机器学习库实战:DL4J与Weka在Java中的应用
机器学习是当今技术领域的热门话题,而Java作为一门广泛使用的编程语言,也有许多强大的机器学习库可供选择。本文将深入探讨两个流行的Java机器学习库:Deeplearning4j(DL4J)和Weka,并通过详细的代码示例帮助新手理解它们的实战应用。
1. Deeplearning4j(DL4J)简介
Deeplearning4j(DL4J)是一个用于Java和JVM的开源深度学习库,它支持各种神经网络架构,包括卷积神经网络(CNN)、循环神经网络(RNN)和长短期记忆网络(LSTM)。DL4J旨在与Hadoop和Spark等大数据技术无缝集成。
1.1 安装与配置
首先,我们需要在项目中添加DL4J的依赖。如果你使用的是Maven,可以在pom.xml文件中添加以下依赖:
<dependencies><dependency><groupId>org.deeplearning4j</groupId><artifactId>deeplearning4j-core</artifactId><version>1.0.0-beta7</version></dependency><dependency><groupId>org.nd4j</groupId><artifactId>nd4j-native-platform</artifactId><version>1.0.0-beta7</version></dependency>
</dependencies>
1.2 构建一个简单的神经网络
接下来,我们将构建一个简单的多层感知器(MLP)神经网络来解决分类问题。以下是一个完整的代码示例:
import org.deeplearning4j.nn.api.OptimizationAlgorithm;
import org.deeplearning4j.nn.conf.NeuralNetConfiguration;
import org.deeplearning4j.nn.conf.layers.DenseLayer;
import org.deeplearning4j.nn.conf.layers.OutputLayer;
import org.deeplearning4j.nn.weights.WeightInit;
import org.nd4j.linalg.activations.Activation;
import org.nd4j.linalg.learning.config.Nesterovs;
import org.nd4j.linalg.lossfunctions.LossFunctions;public class SimpleMLP {public static void main(String[] args) {int numInputs = 2;int numOutputs = 2;int numHiddenNodes = 20;NeuralNetConfiguration.ListBuilder builder = new NeuralNetConfiguration.Builder().seed(123).optimizationAlgo(OptimizationAlgorithm.STOCHASTIC_GRADIENT_DESCENT).updater(new Nesterovs(0.1, 0.9)).list();builder.layer(0, new DenseLayer.Builder().nIn(numInputs).nOut(numHiddenNodes).activation(Activation.RELU).weightInit(WeightInit.XAVIER).build());builder.layer(1, new OutputLayer.Builder(LossFunctions.LossFunction.NEGATIVELOGLIKELIHOOD).nIn(numHiddenNodes).nOut(numOutputs).activation(Activation.SOFTMAX).weightInit(WeightInit.XAVIER).build());builder.build();}
}
1.3 训练与评估
为了训练和评估模型,我们需要加载数据并进行预处理。以下是一个简化的示例:
import org.deeplearning4j.datasets.iterator.impl.ListDataSetIterator;
import org.deeplearning4j.nn.multilayer.MultiLayerNetwork;
import org.deeplearning4j.optimize.listeners.ScoreIterationListener;
import org.nd4j.linalg.dataset.api.iterator.DataSetIterator;
import org.nd4j.linalg.dataset.api.preprocessor.DataNormalization;
import org.nd4j.linalg.dataset.api.preprocessor.NormalizerStandardize;
import org.nd4j.linalg.factory.Nd4j;public class SimpleMLP {public static void main(String[] args) {// 构建网络配置NeuralNetConfiguration.ListBuilder builder = ...;MultiLayerNetwork network = new MultiLayerNetwork(builder.build());network.init();network.setListeners(new ScoreIterationListener(10));// 加载数据DataSetIterator iterator = new ListDataSetIterator<>(...);// 数据预处理DataNormalization normalizer = new NormalizerStandardize();normalizer.fit(iterator);iterator.setPreProcessor(normalizer);// 训练模型for (int i = 0; i < numEpochs; i++) {network.fit(iterator);iterator.reset();}// 评估模型Evaluation eval = network.evaluate(iterator);System.out.println(eval.stats());}
}
2. Weka简介
Weka(Waikato Environment for Knowledge Analysis)是一个用于数据挖掘任务的机器学习库,它提供了大量的算法和工具来处理数据预处理、分类、回归、聚类和关联规则挖掘等任务。
2.1 安装与配置
Weka可以通过其官方网站下载,也可以通过Maven依赖添加到项目中。以下是Maven依赖配置:
<dependencies><dependency><groupId>nz.ac.waikato.cms.weka</groupId><artifactId>weka-stable</artifactId><version>3.8.0</version></dependency>
</dependencies>
2.2 使用Weka进行分类
以下是一个使用Weka进行分类任务的示例:
import weka.classifiers.Classifier;
import weka.classifiers.Evaluation;
import weka.classifiers.functions.Logistic;
import weka.core.Instances;
import weka.core.converters.ConverterUtils.DataSource;public class WekaClassifierExample {public static void main(String[] args) throws Exception {// 加载数据DataSource source = new DataSource("path/to/your/data.arff");Instances data = source.getDataSet();data.setClassIndex(data.numAttributes() - 1);// 构建分类器Classifier classifier = new Logistic();classifier.buildClassifier(data);// 评估分类器Evaluation eval = new Evaluation(data);eval.crossValidateModel(classifier, data, 10, new Random(1));// 输出结果System.out.println(eval.toSummaryString("\nResults\n======\n", false));}
}
2.3 使用Weka进行聚类
以下是一个使用Weka进行聚类任务的示例:
import weka.clusterers.ClusterEvaluation;
import weka.clusterers.SimpleKMeans;
import weka.core.Instances;
import weka.core.converters.ConverterUtils.DataSource;public class WekaClusteringExample {public static void main(String[] args) throws Exception {// 加载数据DataSource source = new DataSource("path/to/your/data.arff");Instances data = source.getDataSet();// 构建聚类器SimpleKMeans kMeans = new SimpleKMeans();kMeans.setNumClusters(3);kMeans.buildClusterer(data);// 评估聚类器ClusterEvaluation eval = new ClusterEvaluation();eval.setClusterer(kMeans);eval.evaluateClusterer(data);// 输出结果System.out.println(eval.clusterResultsToString());}
}
3. 总结
本文详细介绍了Deeplearning4j(DL4J)和Weka这两个强大的Java机器学习库,并通过代码示例展示了它们在分类和聚类任务中的应用。无论是深度学习还是传统的机器学习任务,DL4J和Weka都提供了丰富的功能和灵活的接口,可以满足不同场景的需求。
相关文章:

机器学习库实战:DL4J与Weka在Java中的应用
机器学习是当今技术领域的热门话题,而Java作为一门广泛使用的编程语言,也有许多强大的机器学习库可供选择。本文将深入探讨两个流行的Java机器学习库:Deeplearning4j(DL4J)和Weka,并通过详细的代码示例帮助…...

MongoDB教程(一):Linux系统安装mongoDB详细教程
💝💝💝首先,欢迎各位来到我的博客,很高兴能够在这里和您见面!希望您在这里不仅可以有所收获,同时也能感受到一份轻松欢乐的氛围,祝你生活愉快! 文章目录 引言一、Ubuntu…...

leetcode74. 搜索二维矩阵
给你一个满足下述两条属性的 m x n 整数矩阵: 每行中的整数从左到右按非严格递增顺序排列。每行的第一个整数大于前一行的最后一个整数。 给你一个整数 target ,如果 target 在矩阵中,返回 true ;否则,返回 false 。…...

Redis 布隆过滤器性能对比分析
redis 实现布隆过滤器实现方法: 1、redis 的 setbit 和 getbit 特点:对于某个bit 设置0或1,对于大量的值需要存储,非常节省空间,查询速度极快,但是不能查询整个key所有的bit,在一次请求有大量…...

Java List不同实现类的对比
List不同实现类的对比 文章目录 List不同实现类的对比实现类之一ArrayList实现类之二 LinkedList实现类之三 Vector练习 java.util.Collection用于存储一个一个数据的框架子接口:List存储有序的、可重复的数据(相当于动态数组) ArrayList lis…...

【C语言】 —— 预处理详解(下)
【C语言】 —— 预处理详解(下) 前言七、# 和 \##7.1 # 运算符7.2 ## 运算符 八、命名约定九、# u n d e f undef undef十、命令行定义十一、条件编译11.1、单分支的条件编译11.2、多分支的条件编译11.3、判断是否被定义11.4、嵌套指令 十二、头文件的包…...

Jupyter Notebook简介
Jupyter Notebook是一个开源的Web应用程序,允许你创建和共享包含实时代码、方程、可视化和解释性文本的文档。它广泛用于数据清理和转换、数值模拟、统计建模、机器学习等领域。 Jupyter Notebook的优势包括: 1. **交互式计算**:可以在网页…...

ChatGPT 5.0:一年后的猜想
对于ChatGPT 5.0在未来一年半后的展望与看法,我们可以从以下几个方面进行详细探讨: 一、技术提升与功能拓展 语言翻译能力: ChatGPT 5.0在语言翻译方面有望实现更大突破。据推测,新版本将利用更先进的自然语言处理技术和深度学习…...
Java套红:指定位置合并文档-NiceXWPFDocument
需求:做个公文系统,需要将正文文档在某个节点点击套红按钮,实现文档套红 试了很多方法,大多数网上能查到但是实际代码不能找到关键方法,可能是跟包的版本有关系,下面记录能用的这个。 一:添加依…...

【操作系统】进程管理——进程的同步与互斥(个人笔记)
学习日期:2024.7.8 内容摘要:进程同步/互斥的概念和意义,基于软/硬件的实现方法 进程同步与互斥的概念和意义 为什么要有进程同步机制? 回顾:在《进程管理》第一章中,我们学习了进程具有异步性的特征&am…...

Qt:13.多元素控件(QLinstWidget-用于显示项目列表的窗口部件、QTableWidget- 用于显示二维数据表)
目录 一、QLinstWidget-用于显示项目列表的窗口部件: 1.1QLinstWidget介绍: 1.2属性介绍: 1.3常用方法介绍: 1.4信号介绍: 1.5实例演示: 二、QTableWidget- 用于显示二维数据表: 2.1QTabl…...

恢复出厂设置手机变成砖
上周,许多Google Pixel 6(6、6a、6 Pro)手机用户在恢复出厂设置后都面临着设备冻结的问题。 用户说他们在下载过程中遇到了丢失 tune2fs 文件的错误 。 这会导致屏幕显示以下消息:“Android 系统无法启动。您的数据可能会被损坏…...

解决IntelliJ IDEA中克隆GitHub项目不显示目录结构的问题
前言 当您从GitHub等代码托管平台克隆项目到IntelliJ IDEA,却遇到项目目录结构未能正确加载的情况时,不必太过困扰,本文将为您提供一系列解决方案,帮助您快速找回丢失的目录视图。 1. 调整Project View设置 操作步骤࿱…...

Git错误分析
错误案例1: 原因:TortoiseGit多次安装导致,会记录首次安装路径,若安装路径改变,需要配置最后安装的路径。...

pom.xml中重要标签介绍
在 Maven 项目中,pom.xml 文件是项目对象模型(POM)的配置文件,它定义了项目的依赖关系、插件、构建配置等。以下是 pom.xml 文件中一些重要的标签及其作用: <modelVersion>: 定义 POM 模型的版本。当…...

大模型日报 2024-07-11
大模型日报 2024-07-11 大模型资讯 CVPR世界第二仅次Nature!谷歌2024学术指标出炉,NeurIPS、ICLR跻身前十 谷歌2024学术指标公布,CVPR位居第二,超越Science仅次于Nature。CVPR、NeurIPS、ICLR三大顶会跻身TOP 10。 CVPR成全球第二…...
Redis基础教程(十六):Redis Stream
💝💝💝首先,欢迎各位来到我的博客,很高兴能够在这里和您见面!希望您在这里不仅可以有所收获,同时也能感受到一份轻松欢乐的氛围,祝你生活愉快! 💝Ὁ…...
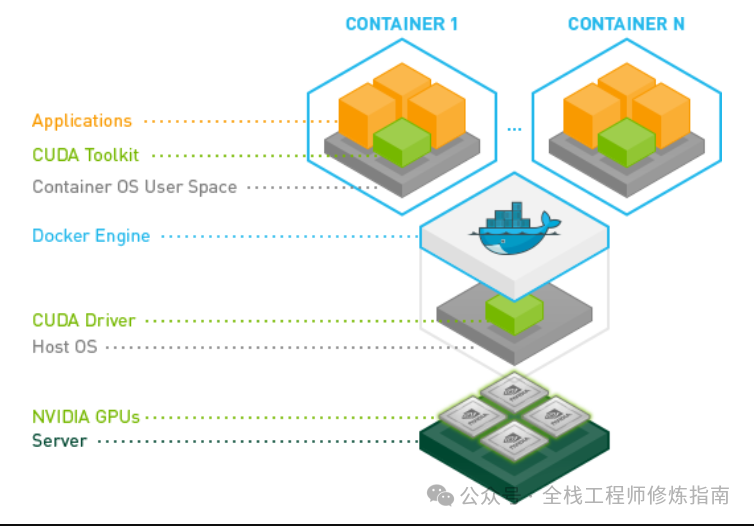
机器学习筑基篇,容器调用显卡计算资源,Ubuntu 24.04 快速安装 NVIDIA Container Toolkit!...
[ 知识是人生的灯塔,只有不断学习,才能照亮前行的道路 ] Ubuntu 24.04 安装 NVIDIA Container Toolkit 什么是 NVIDIA Container Toolkit? 描述:NVIDIA Container Toolkit(容器工具包)使用户能够构建和运行 GPU 加速的容器,该工具包括一个容器运行时库和实用程序,用于自动…...

全网第一个java链接阿里云redis并可操作
添加依赖 redis.clients jedis 5.1.2 然后通过 JedisPool pool new JedisPool(host3, 6379); Jedis jedis pool.getResource(); jedis.auth(“username”,“password”); jedis.set(“ab”,“ab”); System.out.println(jedis.get(“ab”)); 即可链接成功,成功…...

Mysql ORDER BY是否走索引?
在 MySQL 中,ORDER BY 子句是否使用索引取决于多种因素,包括查询的具体情况、索引的类型和结构、查询中的其他条件等。 使用索引的情况 单列索引和 ORDER BY: 当 ORDER BY 子句中的列有单列索引时,MySQL 可以利用该索引来加速排序…...

从失败案例看全球化内容服务的合规架构与自动化风控实践
1. 项目概述与背景解析最近在和一些做全球化内容分发或者跨国协作项目的朋友交流时,大家普遍会提到一个词:“内容合规性审查”。这听起来像是一个法务或者运营的术语,但对我们这些搞技术、做开发的人来说,它背后其实是一整套复杂的…...

5G网优路测数据分析方法:从数据采集到问题定位
路测(Drive Test)是5G网络优化最基础也是最关键的数据采集手段。本文从数据采集、分析方法、问题定位三个层面,系统讲解5G路测数据分析方法论。一、5G路测概述1.1 路测目的目的说明适用场景覆盖验证验证5G网络覆盖是否达标新站开通、优化后验…...

避坑指南:STM32F407的ADC多通道采样,你的数据顺序真的对了吗?
STM32F407多通道ADC采样数据错位排查手册 在嵌入式开发中,ADC多通道采样是常见需求,但数据顺序错乱问题却让不少工程师深夜加班。上周有位同行发来求助:他的四通道温度监测系统运行两周后,突然出现通道数据交叉污染,导…...

开源笔记Memos与AI助手Copaw集成:打造自动化知识管理工作流
1. 项目概述:当开源笔记遇上AI助手最近在折腾个人知识管理工具,发现一个挺有意思的组合:Hailpeng的copaw-memos-integration。简单来说,它把两个独立但都很棒的工具给“焊”在了一起。一边是Memos,一个极简、开源、自部…...

OpenDAN个人AI操作系统:从零构建智能体协作框架
1. 项目概述:个人AI操作系统的诞生与愿景最近在GitHub上看到一个项目,叫“OpenDAN-Personal-AI-OS”,第一眼看到这个标题,我就被吸引住了。作为一个在软件开发和AI应用领域摸爬滚打了十多年的从业者,我见过太多“AI助手…...

独立开发者如何借助Taotoken模型广场为不同任务选型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何借助Taotoken模型广场为不同任务选型 作为一名独立开发者,日常工作中常需处理多种类型的任务࿱…...

RT-Thread Nano串口控制台移植:GD32F470实现rt_kprintf打印与调试
1. 项目概述与核心目标上次我们成功把 RT-Thread Nano 内核搬到了梁山派 GD32F470 开发板上,让这块高性能的 MCU 跑起了实时任务调度。但光有内核,就像给电脑装好了操作系统却没法敲命令、看输出,调试和交互起来非常别扭。官方 Nano 包的精髓…...

QuickCut视频剪辑软件:3分钟快速上手免费视频处理神器
QuickCut视频剪辑软件:3分钟快速上手免费视频处理神器 【免费下载链接】QuickCut Your most handy video processing software 项目地址: https://gitcode.com/gh_mirrors/qu/QuickCut 还在为复杂的专业视频编辑软件头疼吗?QuickCut作为一款轻量级…...

gprMax模拟结果看不懂?手把手教你用Paraview可视化不规则地质雷达模型
gprMax模拟结果可视化实战:用Paraview解析复杂地质雷达模型 地质雷达模拟完成后,面对海量的三维数据,许多研究者常陷入"数据在手,却无从下手"的困境。特别是当模型包含不规则异常体时,传统二维切片往往难以…...

向量数据库在 AI Agent Harness Engineering 记忆模块中的关键作用
向量数据库在 AI Agent Harness Engineering 记忆模块中的关键作用 一、引言 钩子 你有没有遇到过这样的场景:花了3天时间搭了一个专属的AI学习助理Agent,刚上线的时候你告诉它“我对Python异步编程完全不熟悉,以后给我的讲解要尽量基础,不要跳过概念”,它当时答应的好好…...