基于Vision Transformer的图像去雾算法研究与实现(附源码)
基于Vision Transformer的图像去雾算法研究与实现
0. 服务器性能简单监控
\LOG_USE_CPU_MEMORY\文件夹下的use_memory.py文件可以实时输出CPU使用率以及内存使用率,配合nvidia-smi监控GPU使用率
可以了解服务器性能是否足够;运行时在哪一步使用率突然升高;是否需要释放内存等等
1. 数据集

1.1 NH-HAZE
数据集下载: https://competitions.codalab.org/competitions/22236#participate-get_data
Train:1-40;Test:41-45
我们引入了NH-HAZE,一个非均匀的真实数据集,有成对真实的模糊和相应的无雾图像。因此,非均匀雾霾数据集的存在对于图像去雾场是非常重要的。
它代表第一个真实的图像去模糊数据集与非均匀的模糊和无模糊(地面真实)配对图像
为了补充之前的工作,在本文中,我们介绍了NH-HAZE,这是第一个具有非均匀模糊和无雾(地面真实)图像的真实图像去模糊数据集。
1.2 NTIRE 2019
DENSE-haze是一个真实的数据集,包含密集(均匀)模糊和无烟雾(地面真实)图像
官方地址:
https://data.vision.ee.ethz.ch/cvl/ntire19/#:~:text=Datasets%20and%20reports%20for%20NTIRE%202019%20challenges
https://data.vision.ee.ethz.ch/cvl/ntire19//dense-haze/
另一个下载地址:
https://www.kaggle.com/rajat95gupta/hazing-images-dataset-cvpr-2019?select=GT
Train:1-45;Test:51-55
1.3 I-HAZE
其中包含 35 对有雾的图像和相应的无雾(真实)室内图像
下载地址:https://data.vision.ee.ethz.ch/cvl/ntire18//i-haze/
Train:1-25;Test:31-35
1.4 O_HAZE
O-HAZE是第一个引入的包含模糊和无烟雾(地面真实)图像的真实数据集。它由45个不同的户外场景组成,使用一个专业的雾霾发生器在控制照明下拍摄。而O-HAZE和I-HAZE则由相对较轻、均匀的雾霾组成
下载地址:https://data.vision.ee.ethz.ch/cvl/ntire18//o-haze/
Train:1-35;Test:41-45
我们使用NH-HAZE数据集作为举例数据集,其他数据集除了数据集路径之外,大多数参数设置都一样。
该去雾项目源码下载:
https://download.csdn.net/download/DeepLearning_/87570157
2. 模型运行过程
2.0 模型介绍
在文件夹
/Uformer_ProbSparse/下存放模型代码
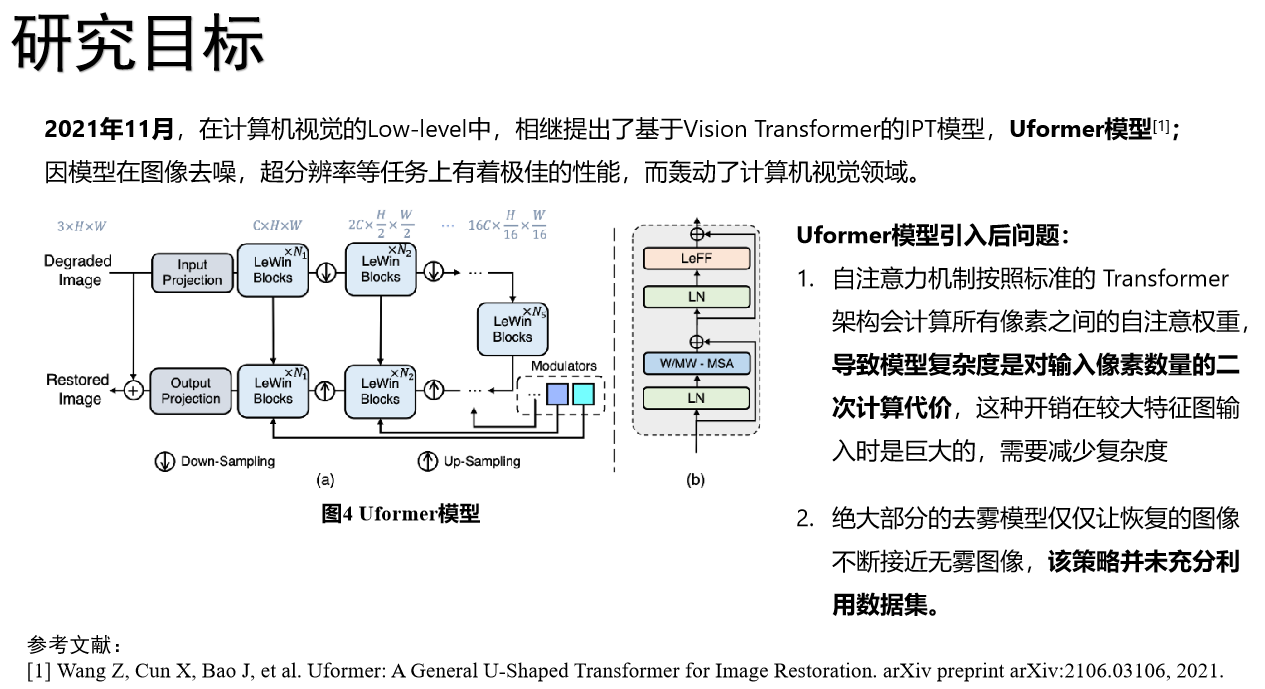

参考代码:https://github.com/ZhendongWang6/Uformer
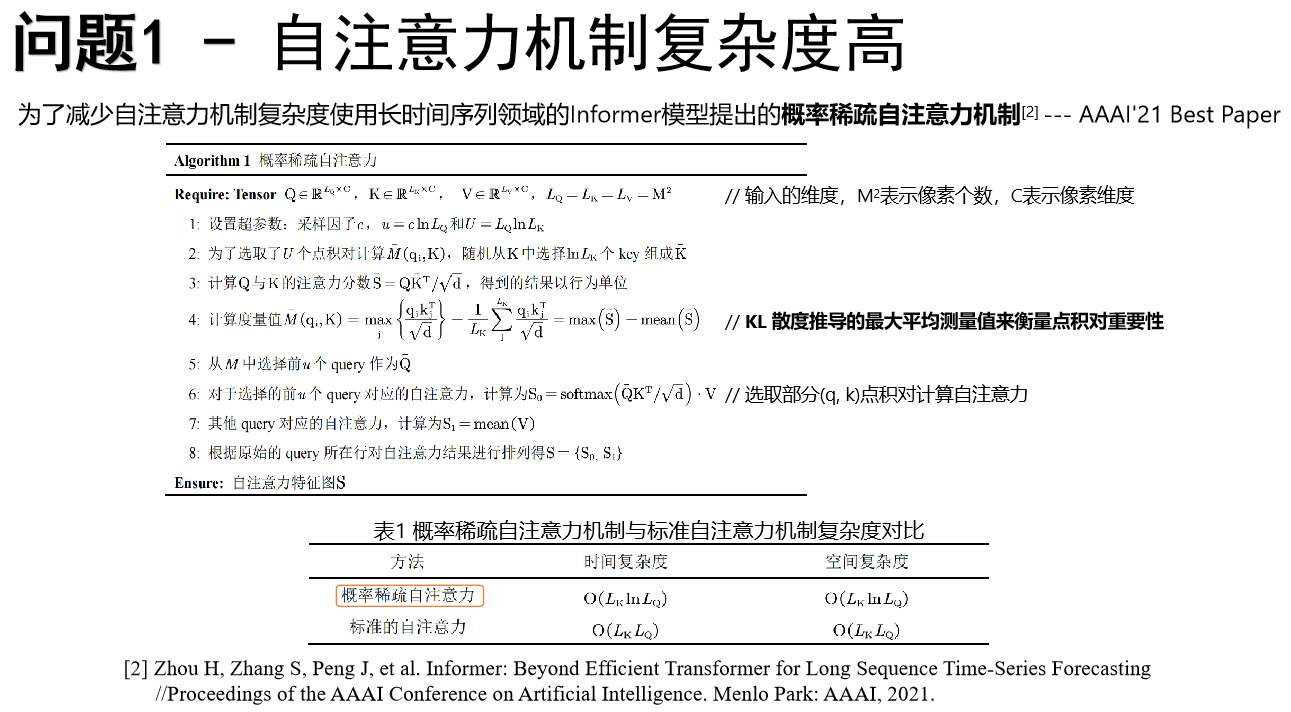
2.1 预处理数据 — 把训练数据图像切分成大小为256*256的小图
下载数据集存放在:
/home/dell/桌面/TPAMI2022/Dehazing/#dataset/NH_haze/
内含两个文件夹:train test
对训练数据集处理:
python3 generate_patches_SIDD.py --src_dir /home/dell/桌面/TPAMI2022/Dehazing/#dataset/NH_haze/train --tar_dir /home/dell/桌面/2022毕业设计/Datasets/NH-HAZE/train_patches
2.2 训练代码My_train.py
python3 ./My_train.py --arch Uformer --nepoch 270 --batch_size 32 --env My_Infor_CR --gpu '1' --train_ps 128 --train_dir /media/dell/fd6f6662-7e38-4427-80c6-0d4fb1f0e8b9/work_file/2022毕业设计/Datasets/NH-HAZE/train_patches --val_dir /media/dell/fd6f6662-7e38-4427-80c6-0d4fb1f0e8b9/work_file/2022毕业设计/Datasets/NH-HAZE/test_patches --embed_dim 32 --warmup
如果要继续对模型进行训练:--pretrain_weights 设置预训练权重路径,我的模型预训练权重在My_best_model文件夹下,以数据集划分不同预训练权重
并添加参数 --resume
训练所有参数设置在option.py文件种,主要的参数含义:
--train_ps训练样本的补丁大小,默认为128,指多大的patches输入到模型中--train_dir--val_dir训练和测试文件夹,文件夹下包含两个文件夹gt和hzay,分别包含无雾图片集和带雾图片集--batch_size设置Batch_size,默认为3--is_ab**是否使用n a对比损失,默认为False(使用)--w_loss_vgg7对比损失使用的权重,默认为1--w_loss_CharbonnierLossCharbonnierLoss 所占权重,默认为1**
2.3 测试代码test_long_GPU.py和预训练权重
预训练权重:
链接:https://pan.baidu.com/s/1a1YPTGSNa0R6I-qiTNir0A
提取码:y422模型预训练权重:将百度网盘中的
Uformer_ProbSparse/My_best_model文件夹放到Uformer_ProbSparse文件夹下,里面包含4大数据集下的权重
python3 ./test_long_GPU.py
测试流程:
在My_train.py文件中,为了训练速度考虑,我们是在每个patch上进行的测试,但patch上测试结果不等于在整图上测试的结果,因此该文件是对模型在整图上结果进行测试,论文中的结果与该测试结果一致
由于代码的特殊设置,需要让输入的图片的长和宽为 --train_ps 的整数倍,如果不够足,则要进行扩展
主要参数解释:
-
--input_dir设置测试的文件夹,文件夹下包含两个文件夹gt和hzay,分别包含无雾图片集和带雾图片集 -
--train_ps训练样本的补丁大小,默认为128,指多大的patches输入到模型中 -
代码中的: L表示图像需要拓展长和宽为多大
例如:输入是1200 * 1600,patch size = 128时,L = 1664
L需要为128倍数,且要大于输入图像的长和宽,需要根据输入图像进行调整,例如:NH-HAZE数据集上的为L = 1664
3. NH-HAZE数据集上的Losslandscape
主要将最优权重的周围的loss可视化,以探索模型收敛的难易程度以及模型架构的性能
参考文献:Park N, Kim S. How Do Vision Transformers Work?[J]. arXiv preprint arXiv:2202.06709, 2022.
3.1 基于CNN模型(FFA-Net)的Loss landscape
预训练权重:
链接:https://pan.baidu.com/s/1a1YPTGSNa0R6I-qiTNir0A
提取码:y422模型预训练权重:将百度网盘中的
FFA_how-do-vits-work-transformer文件夹包含的内容放到FFA_how-do-vits-work-transformer文件夹下,里面包含FFA-Net在NH-HAZE数据集下的最优权重,以及该权重下运行的结果
在/FFA_how-do-vits-work-transformer/FFA_pretrain_weight/下存放FFA-Net模型在该数据集下的预训练权重,决定预训练权重的路径代码在/FFA_how-do-vits-work-transformer/FFA_model/option.py
主要代码FFA_losslandscape.py:在最优权重周围随机找121个权重,然后计算这些权重的loss值,得到的loss值保存在/FFA_how-do-vits-work-transformer/checkpoints/logs/FFA_NH/My_NH_ffa_3_19_best.pk/文件夹下用于绘图,得到的Loss landscape如下:

3.2 基于Vision Transformer架构改进后的Loss landscape
预训练权重:
链接:https://pan.baidu.com/s/1a1YPTGSNa0R6I-qiTNir0A
提取码:y422模型预训练权重在2.3节有阐述
将百度网盘中的
how-do-vits-work-transformer文件夹包含的内容放到how-do-vits-work-transformer文件夹下,下面有讲解文件夹内包含的内容
在/Uformer_ProbSparse/My_best_model/下存放改进后模型在各种数据集下的预训练权重,决定预训练权重的路径代码在/how-do-vits-work-transformer/Uformer_Info/option.py中的--pretrain_weights设置对应数据集上最优的参数权重路径
主要代码My_losslandscape.py:在最优权重周围随机找121个权重,然后计算这些权重的loss值,得到的loss值保存在/how-do-vits-work-transformer/checkpoints/logs/NH/Uformer_Informer/文件夹下用于绘图,得到的Loss landscape如下:
在实践过程中,通常运行
My_losslandscape.py代码就可以直接得到下图但在我运行过程中,因为服务器断电,只能继续训练,因此
\how-do-vits-work-transformer\checkpoints\logs\NH\Uformer_Informer\下的middle_result.txt和NH_Uformer_Informer_x1_losslandscape.csv是两次运行文件中间结构,而losslandscape.ipynb中融合了两次运行结果得到该图

Park N, Kim S. How Do Vision Transformers Work?[J]. arXiv preprint arXiv:2202.06709, 2022.提到:损失景观越平坦,性能和泛化效果越好
可以发现:我们基于Vision Transformer架构改进后的模型和FFA-Net模型在最优参数时的Loss landscape,能够反应出我们的模型收敛效果比较好这与训练过程一致:我们的模型训练270个epoch就会收敛,而FFA-Net则需要40000个epoch
4. 实验结果
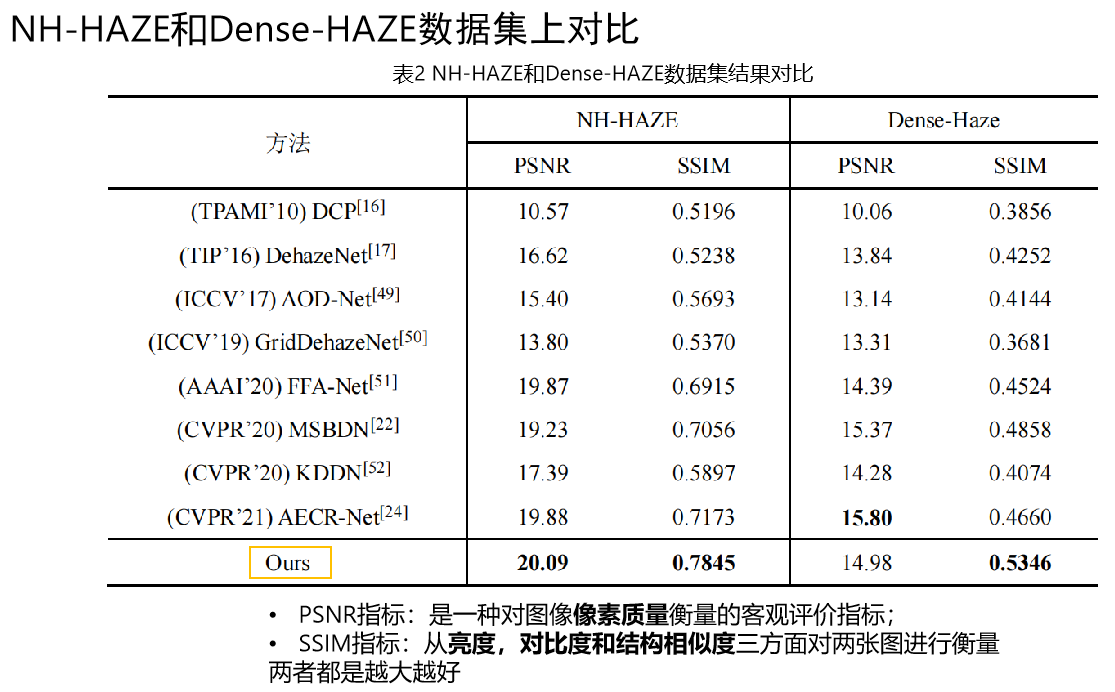

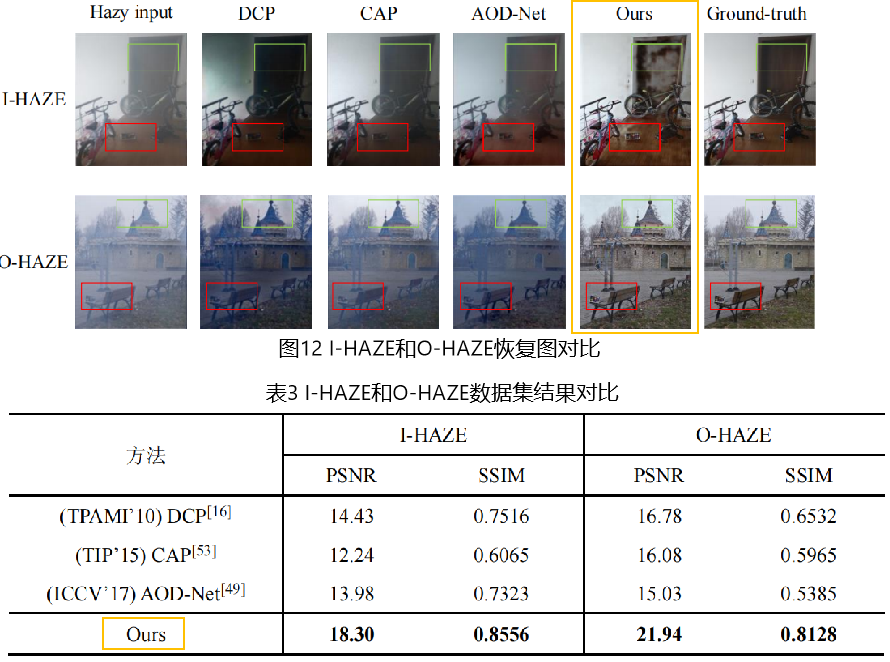
根据恢复图的结果,我们发现在部分图上的效果并不是特别优异
**可以很好的反应Vision Transformer的劣势:该架构虽然全局建模能力强,但局部建模能力没有CNN强,因此当输入某物体占大部分空间时,恢复结果容易受到其影响;因此可以在之后改进中使用CNN和Transformer组合模型,共同对全局和局部进行建模。
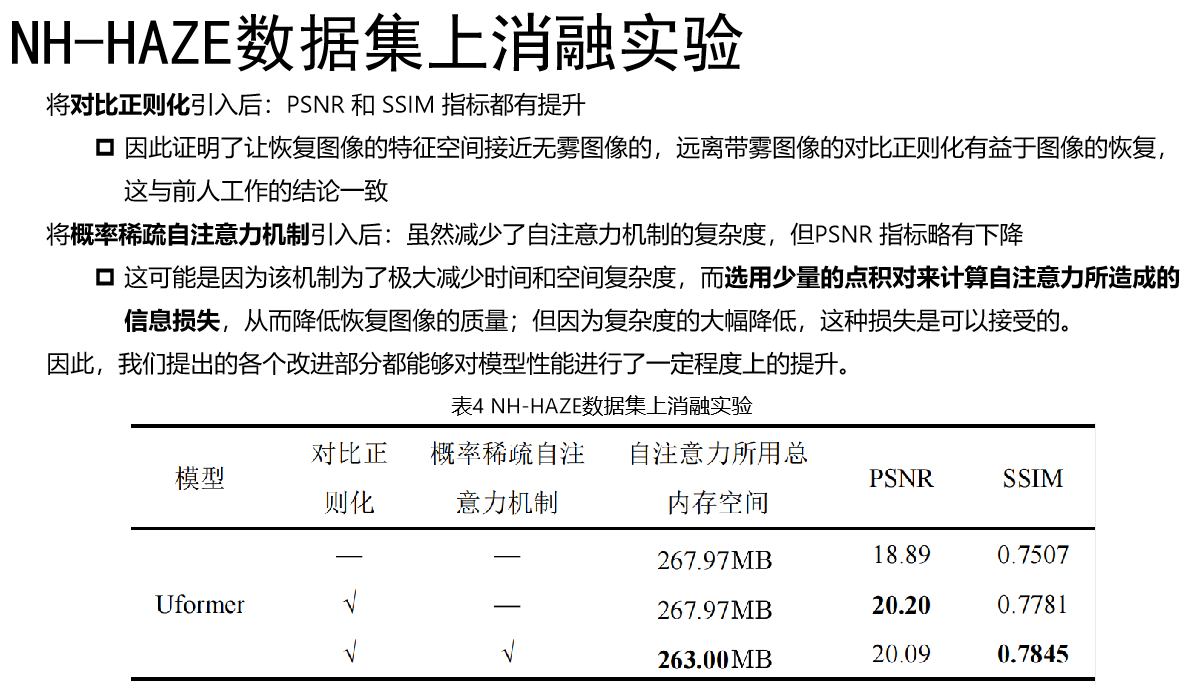
5. 消融实验
6. 总结展望

相关文章:
基于Vision Transformer的图像去雾算法研究与实现(附源码)
基于Vision Transformer的图像去雾算法研究与实现 0. 服务器性能简单监控 \LOG_USE_CPU_MEMORY\文件夹下的use_memory.py文件可以实时输出CPU使用率以及内存使用率,配合nvidia-smi监控GPU使用率 可以了解服务器性能是否足够;运行时在哪一步使用率突然…...

服务器相关常用的命令
cshell语法 https://www.doc88.com/p-4985161471426.html domainname命令 1)查看当前系统域名 domainname2)设置并查看当前系统域名 domainname example.com3)显示主机ip地址 domainname -Iwhich命令 which 系统命令在 PATH 变量指定的…...
今天是国际数学日,既是爱因斯坦的生日又是霍金的忌日
目录 一、库函数计算 π 二、近似值计算 π 三、无穷级数计算 π 四、割圆术计算 π 五、蒙特卡罗法计算 π 六、计算800位精确值 从2020年开始,每年的3月14日又被定为国际数学日,是2019年11月26日联合国教科文组织第四十届大会上正式宣布…...

Qt Quick - StackLayout 堆布局
StackLayout 堆布局一、概述二、attached 属性三、例子1. 按钮切换 StackLayout 页面一、概述 StackLayout 其实就是说,在同一个时刻里面,只有一个页面是展示出来的,类似QStackWidget 的功能,主要就是切换界面的功能。这个类型我…...
C/C++网络编程笔记Socket
https://www.bilibili.com/video/BV11Z4y157RY/?vd_sourced0030c72c95e04a14c5614c1c0e6159b上面链接是B站的博主教程,源代码来自上面视频,侵删,这里只是做笔记,以供复习和分享。上一篇博客我记录了配置环境并且跑通了࿰…...

RK3568平台开发系列讲解(网络篇)什么是Socket套接字
🚀返回专栏总目录 文章目录 一、什么是socket ?二、socket 理解为电话机三、socket 的发展历史四、套接字地址格式4.1、通用套接字地址格式4.2、IPv4 套接字格式地址4.3、IPv6 套接字地址格式4.4、几种套接字地址格式比较沉淀、分享、成长,让自己和他人都能有所收获!😄 …...
网络安全竞赛试题——渗透测试解析(详细))
2022年全国职业院校技能大赛(中职组)网络安全竞赛试题——渗透测试解析(详细)
渗透测试 任务环境说明: 服务器场景:Server9服务器场景操作系统:未知(关闭连接)系统用户名:administrator密码:123456通过本地PC中渗透测试平台Kali对靶机场景进行系统服务及版本扫描渗透测试,以xml格式向指定文件输出信息(使用工具Nmap),将以xml格式向指定文件输出…...

尚融宝03-mybatis-plus基本CRUD和常用注解
目录 一、通用Mapper 1、Create 2、Retrieve 3、Update 4、Delete 二、通用Service 1、创建Service接口 2、创建Service实现类 3、创建测试类 4、测试记录数 5、测试批量插入 三、自定义Mapper 1、接口方法定义 2、创建xml文件 3、测试条件查询 四、自定义Serv…...

vue多行显示文字展开
这几天项目里面有一个需求,多行需要进行展开文字,类似实现这种效果 难点就在于页面布局 一开始就跟无头苍蝇似的,到处百度 ,后面发现网上的都不适合自己,最终想到了解决方案 下面是思路: 需求是超过3行&a…...
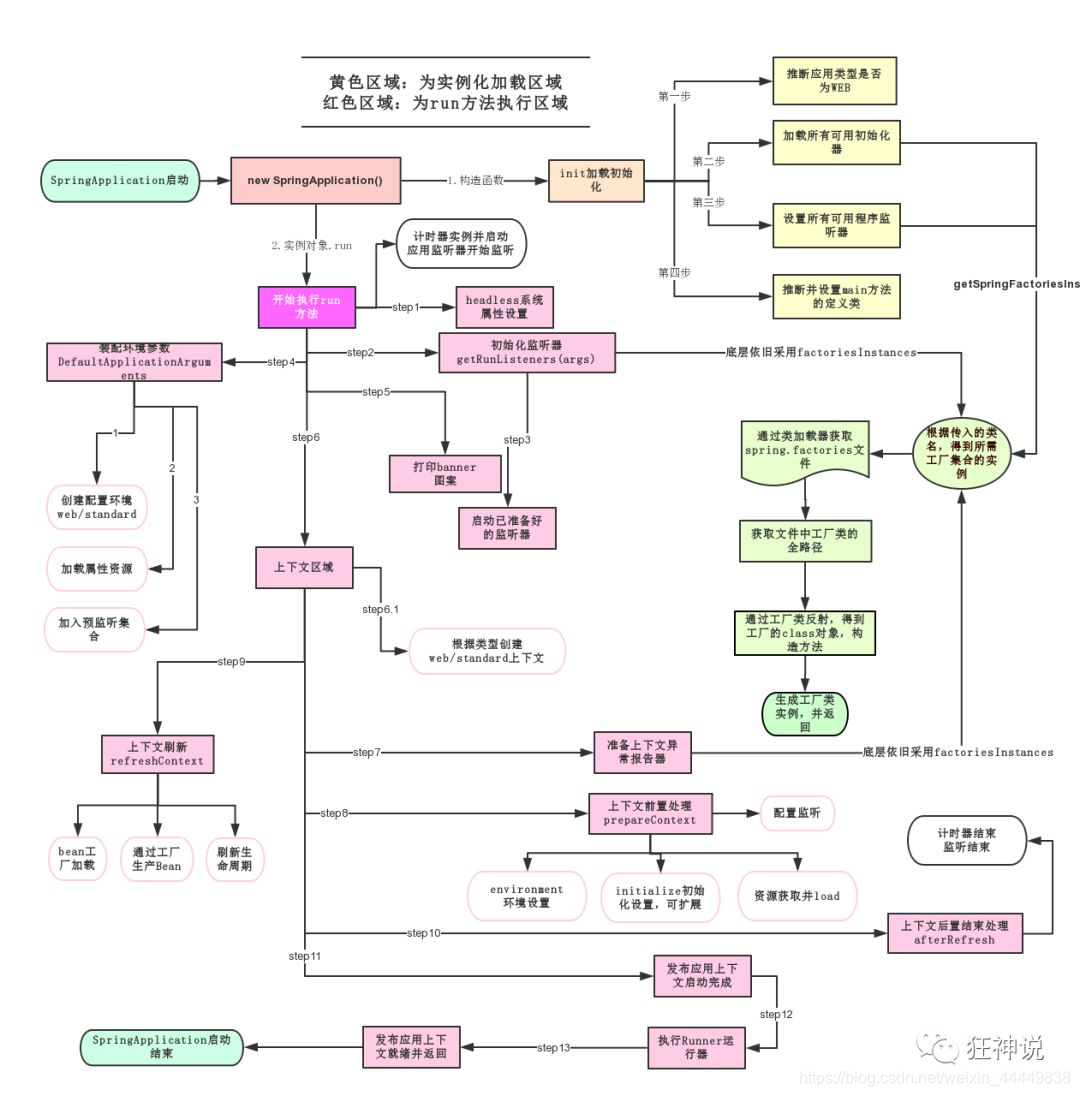
SpringBoot:SpringBoot 的底层运行原理解析
声明原文出处:狂神说 文章目录1. pom.xml1 . 父依赖2 . 启动器 spring-boot-starter2. 主启动类的注解1. 默认的主启动类2. SpringBootApplication3. ComponentScan4. SpringBootConfiguration5. SpringBootApplication 注解6. spring.factories7. 结论8. 简单图解3…...

哪些场景会产生OOM?怎么解决?
文章目录 堆内存溢出方法区(运行时常量池)和元空间溢出直接内存溢出栈内存溢出什么时候会抛出OutOfMemery异常呢?初看好像挺简单的,其实深究起来考察的是对整个JVM的了解,而这个问题从网上可以翻到一些乱七八糟的答案,其实在总结下来基本上4个场景可以概括下来。 堆内存溢出…...

金三银四、金九银十 面试宝典 Spring、MyBatis、SpringMVC面试题 超级无敌全的面试题汇总(超万字的面试题,让你的SSM框架无可挑剔)
Spring、MyBatis、SpringMVC 框架 - 面试宝典 又到了 金三银四、金九银十 的时候了,是时候收藏一波面试题了,面试题可以不学,但不能没有!🥁🥁🥁 一个合格的 计算机打工人 ,收藏夹里…...
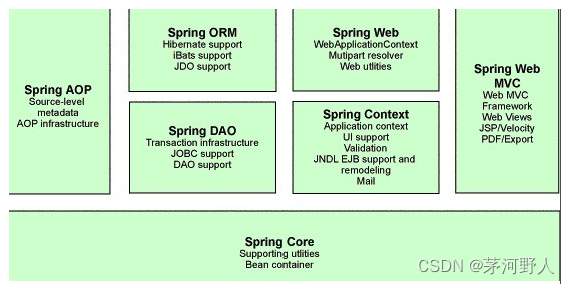
JAVA开发(Spring框架详解)
javaweb项目几乎已经离不开spring框架了,spring 是一个典型的分层架构框架,它包含一系列的功能并被分为多个功能模块,springboot对spring框架又做了一层封装,以至于很多人对原来的spring框架越来越不了解。 要谈Spring的历史&…...

自学大数据第八天~HDFS命令(二)
嗨喽,好久不见,最近抽空复习了一下hadoop,书读百遍,其意自现这句话还真是; 继续学习HDFS常用命令 改变文件 拥有者~chown hdfs dfs -chown -R hadoop /user/hadoop使用 -R 将使改变在目录结构下递归进行。命令的使用者必须是超级用户。 改变文件所属组-chgrp hdfs dfs -chgr…...
贪心算法(几种常规样例)
贪心算法(几种常规样例) 贪心算法,指在对问题进行求解的时候,总是做出当前看来是最好的选择。也就是说不从整体上最优上考虑,算法得到的结果是某种意义上的局部最优解 文章目录贪心算法(几种常规样例&…...

【数据结构】基础知识总结
系列综述: 💞目的:本系列是个人整理为了数据结构复习用的,由于牛客刷题发现数据结构方面和王道数据结构的题目非常像,甚至很多都是王道中的,所以将基础知识进行了整理,后续会将牛客刷题的错题一…...
宣布推出 .NET 社区工具包 8.1!
我们很高兴地宣布 .NET Community Toolkit 8.1 版正式发布!这个新版本包括呼声很高的新功能、bug 修复和对 MVVM 工具包源代码生成器的大量性能改进,使开发人员在使用它们时的用户体验比以往更好! 就像在我们之前的版本中一样,我…...

ChatGPT解开了我一直以来对自动化测试的疑惑
目录 前言 与ChatGPT的对话 什么是自动化测试,我该如何做到自动化测试,或者说需要借助什么工具可以做到自动化测试? 自动化测试如何确保数据的准确性 自动化测试是怎么去验证数据的 如何通过断言验证数据 自动化测试有哪些验证工具可以验证数据 总结 前言…...
十大经典排序算法(上)
目录 1.1冒泡排序 1. 算法步骤 3.什么时候最快 4. 什么时候最慢 5.代码实现 1.2选择排序 1. 算法步骤 2. 动图演示 3.代码实现 1.3 插入排序 1. 算法步骤 2. 动图演示 3. 算法实现 1.4 希尔排序 1. 算法步骤 2. 动图演示 3.代码实现 1.5 归并排序 1. 算法步骤 2…...

如何从 MySQL 读取 100w 数据进行处理
文章目录 场景常规查询流式查询MyBatis 流式查询接口非流式查询和流式查询区别游标查询场景 大数据量操作的场景大致如下: 1、 数据迁移; 2、 数据导出; 3、 批量处理数据; 在实际工作中当指定查询数据过大时,我们一般使用分页查询的方式一页一页的将数据放到内存处理。…...

AI Toolkit for Visual Studio Code完全指南:从环境配置到应用部署的AI开发工具链实践
AI Toolkit for Visual Studio Code完全指南:从环境配置到应用部署的AI开发工具链实践 【免费下载链接】vscode-ai-toolkit 项目地址: https://gitcode.com/GitHub_Trending/vs/vscode-ai-toolkit 工具认知篇:重新定义AI开发流程 AI开发工具链正…...

Qwen3-4B-Instruct-2507问题解决:部署中常见的5个错误及快速修复方法
Qwen3-4B-Instruct-2507问题解决:部署中常见的5个错误及快速修复方法 1. 部署准备与环境检查 在开始部署Qwen3-4B-Instruct-2507模型之前,确保您的环境满足以下基本要求: 硬件配置:推荐使用NVIDIA 4090D显卡(24GB显…...
TranslucentTB启动失败?3步快速解决VCLibs运行时依赖问题
TranslucentTB启动失败?3步快速解决VCLibs运行时依赖问题 【免费下载链接】TranslucentTB A lightweight utility that makes the Windows taskbar translucent/transparent. 项目地址: https://gitcode.com/gh_mirrors/tr/TranslucentTB 当你满怀期待地安装…...

技术速递|底层机制:GitHub Agentic Workflows 的安全架构
作者:Landon Cox & Jiaxiao Zhou排版:Alan WangGitHub Agentic Workflows 构建于隔离、受限输出以及全面日志记录之上。了解我们的威胁模型和安全架构如何帮助团队在 GitHub Actions 中安全运行智能体。无论你是开源维护者还是企业团队的一员&#x…...

5分钟搞定专业级黑苹果配置:OpCore Simplify智能工具让复杂EFI构建化繁为简
5分钟搞定专业级黑苹果配置:OpCore Simplify智能工具让复杂EFI构建化繁为简 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 开篇痛点直击&…...

SiameseUIE在CSDN社区的应用:技术文章智能分析
SiameseUIE在CSDN社区的应用:技术文章智能分析 1. 引言 CSDN社区每天都有成千上万的技术文章发布,涵盖了从编程语言到人工智能的各个领域。面对如此庞大的内容量,如何快速准确地理解每篇文章的核心内容、自动生成标签、进行智能分类&#x…...
)
告别数据迷宫:手把手教你用DataHub搭建企业级元数据搜索中心(支持MySQL/Airflow/Superset)
告别数据迷宫:手把手教你用DataHub搭建企业级元数据搜索中心(支持MySQL/Airflow/Superset) 当数据资产像野草一样在组织内疯长时,工程师们常常发现自己被困在由数百个数据表、数十个BI看板和错综复杂的调度任务构成的迷宫中。上周…...

用Multisim/TINA-TI仿真带你玩转一阶到二阶有源滤波器:从传递函数到实际频响曲线全验证
从仿真到实践:一阶与二阶有源滤波器的可视化验证指南 在模拟电路设计中,滤波器是信号处理的基础模块。许多初学者虽然能推导传递函数,却难以将理论公式与实际电路行为建立直观联系。本文将用Multisim和TINA-TI两款主流仿真工具,带…...

AHB-Lite时序图深度解读:那些官方文档没明说的‘潜规则’与设计陷阱
AHB-Lite时序图深度解读:那些官方文档没明说的‘潜规则’与设计陷阱 在数字IC设计中,AHB-Lite总线作为AMBA3.0协议家族的核心成员,以其简洁高效的架构成为片上系统互连的首选方案。然而,许多工程师在通过官方文档掌握基础协议后&a…...

Go Channel 死锁问题定位技巧
Go Channel 死锁问题定位技巧 在Go语言中,Channel是协程间通信的核心机制,但使用不当容易引发死锁问题。死锁不仅会导致程序阻塞,还可能让开发者陷入调试困境。本文将分享几个实用的定位技巧,帮助开发者快速识别和解决Channel死锁…...