Java for循环嵌套for循环,你需要懂的代码性能优化技巧
前言
本篇分析的技巧点其实是比较常见的,但是最近的几次的代码评审还是发现有不少兄弟没注意到。
所以还是想拿出来说下。
正文
是个什么场景呢?
就是 for循环 里面还有 for循环, 然后做一些数据匹配、处理 这种场景。
我们结合实例代码来看看。
场景示例:
比如我们现在拿到两个list 数据 ,
一个是 User List 集合 ;
另一个是 UserMemo List集合;
我们需要遍历 User List ,然后根据 userId 从 UserMemo List 里面取出 对应这个userId 的 content 值,做数据处理。
代码 User.java :
import lombok.Data;@Data
public class User {private Long userId;private String name;
}
代码 UserMemo.java :
import lombok.Data;@Data
public class UserMemo {private Long userId;private String content;
}
模拟 数据集合 :
5W 条 user 数据 , 3W条 userMemo数据
public static List<User> getUserTestList() {List<User> users = new ArrayList<>();for (int i = 1; i <= 50000; i++) {User user = new User();user.setName(UUID.randomUUID().toString());user.setUserId((long) i);users.add(user);}return users;}public static List<UserMemo> getUserMemoTestList() {List<UserMemo> userMemos = new ArrayList<>();for (int i = 30000; i >= 1; i--) {UserMemo userMemo = new UserMemo();userMemo.setContent(UUID.randomUUID().toString());userMemo.setUserId((long) i);userMemos.add(userMemo);}return userMemos;}先看平时大家不注意的时候可能会这样去写代码处理 :
ps: 其实数据量小的话,其实没多大性能差别,不过我们还是需要知道一些技巧点。
代码:
public static void main(String[] args) {List<User> userTestList = getUserTestList();List<UserMemo> userMemoTestList = getUserMemoTestList();StopWatch stopWatch = new StopWatch();stopWatch.start();for (User user : userTestList) {Long userId = user.getUserId();for (UserMemo userMemo : userMemoTestList) {if (userId.equals(userMemo.getUserId())) {String content = userMemo.getContent();System.out.println("模拟数据content 业务处理......"+content);}}}stopWatch.stop();System.out.println("最终耗时"+stopWatch.getTotalTimeMillis());}我们来看看 这时候的一个耗时情况 :
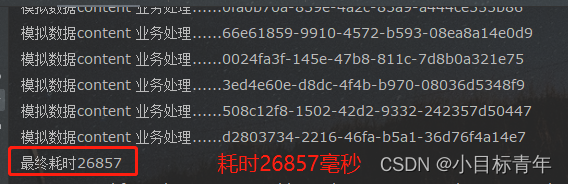
相当于迭代了 5W * 3W 次
可以看到用时 是 26857毫秒
其实到这,插入个题外点,如果说每个userId 在 UserMemo List 里面 都是只有一条数据的场景。
for (User user : userTestList) {Long userId = user.getUserId();for (UserMemo userMemo : userMemoTestList) {if (userId.equals(userMemo.getUserId())) {String content = userMemo.getContent();System.out.println("模拟数据content 业务处理......"+content);}}}单从这段代码有没有问题 ,有没有优化点。
显然是有的, 因为当我们从内循环UserMemo List里面找到匹配数据的时候, 没有做其他操作了。
这样 内for循环会继续下,直到跑完再进行下一轮整体循环。
所以,仅针对这种情形,1对1的或者说我们只需要找到一个匹配项,处理完后我们 应该使用 break 。
我们来看看 加上 break 的一个耗时情况 :
代码:
public static void main(String[] args) {List<User> userTestList = getUserTestList();List<UserMemo> userMemoTestList = getUserMemoTestList();StopWatch stopWatch = new StopWatch();stopWatch.start();for (User user : userTestList) {Long userId = user.getUserId();for (UserMemo userMemo : userMemoTestList) {if (userId.equals(userMemo.getUserId())) {String content = userMemo.getContent();System.out.println("模拟数据content 业务处理......"+content);break;}}}stopWatch.stop();System.out.println("最终耗时"+stopWatch.getTotalTimeMillis());}
耗时情况:
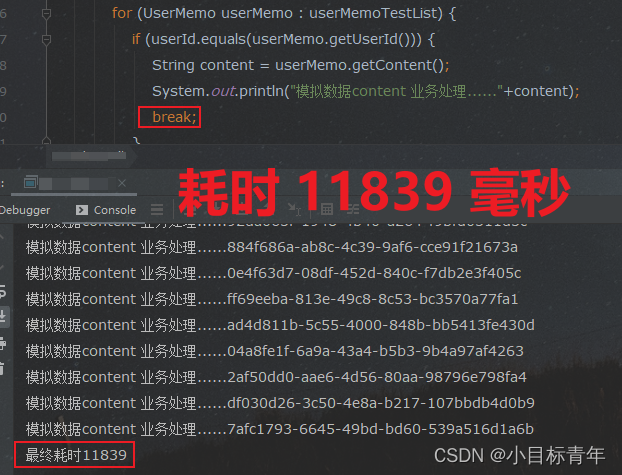
可以看到 从 2W 多毫秒 变成了 1W 多毫秒, 这个break 加的很OK。
回到我们刚才, 平时需要for 循环 里面再 for 循环 这种方式,可以看到耗时是 2万6千多毫秒。
那如果场景更复杂一定, 是for 循环里面 for循环 多个或者, for循环里面还有一层for 循环 ,那这样代码耗时真的非常恐怖。
那么接下来这个技巧点是 使用map 去优化 :
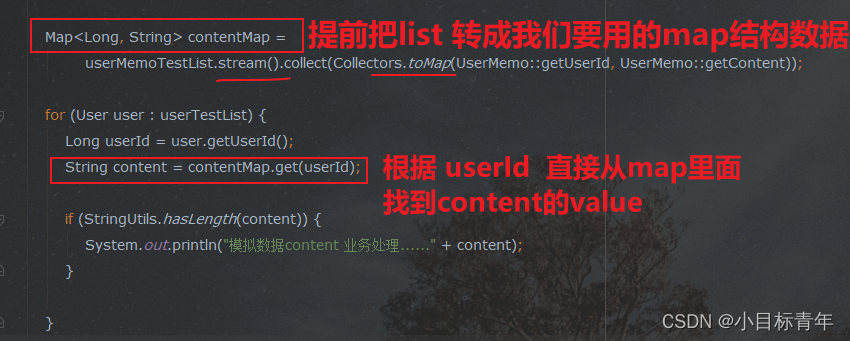
代码:
public static void main(String[] args) {List<User> userTestList = getUserTestList();List<UserMemo> userMemoTestList = getUserMemoTestList();StopWatch stopWatch = new StopWatch();stopWatch.start();Map<Long, String> contentMap =userMemoTestList.stream().collect(Collectors.toMap(UserMemo::getUserId, UserMemo::getContent));for (User user : userTestList) {Long userId = user.getUserId();String content = contentMap.get(userId);if (StringUtils.hasLength(content)) {System.out.println("模拟数据content 业务处理......" + content);}}stopWatch.stop();System.out.println("最终耗时" + stopWatch.getTotalTimeMillis());}看看耗时:
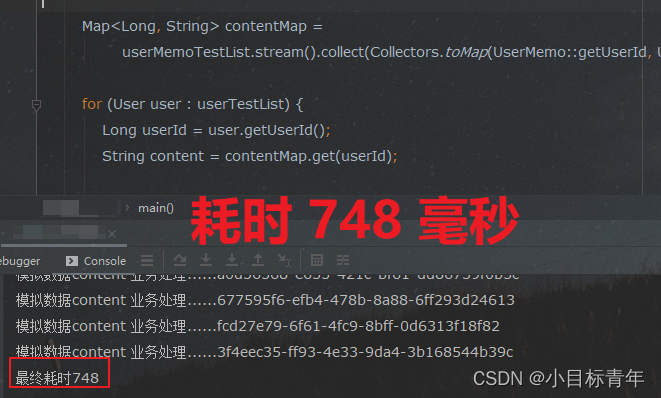
为什么 这么显著的效果 ?
这其实就是时间复杂度,
for循环嵌套for循环,
就好比 循环每一个 user ,拿出 userId
需要在里面的循环从 userMemo list集合里面 按顺序去开盲盒匹配,
拿出第一个,看看userId ,拿出第二个,看看userId ,一直找匹配的。
而我们提前对 userMemo list集合 做一次 遍历,转存储在map里面 。
map的取值效率 在多数的情况下是能维持接近 O(1) 的 , 毕竟数据结构摆着,数组加链表。
相当于拿到userId 想去开盲盒的时候, 根据userId 这个key hash完能直接找到数组里面的索引标记位, 如果底下没链表(有的话O(logN)),直接取出来就完事了。
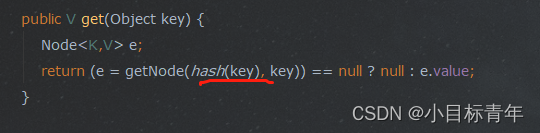
然后补充一个getNode的代码注释 :
/*** Implements Map.get and related methods.* 这是个 Map.get 的实现 方法* @param hash hash for key* @param key the key* @return the node, or null if none*/
// final 写死了 无法更改 返回 Node 传入查找的 hash 值 和 key键final Node<K,V> getNode(int hash, Object key) {
// tab 还是 哈希表
// first 哈希表找的链表红黑树对应的 头结点
// e 代表当前节点
// k 代表当前的 keyNode<K,V>[] tab; Node<K,V> first, e; int n; K k;
// 赋值 并过滤 哈希表 空的长度不够的 对应位置没存数据的 都直接 return nullif ((tab = table) != null && (n = tab.length) > 0 &&(first = tab[(n - 1) & hash]) != null) {
// 头结点就 找到了 hash相等值相等 或者 不空的 key 和当前节点 equalsif (first.hash == hash && // always check first node((k = first.key) == key || (key != null && key.equals(k))))return first;
// 头结点不匹配 没找到就 就用 next 找if ((e = first.next) != null) {
// 是不是红黑树 的if (first instanceof TreeNode)return ((TreeNode<K,V>)first).getTreeNode(hash, key);
// 红黑树就直接 调用 红黑树内查找// 不为空或者没找到就do while 循环do {
// 当前节点 找到了 hash相等值相等 或者 不空的 key 和当前节点 equalsif (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))return e;} while ((e = e.next) != null);}}return null;}
=
按照目前以JDK8 的hash算法,起hash冲突的情况是非常非常少见了。
最恶劣的情况,只有当 全部key 都冲突, 全都分配到一个桶里面去都占用一个位置 ,这时候就是O(n),这种情景不需要去考虑。
好了,该篇就到这。
相关文章:
Java for循环嵌套for循环,你需要懂的代码性能优化技巧
前言 本篇分析的技巧点其实是比较常见的,但是最近的几次的代码评审还是发现有不少兄弟没注意到。 所以还是想拿出来说下。 正文 是个什么场景呢? 就是 for循环 里面还有 for循环, 然后做一些数据匹配、处理 这种场景。 我们结合实例代码来…...

关于我拒绝了腾讯测试开发岗offer这件事
2022年刚开始有了向要跳槽的想法,之前的公司不能算大厂但在重庆也算是数一数二。开始跳槽的的时候我其实挺犹豫的 其实说是有跳槽的想法在2022年过年的时候就有了,因为每年公司3月会有涨薪的机会,所以想着看看那能不能涨(其实还是…...

从GPT到GPT-3:自然语言处理领域的prompt方法
❤️觉得内容不错的话,欢迎点赞收藏加关注😊😊😊,后续会继续输入更多优质内容❤️👉有问题欢迎大家加关注私戳或者评论(包括但不限于NLP算法相关,linux学习相关,读研读博…...
Git代码提交规范
Git 代码规范Git 每次提交代码,都是需要写 Commit message(提交说明),否则就不允许提交。Commit message 的格式 (三部分):Heaher ----- 必填type ---必需scope --- 可选subject --- 必需Body ---- 可省略Footer ---- …...

【JavaScript速成之路】JavaScript内置对象--Math和Date对象
📃个人主页:「小杨」的csdn博客 🔥系列专栏:【JavaScript速成之路】 🐳希望大家多多支持🥰一起进步呀! 文章目录前言1,Math对象1.1,常用属性方法1.1.1,获取x的…...
(自用POC)Fortinet-CVE-2022-40684
本文转载于:https://mp.weixin.qq.com/s?__bizMzIzNDU5Mzk2OQ&mid2247485332&idx1&sn85931aa474f1ae2c23a66bf6486eec63&chksme8f54c4adf82c55c44bc7b1ea919d44d377e35a18c74f83a15e6e20ec6c7bc65965dbc70130d&mpshare1&scene23&srcid…...

ConvNeXt V2实战:使用ConvNeXt V2实现图像分类任务(二)
文章目录训练部分导入项目使用的库设置随机因子设置全局参数图像预处理与增强读取数据设置Loss设置模型设置优化器和学习率调整算法设置混合精度,DP多卡,EMA定义训练和验证函数训练函数验证函数调用训练和验证方法运行以及结果查看测试热力图可视化展示完…...

【人工智能与深度学习】基于正则化潜在可变能量的模型
【人工智能与深度学习】基于正则化潜在可变能量的模型 正则化潜变量能量基础模型稀疏编码FISTALISTA稀疏编码示例卷积稀疏编码自然图像上的卷积稀疏编码可变自动编码器正则化潜变量能量基础模型 具有潜在变量的模型能够生成预测分布 y ‾ \overline{y}...
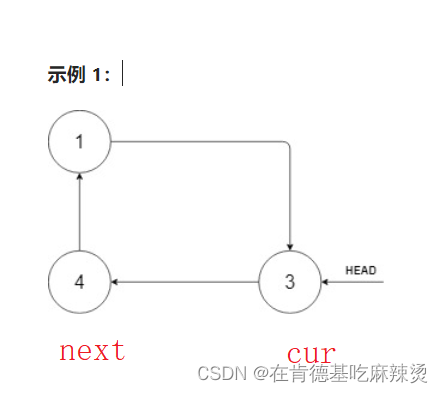
【Leetcode——排序的循环链表】
😊😊😊 文章目录一、力扣题之排序循环链表二、解题思路1. 使用双指针法2、找出最大节点,最大节点的下一个节点是最小节点,由此展开讨论总结一、力扣题之排序循环链表 题目如下:航班直达!&#…...
ChatGPT研究分享:机器第一次开始理解人类世界目录
0、为什么会对ChatGPT感兴趣一开始,我对ChatGPT是没什么关注的,无非就是有更大的数据集,完成了更大规模的计算,所以能够回答更多的问题。但后来了解到几个案例,开始觉得这个事情并不简单。我先分别列举出来,…...

【linux】Linux基本指令(上)
前言: 在之前我们已经简单了介绍了一下【Linux】,包括它的概念,由来啊等进行了讲解,接下来我们就将正式的踏入对其的学习!!! 本文目录👉操作系统的概念1.命令的语法1.1命令介绍1.2选…...
程序员必会技能—— 使用日志
目录 1、为什么要使用日志 2、自定义日志打印 2.1、在程序中得到日志对象 2.2、使用日志对象打印日志 2.3、日志格式 3、日志的级别 3.1、日志级别的分类 3.2、日志级别的设置 4、持久化日志 5、更简单的日志输出——lombok 5.1、如何在已经创建好的SpringBoot项目中添加…...
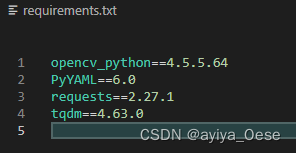
生成项目的包依赖文件requirements.txt
目录生成项目的包依赖文件requirements.txtrequirements.txt文件怎么来?使用pipreqs第三方库requirements.txt文件使用requirements.txt生成项目的包依赖文件requirements.txt 在安装部署代码时或者使用别人的项目时,会需要安装项目的依赖包,…...

安卓渐变的背景框实现
安卓渐变的背景框实现1.背景实现方法1.利用PorterDuffXfermode进行图层的混合,这是最推荐的方法,也是最有效的。2.利用canvas裁剪实现,这个方法有个缺陷,就是圆角会出现毛边,也就是锯齿。3.利用layer绘制边框1.背景 万…...

【拳打蓝桥杯】算法前置课——时间复杂度与空间复杂度
文章目录前言为什么需要复杂度分析?大O复杂度表示法时间复杂度分析几种常见时间复杂度实例分析空间复杂度分析内容小结最后说一句🐱🐉作者简介:大家好,我是黑洞晓威,一名大二学生,希望和大家一…...

vite中动态引入图片,打包之后找不到图片地址?
一般来说项目中我们集中存放图片,然后希望在页面中直接引入! 更好的就是直接在模板中调用一个函数 然后传入图片的名字就可以显示出来 事实上确实可以办到,我们用到了一个 new URL import.meta.url这俩个东西 再src目录下 static 下创建一…...

Docker 常用命令大全
目录 一、Docker (一)Docker基础命令 (二)docker镜像命令 (三)docker容器命令 (四)docker运维命令 一、Docker 容器是一种虚拟化技术,容器是镜像实例…...

React项目规范:目录结构、根目录别名、CSS重置、路由、redux、二次封装axios
React项目(一)一、创建项目二、目录结构三、craco配置别名并安装less1.craco安装2.配置别名3.安装less四、CSS样式重置五、配置路由六、配置Redux1.创建大仓库2.创建小仓库(1)方式1:RTK(2)方式2…...

SystemVerilog 教程第一章:简介
SystemVerilog 教程像 Verilog 和 VHDL 之类的硬件描述语言 (HDL) 主要用于描述硬件行为,以便将其转换为由组合门电路和时序元件组成的数字块。为了验证 HDL 中的硬件描述正确无误,就需要具有更多功能特性的面向对象的编程语言 (OOP) 来支持复杂的测试过…...

【Java|基础篇】逻辑控制-顺序结构、分支结构和循环结构
文章目录顺序结构分支结构if单分支语句if else双分支语句if else if else多分支语句switch语句循环语句for循环while循环do while循环continuebreak总结顺序结构 顺序结构是指代码按照从上往下的顺序依次执行 分支结构 选择语句是条件成立时,才会执行的语句.共有三种.分为是if…...

5步掌握Betaflight 2025升级:从配置到飞行的完整解决方案
5步掌握Betaflight 2025升级:从配置到飞行的完整解决方案 【免费下载链接】betaflight Open Source Flight Controller Firmware 项目地址: https://gitcode.com/gh_mirrors/be/betaflight 还在为穿越机飞行抖动和信号不稳定而烦恼吗?Betaflight …...

从源码细节看muduo为何比libevent2快70%:一次4096字节读取限制引发的性能思考
从缓冲区设计揭秘高性能网络库的优化哲学 在构建高并发服务器时,网络库的性能差异往往源于看似微小的设计决策。当两个知名网络库在相同硬件条件下出现70%的吞吐量差距时,这个数字背后隐藏的是对系统调用、内存管理和数据流控制的深刻理解差异。本文将从…...

MarkdownReader:重构浏览器文档阅读体验的渐进式渲染引擎
MarkdownReader:重构浏览器文档阅读体验的渐进式渲染引擎 【免费下载链接】markdownReader markdownReader is a extention for chrome, used for reading markdown file. 项目地址: https://gitcode.com/gh_mirrors/ma/markdownReader 在当今技术文档创作与…...

3步快速上手Thorium浏览器:新手也能掌握的完整性能优化指南
3步快速上手Thorium浏览器:新手也能掌握的完整性能优化指南 【免费下载链接】thorium Chromium fork named after radioactive element No. 90. Source code and Linux releases. Windows/MacOS/ARM builds served in different repos, links are towards the top o…...

FanControl完整使用指南:解决风扇控制难题的实用技巧
FanControl完整使用指南:解决风扇控制难题的实用技巧 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/fa/…...

避开这些坑!用Vivado FIFO IP核做跨时钟域处理的5个实战细节
避开这些坑!用Vivado FIFO IP核做跨时钟域处理的5个实战细节 在FPGA设计中,跨时钟域(CDC)数据传输一直是工程师们面临的棘手问题。Xilinx Vivado提供的FIFO IP核因其稳定性和易用性,成为处理CDC问题的首选方案。然而&a…...

Python face_recognition 库实战:从环境搭建到人脸特征点检测
1. 环境准备:搭建人脸识别的开发环境 第一次接触人脸识别开发时,最让人头疼的就是环境配置。记得我刚开始用face_recognition库时,光是安装依赖就折腾了大半天。后来才发现,其实只要掌握几个关键步骤,整个过程可以非常…...

为什么你的KFServing比别人慢3.8倍?:SITS 2026现场调试实录——AI原生编排中被忽略的4个cgroup v2陷阱
更多请点击: https://intelliparadigm.com 第一章:为什么你的KFServing比别人慢3.8倍?:SITS 2026现场调试实录——AI原生编排中被忽略的4个cgroup v2陷阱 在 SITS 2026 现场压测中,同一 KFServing v0.11.2 集群部署相…...
)
手把手教你用Matlab R2018a为TI C2000 DSP安装Embedded Coder支持包(含账户与版本避坑)
从零搭建Matlab与TI C2000 DSP的嵌入式开发环境:避坑指南与实战解析 当Matlab R2018a遇上TI C2000系列DSP处理器,工程师们便获得了一个从算法设计到硬件部署的完整解决方案。不同于传统的CCS开发模式,这种基于模型的设计(Model-Ba…...
)
从.axf到.bin:ARM Compiler 6.14链接与格式转换的隐藏细节(Keil MDK实战)
从.axf到.bin:ARM Compiler 6.14链接与格式转换的隐藏细节(Keil MDK实战) 当你在Keil MDK中点击"Build"按钮时,背后发生的远不止简单的代码翻译。对于使用STM32的嵌入式工程师而言,理解从源代码到最终烧录文…...