YOLOv10改进 | Conv篇 | 利用FasterBlock二次创新C2f提出一种全新的结构(全网独家首发,参数量下降70W)
一、本文介绍
本文给大家带来的改进机制是利用FasterNet的FasterBlock改进特征提取网络,将其用来改进ResNet网络,其旨在提高计算速度而不牺牲准确性,特别是在视觉任务中。它通过一种称为部分卷积(PConv)的新技术来减少冗余计算和内存访问。这种方法使得FasterNet在多种设备上运行速度比其他网络快得多,同时在各种视觉任务中保持高准确率,同时本文的内容为我独家创新,全网仅此一份,同时本文的改进机制参数量下降50W,V10n的计算量为6.9GFLOPs。
欢迎大家订阅我的专栏一起学习YOLO!

专栏回顾:YOLOv10改进系列专栏——本专栏持续复习各种顶会内容——科研必备
目录
一、本文介绍
二、FasterNet原理
2.1 FasterNet的基本原理
2.2 部分卷积
2.3 加速神经网络
三、FasterBlock的核心代码
四、 手把手教你添加FasterBlock机制
4.1 修改一
4.2 修改二
4.3 修改三
4.4 修改四
五、FasterBlock的yaml文件和运行记录
5.1 FasterBlock的yaml文件
5.2 训练代码
5.3 FasterBlock的训练过程截图
五、本文总结
二、FasterNet原理
 论文地址:官方论文地址
论文地址:官方论文地址
代码地址:官方代码地址

2.1 FasterNet的基本原理
FasterNet是一种高效的神经网络架构,旨在提高计算速度而不牺牲准确性,特别是在视觉任务中。它通过一种称为部分卷积(PConv)的新技术来减少冗余计算和内存访问。这种方法使得FasterNet在多种设备上运行速度比其他网络快得多,同时在各种视觉任务中保持高准确率。例如,FasterNet在ImageNet-1k数据集上的表现超过了其他模型,如MobileViT-XXS,展现了其在速度和准确度方面的优势。
FasterNet的基本原理可以总结为以下几点:
1. 部分卷积(PConv): FasterNet引入了部分卷积(PConv),这是一种新型的卷积方法,它通过只处理输入通道的一部分来减少计算量和内存访问。
2. 加速神经网络: FasterNet利用PConv的优势,实现了在多种设备上比其他现有神经网络更快的运行速度,同时保持了较高的准确度。
下面为大家展示的是FasterNet的整体架构。
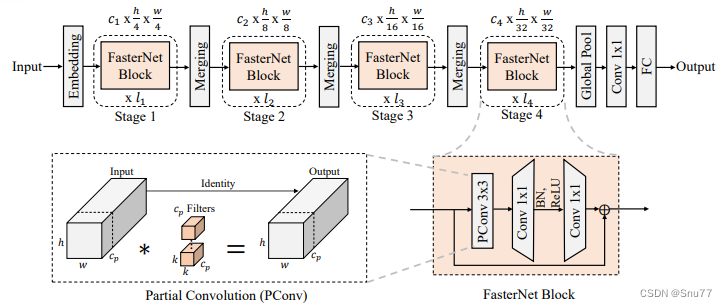
它包括四个层次化的阶段,每个阶段由一系列FasterNet块组成,并由嵌入或合并层开头。最后三层用于特征分类。在每个FasterNet块中,PConv层之后是两个点状卷积(PWConv)层。为了保持特征多样性并实现更低的延迟,仅在中间层之后放置了归一化和激活层。
2.2 部分卷积
部分卷积(PConv)是一种卷积神经网络中的操作,旨在提高计算效率。它通过只在输入特征图的一部分上执行卷积操作,而非传统卷积操作中的全面应用。这样,PConv可以减少不必要的计算和内存访问,因为它忽略了输入中认为是冗余的部分。这种方法特别适合在资源有限的设备上运行深度学习模型,因为它可以在不牺牲太多性能的情况下,显著降低计算需求。
下面我为大家展示了FasterNet中的部分卷积(PConv)与传统卷积和深度卷积/分组卷积的比较:
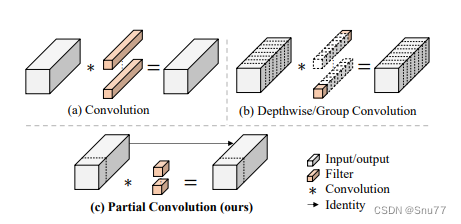
PConv通过仅对输入通道的一小部分应用滤波器,同时保持其余通道不变,实现了快速和高效的特性提取。PConv的计算复杂度(FLOPs)低于常规卷积,但高于深度卷积/分组卷积,这样在减少计算资源的同时提高了运算性能。
2.3 加速神经网络
加速神经网络主要通过优化计算路径、减少模型大小和复杂性、提高操作效率,以及使用高效的硬件实现等方式来降低模型的推理时间。这些方法包括
简化网络层、使用更快的激活函数、采用量化技术将浮点运算转换为整数运算,以及使用特殊的算法来减少内存访问次数等。通过这些策略,可以在不损害模型准确性的前提下,使神经网络能够更快地处理数据和做出预测。
三、FasterBlock的核心代码
核心代码的使用方式看章节四!
import torch
import torch.nn as nn
from timm.models.layers import DropPath__all__ = ['C2f_FasterBlock']class Partial_conv3(nn.Module):def __init__(self, dim, n_div, forward):super().__init__()self.dim_conv3 = dim // n_divself.dim_untouched = dim - self.dim_conv3self.partial_conv3 = nn.Conv2d(self.dim_conv3, self.dim_conv3, 3, 1, 1, bias=False)if forward == 'slicing':self.forward = self.forward_slicingelif forward == 'split_cat':self.forward = self.forward_split_catelse:raise NotImplementedErrordef forward_slicing(self, x):# only for inferencex = x.clone() # !!! Keep the original input intact for the residual connection laterx[:, :self.dim_conv3, :, :] = self.partial_conv3(x[:, :self.dim_conv3, :, :])return xdef forward_split_cat(self, x):# for training/inferencex1, x2 = torch.split(x, [self.dim_conv3, self.dim_untouched], dim=1)x1 = self.partial_conv3(x1)x = torch.cat((x1, x2), 1)return xdef autopad(k, p=None, d=1): # kernel, padding, dilation"""Pad to 'same' shape outputs."""if d > 1:k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-sizeif p is None:p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-padreturn pclass Conv(nn.Module):"""Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)."""default_act = nn.SiLU() # default activationdef __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):"""Initialize Conv layer with given arguments including activation."""super().__init__()self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)self.bn = nn.BatchNorm2d(c2)self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()def forward(self, x):"""Apply convolution, batch normalization and activation to input tensor."""return self.act(self.bn(self.conv(x)))def forward_fuse(self, x):"""Perform transposed convolution of 2D data."""return self.act(self.conv(x))class FasterBlock(nn.Module):def __init__(self,inc,dim,n_div=4,mlp_ratio=2,drop_path=0.1,layer_scale_init_value=0.0,act_layer='RELU',norm_layer='BN',pconv_fw_type='split_cat'):super().__init__()self.dim = dimself.inc = incself.mlp_ratio = mlp_ratioself.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()self.n_div = n_divmlp_hidden_dim = int(dim * mlp_ratio)mlp_layer = [nn.Conv2d(dim, mlp_hidden_dim, 1, bias=False),nn.BatchNorm2d(mlp_hidden_dim),nn.ReLU(),nn.Conv2d(mlp_hidden_dim, dim, 1, bias=False)]self.mlp = nn.Sequential(*mlp_layer)self.spatial_mixing = Partial_conv3(dim,n_div,pconv_fw_type)if inc != dim: # 在输入和输出不等时添加额外处理一步self.firstConv = Conv(inc, dim, 1)if layer_scale_init_value > 0:self.layer_scale = nn.Parameter(layer_scale_init_value * torch.ones((dim)), requires_grad=True)self.forward = self.forward_layer_scaleelse:self.forward = self.forwarddef forward(self, x):if self.inc != self.dim:x = self.firstConv(x)shortcut = xx = self.spatial_mixing(x)x = shortcut + self.drop_path(self.mlp(x))return xdef forward_layer_scale(self, x):if self.inc != self.dim:x = self.firstConv(x)shortcut = xx = self.spatial_mixing(x)x = shortcut + self.drop_path(self.layer_scale.unsqueeze(-1).unsqueeze(-1) * self.mlp(x))return xclass C2f_FasterBlock(nn.Module):"""Faster Implementation of CSP Bottleneck with 2 convolutions."""def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):"""Initialize CSP bottleneck layer with two convolutions with arguments ch_in, ch_out, number, shortcut, groups,expansion."""super().__init__()self.c = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, 2 * self.c, 1, 1)self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)self.m = nn.ModuleList(FasterBlock(self.c, self.c) for _ in range(n))def forward(self, x):"""Forward pass through C2f layer."""x = self.cv1(x)x = x.chunk(2, 1)y = list(x)# y = list(self.cv1(x).chunk(2, 1))y.extend(m(y[-1]) for m in self.m)return self.cv2(torch.cat(y, 1))def forward_split(self, x):"""Forward pass using split() instead of chunk()."""y = list(self.cv1(x).split((self.c, self.c), 1))y.extend(m(y[-1]) for m in self.m)return self.cv2(torch.cat(y, 1))if __name__ == "__main__":# Generating Sample imageimage_size = (1, 64, 240, 240)image = torch.rand(*image_size)# Modelmodel = C2f_FasterBlock(64, 64)out = model(image)print(out.size())四、 手把手教你添加FasterBlock机制
4.1 修改一
第一还是建立文件,我们找到如下ultralytics/nn/modules文件夹下建立一个目录名字呢就是'Addmodules'文件夹(用群内的文件的话已经有了无需新建)!然后在其内部建立一个新的py文件将核心代码复制粘贴进去即可。
4.2 修改二
第二步我们在该目录下创建一个新的py文件名字为'__init__.py'(用群内的文件的话已经有了无需新建),然后在其内部导入我们的检测头如下图所示。
4.3 修改三
第三步我门中到如下文件'ultralytics/nn/tasks.py'进行导入和注册我们的模块(用群内的文件的话已经有了无需重新导入直接开始第四步即可)!
从今天开始以后的教程就都统一成这个样子了,因为我默认大家用了我群内的文件来进行修改!!
4.4 修改四
按照我的添加在parse_model里添加即可。

到此就修改完成了,大家可以复制下面的yaml文件运行。
五、FasterBlock的yaml文件和运行记录
5.1 FasterBlock的yaml文件
此版本的训练信息:YOLOv10n-C2f-FasterBlock summary: 404 layers, 2231750 parameters, 2231734 gradients, 6.9 GFLOPs
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv10 object detection model. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov10n.yaml' will call yolov10.yaml with scale 'n'# [depth, width, max_channels]n: [0.33, 0.25, 1024]backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 3, C2f_FasterBlock, [128, True]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 6, C2f_FasterBlock, [256, True]]- [-1, 1, SCDown, [512, 3, 2]] # 5-P4/16- [-1, 6, C2f_FasterBlock, [512, True]]- [-1, 1, SCDown, [1024, 3, 2]] # 7-P5/32- [-1, 3, C2f_FasterBlock, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9- [-1, 1, PSA, [1024]] # 10# YOLOv10.0n head
head:- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 3, C2f_FasterBlock, [512]] # 13- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 3, C2f_FasterBlock, [256]] # 16 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]]- [[-1, 13], 1, Concat, [1]] # cat head P4- [-1, 3, C2f_FasterBlock, [512]] # 19 (P4/16-medium)- [-1, 1, SCDown, [512, 3, 2]]- [[-1, 10], 1, Concat, [1]] # cat head P5- [-1, 3, C2fCIB, [1024, True, True]] # 22 (P5/32-large)- [[16, 19, 22], 1, v10Detect, [nc]] # Detect(P3, P4, P5)
5.2 训练代码
大家可以创建一个py文件将我给的代码复制粘贴进去,配置好自己的文件路径即可运行。
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLOif __name__ == '__main__':model = YOLO('ultralytics/cfg/models/v8/yolov8-C2f-FasterBlock.yaml')# model.load('yolov8n.pt') # loading pretrain weightsmodel.train(data=r'替换数据集yaml文件地址',# 如果大家任务是其它的'ultralytics/cfg/default.yaml'找到这里修改task可以改成detect, segment, classify, posecache=False,imgsz=640,epochs=150,single_cls=False, # 是否是单类别检测batch=4,close_mosaic=10,workers=0,device='0',optimizer='SGD', # using SGD# resume='', # 如过想续训就设置last.pt的地址amp=False, # 如果出现训练损失为Nan可以关闭ampproject='runs/train',name='exp',)5.3 FasterBlock的训练过程截图

五、本文总结
到此本文的正式分享内容就结束了,在这里给大家推荐我的YOLOv10改进有效涨点专栏,本专栏目前为新开的平均质量分98分,后期我会根据各种最新的前沿顶会进行论文复现,也会对一些老的改进机制进行补充,如果大家觉得本文帮助到你了,订阅本专栏,关注后续更多的更新~
专栏回顾:YOLOv10改进系列专栏——本专栏持续复习各种顶会内容——科研必备
相关文章:
YOLOv10改进 | Conv篇 | 利用FasterBlock二次创新C2f提出一种全新的结构(全网独家首发,参数量下降70W)
一、本文介绍 本文给大家带来的改进机制是利用FasterNet的FasterBlock改进特征提取网络,将其用来改进ResNet网络,其旨在提高计算速度而不牺牲准确性,特别是在视觉任务中。它通过一种称为部分卷积(PConv)的新技术来减少…...

实验-ENSP实现防火墙区域策略与用户管理
目录 实验拓扑 自己搭建拓扑 实验要求 实验步骤 整通总公司内网 sw3配置vlan 防火墙配置IP 配置安全策略(DMZ区内的服务器,办公区仅能在办公时间内(9: 00- 18:00)可以访问,生产区的设备全天可以访问) 配置nat策…...

【游戏客户端】大话slg玩法架构(二)背景地图
【游戏客户端】大话slg玩法架构(二)背景地图 大家好,我是Lampard家杰~~ 今天我们继续给大家分享SLG玩法的实现架构,关于SLG玩法的介绍可以参考这篇上一篇文章:【游戏客户端】制作率土之滨Like玩法 PS:和之前…...

git-工作场景
1. 远程分支为准 强制切换到远程分支并忽略本地未提交的修改 git fetch origin # 获取最新的远程分支信息 git reset --hard origin/feature_server_env_debug_20240604 # 强制切换到远程分支,并忽略本地修改 2. 切换分支 1. **查看所有分支:**…...
)
coco dataset标签数据结构(json文件)
COCO数据集现在有3种标注类型:object instances(目标实例), object keypoints(目标上的关键点), 和image captions(看图说话),使用json文件存储。 NameImagesLabelstrain linkhttp:…...

GaussDB关键技术原理:高性能(四)
GaussDB关键技术原理:高性能(三)从查询重写RBO、物理优化CBO、分布式优化器、布式执行框架、轻量全局事务管理GTM-lite等五方面对高性能关键技术进行了解读,本篇将从USTORE存储引擎、计划缓存计划技术、数据分区与分区剪枝、列式存…...

总结之企业微信(一)——创建外部群二维码,用户扫码入群
创建外部群 企微接口中没有直接通过服务端API接口创建外部群 可以通过jssdk创建外部群:引用jssdk调用会话接口wx.openEnterpriseChat https://work.weixin.qq.com/api/doc/90000/90136/90511 创建外部群二维码 需要通过企业微信的应用,并且配置客户联…...

透视数据治理:企业如何衡量数据治理的效果?
在企业运营中,各个业务部门的成功与否都是直观且易于量化的,像销售部门卖了多少产品又为企业带来多少盈利,这些都能用具体的数字来说话。但当谈到数据治理的成效时,许多企业与决策者却感到迷茫。 数据治理的重要性不言而喻&#…...

ERC20查询操作--获取ERC20 Token的余额
获取ERC20 Token的余额 https://blog.csdn.net/wypeng2010/article/details/81362562 通过REST查询 curl -X POST --data-binary {"jsonrpc":"2.0","method":"eth_call","params":[{"from": "0x954d1a58c7a…...

Linux运维:MySQL中间件代理服务器,mycat读写分离应用实验
Mycat适用的场景很丰富,以下是几个典型的应用场景: 1.单纯的读写分离,此时配置最为简单,支持读写分离,主从切换 2.分表分库,对于超过1000万的表进行分片,最大支持1000亿的单表分片 3.多租户应…...

css文字自适应宽度动态出现省略号...
前言 在列表排行榜中通常会出现的一个需求:从左到右依次是名次、头像、昵称、徽标、分数。徽标可能会有多个或者没有徽标,徽标长度是动态的,昵称如果过长要随着有无徽标进行动态截断出现省略号。如下图布局所示(花里胡哨的底色是…...

边缘计算盒子_B100_Jetson Nano (aarch64)开发环境搭建
目录 一、刷机步骤1、搭建刷机环境2、进入刷机模式3、开始刷机 二、系统迁移到TF卡 或者 U盘1、迁移脚本2、提前插入U盘或者TF卡3、 开始迁移 三、搭建miniconda 环境1、下载安装 四、jetpack开发套件环境1、版本查看2、apt 更换国内源3、安装Jetson-stats管理工具 一、刷机步骤…...

【Superset】dashboard 自定义URL
URL设置 在发布仪表盘(dashboard)后,可以通过修改看板属性中的SLUG等,生成url 举例: http://localhost:8090/superset/dashboard/test/ 参数设置 以下 URL 参数可用于修改仪表板的呈现方式:此处参考了官…...

【Linux网络】IP协议{初识/报头/分片/网段划分/子网掩码/私网公网IP/认识网络世界/路由表}
文章目录 1.入门了解2.认识报头3.认识网段4.路由跳转相关指令路由 该文诸多理解参考文章:好文! 1.入门了解 用户需求:将我的数据可靠的跨网络从A主机送到B主机 传输层TCP:由各种方法(流量控制/超时重传/滑动窗口/拥塞…...

香蕉派BPI-Wifi6迷你路由器公开发售
Banana Pi BPI-Wifi6 Mini 公开发售。 Banana Pi BPI-Wifi6 Mini 开源路由器采用Triductor TR6560 TR5220 wifi SOC设计,是一款迷你尺寸的wifi6路由器解决方案。内置高性能双核ARM Cortec A9处理器用于WIFI报文转发或智能业务处理,内置高性能LSW和硬件N…...

WPF-控件样式设置
1、控件样式设置 1.1、内嵌式为相同控件设置样式 <Window.Resources><Style TargetType"Button"><Setter Property"Background" Value"Yellow"></Setter><Setter Property"Width" Value"60"&g…...

C++20中的指定初始化器(designated initializers)
指定初始化器(designated initializers, 指定初始值设定项)语法如下:C风格指定初始化器语法,初始化数据成员的一种便捷方式 T object { .des1 arg1, .des2 { arg2 } ... }; T object { .des1 arg1, .des2 { arg2 } ... }; 说明: 1.每个指…...
中.pro文件设置)
QT跨平台开发(windows、mac)中.pro文件设置
方法一: 在配置前面加上平台标识符的前缀 # windows win32:INCLUDEPATH F:/Dev/ffmpeg-4.3.2/include win32:LIBS -LF:/Dev/ffmpeg-4.3.2/lib \-lavcodec \-lavdevice \-lavfilter \-lavformat \-lavutil \-lpostproc \-lswscale \-lswresample# mac macx:INCLUD…...

wifi中的stream parser
在Wi-Fi系统中,流解析器(Stream Parser)的主要功能是将传输的数据流(bit stream)按照物理层(PHY)和媒体访问控制层(MAC)协议的要求进行分解和处理。这一步骤对于确保数据…...

GitHub网页打开慢的解决办法
有时候看资料絮叨github网页打不开,经百度后,发下下面的方法有效。 1)获取github官网ip 我们首先要获取github官网的ip地址,方法就是打开cmd,然后ping 找到github的地址:20.205.243.166 2)配…...

AI应用着陆页模板:快速构建专业产品门户的实战指南
1. 项目概述:一个面向AI应用落地的着陆页模板 最近在折腾AI应用开发的朋友,估计都遇到过同一个问题:模型和算法好不容易调好了,后端API也搭起来了,但一到“怎么让用户用起来”这一步,就卡壳了。尤其是那个…...

利用Google可编程搜索引擎API实现免费高效的Python搜索自动化
1. 项目概述:一个被低估的搜索利器 如果你经常需要从Google上批量、自动化地获取搜索结果,并且对搜索结果的质量、速度和稳定性有要求,那你一定遇到过官方API的种种限制,或者对第三方付费服务望而却步。今天要聊的这个项目 chhan…...
)
STM32L4低功耗实战:用RTC内部唤醒定时1秒,让设备续航翻倍(附CubeIDE配置)
STM32L4低功耗实战:RTC唤醒中断与CubeIDE配置全解析 在电池供电的物联网终端设计中,每微安电流都关乎产品寿命。曾有个智能农业项目,原本预计6个月的传感器续航,因未优化低功耗模式,实际仅维持了3周。这促使我们深入研…...

MGRE实验报告
一.实验概述实验名称:MGRE实验实验目的:掌握 PPP 协议的 PAP/CHAP 认证与 HDLC 封装配置,理解不同广域网链路协议的工作机制与认证流程。实现 MGRE 环境(R1 为 Hub)与 GRE 环境的部署,理解点到多点 VPN 与点…...

通用大模型vs行业垂直AI Agent,制造业落地对比:2026年企业级智能体选型深度解析
进入2026年,人工智能在制造业的落地已从早期的“对话式交互”全面转向“任务式闭环”。通用大模型(Foundation Models)与行业垂直AI Agent(Vertical AI Agents)在工业场景中的角色分工日益明确。根据IDC最新发布的《20…...

3步掌握SubtitleOCR:从视频到可编辑字幕的智能转换指南
3步掌握SubtitleOCR:从视频到可编辑字幕的智能转换指南 【免费下载链接】SubtitleOCR 快如闪电的硬字幕提取工具。仅需苹果M1芯片或英伟达3060显卡即可达到10倍速提取。A very fast tool for video hardcode subtitle extraction 项目地址: https://gitcode.com/g…...

天气图片分类模型:基于迁移学习与GPU资源优化
天气图片分类模型:基于迁移学习与GPU资源优化 1. 引言 天气识别在自动驾驶、户外监控、气象服务等领域具有重要应用价值。传统方法依赖于手工设计的特征(如纹理、颜色直方图),鲁棒性不足。深度学习尤其是卷积神经网络(CNN)能够自动从图像中学习层次化特征,显著提升分类…...

GTX 1660实战AI视频生成:低显存环境下的模型瘦身与帧插值方案
1. 项目概述:在入门级显卡上跑通AI视频生成最近看到不少朋友对AI视频生成很感兴趣,但总被“需要RTX 4090”、“至少24GB显存”这类硬件门槛劝退。作为一个常年混迹于“丐版”硬件圈的老玩家,我决定用我手头这块服役多年的GTX 1660(…...

3分钟搞定浏览器二维码:Chrome QRCode插件的终极使用秘籍
3分钟搞定浏览器二维码:Chrome QRCode插件的终极使用秘籍 【免费下载链接】chrome-qrcode :zap: A Chrome plugin to Genrate QRCode of URL / Text, or Decode the QRcode in website. 一个Chrome浏览器插件,用于生成当前URL或者选中内容的二维码&#…...

家庭影院系统构建指南:从流媒体技术到硬件选型
1. 疫情下的娱乐变局:从影院到客厅的深度迁移作为一名长期关注消费电子与家庭娱乐领域的从业者,我亲历了过去几年行业最剧烈的震荡。疫情像一只无形的手,强行按下了社会运行的暂停键,却又为另一个赛道按下了加速键。当电影院的大门…...