spark shuffle写操作——SortShuffleWriter
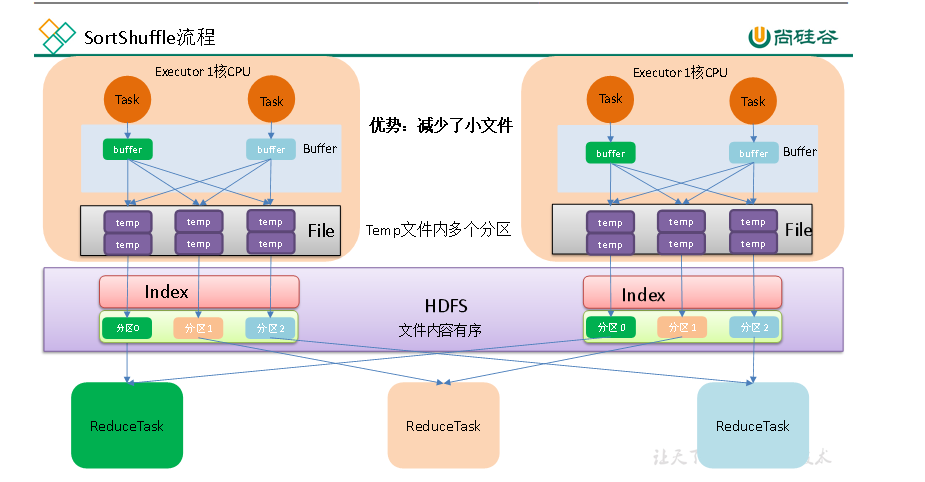
写入的简单流程:
1.生成ExternalSorter对象
2.将消息都是插入ExternalSorter对象中
3.获取到mapOutputWriter,将中间产生的临时文件合并到一个临时文件
4.生成最后的data文件和index文件
可以看到写入的重点类是ExternalSorter对象
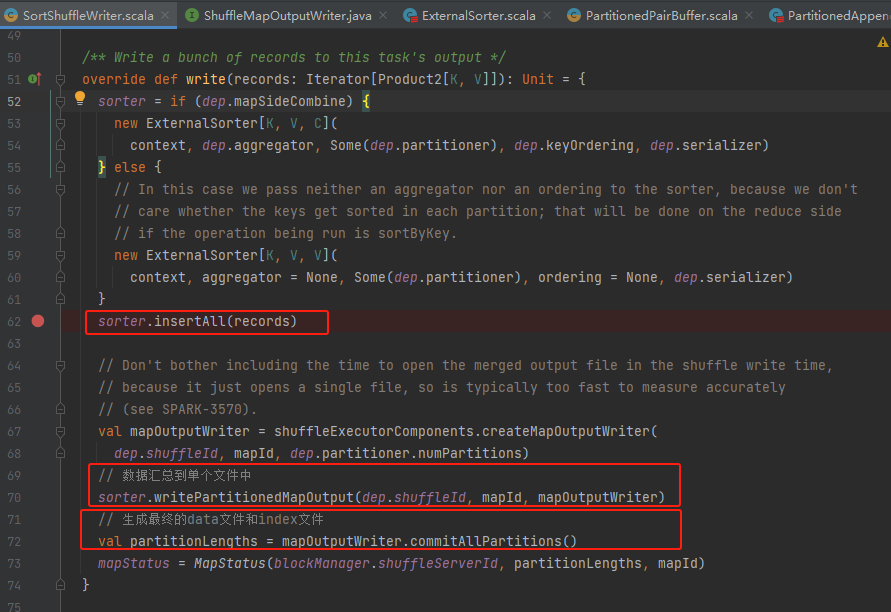
ExternalSorter
基本功能:对(k,v)进行排序,中间可能存在合并操作,最后生成(k,c)。
- 使用partitioner对key进行分区
- 在每个分区中使用Comparator进行排序
- 输出一个单独的文件,每个分区对应这个文件中的一段范围。
如果禁用了合并操作,类型C必须等于V
这个类的工作流程如下:
- 使用数据,反复填充内存缓冲区。如果是可以合并的数据,则使用PartitionedAppendOnlyMap;如果不合并,则使用PartitionedPairBuffer。在这些缓冲区中,我们首先按分区ID对元素进行排序,然后可能还会按键进行排序。为了避免对每个键多次调用分区器,我们将分区ID与每条记录一同存储。
- 当每个缓冲区达到内存限制时,会将其spill到文件中。这个文件首先按分区ID排序,如果需要做聚合操作,其次可能按键或键的哈希码排序。对于每个文件,跟踪每个分区在内存中的对象数量,因此不必为每个元素都写出分区ID。
- 当用户请求迭代器或文件输出时,溢写的文件会与任何剩余的内存数据一起被合并,使用上述定义的相同排序顺序(除非排序和聚合都被禁用)。如果需要按键进行聚合,我们或者从ordering参数中使用全序,或者读取具有相同哈希码的键并相互比较它们的相等性来合并值。
- 用户在结束时应调用stop()方法来删除所有中间文件。
缓存buffer:PartitionedAppendOnlyMap、PartitionedPairBuffer
关键方法:insertAll、maybeSpillCollection、spill、writePartitionedMapOutput

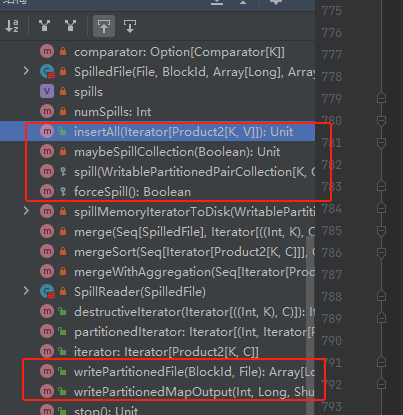
PartitionedPairBuffer
capacity 容量
curSize 当前放入的数据量
data 数组,存储的数据,(k,v)占用数组的两个位置
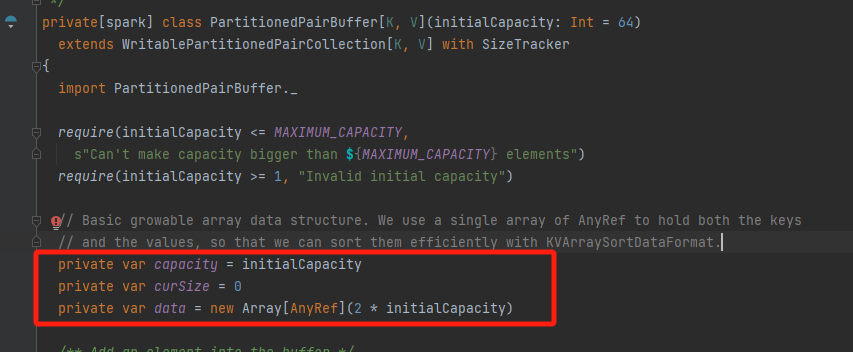
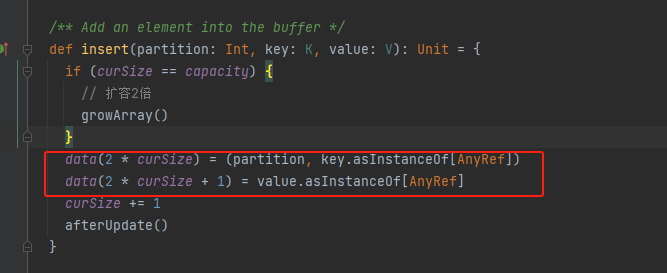
insert
如果容量达到瓶颈就进行扩容。
先存key,再存value。再调用afterUpdate
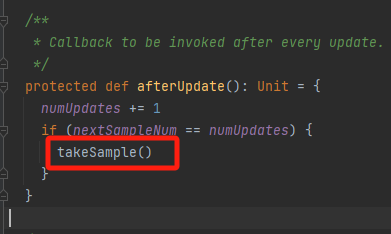
afterUpdate
numUpdates数据插入/更新次数
nextSampleNum下一次采样的次数
更新numUpdates,如果达到采样次数,执行采样takeSample
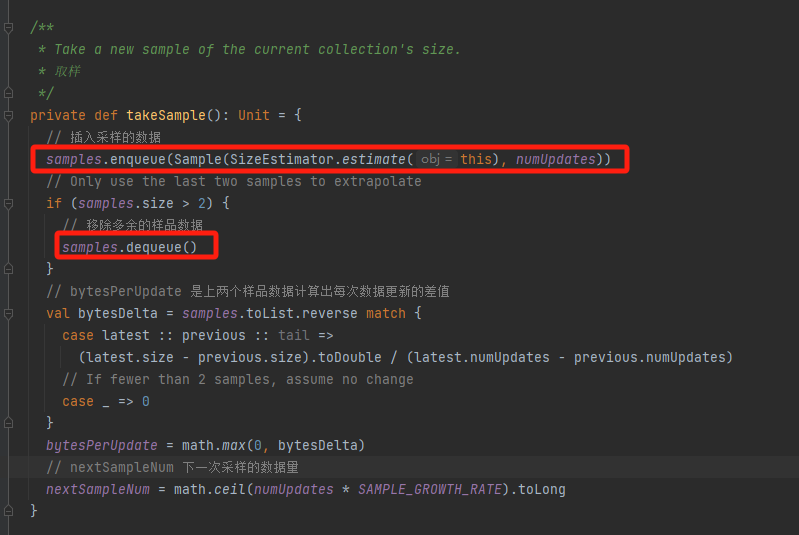
takeSample
samples中只存两个样品数据,用来计算每次更新的差值。
采样的时候要移除多余的数据。更新下一次采样的数据量。
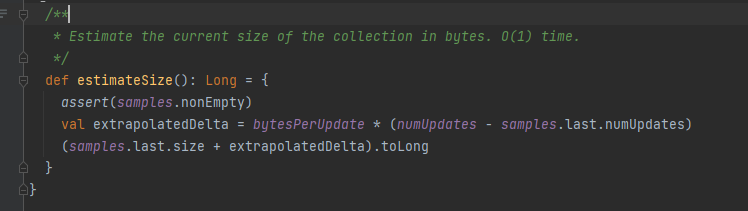
estimateSize
预估大小。
最后一个样品的lastSize+bytesPerUpdate*新增的更新次数。
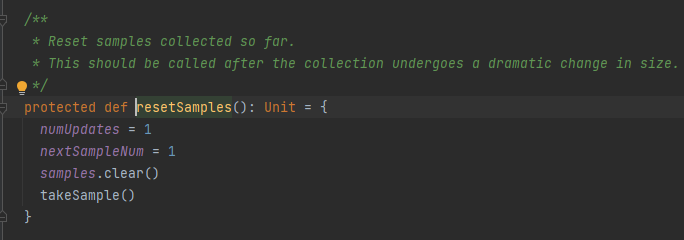
resetSamples
重新进行采样。
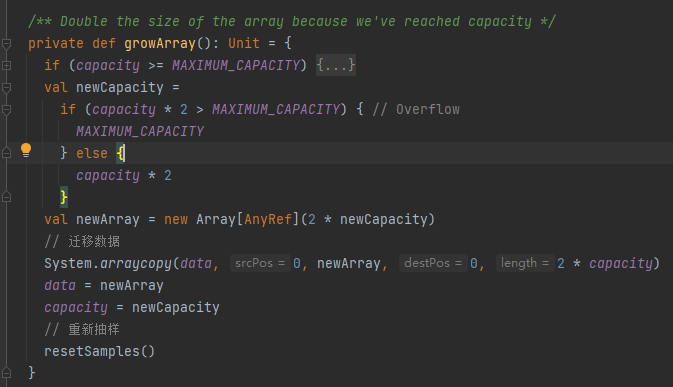
growArray
扩容2倍容量,迁移数据,重启采样
partitionedDestructiveSortedIterator
生成比较器comparator,调用sort对缓存的数据进行排序。

sorter是使用TimSort进行排序的。
TimSort介绍: https://zhuanlan.zhihu.com/p/695042849
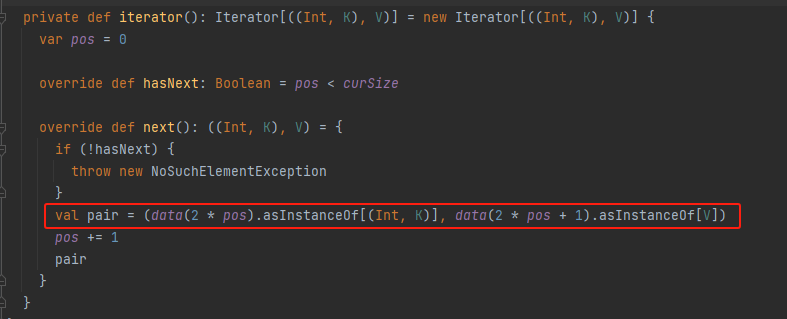
iterator
用pos计算剩余量。
data(2 * pos)为key,data(2 * pos+1) 为value
PartitionedAppendOnlyMap
存储数据用的数组data,里面的元素是key0, value0, key1, value1, key2, value2…

changeValue
PartitionedAppendOnlyMap插入数据不再是追加,而是有一个相同key合并值的过程。
- key是null,返回null,不进行存储
- key首次插入,更新data中的对应的kv值
- key非首次插入,更新data中合并的的新value
- key发生哈希冲突,就向后加1,直到不冲突
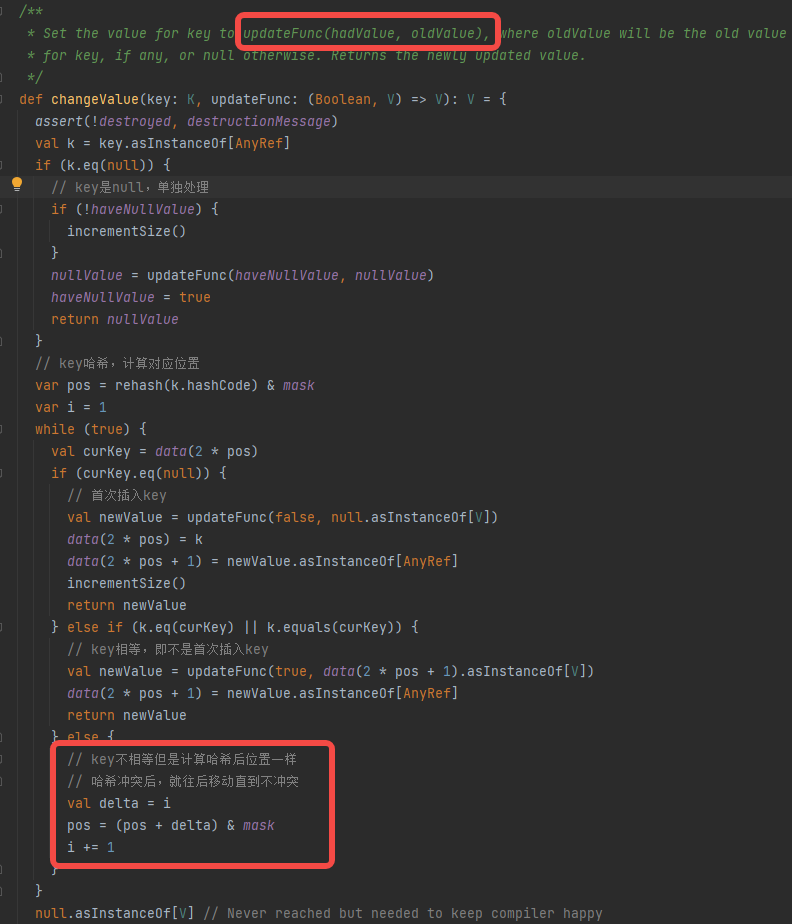
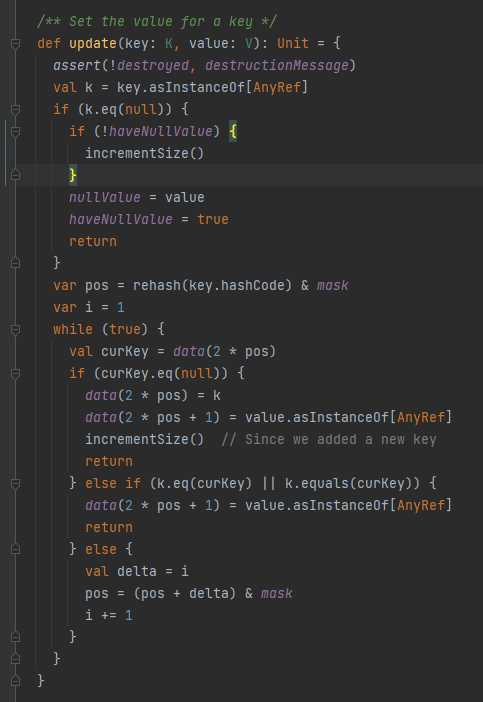
update
跟changeValue类似。
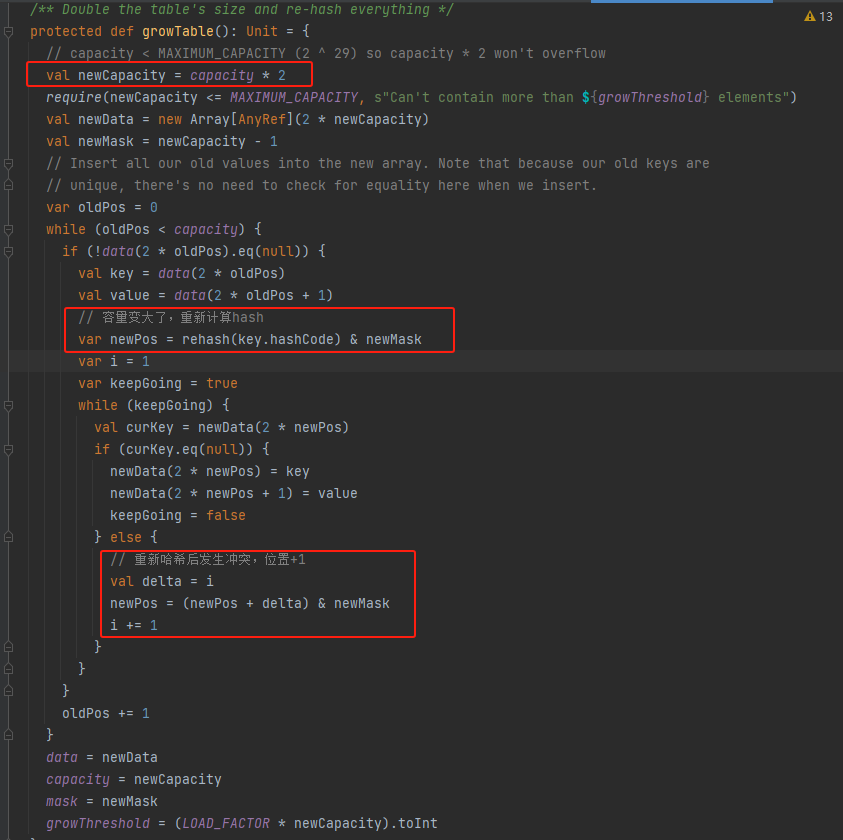
growTable
比较简单,就是容量扩大两倍,将旧的kv值重新计算hash插入到新的数组中,如果发生hash冲突就不断向后移动一位。
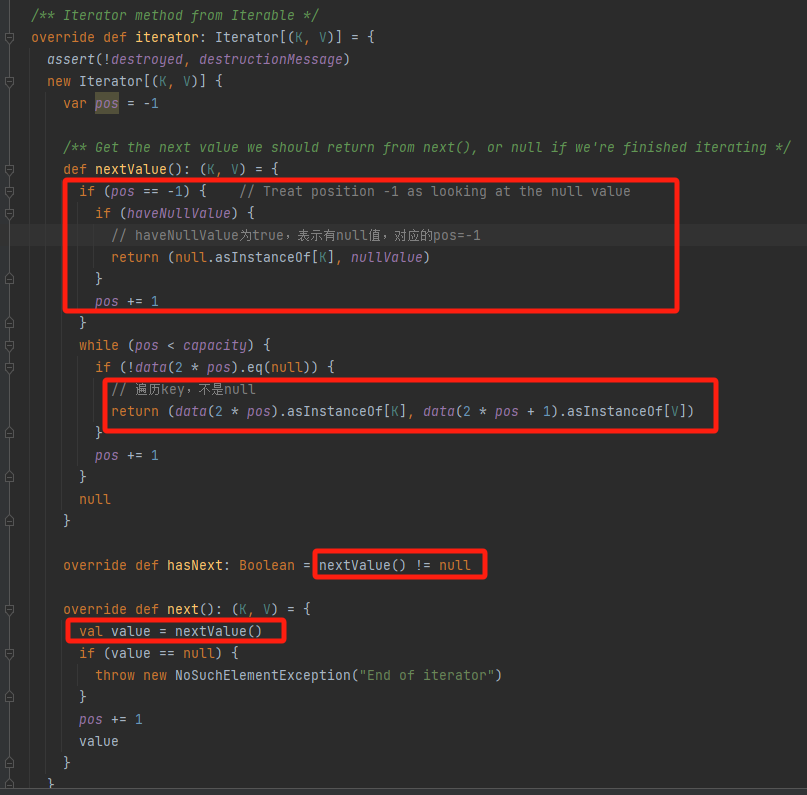
iterator
核心方法是nextValue,在nextValue中,遍历data数组的对应key值,要求不是null,表明这个位置是有值的。
如果有key为null,要求pos=-1且haveNullValue=true
partitionedDestructiveSortedIterator
调用destructiveSortedIterator方法
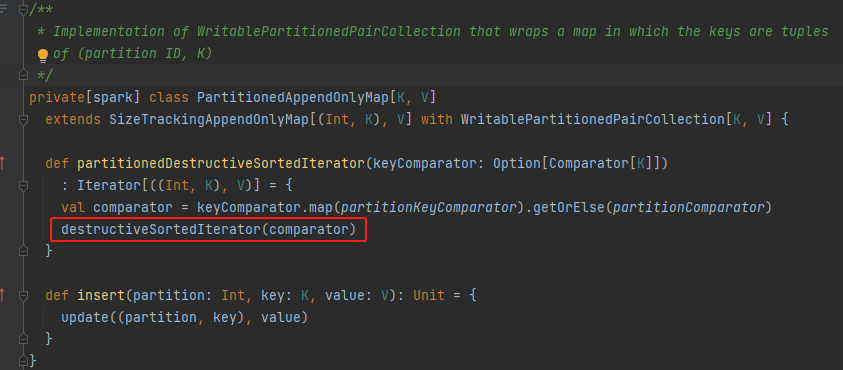
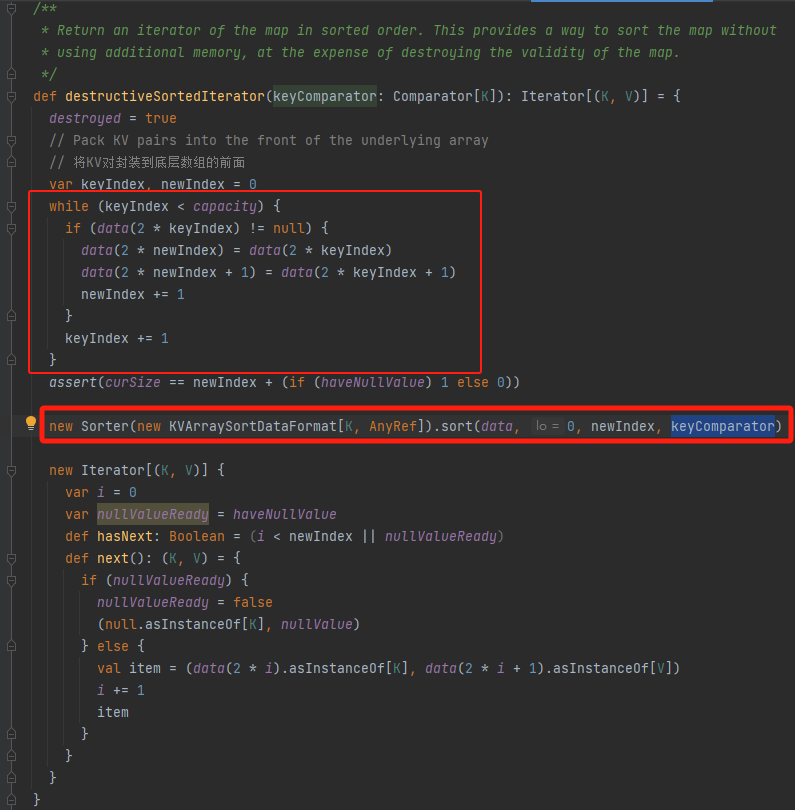
destructiveSortedIterator
data数组中元素是分散的,首先将数组中的元素都集中到数组的前面。后面就跟PartitionedPairBuffer的partitionedDestructiveSortedIterator方法一样使用TimeSort进行排序。
采样相关方法
跟上面的PartitionedPairBuffer的采样相关方法一样。
spill相关方法
入口方法是maybeSpillCollection
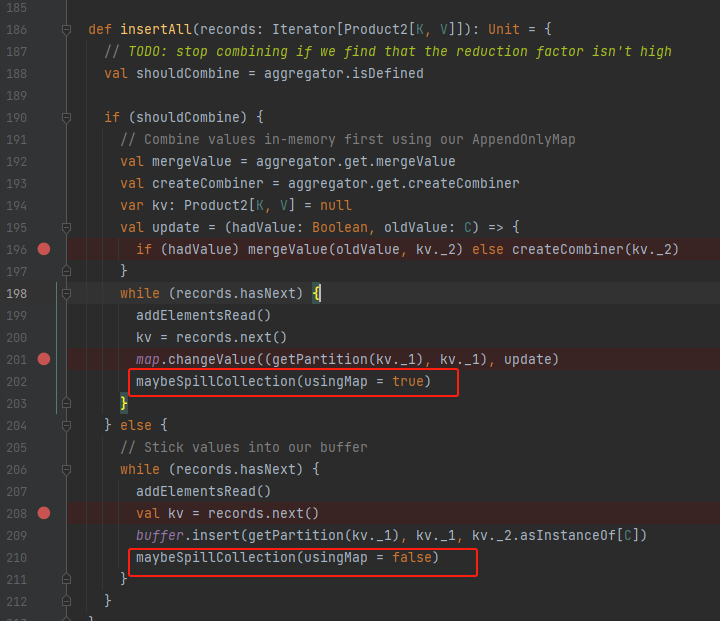
maybeSpillCollection
不论使用的数据结构是buffer还是map,都是计算消耗的容量,再调用maybeSpill方法,最后重新初始化化对应数据结构。可以想到maybeSpill中就将缓存的数据放到了本地。
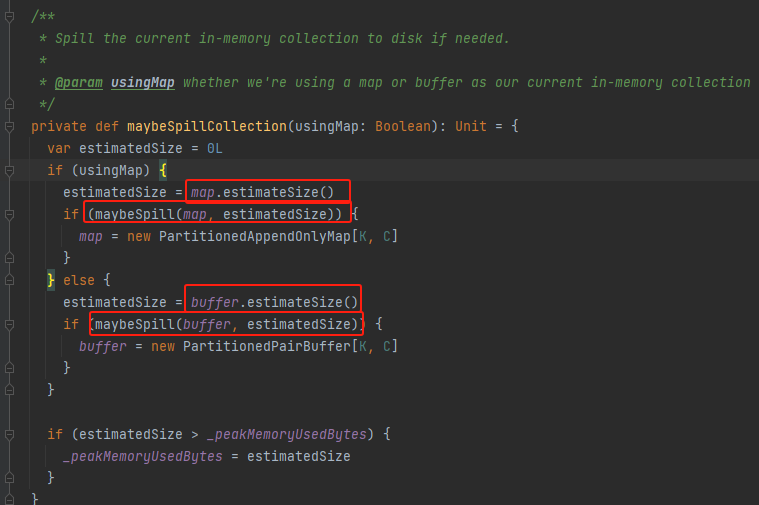
maybeSpill
每32条数据就进行一次内存使用情况判断。如果当前使用内存超过了限制,就先申请新的内存,按照两倍的内存使用量申请,不一定申请到足量的内存。申请后还是内存使用超过了限制,就进行spill,调用spill方法,同时调用releaseMemory释放内存。
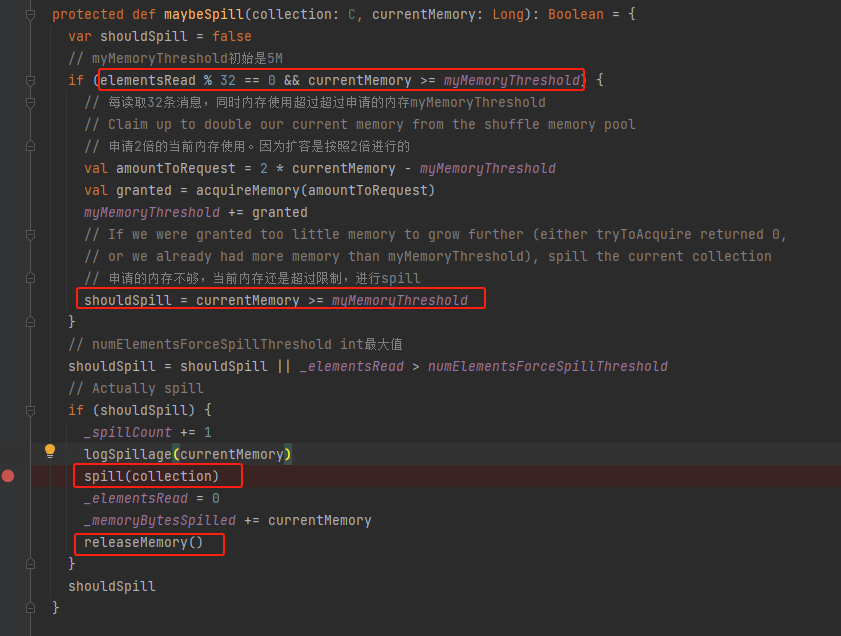
releaseMemory
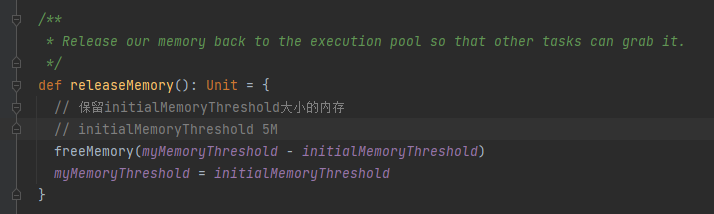
spill
调用destructiveSortedWritablePartitionedIterator方法返回排好序的分区迭代器。
调用spillMemoryIteratorToDisk将数据溢写到磁盘上
最后将生成的文件记录到spills中
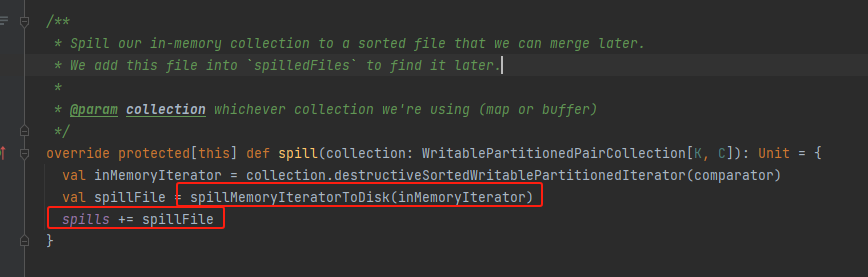
destructiveSortedWritablePartitionedIterator
调用对应数据结构的partitionedDestructiveSortedIterator方法返回排序的迭代器。
就是上面的PartitionedPairBuffer和PartitionedAppendOnlyMap的partitionedDestructiveSortedIterator方法。
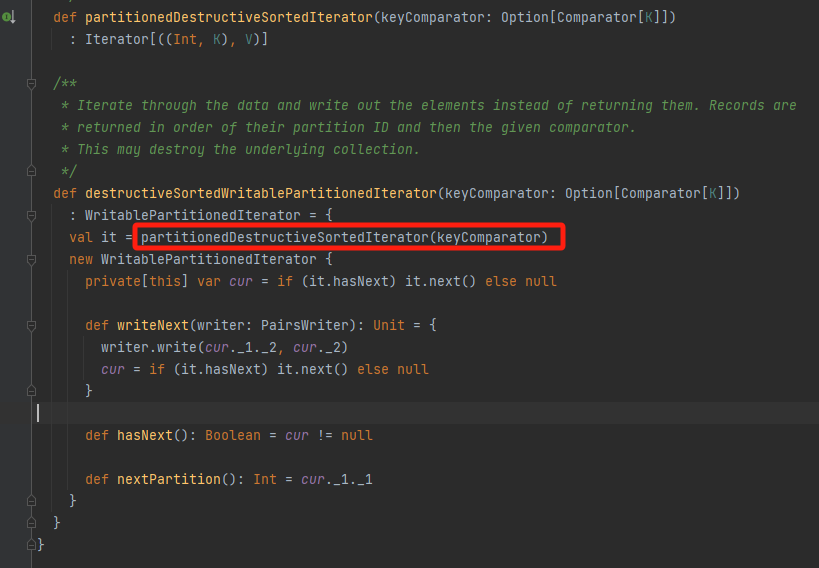
spillMemoryIteratorToDisk
创建临时文件,生成对应的writer
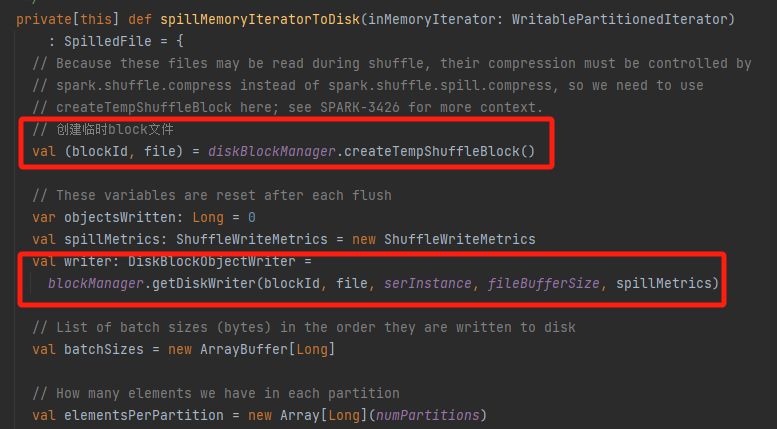
遍历将数据写入的文件中,每10000条进行一次flush。
如果失败了,调用revertPartialWritesAndClose进行回滚。
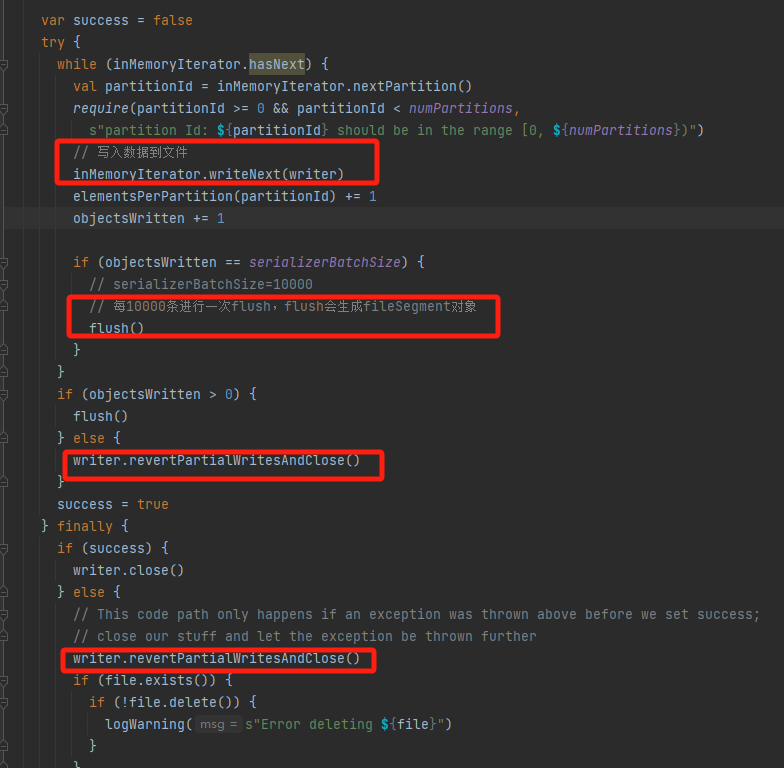
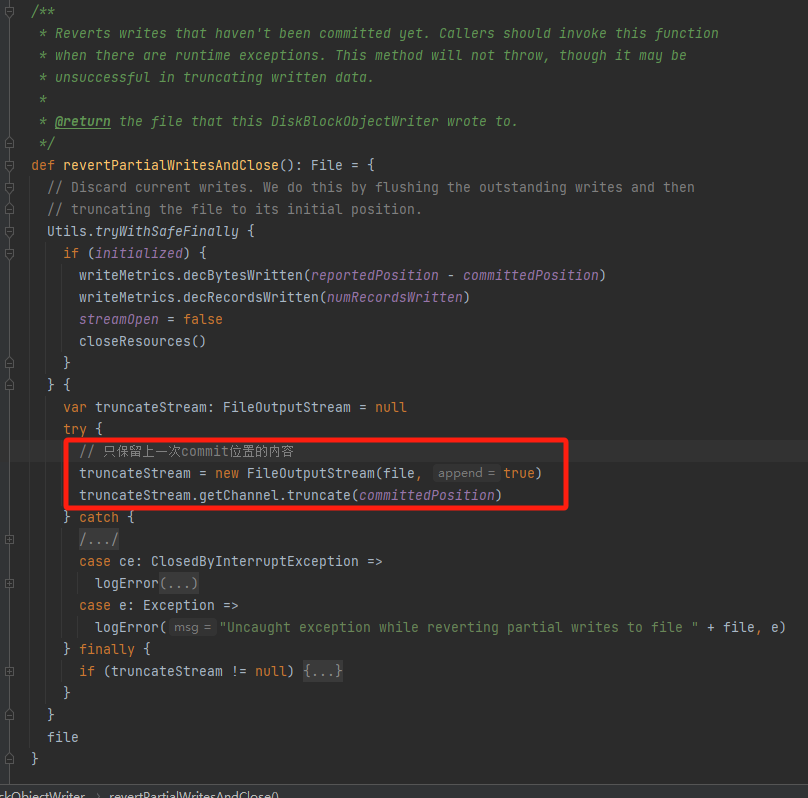
revertPartialWritesAndClose
如果这次写入出现问题,使用这个方法。回滚写入,只保留截止到上一次写入的内容。
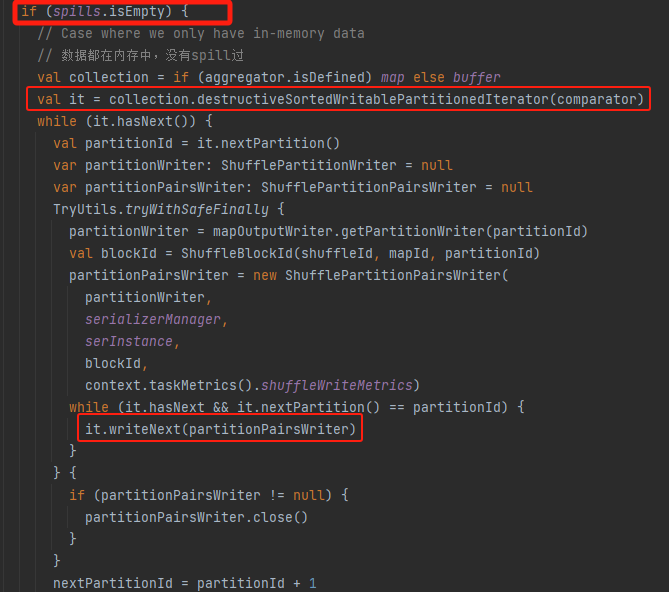
writePartitionedMapOutput
将排好序的缓存和文件合并成一个文件输出。
spills为空,即没有产生排序文件。将缓存中数据生成排好序的迭代器,遍历写入到文件中。
存在排好序的文件。则需要调用partitionedIterator方法将文件数据和缓存的数据进行合并,再遍历输出。
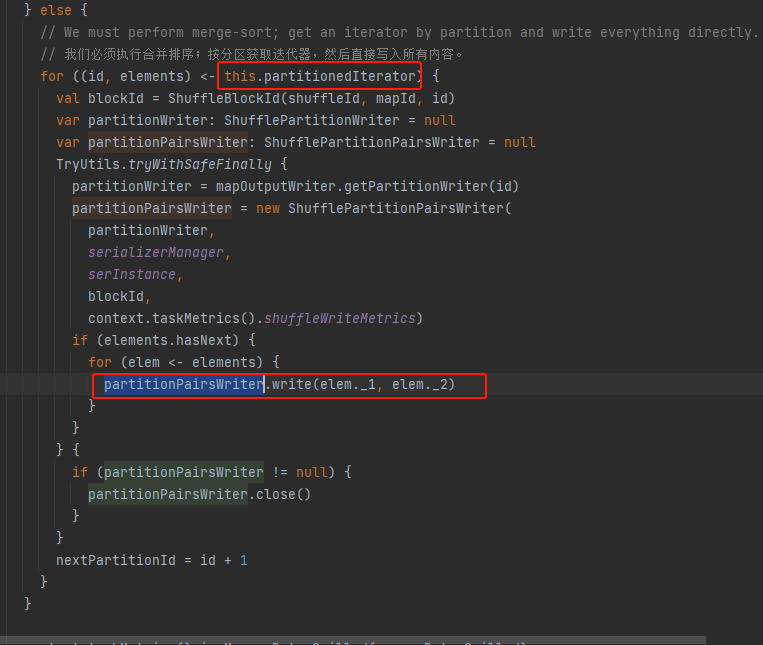
partitionedIterator
调用merge方法合并内存和文件数据
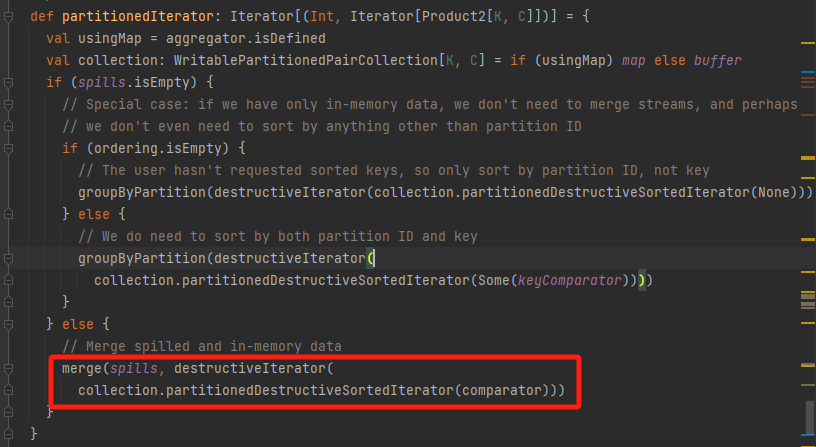
merge
merge的第一个参数是spilled文件,第二个参数是内存缓存的数据。
流程是遍历分区,取出对应分区的spilled文件中和缓存中的数据。
根据情况进行聚合或者排序等操作后输出合并后的排好序的文件。
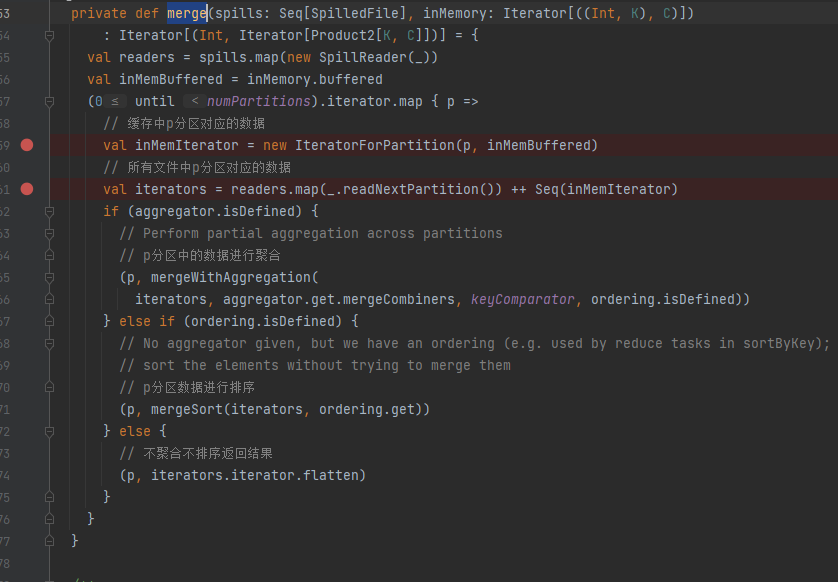
mergeSort
使用堆排序,但是heap中存放的是已经排好序的iterator。
最小值就是heap中首个iterator中的第一个元素。
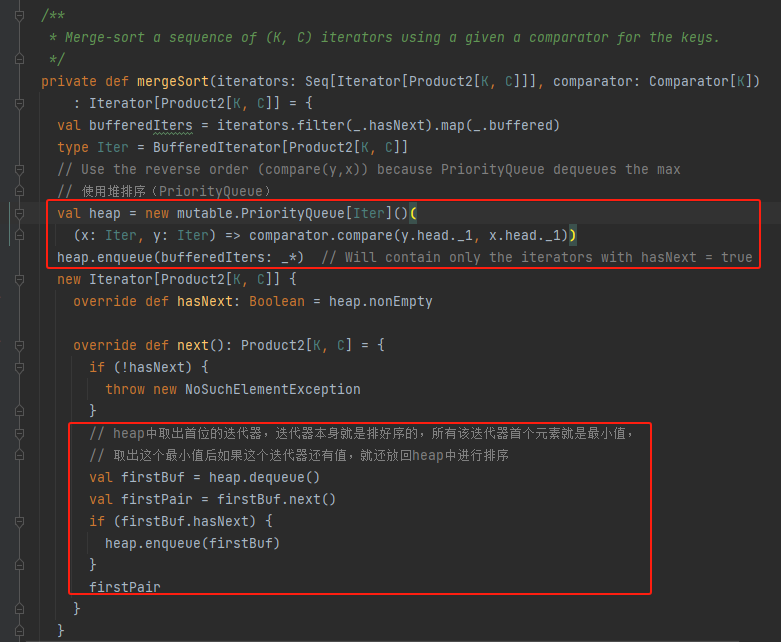
mergeWithAggregation
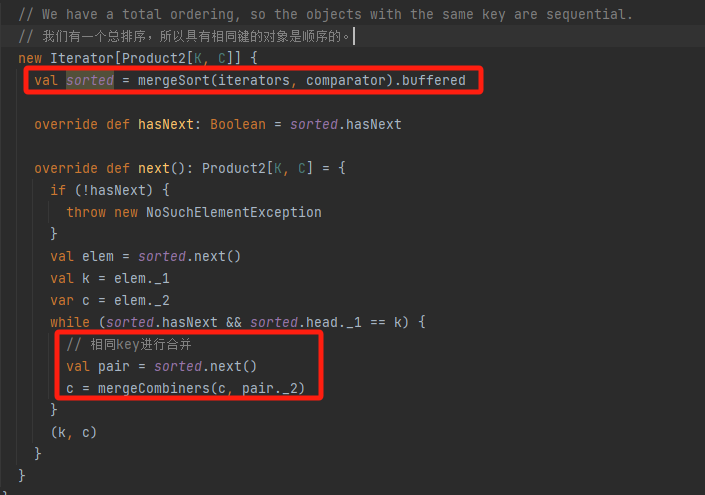
有总排序,这样相同的key会在一起。
调用mergeSort将iterators合并成一个排好序的iterator。
next方法就是遍历key出来全部的值,进行合并后输出,因为是全局有序,不需要遍历iterator全部数据。
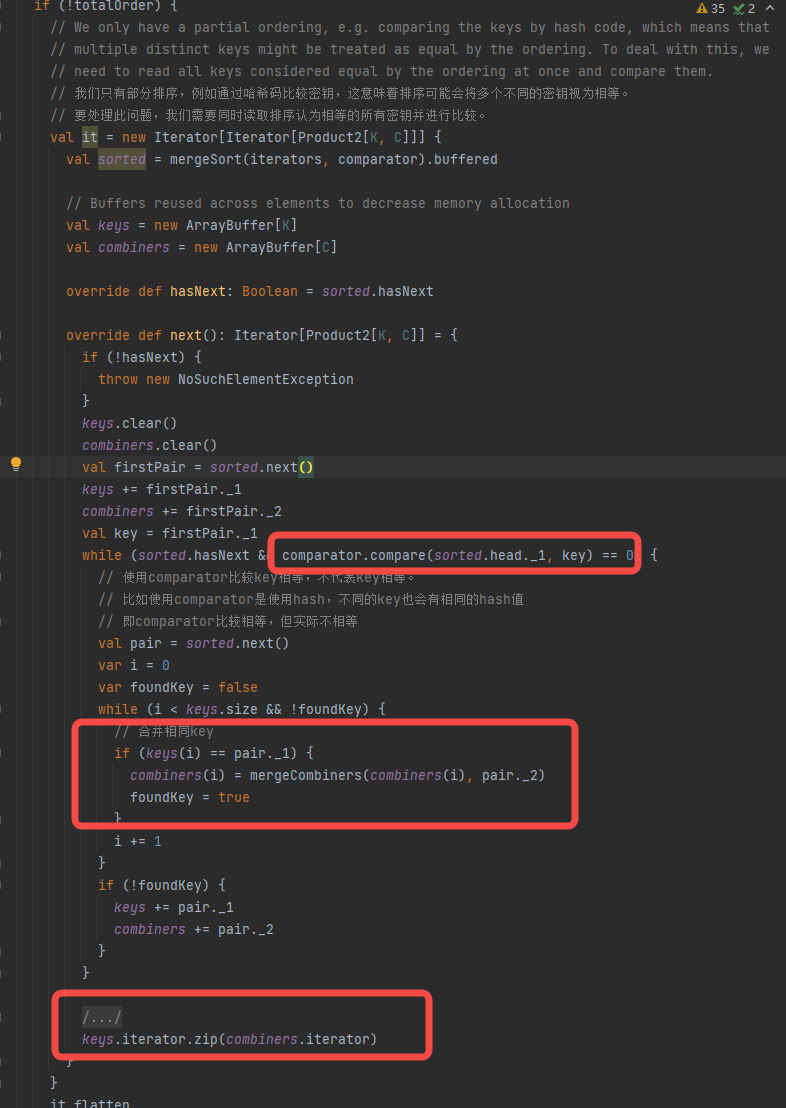
没有总排序
跟上面流程类似,先得到合并的iterator,但是它不是全局有序的。存在不同的key在comparator比较下相等,如使用hash进行比较,因此存在 aaabaaa 这种情况的key分布。
在获取相同key对应的值的时候需要遍历iterator的使用comparator和equal进行比较数据,再进行合并。返回值是一个comparator相同有可能key不同的key组成的iterator
相关文章:
spark shuffle写操作——SortShuffleWriter
写入的简单流程: 1.生成ExternalSorter对象 2.将消息都是插入ExternalSorter对象中 3.获取到mapOutputWriter,将中间产生的临时文件合并到一个临时文件 4.生成最后的data文件和index文件 可以看到写入的重点类是ExternalSorter对象 ExternalSorter 基…...
ESP32CAM物联网教学12
ESP32CAM物联网教学12 MicroPython 视频服务 小智希望能在MicroPython中实现摄像头的视频服务,就像官方示例程序CameraWebServer那样。 下载视频服务驱动库 小智通过上网搜索,发现相关的教学材料还不少,并且知道有人已经写出了视频服务的驱…...

【C++精华铺】12.STL list模拟实现
1.序言 STL (Standard Template Library)是C标准库中的一个重要组件,提供了许多通用的数据结构和算法。其中,STL list是一种带头双向链表容器,可以存储任意类型的元素。 list的特点包括: 双向性:list中的元素可以根据需…...
ChatGPT Mac App 发布!
2024 年 6 月,OpenAI 的大语言模型 ChatGPT 的 Mac 客户端与 ChatGPT-4o 一起发布了。ChatGPT Mac 户端可以让用户直接在 Mac 电脑上使用 ChatGPT 进行对话。它提供了一个简单易用的用户界面,用户可以在其中输入文本或语音指令,并接收模型生成…...

ACE之ACE_Time_Value
简介 ACE_Time_Value在ACE中表示时间,集成不同平台的时间 结构 #mermaid-svg-dGoKn1R7GicabUif {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-dGoKn1R7GicabUif .error-icon{fill:#552222;}#mermaid-…...
[论文笔记] 自对齐指令反翻译:SELF-ALIGNMENT WITH INSTRUCTION BACKTRANSLATION
https://arxiv.org/pdf/2308.06259 这篇论文介绍了一种名为“指令反向翻译”(instruction backtranslation)的方法,用于通过自动标记人类书写的文本和相应的指令来构建高质量的指令跟随语言模型。这里是一个通俗易懂的解释: 一、背景 通常,训练一个高质量的指令跟随语言…...

算术运算符. 二
# 表达式 # 操作数和运算符组成 比如 11 # 作用:表达式可以求值,也可以给变量赋值。 # Python算术运算符: # - * / % //(整除:向下取整) ** print(10 4) # 14 print(10 - 4) # 6 print(10 * 4) # 40 …...

代码优化方法记录
每次代码 review 之后,对 review 的情况进行总结记录,产出实际经验,方便组内学习、分享。 1、提取公共内容 公共内容要提取,避免重复编写; 2、css 色值使用变量 css 中的色值、字体,都换成组件库中的变…...

qt 图形、图像、3D相关知识
1.qt 支持3d吗 Qt确实支持3D图形渲染。Qt 3D模块是Qt的一个组成部分,它允许开发者在Qt应用程序中集成3D内容。Qt 3D模块提供了一组类和函数,用于创建和渲染3D场景、处理3D对象、应用光照和纹理等。 Qt 3D模块包括以下几个主要组件: Qt 3D …...
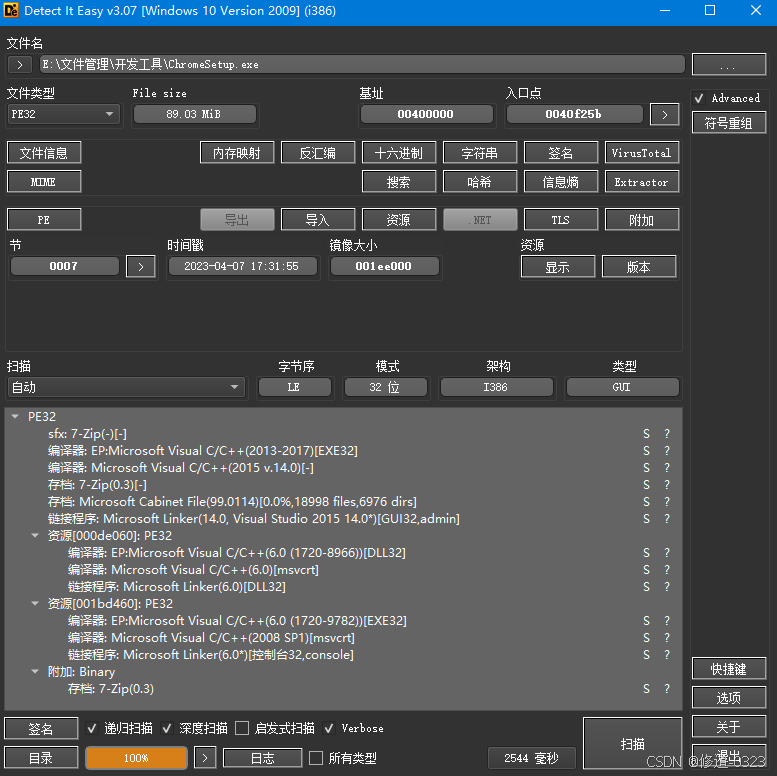
【逆向基础】十、工具分享之DIE(Detect It Easy)
一、简介 DIE(Detect It Easy)是一款可以轻松检测PE文件的程序;其主要作用是查壳,并将pe文件的内容解析出来,包括PE文件中包含的导入函数、导出函数的名称及地址,入口函数地址等,是技术人员分析…...

Netcat:——网络瑞士军刀
Netcat: 网络瑞士军刀 概述 Netcat(通常称为 nc)是一个功能强大的网络工具,广泛用于网络测试和调试。它能够读取和写入网络数据,支持TCP、UDP协议,可以用于端口扫描、端口监听、文件传输等多种用途。 主要用途 获取…...

C++ //练习 14.50 在初始化ex1和ex2的过程中,可能用到哪些类类型的转换序列呢?说明初始化是否正确并解释原因。
C Primer(第5版) 练习 14.50 练习 14.50 在初始化ex1和ex2的过程中,可能用到哪些类类型的转换序列呢?说明初始化是否正确并解释原因。 struct LongDouble{LongDouble(double 0.0);operator double();operator float(); }; Long…...
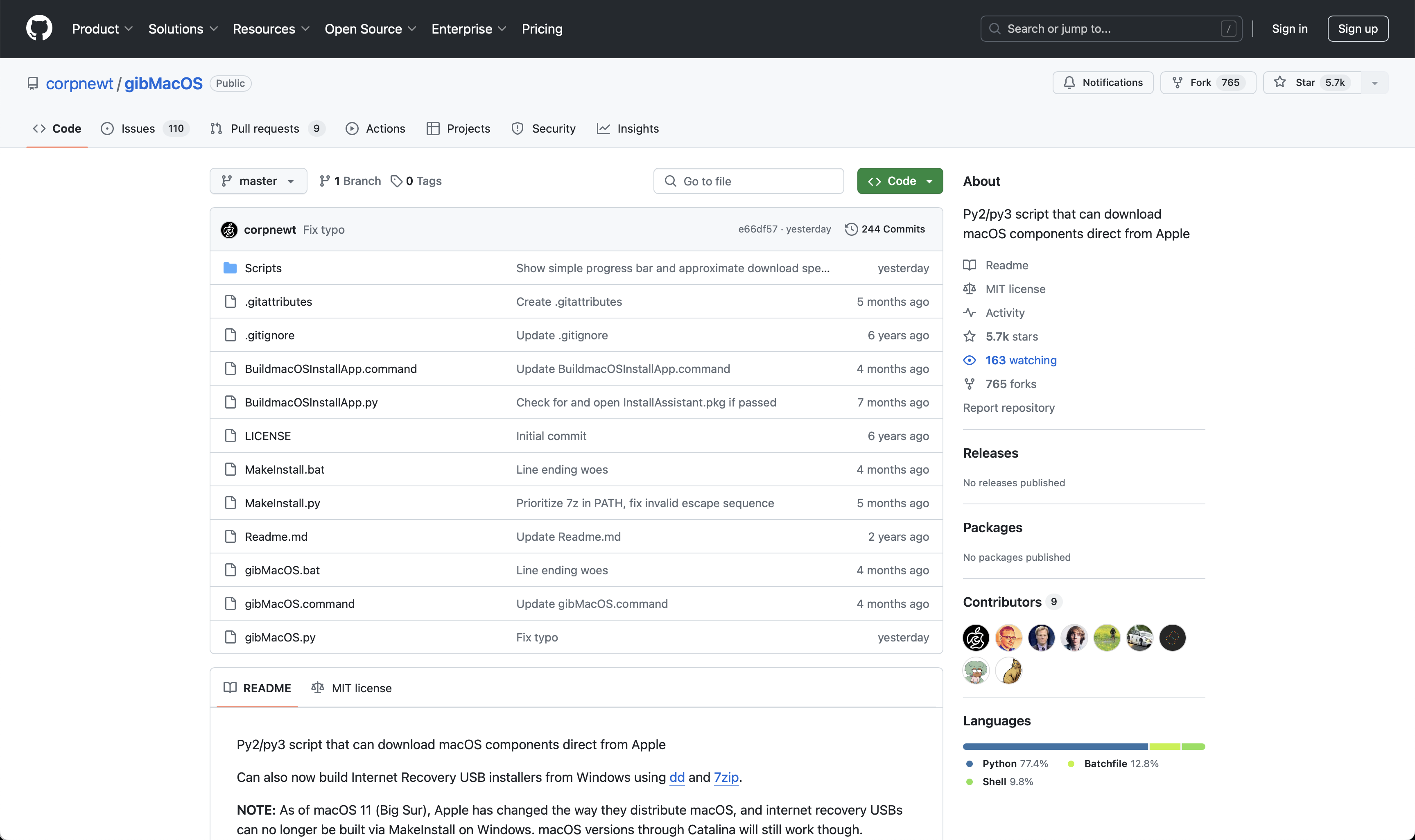
【开源 Mac 工具推荐之 1】gibMacOS:方便快捷的 macOS 完整包下载 Shell 工具
简介 gibMacOS 是由 GitHub 开发者 corpnewt 编写的一款 Shell 工具。它采用 Python 编程语言,可以让用户打开后在纯文本页面中轻松选择并下载来源于 Apple 官方的 macOS 完整安装包。 Repo 地址:https://github.com/corpnewt/gibMacOS (其…...

pdf文件如何快速英文转中文?
要将 PDF 文件中的英文内容转换为中文,你可以使用以下几种方法: 1、在线翻译工具: 使用网上的免费在线翻译工具,如Google翻译、百度翻译或有道翻译,将整个 PDF 文档粘贴到工具中进行翻译。 2、专业翻译软件…...

程序的控制结构——if-else语句(双分支结构)【互三互三】
目录 🍁 引言 🍁if-else语句(双分支结构) 👉格式1: 👉功能: 👉程序设计风格提示: 👉例题 👉格式2: 👉…...

[C++]初识C++(命名空间,命名空间使用,函数重载,缺省参数等)
💖💖💖欢迎来到我的博客,我是anmory💖💖💖 又和大家见面了 欢迎来到C探索系列 作为一个程序员你不能不掌握的知识 先来自我推荐一波 个人网站欢迎访问以及捐款 推荐阅读 如何低成本搭建个人网站…...
- 线性回归模型)
每天一个数据分析题(四百十六)- 线性回归模型
根据模型假设,线性回归模型中误差项的方差为 A. 常数 B. 函数 C. 随机变量 D. 以上都不是 数据分析认证考试介绍:点击进入 题目来源于CDA模拟题库 点击此处获取答案 数据分析专项练习题库 内容涵盖Python,SQL,统计学&#…...
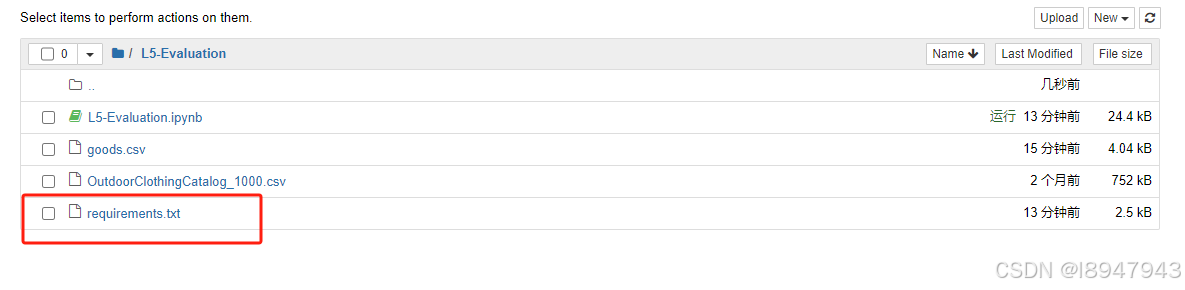
JupyterNotebook中导出当前环境,并存储为requirements.txt
使用Anaconda管理Python环境时,可以轻松地导出环境配置,以便在其他机器或环境中重新创建相同的环境。可以通过生成一个environment.yml文件实现的,该文件包含了环境中安装的所有包及其版本。但是,常常在一些课程中JupyterNotebo…...

Java对象复制系列二: 手把手带你写一个Apache BeanUtils
👆🏻👆🏻👆🏻关注博主,让你的代码变得更加优雅。 前言 Apache BeanUtils 是Java中用来复制2个对象属性的一个类型。 上一篇文章我们讲到了 Apache BeanUtils 性能相对比较差,今天…...

一个极简的 Vue 示例
https://andi.cn/page/621516.html...

星露谷物语SMAPI模组加载器:从新手到专家的终极指南
星露谷物语SMAPI模组加载器:从新手到专家的终极指南 【免费下载链接】SMAPI The modding API for Stardew Valley. 项目地址: https://gitcode.com/gh_mirrors/smap/SMAPI 你是否曾梦想为星露谷物语添加全新的游戏体验?SMAPI模组加载器正是实现这…...

Red Hat和IBM Node.js参考架构:企业级Node.js应用开发的完整指南
Red Hat和IBM Node.js参考架构:企业级Node.js应用开发的完整指南 【免费下载链接】nodejs-reference-architecture The Red Hat and IBM Node.js Reference architecture. The teams opinion on what components our customers and internal teams should use when …...

Windows系统Btrfs驱动终极指南:免费解锁Linux文件系统的强大功能
Windows系统Btrfs驱动终极指南:免费解锁Linux文件系统的强大功能 【免费下载链接】btrfs WinBtrfs - an open-source btrfs driver for Windows 项目地址: https://gitcode.com/gh_mirrors/bt/btrfs 想在Windows上体验Linux下一代文件系统的强大功能吗&#…...

3分钟搞定M3U8视频下载:免费开源工具的终极懒人包
3分钟搞定M3U8视频下载:免费开源工具的终极懒人包 【免费下载链接】N_m3u8DL-CLI-SimpleG N_m3u8DL-CLIs simple GUI 项目地址: https://gitcode.com/gh_mirrors/nm3/N_m3u8DL-CLI-SimpleG 还在为下载在线视频发愁吗?那些藏在网页里的M3U8格式视频…...

CANN-opbase-昇腾NPU算子开发的基础设施为什么这么重要
CANN-opbase-昇腾NPU算子开发的基础设施为什么这么重要 所有 CANN AOL 算子仓库的底层都依赖 opbase。它不提供任何算子实现,提供的是算子注册、编译、调度的基础设施。如果你要写自定义 Ascend C 算子,opbase 是绕不过去的第一步。 opbase 提供了什么组…...

AUTOSAR OS任务机制解析:从实时调度原理到RTA-OS工程实践
1. 项目概述:为什么AUTOSAR OS的Task是嵌入式软件的核心骨架?在汽车电子领域,如果你正在开发基于AUTOSAR架构的ECU软件,那么RTA-OS(Real-Time Application Operating System)中的Task(任务&…...

第一学期结果
关注 1.从安涛老师前三期视频中了解了方向2.从b站了解了555的内部结构3.仿真。4.低通滤波器的基本原理:一、核心定义只允许低频信号顺利通过,阻挡、衰减高频信号的电路。 你电路里作用:滤掉方波里的高频谐波,留下低频基波…...
 1. Q-learning的遗憾界分析-高效的Q-learning算法)
(二) 1. Q-learning的遗憾界分析-高效的Q-learning算法
高效的Q-learning算法 1.1. 无模型算法 1.2. UCB算法 1.3. 文献回顾 无模型(Model-free)强化学习算法(如 Q-learning)无需显式地对环境进行建模,而是直接对价值函数或策略进行参数化和更新。与基于模型(Model-based)的方法相比,这类算法通常更简单、更灵活,因此在现代…...

benchmark-ips源码剖析:理解Ruby性能测试的内部机制
benchmark-ips源码剖析:理解Ruby性能测试的内部机制 【免费下载链接】benchmark-ips Provides iteration per second benchmarking for Ruby 项目地址: https://gitcode.com/gh_mirrors/be/benchmark-ips 什么是benchmark-ips? benchmark-ips是一…...

如何快速掌握Prism-Samples-Wpf交互性编程:InvokeCommandAction事件驱动开发终极指南
如何快速掌握Prism-Samples-Wpf交互性编程:InvokeCommandAction事件驱动开发终极指南 【免费下载链接】Prism-Samples-Wpf Samples that demonstrate how to use various Prism features with WPF 项目地址: https://gitcode.com/gh_mirrors/pr/Prism-Samples-Wpf…...