第二周:李宏毅机器学习笔记
第二周学习周报
- 摘要
- Abstract
- 一、深度学习
- 1.Backpropagation(反向传播)
- 1.1 链式法则
- 1.2 Forward pass(前向传播)
- 1.3 Backward pass(向后传播)
- 1.4 总结
- 2. Regression(神奇宝贝案例)
- 2.1 第一步:设置Model(A set of function)
- 2.2 第二步:评估函数的好坏(goodness of function)
- 2.3 第三步:找到最好的function(best function)
- 2.3.1 Gradient Descent
- 2.3.1.1 Gradient Descent的最小值问题(linear regression没有local optimal)
- 2.4 结果以及优化
- 2.4.1 过拟合现象(overfitting)
- 2.6 改善模型
- 2.6.1 重新设置模型(Redesign the model)
- 2.6.2 正则化(Regularization)
- 二、Pytorch学习
- 1. Pytorch加载数据的初认知
- 1.1 Dataset与Dataloader
- 1.2 Dataset代码实战
- 总结
摘要
这周主要对Deep Learning进行了进一步的学习,内容包括反向传播算法的过程原理。还学习了regression,根据宝可梦的案例学习到了Loss中使用正则化的技巧。此还继续学习了Pytorch课程,包括学习Dataset和Dataloader各自的功能,以及Dataset的代码实战。
Abstract
This week, I mainly conducted further learning on Deep Learning, including the process principle of backpropagation algorithm. I also learned about regression and learned the technique of using regularization in Loss based on the case of Pok é mon. I also continued to study Python courses, including learning the functions of Dataset and Dataloader, as well as practical coding for Dataset.
一、深度学习
1.Backpropagation(反向传播)
回顾一下梯度下降的过程:
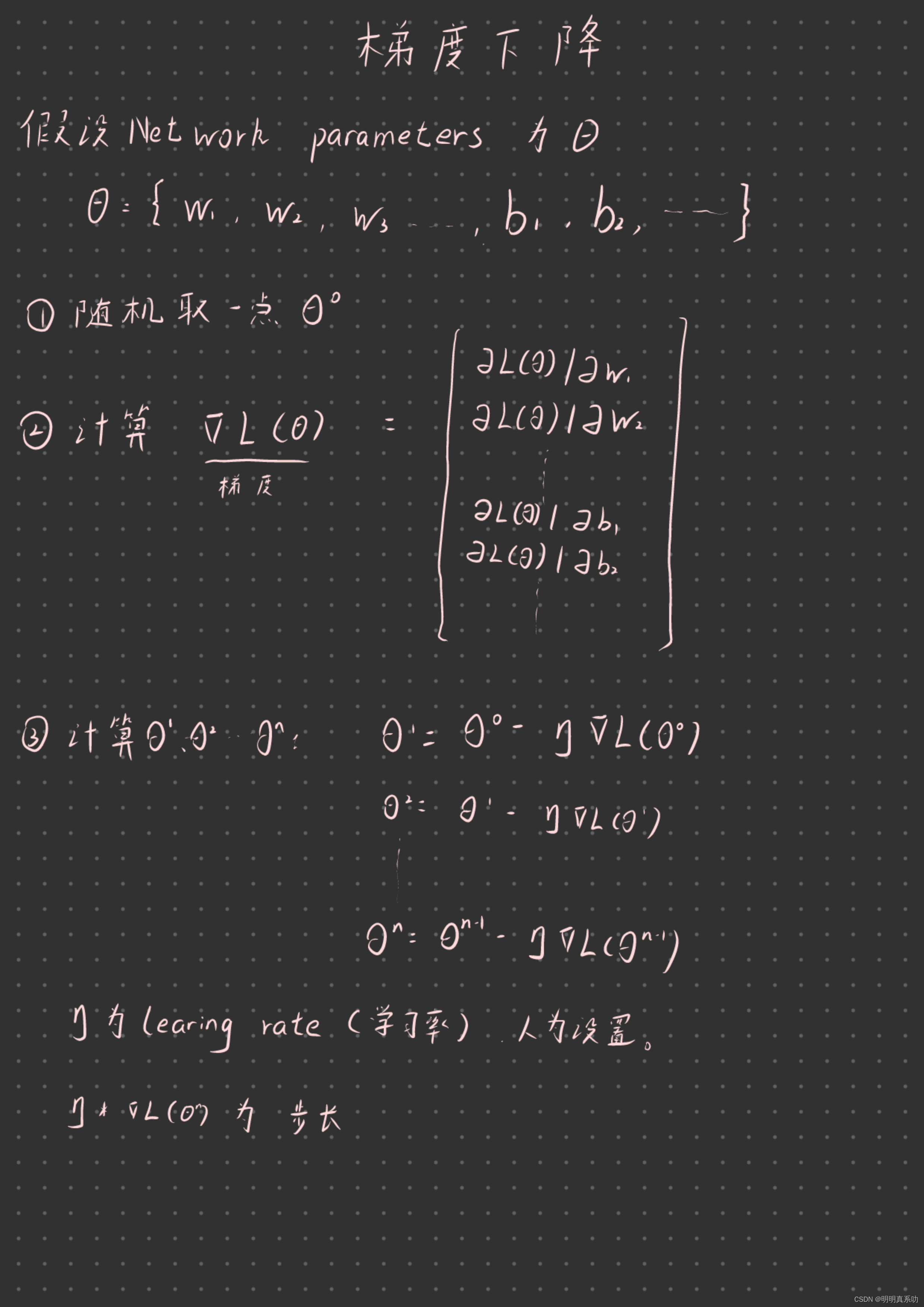
在学习梯度下降的算法中,我们计算的过程中的θ这个vector(向量)是非常长的,即可能会有上百万个参数,为了有效率地计算面对这么多参数,我们就需要使用反向传播算法去完成θ的计算了。

1.1 链式法则
链式法则是在学习高等数学中求复合函数导数非常常用的一种方法。完成链式求导主要需要掌握两个步骤:
1、列出各个变量之间的关系
2、根据关系写出链式(同一条路径相乘、不同路径相加)
例子如下:
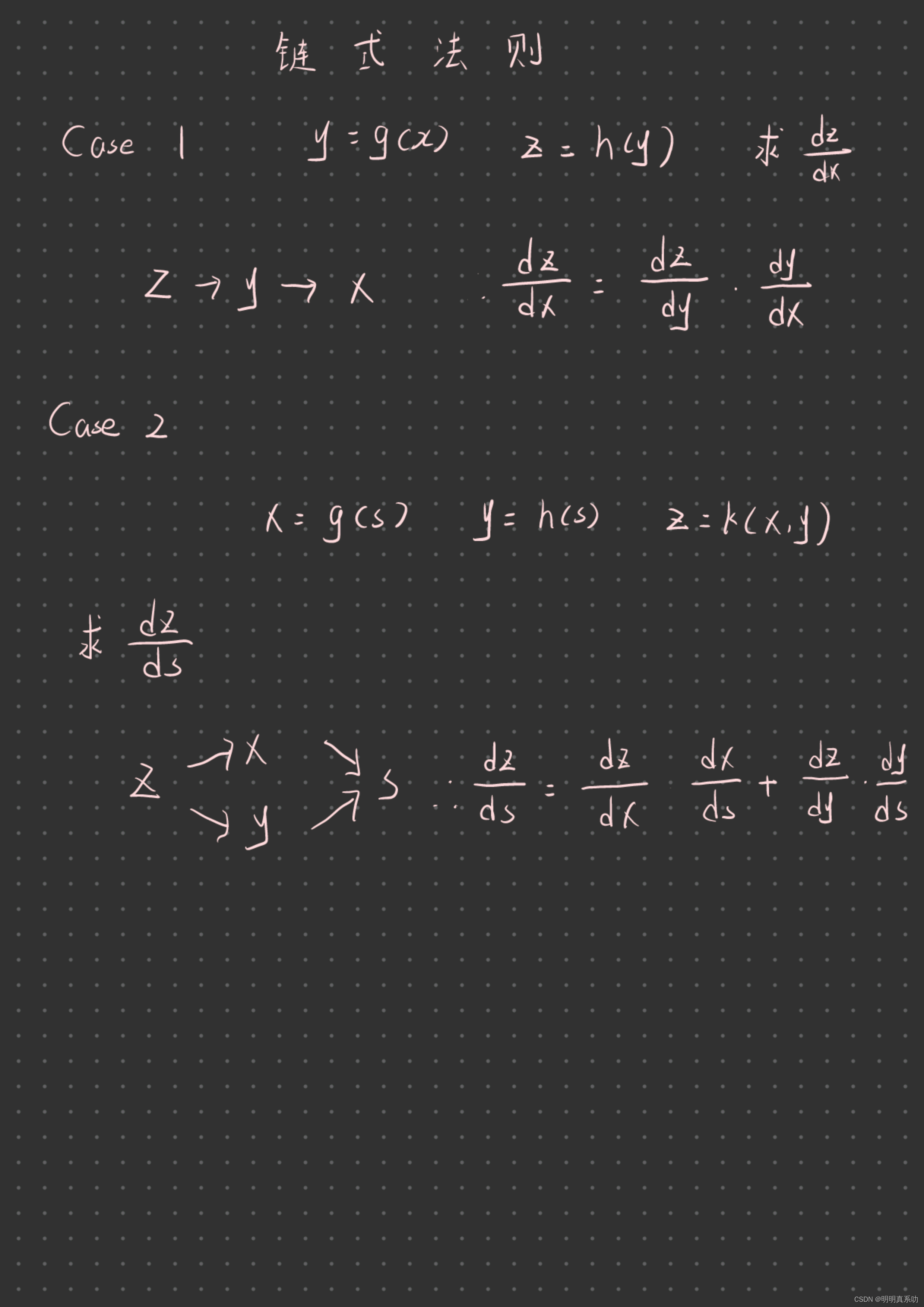
掌握了链式法则后,我们就要用来解决实际的问题了。
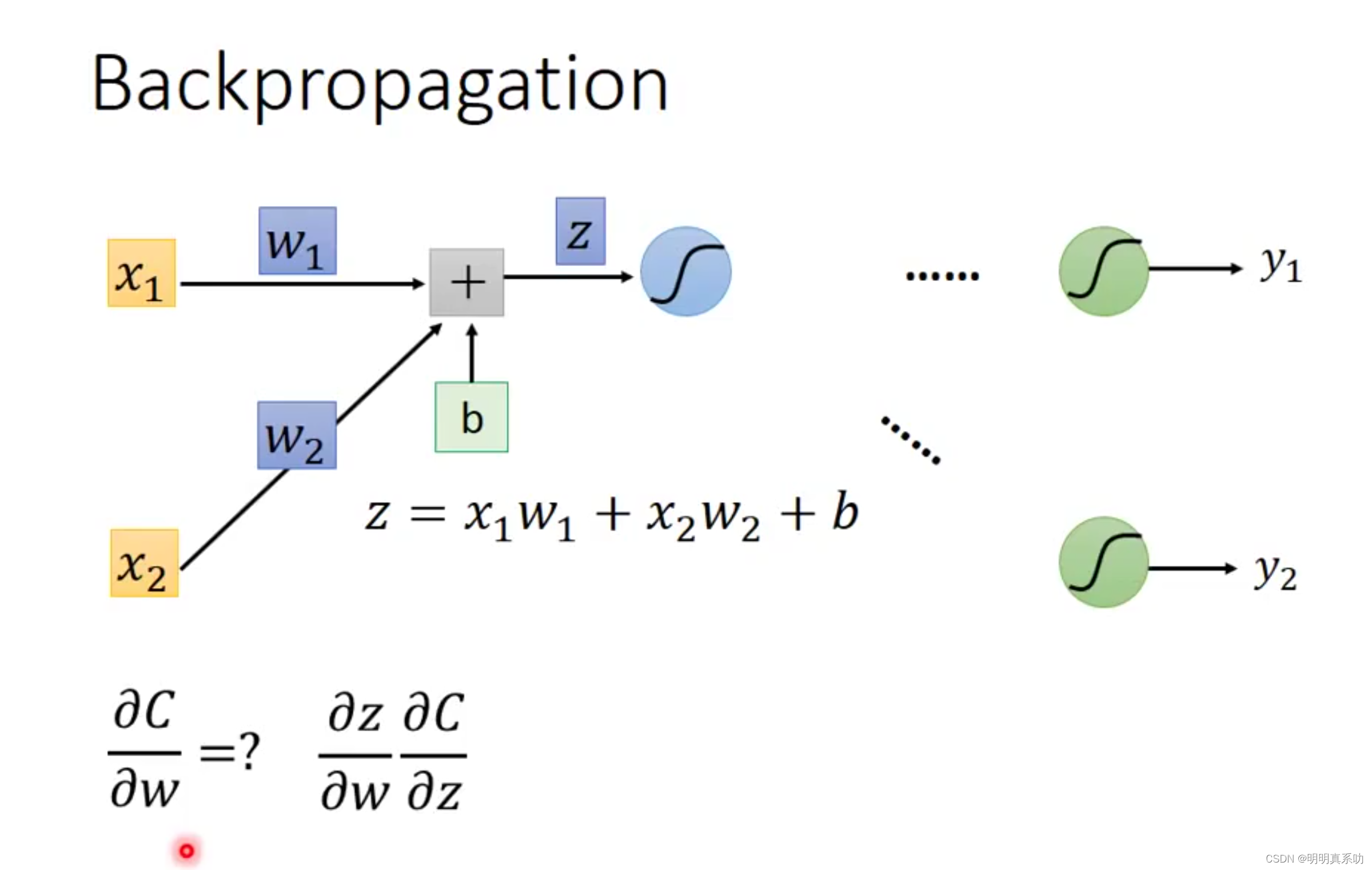
假设我们神经网络结构如下图所示,
其中Cn是yn与ŷn的交叉熵(可以理解为它们之间的距离,距离越近则误差越小)
我们要求Cn对w(权重未知量)的偏导。
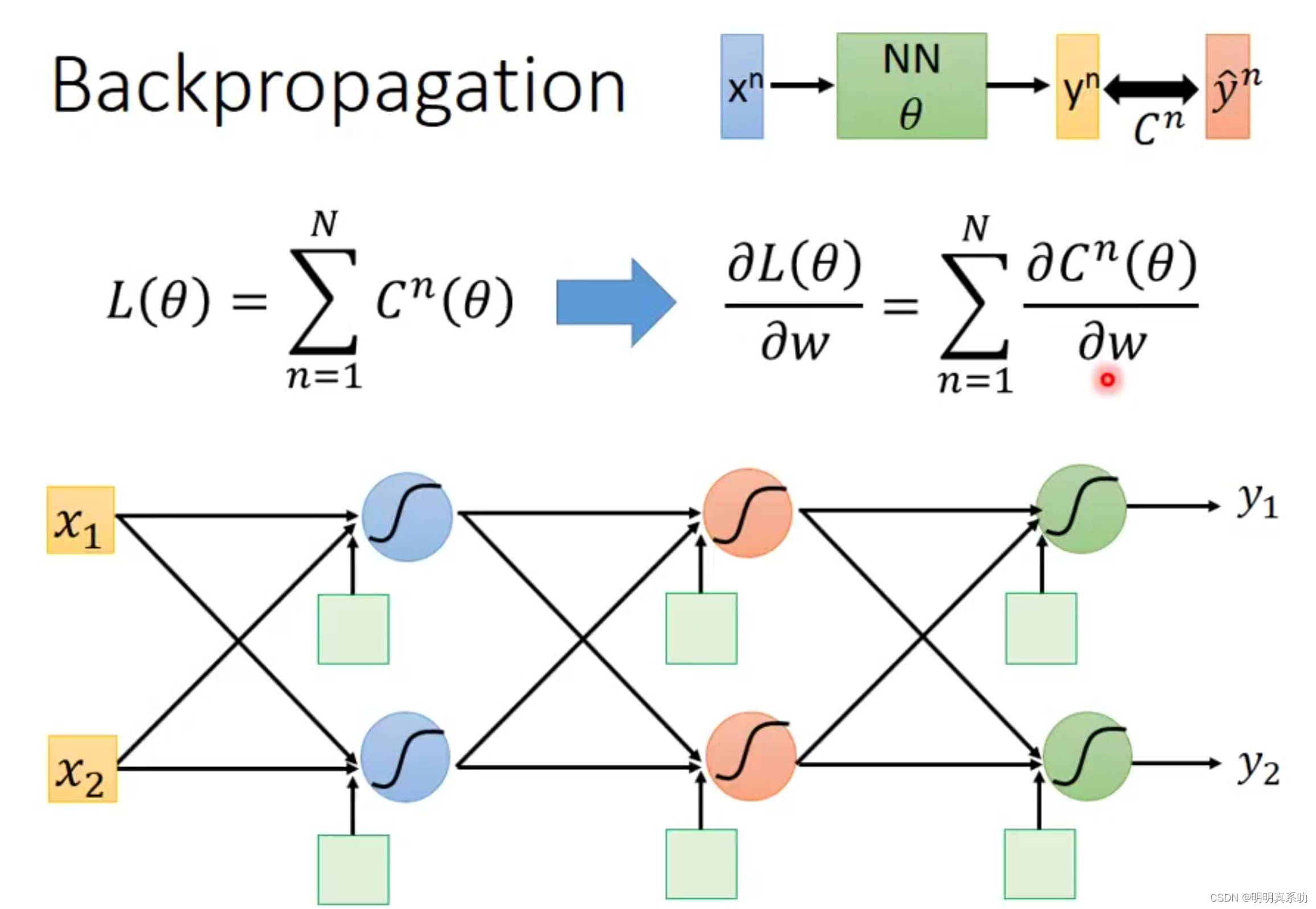
1.2 Forward pass(前向传播)
因为我们的C是经过整个神经网络得出结果后得出预测值y与真实值ŷ计算出来的,所以是一个整体的性的值,要求偏导,就要一层一层的计算。
所以,我们把下图的下三角先提出来,先处理这个部分的计算从而以小见大,理解整个个过程的计算。
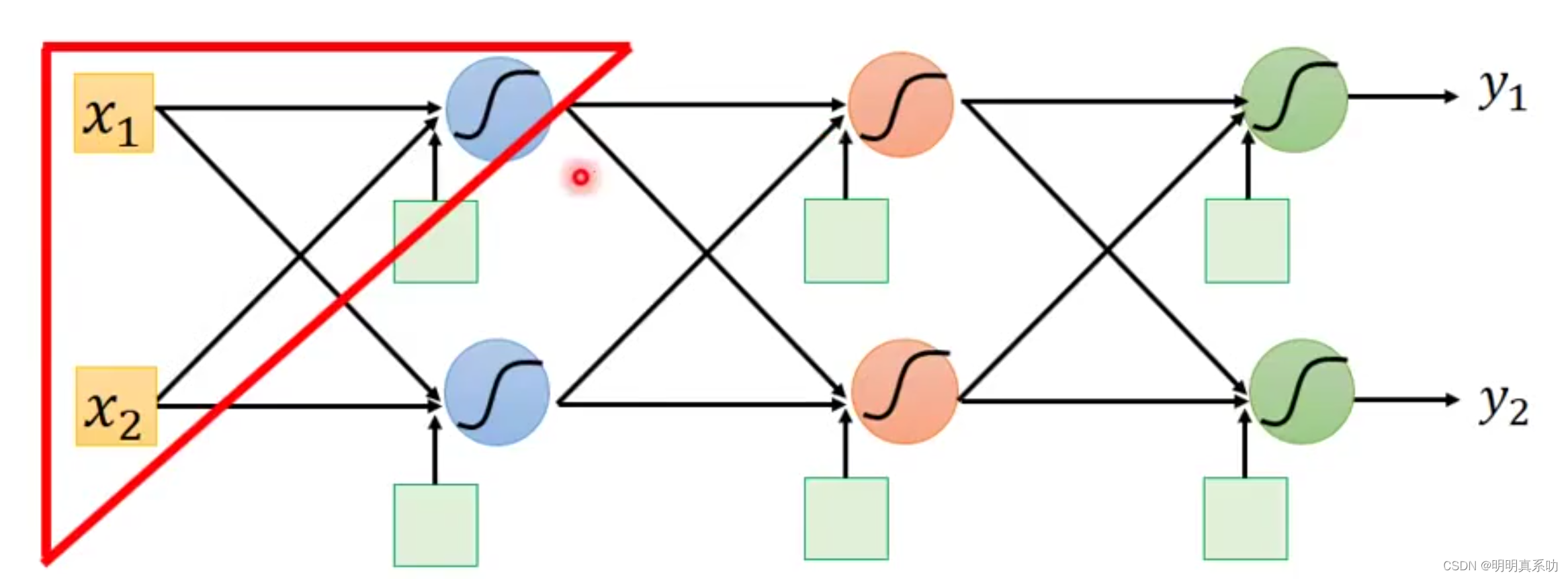
在这个上三角中,我们有::
feature :x1与x2
未知量:w1,w2,b
z:是他们计算结果。
那么我们如何用这些变量来表示C对w的偏导呢?
先拿w1举例:

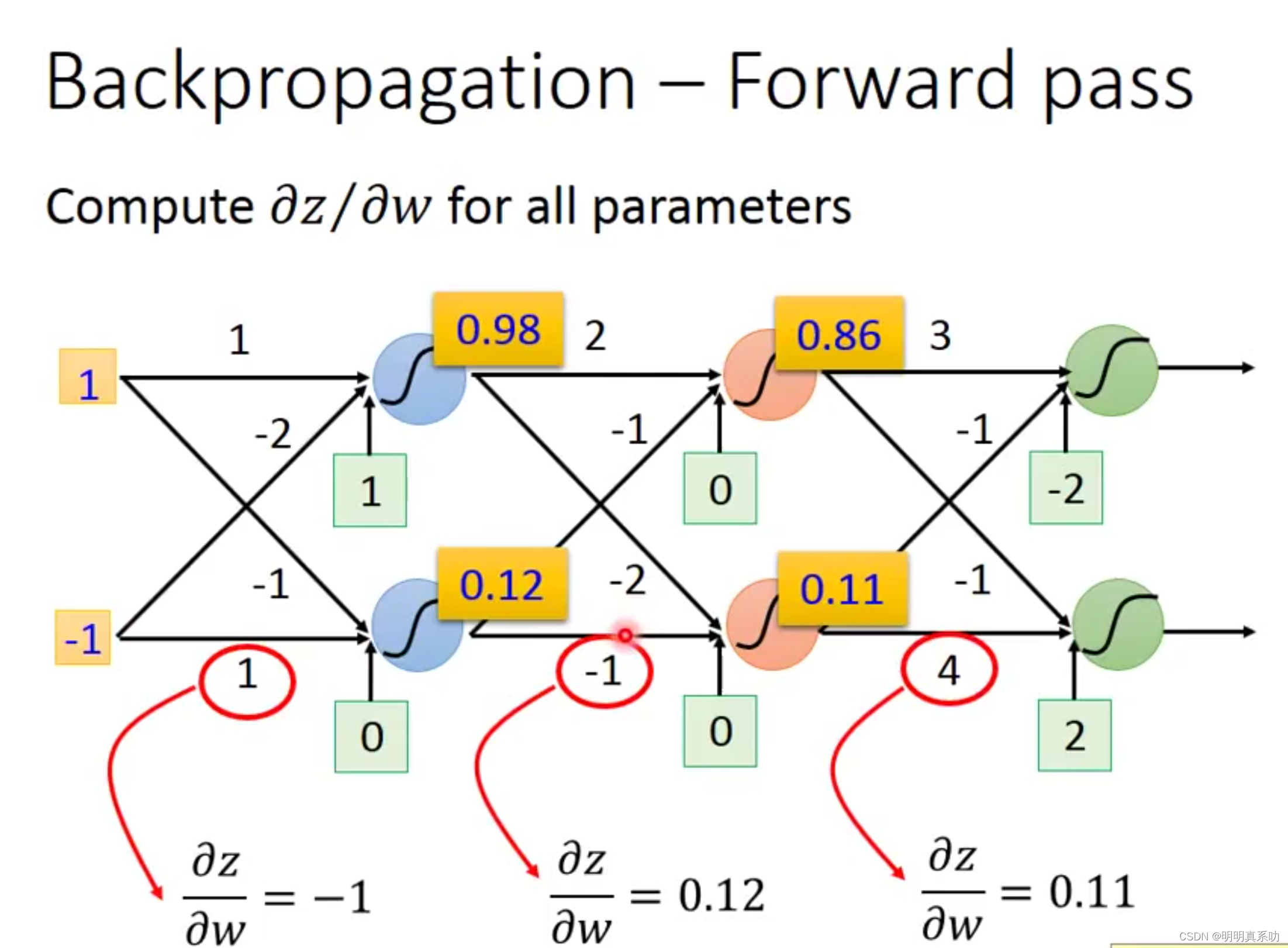
在上述计算总结中,我们很明显可以发现一个规律,就是w(权重)对应的偏导,就是其对应输入的值。
比如,下图中,w = 1对应的偏导为 -1(输入值)、w = -1 对应的偏导值为0.12(输入值)…以此类推。
1.3 Backward pass(向后传播)
那么处理完z对w的偏导,还有一个令人头痛的C对z的偏导要计算,因为我们如果用z的变量表达C,就要一直推导,非常麻烦,因为z后面还有N多层。那么要如何解决呢?
假设我们再往下走一层,就有了以下参数:
a:z经过sigmoid运算后的结果。
w3、w4…:未知数
z’‘,z’':同z一个意思。
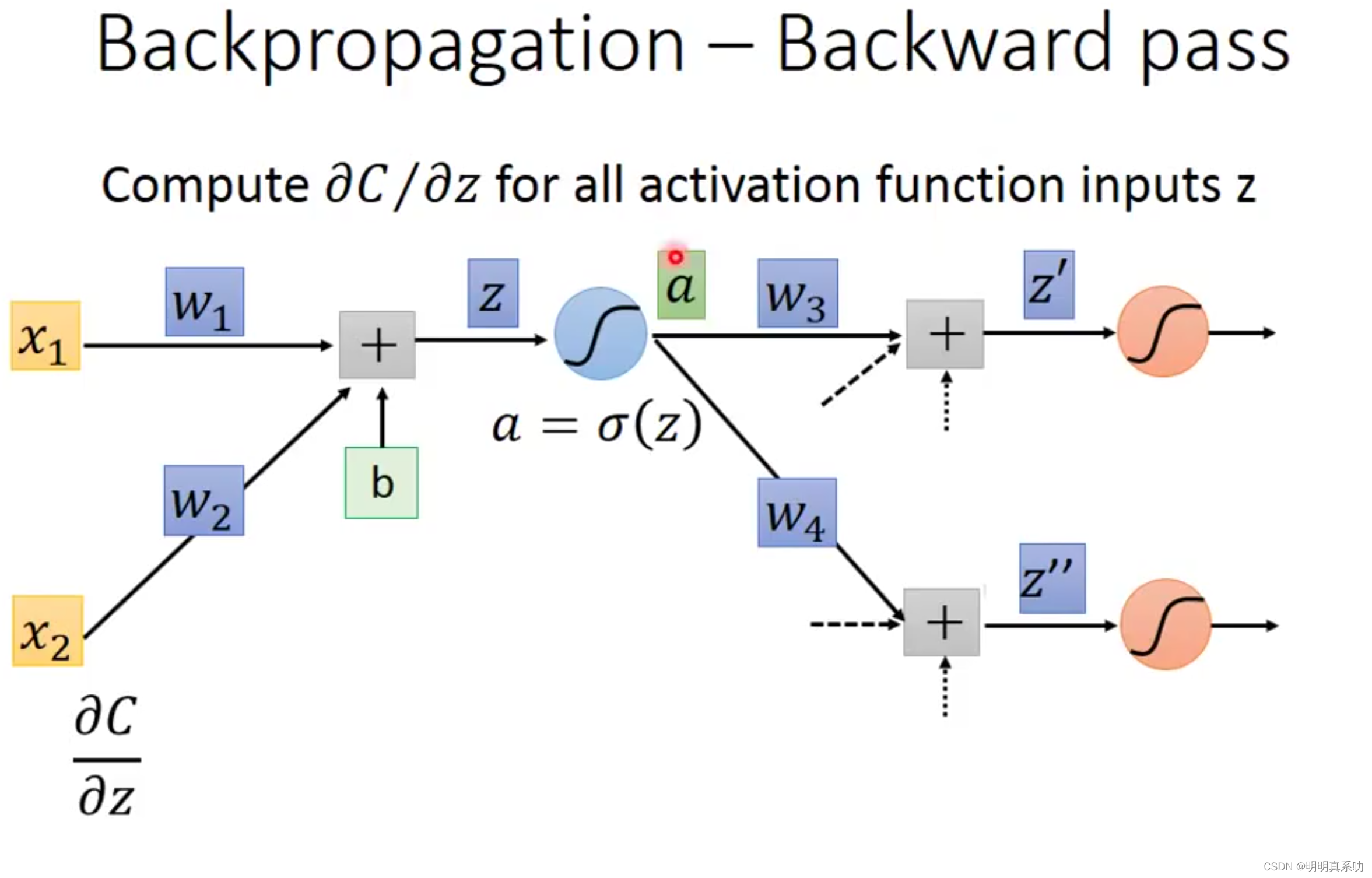
表示如下:
假设1:其下一层就是输出层。
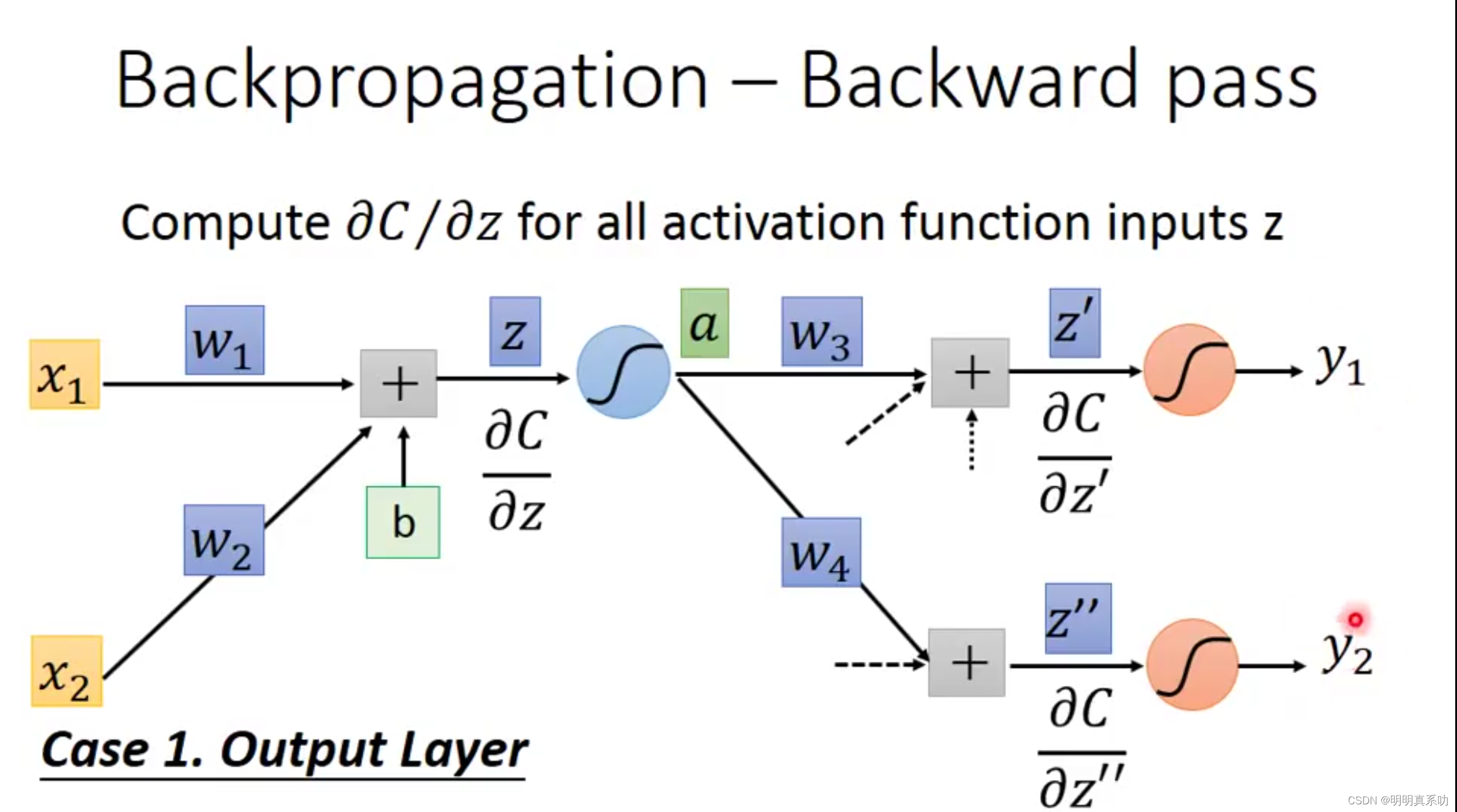
计算方式如下:

假设其下一层不是输出层,就要找其下一层再推导,直到找到输出层为止。
所以,一开始从输出层往前推导快一点,因为都是已知结果
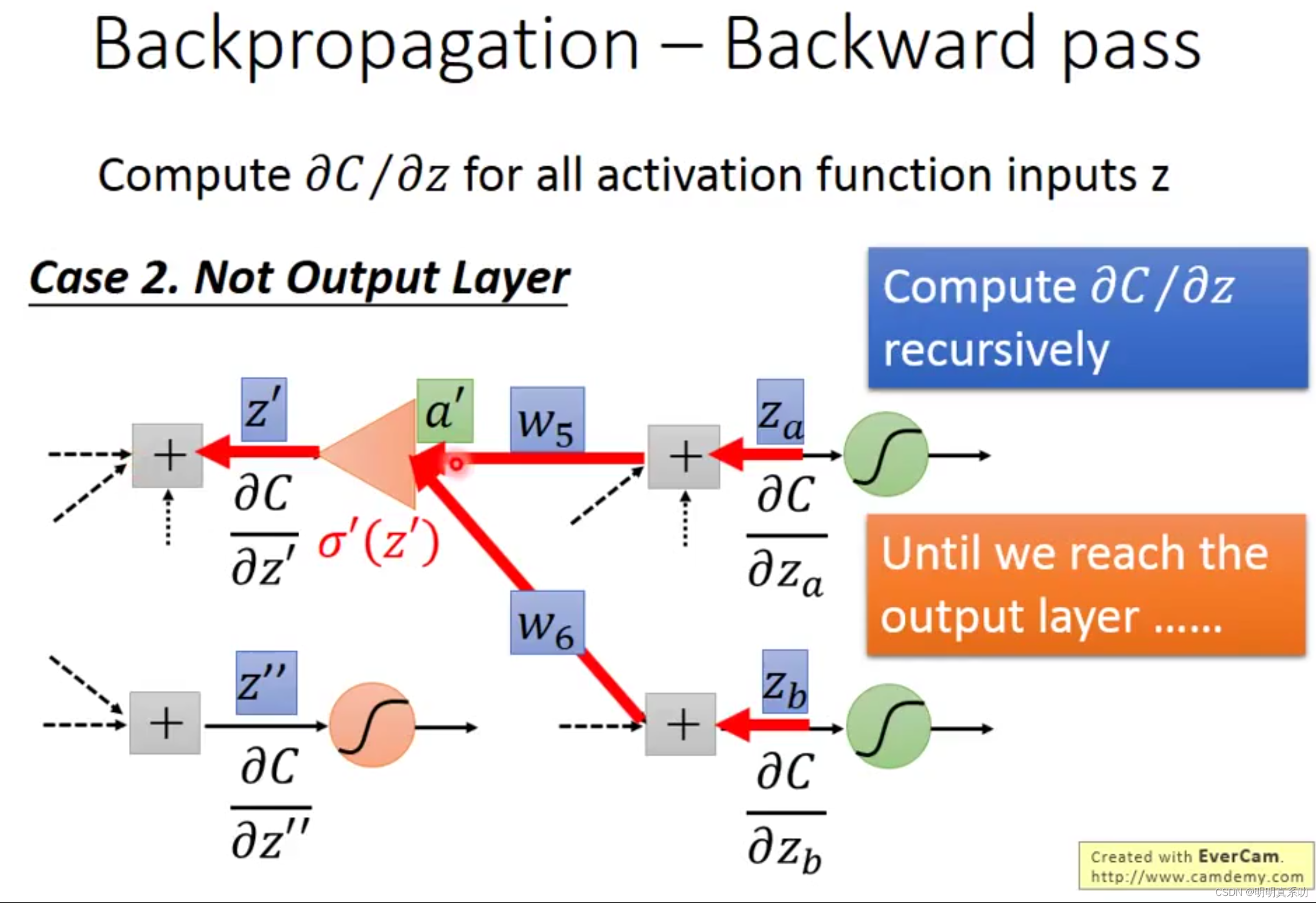
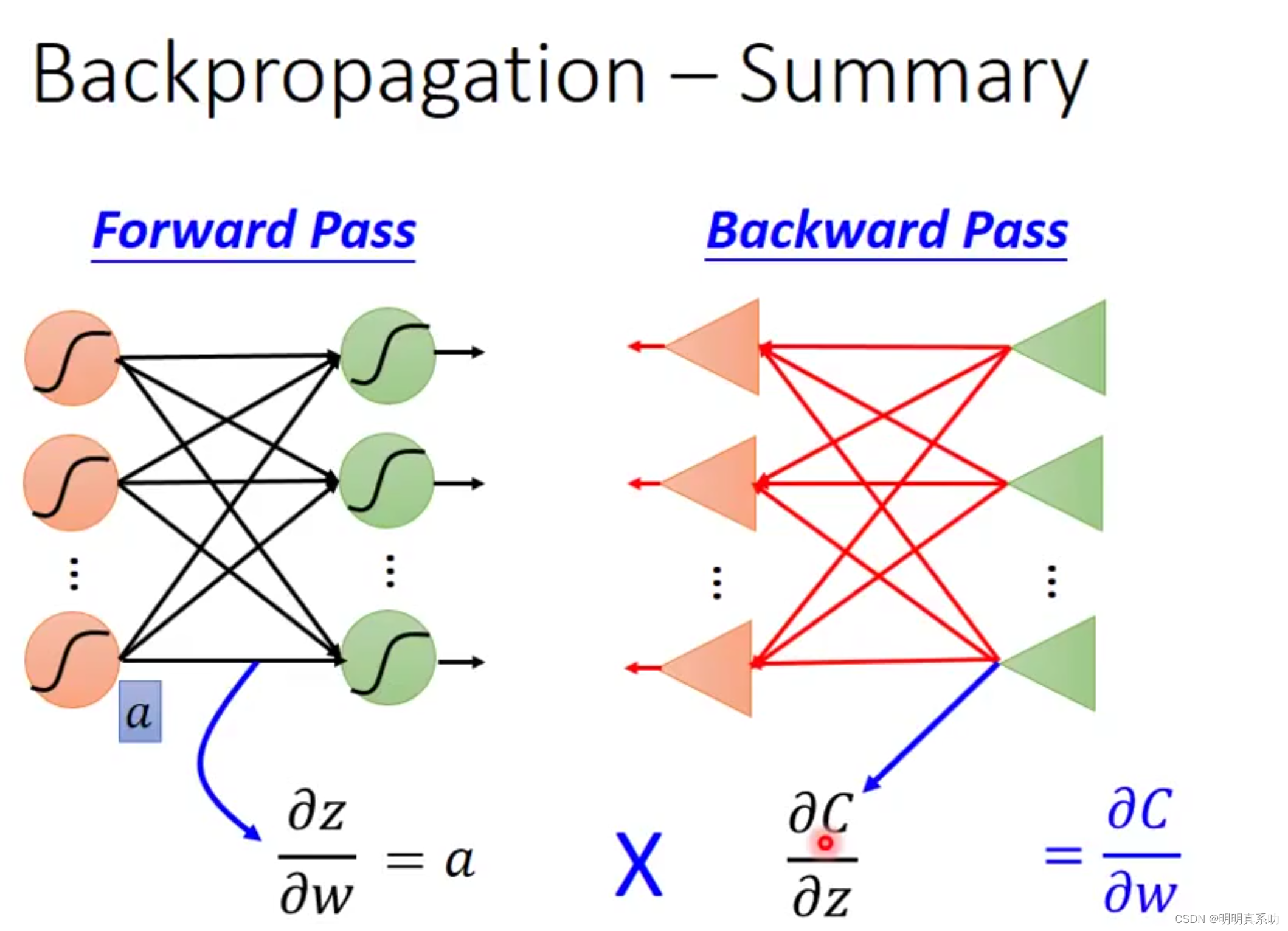
1.4 总结
计算z对w偏导用forward pass,计算C对z的偏导用Backward pass
2. Regression(神奇宝贝案例)
在学习regression中,我们了解到其实一个回归问题,用于解决预测问题。
比如输入对应的函数,就会输出一个结果。
如下图所示,可以用于股市趋势的预测、自动驾驶的场景、网络购物推介等

下面我们用预测宝可梦的战斗力的例子,来更加深入的了解Regression。
我们输入函数的参数如下:
Xcp:是feature,表示宝可梦原先的战斗力。
Xs:是宝可梦的名字。
Xhp:是宝可梦的血量
Xw:宝可梦的重量
Xh:宝可梦的高度

2.1 第一步:设置Model(A set of function)
假设我们设置一组函数(可以有无数个),这些函数都是线性的(linear model),但是不一定是正确的,需要使用training date来验证哪个函数最合理,最后用来预测宝可梦进化后的战斗力。

2.2 第二步:评估函数的好坏(goodness of function)
我们根据进化后的真实值与初始值一一对应起来,并做成一幅直观的图。
这些数据称之为training date
横轴代表初始战斗力(x1…x10)。
纵轴代表精华后的真实战斗力(ŷ1…ŷ10)。

要评估模型的好坏,就要用到Loss function,这里我们采用平方差的方式来表示Loss的大小,其实Loss function就是用来输出这个模型到底有多差(所以L越小越好)

关于括号里面数字的由来:

在下面的图像中,图像的颜色代表L的大小,越红代表数值越大,越偏蓝色代表数值越小

2.3 第三步:找到最好的function(best function)
找到最佳的function,就要找到w与b使L 最小(min)。

2.3.1 Gradient Descent
为了找到最小值,我们还是使用 Gradient Descent,接下来我们复习一下:
假设只有一个未知数w。
其中包含local optimal(是我们随机取点,一直找到的最小值)和global optimal(全局最小值,基本上很难实现)

假设有两个未知数w和b,我们可以以此类推:
我们就可以先带入w0,b0,求偏导值,然后算出w1,b1,再代入w1,b1求出w2,b2.以此类推。
这时候的L的梯度就是一个二维的Vector
再多的参数就再加维度即可。

于是我们把,偏导完整的格式写出来,如下图所示:

用图像来表示上述过程,如下图:
2.3.1.1 Gradient Descent的最小值问题(linear regression没有local optimal)
当我们使用gradient decent时候,会出现一个问题:
比如在下图的左图中,如果我们随机取不同的点,L最小值也会不一样。
完全看我们的人品
但是!
线性回归不会出现这个问题,
因为其Loss function是convex(凸面的),无论我们从哪一点出发,都可以找到同一个最小值。

2.4 结果以及优化
经过计算,我们得到了最佳的w与b。
运用这套线性的模型,我们最终得出一个结果:
在测试集上的L为35.0,在训练集上为31.9.

那么我们是否有办法让其L更低,让模型更加准确呢?
2.4.1 过拟合现象(overfitting)
于是我们可以增加未知量,让模型变得更加复杂,模型也就更加的精准。
我们先添加一个w2的未知数到方程中,看到结果在测试集和训练集中的Loss都减少了,
测试集的平均错误:从35.0->18.4
训练集的平均错误:从31.9->15.4

于是我们继续增加w3,w4,w5,持续增加模型的复杂度,如下图所示:

按照理论来说,我们模型的复杂度越高,在训练集中的错误就越低(前提是使用gradient descent找到最佳的未知数值)。

但是从这个表格中,我们就发现一个问题:
随着模型越来越复杂,我们的Training的average Error使越来越低,但是我们在Testing上的Error却在w4后越来越高,特别是加入w5后达到了惊人的232.1。
这种现象就称之为过拟合现象(overfitting),通常是由于模型过于复杂导致的。
因为我们最重要的还是要预测数据,所以testing上的Error是非常重要的(要做大考型选手,不做模拟哥)
因此,我们最佳的模型实际上就是加入w3后的模型。

2.6 改善模型
我们上面设置的模型,只考虑了个别的情况,但是我们的宝可梦进化实际上是受很多条件影响的,例如:不同物种之间进化后的强度是不一样的。
因此我们要考虑上一些隐藏的因素,再重新设置模型。

2.6.1 重新设置模型(Redesign the model)
我们可以设置这样一个Model:使用一个类似编程语言中的if语句来完成不同物种进化使用不同model的功能
如下图中所示:

当我要预测Pidgey的进化后的攻击力,其他物种的Xs都为0,只有Xs=Pidgey的Xs为1

经过这一改变后,
我们的Training Data的Average error为3.8
Tesing Data的Average error 为14.3.
很明显这种对症下药的model效果非常显著

再或者我们在这个基础上,让模型更加复杂一点我们再增加一些未知数,模型说不定会预测地更加的精准

2.6.2 正则化(Regularization)
正则化是一种防止模型过拟合的手段,通过给损失函数加上一些限制条件,使模型参数更接近于0。
我们在Loss function中可以加入一个λ∑(wi)²,来使得线段更加平滑。
为什么要变得平滑呢?
因为越平滑的线就越能够减少外界的干扰,预测的准确度就越高(比如我们的输入数据有受到了一些干扰,会影响结果,我们加入这个部分后,就能减少这些干扰对结果的影响)

我们通过控制λ的大小来控制线的平滑程度,我们需要平滑,但不能过于平滑。
因为可以看到当我们的λ从0增加到100,其在训练集和测试集上的Error都再一直下降
但是100后,图像就有一个转折点,再增加Error就变大了。
因此我们要根据测试结果,选定一个最佳λ,使得我们的效果最佳。

二、Pytorch学习
1. Pytorch加载数据的初认知
1.1 Dataset与Dataloader
在Pytorch中如何读取数据主要分为两个类,一个是Dataset、一个是Dataloader。
假设数据就是一堆垃圾,我们要在这堆垃圾中寻找我们有用的数据。
就要使用Dataset完成,然后经过Dataloader打包后,再传入网路中,如下图所示:

其中Dataset与Dataloader的功能如下:
| 名称 | Dataset | Dataloader |
|---|---|---|
| 功能 | 提供一种方式去获取数据以及其label (获取每一种数据以及其label、并告诉我们共有多少数据) | 为后面的网络提供不同的数据形式 |
1.2 Dataset代码实战
接下来,我们下载一个数据集,来学习Dataset
数据集下载链接https://download.pytorch.org/tutorial/hymenoptera_data.zip
解压打开后可以看到这个数据集包括训练集和验证集,里面都是一些蚂蚁和蜜蜂的图片,如下图所示:

这里的label 就是文件夹对应的名称(这是众多的组织形式之一)


接下来,我们启动jupyter notebook,输入以下代码,引入Dataset类
from torch.utils.data import Dataset
然后我们可以使用help函数,查看使用方法
help(Dataset)

或者使用**Dataset??**查看更加直观的使用方法
Dataset??

从上述英文,我们大致了解到Dataset的作用就是用来提取数据的。

图片作为输入,一般是将图片的路径

接下来我们把数据集放到项目里(目的是为了生产相对路径,好说明图片位置):
我们在python console中输入代码,将图片的绝对路径传输进去
from PIL import Image //导入PIL用于导入图片
img_path = "E:\DeepLearing\learn_pytorch\\Dataset\\train\\ants\\0013035.jpg" //图片绝对路径
img = Image.open(img_path) //赋值给img
img.size //查看图片的尺寸
img.show() //展示图片
效果如下:

import os
dir_path = "Dataset/train/ants"
img_path_list = os.listdir(dir_path)

然后,如果我们想要获取图片的所有地址,就需要用list获取图片文件夹,然后再用getitem获取的idx获取每张图片的地址。
在pycharm上输入如下代码:
(//后面为注释)
from torch.utils.data import Dataset //引入Dataset类
from PIL import Image //用于导入图片
import os //用于导入图片路径class MyData(Dataset):def __init__(self, root_dir, label_dir): //初始化。self用于该类的全局变量,用于后面两个函数的作为变量使用self.root_dir = root_dir //根路径 比如:"Dataset/train"self.label_dir = label_dir //标签名,比如"ants"或"bees"self.path = os.path.join(self.root_dir, self.label_dir)//拼接在一起self.img_path = os.listdir(self.path) //转化为字节流def __getitem__(self, idx): //该函数用于获取各图片img_name = self.img_path[idx] //idx,表示每张图片序号,例如:idx = 0表示第一张图img_item_path = os.path.join(self.root_dir, self.label_dir, img_name) //拼接在一起img = Image.open(img_item_path) //赋值图片路径label = self.label_dir //赋值标签名字return img, label //返回图片信息和标签名def __len__(self): //用于返回有多少张图return len(self.img_path) //返回图片长度//类实例化
root_dir = "Dataset/train" //训练集根路径
ants_label_dir = "ants" //蚂蚁标签
bees_label_dir = "bees" //蜜蜂标签
ants_dataset = MyData(root_dir, ants_label_dir) //创建蚂蚁dataset实例
bees_dataset = MyData(root_dir, bees_label_dir)//创建蜜蜂dataset实例
train_dataset = ants_dataset + bees_dataset //创建蚂蚁和蜜蜂dataset实例
输入后便创建了实例

运行如下代码,展示蚂蚁训练集第一张图片:
img,label = ants_dataset[0]
img.show()

运行如下代码,展示蜜蜂训练集第一张图片:
img,label = bees_dataset[0]
img.show()

len(bees_dataset)//蜜蜂训练集图片数量
len(ants_dataset)//蚂蚁训练集图片数量
len(train_dataset)//总训练集数量(蜜蜂 + 蚂蚁)
接下来,我们输入如下代码,创建image对应的label文件
首先我们要在Dataset目录下创建一个ants_label与bees_label用来存放txt的label文件。
代码如下:
import osroot_dir = "Dataset/train"
target_dir = "ants_image"
img_path = os.listdir(os.path.join(root_dir, target_dir))
label = target_dir.split('_')[0]
out_dir = "ants_label"
for i in img_path:file_name = i.split('.jpg')[0]with open(os.path.join(root_dir, out_dir, "{}.txt".format(file_name)), 'w') as f:f.write(label)
这段代码的作用是将指定目录下的所有以".jpg"结尾的图片文件的标签写入同名的".txt"文件中。假设有一个名叫"antsimage"的目录,里面存放了一些以"ants"开头的蚂蚁图片,我们需要将其标签写入同名的".txt"文件中,以便后续使用。
代码核心部分使用了Python的os模块来定位文件位置和创建文件
主要分为以下步骤:
1. 定义根目录rootdir、目标目录targetdir和标签label。在该段代码中,rootdir指的是存放所有图片的目录;targetdir指的是存放待处理图片的目录名称,本例中为"ants_image";而label则是标签,这里为"ants"。
2. 获取目标文件夹下所有图片文件的名称,并去掉文件扩展名".jpg",只保留文件名。
3. 遍历所有文件,使用with open()语句创建同名".txt"文件,并向其中写入标签label。
4. 循环结束后,所有的图片的标签都写入了同名".txt"文件中,存放在指定的目录out_dir下。
总之,这段代码的作用是将一些图片的标签写入同名文件中,方便后续使用。

将上述代码的ants换成bees就可以生成蜜蜂的label文件

总结
这一周在Deep Learning的课程李宏毅中学习到了反向传播算法、regression宝可梦案例,其中在反向传播算法主要是为了提高了在梯度下降算法中的计算效率,在反向传播算法中分为foward pass和 backward pass两种模式,都是解决了在链式求导的裂项中如何求值的问题。在regression中复习了之前的内容,并学习率正则化(Regularization)这个知识点,主要用于防止过拟合,使Loss变得平滑,减少干扰。此外还继续学习了pytorch,学会了如何使用Dataset和定义其里面的getitem(用于获取图片)和len(用于统计图片数量)函数,并用文件操作完成label文件的批量创建。
最后希望继续保持学习的热情,更多的去了解底层原理,下一周计划学习classification的神奇宝贝案例、逻辑回归,以及继续学习pytorch的TensorBoard的使用课程。
相关文章:
第二周:李宏毅机器学习笔记
第二周学习周报 摘要Abstract一、深度学习1.Backpropagation(反向传播)1.1 链式法则1.2 Forward pass(前向传播)1.3 Backward pass(向后传播)1.4 总结 2. Regression(神奇宝贝案例)2…...

搜维尔科技:【研究】Scalefit是一款可在工作场所自动处理3D姿势分析结果的软件
Scalefit是一款可在工作场所自动处理 3D 姿势分析结果的软件。这甚至可以在衡量员工的同时发生。然后,Scalefit 根据国际标准对姿势、压缩力和关节力矩进行分析和可视化。 3D姿势分析 如今,Xsens 技术可让您快速测量工作场所员工的态度。一套带有 17 个…...

网络编程:各协议头(数据报格式)
一、mac头 二、ip头 protocol——tcp/udp (7)TTL——生存时间 三、tcp头 四、udp头...

SpringBoot报错:The field file exceeds its maximum permitted size of 1048576 bytes
报错信息 The field file exceeds its maximum permitted size of 1048576 bytes原因是 SpringBoot内嵌的 tomcat 默认的所有上传的文件大小为 1MB 解决办法 修改配置 spring:servlet:multipart:max-file-size: 50MBmax-request-size: 50MB或者 spring.servlet.multipart.…...

C++的介绍与认识
目录 前言 1.什么是C 2.C的发展历史 3.C参考文档 4.C重要性 4.1C特点 4.2编程语言排行榜 4.3 C的应用领域 5.C学习指南 1. 基础知识 2. 面向对象编程(OOP) 3. 泛型编程 4. 标准库(STL) 结束语 前言 学习了C语言的知识…...

Spark源码详解
https://www.cnblogs.com/huanghanyu/p/12989067.html#_label3_3...

浅尝Apache Mesos
文章目录 1. Mesos是什么2. 共享集群3. Apache Mesos3.1 Mesos主节点3.2 Mesos代理3.3 Mesos框架 4. 资源管理4.1 资源提供4.2 资源角色4.3 资源预留4.4 资源权重与配额 5. 实现框架5.1 框架主类5.3 实现执行器 6. 小结参考 1. Mesos是什么 Mesos是什么,Mesos是一个…...

buuctf题目讲解-1
一眼就解密 ZmxhZ3tUSEVfRkxBR19PRl9USElTX1NUUklOR30 flag{THEFLAGOFTHISSTRING} base家族 base64 加密原理: 明文:abc 去找ascii码的二进制形式 a-->97-→01100001 (二进制为8位如果不足8位则在最左边补0至8位) b-→…...

软件测试学习之-ADB命令
ADB命令 adb工具即Android Debug Bridge(安卓调试桥) tools。它就是一个命令行窗口,用于通过电脑端与模拟器或者真实设备交互。在某些特殊的情况下进入不了系统,adb就派上用场啦! Android程序的开发通常需要使用到一…...

Redis的入门导读(一)
目录 单机架构 分布式系统 个人总结 一.Redis的介绍 二.Redis特性 三.Redis的快原因 四.Redis的应用场景 五.Redis的总结 由于Redis和分布式系统息息相关,因此我们需要先了解一下,分布式系统! 接下来就是分布式系统的演化过程。 单…...

H5与小程序:两者有何不同?
H5,即HTML5,是构建Web内容的一种语言描述方式,也是互联网的下一代标准,被认为是互联网的核心技术之一。HTML5是在HTML4.01的基础上进行了一定的改进后的规范,用户在使用任何手段进行网页浏览时看到的内容原本都是HTML格…...

计算机视觉、目标检测、视频分析的过去和未来:目标检测从入门到精通 ------ YOLOv8 到 多模态大模型处理视觉基础任务
文章大纲 计算机视觉项目的关键步骤计算机视觉项目核心内容概述步骤1: 确定项目目标步骤2:数据收集和数据标注步骤3:数据增强和拆分数据集步骤4:模型训练步骤5:模型评估和模型微调步骤6:模型测试步骤7:模型部署常见问题目标检测入门什么是目标检测目标检测算法的分类一阶…...

7月10日学习打卡,环形链表+栈OJ
前言 大家好呀,本博客目的在于记录暑假学习打卡,后续会整理成一个专栏,主要打算在暑假学习完数据结构,因此会发一些相关的数据结构实现的博客和一些刷的题,个人学习使用,也希望大家多多支持,有…...

鸿蒙语言基础类库:【@ohos.util.TreeSet (非线性容器TreeSet)】
非线性容器TreeSet 说明: 本模块首批接口从API version 8开始支持。后续版本的新增接口,采用上角标单独标记接口的起始版本。开发前请熟悉鸿蒙开发指导文档:gitee.com/li-shizhen-skin/harmony-os/blob/master/README.md点击或者复制转到。 T…...

freemarker生成pdf,同时pdf插入页脚,以及数据量大时批量处理
最近公司有个需求,就是想根据一个模板生成一个pdf文档,当即我就想到了freemarker这个远古老东西,毕竟freemarker在模板渲染方面还是非常有优势的。 准备依赖: <dependency><groupId>org.springframework.boot</gr…...

勇攀新高峰|暴雨信息召开2024年中述职工作会议
7月8日至9日,暴雨信息召开2024年中述职工作会议,总结回顾了上半年的成绩和不足,本次会议采用线上线下的方式举行,公司各部门管理人员、前台市场营销人员参加述职,公司领导班子出席会议。 本次述职采取了现场汇报点评的…...

C++:filter2D函数简要概述
OpenCV中的filter2D函数是一个非常强大的工具,用于对图像进行卷积操作,从而应用各种线性滤波器。这个函数能够处理图像中的每个像素,通过将其与指定的卷积核(或称为滤波器)进行卷积运算,来修改图像的特性。…...

Postman使用教程【项目实战】
目录 引言软件下载及安装项目开发流程1. 创建项目2. 创建集合(理解为:功能模块)3. 设置环境变量,4. 创建请求5. 测试脚本6. 响应分析7. 共享与协作 结语 引言 Postman 是一款功能强大的 API 开发工具,它可以帮助开发者测试、开发和调试 API。…...

微软Phi-3:小型而强大的AI模型解析与实战指南
微软Phi-3:小型而强大的AI模型解析与实战指南 引言 随着人工智能技术的飞速发展,小型而高效的AI模型逐渐成为研究与应用的新热点。微软研究院推出的Phi-3系列模型,以其卓越的性能和高效的成本效益,在AI领域引起了广泛关注。本文…...

Python 获取 SQL 指纹和 HASH 值
前言 本文介绍一个提取 SQL 指纹的方法,就是将 SQL 语句的条件转换为 ?可用于脱敏和 SQL 聚类分析的场景。 1. 工具安装 这里用到的工具,就是 pt 工具集中的 pt-fingerprint 含在 Percona Toolkit 中,安装方法可参考 Percona T…...

Real-ESRGAN-GUI完整指南:3个技巧让模糊图片变高清的免费AI工具
Real-ESRGAN-GUI完整指南:3个技巧让模糊图片变高清的免费AI工具 【免费下载链接】Real-ESRGAN-GUI Lovely Real-ESRGAN / Real-CUGAN GUI Wrapper 项目地址: https://gitcode.com/gh_mirrors/re/Real-ESRGAN-GUI 你是否曾为模糊的老照片感到惋惜?…...

PID控温实战:从STM32的PWM输出到加热棒,手把手教你调出稳定曲线
PID控温实战:从STM32的PWM输出到加热棒的温度控制艺术 在工业自动化、智能家居和实验室设备中,精确的温度控制一直是开发者面临的经典挑战。想象一下,当你需要将一块金属加热到200C并保持稳定,或者让培养箱维持在37C0.1C的精度时&…...

ExplorerPatcher终极指南:快速打造你的专属Windows工作界面
ExplorerPatcher终极指南:快速打造你的专属Windows工作界面 【免费下载链接】ExplorerPatcher This project aims to enhance the working environment on Windows 项目地址: https://gitcode.com/GitHub_Trending/ex/ExplorerPatcher 厌倦了Windows 11强制性…...

3步打造完美macOS菜单栏:Ice菜单栏管理终极指南
3步打造完美macOS菜单栏:Ice菜单栏管理终极指南 【免费下载链接】Ice Powerful menu bar manager for macOS 项目地址: https://gitcode.com/GitHub_Trending/ice/Ice 你是否厌倦了macOS菜单栏上杂乱无章的图标?想要一个整洁、高效且个性化的桌面…...

CTFshow F5杯 逆向与隐写实战解析 超详细
1. CTFshow F5杯逆向与隐写技术全景解析 去年参加F5杯时,我对着那道LSB隐写题折腾到凌晨三点。当终于从图片噪点中提取出flag那一刻,突然理解了什么叫做"数字世界的考古学"。逆向工程和隐写术就像侦探破案,需要同时具备技术功底和发…...

QMCDecode:解锁QQ音乐加密文件,三步实现音乐格式自由转换
QMCDecode:解锁QQ音乐加密文件,三步实现音乐格式自由转换 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录&am…...

WinForm + Modbus 上位机温湿度数据采集系统
前言工业自动化和环境监控领域,实时掌握现场的温湿度数据至关重要。传统的监控方式往往依赖人工记录或简单的报警装置,缺乏直观性和连续性。本文推荐一个基于WinForm开发的上位机温湿度采集系统,通过Modbus通信协议与下位机进行数据交互&…...

3步实现智能自动化:三月七小助手如何每天为你节省90分钟游戏时间?
3步实现智能自动化:三月七小助手如何每天为你节省90分钟游戏时间? 【免费下载链接】March7thAssistant 崩坏:星穹铁道全自动 三月七小助手 项目地址: https://gitcode.com/gh_mirrors/ma/March7thAssistant 你是否每天花费大量时间在《…...
》进阶深化中篇:Spring核心 + 数据库进阶)
《Java面试85题图解版(二)》进阶深化中篇:Spring核心 + 数据库进阶
📘 《Java面试85题图解版(二)》进阶深化中篇:Spring核心 数据库进阶 阅读提示:这是“图解比喻一句话总结”面试题库第二篇的进阶深化中篇,覆盖Spring核心与Spring Boot(9题)和数据库…...

构建安全代码执行沙箱:基于容器与系统调用的多层隔离实践
1. 项目概述:安全代码执行的挑战与机遇 在软件开发、在线教育、自动化测试乃至安全研究领域,我们常常面临一个共同的难题:如何在一个受控、隔离的环境中,安全地执行一段来源未知或不可信的代码?无论是处理用户提交的在…...