MySQL篇五:基本查询
文章目录
- 前言
- 1. Create
- 1.1 单行数据 + 全列插入
- 1.2 多行数据 + 指定列插入
- 1.3 插入否则更新
- 1.4 替换
- 2. Retrieve
- 2.1 SELECT 列
- 2.1.1 全列查询
- 2.1.2 指定列查询
- 2.1.3 查询字段为表达式
- 2.1.4 为查询结果指定别名
- 2.1.5 结果去重
- 2.2 WHERE 条件
- 2.2.1 练习
- 2.3 结果排序
- 2.3.1 练习
- 2.4 筛选分页结果
- 3. Update
- 3.1 练习
- 4. Delete
- 4.1 练习
- 4.2 截断表
- 5. 插入查询结果
- 6. 聚合函数
- 6.1 练习
- 7. group by子句的使用
- 7.1 练习
前言
表的增删改查:CRUD : Create(创建), Retrieve(读取),Update(更新),Delete(删除)。
1. Create
语法:
INSERT [INTO] table_name[(column [, column] ...)]VALUES (value_list) [, (value_list)] ...value_list: value, [, value] ...
样例:
CREATE TABLE students (id INT UNSIGNED PRIMARY KEY AUTO_INCREMENT,sn INT NOT NULL UNIQUE COMMENT '学号',name VARCHAR(20) NOT NULL,qq VARCHAR(20)
);
1.1 单行数据 + 全列插入
INSERT INTO students VALUES (100, 10000, '唐三藏', NULL);
1.2 多行数据 + 指定列插入
INSERT INTO students (id, sn, name) VALUES
(102, 20001, '曹孟德'),
(103, 20002, '孙仲谋');
1.3 插入否则更新
如果插入的数据发生冲突,则进行修正。
可以选择性的进行同步更新操作 语法:
INSERT ... ON DUPLICATE KEY UPDATEcolumn = value [, column = value] ...
样例:
INSERT INTO students (id, sn, name) VALUES (100, 10010, '唐大师')ON DUPLICATE KEY UPDATE sn = 10010, name = '唐大师';
解释:如果(100, 10010, ‘唐大师’)发生数据冲突,则将已插入的值修改为 sn = 10010, name = ‘唐大师’。比如说此时数据库中有(100, 9999, ‘唐玄奘’),由于id是主键,新插入数据的id发生了冲突,那么就会将(100, 9999, ‘唐玄奘’)改为(100, 10010, ‘唐大师’)。
SELECT ROW_COUNT(); //通过 MySQL 函数获取受到影响的数据行数
1.4 替换
-- 主键 或者 唯一键 没有冲突,则直接插入;
-- 主键 或者 唯一键 如果冲突,则删除后再插入
REPLACE INTO students (sn, name) VALUES (20001, '曹阿瞒');Query OK, 2 rows affected (0.00 sec)
2. Retrieve
语法:
SELECT[DISTINCT] {* | {column [, column] ...}[FROM table_name][WHERE ...][ORDER BY column [ASC | DESC], ...]LIMIT ...
样例:
-- 创建表结构
CREATE TABLE exam_result (id INT UNSIGNED PRIMARY KEY AUTO_INCREMENT,name VARCHAR(20) NOT NULL COMMENT '同学姓名',chinese float DEFAULT 0.0 COMMENT '语文成绩',math float DEFAULT 0.0 COMMENT '数学成绩',english float DEFAULT 0.0 COMMENT '英语成绩'
);
2.1 SELECT 列
2.1.1 全列查询
-- 通常情况下不建议使用 * 进行全列查询
-- 1. 查询的列越多,意味着需要传输的数据量越大;
-- 2. 可能会影响到索引的使用。(索引待后面讲解)SELECT * FROM exam_result;
2.1.2 指定列查询
-- 指定列的顺序不需要按定义表的顺序来
SELECT id, name, english FROM exam_result;
2.1.3 查询字段为表达式
-- 表达式不包含字段
SELECT id, name, 10 FROM exam_result;
-- 表达式包含一个字段
SELECT id, name, english + 10 FROM exam_result;
-- 表达式包含多个字段
SELECT id, name, chinese + math + english FROM exam_result;
2.1.4 为查询结果指定别名
语法:
SELECT column [AS] alias_name [...] FROM table_name;
样例:
SELECT id, name, chinese + math + english 总分 FROM exam_result;
2.1.5 结果去重
-- 98 分重复了
SELECT math FROM exam_result;
-- 去重结果
SELECT DISTINCT math FROM exam_result;
2.2 WHERE 条件
比较运算符:
| 运算符 | 说明 |
|---|---|
| >, >=, <, <= | 大于,大于等于,小于,小于等于 |
| = | 等于,NULL 不安全,例如 NULL = NULL 的结果是 NULL |
| <=> | 等于,NULL 安全,例如 NULL <=> NULL 的结果是 TRUE(1) |
| !=, <> | 不等于 |
| BETWEEN a0 AND a1 | 范围匹配,[a0, a1],如果 a0 <= value <= a1,返回 TRUE(1) |
| IN (option, …) | 如果是 option 中的任意一个,返回 TRUE(1) |
| IS NULL | 是 NULL |
| IS NOT NULL | 不是 NULL |
| LIKE | 模糊匹配。% 表示任意多个(包括 0 个)任意字符;_ 表示任意一个字符 |
逻辑运算符:
| 运算符 | 说明 |
|---|---|
| AND | 多个条件必须都为 TRUE(1),结果才是 TRUE(1) |
| OR | 任意一个条件为 TRUE(1), 结果为 TRUE(1) |
| NOT | 条件为 TRUE(1),结果为 FALSE(0) |
2.2.1 练习
英语不及格的同学及英语成绩 ( < 60 )
-- 基本比较
SELECT name, english FROM exam_result WHERE english < 60;
语文成绩在 [80, 90] 分的同学及语文成绩
-- 使用 AND 进行条件连接
SELECT name, chinese FROM exam_result WHERE chinese >= 80 AND chinese <= 90;
-- 使用 BETWEEN ... AND ... 条件
SELECT name, chinese FROM exam_result WHERE chinese BETWEEN 80 AND 90;
数学成绩是 58 或者 59 或者 98 或者 99 分的同学及数学成绩
-- 使用 OR 进行条件连接
SELECT name, math FROM exam_resultWHERE math = 58OR math = 59OR math = 98OR math = 99;
-- 使用 IN 条件
SELECT name, math FROM exam_result WHERE math IN (58, 59, 98, 99);
姓孙的同学及孙某同学
-- % 匹配任意多个(包括 0 个)任意字符
SELECT name FROM exam_result WHERE name LIKE '孙%';
-- _ 匹配严格的一个任意字符
SELECT name FROM exam_result WHERE name LIKE '孙_';
语文成绩好于英语成绩的同学
-- WHERE 条件中比较运算符两侧都是字段
SELECT name, chinese, english FROM exam_result WHERE chinese > english;
总分在 200 分以下的同学
-- WHERE 条件中使用表达式
-- 别名不能用在 WHERE 条件中
SELECT name, chinese + math + english 总分 FROM exam_result
WHERE chinese + math + english < 200;
语文成绩 > 80 并且不姓孙的同学
-- AND 与 NOT 的使用
SELECT name, chinese FROM exam_resultWHERE chinese > 80 AND name NOT LIKE '孙%';
孙某同学,否则要求总成绩 > 200 并且 语文成绩 < 数学成绩 并且 英语成绩 > 80
-- 综合性查询
SELECT name, chinese, math, english, chinese + math + english 总分
FROM exam_result
WHERE name LIKE '孙_' OR (chinese + math + english > 200 AND chinese < math AND english > 80
);
NULL 的查询
-- 查询 qq 号已知的同学姓名
SELECT name, qq FROM students WHERE qq IS NOT NULL;
-- NULL 和 NULL 的比较,= 和 <=> 的区别
SELECT NULL = NULL, NULL = 1, NULL = 0;
+-------------+----------+----------+
| NULL = NULL | NULL = 1 | NULL = 0 |
+-------------+----------+----------+
| NULL | NULL | NULL |
+-------------+----------+----------+
SELECT NULL <=> NULL, NULL <=> 1, NULL <=> 0;
+---------------+------------+------------+
| NULL <=> NULL | NULL <=> 1 | NULL <=> 0 |
+---------------+------------+------------+
| 1 | 0 | 0 |
+---------------+------------+------------+
如果使用=让null和其他值进行比较,结果都是null。如果使用<=>让null进行比较,只有 NULL <=> NULL的结果为1(真),其他都为0(假),因为null和0是不一样的。
2.3 结果排序
语法:
-- ASC 为升序(从小到大)
-- DESC 为降序(从大到小)
-- 默认为 ASCSELECT ... FROM table_name [WHERE ...]ORDER BY column [ASC|DESC], [...];
注意:没有 ORDER BY 子句的查询,返回的顺序是未定义的,永远不要依赖这个顺序。
2.3.1 练习
同学及数学成绩,按数学成绩升序显示
SELECT name, math FROM exam_result ORDER BY math;
同学及 qq 号,按 qq 号排序显示
-- NULL 视为比任何值都小,升序出现在最上面
SELECT name, qq FROM students ORDER BY qq;
-- NULL 视为比任何值都小,降序出现在最下面
SELECT name, qq FROM students ORDER BY qq DESC;
查询同学各门成绩,依次按 数学降序,英语升序,语文升序的方式显示
-- 多字段排序,排序优先级随书写顺序
SELECT name, math, english, chinese FROM exam_resultORDER BY math DESC, english, chinese;
查询同学及总分,由高到低
SELECT name, chinese + english + math FROM exam_resultORDER BY chinese + english + math DESC;
-- ORDER BY 子句中可以使用列别名
SELECT name, chinese + english + math 总分 FROM exam_resultORDER BY 总分 DESC;
查询姓孙的同学或者姓曹的同学数学成绩,结果按数学成绩由高到低显示
-- 结合 WHERE 子句 和 ORDER BY 子句
SELECT name, math FROM exam_resultWHERE name LIKE '孙%' OR name LIKE '曹%'ORDER BY math DESC;
-- 错的,在where后面不允许使用别名
select chinese+math as total from exam_result where total > 150;
select chinese+math as total from exam_result where chinese+math > 150;-- 正确的,order by 后面可以使用别名,为什么呢?
select chinese+math as total from exam_result order by total asc;
2.4 筛选分页结果
语法:
-- 起始下标为 0-- 从 s 开始,筛选 n 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT s, n-- 从 0 开始,筛选 n 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n;
;
-- 从 s 开始,筛选 n 条结果,比第二种用法更明确,建议使用
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n OFFSET s;
建议:对未知表进行查询时,最好加一条 LIMIT 1,避免因为表中数据过大,查询全表数据导致数据库卡死,按 id 进行分页,每页 3 条记录,分别显示 第 1、2、3 页
-- 第 1 页
SELECT id, name, math, english, chinese FROM exam_resultORDER BY id LIMIT 3 OFFSET 0;
-- 第 2 页
SELECT id, name, math, english, chinese FROM exam_resultORDER BY id LIMIT 3 OFFSET 3;
-- 第 3 页,如果结果不足 3 个,不会有影响
SELECT id, name, math, english, chinese FROM exam_resultORDER BY id LIMIT 3 OFFSET 6;
3. Update
语法:
UPDATE table_name SET column = expr [, column = expr ...][WHERE ...] [ORDER BY ...] [LIMIT ...]
3.1 练习
将孙悟空同学的数学成绩变更为 80 分
UPDATE exam_result SET math = 80 WHERE name = '孙悟空';
将曹孟德同学的数学成绩变更为 60 分,语文成绩变更为 70 分
UPDATE exam_result SET math = 60, chinese = 70 WHERE name = '曹孟德';
将总成绩倒数前三的 3 位同学的数学成绩加上 30 分
-- 数据更新,不支持 math += 30 这种语法
UPDATE exam_result SET math = math + 30ORDER BY chinese + math + english LIMIT 3;-- 思考:这里还可以按总分升序排序取前 3 个么?
SELECT name, math, chinese + math + english 总分 FROM exam_resultORDER BY 总分 LIMIT 3;
将所有同学的语文成绩更新为原来的 2 倍
UPDATE exam_result SET chinese = chinese * 2;
4. Delete
语法:
DELETE FROM table_name [WHERE ...] [ORDER BY ...] [LIMIT ...]
4.1 练习
删除孙悟空同学的考试成绩
DELETE FROM exam_result WHERE name = '孙悟空';
删除整张表数据
DELETE FROM for_delete;
清除表数据,auto_increment并不会变为0,依旧是清楚前的大小。截断表会清除auto_increment。
4.2 截断表
语法:
TRUNCATE [TABLE] table_name
注意:这个操作慎用
- 只能对整表操作,不能像 DELETE 一样针对部分数据操作;
- 实际上 MySQL 不对数据操作,所以比 DELETE 更快,但是TRUNCATE在删除数据的时候,并不经过真正的事物,所以无法回滚
- 会重置 AUTO_INCREMENT 项
-- 截断整表数据,注意影响行数是 0,所以实际上没有对数据真正操作
TRUNCATE for_truncate;
5. 插入查询结果
语法:
INSERT INTO table_name [(column [, column ...])] SELECT ...
-- 将 duplicate_table 的去重数据插入到 no_duplicate_table
INSERT INTO no_duplicate_table SELECT DISTINCT * FROM duplicate_table;-- 通过重命名表,实现原子的去重操作
RENAME TABLE duplicate_table TO old_duplicate_table,
no_duplicate_table TO duplicate_table;
6. 聚合函数
| 函数 | 说明 |
|---|---|
| COUNT([DISTINCT] expr) | 返回查询到的数据的数量 |
| SUM([DISTINCT] expr) | 返回查询到的数据的 总和,不是数字没有意义 |
| AVG([DISTINCT] expr) | 返回查询到的数据的 平均值,不是数字没有意义 |
| MAX([DISTINCT] expr) | 返回查询到的数据的 最大值,不是数字没有意义 |
| MIN([DISTINCT] expr) | 返回查询到的数据的 最小值,不是数字没有意义 |
6.1 练习
统计班级共有多少同学
-- 使用 * 做统计,不受 NULL 影响
SELECT COUNT(*) FROM students;-- 使用表达式做统计
SELECT COUNT(1) FROM students;
统计班级收集的 qq 号有多少
-- NULL 不会计入结果
SELECT COUNT(qq) FROM students;
统计本次考试的数学成绩分数个数
-- COUNT(math) 统计的是全部成绩
SELECT COUNT(math) FROM exam_result;-- COUNT(DISTINCT math) 统计的是去重成绩数量
SELECT COUNT(DISTINCT math) FROM exam_result;
统计数学成绩总分
SELECT SUM(math) FROM exam_result;-- 不及格 < 60 的总分,没有结果,返回 NULL
SELECT SUM(math) FROM exam_result WHERE math < 60;
统计平均总分
SELECT AVG(chinese + math + english) 平均总分 FROM exam_result;
返回英语最高分
SELECT MAX(english) FROM exam_result;
返回 > 70 分以上的数学最低分
SELECT MIN(math) FROM exam_result WHERE math > 70;
7. group by子句的使用
分组,聚合统计
在select中使用group by 子句可以对指定列进行分组查询:
select column1, column2, .. from table group by column;
样例:
准备工作,创建一个雇员信息表(来自oracle 9i的经典测试表)
- EMP员工表
- DEPT部门表
- SALGRADE工资等级表
group by —— 指定列名,实际分组,是用该列的不同行的数据来进行分组。分组的条件depton(下面的第一个例子),组内一定是相同的,是可以被聚合压缩的。
分组,就是把一组按照条件拆分成了多个组,进行各自组内的统计。分组(“分表”),就是把一长表按照条件在逻辑上拆成了多个元素,然后分别对各自的子表进行聚合统计。
7.1 练习
如何显示每个部门的平均工资和最高工资
select deptno,avg(sal),max(sal) from EMP group by deptno;
显示每个部门的每种岗位的平均工资和最低工资
select avg(sal),min(sal),job, deptno from EMP group by deptno, job;
只有分组之后的信息才能卸载select后面,在上面也就是只有depton和job可以写在select后面。
显示平均工资低于2000的部门和它的平均工资
1. 统计各个部门的平均工资
select avg(sal) from EMP group by deptno
2. having和group by配合使用,对group by结果进行过滤
select avg(sal) as myavg from EMP group by deptno having myavg<2000;
--having经常和group by搭配使用,作用是对分组进行筛选,作用有些像where
having 和 where区别理解?执行顺序,构建对 “结果” 的理解。
where是对具体的一列进行筛选,having是对分组聚合后的结果进行筛选。条件筛选的阶段是不同的。
不要单纯的认为,只有磁盘上的表结构导入到MySQL,真实存在的表,才叫做表。在MySQL中间筛选出来的表,包括最终的结果,在我看来都是逻辑上的表。
面试题:SQL查询中各个关键字的执行先后顺序 from > on> join > where > group by > with > having > select> distinct > order by > limit
相关文章:

MySQL篇五:基本查询
文章目录 前言1. Create1.1 单行数据 全列插入1.2 多行数据 指定列插入1.3 插入否则更新1.4 替换 2. Retrieve2.1 SELECT 列2.1.1 全列查询2.1.2 指定列查询2.1.3 查询字段为表达式2.1.4 为查询结果指定别名2.1.5 结果去重 2.2 WHERE 条件2.2.1 练习 2.3 结果排序2.3.1 练习 …...
FreeBSD@ThinkPad x250因电池耗尽关机后无法启动的问题存档
好几次碰到电池耗尽FreeBSD关机,再启动,网络通了之后到了该出Xwindows窗体的时候,屏幕灭掉,网络不通,只有风扇在响,启动失败。关键是长按开关键后再次开机,还是启动失败。 偶尔有时候重启到单人…...

pdfplumber vs PyMuPDF:PDF文本、图像和表格识别的比较
pdfplumber vs PyMuPDF:PDF文本、图像和表格识别的比较 1. 文本提取pdfplumberPyMuPDF 2. 图像提取pdfplumberPyMuPDF 3. 表格提取pdfplumberPyMuPDF 总结 在处理PDF文件时,提取文本、图像和表格是常见的需求。本文将比较两个流行的Python PDF处理库:pdfplumber和PyMuPDF(fitz)…...

深入Django系列
Django简介与环境搭建 引言 在这个系列的第一天,我们将从Django的基本概念开始,逐步引导你搭建一个Django开发环境,并运行你的第一个Django项目。 Django简介 Django是一个开源的Web框架,它鼓励快速开发和干净、实用的设计。D…...

【Python】找Excel重复行
【背景】 找重复行虽然可以通过Excel实现,但是当数据量巨大时光是找结果就很费时间,所以考虑用Python实现。 【代码】 import pandas as pd# 读取Excel文件 file_path = your excel file path df = pd.read_excel(file_path)# 查找重复行 # 这里假设要检查所有列的重复项 …...

重读AI金典算法模型-GPT系列
2023年对于AI来说,可以算是一个里程碑式的年份,随着OpenAI的chatGPT的大火,遍地的生成式AI应用应运而生。在这些上层应用大放异彩的时候,我们需要了解一些底层的算法模型,并从中窥探出为什么时代选择了OpenAI的chatGPT…...

仙人掌中的SNMP检测不到服务器
登录有问题的服务器1.检测snmp localhost:~ # ps -ef|grep snmp root 55180 1 0 08:37 ? 00:00:08 /usr/sbin/snmpd -r -A -LF n /var/log/net-snmpd.log -p /var/run/snmpd.pid root 58436 53989 0 09:44 pts/0 00:00:00 grep --colorauto snmp2.检测…...
git只列出本地分支
git只列出本地分支 git branch --list git强制删除本地分支 git branch -D_error: the branch dlx-test is not fully merged. -CSDN博客文章浏览阅读648次。git branch -d 可以通过: git branch 查看所有本地分支及其名字,然后删除特定分支。git删除远程remote分支…...

算力狂飙|WAIC 2024上的服务器
7月7日,2024世界人工智能大会暨人工智能全球治理高级别会议(WAIC 2024)在上海落下帷幕。这场备受瞩目的AI盛宴与热辣夏日碰撞,吸引了全球科技、产业及学术界的广泛关注,线下参观人数突破30万人次,线上流量突…...
)
uniapp app端跳转第三方app(高德地图/百度地图为例)
1.先写一个picker选择器 <picker change"bindPickerChange" :value"index" :range"array"><view class"uni-input">{{array[index] || 打开第三方app }}</view></picker> 2.在data中定义好高德地图/百度地图…...
阿里云RDS云数据库库表恢复操作
最近数据库中数据被人误删了,记录一下恢复操作方便以后发生时进行恢复. 1.打开控制台,进入云数据库实例. 2.进入实例后 ,点击右侧的备份恢复,然后看一下备份时间点,中间这边都是阿里云自动备份的备份集,基本都是7天一备…...
来一场栈的大模拟(主要是单调栈)
一.栈模拟 二.单调栈求最大矩形面积 通常,直方图用于表示离散分布,例如,文本中字符的频率。 现在,请你计算在公共基线处对齐的直方图中最大矩形的面积。 图例右图显示了所描绘直方图的最大对齐矩形。 输入格式 输入包含几个测…...
13 - matlab m_map地学绘图工具基础函数 - 介绍创建管理颜色映射的函数m_colmap和轮廓图绘制颜色条的函数m_contfbar
13 - matlab m_map地学绘图工具基础函数 - 介绍创建管理颜色映射的函数m_colmap和轮廓图绘制颜色条的函数m_contfbar 0. 引言1. 关于m_colmap2. 关于m_contfbar3. 结语 0. 引言 本篇介绍下m_map中用于创建和管理颜色映射函数(m_colmap)和 为轮廓图绘制颜…...
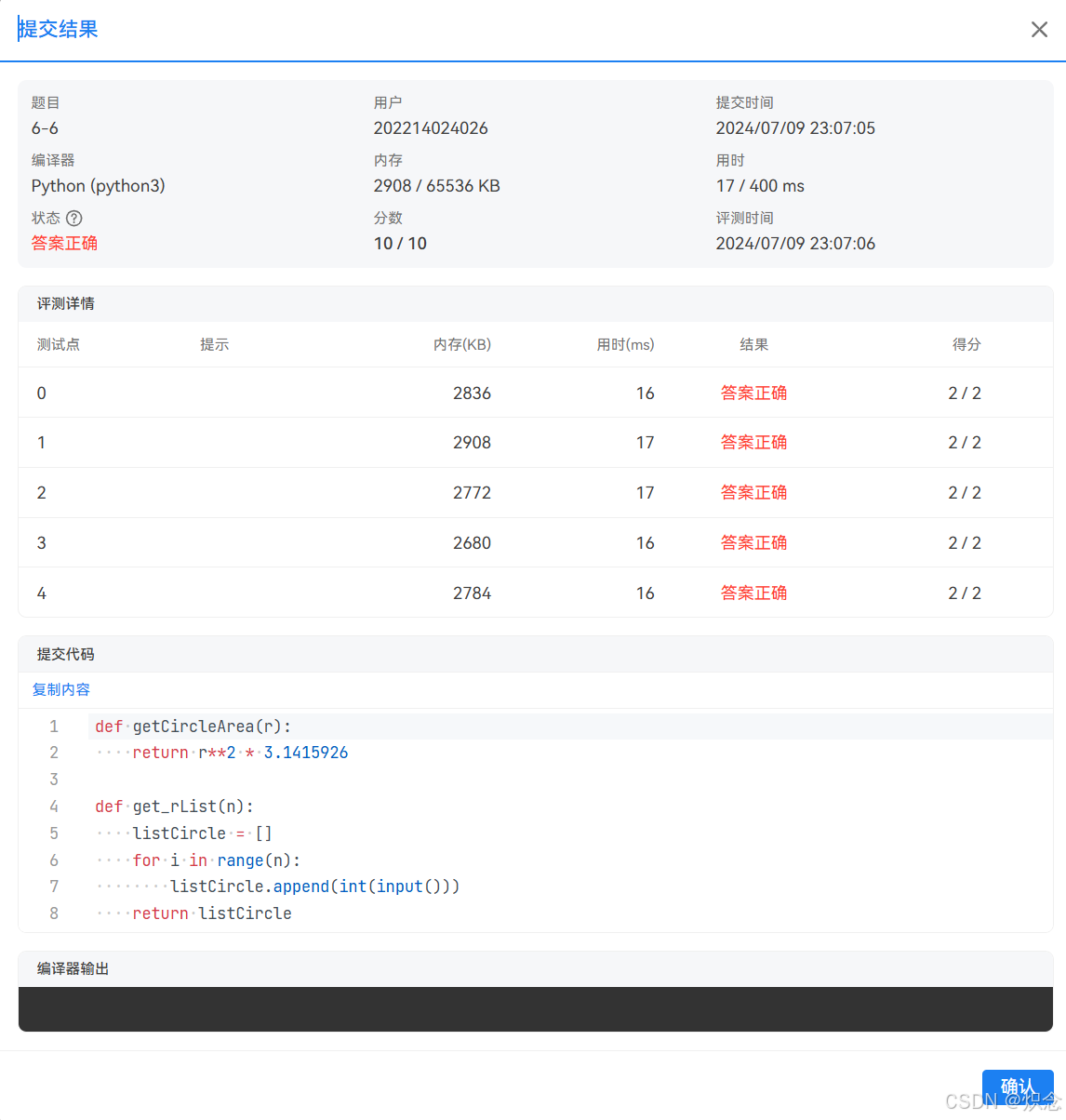
PTA - 编写函数计算圆面积
题目描述: 1.要求编写函数getCircleArea(r)计算给定半径r的圆面积,函数返回圆的面积。 2.要求编写函数get_rList(n) 输入n个值放入列表并将列表返回 函数接口定义: getCircleArea(r); get_rList(n); 传入的参数r表示圆的半径,…...

Golang | Leetcode Golang题解之第218题天际线问题
题目: 题解: type pair struct{ right, height int } type hp []pairfunc (h hp) Len() int { return len(h) } func (h hp) Less(i, j int) bool { return h[i].height > h[j].height } func (h hp) Swap(i, j int) { h[i], h[j]…...

【Mars3d】osgb倾斜摄影模型加载慢卡顿的优化方案参考
倾斜摄影模型文件一共6个多g,一个村子十几间房, 服务器配置:8c16g 100M 答: 目前可以对 3dtiles 模型有下面 3 方法来入手: 数据处理层面,比如数据处理工具的选择、和选择的工具本身的一些优化参数的设…...

认识同源策略
同源策略是一种浏览器安全机制,用于限制一个源的文档或脚本如何与另一个源的资源进行交互。源由协议(如HTTP或HTTPS)、域名和端口号组成。如果两个URL的协议、域名和端口都相同,则它们具有相同的源。 同源策略主要影响以下几个方…...

ADOQuery 查询MSSQL存储过程一个莫名其妙的错误;
在 SSMS 中执行完成正常的的存储过程。 也能正常的返回想要的数据,,然后通过 ADO 查询时,总是提法 某 字段不存在的问题; 此问题困扰了一天。 例如(当然,实际数据结构比下面举例的复杂)&…...

变阻器的分类
变阻器作为用于调节电路中电阻值的电子元件,在电子电路中具有广泛的应用。根据不同的工作原理和结构形式,变阻器可以分为多种类型。以下是对变阻器分类的详细阐述: 一、按工作原理分类 电位器是一种通过滑动端位置调节电阻值的变阻器&#x…...

微服务节流阀:Eureka中服务限流策略的精妙实现
微服务节流阀:Eureka中服务限流策略的精妙实现 引言 在微服务架构中,服务的稳定性和可靠性至关重要。限流策略作为保障服务稳定性的一种手段,通过控制服务的访问速率,可以有效避免服务过载和故障扩散。Eureka作为Netflix开源的服…...

Claude code热门快捷指令清单
文章目录1、Claude code 热门快捷指令1.1、上下文控制类1.2、回退与实验类1.3、质量审查类1.4、模型与成本控制类1.5、自动化与远程协作类1.6、官方热门指令清单1、Claude code 热门快捷指令 Claude code热门快捷指令清单。分为上下文控制、回退与实验、质量审查、模型与成本控…...

告别内存泄漏和数组越界:用CppCheck给你的C++项目做一次免费‘体检’
深度解析CppCheck:为C项目构建坚不可摧的代码防线 在当今快节奏的软件开发环境中,代码质量往往成为项目后期维护的隐形杀手。许多C开发者都有过这样的经历:代码编译通过,测试用例跑通,却在生产环境中遭遇诡异崩溃。这些…...

WSL启动器openclaw-wsl-launcher:提升Windows与Linux开发效率的桥梁工具
1. 项目概述:一个为WSL设计的OpenClaw启动器如果你和我一样,日常开发的主力环境是Windows,但核心的编译、部署和测试工作又离不开Linux,那么Windows Subsystem for Linux(WSL)绝对是你绕不开的利器。它让我…...

工业物联网实战:连接老旧设备与数据孤岛的三步走策略
1. 工业物联网的“孤岛”困境与连接之道在工业自动化领域干了十几年,我亲眼见证了从最初的继电器逻辑控制,到PLC、DCS,再到如今炙手可热的工业物联网(IIoT)的整个演进过程。一个最深刻的感受是:技术浪潮总是…...

Simba MCP Server:用AI助手对话式驱动贝叶斯营销组合模型分析
1. 项目概述:当贝叶斯营销组合模型遇上AI助手如果你是一名市场分析师、营销科学家,或者任何需要回答“我的营销预算到底花得值不值”的人,那么你对营销组合模型(MMM)一定不陌生。这玩意儿是量化不同营销渠道࿰…...

2026 年 5 月 CERT 发布 dnsmasq 六个严重安全漏洞,2.93 版本或一周左右发布
消息基本信息西蒙凯利在 2026 年 5 月 11 日,周一,协调世界时 17:18:25 发布消息,上一条消息(按线程)是[[Dnsmasq 讨论组] DHCP 请求中电路 ID 匹配问题],下一条消息(按线程)是[[Dns…...

非傍轴效应在量子比特操控中的影响与优化策略
1. 非傍轴效应与量子比特操控:从理论到实验的全景解析在量子计算与模拟领域,光学镊子技术正经历着革命性的发展。这项技术通过高度聚焦的激光束,实现了对单个原子或离子的精确操控,为构建大规模量子处理器提供了可能路径。然而&am…...

16Gb容量+1866Mbps速率:NT6CL512T32AM-H1的LPDDR3移动存储参数解析
NT6CL512T32AM-H1:16Gb LPDDR3移动DRAM的技术解析在移动计算、工业嵌入式以及车载信息娱乐等对功耗和性能双重敏感的应用领域,内存子系统的选择直接影响产品的续航能力和数据处理效率。NT6CL512T32AM-H1是南亚科技推出的一款16Gb LPDDR3 SDRAM࿰…...
)
别再手动画图了!用Python ASE + Matplotlib一键生成高质量材料结构图(附完整代码)
科研绘图革命:用Python ASEMatplotlib实现材料结构可视化自动化 深夜的实验室里,屏幕荧光映照着一张疲惫的脸——这可能是许多材料科学研究者共同的记忆。当你在论文截稿日前夕,还在反复调整VESTA中的原子位置、尝试各种角度截图时࿰…...

【NotebookLM NLP辅助天花板级用法】:谷歌内部未公开的3类Prompt架构+2个隐藏API调用技巧
更多请点击: https://intelliparadigm.com 第一章:NotebookLM NLP任务辅助全景概览 NotebookLM 是 Google 推出的基于用户自有文档的实验性 AI 助手,专为研究者与工程师设计,其核心能力在于对上传文本进行深度语义理解与上下文感…...