ChatGLM-6B入门
ChatGLM-6B
- ChatGLM-6B
一、介绍
ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。 ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答,更多信息请参考我们的博客。此外,为了方便下游开发者针对自己的应用场景定制模型,我们同时实现了基于 P-Tuning v2 的高效参数微调方法 (使用指南) ,INT4 量化级别下最低只需 7GB 显存即可启动微调。
不过,由于 ChatGLM-6B 的规模较小,目前已知其具有相当多的局限性,如事实性/数学逻辑错误,可能生成有害/有偏见内容,较弱的上下文能力,自我认知混乱,以及对英文指示生成与中文指示完全矛盾的内容。请大家在使用前了解这些问题,以免产生误解。更大的基于 1300 亿参数 GLM-130B 的 ChatGLM 正在内测开发中。
二、使用方式
硬件需求
| 量化等级 | 最低 GPU 显存(推理) | 最低 GPU 显存(高效参数微调) |
|---|---|---|
| FP16(无量化) | 13 GB | 14 GB |
| INT8 | 8 GB | 9 GB |
| INT4 | 6 GB | 7 GB |
环境安装
使用 pip 安装依赖:pip install -r requirements.txt,其中 transformers 库版本推荐为 4.27.1,但理论上不低于 4.23.1 即可。
代码调用
可以通过如下代码调用 ChatGLM-6B 模型来生成对话:
python代码解读复制代码>>> from transformers import AutoTokenizer, AutoModel
>>> tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
>>> model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda()
>>> model = model.eval()
>>> response, history = model.chat(tokenizer, "你好", history=[])
>>> print(response)
你好👋!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。
>>> response, history = model.chat(tokenizer, "晚上睡不着应该怎么办", history=history)
>>> print(response)
晚上睡不着可能会让你感到焦虑或不舒服,但以下是一些可以帮助你入睡的方法:1. 制定规律的睡眠时间表:保持规律的睡眠时间表可以帮助你建立健康的睡眠习惯,使你更容易入睡。尽量在每天的相同时间上床,并在同一时间起床。
2. 创造一个舒适的睡眠环境:确保睡眠环境舒适,安静,黑暗且温度适宜。可以使用舒适的床上用品,并保持房间通风。
3. 放松身心:在睡前做些放松的活动,例如泡个热水澡,听些轻柔的音乐,阅读一些有趣的书籍等,有助于缓解紧张和焦虑,使你更容易入睡。
4. 避免饮用含有咖啡因的饮料:咖啡因是一种刺激性物质,会影响你的睡眠质量。尽量避免在睡前饮用含有咖啡因的饮料,例如咖啡,茶和可乐。
5. 避免在床上做与睡眠无关的事情:在床上做些与睡眠无关的事情,例如看电影,玩游戏或工作等,可能会干扰你的睡眠。
6. 尝试呼吸技巧:深呼吸是一种放松技巧,可以帮助你缓解紧张和焦虑,使你更容易入睡。试着慢慢吸气,保持几秒钟,然后缓慢呼气。如果这些方法无法帮助你入睡,你可以考虑咨询医生或睡眠专家,寻求进一步的建议。
完整的模型实现可以在 Hugging Face Hub 上查看。如果你从 Hugging Face Hub 上下载 checkpoint 的速度较慢,也可以从这里手动下载。
Demo
我们提供了一个基于 Gradio 的网页版 Demo 和一个命令行 Demo。使用时首先需要下载本仓库:
shell代码解读复制代码git clone https://github.com/THUDM/ChatGLM-6B
cd ChatGLM-6B
网页版 Demo
首先安装 Gradio:pip install gradio,然后运行仓库中的 web_demo.py:
shell代码解读
复制代码python web_demo.py
程序会运行一个 Web Server,并输出地址。在浏览器中打开输出的地址即可使用。最新版 Demo 实现了打字机效果,速度体验大大提升。注意,由于国内 Gradio 的网络访问较为缓慢,启用 demo.queue().launch(share=True, inbrowser=True) 时所有网络会经过 Gradio 服务器转发,导致打字机体验大幅下降,现在默认启动方式已经改为 share=False,如有需要公网访问的需求,可以重新修改为 share=True 启动。
感谢 @AdamBear 实现了基于 Streamlit 的网页版 Demo,运行方式见#117.
命令行 Demo
运行仓库中 cli_demo.py:
shell代码解读
复制代码python cli_demo.py
程序会在命令行中进行交互式的对话,在命令行中输入指示并回车即可生成回复,输入 clear 可以清空对话历史,输入 stop 终止程序。
API部署
首先需要安装额外的依赖 pip install fastapi uvicorn,然后运行仓库中的 api.py:
shell代码解读
复制代码python api.py
默认部署在本地的 8000 端口,通过 POST 方法进行调用
shell代码解读复制代码curl -X POST "http://127.0.0.1:8000" \-H 'Content-Type: application/json' \-d '{"prompt": "你好", "history": []}'
得到的返回值为
shell代码解读复制代码{"response":"你好👋!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。","history":[["你好","你好👋!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。"]],"status":200,"time":"2023-03-23 21:38:40"
}
低成本部署
模型量化
默认情况下,模型以 FP16 精度加载,运行上述代码需要大概 13GB 显存。如果你的 GPU 显存有限,可以尝试以量化方式加载模型,使用方法如下:
python代码解读复制代码# 按需修改,目前只支持 4/8 bit 量化
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().quantize(4).cuda()
进行 2 至 3 轮对话后,8-bit 量化下 GPU 显存占用约为 10GB,4-bit 量化下仅需 6GB 占用。随着对话轮数的增多,对应消耗显存也随之增长,由于采用了相对位置编码,理论上 ChatGLM-6B 支持无限长的 context-length,但总长度超过 2048(训练长度)后性能会逐渐下降。
模型量化会带来一定的性能损失,经过测试,ChatGLM-6B 在 4-bit 量化下仍然能够进行自然流畅的生成。使用 GPT-Q 等量化方案可以进一步压缩量化精度/提升相同量化精度下的模型性能,欢迎大家提出对应的 Pull Request。
[2023/03/19] 量化过程需要在内存中首先加载 FP16 格式的模型,消耗大概 13GB 的内存。如果你的内存不足的话,可以直接加载量化后的模型,仅需大概 5.2GB 的内存:
python代码解读
复制代码model = AutoModel.from_pretrained("THUDM/chatglm-6b-int4", trust_remote_code=True).half().cuda()
[2023/03/24] 我们进一步提供了对Embedding量化后的模型,模型参数仅占用4.3 GB显存:
python代码解读
复制代码model = AutoModel.from_pretrained("THUDM/chatglm-6b-int4-qe", trust_remote_code=True).half().cuda()
CPU 部署
如果你没有 GPU 硬件的话,也可以在 CPU 上进行推理,但是推理速度会更慢。使用方法如下(需要大概 32GB 内存)
python代码解读
复制代码model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).float()
[2023/03/19] 如果你的内存不足,可以直接加载量化后的模型:
python代码解读
复制代码model = AutoModel.from_pretrained("THUDM/chatglm-6b-int4",trust_remote_code=True).float()
如果遇到了报错 Could not find module 'nvcuda.dll' 或者 RuntimeError: Unknown platform: darwin (MacOS) 的话请参考这个Issue.
Mac 上的 GPU 加速
对于搭载了Apple Silicon的Mac(以及MacBook),可以使用 MPS 后端来在 GPU 上运行 ChatGLM-6B。首先需要参考 Apple 的 官方说明 安装 PyTorch-Nightly。然后将模型仓库 clone 到本地(需要先安装Git LFS)
shell代码解读复制代码git lfs install
git clone https://huggingface.co/THUDM/chatglm-6b
将代码中的模型加载改为从本地加载,并使用 mps 后端
python代码解读
复制代码model = AutoModel.from_pretrained("your local path", trust_remote_code=True).half().to('mps')
即可使用在 Mac 上使用 GPU 加速模型推理。
高效参数微调
基于 P-tuning v2 的高效参数微调。具体使用方法详见 ptuning/README.md。
ChatGLM-6B 示例
以下是一些使用 web_demo.py 得到的示例截图。更多 ChatGLM-6B 的可能,等待你来探索发现!










局限性
由于 ChatGLM-6B 的小规模,其能力仍然有许多局限性。以下是我们目前发现的一些问题:
-
模型容量较小:6B 的小容量,决定了其相对较弱的模型记忆和语言能力。在面对许多事实性知识任务时,ChatGLM-6B 可能会生成不正确的信息;它也不擅长逻辑类问题(如数学、编程)的解答。
点击查看例子

-
产生有害说明或有偏见的内容:ChatGLM-6B 只是一个初步与人类意图对齐的语言模型,可能会生成有害、有偏见的内容。(内容可能具有冒犯性,此处不展示)
-
英文能力不足:ChatGLM-6B 训练时使用的指示/回答大部分都是中文的,仅有极小一部分英文内容。因此,如果输入英文指示,回复的质量远不如中文,甚至与中文指示下的内容矛盾,并且出现中英夹杂的情况。
-
易被误导,对话能力较弱:ChatGLM-6B 对话能力还比较弱,而且 “自我认知” 存在问题,并很容易被误导并产生错误的言论。例如当前版本的模型在被误导的情况下,会在自我认知上发生偏差。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
资源分享

大模型AGI学习包


资料目录
- 成长路线图&学习规划
- 配套视频教程
- 实战LLM
- 人工智能比赛资料
- AI人工智能必读书单
- 面试题合集
《人工智能\大模型入门学习大礼包》,可以扫描下方二维码免费领取!

1.成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。
2.视频教程
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,其中一共有21个章节,每个章节都是当前板块的精华浓缩。
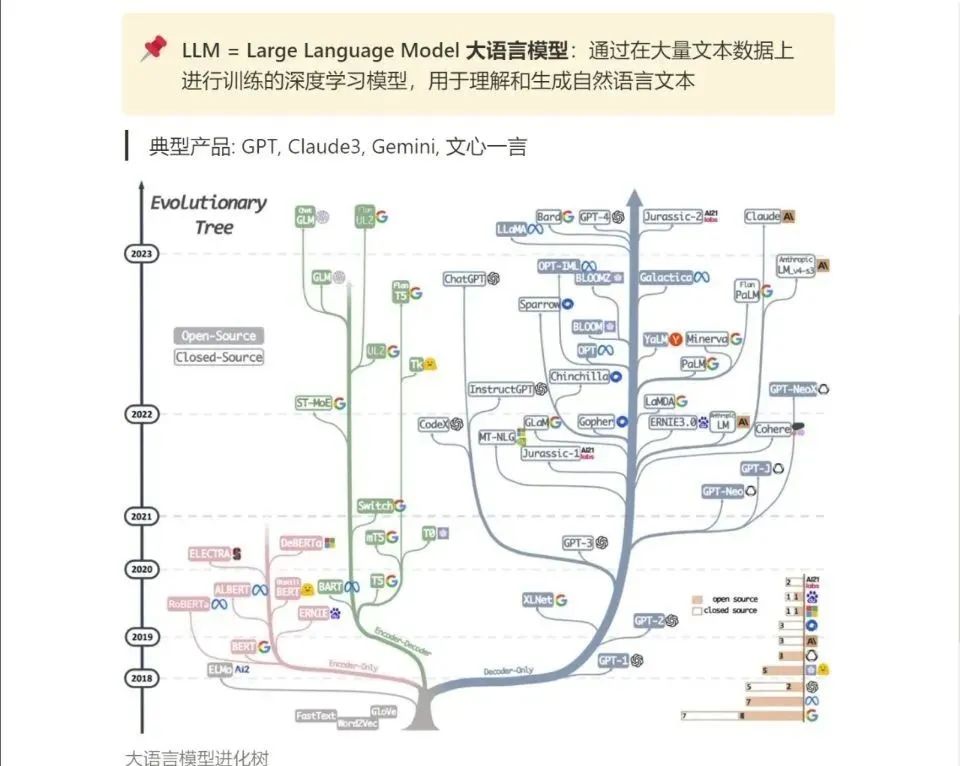
3.LLM
大家最喜欢也是最关心的LLM(大语言模型)
《人工智能\大模型入门学习大礼包》,可以扫描下方二维码免费领取!
相关文章:
ChatGLM-6B入门
ChatGLM-6B ChatGLM-6B 一、介绍 ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最…...

项目实战--Spring Boot + GraphQL实现实时数据推送
背景 用户体验不断提升而3对实时数据的需求日益增长,传统的数据获取方式无法满足实时数据的即时性和个性化需求。 GraphQL作为新兴的API查询语言,提供更加灵活、高效的数据获取方案。结合Spring Boot作为后端框架,利用GraphQL实现实时数据推…...

ASPICE是汽车软件开发中的质量保证流程
复杂的汽车系统对软件的质量和可靠性提出了极高的要求。为了确保汽车软件的高质量和可靠性,ASPICE(Automotive SPICE,汽车软件过程改进和能力确定)流程应运而生。本文将对ASPICE流程进行详细介绍。 一、ASPICE概述 ASPICE是汽车行…...

Linux调试器-gdb使用以及Linux项目自动化构建工具-make/Makefile
目录 1.gdb背景2.开始使用gdb3.make/makefile 背景4.实例代码5.依赖关系6.依赖方法7.原理8.项目清理 1.gdb背景 程序的发布方式有两种,debug模式和release模式 Linux gcc/g出来的二进制程序,默认是release模式 要使用gdb调试,必须在源代码生…...

Html5前端基本知识整理与回顾下篇
今天我们继续结合发布的Html5基础知识点文档进行复习,希望对大家有所帮助。 目录 列表 无需列表 有序列表 自定义列表 样例 表格 基本属性 编辑 相关属性 Border Width Height 编辑 表格标题 编辑 表格单元头 合并单元格 垂直单元格合并 水…...

vmware 虚拟机扩容 centos 硬盘扩容 kylinos v10扩容
1. 虚拟机先扩容 1.1 关机,并点击系统,让他是点选状态,但是没开机 1.2 右击,点击最下方设置,点击硬盘 1.3 点击扩展磁盘 1.4 选择你需要扩容的大小,数字为总大小 完成提示: 磁盘已成功扩展。您…...

什么样的开放式耳机好用?,五大超强卷王单品推荐!
对于热衷尝试不同耳机类型的小伙伴们而言,经过对佩戴舒适度、音质清晰度及电池续航能力的全面考量,开放式蓝牙耳机因其卓越的平衡性脱颖而出,成为多数人的心头好。其轻巧设计不仅保证了长时间佩戴的舒适感,还兼顾了音质与续航的双…...

java使用poi-tl模版引擎导出word之饼状图生成及循环批量生成饼状图
文章目录 一、单个饼状图生成1.word模版制作2.编写接口完整代码3.导出结果 二、批量生成饼图1.word模版制作2.编写接口完整代码3.导出结果 一、单个饼状图生成 1.word模版制作 在word中创建一个饼状图,点击图表,点击“文本选项”,在可选文字…...

指定版本ceph-common安装
如,安装15.2.13的ceph-common PACKAGE_NAMEceph-common CEPH_VERSION15.2.13 wget -q -O- https://download.ceph.com/keys/release.asc | sudo apt-key add - echo deb http://download.ceph.com/debian-${CEPH_VERSION}/ $(lsb_release -sc) main | sudo tee …...
)
C++语言特性——关键字(static、volatile、extern、const、mutable、inline)
注意: 本内容为摘抄网上的学习资料,作为个人笔记使用,如有侵权, 立刻删除。 C语言特性 1.关键字 (1)static static全局变量和普通全局变量 面试高频指数:★★★☆☆ 相同点: 存储方式&…...

在Ubuntu 16.04上安装和配置VNC的方法
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。 ###介绍 VNC,即“Virtual Network Computing”,是一种连接系统,允许您使用键盘和鼠标与远程服务器上…...

@RequestBody注解的使用及源码解析
前言 RequestBody 注解是我们进行JavaEE开发,最常见的几个注解之一,这篇博文我们以案例和源码相结合,帮助大家更好的了解 RequestBody 注解 使用案例 1.自定义实体类 Data NoArgsConstructor AllArgsConstructor public class User {priv…...

linux 服务器数据备份 和 mysql 数据迁移
查看域名ip 查看程序所处文件位置 list open files 1、 lsof -i :port 查看端口获取进程 pid 2、lsof -i pid 1、scp 下载服务器文件到本地 security copy protocol 2、导出服务器 mysql 数据库(表)到本地 mysqldump是MySQL自带的一个实用程序&…...

安防视频监控/云存储/视频汇聚EasyCVR平台播放设备录像不稳定,是什么原因?
安防视频监控/视频集中存储/云存储/磁盘阵列EasyCVR平台可拓展性强、视频能力灵活、部署轻快,EasyCVR基于云边端一体化架构,具有强大的数据接入、处理及分发能力,可提供7*24小时实时高清视频监控、云端录像、云存储、录像检索与回看、智能告警…...

S32V234平台开发(一)快速使用
快速使用 准备供电复位选择串口通信启动选择显示登陆系统 准备供电 s32v234可以使用两种电源供电 一种是左边电源端子,一种是右边电源适配器(12V 3A) 注意:不要同时使用两种电源同时供电 复位选择 Pressing POR RESET pulls active low EXT_POR signal on S32V2…...

C# 如何防止反编译?C#程序加密混淆保护方法大全
在C#开发中,由于.NET程序集(assemblies)是基于中间语言(Intermediate Language, IL)编译的,这些程序集可以被反编译回接近原始源代码的形式。为了保护代码不被轻易反编译,开发者可以采取以下几种…...

企业数字化转型中的低代码开发平台应用:释放创新潜能
随着信息技术的飞速发展,企业数字化转型已成为行业趋势。在这场转型浪潮中,低代码开发平台以其独特的优势,成为众多企业实现快速迭代、高效创新的得力助手。本文将深入探讨低代码开发平台在企业数字化转型中的应用,以及如何帮助企…...

因为目录问题开通的另外一个网站的美化过程
起 其实也不完全是目录,是查找问题过程中看到别人的界面好好看,而且确实那个目录很吸引我…… 然后我在csdn看了半天,看到一个有目录的我赶紧换上,结果并不能显示。而且把原来黑色模式的给搞没有了——它居然要vip了……所以………...

RedHat运维-Ansible自动化运维基础24-寻找问题常用模块
1. ansible.builtin.uri模块的作用是____________________________; 2. ansible.builtin.uri模块的作用是____________________________; 3. ansible.builtin.uri模块的作用是____________________________; 4. 试着用ansible.builtin.uri模块…...
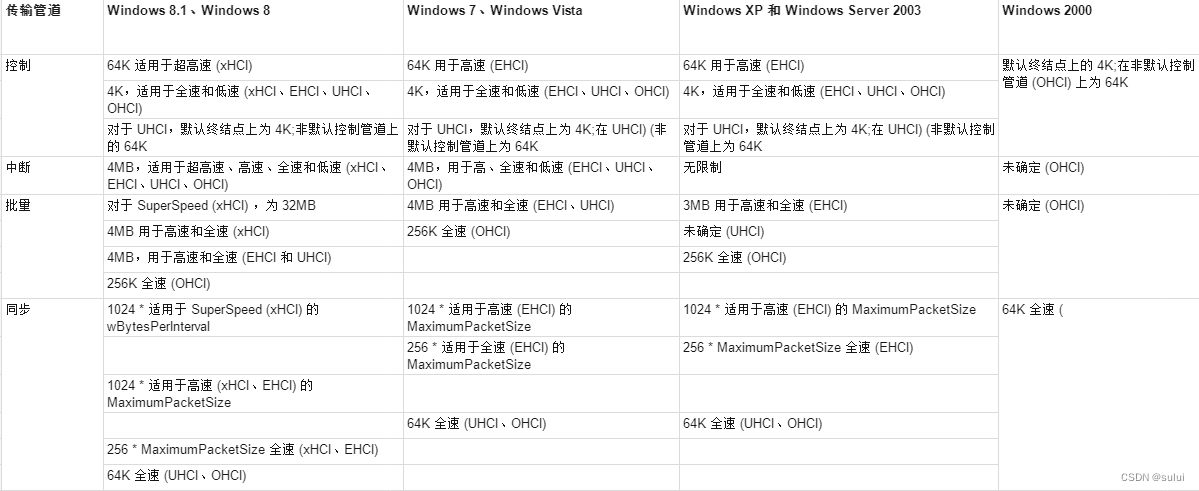
windows USB 设备驱动开发-USB带宽
本文讨论如何仔细管理 USB 带宽的指导。 每个 USB 客户端驱动程序都有责任最大程度地减少其使用的 USB 带宽,并尽快将未使用的带宽返回到可用带宽池。 在这里,我们认为USB 2.0 的速度是480Mbps、12Mbps、1.5Mbps,这分别对应高速、全速、低速…...

TextInputLayout实战:从属性解析到自定义样式进阶
1. TextInputLayout基础入门:从零开始掌握Material输入框 第一次接触TextInputLayout时,我被它丝滑的浮动提示动画惊艳到了。相比传统的EditText,这个Material Design组件确实能让表单界面瞬间提升好几个档次。记得去年做登录页面重构时&…...
)
告别启动盘识别难题:手把手教你搞定CentOS 7在SR650上的UEFI启动与自定义分区(含/dev/sdX查找技巧)
告别启动盘识别难题:手把手教你搞定CentOS 7在SR650上的UEFI启动与自定义分区(含/dev/sdX查找技巧) 在服务器运维领域,系统安装看似基础却暗藏玄机。特别是当面对企业级硬件如Lenovo SR650时,UEFI启动模式与传统BIOS的…...

Steam Cron Studio:可视化配置生成器,为AI代理打造Steam自动化任务
1. Steam Cron Studio:一个为AI代理量身定制的Steam自动化配置生成器如果你是一个Steam重度用户,同时又对AI代理(AI Agent)和自动化工具感兴趣,那么你很可能和我一样,曾经被一个看似简单实则繁琐的问题困扰…...

5个常见照片管理难题,ExifToolGUI一站式解决
5个常见照片管理难题,ExifToolGUI一站式解决 【免费下载链接】ExifToolGui A GUI for ExifTool 项目地址: https://gitcode.com/gh_mirrors/ex/ExifToolGui 你有没有遇到过这样的情况?旅行归来,几百张照片的拍摄时间全乱了,…...

4 生成器模式
生成器模式 的核心是:将一个复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示。简单说:像搭积木一样,用相同的步骤可以搭出不同样式的房子。建造房子的步骤是固定的:打地基建墙体安装屋顶装修内部但…...

ksail:本地Kubernetes开发环境一键搭建与云原生实践
1. 项目概述:当Kubernetes遇上本地开发如果你是一名后端或云原生方向的开发者,大概率经历过这样的场景:为了调试一个微服务,你需要在本地启动一整套依赖——数据库、消息队列、缓存,可能还有另外两三个兄弟服务。你手忙…...
)
专利技术复杂性地级市面板(2001-2025)
核心速览数据编号:2323时间跨度:2001–2025空间尺度:中国全部地级市数据格式:Excel 年度面板测算依据:Research Policy 2026 顶刊范式(Frigon)测算方法(可直接写论文)以I…...

5分钟掌握TrafficMonitor插件系统:从零开始构建你的桌面监控中心
5分钟掌握TrafficMonitor插件系统:从零开始构建你的桌面监控中心 【免费下载链接】TrafficMonitorPlugins 用于TrafficMonitor的插件 项目地址: https://gitcode.com/gh_mirrors/tr/TrafficMonitorPlugins 还在为Windows桌面上单调的系统监控而烦恼吗&#x…...

APK Installer完整指南:在Windows上快速安装Android应用的终极方案
APK Installer完整指南:在Windows上快速安装Android应用的终极方案 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾经想在Windows电脑上轻松安装An…...

CANopen通信避坑指南:你的SDO为什么读不到映射变量?从对象字典EDS文件说起
CANopen通信避坑指南:你的SDO为什么读不到映射变量?从对象字典EDS文件说起 调试CANopen通信时,最令人抓狂的瞬间莫过于:从站程序明明能正常读写变量,主站却死活读不到映射值。上周我就遇到一个典型案例——某工业设备厂…...