从GPT到GPT-3:自然语言处理领域的prompt方法

从GPT到GPT-3:自然语言处理领域的prompt方法
自然语言处理(NLP)是一项正在快速发展的技术,旨在使计算机能够更好地理解人类的自然语言。Prompt方法是一种新兴的NLP技术,其在许多自然语言处理任务中显示出了出色的性能。本文将介绍Prompt方法的原理、优势、劣势以及相关代码和案例,并探讨该技术在未来的发展前景。
1. 简介
Prompt方法是一种基于语言提示(language prompting)的方法,其原理是通过向计算机提供一个提示或问题,使其能够更好地理解文本。具体而言,Prompt方法通过在自然语言处理任务的输入中添加一些自然语言的提示信息,从而帮助计算机更好地理解该任务的语境。
为了更好地理解Prompt方法,我们可以以文本分类任务为例。在传统的文本分类任务中,我们通常将文本输入模型中,并期望模型自动从文本中提取相关特征以实现分类。但是,在Prompt方法中,我们可以向模型中输入一个问题或提示,以帮助模型更好地理解文本并进行分类。例如,对于一个二分类任务,我们可以向模型中输入一个类似于“这个文本是正面的吗?”的提示,帮助模型更好地理解文本,并更准确地进行分类。
2. 优劣势
Prompt方法的优势主要体现在以下几个方面:
-
提高了模型的性能:Prompt方法通过向模型中添加提示信息,可以帮助模型更好地理解任务的上下文,从而提高模型的性能。在许多自然语言处理任务中,Prompt方法已经显示出了比传统模型更好的性能,如文本分类、问答系统、机器翻译等。
-
增加了模型的可解释性:Prompt方法可以使模型的决策更加透明,因为我们可以通过提示信息来解释模型的决策。这在一些需要高可解释性的应用中非常重要,如医疗诊断、法律判决等。
-
减少了模型的不确定性:Prompt方法可以减少模型在文本处理过程中的不确定性,因为提示信息可以帮助模型更好地理解文本,并减少对上下文的猜测。这对于需要高准确性的应用非常重要,如情感分析、金融预测等。
-
提高了模型的泛化能力:Prompt方法可以帮助模型更好地理解任务的上下文,并提高模型的泛化能力。这对于处理新领域的数据非常重要,因为新领域的数据通常具有不同的语境和词汇。
Prompt方法的劣势主要体现在以下几个方面:
-
手动设计提示信息:Prompt方法需要手动设计提示信息,这需要消耗大量的时间和人力。此外,如果提示信息设计不当,则可能会导致模型性能的下降。
-
对任务的依赖性:Prompt方法的效果很大程度上取决于所使用的任务类型。对于某些任务,Prompt方法可能会带来显著的性能提升,但对于其他任务可能不起作用。
-
可解释性的局限性:尽管Prompt方法可以增加模型的可解释性,但它并不能解决所有的可解释性问题。有些问题需要更深入的解释,而Prompt方法可能无法提供。
-
对数据的依赖性:Prompt方法的效果很大程度上取决于所使用的数据类型。对于某些数据类型,Prompt方法可能会带来显著的性能提升,但对于其他数据类型可能不起作用。
3. 案例
我们以文本分类任务为例,演示Prompt方法的应用。我们使用GLUE数据集中的MNLI任务,该任务旨在将给定的前提和假设之间的关系分类为“蕴含”、“中立”或“矛盾”。我们使用BERT模型作为基准模型,并使用Prompt方法进行改进。
首先,我们将BERT模型的输入分为前提和假设两部分,如下所示:
model_input = {'premise': 'The dog is happy.', 'hypothesis': 'The cat is sad.'}
接下来,我们使用Prompt方法,在模型的输入中添加一个提示问题:“这两句话是否意义相同?”,代码如下所示:
prompt = "Are these two sentences semantically equivalent?"
model_input = {'premise': 'The dog is happy.', 'hypothesis': 'The cat is sad.'}
prompt_input = {'premise': prompt, 'hypothesis': prompt}
full_input = {k: v + prompt_input[k] for k, v in model_input.items()}
在上述代码中,我们首先定义一个提示问题:“Are these two sentences semantically equivalent?”,然后将其添加到模型的输入中。
接下来,我们使用PyTorch实现一个基于Prompt的BERT模型,代码如下所示:
import torch
from transformers import AutoTokenizer, AutoModelclass PromptBERT(torch.nn.Module):def __init__(self, model_name_or_path, prompt):super(PromptBERT, self).__init__()self.tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)self.bert = AutoModel.from_pretrained(model_name_or_path)self.prompt = promptdef forward(self, inputs):prompt_inputs = {k: self.prompt + v for k, v in inputs.items()}encoded_inputs = self.tokenizer(prompt_inputs, padding=True, truncation=True, return_tensors='pt')outputs = self.bert(**encoded_inputs)return outputs.pooler_output
在上述代码中,我们首先加载预训练的BERT模型和Tokenizer,并定义一个Prompt。然后,我们定义一个PromptBERT类,并重写其forward()方法。在forward()方法中,我们首先将Prompt添加到输入中,然后使用Tokenizer对输入进行编码,并将编码后的输入传递给BERT模型。最后,我们返回模型的pooler_output,它是BERT模型的最后一层隐藏状态的池化表示。
接下来,我们使用PromptBERT模型和MNLI数据集进行训练和测试,代码如下所示:
import pandas as pd
from sklearn.model_selection import train_test_split
from transformers import Trainer, TrainingArguments# Load MNLI data
mnli_data = pd.read_csv('mnli_data.csv')# Split data into train and test sets
train_data, test_data = train_test_split(mnli_data, test_size=0.2, random_state=42)# Define PromptBERT model
model = PromptBERT('bert-base-cased', 'Are these two sentences semantically equivalent?')# Define training arguments
training_args = TrainingArguments(output_dir='./results',num_train_epochs=3,per_device_train_batch_size=16,per_device_eval_batch_size=16,warmup_steps=500,weight_decay=0.01,logging_dir='./logs',logging_steps=500,evaluation_strategy='steps',eval_steps=1000,save_strategy='steps',save_steps=1000,load_best_model_at_end=True,
)# Define trainer
trainer = Trainer(model=model,args=training_args,train_dataset=train_data,eval_dataset=test_data,
)# Train model
trainer.train()# Evaluate model
trainer.evaluate()
在上述代码中,我们首先加载MNLI数据集,然后将其拆分为训练集和测试集。接下来,我们定义PromptBERT模型,并使用TrainingArguments和Trainer来训练和测试模型。在训练和测试结束后,我们可以使用模型对新的句子进行推断,以判断它们是否语义上等价,代码如下所示:
# Load PromptBERT model
model = PromptBERT('bert-base-cased', 'Are these two sentences semantically equivalent?')# Define input sentences
inputs = [{'premise': 'The dog is happy.', 'hypothesis': 'The cat is sad.'},{'premise': 'The cat is sleeping.', 'hypothesis': 'The dog is awake.'},{'premise': 'The book is on the table.', 'hypothesis': 'The table is under the book.'}]# Run inference on input sentences
for input in inputs:outputs = model(input)similarity = torch.nn.functional.cosine_similarity(outputs[0], outputs[1], dim=0)print(f"Input: {input}")print(f"Similarity score: {similarity.item()}")
在上述代码中,我们首先加载PromptBERT模型,然后定义三个输入句子。接下来,我们使用模型对这三个句子进行推断,并计算它们的相似度得分。最后,我们将输入句子和相似度得分打印出来。
相关文章:
从GPT到GPT-3:自然语言处理领域的prompt方法
❤️觉得内容不错的话,欢迎点赞收藏加关注😊😊😊,后续会继续输入更多优质内容❤️👉有问题欢迎大家加关注私戳或者评论(包括但不限于NLP算法相关,linux学习相关,读研读博…...
Git代码提交规范
Git 代码规范Git 每次提交代码,都是需要写 Commit message(提交说明),否则就不允许提交。Commit message 的格式 (三部分):Heaher ----- 必填type ---必需scope --- 可选subject --- 必需Body ---- 可省略Footer ---- …...

【JavaScript速成之路】JavaScript内置对象--Math和Date对象
📃个人主页:「小杨」的csdn博客 🔥系列专栏:【JavaScript速成之路】 🐳希望大家多多支持🥰一起进步呀! 文章目录前言1,Math对象1.1,常用属性方法1.1.1,获取x的…...
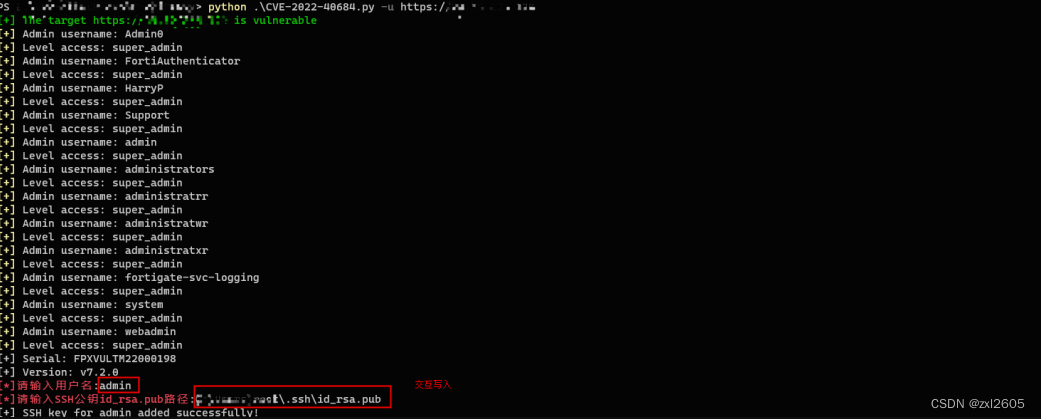
(自用POC)Fortinet-CVE-2022-40684
本文转载于:https://mp.weixin.qq.com/s?__bizMzIzNDU5Mzk2OQ&mid2247485332&idx1&sn85931aa474f1ae2c23a66bf6486eec63&chksme8f54c4adf82c55c44bc7b1ea919d44d377e35a18c74f83a15e6e20ec6c7bc65965dbc70130d&mpshare1&scene23&srcid…...

ConvNeXt V2实战:使用ConvNeXt V2实现图像分类任务(二)
文章目录训练部分导入项目使用的库设置随机因子设置全局参数图像预处理与增强读取数据设置Loss设置模型设置优化器和学习率调整算法设置混合精度,DP多卡,EMA定义训练和验证函数训练函数验证函数调用训练和验证方法运行以及结果查看测试热力图可视化展示完…...

【人工智能与深度学习】基于正则化潜在可变能量的模型
【人工智能与深度学习】基于正则化潜在可变能量的模型 正则化潜变量能量基础模型稀疏编码FISTALISTA稀疏编码示例卷积稀疏编码自然图像上的卷积稀疏编码可变自动编码器正则化潜变量能量基础模型 具有潜在变量的模型能够生成预测分布 y ‾ \overline{y}...
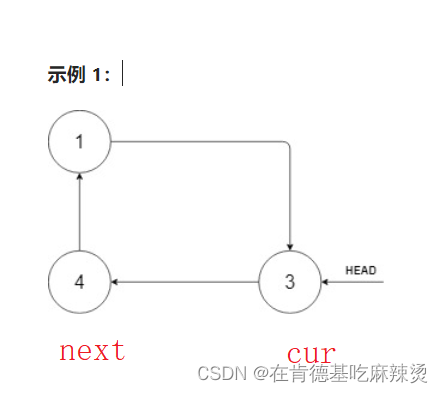
【Leetcode——排序的循环链表】
😊😊😊 文章目录一、力扣题之排序循环链表二、解题思路1. 使用双指针法2、找出最大节点,最大节点的下一个节点是最小节点,由此展开讨论总结一、力扣题之排序循环链表 题目如下:航班直达!&#…...
ChatGPT研究分享:机器第一次开始理解人类世界目录
0、为什么会对ChatGPT感兴趣一开始,我对ChatGPT是没什么关注的,无非就是有更大的数据集,完成了更大规模的计算,所以能够回答更多的问题。但后来了解到几个案例,开始觉得这个事情并不简单。我先分别列举出来,…...

【linux】Linux基本指令(上)
前言: 在之前我们已经简单了介绍了一下【Linux】,包括它的概念,由来啊等进行了讲解,接下来我们就将正式的踏入对其的学习!!! 本文目录👉操作系统的概念1.命令的语法1.1命令介绍1.2选…...
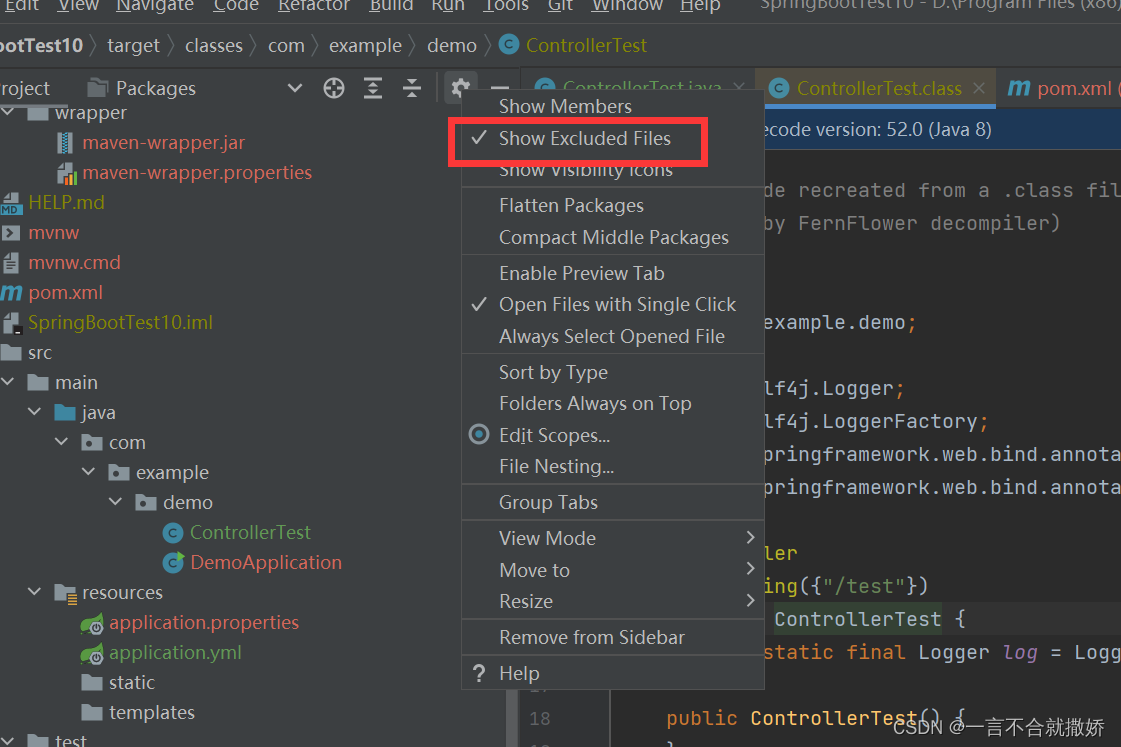
程序员必会技能—— 使用日志
目录 1、为什么要使用日志 2、自定义日志打印 2.1、在程序中得到日志对象 2.2、使用日志对象打印日志 2.3、日志格式 3、日志的级别 3.1、日志级别的分类 3.2、日志级别的设置 4、持久化日志 5、更简单的日志输出——lombok 5.1、如何在已经创建好的SpringBoot项目中添加…...
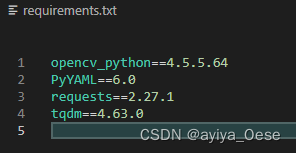
生成项目的包依赖文件requirements.txt
目录生成项目的包依赖文件requirements.txtrequirements.txt文件怎么来?使用pipreqs第三方库requirements.txt文件使用requirements.txt生成项目的包依赖文件requirements.txt 在安装部署代码时或者使用别人的项目时,会需要安装项目的依赖包,…...

安卓渐变的背景框实现
安卓渐变的背景框实现1.背景实现方法1.利用PorterDuffXfermode进行图层的混合,这是最推荐的方法,也是最有效的。2.利用canvas裁剪实现,这个方法有个缺陷,就是圆角会出现毛边,也就是锯齿。3.利用layer绘制边框1.背景 万…...

【拳打蓝桥杯】算法前置课——时间复杂度与空间复杂度
文章目录前言为什么需要复杂度分析?大O复杂度表示法时间复杂度分析几种常见时间复杂度实例分析空间复杂度分析内容小结最后说一句🐱🐉作者简介:大家好,我是黑洞晓威,一名大二学生,希望和大家一…...

vite中动态引入图片,打包之后找不到图片地址?
一般来说项目中我们集中存放图片,然后希望在页面中直接引入! 更好的就是直接在模板中调用一个函数 然后传入图片的名字就可以显示出来 事实上确实可以办到,我们用到了一个 new URL import.meta.url这俩个东西 再src目录下 static 下创建一…...

Docker 常用命令大全
目录 一、Docker (一)Docker基础命令 (二)docker镜像命令 (三)docker容器命令 (四)docker运维命令 一、Docker 容器是一种虚拟化技术,容器是镜像实例…...

React项目规范:目录结构、根目录别名、CSS重置、路由、redux、二次封装axios
React项目(一)一、创建项目二、目录结构三、craco配置别名并安装less1.craco安装2.配置别名3.安装less四、CSS样式重置五、配置路由六、配置Redux1.创建大仓库2.创建小仓库(1)方式1:RTK(2)方式2…...

SystemVerilog 教程第一章:简介
SystemVerilog 教程像 Verilog 和 VHDL 之类的硬件描述语言 (HDL) 主要用于描述硬件行为,以便将其转换为由组合门电路和时序元件组成的数字块。为了验证 HDL 中的硬件描述正确无误,就需要具有更多功能特性的面向对象的编程语言 (OOP) 来支持复杂的测试过…...

【Java|基础篇】逻辑控制-顺序结构、分支结构和循环结构
文章目录顺序结构分支结构if单分支语句if else双分支语句if else if else多分支语句switch语句循环语句for循环while循环do while循环continuebreak总结顺序结构 顺序结构是指代码按照从上往下的顺序依次执行 分支结构 选择语句是条件成立时,才会执行的语句.共有三种.分为是if…...

【数据挖掘实战】——家用电器用户行为分析及事件识别(BP神经网络)
项目地址:Datamining_project: 数据挖掘实战项目代码 目录 一、背景和挖掘目标 1、问题背景 2、原始数据 3、挖掘目标 二、分析方法与过程 1、初步分析 2、总体流程 第一步:数据抽取 第二步:探索分析 第三步:数据的预处…...

Kmeans聚类算法-python
import random import pandas as pd import numpy as np import matplotlib.pyplot as plt # 计算欧拉距离 def calcDis(dataSet, centroids, k): clalist[] for data in dataSet: diff np.tile(data, (k, 1)) - centroids #相减 (np.tile(a,(2,1))就是把…...

探索RBMO - BiLSTM - Attention分类算法:MATLAB实现与应用
【24年5月顶刊算法】RBMO-BiLSTM-Attention分类 基于红嘴蓝鹊优化器(RBMO)-双向长短期记忆网络(BiLSTM)-注意力机制(Attention)的数据分类预测(可更换为回归/单变量/多变量时序预测,前私),Matlab代码,可直接运行,适合小白新手 无需…...
 Boot ISO 原版可引导映像下载)
macOS Sequoia 15.7.5 (24G624) Boot ISO 原版可引导映像下载
macOS Sequoia 15.7.5 (24G624) Boot ISO 原版可引导映像下载 iPhone 镜像、Safari 浏览器重大更新和 Apple Intelligence 等众多全新功能令 Mac 使用体验再升级 请访问原文链接:https://sysin.org/blog/macOS-Sequoia-boot-iso/ 查看最新版。原创作品,…...

vLLM-v0.17.1在新闻聚合平台的应用:热点事件摘要生成服务
vLLM-v0.17.1在新闻聚合平台的应用:热点事件摘要生成服务 1. 技术背景与需求场景 新闻聚合平台每天需要处理海量新闻内容,如何快速生成准确、简洁的热点事件摘要成为关键挑战。传统方法依赖人工编辑或简单规则提取,效率低下且质量参差不齐。…...
)
【华为OD机试真题】战场索敌 · 区域统计问题 (Java/Go)
一、题目题目描述:有一个大小是 N*M 的战场地图,被墙壁 # 分隔成大小不同的区域。上下左右四个方向相邻的空地 . 属于同一个区域。只有空地上可能存在敌人 E。请求出地图上总共有多少区域里的敌人数小于 K。输入描述:第一行输入为 N, M, K&am…...

Coda Prompt 实战:如何通过智能提示提升开发效率
作为一名开发者,每天面对海量代码,你是否也常常感到疲惫?重复的 CRUD 操作、频繁在文档和 IDE 之间切换、为某个函数命名绞尽脑汁……这些看似微小的“摩擦力”,日积月累却严重消耗着我们的精力与时间。今天,我想和大家…...

Rasa Pro企业级对话AI实战:从安全扫描到密钥管理的完整配置指南
Rasa Pro企业级对话AI实战:从安全扫描到密钥管理的完整配置指南 在金融行业数字化转型浪潮中,智能对话系统已成为客户服务的核心组件。作为Rasa的商业化企业版本,Rasa Pro凭借其专业级的安全防护和可观测性功能,正在成为银行、保险…...

Stable Diffusion XL 1.0艺术表现力:灵感画廊1024x1024超清水墨质感实测
Stable Diffusion XL 1.0艺术表现力:灵感画廊1024x1024超清水墨质感实测 1. 开篇:当AI遇见东方美学 想象一下,你坐在一间安静的书房里,窗外是细雨绵绵,桌面上铺着宣纸,手边是笔墨砚台。你想画一幅水墨山水…...
高级使用技巧:引导模型优化抠图边缘)
SDMatte提示词(Prompt)高级使用技巧:引导模型优化抠图边缘
SDMatte提示词(Prompt)高级使用技巧:引导模型优化抠图边缘 1. 为什么提示词对抠图质量至关重要 你可能已经发现,同样的图片在不同提示词下,SDMatte生成的蒙版质量会有明显差异。这就像给修图师不同的工作指令——说&…...

【ArUco GridBoard实战】从精度瓶颈到优化检测的完整指南
1. ArUco GridBoard的精度瓶颈与优化思路 在实际的计算机视觉项目中,我们经常会遇到标定板尺寸受限的情况。比如我之前做的一个工业检测项目,标定板尺寸被限制在3cm2cm以内。最初使用的是Charuco标定板,但很快就发现了一个严重问题࿱…...

vLLM推理服务搭建指南:从环境配置到模型上线,一步不漏
vLLM推理服务搭建指南:从环境配置到模型上线,一步不漏 1. vLLM框架简介 vLLM是一个专为大型语言模型(LLM)设计的高性能推理和服务库,以其出色的吞吐量和易用性在AI社区广受欢迎。这个最初由加州大学伯克利分校开发的框架,如今已…...