昇思MindSpore学习笔记4-03生成式--Diffusion扩散模型
摘要:
记录昇思MindSpore AI框架使用DDPM模型给图像数据正向逐步添加噪声,反向逐步去除噪声的工作原理和实际使用方法、步骤。
一、概念
1. 扩散模型Diffusion Models
DDPM(denoising diffusion probabilistic model)
(无)条件图像/音频/视频生成领域
Open-ai
GLIDE
DALL-E
海德堡大学
潜在扩散
Google Brain
图像生成
2. 扩散过程
固定(或预定义)正向扩散过程 q
将噪声从一些简单分布转换为数据样本
逐渐添加高斯噪声到图像中,得到纯噪声
学习反向去噪的扩散过程 p0
训练神经网络从纯噪声开始逐渐图像去噪,得到实际图像

3. 扩散模型实现原理
(1)正向过程
图片上加噪声
神经网络优化可控损失函数
真实数据分布q(x0)
由于 x0∼q(x0) ,采样获得图像x0
定义正向扩散过程q(xt|xt-1)
动态方差 0<β1<β2<...<βT<1 时间步长t
每个时间步长t添加高斯噪声
马尔科夫过程:
正态分布(高斯分布)定义参数
平均值μ
方差σ2 ≥0
每个时间步长t从条件高斯分布产生新的噪声图像
采样
设置
每个时间步长t不恒定
通过动态方差
每个时间步长的 是线性的、二次的、余弦的等
设置时间表,得到,...,
,...
t足够大时就是纯高斯噪声
(2)反向过程
条件概率分布
采样随机高斯噪声
逐渐去噪
得到真实分布 样本
神经网络近似学习条件概率分布 pθ(xt-1|xt)
神经网络参数θ
高斯分布参数:
由参数化的平均值
由参数化的方差
反向过程公式
平均值和方差取决于噪声水平t
神经网络通过学习来找到这些均值和方差
方差固定
神经网络只学习条件概率分布的平均值μθ
导出目标函数来学习反向过程的平均值
q和组合为变分自动编码器(VAE)
最小化真值数据样本的似然负对数
变分下界ELBO是每个时间步长的损失之和
每项损失是2个高斯分布之间的KL发散,除了
相对于均值的L2-loss!
构建Diffusion正向过程的直接结果条件下任意噪声水平采样
,
采样高斯噪声适当缩放添加到 直接获得
是已知
方差计划的函数,可以预先计算
训练期间随机采样t优化损失函数L的随机项
优点
重新参数化平均值
神经网络学习构成损失的KL项中噪声的附加噪声
神经网络成了噪声预测器,不是均值预测器
平均值计算:
目标函数Lt :
随机步长t由(ϵ∼N(0,I)) 给定
初始图像
ϵ时间步长t纯噪声采样
神经网络
基于真实噪声和预测高斯噪声之间的简单均方误差(MSE)优化神经网络
训练算法如下:

4. Net神经网络预测噪声
神经网络需要在特定时间步长接收带噪声的图像,并返回预测的噪声。
预测噪声是与输入图像具有相同大小/分辨率的张量。
网络接受并输出相同形状的张量。
自动编码器
编码器编码图像为"bottleneck"--较小的隐藏表示
解码器解码"bottleneck"回实际图像
残差连接改善梯度流

正向和反向过程在有限时间步长T(T=1000)内
从t=0开始,在数据分布中采样真实图像
使用ImageNet猫图像添加噪声
正向过程
每个时间步长t都采样一些高斯分布噪声
添加到上一个次图像中
足够大的T + 较好地添加噪声过程
t = T时得到各向同性高斯分布
二、环境准备
安装并导入所需的库MindSpore、download、dataset、matplotlib以及tqdm
%%capture captured_output
# 实验环境已经预装了mindspore==2.2.14,如需更换mindspore版本,可更改下面mindspore的版本号
!pip uninstall mindspore -y
!pip install -i https://pypi.mirrors.ustc.edu.cn/simple mindspore==2.2.14
# 查看当前 mindspore 版本
!pip show mindspore输出:
import math
from functools import partial
%matplotlib inline
import matplotlib.pyplot as plt
from tqdm.auto import tqdm
import numpy as np
from multiprocessing import cpu_count
from download import downloadimport mindspore as ms
import mindspore.nn as nn
import mindspore.ops as ops
from mindspore import Tensor, Parameter
from mindspore import dtype as mstype
from mindspore.dataset.vision import Resize, Inter, CenterCrop, ToTensor, RandomHorizontalFlip, ToPIL
from mindspore.common.initializer import initializer
from mindspore.amp import DynamicLossScalerms.set_seed(0)三、构建Diffusion模型
1.定义帮助函数和类
def rearrange(head, inputs):b, hc, x, y = inputs.shapec = hc // headreturn inputs.reshape((b, head, c, x * y))def rsqrt(x):res = ops.sqrt(x)return ops.inv(res)def randn_like(x, dtype=None):if dtype is None:dtype = x.dtyperes = ops.standard_normal(x.shape).astype(dtype)return resdef randn(shape, dtype=None):if dtype is None:dtype = ms.float32res = ops.standard_normal(shape).astype(dtype)return resdef randint(low, high, size, dtype=ms.int32):res = ops.uniform(size, Tensor(low, dtype), Tensor(high, dtype), dtype=dtype)return resdef exists(x):return x is not Nonedef default(val, d):if exists(val):return valreturn d() if callable(d) else ddef _check_dtype(d1, d2):if ms.float32 in (d1, d2):return ms.float32if d1 == d2:return d1raise ValueError('dtype is not supported.')class Residual(nn.Cell):def __init__(self, fn):super().__init__()self.fn = fndef construct(self, x, *args, **kwargs):return self.fn(x, *args, **kwargs) + x2.定义上采样和下采样操作的别名
def Upsample(dim):return nn.Conv2dTranspose(dim, dim, 4, 2, pad_mode="pad", padding=1)def Downsample(dim):return nn.Conv2d(dim, dim, 4, 2, pad_mode="pad", padding=1)3.位置向量
神经网络时间参数使用正弦位置嵌入来编码特定时间步长t
SinusoidalPositionEmbeddings模块
输入采用(batch_size, 1)形状的张量
批处理噪声图像、噪声水平
转换为(batch_size, dim)形状的张量
dim是位置嵌入尺寸
添加到每个剩余块中
class SinusoidalPositionEmbeddings(nn.Cell):def __init__(self, dim):super().__init__()self.dim = dimhalf_dim = self.dim // 2emb = math.log(10000) / (half_dim - 1)emb = np.exp(np.arange(half_dim) * - emb)self.emb = Tensor(emb, ms.float32)def construct(self, x):emb = x[:, None] * self.emb[None, :]emb = ops.concat((ops.sin(emb), ops.cos(emb)), axis=-1)return emb4.ResNet/ConvNeXT块
选择ConvNeXT块构建U-Net模型
class Block(nn.Cell):def __init__(self, dim, dim_out, groups=1):super().__init__()self.proj = nn.Conv2d(dim, dim_out, 3, pad_mode="pad", padding=1)self.proj = c(dim, dim_out, 3, padding=1, pad_mode='pad')self.norm = nn.GroupNorm(groups, dim_out)self.act = nn.SiLU()
def construct(self, x, scale_shift=None):x = self.proj(x)x = self.norm(x)
if exists(scale_shift):scale, shift = scale_shiftx = x * (scale + 1) + shift
x = self.act(x)return x
class ConvNextBlock(nn.Cell):def __init__(self, dim, dim_out, *, time_emb_dim=None, mult=2, norm=True):super().__init__()self.mlp = (nn.SequentialCell(nn.GELU(), nn.Dense(time_emb_dim, dim))if exists(time_emb_dim)else None)
self.ds_conv = nn.Conv2d(dim, dim, 7, padding=3, group=dim, pad_mode="pad")self.net = nn.SequentialCell(nn.GroupNorm(1, dim) if norm else nn.Identity(),nn.Conv2d(dim, dim_out * mult, 3, padding=1, pad_mode="pad"),nn.GELU(),nn.GroupNorm(1, dim_out * mult),nn.Conv2d(dim_out * mult, dim_out, 3, padding=1, pad_mode="pad"),)
self.res_conv = nn.Conv2d(dim, dim_out, 1) if dim != dim_out else nn.Identity()
def construct(self, x, time_emb=None):h = self.ds_conv(x)if exists(self.mlp) and exists(time_emb):assert exists(time_emb), "time embedding must be passed in"condition = self.mlp(time_emb)condition = condition.expand_dims(-1).expand_dims(-1)h = h + condition
h = self.net(h)return h + self.res_conv(x)5.Attention模块
multi-head self-attention
常规注意力中缩放
LinearAttention
时间和内存要求在序列长度上线性缩放
class Attention(nn.Cell):def __init__(self, dim, heads=4, dim_head=32):super().__init__()self.scale = dim_head ** -0.5self.heads = headshidden_dim = dim_head * heads
self.to_qkv = nn.Conv2d(dim, hidden_dim * 3, 1, pad_mode='valid', has_bias=False)self.to_out = nn.Conv2d(hidden_dim, dim, 1, pad_mode='valid', has_bias=True)self.map = ops.Map()self.partial = ops.Partial()
def construct(self, x):b, _, h, w = x.shapeqkv = self.to_qkv(x).chunk(3, 1)q, k, v = self.map(self.partial(rearrange, self.heads), qkv)
q = q * self.scale
# 'b h d i, b h d j -> b h i j'sim = ops.bmm(q.swapaxes(2, 3), k)attn = ops.softmax(sim, axis=-1)# 'b h i j, b h d j -> b h i d'out = ops.bmm(attn, v.swapaxes(2, 3))out = out.swapaxes(-1, -2).reshape((b, -1, h, w))
return self.to_out(out)
class LayerNorm(nn.Cell):def __init__(self, dim):super().__init__()self.g = Parameter(initializer('ones', (1, dim, 1, 1)), name='g')
def construct(self, x):eps = 1e-5var = x.var(1, keepdims=True)mean = x.mean(1, keep_dims=True)return (x - mean) * rsqrt((var + eps)) * self.g
class LinearAttention(nn.Cell):def __init__(self, dim, heads=4, dim_head=32):super().__init__()self.scale = dim_head ** -0.5self.heads = headshidden_dim = dim_head * headsself.to_qkv = nn.Conv2d(dim, hidden_dim * 3, 1, pad_mode='valid', has_bias=False)
self.to_out = nn.SequentialCell(nn.Conv2d(hidden_dim, dim, 1, pad_mode='valid', has_bias=True),LayerNorm(dim))
self.map = ops.Map()self.partial = ops.Partial()
def construct(self, x):b, _, h, w = x.shapeqkv = self.to_qkv(x).chunk(3, 1)q, k, v = self.map(self.partial(rearrange, self.heads), qkv)
q = ops.softmax(q, -2)k = ops.softmax(k, -1)
q = q * self.scalev = v / (h * w)
# 'b h d n, b h e n -> b h d e'context = ops.bmm(k, v.swapaxes(2, 3))# 'b h d e, b h d n -> b h e n'out = ops.bmm(context.swapaxes(2, 3), q)
out = out.reshape((b, -1, h, w))return self.to_out(out)6.组归一化
U-Net卷积/注意层与群归一化
定义PreNorm类
在注意层之前应用groupnorm
class PreNorm(nn.Cell):def __init__(self, dim, fn):super().__init__()self.fn = fnself.norm = nn.GroupNorm(1, dim)
def construct(self, x):x = self.norm(x)return self.fn(x)7.条件U-Net
网络
输入
噪声图像,(batch_size, num_channels, height, width)形状
噪音水平,(batch_size, 1)形状
输出
噪声,(batch_size, num_channels, height, width)形状的张量
8.网络构建过程
噪声图像批上应用卷积层
计算噪声水平位置
应用一系列下采样级
每个下采样阶段
2个ResNet/ConvNeXT块
Groupnorm
Attention
残差连接
一个下采样操作
应用ResNet或ConvNeXT块
交织attention
应用一系列上采样级
每个上采样级
2个ResNet/ConvNeXT块
Groupnorm
Attention
残差连接
一个上采样操作
应用ResNet/ConvNeXT块
应用卷积层
class Unet(nn.Cell):def __init__(self,dim,init_dim=None,out_dim=None,dim_mults=(1, 2, 4, 8),channels=3,with_time_emb=True,convnext_mult=2,):super().__init__()
self.channels = channels
init_dim = default(init_dim, dim // 3 * 2)self.init_conv = nn.Conv2d(channels, init_dim, 7, padding=3, pad_mode="pad", has_bias=True)
dims = [init_dim, *map(lambda m: dim * m, dim_mults)]in_out = list(zip(dims[:-1], dims[1:]))
block_klass = partial(ConvNextBlock, mult=convnext_mult)
if with_time_emb:time_dim = dim * 4self.time_mlp = nn.SequentialCell(SinusoidalPositionEmbeddings(dim),nn.Dense(dim, time_dim),nn.GELU(),nn.Dense(time_dim, time_dim),)else:time_dim = Noneself.time_mlp = None
self.downs = nn.CellList([])self.ups = nn.CellList([])num_resolutions = len(in_out)
for ind, (dim_in, dim_out) in enumerate(in_out):is_last = ind >= (num_resolutions - 1)
self.downs.append(nn.CellList([block_klass(dim_in, dim_out, time_emb_dim=time_dim),block_klass(dim_out, dim_out, time_emb_dim=time_dim),Residual(PreNorm(dim_out, LinearAttention(dim_out))),Downsample(dim_out) if not is_last else nn.Identity(),]))
mid_dim = dims[-1]self.mid_block1 = block_klass(mid_dim, mid_dim, time_emb_dim=time_dim)self.mid_attn = Residual(PreNorm(mid_dim, Attention(mid_dim)))self.mid_block2 = block_klass(mid_dim, mid_dim, time_emb_dim=time_dim)
for ind, (dim_in, dim_out) in enumerate(reversed(in_out[1:])):is_last = ind >= (num_resolutions - 1)
self.ups.append(nn.CellList([block_klass(dim_out * 2, dim_in, time_emb_dim=time_dim),block_klass(dim_in, dim_in, time_emb_dim=time_dim),Residual(PreNorm(dim_in, LinearAttention(dim_in))),Upsample(dim_in) if not is_last else nn.Identity(),]))
out_dim = default(out_dim, channels)self.final_conv = nn.SequentialCell(block_klass(dim, dim), nn.Conv2d(dim, out_dim, 1))
def construct(self, x, time):x = self.init_conv(x)
t = self.time_mlp(time) if exists(self.time_mlp) else None
h = []
for block1, block2, attn, downsample in self.downs:x = block1(x, t)x = block2(x, t)x = attn(x)h.append(x)
x = downsample(x)
x = self.mid_block1(x, t)x = self.mid_attn(x)x = self.mid_block2(x, t)
len_h = len(h) - 1for block1, block2, attn, upsample in self.ups:x = ops.concat((x, h[len_h]), 1)len_h -= 1x = block1(x, t)x = block2(x, t)x = attn(x)
x = upsample(x)return self.final_conv(x)四、正向扩散
1.定义T时间步的时间表
def linear_beta_schedule(timesteps):beta_start = 0.0001beta_end = 0.02return np.linspace(beta_start, beta_end, timesteps).astype(np.float32)首先使用T = 200时间步长的线性计划
定义的各种变量
方差 的累积乘积
每个变量都是一维张量,存储t到T的值
extract函数,批量提取t索引
# 扩散200步
timesteps = 200
# 定义 beta schedule
betas = linear_beta_schedule(timesteps=timesteps)
# 定义 alphas
alphas = 1. - betas
alphas_cumprod = np.cumprod(alphas, axis=0)
alphas_cumprod_prev = np.pad(alphas_cumprod[:-1], (1, 0), constant_values=1)
sqrt_recip_alphas = Tensor(np.sqrt(1. / alphas))
sqrt_alphas_cumprod = Tensor(np.sqrt(alphas_cumprod))
sqrt_one_minus_alphas_cumprod = Tensor(np.sqrt(1. - alphas_cumprod))
# 计算 q(x_{t-1} | x_t, x_0)
posterior_variance = betas * (1. - alphas_cumprod_prev) / (1. - alphas_cumprod)
p2_loss_weight = (1 + alphas_cumprod / (1 - alphas_cumprod)) ** -0.
p2_loss_weight = Tensor(p2_loss_weight)
def extract(a, t, x_shape):b = t.shape[0]out = Tensor(a).gather(t, -1)return out.reshape(b, *((1,) * (len(x_shape) - 1)))2.扩散过程的每个时间步给猫图像添加噪音
# 下载猫猫图像
url = 'https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/image_cat.zip'
path = download(url, './', kind="zip", replace=True)输出:
Downloading data from https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/image_cat.zip (170 kB)file_sizes: 100%|████████████████████████████| 174k/174k [00:00<00:00, 1.45MB/s]
Extracting zip file...
Successfully downloaded / unzipped to ./from PIL import Image
image = Image.open('./image_cat/jpg/000000039769.jpg')
base_width = 160
image = image.resize((base_width, int(float(image.size[1]) * float(base_width / float(image.size[0])))))
image.show()输出:

添加噪声到mindspore张量
定义图像转换
从PIL图像转换到mindspore张量
除以255标准化图像,确保在[-1,1]范围内(假设图像数据由{0,1,...,255}中的整数组成)
from mindspore.dataset import ImageFolderDataset
image_size = 128
transforms = [Resize(image_size, Inter.BILINEAR),CenterCrop(image_size),ToTensor(),lambda t: (t * 2) - 1
]
path = './image_cat'
dataset = ImageFolderDataset(dataset_dir=path, num_parallel_workers=cpu_count(),extensions=['.jpg', '.jpeg', '.png', '.tiff'],num_shards=1, shard_id=0, shuffle=False, decode=True)
dataset = dataset.project('image')
transforms.insert(1, RandomHorizontalFlip())
dataset_1 = dataset.map(transforms, 'image')
dataset_2 = dataset_1.batch(1, drop_remainder=True)
x_start = next(dataset_2.create_tuple_iterator())[0]
print(x_start.shape)输出:
(1, 3, 128, 128)3.定义反向变换
输入一个包在[−1,1]中的张量
输出PIL图像
import numpy as np
reverse_transform = [lambda t: (t + 1) / 2,lambda t: ops.permute(t, (1, 2, 0)), # CHW to HWClambda t: t * 255.,lambda t: t.asnumpy().astype(np.uint8),ToPIL()
]
def compose(transform, x):for d in transform:x = d(x)return x验证:
reverse_image = compose(reverse_transform, x_start[0])
reverse_image.show()输出:

4.定义正向扩散过程
def q_sample(x_start, t, noise=None):if noise is None:noise = randn_like(x_start)return (extract(sqrt_alphas_cumprod, t, x_start.shape) * x_start +extract(sqrt_one_minus_alphas_cumprod, t, x_start.shape) * noise)测试:
def get_noisy_image(x_start, t):# 添加噪音x_noisy = q_sample(x_start, t=t)
# 转换为 PIL 图像noisy_image = compose(reverse_transform, x_noisy[0])
return noisy_image
[18]:# 设置 time step
t = Tensor([40])
noisy_image = get_noisy_image(x_start, t)
print(noisy_image)
noisy_image.show()输出:
<PIL.Image.Image image mode=RGB size=128x128 at 0x7F54569F3950>
显示不同的时间步骤:
import matplotlib.pyplot as plt
def plot(imgs, with_orig=False, row_title=None, **imshow_kwargs):if not isinstance(imgs[0], list):imgs = [imgs]
num_rows = len(imgs)num_cols = len(imgs[0]) + with_orig_, axs = plt.subplots(figsize=(200, 200), nrows=num_rows, ncols=num_cols, squeeze=False)for row_idx, row in enumerate(imgs):row = [image] + row if with_orig else rowfor col_idx, img in enumerate(row):ax = axs[row_idx, col_idx]ax.imshow(np.asarray(img), **imshow_kwargs)ax.set(xticklabels=[], yticklabels=[], xticks=[], yticks=[])
if with_orig:axs[0, 0].set(title='Original image')axs[0, 0].title.set_size(8)if row_title is not None:for row_idx in range(num_rows):axs[row_idx, 0].set(ylabel=row_title[row_idx])
plt.tight_layout()
[20]:plot([get_noisy_image(x_start, Tensor([t])) for t in [0, 50, 100, 150, 199]])
定义损失函数:
def p_losses(unet_model, x_start, t, noise=None):if noise is None:noise = randn_like(x_start)x_noisy = q_sample(x_start=x_start, t=t, noise=noise)predicted_noise = unet_model(x_noisy, t)
loss = nn.SmoothL1Loss()(noise, predicted_noise)# todoloss = loss.reshape(loss.shape[0], -1)loss = loss * extract(p2_loss_weight, t, loss.shape)return loss.mean()五、数据准备与处理
1.下载数据集
Fashion-MNIST图像
线性缩放为 [−1,1]
相同图像大小28x28
随机水平翻转
使用download下载
解压到指定路径./
# 下载MNIST数据集
url = 'https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/dataset.zip'
path = download(url, './', kind="zip", replace=True)输出:
Downloading data from https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/dataset.zip (29.4 MB)file_sizes: 100%|██████████████████████████| 30.9M/30.9M [00:00<00:00, 43.4MB/s]
Extracting zip file...
Successfully downloaded / unzipped to ./from mindspore.dataset import FashionMnistDataset
image_size = 28
channels = 1
batch_size = 16
fashion_mnist_dataset_dir = "./dataset"
dataset = FashionMnistDataset(dataset_dir=fashion_mnist_dataset_dir, usage="train", num_parallel_workers=cpu_count(), shuffle=True, num_shards=1, shard_id=0)2.定义transform操作
图像预处理
随机水平翻转
重新调整
值在 [−1,1]范围内
transforms = [RandomHorizontalFlip(),ToTensor(),lambda t: (t * 2) - 1
]
dataset = dataset.project('image')
dataset = dataset.shuffle(64)
dataset = dataset.map(transforms, 'image')
dataset = dataset.batch(16, drop_remainder=True)x = next(dataset.create_dict_iterator())
print(x.keys())输出:
dict_keys(['image'])3.采样
在训练期间从模型中采样。
采样算法2:

反转扩散过程
从T开始,采样高斯分布纯噪声
神经网络使用条件概率逐渐去噪,时间步t=0结束
重新参数化
噪声预测器插入平均值
导出降噪程度较低的图像xt-1
得到一个近似真实数据分布的图像
def p_sample(model, x, t, t_index):betas_t = extract(betas, t, x.shape)sqrt_one_minus_alphas_cumprod_t = extract(sqrt_one_minus_alphas_cumprod, t, x.shape)sqrt_recip_alphas_t = extract(sqrt_recip_alphas, t, x.shape)model_mean = sqrt_recip_alphas_t * (x - betas_t * model(x, t) / sqrt_one_minus_alphas_cumprod_t)
if t_index == 0:return model_meanposterior_variance_t = extract(posterior_variance, t, x.shape)noise = randn_like(x)return model_mean + ops.sqrt(posterior_variance_t) * noise
def p_sample_loop(model, shape):b = shape[0]# 从纯噪声开始img = randn(shape, dtype=None)imgs = []
for i in tqdm(reversed(range(0, timesteps)), desc='sampling loop time step', total=timesteps):img = p_sample(model, img, ms.numpy.full((b,), i, dtype=mstype.int32), i)imgs.append(img.asnumpy())return imgs
def sample(model, image_size, batch_size=16, channels=3):return p_sample_loop(model, shape=(batch_size, channels, image_size, image_size))六、训练过程
# 定义动态学习率
lr = nn.cosine_decay_lr(min_lr=1e-7, max_lr=1e-4, total_step=10*3750, step_per_epoch=3750, decay_epoch=10)
# 定义 Unet模型
unet_model = Unet(dim=image_size,channels=channels,dim_mults=(1, 2, 4,)
)
name_list = []
for (name, par) in list(unet_model.parameters_and_names()):name_list.append(name)
i = 0
for item in list(unet_model.trainable_params()):item.name = name_list[i]i += 1
# 定义优化器
optimizer = nn.Adam(unet_model.trainable_params(), learning_rate=lr)
loss_scaler = DynamicLossScaler(65536, 2, 1000)
# 定义正向过程
def forward_fn(data, t, noise=None):loss = p_losses(unet_model, data, t, noise)return loss
# 计算梯度
grad_fn = ms.value_and_grad(forward_fn, None, optimizer.parameters, has_aux=False)
# 梯度更新
def train_step(data, t, noise):loss, grads = grad_fn(data, t, noise)optimizer(grads)return lossimport time
# 由于时间原因,epochs设置为1,可根据需求进行调整
epochs = 1
for epoch in range(epochs):begin_time = time.time()for step, batch in enumerate(dataset.create_tuple_iterator()):unet_model.set_train()batch_size = batch[0].shape[0]t = randint(0, timesteps, (batch_size,), dtype=ms.int32)noise = randn_like(batch[0])loss = train_step(batch[0], t, noise)
if step % 500 == 0:print(" epoch: ", epoch, " step: ", step, " Loss: ", loss)end_time = time.time()times = end_time - begin_timeprint("training time:", times, "s")# 展示随机采样效果unet_model.set_train(False)samples = sample(unet_model, image_size=image_size, batch_size=64, channels=channels)plt.imshow(samples[-1][5].reshape(image_size, image_size, channels), cmap="gray")
print("Training Success!")输出:
epoch: 0 step: 0 Loss: 0.43375123epoch: 0 step: 500 Loss: 0.113769315epoch: 0 step: 1000 Loss: 0.08649178epoch: 0 step: 1500 Loss: 0.067664884epoch: 0 step: 2000 Loss: 0.07234038epoch: 0 step: 2500 Loss: 0.043936778epoch: 0 step: 3000 Loss: 0.058127824epoch: 0 step: 3500 Loss: 0.049789283
training time: 922.3438229560852 sepoch: 1 step: 0 Loss: 0.05088563epoch: 1 step: 500 Loss: 0.051174678epoch: 1 step: 1000 Loss: 0.04455947epoch: 1 step: 1500 Loss: 0.055165425epoch: 1 step: 2000 Loss: 0.043942295epoch: 1 step: 2500 Loss: 0.03274461epoch: 1 step: 3000 Loss: 0.048117325epoch: 1 step: 3500 Loss: 0.063063145
training time: 937.5596783161163 sepoch: 2 step: 0 Loss: 0.052893892epoch: 2 step: 500 Loss: 0.05721748epoch: 2 step: 1000 Loss: 0.057248186epoch: 2 step: 1500 Loss: 0.048806388epoch: 2 step: 2000 Loss: 0.05007638epoch: 2 step: 2500 Loss: 0.04337231epoch: 2 step: 3000 Loss: 0.043207955epoch: 2 step: 3500 Loss: 0.034530163
training time: 947.6374666690826 sepoch: 3 step: 0 Loss: 0.04867614epoch: 3 step: 500 Loss: 0.051636297epoch: 3 step: 1000 Loss: 0.03338969epoch: 3 step: 1500 Loss: 0.0420174epoch: 3 step: 2000 Loss: 0.052145053epoch: 3 step: 2500 Loss: 0.03905913epoch: 3 step: 3000 Loss: 0.07621498epoch: 3 step: 3500 Loss: 0.06484105
training time: 957.7780408859253 sepoch: 4 step: 0 Loss: 0.046281893epoch: 4 step: 500 Loss: 0.03783619epoch: 4 step: 1000 Loss: 0.0587488epoch: 4 step: 1500 Loss: 0.06974746epoch: 4 step: 2000 Loss: 0.04299112epoch: 4 step: 2500 Loss: 0.027945498epoch: 4 step: 3000 Loss: 0.045338146epoch: 4 step: 3500 Loss: 0.06362417
training time: 955.6116819381714 sepoch: 5 step: 0 Loss: 0.04781142epoch: 5 step: 500 Loss: 0.032488734epoch: 5 step: 1000 Loss: 0.061507083epoch: 5 step: 1500 Loss: 0.039130375epoch: 5 step: 2000 Loss: 0.034972396epoch: 5 step: 2500 Loss: 0.039485026epoch: 5 step: 3000 Loss: 0.06690869epoch: 5 step: 3500 Loss: 0.05355365
training time: 951.7758958339691 sepoch: 6 step: 0 Loss: 0.04807706epoch: 6 step: 500 Loss: 0.021469856epoch: 6 step: 1000 Loss: 0.035354104epoch: 6 step: 1500 Loss: 0.044303045epoch: 6 step: 2000 Loss: 0.040063944epoch: 6 step: 2500 Loss: 0.02970439epoch: 6 step: 3000 Loss: 0.041152682epoch: 6 step: 3500 Loss: 0.02062454
training time: 955.2220208644867 sepoch: 7 step: 0 Loss: 0.029668871epoch: 7 step: 500 Loss: 0.028485576epoch: 7 step: 1000 Loss: 0.029675964epoch: 7 step: 1500 Loss: 0.052743085epoch: 7 step: 2000 Loss: 0.03664278epoch: 7 step: 2500 Loss: 0.04454907epoch: 7 step: 3000 Loss: 0.043067697epoch: 7 step: 3500 Loss: 0.0619511
training time: 952.6654670238495 sepoch: 8 step: 0 Loss: 0.055328347epoch: 8 step: 500 Loss: 0.035807922epoch: 8 step: 1000 Loss: 0.026412832epoch: 8 step: 1500 Loss: 0.051044375epoch: 8 step: 2000 Loss: 0.05474911epoch: 8 step: 2500 Loss: 0.044595096epoch: 8 step: 3000 Loss: 0.034082986epoch: 8 step: 3500 Loss: 0.02653109
training time: 961.9374921321869 sepoch: 9 step: 0 Loss: 0.039675284epoch: 9 step: 500 Loss: 0.046295933epoch: 9 step: 1000 Loss: 0.031403508epoch: 9 step: 1500 Loss: 0.028816734epoch: 9 step: 2000 Loss: 0.06530296epoch: 9 step: 2500 Loss: 0.051451046epoch: 9 step: 3000 Loss: 0.037913296epoch: 9 step: 3500 Loss: 0.030541396
training time: 974.643147945404 s
Training Success!
七、推理过程(从模型中采样)
从模型中采样,只使用上面定义的采样函数:
# 采样64个图片
unet_model.set_train(False)
samples = sample(unet_model, image_size=image_size, batch_size=64, channels=channels)输出:
sampling loop time step: 0%| | 0/200 [00:00<?, ?it/s]# 展示一个随机效果
random_index = 5
plt.imshow(samples[-1][random_index].reshape(image_size, image_size, channels), cmap="gray")cmap="gray")
输出:
<matplotlib.image.AxesImage at 0x7f5175ea1690>
这个模型产生一件衣服!
创建去噪过程的gif:
import matplotlib.animation as animation
random_index = 53
fig = plt.figure()
ims = []
for i in range(timesteps):im = plt.imshow(samples[i][random_index].reshape(image_size, image_size, channels), cmap="gray", animated=True)ims.append([im])
animate = animation.ArtistAnimation(fig, ims, interval=50, blit=True, repeat_delay=100)
animate.save('diffusion.gif')
plt.show()输出:

相关文章:
昇思MindSpore学习笔记4-03生成式--Diffusion扩散模型
摘要: 记录昇思MindSpore AI框架使用DDPM模型给图像数据正向逐步添加噪声,反向逐步去除噪声的工作原理和实际使用方法、步骤。 一、概念 1. 扩散模型Diffusion Models DDPM(denoising diffusion probabilistic model) (无)条件…...

Go:hello world
开启转职->Go开发工程师 下面是我的第一个go的程序 在上面的程序介绍: 1、package main 第一行代码package main定义了包名。必须在源文件中非注释的第一行指明这个文件属于哪个包,如:package main。package main表示一个可独立执行的程…...

JVM专题之内存模型以及如何判定对象已死问题
体验与验证 2.4.5.1 使用visualvm **visualgc插件下载链接 :https://visualvm.github.io/pluginscenters.html https://visualvm.github.io/pluginscenters.html **选择对应JDK版本链接--->Tools--->Visual GC** 2.4.5.2 堆内存溢出 * **代码** java @RestCont…...

vscode使用Git的常用操作
主打一个实用 查看此篇之前请先保证电脑安装了Git,安装教程很多,可自行搜索 一.初始化本地仓库🔴 使用vscode打开项目文件夹如图所使初始化仓库,相当于命令行的git init 二.提交到暂存区🔴 二.提交到新版本…...

RPC与REST
RPC与REST 访问远程服务1远程服务调用(Remote Procedure Call,RPC):RPC 解决什么问题?如何解决的?为什么要那样解决?1.1 先解决两个进程间如何交换数据的问题,也就是进程间通信&…...

计数排序的实现
原理 对一个数组进行遍历,再创建一个count数组 每找到一个值则在count数组中对应的位置加一,再在count数组中找到数字上方的count值,count值为几,则打印几次数组中的值. 开空间 相对映射 排序的实现 void CountSort(int* a, i…...

【Qt】QTableWidget设置可以选择多行多列,并能复制选择的内容到剪贴板
比如有一个 QTableWidget*m_tbwQuery m_tbwQuery->installEventFilter(this); //进行事件过滤处理//设置可以选择多行多列 m_tbwQuery->setSelectionMode(QAbstractItemView::MultiSelection); m_tbwQuery->setSelectionBehavior(QAbstractItemView::SelectItems); …...

跨越界限的温柔坚守
跨越界限的温柔坚守 —— 郑乃馨与男友的甜蜜抉择在这个光怪陆离、瞬息万变的娱乐圈里,每一段恋情像是夜空中划过的流星,璀璨短暂。然而,当“郑乃馨与男友甜蜜约会”的消息再次跃入公众视野,它不仅仅是一段简单的爱情故事…...

Vue3 对于内嵌Iframe组件进行缓存
1:应用场景 对于系统内所有内嵌iframe 的页面均通过同一个路由/iframe, 在router.query内传入不同src 参数,在同一组件内显示iframe 内嵌页面,对这些页面分别进行缓存。主要是通过v-show 控制显示隐藏从而达到iframe 缓存逻辑 2:…...

L04_MySQL知识图谱
这些知识点你都掌握了吗?大家可以对着问题看下自己掌握程度如何?对于没掌握的知识点,大家自行网上搜索,都会有对应答案,本文不做知识点详细说明,只做简要文字或图示引导。 1 基础 1.1内部组件结构 1.2 数据…...

什么是CNN,它和传统机器学习有什么区别
CNN,全称为卷积神经网络(Convolutional Neural Networks),是一种专门用于处理具有网格结构数据(如图像、视频)的深度学习模型。它由多个卷积层、池化层、全连接层等组成,通过卷积运算和池化操作…...

游戏开发面试题3
unity如何判断子弹射击到敌人,如果子弹特别快怎么办 使用物理学碰撞检测。使用Unity的物理组件,如Rigidbody和Collider,将子弹和敌人都设置为有一定的物理碰撞属性,当子弹碰到敌人的时候,就会触发OnCollisionEnter()事…...
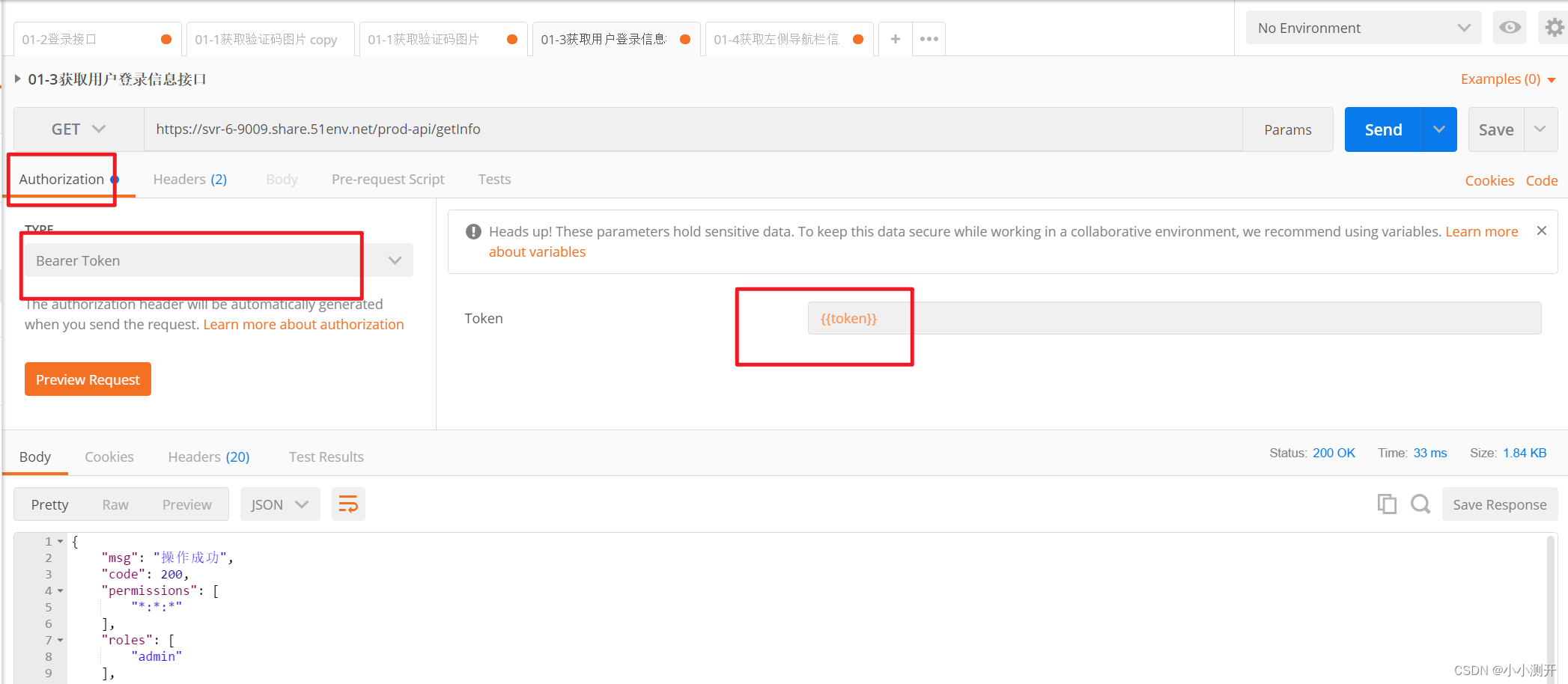
postman请求访问:认证失败,无法访问系统资源
1、使用postman时,没有传入相应的token,就会出现这种情况,此时需要把token放进去 发现问题: { "msg": "请求访问:/getInfo,认证失败,无法访问系统资源", "code": 401 } 1…...

Apache Seata新特性支持 -- undo_log压缩
本文来自 Apache Seata官方文档,欢迎访问官网,查看更多深度文章。 本文来自 Apache Seata官方文档,欢迎访问官网,查看更多深度文章。 Apache Seata新特性支持 – undo_log压缩 Seata新特性支持 – undo_log压缩 现状 & 痛点…...

Java中的软件架构重构与升级策略
Java中的软件架构重构与升级策略 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿! 重构与升级的背景和意义 软件架构在应用开发中起着至关重要的作用。随着技术…...

设置Docker中时区不生效的问题
项目中使用docker-compose,并通过以下方式设置了时区 environment:- SET_CONTAINER_TIMEZONEtrue- CONTAINER_TIMEZONEAsia/Shanghai 但是并没有正确生效,网上有很多博客都在推荐这个做法,另外一种是使用标准环境标量 -TZAsia/Shangehai …...

LeetCode436:寻找右区间
题目链接:436. 寻找右区间 - 力扣(LeetCode) class Solution { public:vector<int> findRightInterval(vector<vector<int>>& intervals) {vector<pair<int, int>> startIntervals;int n intervals.size…...
前端JS特效第22集:html5音乐旋律自定义交互特效
html5音乐旋律自定义交互特效,先来看看效果: 部分核心的代码如下(全部代码在文章末尾): <!DOCTYPE html> <html lang"en" > <head> <meta charset"UTF-8"> <title>ChimeTime™</title…...

pyrender 离线渲染包安装教程
pyrender 离线渲染包安装教程 安装 安装 官方安装教程:https://pyrender.readthedocs.io/en/latest/install/index.html#installmesa 首先 pip install pyrenderclang6.0安装 下载地址:https://releases.llvm.org/download.html#6.0.0 注意下好是叫:clangllvm-6…...

XSS平台的搭建
第一步:安装MySQL 数据库 因为xss平台涉及到使用mysql 数据库,在安装之前,先使用docker 安装mysql 数据库。 docker run --name mysqlserver -e MYSQL_ROOT_PASSWORD123 -d -i -p 3309:3306 mysql:5.6 第二步:安装xssplatform…...

Qwen-Image-Edit-2511商业落地:快速生成产品设计图,提升工作效率
Qwen-Image-Edit-2511商业落地:快速生成产品设计图,提升工作效率 1. 产品设计效率的革命性提升 在当今快节奏的商业环境中,产品设计团队面临着前所未有的压力:需要在更短时间内交付更多设计方案,同时保持高质量和创新…...

Excel VBA 技巧:让工作表中的形状宏自适应
在日常工作中,Excel 不仅仅是数据处理的工具,更是我们自动化办公的利器。今天我们要探讨的是如何让Excel工作表中的形状宏能够自适应地工作,即使在复制工作表到新的工作簿时也能保持其功能性。 问题背景 假设我们有一个工作簿BOOK1,其中包含一个名为TEST的工作表和一个名…...

Hunyuan-MT-7B翻译模型部署:Docker环境隔离实战解析
Hunyuan-MT-7B翻译模型部署:Docker环境隔离实战解析 想让一个支持33种语言互译、性能顶尖的70亿参数大模型,在你的电脑上“一键启动”吗?听起来像是实验室里的高端玩具,但今天我要告诉你,通过Docker,这完全…...

Lychee-Rerank实战案例:专利文献检索中权利要求与技术方案的语义匹配
Lychee-Rerank实战案例:专利文献检索中权利要求与技术方案的语义匹配 1. 引言:当专利检索遇上语义匹配难题 如果你是专利工程师、知识产权分析师,或者从事技术研发工作,一定遇到过这样的场景:面对海量的专利文献&…...

Lux测试框架完整指南:如何编写高效的数据可视化测试用例
Lux测试框架完整指南:如何编写高效的数据可视化测试用例 【免费下载链接】lux Automatically visualize your pandas dataframe via a single print! 📊 💡 项目地址: https://gitcode.com/gh_mirrors/lux/lux Lux是一个强大的Python数…...

Klipper固件全攻略:从配置到优化解决3D打印核心难题
Klipper固件全攻略:从配置到优化解决3D打印核心难题 【免费下载链接】klipper Klipper is a 3d-printer firmware 项目地址: https://gitcode.com/GitHub_Trending/kl/klipper 3D打印技术面临精度不足、振动干扰和配置复杂等挑战,Klipper固件通过…...

盈鹏飞T527评估板AHD摄像头实战:从硬件连接到QT界面调试全流程
盈鹏飞T527评估板AHD摄像头全流程开发指南:从硬件对接到QT界面优化 在嵌入式视觉系统开发中,AHD摄像头因其长距离传输优势成为安防、工业检测等场景的首选。盈鹏飞T527评估板搭载全志T527处理器,通过TP2815转换板实现四路AHD摄像头接入&#…...

基于LCL滤波器的光伏三相逆变并网模型 1.模型由光伏系统,逆变器,LCL滤波器和交流主网组成 2
基于LCL滤波器的光伏三相逆变并网模型1.模型由光伏系统,逆变器,LCL滤波器和交流主网组成 2.光伏采用扰动观测法实现最大功率输出,逆变器采用恒定直流母线电压控制策略 实现以下目标: 1.光伏维持在最大功率输出。 2.逆变器实现直流…...

微信小程序助力老年智能评估,Pillow高级实战案例:图像处理的进阶应用。
基于微信小程序的关爱老年人在线能力评估系统设计 系统背景与意义 随着老龄化社会进程加速,老年人能力评估成为养老服务的重要环节。传统纸质评估方式效率低、数据难留存。基于微信小程序的在线评估系统可实现便捷化、标准化评估,提升养老服务智能化水平…...

单片机驱动MOS管的原理与实战技巧
1. 单片机直接驱动MOS管的原理与风险MOS管作为现代电子设计中最常用的功率开关器件,其控制方式看似简单却暗藏玄机。作为一名经历过多次"炸管"教训的硬件工程师,我想分享一些关于单片机直接驱动MOS管的实战经验。MOS管分为NMOS和PMOS两种类型&…...