「PaddleOCR」 模型应用优化流程
PaddleOCR 算是OCR算法里面较好用的,支持的内容多,而且社区维护的好(手把手教你,生怕你学不会),因此在国内常采用。目前已经更新到 2.8版本了,功能更加丰富、强大;目前支持通用OCR、表格识别、图片信息提取以及文档场景信息提取,基本覆盖了常用的场景
首先下载模型代码 https://github.com/PaddlePaddle/PaddleOCR
需要视频课程的可以看 https://aistudio.baidu.com/education/group/info/25207
参考资料:https://github.com/PaddlePaddle/PaddleOCR/blob/main/doc/doc_ch/models_list.md


1、安装环境
首先PaddleOCR处理模型训练需要环境,数据打标工具PPOCRLabel也需要配置,因此一并配置好 conda 环境 paddle_ocr
创建conda环境 paddle_ocr,可以参考 doc/doc_ch/environment.md、installation.md 文件
# 推荐环境:
PaddlePaddle >= 2.1.2
Python 3.7
CUDA10.1 / CUDA10.2
CUDNN 7.6# 常规创建 conda环境
conda create -n paddle_ocr python=3.7 # python 版本可自定义*# 使用清华源加速下载
conda create --name paddle_ocr python=3.8 --channel https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/# 激活paddle_ocr环境
conda activate paddle_ocr# 安装paddle等库
pip3 install --upgrade pip#如果您的机器安装的是CUDA9或CUDA10,请运行以下命令安装
python3 -m pip install paddlepaddle-gpu==2.0.0 -i https://mirror.baidu.com/pypi/simple#如果您的机器是CPU,请运行以下命令安装
python3 -m pip install paddlepaddle==2.0.0 -i https://mirror.baidu.com/pypi/simple更多的版本需求,请参照[安装文档](https://www.paddlepaddle.org.cn/install/quick)中的说明进行操作。# 安装标注软件 PPOCRLabel
pip install PPOCRLabel
2、数据标注
最新版的PaddleOCR内部不再包含PPOCRLabel,可以参考 https://github.com/ViatorSun/PPOCRLabel
将conda环境切换成 paddle_ocr,然后在终端输入 PPOCRLabel --lang ch 即可启动 PPOCRLabel 标注工具, --lang 设置界面语言(默认英文,仅支持中英文,中文ch、英文en),如下图所示
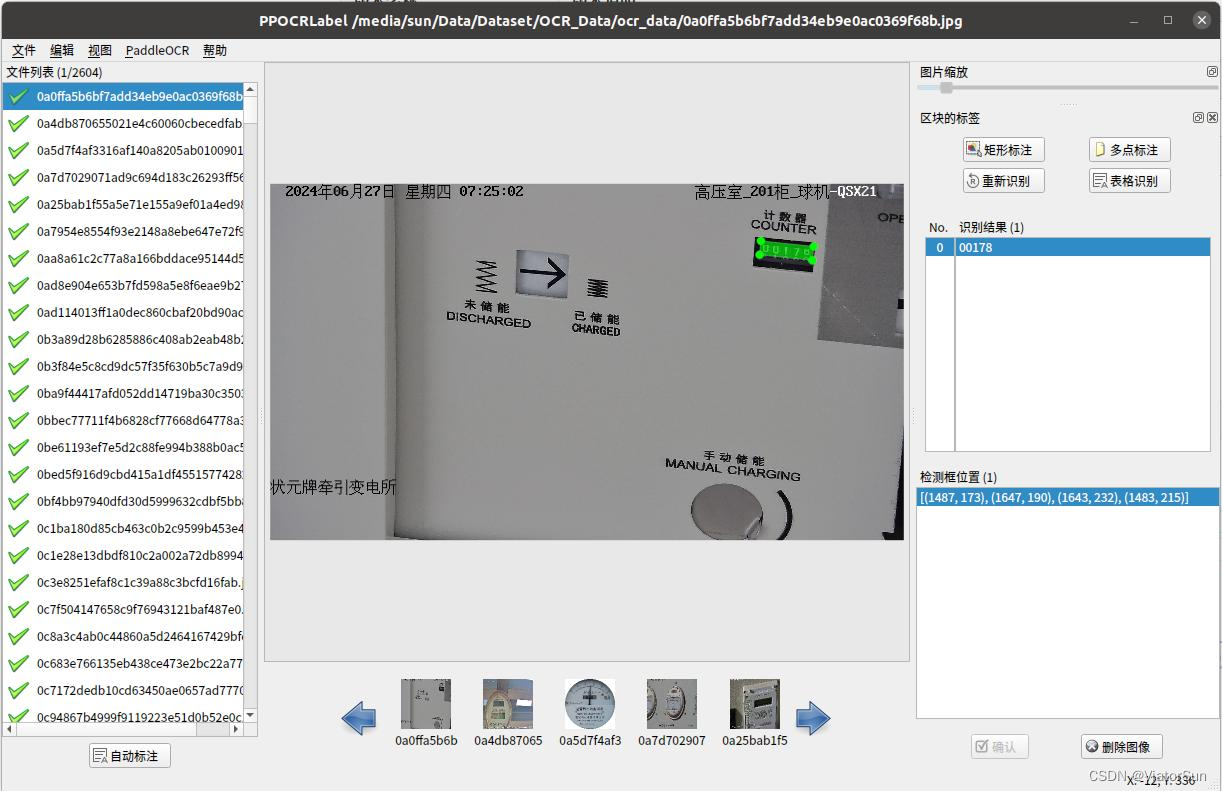
- PPOCRLabel 支持预标注,选择 PaddleOCR -> 选择模型,可以选择待识别文字的语言,如中英文、英文、法语等;
- 左下角的自动标注可以帮助将图片中的文字用 PaddleOCR模型检测并标注下,预标注的效果一般比较差,但是可以节省拉框的时间,还是有一定作用的
- 标注过程中会有几个txt文件用于保存数据,Cache.cach 用于保存预标注数据,fileState.txt记录图片标注状态,Label.txt 为导出的标记结果,rec_gt.txt 和 crop_img 为导出的识别结果,
# 修改 fileState.txt 文件,免去一张一张确认
import os
import os.path as ospshuffixes = [".jpg", ".jpeg", ".png"]
file_path = "/media/sun/Data/Dataset/OCR_Data/ocr_data"if osp.exists(file_path):with open(osp.join(file_path,"fileState.txt"), "w", encoding="utf-8") as f:for file in os.listdir(file_path):if osp.splitext(file)[-1].lower() in shuffixes:img_dir = osp.join(file_path, file)f.write(img_dir + "\t1\n")print(f"save {img_dir} \t1")
对于预标注的内容,未必全部适合项目需求,因此可以通过正则化将预标注内容筛选,降低手动删除目标框的低效
import re
import json
import os.path as ospLabel_dir = "/media/sun/DataYZ/DataSet/led_Digital/Label.txt"label_lst = []
if osp.exists(Label_dir):with open(Label_dir, "r", encoding="utf-8") as f:for line in f.readlines():print(line)save_data = []data_list = json.loads(line.split('\t')[-1].replace('\n', ''))for data in data_list:if bool(re.match(r'^[0-9.]+$', data["transcription"])): # 只保留数字和小数点 的识别结果save_data.append(data)save_label = line.split('\t')[0] + '\t' + str(save_data) + '\n'label_lst.append(save_label)# 重写
with open(Label_dir, "w", encoding="utf-8") as f:for data in label_lst:f.write(data)
注意
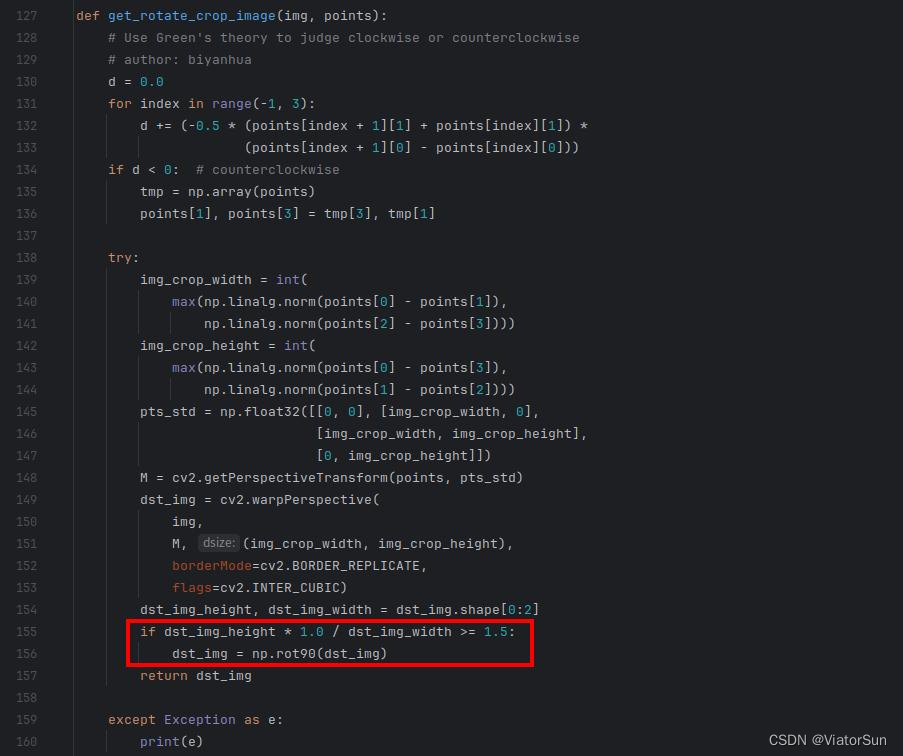
发现标注工具有一个隐藏小问题(谈不上bug),可能跟后续的识别有关
当标注框的高与宽的比例大于 1.5则进行 90度旋转(默认顺时针旋转),如果想避免这种情况将红框两行代码注释掉就可以了
标注完所有的数据之后,需要划分数据集,可以采用PaddeOCR/PPOCRLabel/gen_ocr_train_val_test.py 脚本进行处理,–trainValTestRatio 设置三个数据集的比例,–datasetRootPath设置标注好的数据集路径,–detRootPath 生成的检测数据集路径,–recRootPath 生成识别数据集路径 即可。注意,标注文件中的框只能是四个点坐标,过多过少都会无法识别
至此,数据处理完成
3、模型训练
PaddleOCR 识别分为两个过程,目标区域的检测 det 以及 对目标区域的内容识别 rec
训练脚本如下,配置好 yaml 文件,即可直接训练,此处的 data/ 路径是博主自己创建的,避免与官方提供的 config/ 下的yaml 文件冲突,可将需要的 config/*.yaml 拷贝到 ./data 路径下
import os# detect 模型检测
command = "python3 tools/train.py -c data/det_r50_vd_db.yml"
print(command)
os.system(command)# rec 模型识别
command = "python tools/train.py -c data/ch_PP-OCRv3_rec.yml"
print(command)
os.system(command)
det.yaml 文件与 rec.yaml 几乎一致
其中 rec.yml 的 save_model_dir 为模型训练保存路径;pretrained_model 为预训练模型权重;save_inference_dir 为模型导出时的输出路径;character_dict_path 为字符词典路径;其余的就是 Train & Eval 数据集的路径需要修改;
在生成的 模型训练保存路径中,有 train.log 、config.yaml 、best_model 和其他中间epoch 权重

导出推理模型
训练过程中保存的模型权重
path.pdopt:优化器状态
path.states:训练中间信息
path.pdparams:保存的模型的参数

导出的推理模型格式为 inference.pdmodel、inference.pdiparams,其中 Global.save_inference_dir 不需要重复设置 *yaml 文件中已经包含了,如果 *.yaml 中已经设置过了,模型转换就无需再赋值,当然赋值了会以重新赋值的参数运行
注意!
此处有一点需要注意的就是Global.pretrained_model必须从新赋值,因为 *yaml 文件中的 pretrained_model 为训练时的预训练权重,此处为待导出的模型权重路径;
还有就是权重路径是./runs/20240703/det_r50_vd/best_model/model.pdopt/pdparams省去后缀的路径,而不是文件夹的路径,因此必须填写到权重名
import os# det
os.system(f"python tools/export_model.py "f"-c data/det_r50_vd_db.yml "f"-o Global.pretrained_model=./runs/20240703/det_r50_vd/best_model/model " # 待转化权重f"Global.load_static_weights=False "# f"Global.save_inference_dir=./inference/20240704/db_r50/ ")# ocr
os.system(f"python3 tools/export_model.py "f"-c data/ch_PP-OCRv3_rec.yml "f"-o Global.pretrained_model=./runs/20240703/rec_ppocr/best_model/model ") # 待转化权重# f"Global.save_inference_dir=./inference/20240704/rec_ppocr/ ")
模型推理
最后是模型推理,此处可以使用如下脚本预测,生成的结果在 inference_results 路径下
import os
import os.path as ospif __name__ == '__main__':img_path = "./test"det_model_dir = "./inference/20240710/det_infer"rec_model_dir = "./inference/20240710/rec_infer"for i, file in enumerate(os.listdir(img_path)):img = osp.join(img_path, file)command = f"python3 tools/infer/predict_system.py --image_dir={img} --det_model_dir={det_model_dir} --rec_model_dir={rec_model_dir} --use_angle_cls=false"print(command)os.system(command)

相关文章:
「PaddleOCR」 模型应用优化流程
PaddleOCR 算是OCR算法里面较好用的,支持的内容多,而且社区维护的好(手把手教你,生怕你学不会),因此在国内常采用。目前已经更新到 2.8版本了,功能更加丰富、强大;目前支持通用OCR、表格识别、图片信息提取…...

VUE2 子组件传多个参数,父组件函数接收所有入参并加自定义参数
需求中有个场景是需要在子组件中传多个参数,让父组件接收所有入参,并且父组件也要加自己的参数 1.子组件传多个参数给父组件 子组件 // 子组件 ChildComponent.vue <template><button click"sendDataToParent">传递数据给父组件…...

less和sass有啥区别哪个更加好
Less 和 Sass(特别是其最流行的变体 SCSS)都是 CSS 预处理器,它们扩展了 CSS 的功能,如变量、嵌套规则、混合(Mixins)、函数等,以编程方式生成 CSS。它们之间的主要区别在于语法、功能和工具生态…...

Qt Design Studio 4.5现已发布
Qt Design Studio现已强势回归,生产力和可用性均得到大幅提升。无论是直观的3D编辑界面,还是与Figma和Qt Creator的无缝连接,新版Qt Design Studio将为您带来更好的产品开发体验。快来深入了解Qt Design Studio的全新功能吧! 为3…...

GCN-LSTM实现时空预测
简介:现有的预测模型越来考虑时间和空间的相关性,统称为时空预测。这种预测模型往往比简单的序列模型(例如RNN、LSTM、GRU及其变体)、Transformer等效果更好。我使用Keras实现了该GCN-LSTM代码,因为Keras相比于torch更容易入手和理解。我实现了一个基于Keras的GCN网络层,…...

《算法笔记》总结No.6——贪心
一.简单贪心 贪心法是求解一类最优化问题的方法,它总是考虑在当前状态下局部最优(或较优)之后,来使全局的结果达到最优(或较优)的策略。显然,如果采取较优而非最优的策略(最优策略可能不存在或是不易想到),得到的全局结果也无法是…...
久期分析与久期模型
目录 一、久期分析的理论原理 二、数据准备 三、Stata 程序代码及解释 四、代码运行结果 一、久期分析的理论原理 久期(Duration)是衡量债券价格对利率变动敏感性的重要指标。它不仅仅是一个简单的时间概念,更是反映了债券现金流回收的平均…...

MybatisPlus 使用教程
MyBatisPlus使用教程 文章目录 MyBatisPlus使用教程1、使用方式1.1 引入依赖1.2 构建mapper接口 2、常用注解2.1 TableName2.2 TableId2.3 TableField MyBatisPlus顾名思义便是对MyBatis的加强版,但两者本身并不冲突(只做增强不做改变): 引入它并不会对原…...

bash: redi-cli: 未找到命令...
问题描述 在执行命令:redi-cli --bigkeys 提示:bash: redi-cli: 未找到命令... 确定服务器是否有Redis进程 ps -ef | grep redis查找Redis 文件信息 find / -name "redis-*"进入到当前目录 cd /usr/bin/再次执行命令 涉及redis-cli 连…...

linux 内核 红黑树接口说明
红黑树(rbtree)在linux内核中使用非常广泛,cfs调度任务管理,vma管理等。本文不会涉及关于红黑树插入和删除时的各种case的详细描述,感兴趣的读者可以查阅其他资料。本文主要聚焦于linux内核中经典rbtree和augment-rbtree操作接口的说明。 1、基本概念 二叉树:每个…...

【ELK】filebeat 和logstash区别
Filebeat 和 Logstash 都是 Elastic Stack (也称为 ELK Stack) 的重要组件,用于日志数据的收集、处理和传输。它们有不同的功能和使用场景: Filebeat 角色: 轻量级日志收集器。功能: 从指定的日志文件中读取日志数据。可以从多个源(如文件、…...

CNN -1 神经网络-概述
CNN -1 神经网络-概述 一:芯片科技发展介绍了解1> 芯片科技发展趋势2> 芯片使用领域3> 芯片介绍1. 神经网络芯片2. 神经网络处理单元NPU(Neural Processing Unit)二:神经网络1> 什么是神经网络2> 神经元3> 人工神经网络三:卷积神经网络(CNN)入门讲解一…...

插片式远程IO模块:Profinet总线耦合器在STEP7配置
XD9000是Profinet总线耦合器,单个耦合器最多可扩展32个I/O模块!本文将深入探讨插片式远程IO模块的应用,并揭秘Profinet总线耦合器在STEP7配置过程中的技巧与注意事项。 STEP7-MicroWINSMART软件组态步骤: 1、按照下图指示安装GSD…...

python3读取shp数据
目录 1 介绍 1 介绍 需要tmp.shp文件和tmp.dbf文件,需要安装geopandas第三方库,python3代码如下, import geopandas as gpdshp_file_path "tmp.shp" shp_data gpd.read_file(shp_file_path) for index, row in shp_data.iterro…...

pytorch实现水果2分类(蓝莓,苹果)
1.数据集的路径,结构 dataset.py 目的: 输入:没有输入,路径是写死了的。 输出:返回的是一个对象,里面有self.data。self.data是一个列表,里面是(图片路径.jpg,标签&…...

Redis实践经验
优雅的Key结构 Key实践约定: 遵循基本格式:[业务名称]:[数据名]:id例:login:user:10长度步超过44字节(版本不同,上限不同)不包含特殊字符 优点: 可读性强避免key冲突方便管理节省内存&#x…...

分类题解清单
目录 简介MySQL题一、聚合函数二、排序和分组三、高级查询和连接四、子查询五、高级字符串函数 / 正则表达式 / 子句 算法题一、双指针二、滑动窗口三、模拟四、贪心五、矩阵六、排序七、链表八、设计九、前缀和十、哈希表十一、字符串十二、二叉树十三、二分查找十四、回溯十五…...

QUdpSocket 的bind函数详解
QUdpSocket 是 Qt 框架中用于处理 UDP 网络通信的类。bind 函数是此类中的一个重要方法,它用于将 QUdpSocket 对象绑定到一个特定的端口上,以便在该端口上接收 UDP 数据包。 函数原型 在 Qt 中,bind 函数的原型通常如下所示: b…...
[spring] Spring MVC - security(下)
[spring] Spring MVC - security(下) callback 一下,当前项目结构如下: 这里实现的功能是连接数据库,大范围和 [spring] rest api security 重合 数据库连接 - 明文密码 第一部分使用明文密码 设置数据库 主要就是…...

数据库数据恢复—SQL Server数据库由于存放空间不足报错的数据恢复案例
SQL Server数据库数据恢复环境: 某品牌服务器存储中有两组raid5磁盘阵列。操作系统层面跑着SQL Server数据库,SQL Server数据库存放在D盘分区中。 SQL Server数据库故障: 存放SQL Server数据库的D盘分区容量不足,管理员在E盘中生…...
)
解密冰蝎和蚁剑:在CTF流量分析中如何识别和还原WebShell攻击(含AES/Base64解密实操)
解密冰蝎与蚁剑:CTF流量分析中的WebShell识别与解密实战 在CTF竞赛和安全分析领域,WebShell流量分析一直是让许多选手头疼的高阶挑战。特别是当面对冰蝎(Behinder)、蚁剑(AntSword)这类采用强加密通信的Web…...
的3D视觉原理与应用)
从‘看见’到‘看懂’:手把手拆解RGB-D摄像头(如Intel Realsense)的3D视觉原理与应用
从‘看见’到‘看懂’:手把手拆解RGB-D摄像头的3D视觉原理与应用 当你第一次看到RGB-D摄像头生成的彩色点云在屏幕上旋转时,那种将现实世界数字化的震撼感令人难忘。但真正让这种设备发挥价值的,是理解它如何将光信号转化为三维坐标的完整技术…...

基于Adafruit CRICKIT与3D打印的水面机器人DIY全攻略
1. 项目概述:打造你的第一艘智能水面机器人 如果你对机器人、水上航行或者水下摄影感兴趣,但又觉得从零开始设计电路和结构太复杂,那么这个项目就是为你准备的。今天,我想分享一个我最近完成的、非常有趣且实用的创客项目&#x…...

初探Taotoken模型广场如何帮助开发者快速选型与切换模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初探Taotoken模型广场如何帮助开发者快速选型与切换模型 当开发者开始一个新的大模型应用项目时,面对市场上众多的模型…...

ME_PURCHDOC_POSTED
创建采购订单时常用的保存增强ME_PROCESS_PO_CUST~POST里是没有订单号的可以使用ME_PURCHDOC_POSTED来做相关处理...

在Node.js后端服务中集成Taotoken实现稳定高效的多模型调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Node.js后端服务中集成Taotoken实现稳定高效的多模型调用 对于需要构建AI功能的后端开发者而言,直接对接多个模型厂商…...

泉州某卫浴GEO优化实战:四标融合+场景化方法论,从搜索不可见到AI优先引用
我们在服务制造业企业的过程中发现一个根本性变化:过去大家关心“怎么让用户搜到我”,现在AI直接生成答案,企业真正的挑战变成了“怎么让AI准确信任我、优先引用我”。传统SEO在AI的“黑箱”面前越来越失效,企业必须重新建立一套可…...

ContextMenuManager:5分钟掌握Windows右键菜单管理的终极免费方案
ContextMenuManager:5分钟掌握Windows右键菜单管理的终极免费方案 【免费下载链接】ContextMenuManager 🖱️ 纯粹的Windows右键菜单管理程序 项目地址: https://gitcode.com/gh_mirrors/co/ContextMenuManager 你是否厌倦了每次右键点击文件时&a…...

VS Code CircuitPython扩展实战:嵌入式开发环境搭建与高效调试指南
1. 项目概述:为什么选择 VS Code CircuitPython 扩展?如果你正在玩像 Adafruit Feather、Raspberry Pi Pico 或者 ESP32-S3 这类支持 CircuitPython 的开发板,你可能已经习惯了在CIRCUITPY这个神奇的U盘里直接编辑code.py文件。这种方式简单…...

LPC18xx/LPC43xx USB0接口低速设备识别问题解决方案
1. 问题现象与背景分析在嵌入式开发领域,NXP LPC1800和LPC4300系列微控制器因其强大的USB主机功能而被广泛应用。但在实际项目中,工程师们发现一个奇怪现象:当某些特定型号的DELL键盘(USB低速设备)连接到LPC18xx/LPC43…...