深度学习数据集处理基础内容——xml和json文件详解
文章目录
- 一、xml文件
- 1.1 什么是 XML?
- 1.2XML 和 HTML 之间的差异
- 1.3XML 不会做任何事情
- 1.4通过 XML 您可以发明自己的标签
- 1.5XML 不是对 HTML 的替代
- 1.6XML 无所不在
- 二、json文件
- 基本的JSON结构体类型(共享部分)
- 三、转COCO数据集
- 3.1 info
- 3.2 licenses
- 3.3 Image
- 3.4 categories
- 3.5 annotations
- 四、组装coco
- 4.1定义大项集合
- 4.2 遍历组装
- 五、保存标注文件
- 为什么JSON比XML更受欢迎
一、xml文件
XML 被设计用来传输和存储数据。
HTML 被设计用来显示数据。
XML 指可扩展标记语言(eXtensible Markup Language)。
可扩展标记语言(英语:Extensible Markup Language,简称:XML)是一种标记语言,是从标准通用标记语言(SGML)中简化修改出来的。它主要用到的有可扩展标记语言、可扩展样式语言(XSL)、XBRL和XPath等。

1.1 什么是 XML?
- XML 指可扩展标记语言(EXtensible Markup Language)。
- XML 是一种很像HTML的标记语言。
- XML 的设计宗旨是传输数据,而不是显示数据。
- XML 标签没有被预定义。您需要自行定义标签。
- XML 被设计为具有自我描述性。
- XML 是 W3C 的推荐标准。
1.2XML 和 HTML 之间的差异
XML 不是 HTML 的替代。
XML 和 HTML 为不同的目的而设计:
- XML 被设计用来传输和存储数据,其焦点是数据的内容。
- HTML 被设计用来显示数据,其焦点是数据的外观。
HTML 旨在显示信息,而 XML 旨在传输信息。
1.3XML 不会做任何事情
也许这有点难以理解,但是 XML 不会做任何事情。XML 被设计用来结构化、存储以及传输信息。
下面实例是 Jani 写给 Tove 的便签,存储为 XML:
<note>
<to>Tove</to>
<from>Jani</from>
<heading>Reminder</heading>
<body>Don't forget me this weekend!</body>
</note>
上面的这条便签具有自我描述性。它包含了发送者和接受者的信息,同时拥有标题以及消息主体。
但是,这个 XML 文档仍然没有做任何事情。它仅仅是包装在 XML 标签中的纯粹的信息。我们需要编写软件或者程序,才能传送、接收和显示出这个文档。
1.4通过 XML 您可以发明自己的标签
上面实例中的标签没有在任何 XML 标准中定义过(比如 和 )。这些标签是由 XML 文档的创作者发明的。
这是因为 XML 语言没有预定义的标签。
HTML 中使用的标签都是预定义的。HTML 文档只能使用在 HTML 标准中定义过的标签(如< p > 、 < h1 >等等)。
XML 允许创作者定义自己的标签和自己的文档结构。
1.5XML 不是对 HTML 的替代
XML 是对 HTML 的补充。
XML 不会替代 HTML,理解这一点很重要。在大多数 Web 应用程序中,XML 用于传输数据,而 HTML 用于格式化并显示数据。
对 XML 最好的描述是:
XML 是独立于软件和硬件的信息传输工具。
1.6XML 无所不在
目前,XML 在 Web 中起到的作用不会亚于一直作为 Web 基石的 HTML。
XML 是各种应用程序之间进行数据传输的最常用的工具。
二、json文件
JSON是全称为JavaScript Object Notation,是一种有条理,易于访问的存储信息的方法。它为我们提供了一个可读的数据集合,我们可以通过合理的方式来访问这些数据。JSON文件可以存储简单的数据结构和对象。JSON文件在许多不同的编程API中都被支持。如今,JSON已被用于许多Web应用程序来进行数据交换,并且它们实际上不会在硬盘驱动器上保存“.JSON”文件,可以在互联网连接的计算机之间进行数据交换。某些应用程序允许用户将其保存在“.JSON”文件中
提到json,我们首先应该想到的是COCO格式的数据集。
COCO的 全称是Common Objects in COntext,是微软团队提供的一个可以用来进行图像识别的数据集。MS COCO数据集中的图像分为训练、验证和测试集。COCO通过在Flickr上搜索80个对象类别和各种场景类型来收集图像,其使用了亚马逊的Mechanical Turk(AMT)。
COCO通过大量使用Amazon Mechanical Turk来收集数据。COCO数据集现在有3种标注类型:object instances(目标实例), object keypoints(目标上的关键点), 和image captions(看图说话),使用JSON文件存储。
基本的JSON结构体类型(共享部分)
object instances(目标实例)、object keypoints(目标上的关键点)、image captions(看图说话)这3种类型共享这些基本类型:info、image、license。而annotation类型则呈现出了多态:
{"info": info, # dict"licenses": [license], # list ,内部是dict"images": [image], # list ,内部是dict"annotations": [annotation], # list ,内部是dict"categories": # list ,内部是dict
}info{ # 数据集信息描述"description": str, # 数据集描述"url": str, # 下载地址"version": str, # 版本"year": int, # 年份"contributor": str, # 提供者"date_created": str # 数据创建日期},license{"id": int,"name": str,"url": str,
}
image{"id": int,# 图片的ID编号(每张图片ID是唯一的)"width": int,# 宽"height": int,# 高"file_name": str,# 图片名"license": int,"flickr_url": str,# flickr网路地址"coco_url": str,"date_captured": datetime,# 数据获取日期
}
三、转COCO数据集
# 定义coco集合
coco=dict()
3.1 info
info类型,比如一个info类型的实例
{"info": info,"licenses": [license],"images": [image],#数组元素的数量等同于划入训练集(或者测试集)的图片的数量;"annotations": [annotation],#数组元素的数量等同于训练集(或者测试集)中bounding box的数量;"categories": [category]
}
info={"description":"This is stable 1.0 version of the 2014 MS COCO dataset.","url":"http:\/\/mscoco.org","version":"1.0","year":2014,"contributor":"Microsoft COCO group","date_created":"2022-12-26"
}
# 定义coco的info部分,并加入coco集合info={"description":"This is stable 1.0 version of the 2014 MS COCO dataset.","url":"http:\/\/mscoco.org","version":"1.0","year":2014,"contributor":"Microsoft COCO group","date_created":"2022-12-26"
}
coco['info']=info
3.2 licenses
licenses是包含多个license实例的数组,对于一个license类型的实例
license{"id": int,"name": str,"url": str,
}
例如
licenses={"url":"http:\/\/creativecommons.org\/licenses\/by-nc-sa\/2.0\/","id":1,"name":"Attribution-NonCommercial-ShareAlike License"
}
license跟图像id有关,定义函数如下:
def generate_license(image_id):license = {"url": "http:\/\/goingtodo.cn\/licenses\/","id": image_id,"name": "nothing just awsome License"}return license
3.3 Image
Images是包含多个image实例的数组,对于一个image类型的实例:
image{"id": int,# 图片的ID编号(每张图片ID是唯一的)"width": int,# 宽"height": int,# 高"file_name": str,# 图片名"license": int,"flickr_url": str,# flickr网路地址"coco_url": str,"date_captured": datetime,# 数据获取日期
}
Image跟图像id以及图片尺寸有关,定义函数如下:
import cv2def image_info(image_name, image_id):# img = cv2.imread(image_name)# 加入相对路径img = cv2.imread(os.path.join('data/train/imgs', image_name))image_info = {"id": image_id, # 图片的ID编号(每张图片ID是唯一的)"width": img.shape[1], # 宽"height": img.shape[0], # 高"file_name": image_name, # 图片名"license": "awsome license","flickr_url": "no url", # flickr网路地址"coco_url": "no url","date_captured": "2022-12-26" # 数据获取日期}return image_info
3.4 categories
categories是一个包含多个category实例的数组,而category结构体描述如下:
"categories":{ # 类别描述"id": int,# 类对应的id (0 默认为背景)"name": str, # 子类别"supercategory": str,# 主类别
}
从instances_val2017.json文件中摘出的2个category实例如下所示:
{"supercategory": "person","id": 1,"name": "person"
},
{"supercategory": "vehicle","id": 2,"name": "bicycle"
}
categories跟图像id有关
def generate_categories(image_id):cat = {"supercategory": "table","id": image_id,"name": "table","keypoints": ['lb', 'lt' , 'rt' , 'rb'],"skeleton": [[1,2],[2,3],[3,4],[4,1]]}return cat
3.5 annotations
annotation{"id": int, # int 图片中每个被标记物体的id编号"image_id": int, # int 该物体所在图片的编号"category_id": int,# int 被标记物体的类别id编号"segmentation": RLE or [polygon],#分割区域的坐标,对象的边界点(边界多边形)"area": float,# float 被检测物体的面积"bbox": [x,y,width,height],# 目标检测框的坐标信息"iscrowd": 0 or 1,# 0 or 1 目标是否被遮盖,默认为0
}
这个类型中的annotation结构体包含了Object Instance中annotation结构体的所有字段,再加上2个额外的字段。
新增的keypoints是一个长度为3*k的数组,其中k是category中keypoints的总数量。每一个keypoint是一个长度为3的数组,第一和第二个元素分别是x和y坐标值,第三个元素是个标志位v,v为0时表示这个关键点没有标注(这种情况下x=y=v=0),v为1时表示这个关键点标注了但是不可见(被遮挡了),v为2时表示这个关键点标注了同时也可见。
num_keypoints表示这个目标上被标注的关键点的数量(v>0),比较小的目标上可能就无法标注关键点。
annotation{"keypoints": [x1,y1,v1,...],"num_keypoints": int,"id": int,"image_id": int,"category_id": int,"segmentation": RLE or [polygon],"area": float,"bbox": [x,y,width,height],"iscrowd": 0 or 1,
}
此次需要的数据如下:
- bbox
- keypoints
四、组装coco
前面定义了coco集合,加入了info,现在组装其他数据,主要有:
- license
- image
- annotation
4.1定义大项集合
coco['images'] = []
coco['annotations'] = []
coco['categories'] = []
coco['licenses'] = []
4.2 遍历组装
info前面已经组装了,现在组装其他部分:
- images
- categories
- licenses
- annotations
- 目标检测
- 关键点
# 遍历组装
ii=0for i in json_data.keys():image_temp=dict()# 1.coco['images']信息组装# 获取图片信息# print(i, ii)image_info_some = image_info(image_name=i, image_id=ii)# 添加到 coco['images'] 数组coco['images'].append(image_info_some)# 2.coco['images']信息组装# 类别信息获取cat_info=generate_categories(image_id=ii)# 添加到 coco['categories'] 数组coco['categories'].append(cat_info)# 3.coco['licenses'] 信息组装# 版权信息获取lic_info=generate_license(image_id=ii)# 添加到 coco['licenses'] 数组coco['licenses'].append(lic_info)# 4.coco['annotations'] 信息组装# 标注信息集合定义 annotation_temp=dict()# 4.1 annotations公共部分信息# 标注id信息annotation_temp['id']=ii# 图像idannotation_temp['image_id']=ii# 关键点个数 4个,上下左右 annotation_temp['num_keypoints']=4# 0好像是背景annotation_temp['category_id']=1image_anno= json_data[i][0]# 4.2 annotations目标检测部分# bbox,目标检测框的坐标信息,一张图只有一个表格,所以就这样了。# print(image_anno)# [{'box': [987, 2135, 2343, 2550], 'lb': [987, 2542], 'lt': [1029, 2135], 'rt': [2264, 2139], 'rb': [2343, 2550]}]annotation_temp['bbox']=image_anno['box']# 0 or 1 目标是否被遮盖,默认为0annotation_temp['iscrowd']=0# 被标记物体的类别id编号# 4.3 annotations关键点部分部分# 新增的keypoints是一个长度为3*k的数组,其中k是category中keypoints的总数量。# 每一个keypoint是一个长度为3的数组,第一和第二个元素分别是x和y坐标值,第三个元素是个标志位v,v为0时表示这个关键点没有标注(这种情况下x=y=v=0),v为1时表示这个关键点标注了但是不可见(被遮挡了),v为2时表示这个关键点标注了同时也可见。keypoints=[image_anno['lb'][0],image_anno['lb'][1],2, image_anno['lt'][0],image_anno['lt'][1],2,image_anno['rt'][0],image_anno['rt'][1],2,image_anno['rb'][0],image_anno['rb'][1],2]# 加入annotation标注集合annotation_temp['keypoints']=keypointscoco['annotations'].append(annotation_temp)ii=ii+1
五、保存标注文件
import jsonff = open('table_keypoints_val2017.json', 'w')
ff.write(json.dumps(coco, ensure_ascii=False ) + '\n')
ff.close()
参考文章表格关键点检测之COCO数据集转换
为什么JSON比XML更受欢迎
JSON和XML完全是两种不同的数据格式。都是在Web中用于数据交换目的。与XML相比,放置java脚本或JSON Object Notation是一种更轻量级的数据交换格式。而且XML使用了大量的开始和结束标记,而JSON只使用{}表示对象,[]表示数组,这使得它更加轻量级。有利于快速传输和处理,JSON的对象和数组的表示使得映射更直接容易
相关文章:
深度学习数据集处理基础内容——xml和json文件详解
文章目录一、xml文件1.1 什么是 XML?1.2XML 和 HTML 之间的差异1.3XML 不会做任何事情1.4通过 XML 您可以发明自己的标签1.5XML 不是对 HTML 的替代1.6XML 无所不在二、json文件基本的JSON结构体类型(共享部分)三、转COCO数据集3.1 info3.2 l…...

蓝桥杯基础技能训练
51单片机系统浓缩图 1. HC138译码器 用3个输入引脚,实现8个输出引脚,而且这个八个输出引脚中只要一个低电平,所以我们只需要记住真值表就行 #include "reg52.h" sbit HC138_A P2^5; sbit HC138_B P2^6; sbit HC…...
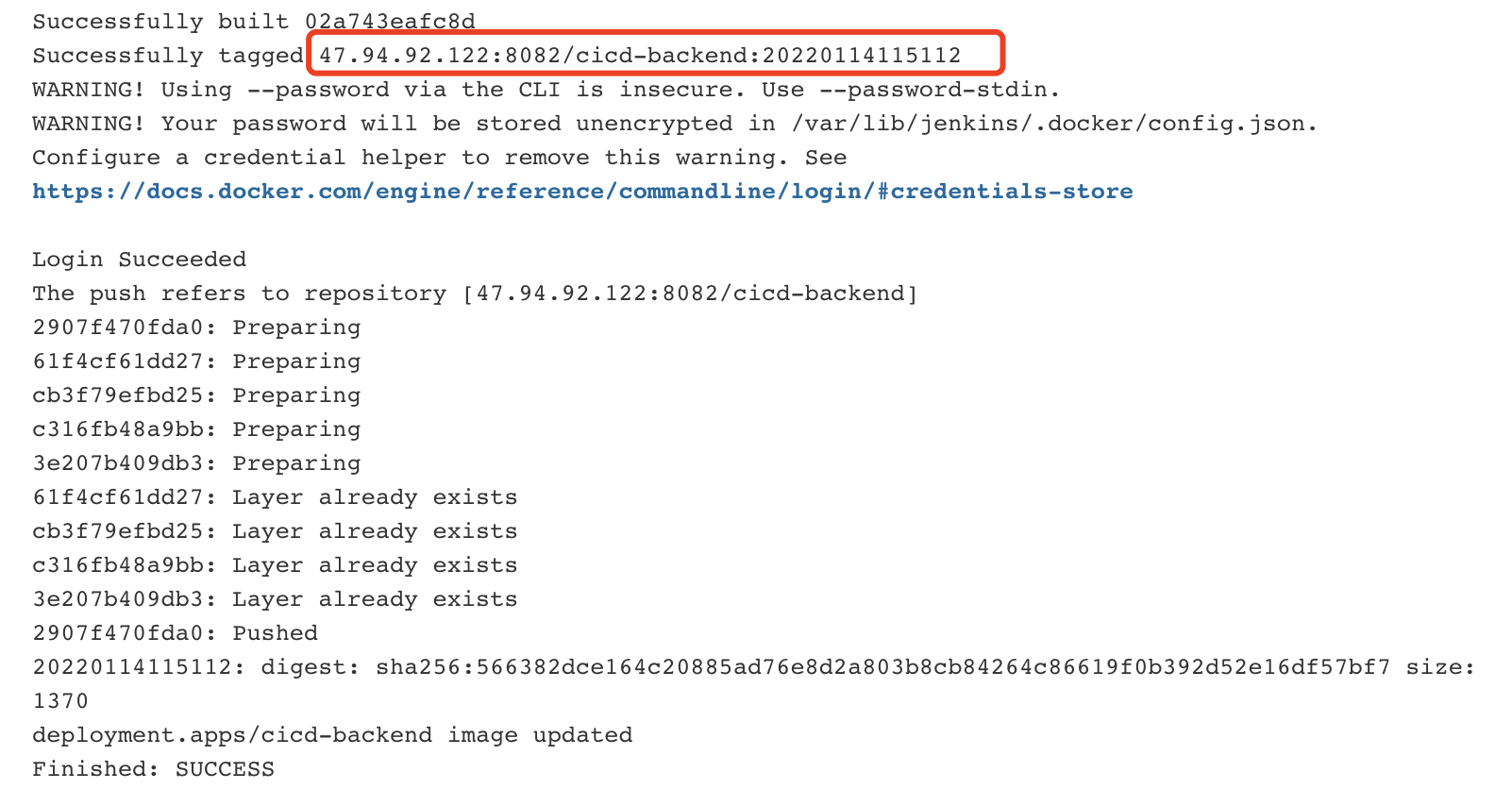
【Kubernetes】第二十八篇 - 实现自动构建部署
一,前言 上一篇,介绍了 Deployment、Service 的创建,完成了前端项目的构建部署; 希望实现:推送代码 -> 自动构建部署-> k8s 滚动更新; 本篇,实现自动构建部署 二,推送触发构…...

蓝桥杯刷题第十天
第一题:裁纸刀问题描述本题为填空题,只需要算出结果后,在代码中使用输出语句将所填结果输出即可。小蓝有一个裁纸刀,每次可以将一张纸沿一条直线裁成两半。小蓝用一张纸打印出两行三列共 6 个二维码,至少使用九次裁出来…...
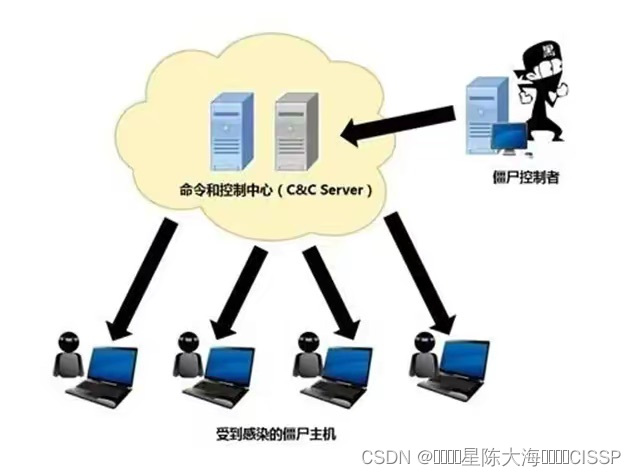
网络安全缓冲区溢出与僵尸网络答题分析
一、缓冲区溢出攻击 缓冲区溢出是指当计算机向缓冲区内填充数据位数时超过了缓冲区本身的容量,溢出的数据覆盖在合法数据上。理想的情况是:程序会检查数据长度,而且并不允许输入超过缓冲区长度的字符。但是绝大多数程序都会假设数据长度总是…...
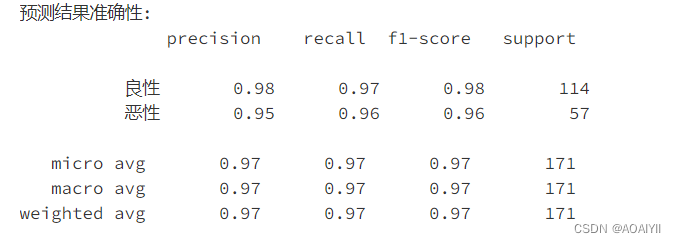
机器学习:逻辑回归模型算法原理(附案例实战)
机器学习:逻辑回归模型算法原理 作者:AOAIYI 作者简介:Python领域新星作者、多项比赛获奖者:AOAIYI首页 😊😊😊如果觉得文章不错或能帮助到你学习,可以点赞👍收藏&#x…...
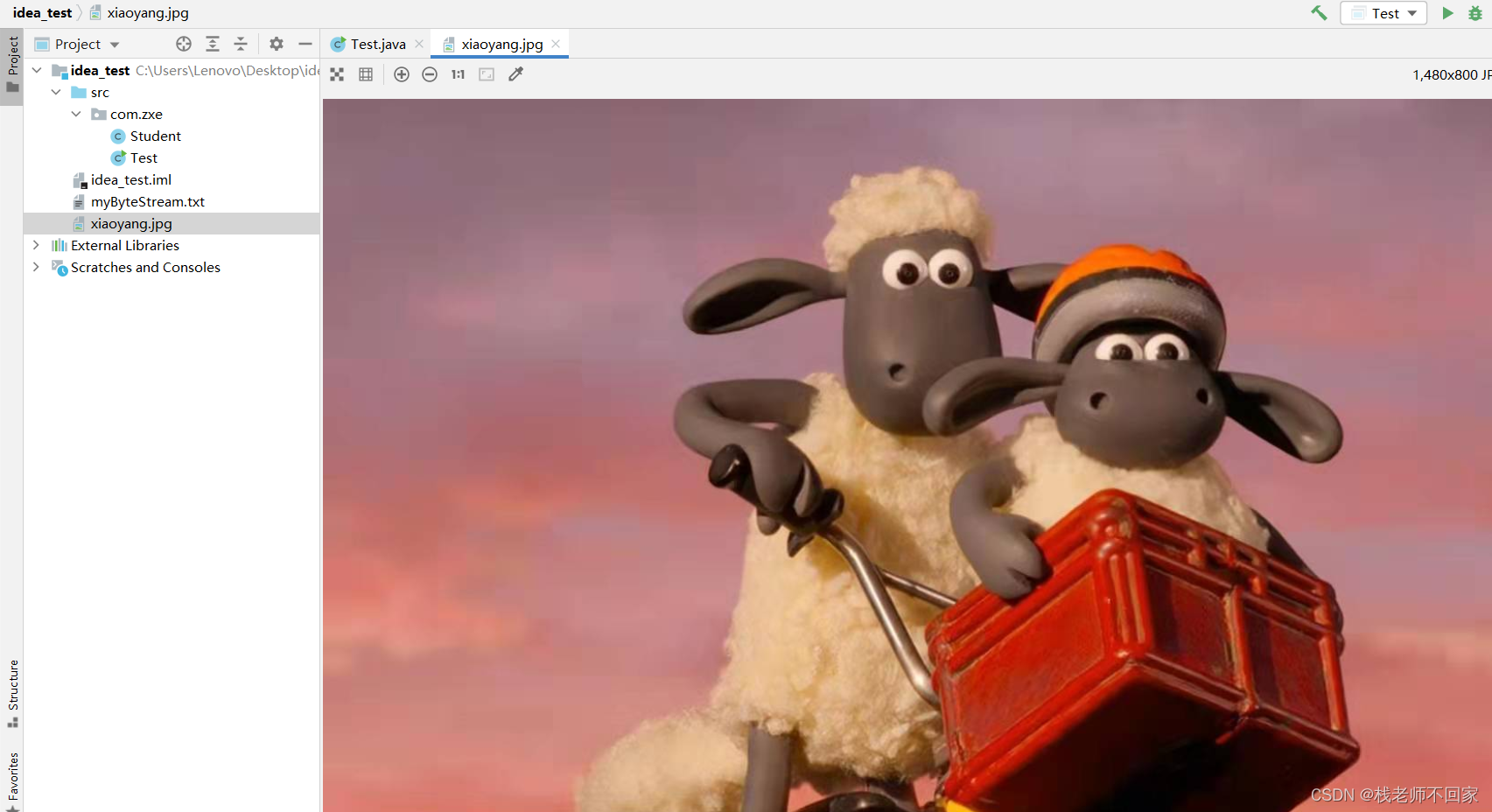
IO流之 File 类和字节流
文章目录一、File 类1. 概述2. 创建功能3. 删除功能4. 判断和获取功能5. 递归策略5.1 递归求阶乘5.2 遍历目录二、字节流1. IO 流概述2. 字节流写数据2.1 三种方式2.2 换行及追加2.3 加异常处理3. 字节流读数据3.1 一次读一个字节3.2 一次读一个字节数组3.3 复制文本文件3.4 复…...
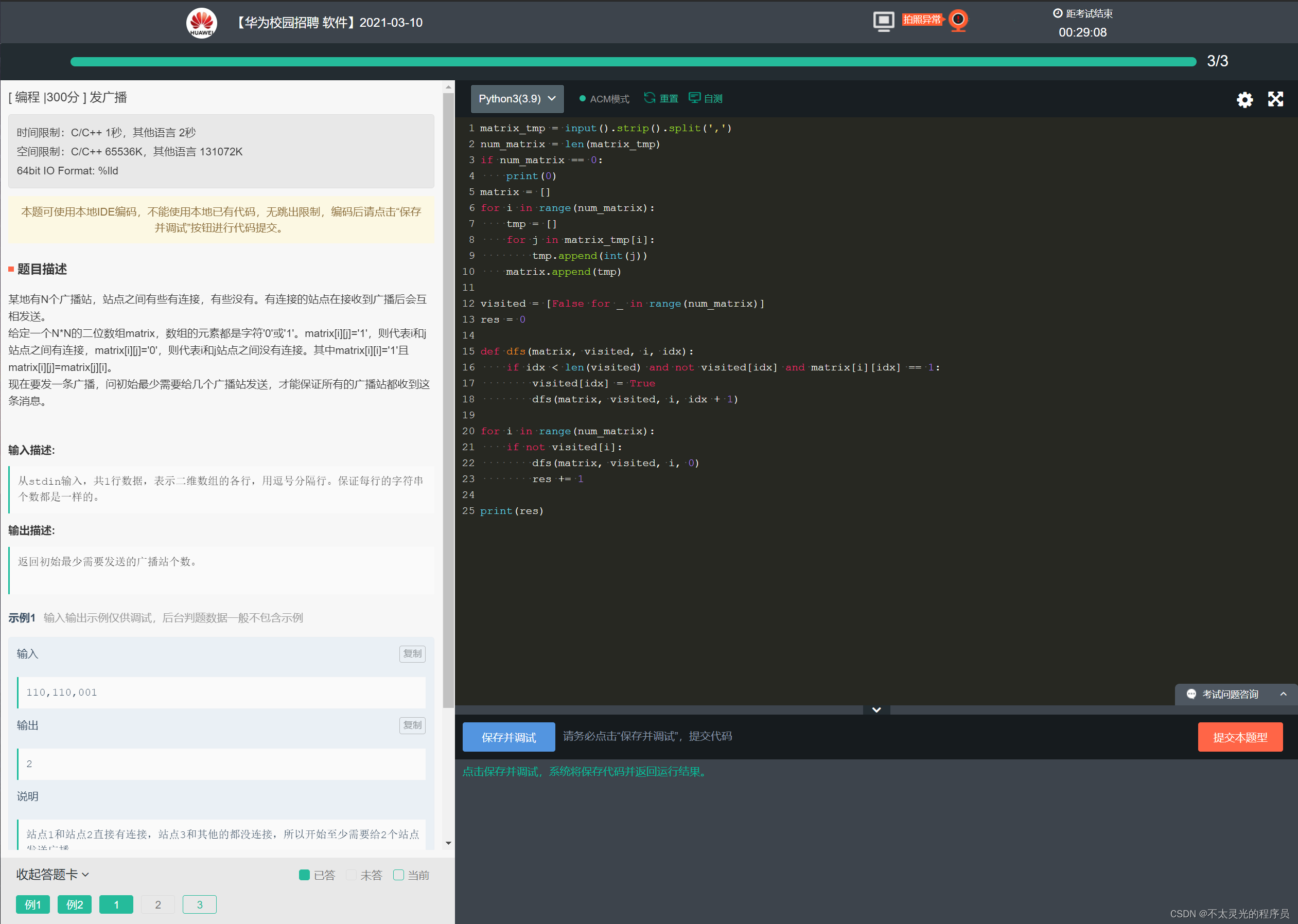
【华为机试真题 Python实现】2023年1、2月高频机试题
文章目录2023年1季度最新机试题机考注意事项1. 建议提前刷题2. 关于考试设备3. 关于语言环境3.1. 编译器信息3.2. ACM 模式使用sys使用input(推荐)3. 关于题目分值及得分计算方式4. 关于做题流程5. 关于作弊2023年1季度最新机试题 两个专栏现在有200博文…...

【拳打蓝桥杯】最基础的数组你真的掌握了吗?
文章目录一:数组理论基础二:数组这种数据结构的优点和缺点是什么?三:数组是如何实现随机访问的呢?四:低效的“插入”和“删除”原因在哪里?五:实战解题1. 移除元素暴力解法双指针法2…...
断崖式难度的春招,可以get这些点
前言 大家好,我是bigsai,好久不见,甚是想念。 开学就等评审结果,还好擦边过了,上周答辩完整理材料,还好都过了(终于可以顺利毕业了),然后后面就是一直安享学生时代的晚年。 最近金三银四黄金…...

一年经验年初被裁面试1月有余无果,还遭前阿里面试官狂问八股,人麻了
最近接到一粉丝投稿:年初被裁员,在家躺平了6个月,然后想着学习下再去面试,现在面试了1个月有余,无果,天天打游戏到半夜,根本无法静下心来学习。下面是他这些天面试经常会被问到的一些问题&#…...
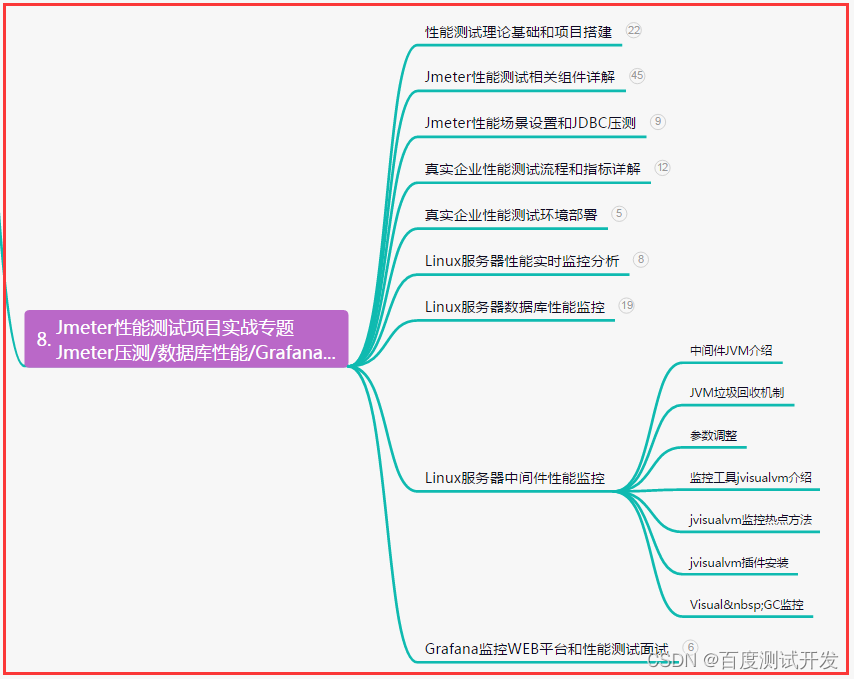
我从功能测试到python接口自动化测试涨到22k,谁知道我经历了什么......
目录:导读前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜)前言 常见的接口…...
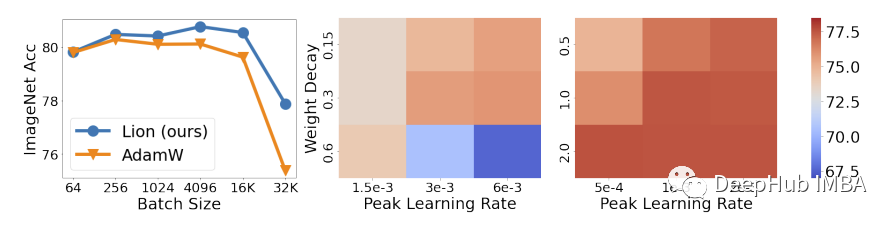
SDG,ADAM,LookAhead,Lion等优化器的对比介绍
本文将介绍了最先进的深度学习优化方法,帮助神经网络训练得更快,表现得更好。有很多个不同形式的优化器,这里我们只找最基础、最常用、最有效和最新的来介绍。 优化器 首先,让我们定义优化。当我们训练我们的模型以使其表现更好…...
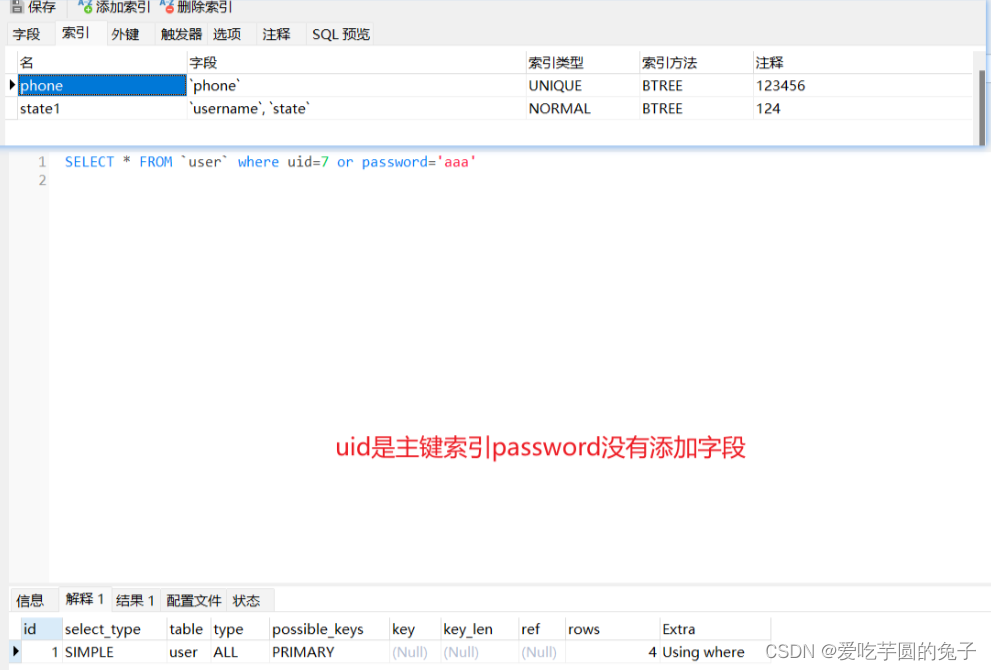
【项目实现典型案例】12.数据库数据类型不一致导致查询慢
目录一:背景介绍二:索引失效复现四:索引实现的六种情况1、类型转换,函数2、ISNULL3、通配符开头4、范围查询5、组合索引,不符合最左匹配原则6、WHERE子句中的OR四:总结一:背景介绍 MySql数据库…...

【大数据开发】报错汇总
目录 Hadoop Attempting to operate on hdfs namenode as root jps后没有namenode Hive Exception in thread "main" java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V Caused by:o…...

HTTPS的加密原理(工作机制)
现在很多网站使用的都是HTTPS协议,比如CSDN他们为什么要使用HTTPS协议而不是继续使用HTTP协议呢?以及HTTPS都做了些什么?HTTP协议与HTTPS有哪些区别? 下面我来 讲解这些问题?(篇幅可能有些长,请求耐心观看,我以0基础的角度去讲解这些东西, 如果你有一定的基础前面的跳过就好…...

Git仓库迁移
背景 由于公司原来的gitee地址需要改完新的gitlab仓库,大量的服务模块已再本地进行开发,且存在大量分支进行维护,迁移要求历史提交记录也得同步,需要简单快捷一并完成各服务已经分支迁移。 一、在新的目标git中创建新代码仓 新…...

用CHATGPT生成C++面试题及答案
以下是C的面试题及其答案: 什么是C?C与C语言有什么区别? C是一种高级编程语言,是对C语言的扩展。C具有更强大的面向对象编程能力,支持类、继承、多态等特性。 什么是面向对象编程? 面向对象编程是一种编程…...

二进制,八进制,十进制,十六进制的相互转换【简单易懂】(含代码模板)
目录 二进制转十进制 十进制原理: 二进制转十进制计算: 八、十六进制转十进制 八、十六进制转十进制计算: 十进制转其他进制 十进制转二进制: 十进制转八进制: 十进制转十六进制: 不同进制之间的相互转…...
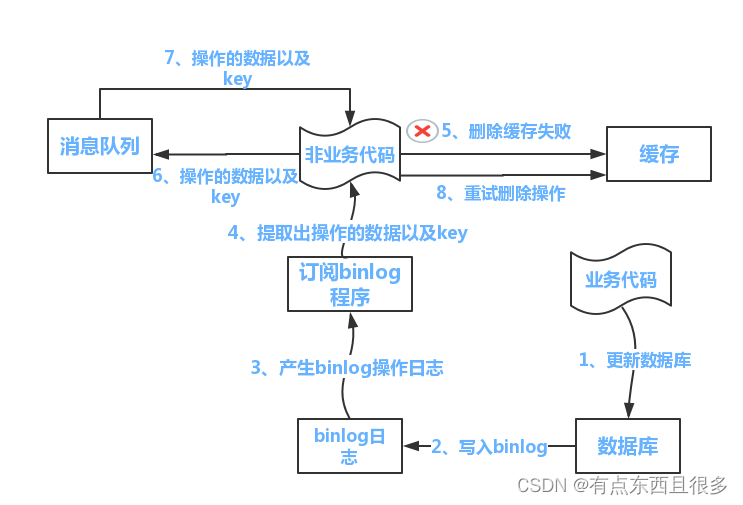
Redis技术详解
Redis技术详解 Redis是一种支持key-value等多种数据结构的存储系统。可用于缓存,事件发布或订阅,高速队列等场景。支持网络,提供字符串,哈希,列表,队列,集合结构直接存取,基于内存&…...

Windows 11下用VSCode+CMake+MinGW编译OpenCV 4.8.0,保姆级避坑指南
Windows 11下用VSCodeCMakeMinGW编译OpenCV 4.8.0全流程实战 最近在Windows 11上配置OpenCV开发环境时,发现很多教程都存在版本过时或Win11特有兼容性问题。本文将分享一套经过验证的最新工具链组合:VSCode 1.85CMake 3.28MinGW-w64 12.2OpenCV 4.8.0。不…...

告别“人工智障”!OpenClaw + 大模型:打造真正能“看懂、想通、干成”的机械臂智能体
写在前面 在机器人圈子里,有个心照不宣的痛点:机械臂越来越便宜,但让它“听话”却越来越难。 传统的示教编程(Teaching Pendant)太慢,改个产品就得重教一遍;视觉定位(Vision Guided&…...

EmbeddingGemma-300m在Mathtype公式的语义理解中的应用
EmbeddingGemma-300m在Mathtype公式的语义理解中的应用 1. 引言 数学公式的语义理解一直是自然语言处理领域的挑战性任务。传统的文本嵌入模型在处理复杂的数学表达式时往往力不从心,无法准确捕捉公式背后的数学含义和逻辑关系。EmbeddingGemma-300m作为Google最新…...

法律文书助手:OpenClaw+Qwen3-32B的合同条款审查与风险提示
法律文书助手:OpenClawQwen3-32B的合同条款审查与风险提示 1. 为什么需要本地化的法律文书助手? 去年处理一份股权投资协议时,我经历了传统法律AI工具的典型痛点:上传合同到第三方平台后,法务团队突然发现协议中涉及…...

DeepSeek-OCR实战教程:批量处理脚本编写与异步解析任务队列设计
DeepSeek-OCR实战教程:批量处理脚本编写与异步解析任务队列设计 1. 学习目标与场景引入 如果你正在处理大量的文档图片,比如扫描的合同、发票、报告或者历史档案,一张张上传到DeepSeek-OCR界面手动处理,不仅效率低下,…...

大语言模型训练中的显存占用与优化方法简述
在进行大语言模型(LLM)的微调或预训练时,显存(VRAM)不足通常是首要面临的问题。为了在有限的硬件资源下完成训练,了解显存的具体去向以及相应的优化技术是比较基础的工作。 从模型训练的流程来看ÿ…...
从音频生成到DNA分析:手把手带你用S4和Hyena搞定Transformer不擅长的那些长序列任务
从音频生成到DNA分析:手把手带你用S4和Hyena搞定Transformer不擅长的那些长序列任务 当我们需要处理长达数小时的音频波形、百万碱基对的DNA序列或整本小说级别的文本时,传统Transformer架构很快就会遇到计算瓶颈。本文将带您探索两种突破性的序列建模方…...

华为光猫配置解密工具技术架构解析与实现机制
华为光猫配置解密工具技术架构解析与实现机制 【免费下载链接】HuaWei-Optical-Network-Terminal-Decoder 项目地址: https://gitcode.com/gh_mirrors/hu/HuaWei-Optical-Network-Terminal-Decoder 在网络设备运维领域,华为光猫配置文件的安全加密机制为设备…...

从定时器到任务调度:用Qt QTimer和QThreadPool构建一个轻量级后台任务管理器
从定时器到任务调度:用Qt QTimer和QThreadPool构建轻量级后台任务管理器 在开发中型Qt应用时,后台任务管理往往成为架构设计的痛点。当简单的定时器无法满足复杂业务需求,当主线程被耗时任务拖累导致界面卡顿,开发者需要一套更优雅…...

RWKV7-1.5B-g1a惊艳案例:将复杂段落压缩为三条逻辑闭环要点
RWKV7-1.5B-g1a惊艳案例:将复杂段落压缩为三条逻辑闭环要点 1. 模型能力展示:从复杂到简洁的文本处理 RWKV7-1.5B-g1a作为一款轻量级文本生成模型,在信息压缩和提炼方面展现出令人惊喜的能力。我们通过一个实际案例来展示它如何将复杂内容转…...