【数据挖掘实战】——家用电器用户行为分析及事件识别(BP神经网络)

项目地址:Datamining_project: 数据挖掘实战项目代码
目录
一、背景和挖掘目标
1、问题背景
2、原始数据
3、挖掘目标
二、分析方法与过程
1、初步分析
2、总体流程
第一步:数据抽取
第二步:探索分析
第三步:数据的预处理
第四步:构建专家样本
第五步: 构建用水事件行为识别模型
三、总结和思考
一、背景和挖掘目标
1、问题背景
- 智能家居是利用先进的技术,融合个性需求,将与家居生活有关的各个子系统有机地结合在一起,通过网络化综合智能控制和管理,实现“以人为本”的全新生活体验。
- 企业若能深入了解其产品在不同用户群的使用习惯,开发新功能,就能开拓新市场,实现产品的智能化。根据家居的智能化,分析客户行为,识别不同客户群的特征、加深对客户的理解等。(以热水器为例,分析客户行为)
- 针对不同的客户群提供个性化产品、改进新产品的智能化的研发和制定相应的营销策略。
2、原始数据
用户用水数据表:包括了洗浴、洗手、洗脸、洗菜、做饭等用水行为

3、挖掘目标
- 根据热水器采集到的数据,划分一次完整用水事件;
- 在划分好的一次完整用水事件中,识别出洗浴事件。
二、分析方法与过程
1、初步分析
- 热水器在状态发生改变或者有水流状态时,每2秒会采集一条流水数据。因为用户行为不仅仅只有洗浴还存在其他的用水事件:比如洗手、洗菜等,所以热水器采集的数据来自各种不同的用水事件。
- 基于热水器采集的数据,根据水流量和停顿时间间隔划分为不同大小的时间区间,每个区间是一个可理解的一次完整用水事件,并以热水器一次完整用水事件作为一个基本事件。
- 从独立的用水事件中识别出其中属于洗浴的事件。
2、总体流程

第一步:数据抽取
| 属性名称 | 属性说明 |
| 热水器编码 | 热水器出厂编号 |
| 发生时间 | 记录热水器处于某状态的时刻 |
| 开关机状态 | 热水器是否开机 |
| 即热 | 即时加热 |
| 加热中 | 热水器处于对水进行加热的状态 |
| 保温中 | 热水器处于对水进行保温的状态 |
| 有无水流 | 热水水流量大于等于10L/min为有水,否则为无 |
| 实际温度 | 热水器中热水的实际温度 |
| 热水量 | 热水器热水的含量 |
| 水流量 | 热水器热水的水流速度 单位:L/min |
| 节能模式 | 热水器的一种节能工作模式 |
| 预约洗 | 预约一个时间使用热水 |
| 即时洗 | 不预约直接使用热水器 |
| 加热剩余时间 | 加热到设定温度还需多长时间 |
| 当前设置温度 | 热水器加热时热水能够到达的最大温度 |
第二步:探索分析
为了探究用户真实用水停顿时间间隔的分布情况,统计用水停顿的时间间隔并作频率分布直方图。

停顿时间间隔为0~0.3分钟的频率很高,根据日常用水经验可以判断其为一次用水时间中的停顿;停顿时间间隔为6~13分钟的频率较低,分析其为两次用水事件之间的停顿间隔。两次用水事件的停顿时间间隔分布在3~7分钟与现场实验统计用水停顿的时间间隔近似。
第三步:数据的预处理
2、数据变换
一次完整用水事件的划分:用水状态记录中,水流量不为0表明用户正在使用热水;而水流量为0时用户用热水发生停顿或者用热水结束。水流量为0的状态记录之间的时间间隔如果超过一个阈值T,则从该段水流量为0的状态记录向前找到最后一条水流量不为0的用水记录作为上一次用水事件的结束;向后找到水流量不为0的状态记录作为下一个用水事件的开始。

#-*- coding: utf-8 -*-
#用水事件划分
import pandas as pdthreshold = pd.Timedelta('4 min') #阈值为分钟
inputfile = 'data/water_heater.xls' #输入数据路径,需要使用Excel格式
outputfile = 'tmp/dividsequence.xls' #输出数据路径,需要使用Excel格式data = pd.read_excel(inputfile)
data[u'发生时间'] = pd.to_datetime(data[u'发生时间'], format = '%Y%m%d%H%M%S')
data = data[data[u'水流量'] > 0] #只要流量大于0的记录
d = data[u'发生时间'].diff() > threshold #相邻时间作差分,比较是否大于阈值
data[u'事件编号'] = d.cumsum() + 1 #通过累积求和的方式为事件编号data.to_excel(outputfile)用水事件阈值寻优:根据水流量和停顿时间间隔的阈值划分一次完整的用水事件。

# -*- coding: utf-8 -*-
# 阈值寻优
import numpy as np
import pandas as pdinputfile = 'data/water_heater.xls' # 输入数据路径,需要使用Excel格式
n = 4 # 使用以后四个点的平均斜率threshold = pd.Timedelta(minutes=5) # 专家阈值
data = pd.read_excel(inputfile)
data[u'发生时间'] = pd.to_datetime(data[u'发生时间'], format='%Y%m%d%H%M%S')
data = data[data[u'水流量'] > 0] # 只要流量大于0的记录def event_num(ts):d = data[u'发生时间'].diff() > ts # 相邻时间作差分,比较是否大于阈值return d.sum() + 1 # 这样直接返回事件数dt = [pd.Timedelta(minutes=i) for i in np.arange(1, 9, 0.25)]
h = pd.DataFrame(dt, columns=[u'阈值']) # 定义阈值列
h[u'事件数'] = h[u'阈值'].apply(event_num) # 计算每个阈值对应的事件数
h[u'斜率'] = h[u'事件数'].diff() / 0.25 # 计算每两个相邻点对应的斜率# df_test['col_name'].rolling(ma).mean()新版本 ---->pd.rolling_mean(df_test['col_name'], ma) 旧版本
# pd.rolling_mean(h[u'斜率'].abs(), n)
h[u'斜率指标'] = h[u'斜率'].rolling(n).mean() # 采用后n个的斜率绝对值平均作为斜率指标
ts = h[u'阈值'][h[u'斜率指标'].idxmin() - n]
# 注:用idxmin返回最小值的Index,由于rolling_mean()自动计算的是前n个斜率的绝对值平均
# 所以结果要进行平移(-n)if ts > threshold:ts = pd.Timedelta(minutes=4)print(ts)
属性构造:根据用水行为,需构造四类指标:时长指标、频率指标、用水的量化指标以及用水的波动指标。

属性解释:
 候选洗浴事件:从大量的一次完整用水事件中筛选规则剔除可以明显判定不是洗浴的事件
候选洗浴事件:从大量的一次完整用水事件中筛选规则剔除可以明显判定不是洗浴的事件
筛选掉非常短暂的用水事件:一次完整的用水事件满足其中任意一个条件,就被判定为短暂用水事件,其筛选条件为:1、一次用水事件中总用水量(纯热水)小于y升;2、用水时长小于100秒;3、总用水时长小于120秒。
3、缺失值的处理

第四步:构建专家样本

第五步:构建用水事件行为识别模型
1、洗浴识别模型
根据建模样本数据和用户记录的包含用水的用途、用水开始时间、用水结束时间等属性的用水日志,建立BP神经网络模型识别洗浴事件。

# -*- coding: utf-8 -*-
# 建立、训练多层神经网络,并完成模型的检验
from __future__ import print_function
import pandas as pdinputfile1 = '../data/train_neural_network_data.xls' # 训练数据
inputfile2 = '../data/test_neural_network_data.xls' # 测试数据
testoutputfile = '../tmp/test_output_data.xls' # 测试数据模型输出文件
data_train = pd.read_excel(inputfile1) # 读入训练数据(由日志标记事件是否为洗浴)
data_test = pd.read_excel(inputfile2) # 读入测试数据(由日志标记事件是否为洗浴)
y_train = data_train.iloc[:, 4].as_matrix() # 训练样本标签列
x_train = data_train.iloc[:, 5:17].as_matrix() # 训练样本特征
y_test = data_test.iloc[:, 4].as_matrix() # 测试样本标签列
x_test = data_test.iloc[:, 5:17].as_matrix() # 测试样本特征from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activationmodel = Sequential() # 建立模型
model.add(Dense(11, 17)) # 添加输入层、隐藏层的连接
model.add(Activation('relu')) # 以Relu函数为激活函数
model.add(Dense(17, 10)) # 添加隐藏层、隐藏层的连接
model.add(Activation('relu')) # 以Relu函数为激活函数
model.add(Dense(10, 1)) # 添加隐藏层、输出层的连接
model.add(Activation('sigmoid')) # 以sigmoid函数为激活函数
# 编译模型,损失函数为binary_crossentropy,用adam法求解
model.compile(loss='binary_crossentropy', optimizer='adam', class_mode="binary")model.fit(x_train, y_train, nb_epoch=100, batch_size=1) # 训练模型
model.save_weights('../tmp/net.model') # 保存模型参数r = pd.DataFrame(model.predict_classes(x_test), columns=[u'预测结果'])
pd.concat([data_test.iloc[:, :5], r], axis=1).to_excel(testoutputfile)
model.predict(x_test)
2、模型检验
通过某热水器用户记录了两周的热水器用水日志,将前一周的数据作为训练数据,后一周的数据作为测试数据。根据该热水器用户提供的用水日志与多层神经网络模型识别结果的比较,总共21条检测数据,准确识别了18条数据,模型对洗浴事件的识别准确率为85.5%。

三、总结和思考
- 根据上述模型划分的结果,发现有时候会将两次(或多次)洗浴划分为一次洗浴,因为在实际情况中,存在着一个人洗完澡后,另一个人马上洗的情况,这中间过渡期间的停顿间隔小于阈值。针对两次(或多次)洗浴事件被合并为一次洗浴事件的情况,需要进行优化,对连续洗浴事件作识别,提高模型识别精确度。
- 判断连续洗浴的方法:对每次用水事件,建立一个连续洗判别指标。连续洗判别指标初始值为0,每当有一个属性超过设定的阈值,就给该指标加上相应的值,最后判别连续洗指标是否超过给定的阈值,如果超过给定的阈值,认为该次用水事件为连续洗事件。
相关文章:
【数据挖掘实战】——家用电器用户行为分析及事件识别(BP神经网络)
项目地址:Datamining_project: 数据挖掘实战项目代码 目录 一、背景和挖掘目标 1、问题背景 2、原始数据 3、挖掘目标 二、分析方法与过程 1、初步分析 2、总体流程 第一步:数据抽取 第二步:探索分析 第三步:数据的预处…...

Kmeans聚类算法-python
import random import pandas as pd import numpy as np import matplotlib.pyplot as plt # 计算欧拉距离 def calcDis(dataSet, centroids, k): clalist[] for data in dataSet: diff np.tile(data, (k, 1)) - centroids #相减 (np.tile(a,(2,1))就是把…...

Linux|奇怪的知识|locate命令---文件管理小工具
前言: Linux的命令是非常多的,有一些冷门的命令,虽然很少用,但可能会有意想不到的功能,例如,本文将要介绍的locate命令。 (平常很少会想到使用此命令,find命令使用的更多,偶然想起…...

Cadence Allegro 导出Function Pin Report报告详解
⏪《上一篇》 🏡《上级目录》 ⏩《下一篇》 目录 1,概述2,Function Pin Reportt作用3,Function Pin Report示例4,Function Pin Report导出方法4.1,方法14.2,方法2B站关注“硬小二”浏览更多演示视频 1,概述...

蓝桥杯2018年第九题-缩位求和
题目:在电子计算机普及以前,人们经常用一个粗略的方法来验算四则运算是否正确。比如:248 * 15 3720把乘数和被乘数分别逐位求和,如果是多位数再逐位求和,直到是1位数,得2 4 8 14 > 1 4 5;1 5 65…...

基于Yolv5s的口罩检测
1.Yolov5算法原理和网络结构 YOLOv5按照网络深度和网络宽度的大小,可以分为YO-LOv5s、YOLOv5m、YOLOv5l、YOLOv5x。本文使用YOLOv5s,它的网络结构最为小巧,同时图像推理速度最快达0.007s。YO-LOv5的网络结构主要由四部分组成,分别…...

Linux基本命令
Linux基本命令Linux的目录结构Linux命令入门目录切换相关命令(cd/pwd)相对路径、绝对路径和特殊路径符创建目录命令(mkdir)文件操作命令part1 (touch、cat、more)文件操作命令part2 (cp、mv、rm)查找命令 (which、find…...

云原生场景下的安全左移
本博客地址:https://security.blog.csdn.net/article/details/129430859 一、安全左移概述 安全左移需要考虑开发安全、软件供应链安全、镜像仓库、配置核查这四个部分。 首先是开发安全,安全团队需要关注代码漏洞,比如使用代码检查工具进…...

mysql面试经典问题
文章目录 1. 能说下myisam 和 innodb的区别吗?2. 说下mysql的索引有哪些吧,聚簇和非聚簇索引又是什么?3. 那你知道什么是覆盖索引和回表吗?4. 锁的类型有哪些呢5. 你能说下事务的基本特性和隔离级别吗?6. 那ACID靠什么保证的呢?7. 那你说说什么是幻读,什么是MVCC?幻读什…...
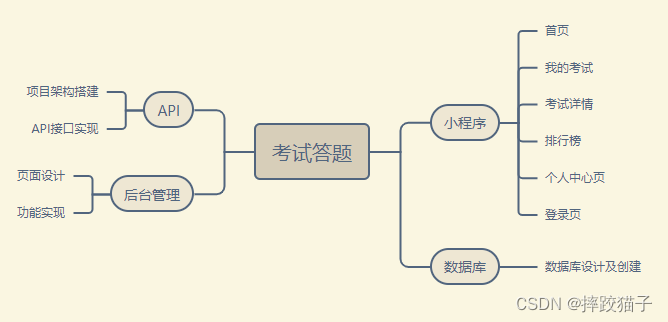
微信小程序|基于小程序+C#制作一个考试答题小程序
基于小程序+C#制作一个考试答题小程序打破传统线下考试答题的边界线问题,使考试不用再局限与某个统一的场所,只要有设备,哪里都能考试。 一、小程序...

【1605. 给定行和列的和求可行矩阵】
来源:力扣(LeetCode) 描述: 给你两个非负整数数组 rowSum 和 colSum ,其中 rowSum[i] 是二维矩阵中第 i 行元素的和, colSum[j] 是第 j 列元素的和。换言之你不知道矩阵里的每个元素,但是你知…...
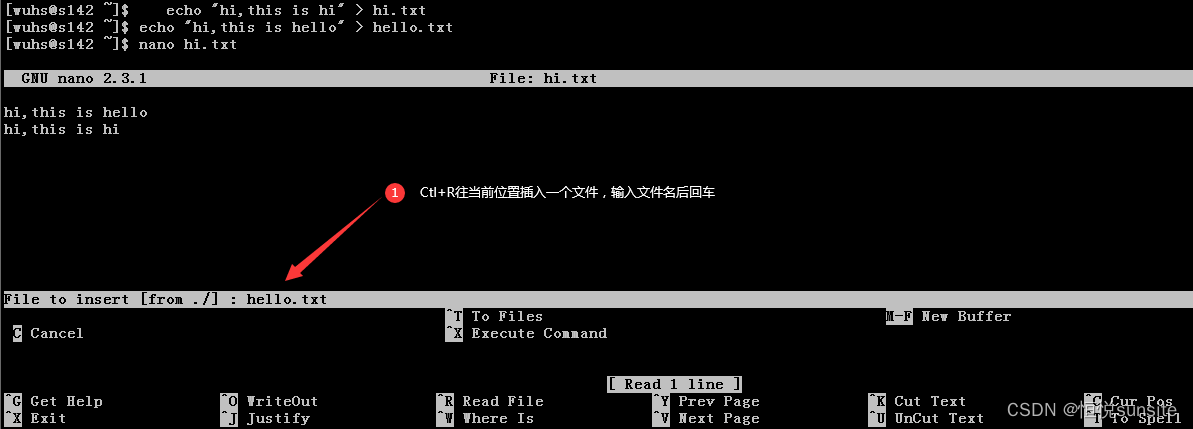
Linux命令之nano命令
一、nano命令简介 nano是一个小型、免费、友好的编辑器,旨在取代非免费Pine包中的默认编辑器Pico。nano不仅复制了Pico的外观,还实现了Pico中一些缺失(或默认禁用)的功能,例如“搜索和替换”和“转到行号和列号”。nan…...
)
IT项目管理(作业1)
一.单选题(共12题,100.0分) 1.以下哪项是项目的一个实例?( ) A、改进现有的业务流程或程序B、为公司运营提供信息技术支持C、批量生产一种新近开发出来的家用电冰箱D、管理一个公司 我的答案:A 2.下列哪项不能成为项目结束的理由?( ) A…...

蓝桥杯嵌入式(G4系列):串口收发
前言: 在整个蓝桥杯考试中涉及串口的次数还是较多,这里写下这篇博客,记录一下自己的学习过程。 STM32Cubemx配置: 首先,我们点击左侧的Connectivity选择USART1进行如下配置。 使能串口中断 在左侧的管脚配置上也要做出…...

「兔了个兔」玉兔踏青,纯CSS实现瑞兔日历(附源码)
💂作者简介: THUNDER王,一名热爱财税和SAP ABAP编程以及热爱分享的博主。目前于江西师范大学会计学专业大二本科在读,同时任汉硕云(广东)科技有限公司ABAP开发顾问。在学习工作中,我通常使用偏后…...

第17章 关于局部波动率的一些总结
这学期会时不时更新一下伊曼纽尔德曼(Emanuel Derman) 教授与迈克尔B.米勒(Michael B. Miller)的《The Volatility Smile》这本书,本意是协助导师课程需要,发在这里有意的朋友们可以学习一下,思…...

反转链表合并两个有序链表链表分割链表的回文结构相交链表
反转链表来源:杭哥206. 反转链表 - 力扣(LeetCode)typedef struct ListNode ListNode; struct ListNode* reverseList(struct ListNode* head) {if (headNULL){return NULL;}ListNode* prevhead;ListNode* curhead->next;ListNode* furNUL…...

联想触摸板只能单击,二指三指失效
问题背景 这问题是我笔记本两三年前重装win10系统后出现的,当时有鼠标懒得弄。今天发现没鼠标后,触摸板连二指滑动都没有太麻烦了,所以决定弄一下。 联想笔记本,win10系统重装后出现的问题。 1.鲁大师,联想电脑管家 …...
卡死解决办法)
mysql 删除表卡死,或是截断(truncate)卡死解决办法
利用工具进行truncate表的时候,一直运行,运行了十几分钟也没有成功。中止之后再运行也是一样。但是删除表的数据以及查询表数据都是可以的。猜测是锁死了。 使用 show processlist; 发现Waiting for table metadata lock 问题; mysql> s…...
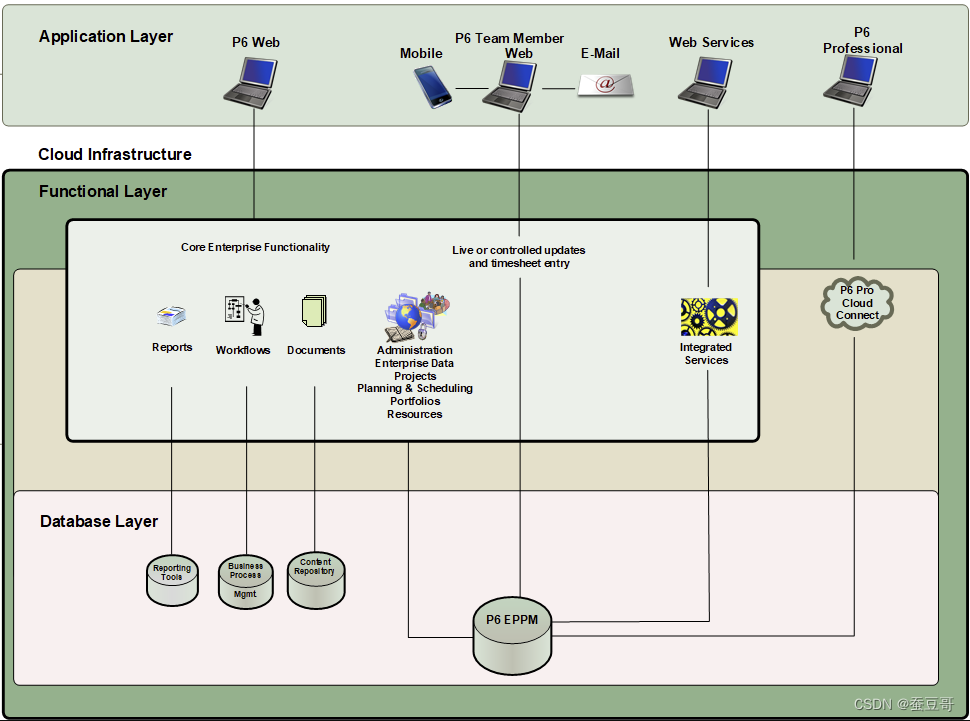
ORACLE P6 EPPM 架构及套件介绍(源自Oracle Help)
引言 借助官方帮助的内容, 我水一篇文章,翻译了下文 P6EPPM架构 P6各套件 P6:大多数用户几乎完全依赖在标准网络浏览器中运行的 P6 网络应用程序。简称为 P6,它是管理项目的主要界面。P6 移动版:允许团队成员提供任…...

InputTip:提升表单体验的动态输入引导组件设计与实战
1. 项目概述:一个被低估的输入增强工具 在桌面应用开发中,我们常常会花费大量精力去构建复杂的业务逻辑和炫酷的界面,却容易忽略一个直接影响用户体验的细节: 输入引导 。回想一下,你是否遇到过这样的场景࿱…...

OpenClaw Memory启动器:快速构建AI记忆系统的开源脚手架
1. 项目概述:一个为AI记忆系统设计的开源启动器最近在折腾AI应用开发,特别是那些需要长期记忆和上下文管理的项目时,发现了一个挺有意思的GitHub仓库:christiancaviedes/openclaw-memory-starter。这本质上是一个为“OpenClaw Mem…...

用Matplotlib heatmap分析你的数据:从农产品收成到商品销量的实战案例拆解
用Matplotlib heatmap解锁业务洞察:从农场到电商的数据可视化实战 热力图(heatmap)远不止是颜色方块的排列——它是数据与商业决策之间的视觉桥梁。想象一下,你面前有一张农场作物产量的热力图,颜色从深绿渐变到亮黄&a…...

GPU加速网络爬虫:OpenCL异构计算在数据采集中的实践
1. 项目概述:一个面向硬件加速的开源抓取工具包最近在折腾一些数据采集和自动化任务时,我常常遇到一个瓶颈:当需要处理海量网页、进行高频次请求或者解析复杂的动态内容时,传统的基于CPU的抓取框架(比如Scrapy、Reques…...

Roast:颠覆AI助手模式,打造苏格拉底式思维拷问引擎
1. 项目概述:当AI开始“拷问”你如果你用过市面上那些主流的AI助手,不管是ChatGPT、Claude还是DeepSeek,你大概率有过这样的体验:你抛出一个想法,它总能给你一堆“哇,这个想法太棒了!”、“很有…...

5个简单步骤实现iOS虚拟定位:iFakeLocation终极解决方案
5个简单步骤实现iOS虚拟定位:iFakeLocation终极解决方案 【免费下载链接】iFakeLocation Simulate locations on iOS devices on Windows, Mac and Ubuntu. 项目地址: https://gitcode.com/gh_mirrors/if/iFakeLocation 你是否曾经需要在不同城市测试应用的位…...

技术奇点之后,人类程序员的历史角色
当人工智能越过技术奇点,代码生成、测试用例设计乃至系统运维都将发生质变。本文从软件测试从业者的视角出发,系统探讨人类程序员在奇点之后可能扮演的六种核心角色:系统守护者、需求翻译官、质量伦理法官、人机交互设计师、持续学习组织者与…...
)
【Nature期刊精准捕获术】:基于Perplexity语义图谱的跨学科文献溯源方法论(附2024最新验证数据集)
更多请点击: https://intelliparadigm.com 第一章:【Nature期刊精准捕获术】:基于Perplexity语义图谱的跨学科文献溯源方法论(附2024最新验证数据集) 传统关键词检索在跨学科高影响力期刊(如 Nature、Scie…...

别再只盯着应力云图了!用ANSYS Workbench的‘圣维南原理’和模型简化,把你的计算效率提升200%
别再只盯着应力云图了!用ANSYS Workbench的‘圣维南原理’和模型简化,把你的计算效率提升200% 有限元分析工程师常常陷入一个误区:认为模型越精细,结果越准确。但现实情况是,一个未经合理简化的复杂模型不仅会消耗大量…...

在多轮对话应用中体验Taotoken路由策略对响应速度的优化
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在多轮对话应用中体验Taotoken路由策略对响应速度的优化 1. 场景与背景 在开发一个需要多轮交互的对话应用时,我们常常…...