大语言模型系列-Transformer介绍
大语言模型系列:Transformer介绍
引言
在自然语言处理(NLP)领域,Transformer模型已经成为了许多任务的标准方法。自从Vaswani等人在2017年提出Transformer以来,它已经彻底改变了NLP模型的设计。本文将介绍Transformer模型的基本结构和关键技术细节,并通过具体的公式来阐述其工作原理。
Transformer模型概述
Transformer模型主要由编码器(Encoder)和解码器(Decoder)两个部分组成,每个部分又由多个相同的层(Layer)堆叠而成。每一层都包含两个子层:多头自注意力机制(Multi-Head Self-Attention Mechanism)和前馈神经网络(Feed-Forward Neural Network)。
编码器
编码器由N个相同的编码器层(Encoder Layer)堆叠而成。每个编码器层包含以下两个子层:
- 多头自注意力机制(Multi-Head Self-Attention Mechanism)
- 前馈神经网络(Feed-Forward Neural Network)
解码器
解码器也由N个相同的解码器层(Decoder Layer)堆叠而成。与编码器层类似,每个解码器层包含以下三个子层:
- 多头自注意力机制(Masked Multi-Head Self-Attention Mechanism)
- 多头注意力机制(Multi-Head Attention Mechanism)
- 前馈神经网络(Feed-Forward Neural Network)
注意力机制(Attention Mechanism)
注意力机制是Transformer的核心。它通过计算输入序列中每个位置的加权平均值来捕捉序列中不同位置之间的依赖关系。注意力机制的计算过程包括三个步骤:计算查询(Query)、键(Key)和值(Value)的线性变换,计算注意力权重,并对值进行加权求和。
公式
- 线性变换:
Q = X W Q , K = X W K , V = X W V Q = XW^Q, \quad K = XW^K, \quad V = XW^V Q=XWQ,K=XWK,V=XWV
其中,( X )是输入序列的表示,( W^Q )、( W^K )和( W^V )是可学习的参数矩阵。
- 注意力权重计算:
Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dkQKT)V
其中, d k d_k dk是键的维度。
多头注意力机制(Multi-Head Attention Mechanism)
多头注意力机制通过引入多个注意力头(Attention Heads),可以在不同的子空间中并行计算注意力。多头注意力机制的公式如下:
- 分头计算:
head i = Attention ( Q W i Q , K W i K , V W i V ) \text{head}_i = \text{Attention}(QW_i^Q, KW_i^K, VW_i^V) headi=Attention(QWiQ,KWiK,VWiV)
-
头的拼接:
MultiHead ( Q , K , V ) = Concat ( head 1 , head 2 , … , head h ) W O \text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, \text{head}_2, \ldots, \text{head}_h)W^O MultiHead(Q,K,V)=Concat(head1,head2,…,headh)WO
其中,QKV是可学习的参数矩阵。
位置编码(Positional Encoding)
由于Transformer模型没有使用循环神经网络(RNN)或卷积神经网络(CNN),它不能直接捕捉序列中的位置信息。因此,Transformer通过添加位置编码(Positional Encoding)来引入位置信息。位置编码的公式如下:
P E ( p o s , 2 i ) = sin ( p o s 1000 0 2 i / d m o d e l ) PE_{(pos, 2i)} = \sin\left(\frac{pos}{10000^{2i/d_{model}}}\right) PE(pos,2i)=sin(100002i/dmodelpos)
P E ( p o s , 2 i + 1 ) = cos ( p o s 1000 0 2 i / d m o d e l ) PE_{(pos, 2i+1)} = \cos\left(\frac{pos}{10000^{2i/d_{model}}}\right) PE(pos,2i+1)=cos(100002i/dmodelpos)
其中, p o s pos pos是位置, i i i是维度索引, d m o d e l d_{model} dmodel是模型的维度。
前馈神经网络(Feed-Forward Neural Network)
在每个编码器层和解码器层中,前馈神经网络(FFN)通过两个线性变换和一个激活函数来处理每个位置的表示。前馈神经网络的公式如下:
FFN ( x ) = max ( 0 , x W 1 + b 1 ) W 2 + b 2 \text{FFN}(x) = \max(0, xW_1 + b_1)W_2 + b_2 FFN(x)=max(0,xW1+b1)W2+b2
其中, W 1 W_1 W1、 W 2 W_2 W2、 b 1 b_1 b1和 b 2 b_2 b2是可学习的参数矩阵和偏置向量。
总结
Transformer模型通过自注意力机制和多头注意力机制,有效地捕捉序列中不同位置之间的依赖关系,并通过位置编码引入位置信息。它的并行计算能力使其在处理大规模数据时表现出色,已经成为NLP任务中的主流模型。
希望本文对您理解Transformer模型有所帮助。如果您有任何问题或建议,欢迎在评论区留言。
参考文献
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … & Polosukhin, I. (2017). Attention is all you need. In Advances in neural information processing systems (pp. 5998-6008).
相关文章:
大语言模型系列-Transformer介绍
大语言模型系列:Transformer介绍 引言 在自然语言处理(NLP)领域,Transformer模型已经成为了许多任务的标准方法。自从Vaswani等人在2017年提出Transformer以来,它已经彻底改变了NLP模型的设计。本文将介绍Transforme…...

JavaDS —— 顺序表ArrayList
顺序表 顺序表是用一段物理地址连续的存储单元依次存储数据元素的线性结构,一般情况下采用数组存储。在数组上完成数据的增删查改。在物理和逻辑上都是连续的。 模拟实现 下面是我们要自己模拟实现的方法: 首先我们要创建一个顺序表,顺序表…...

Sphinx 搜索配置
官方文档 http://sphinxsearch.com/docs/sphinx3.html 支持中文,英文,日文,韩文,俄罗斯语搜索 版本是 官网3.6.1版本 文件 sphinx.conf.dist 的windows 配置,官网下载下来后微微配置即可。 # Minimal Sphinx confi…...

如何在不关闭防火墙的情况下,让两台设备ping通
问题现象 如题,做虚拟机实验的时候,有一台linux系统的虚拟机配置的ip地址是192.168.172.181 物理主机的ip地址是192.168.172.1 此时物理主机可以ping通虚拟机 但是虚拟机不能ping通物理主机 此时我们可以想到,有可能是物理主机防火墙的原因。…...
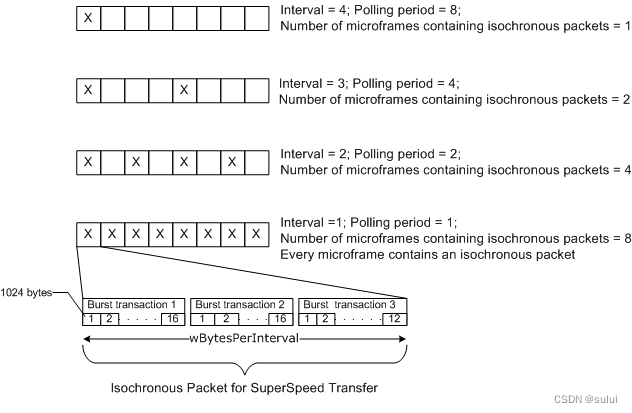
windows USB 设备驱动开发-USB 等时传输
客户端驱动程序可以生成 USB 请求块 (URB) 以在 USB 设备中向/从常时等量端点传输数据。虽然USB设备一向以非等时传输出名,USB提供的是一种串行数据,而非等时,但是USB仍然设计了等时传输的机制,但根据笔者的经验,等时传…...

【文件共享 windows和linux】Windows Server 2016上开启文件夹共享,并在CentOS 7.4上访问和下载文件
要在Windows Server 2016上开启文件夹共享,并在CentOS 7.4上访问和下载文件,请按照以下步骤操作: 在Windows Server 2016上开启文件夹共享: 启用SMB服务: 打开“服务器管理器”。选择“文件和存储服务” > “共享…...

【知网CNKI-注册安全分析报告】
前言 由于网站注册入口容易被黑客攻击,存在如下安全问题: 暴力破解密码,造成用户信息泄露短信盗刷的安全问题,影响业务及导致用户投诉带来经济损失,尤其是后付费客户,风险巨大,造成亏损无底洞…...

【Python_GUI】tkinter常用组件——文本类组件
文本时窗口中必不可少的一部分,tkinter模块中,有3种常用的文本类组件,通过这3种组件,可以在窗口中显示以及输入单行文本、多行文本、图片等。 Label标签组件 Label组件的基本使用 Label组件是窗口中比较常用的组件,…...

zdppy+onlyoffice+vue3解决文档加载和文档强制保存时弹出警告的问题
解决过程 第一次排查 最开始排查的是官方文档说的 https://api.onlyoffice.com/editors/troubleshooting#key 解决方案。参考的是官方的 https://github.com/ONLYOFFICE/document-server-integration/releases/latest/download/Python.Example.zip 基于Django的Python代码。 …...

C语言从头学31——与字符串变量相关的几个函数
strlen、strcpy、strcat、strcmp、sprintf这些函数都是与字符串相关的,除了sprintf是定义在stdio.h中外,其余几个都定义在string.h中,比较新的编译器版本stdio.h中已经含有string.h的内容,所以编程时不需要再包含string.h这个头文…...

Laravel批量插入数据:提升数据库操作效率的秘诀
Laravel批量插入数据:提升数据库操作效率的秘诀 Laravel作为PHP的现代Web应用框架,提供了优雅而简洁的方法来处理数据库操作。批量插入数据是数据库操作中常见的需求,尤其是在处理大量数据时,批量插入可以显著提高性能。本文将详…...

OpenCV:解锁计算机视觉的魔法钥匙
OpenCV:解锁计算机视觉的魔法钥匙 在人工智能与图像处理的世界里,OpenCV是一个响当当的名字。作为计算机视觉领域的瑞士军刀,OpenCV以其丰富的功能库、跨平台的特性以及开源的便利性,成为了开发者手中不可或缺的工具。本文将深入…...
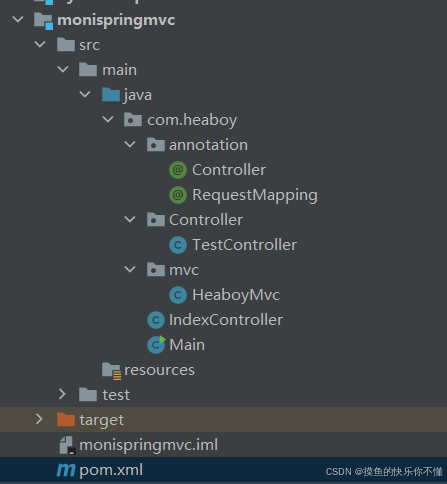
手写简单模拟mvc
目录结构: 两个注解类: Controller: package com.heaboy.annotation;import java.lang.annotation.*;/*** 注解没有功能只是简单标记* .RUNTIME 运行时还能看到* .CLASS 类里面还有,构建对象久没来了,这个说明…...

【FreeRTOS】同步互斥与通信 FreeRTOS提供的方法
目录 各类方法的对比队列事件组信号量互斥量任务通知 各类方法的本质 使用全局变量可以实现通信,但是使用全局变量会有一些缺陷。 那我们怎么保证通信的正确性呢??? 我们需要引入很多互斥的方法。除了互斥之外,还需要高…...

Kafka 面试题指南
Kafka 面试题指南 本文档提供了一份详细的 Kafka 面试题指南,涵盖了 Kafka 的核心概念、架构、配置、操作和实际应用场景等方面的内容。希望通过这份指南能够帮助你在 Kafka 面试中取得成功。 目录 Kafka 基础知识 什么是 Kafka?Kafka 的主要特点是什…...

2024年7月5日 (周五) 叶子游戏新闻
老板键工具来唤去: 它可以为常用程序自定义快捷键,实现一键唤起、一键隐藏的 Windows 工具,并且支持窗口动态绑定快捷键(无需设置自动实现)。 卸载工具 HiBitUninstaller: Windows上的软件卸载工具 《乐高地平线大冒险》为何不登陆…...

热门开源项目推荐:探索开源世界的精彩
热门开源项目推荐 随着开源程序的发展,越来越多的程序员开始关注并加入开源大模型的行列。开源不仅为个人学习和成长提供了绝佳的平台,也为整个技术社区带来了创新和进步。无论你是初学者还是经验丰富的开发者,参与开源项目都能让你受益匪浅…...

Codeforces Round #956 (Div. 2) and ByteRace 2024(A~D题解)
这次比赛也是比较吃亏的,做题顺序出错了,先做的第三个,错在第三个数据点之后,才做的第二个(因为当时有个地方没检查出来)所以这次比赛还是一如既往地打拉了 那么就来发一下题解吧 A. Array Divisibility …...
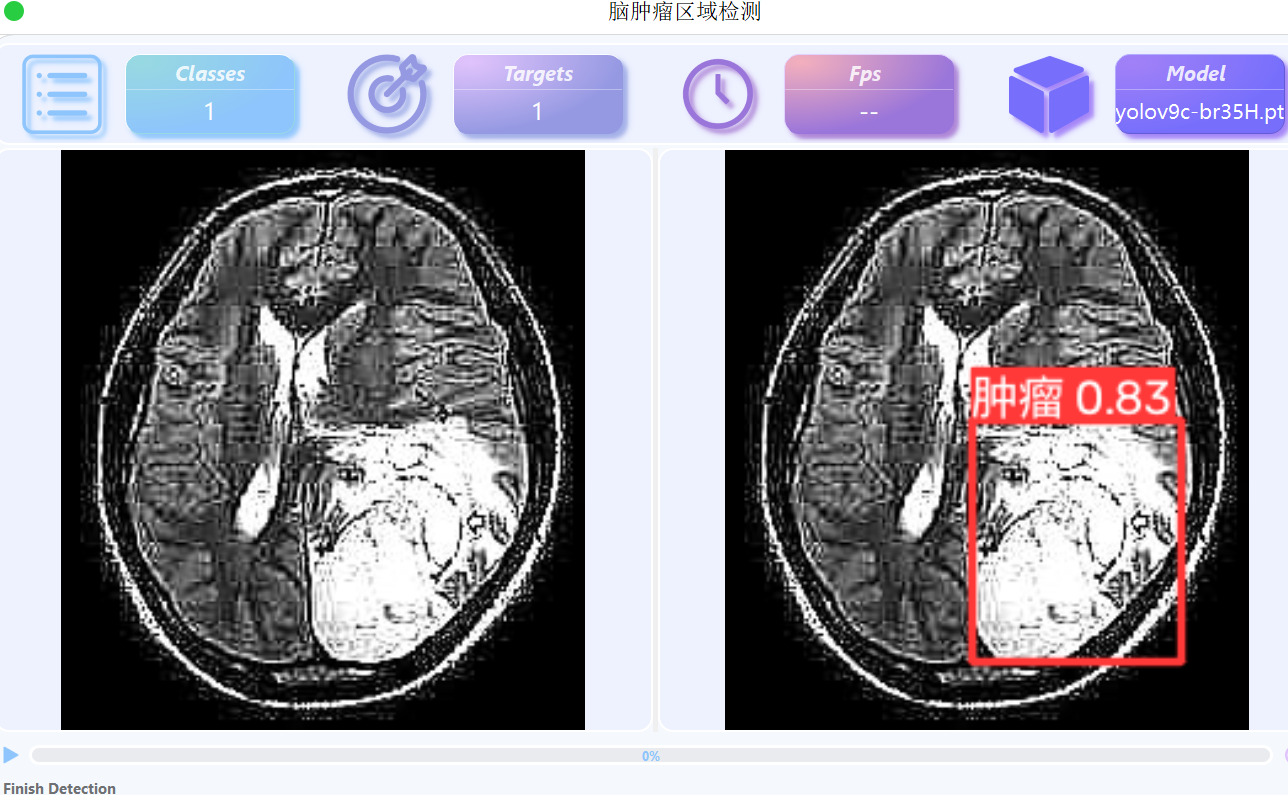
基于YOLOv9的脑肿瘤区域检测
数据集 脑肿瘤区域检测,我们直接采用kaggle公开数据集,Br35H 数据中已对医学图像中脑肿瘤位置进行标注 数据集我已经按照YOLO格式配置好,数据内容如下 数据集中共包含700张图像,其中训练集500张,验证集200张 模型训…...
阿里云 ECS 服务器的安全组设置
阿里云 ECS 服务器的安全组设置 缘由安全组多个安全组各司其职一些常见的IP段百度 IP 段华为云 IP 段搜狗蜘蛛 IP 段阿里云 IP 段 。。。 缘由 最近公司规模缩减,原有的托管在 IDC 机房的服务器,都被处理掉了,所有代码都迁移到了阿里云的云服…...

小米智能家居与Home Assistant深度整合方案
小米智能家居与Home Assistant深度整合方案 【免费下载链接】ha_xiaomi_home Xiaomi Home Integration for Home Assistant 项目地址: https://gitcode.com/GitHub_Trending/ha/ha_xiaomi_home 小米智能家居与Home Assistant的深度整合为用户提供了全面的智能设备控制解…...

java篇26-Java匿名内部类、invoke方法、动态代理
一、匿名内部类 匿名内部类一般作为方法的参数,这个方法的形参为接口,而实参为匿名内部类(可以理解为接口的对象)并且重写了接口中的方法。 书写形式: new <接口名>(){ Overvide //重写方法 }例如: 定…...

终极指南:5分钟掌握Piper鼠标地图组件与SVG渲染核心技术
终极指南:5分钟掌握Piper鼠标地图组件与SVG渲染核心技术 【免费下载链接】piper GTK application to configure gaming devices 项目地址: https://gitcode.com/gh_mirrors/pip/piper Piper是一款功能强大的GTK应用程序,专为配置游戏设备而设计。…...
对齐工具(左对齐/居中对齐/右对齐)对齐工具(左对齐/居中对齐/右对齐)对齐工具(左对齐/居中对齐/右对齐)对齐工具(左对齐/)
《QGIS快速入门与应用基础》248:对齐工具(左对齐/居中对齐/右对齐)对齐工具(左对齐/居中对齐/右对齐)对齐工具(左对齐/居中对齐/右对齐)对齐工具(左对齐/居中对齐/右对齐)对齐工具(左对齐/
作者:翰墨之道,毕业于国际知名大学空间信息与计算机专业,获硕士学位,现任国内时空智能领域资深专家、CSDN知名技术博主。多年来深耕地理信息与时空智能核心技术研发,精通 QGIS、GrassGIS、OSG、OsgEarth、UE、Cesium、OpenLayers、Leaflet、MapBox 等主流工具与框架,兼具…...

iOS设备安全定制指南:使用Cowabunga Lite实现零风险个性化配置
iOS设备安全定制指南:使用Cowabunga Lite实现零风险个性化配置 【免费下载链接】CowabungaLite iOS 15 Customization Toolbox 项目地址: https://gitcode.com/gh_mirrors/co/CowabungaLite iOS系统的封闭性常让用户陷入个性化与安全性的两难选择——越狱虽能…...
)
用MQTT协议玩转OneNet物联网:STM32F103+ESP8266实现温湿度监控(附心跳包优化技巧)
STM32F103与ESP8266的物联网实战:MQTT协议深度优化与温湿度监控系统设计 1. 资源受限环境下的物联网通信架构设计 在嵌入式物联网设备开发中,资源优化始终是核心挑战。STM32F103C8T6作为经典的Cortex-M3内核微控制器,仅有64KB Flash和20KB RA…...

工业软件全景图:从核心分类到行业深度应用指南
深入理解现代制造业的核心驱动力一、 工业之魂:现代制造业的核心引擎在智能制造与工业4.0的浪潮下,工业软件已不再仅仅是辅助工具,而是被公认为“工业之魂”。它将复杂的工业知识、逻辑和经验代码化,嵌入到硬件设备和业务流程中&a…...

【空气涡轮发动机Matlab_simulink动态仿真模型 ✔【空气涡轮发动机Matlab_simulink动态仿真模型】 1、部件级模型;进气道,涡轮,气室,压气机,尾喷管,转子模块,容积模块 2、
【空气涡轮发动机Matlab/simulink动态仿真模型 ✔【空气涡轮发动机Matlab/simulink动态仿真模型】 1、部件级模型;进气道,涡轮,气室,压气机,尾喷管,转子模块,容积模块 2、PID控制器: 输出扭矩阶跃扰动下&am…...

告别动物实验?AI设计抗体成功率低怎么办?聊聊RFdiffusion的局限与未来优化方向
AI抗体设计的突破与挑战:从RFdiffusion看技术瓶颈与未来路径 当David Baker团队在bioRxiv上发布利用RFdiffusion实现抗体原子级精度从头设计的论文时,整个AI制药领域为之振奋。这项技术突破意味着,我们可能正站在抗体药物研发范式转变的临界点…...
)
气象防灾实战:如何用QGIS快速生成暴雨等值面预警图?(含历史数据对比)
气象防灾实战:如何用QGIS快速生成暴雨等值面预警图?(含历史数据对比) 暴雨灾害的预警与防控一直是应急管理和市政规划领域的核心挑战。传统的气象数据分析往往依赖专业软件和复杂代码,让非技术背景的从业者望而却步。本…...