfileGet 获取城通网盘一次性直连地址 项目地址: https://gitcode.com/gh_mirrors/ct/ctfileGet 在数字化办公与学习中,网盘已成为文件传输的重要工具。…...

C++ STL 容器选型实战:vector/list/map/unordered_map 性能对比与选型指南
一、前言:为什么容器选型是 C 工程的核心?在 C 后端开发、Qt 桌面应用、高性能服务器、嵌入式系统、游戏引擎、实时仿真、数据分析等几乎所有工业级项目中,STL 容器的选型直接决定程序性能、内存占用、可维护性与稳定性。很多开发者习惯随手写…...

虚拟手柄革命:用vJoy解锁游戏控制的无限可能
虚拟手柄革命:用vJoy解锁游戏控制的无限可能 【免费下载链接】vJoy Virtual Joystick 项目地址: https://gitcode.com/gh_mirrors/vj/vJoy 在数字娱乐的世界里,控制体验往往决定了游戏乐趣的深度。当物理手柄的限制束缚了你的创意,当键…...

3分钟找回遗忘QQ号:手机号查询QQ号Python工具终极指南
3分钟找回遗忘QQ号:手机号查询QQ号Python工具终极指南 【免费下载链接】phone2qq 项目地址: https://gitcode.com/gh_mirrors/ph/phone2qq 你是否曾经因为忘记QQ号而无法登录重要账号?当更换手机或电脑时,那个熟悉的数字突然从记忆中…...

基于PLC的五自由度抓取机械手设计
P13-基于PLC的五自由度抓取机械手设计 资料包含: PLC梯形图和HMI组态运行画面,I/O分配、CAD原理图、硬件设备清单、软件安装包、运行讲解视频、设计报告说明等,解难问题,全套资料通俗易懂非常适合新手PLC编程学习参考 功能介绍&am…...

GCC/Clang编译警告终极配置:用-Wall -Wextra提升代码质量的3个冷技巧
GCC/Clang编译警告终极配置:用-Wall -Wextra提升代码质量的3个冷技巧 在C/C开发中,编译警告常被视为"可以忽略的噪音",但经验丰富的开发者知道,这些警告往往是代码质量的早期预警系统。当你在深夜调试一个难以复现的内存…...