Redis实践
Redis实践
使用复杂度高的命令
如果在使用Redis时,发现访问延迟突然增大,如何进行排查?
首先,第一步,建议你去查看一下Redis的慢日志。Redis提供了慢日志命令的统计功能,我们通过以下设置,就可以查看有哪些命令在执行时延迟比较大。
首先设置Redis的慢日志阈值,只有超过阈值的命令才会被记录,这里的单位是微妙,例如设置慢日志的阈值为5毫秒,同时设置只保留最近1000条慢日志记录:
# 命令执行超过5毫秒记录慢日志
CONFIG SET slowlog-log-slower-than 5000
# 只保留最近1000条慢日志
CONFIG SET slowlog-max-len 1000
设置完成之后,所有执行的命令如果延迟大于5毫秒,都会被Redis记录下来,我们执行SLOWLOG get 5查询最近5条慢日志:
127.0.0.1:6379> SLOWLOG get 5
1) 1) (integer) 32693 # 慢日志ID2) (integer) 1593763337 # 执行时间3) (integer) 5299 # 执行耗时(微妙)4) 1) "LRANGE" # 具体执行的命令和参数2) "user_list_2000"3) "0"4) "-1"
2) 1) (integer) 326922) (integer) 15937633373) (integer) 50444) 1) "GET"2) "book_price_1000"
...
通过查看慢日志记录,我们就可以知道在什么时间执行哪些命令比较耗时,如果你的业务经常使用O(n)以上复杂度的命令,例如sort、sunion、zunionstore,或者在执行O(n)命令时操作的数据量比较大,这些情况下Redis处理数据时就会很耗时。
如果你的服务请求量并不大,但Redis实例的CPU使用率很高,很有可能是使用了复杂度高的命令导致的。
存储大key
如果查询慢日志发现,并不是复杂度较高的命令导致的,例如都是SET、DELETE操作出现在慢日志记录中,那么你就要怀疑是否存在Redis写入了大key的情况。
Redis在写入数据时,需要为新的数据分配内存,当从Redis中删除数据时,它会释放对应的内存空间。
如果一个key写入的数据非常大,Redis在分配内存时也会比较耗时。同样的,当删除这个key的数据时,释放内存也会耗时比较久。
你需要检查你的业务代码,是否存在写入大key的情况,需要评估写入数据量的大小,业务层应该避免一个key存入过大的数据量。
那么有没有什么办法可以扫描现在Redis中是否存在大key的数据吗?
Redis也提供了扫描大key的方法:
redis-cli -h <span class="katex--inline"><span class="katex"><span class="katex-mathml"><math xmlns="http://www.w3.org/1998/Math/MathML"><semantics><mrow><mi>h</mi><mi>o</mi><mi>s</mi><mi>t</mi><mo>−</mo><mi>p</mi></mrow><annotation encoding="application/x-tex">host -p </annotation></semantics></math></span><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:0.7778em;vertical-align:-0.0833em;"><span class="mord mathnormal">h</span><span class="mord mathnormal">os</span><span class="mord mathnormal">t</span><span class="mspace" style="margin-right:0.2222em;"><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222em;"></span><span class="base"><span class="strut" style="height:0.625em;vertical-align:-0.1944em;"><span class="mord mathnormal">p</span></span></span></span></span>port --bigkeys -i 0.01
</span></span></span></span>使用上面的命令就可以扫描出整个实例key大小的分布情况,它是以类型维度来展示的。
需要注意的是当我们在线上实例进行大key扫描时,Redis的QPS会突增,为了降低扫描过程中对Redis的影响,我们需要控制扫描的频率,使用i参数控制即可,它表示扫描过程中每次扫描的时间间隔,单位是秒。
使用这个命令的原理,其实就是Redis在内部执行scan命令,遍历所有key,然后针对不同类型的key执行strlen、llen、hlen、scard、zcard来获取字符串的长度以及容器类型(list/dict/set/zset)的元素个数。
而对于容器类型的key,只能扫描出元素最多的key,但元素最多的key不一定占用内存最多,这一点需要我们注意下。不过使用这个命令一般我们是可以对整个实例中key的分布情况有比较清晰的了解。
针对大key的问题,Redis官方在4.0版本推出了lazy-free的机制,用于异步释放大key的内存,降低对Redis性能的影响。
即使这样,我们也不建议使用大key,大key在集群的迁移过程中,也会影响到迁移的性能
集中过期
有时你会发现,平时在使用Redis时没有延时比较大的情况,但在某个时间点突然出现一波延时,而且报慢的时间点很有规律,例如某个整点,或者间隔多久就会发生一次。
如果出现这种情况,就需要考虑是否存在大量key集中过期的情况。
如果有大量的key在某个固定时间点集中过期,在这个时间点访问Redis时,就有可能导致延迟增加。
解决方案是,在集中过期时增加一个随机时间,把这些需要过期的key的时间打散即可 。
伪代码可以这么写:
# 在过期时间点之后的5分钟内随机过期掉
redis.expireat(key, expire_time + random(300))
实例内存达到上限
有时我们把Redis当做纯缓存使用,就会给实例设置一个内存上限maxmemory,然后开启LRU淘汰策略。
当实例的内存达到了maxmemory后,你会发现之后的每次写入新的数据,有可能变慢了。
导致变慢的原因是,当Redis内存达到maxmemory后,每次写入新的数据之前,必须先踢出一部分数据,让内存维持在maxmemory之下。
这个踢出旧数据的逻辑也是需要消耗时间的,而具体耗时的长短,要取决于配置的淘汰策略:
- allkeys-lru:不管key是否设置了过期,淘汰最近最少访问的key
- volatile-lru:只淘汰最近最少访问并设置过期的key
- allkeys-random:不管key是否设置了过期,随机淘汰
- volatile-random:只随机淘汰有设置过期的key
- allkeys-ttl:不管key是否设置了过期,淘汰即将过期的key
- noeviction:不淘汰任何key,满容后再写入直接报错
- allkeys-lfu:不管key是否设置了过期,淘汰访问频率最低的key(4.0+支持)
- volatile-lfu:只淘汰访问频率最低的过期key(4.0+支持)
我们最常使用的一般是allkeys-lru或volatile-lru策略,它们的处理逻辑是,每次从实例中随机取出一批key(可配置),然后淘汰一个最少访问的key,之后把剩下的key暂存到一个池子中,继续随机取出一批key,并与之前池子中的key比较,再淘汰一个最少访问的key。以此循环,直到内存降到maxmemory之下。
如果使用的是allkeys-random或volatile-random策略,那么就会快很多,因为是随机淘汰,那么就少了比较key访问频率时间的消耗了,随机拿出一批key后直接淘汰即可,因此这个策略要比上面的LRU策略执行快一些。
fork耗时严重
如果你的Redis开启了自动生成RDB和AOF重写功能,那么有可能在后台生成RDB和AOF重写时导致Redis的访问延迟增大,而等这些任务执行完毕后,延迟情况消失。
遇到这种情况,一般就是执行生成RDB和AOF重写任务导致的。
生成RDB和AOF都需要父进程fork出一个子进程进行数据的持久化,在fork执行过程中,父进程需要拷贝内存页表给子进程,如果整个实例内存占用很大,那么需要拷贝的内存页表会比较耗时,此过程会消耗大量的CPU资源,在完成fork之前,整个实例会被阻塞住,无法处理任何请求,如果此时CPU资源紧张,那么fork的时间会更长,甚至达到秒级。这会严重影响Redis的性能。
我们可以执行info命令,查看最后一次fork执行的耗时latest_fork_usec,单位微妙。这个时间就是整个实例阻塞无法处理请求的时间。
要想避免这种情况,我们需要规划好数据备份的周期,建议在从节点上执行备份,而且最好放在低峰期执行。如果对于丢失数据不敏感的业务,那么不建议开启RDB和AOF重写功能。
另外,fork的耗时也与系统有关,如果把Redis部署在虚拟机上,那么这个时间也会增大。所以使用Redis时建议部署在物理机上,降低fork的影响。
使用Swap
如果你发现Redis突然变得非常慢,每次访问的耗时都达到了几百毫秒甚至秒级,那此时就检查Redis是否使用到了Swap,这种情况下Redis基本上已经无法提供高性能的服务。
我们知道,操作系统提供了Swap机制,目的是为了当内存不足时,可以把一部分内存中的数据换到磁盘上,以达到对内存使用的缓冲。
但当内存中的数据被换到磁盘上后,访问这些数据就需要从磁盘中读取,这个速度要比内存慢太多!
尤其是针对Redis这种高性能的内存数据库来说,如果Redis中的内存被换到磁盘上,对于Redis这种性能极其敏感的数据库,这个操作时间是无法接受的。
我们需要检查机器的内存使用情况,确认是否确实是因为内存不足导致使用到了Swap。
如果确实使用到了Swap,要及时整理内存空间,释放出足够的内存供Redis使用,然后释放Redis的Swap,让Redis重新使用内存。
释放Redis的Swap过程通常要重启实例,为了避免重启实例对业务的影响,一般先进行主从切换,然后释放旧主节点的Swap,重新启动服务,待数据同步完成后,再切换回主节点即可。
可见,当Redis使用到Swap后,此时的Redis的高性能基本被废掉,所以我们需要提前预防这种情况。
我们需要对Redis机器的内存和Swap使用情况进行监控,在内存不足和使用到Swap时及时报警出来,及时进行相应的处理 。
网卡负载过高
特点就是从某个时间点之后就开始变慢,并且一直持续。这时你需要检查一下机器的网卡流量,是否存在网卡流量被跑满的情况。
网卡负载过高,在网络层和TCP层就会出现数据发送延迟、数据丢包等情况。Redis的高性能除了内存之外,就在于网络IO,请求量突增会导致网卡负载变高。
相关文章:

Redis实践
Redis实践 使用复杂度高的命令 如果在使用Redis时,发现访问延迟突然增大,如何进行排查? 首先,第一步,建议你去查看一下Redis的慢日志。Redis提供了慢日志命令的统计功能,我们通过以下设置,就…...

【Lora模型推荐】Stable Diffusion创作具有玉石翡翠质感的图标设计
站长素材AI教程是站长之家旗下AI绘图教程平台 海量AI免费教程,每日更新干货内容 想要深入学习更多AI绘图教程,请访问站长素材AI教程网: AI教程_深度学习入门指南 - 站长素材 (chinaz.com) logo版权归各公司所有!本笔记仅供AIGC…...

vscode 远程开发
目录 vscode 远程连接 选择 Python 环境 vscode 远程连接 按 CtrlShiftP 打开命令面板。输入并选择 Remote-SSH: Open SSH Configuration File...。选择 ~/.ssh/config 文件(如果有多个选项)。在打开的文件中添加或修改你的 SSH 配置。 这个可以右键…...
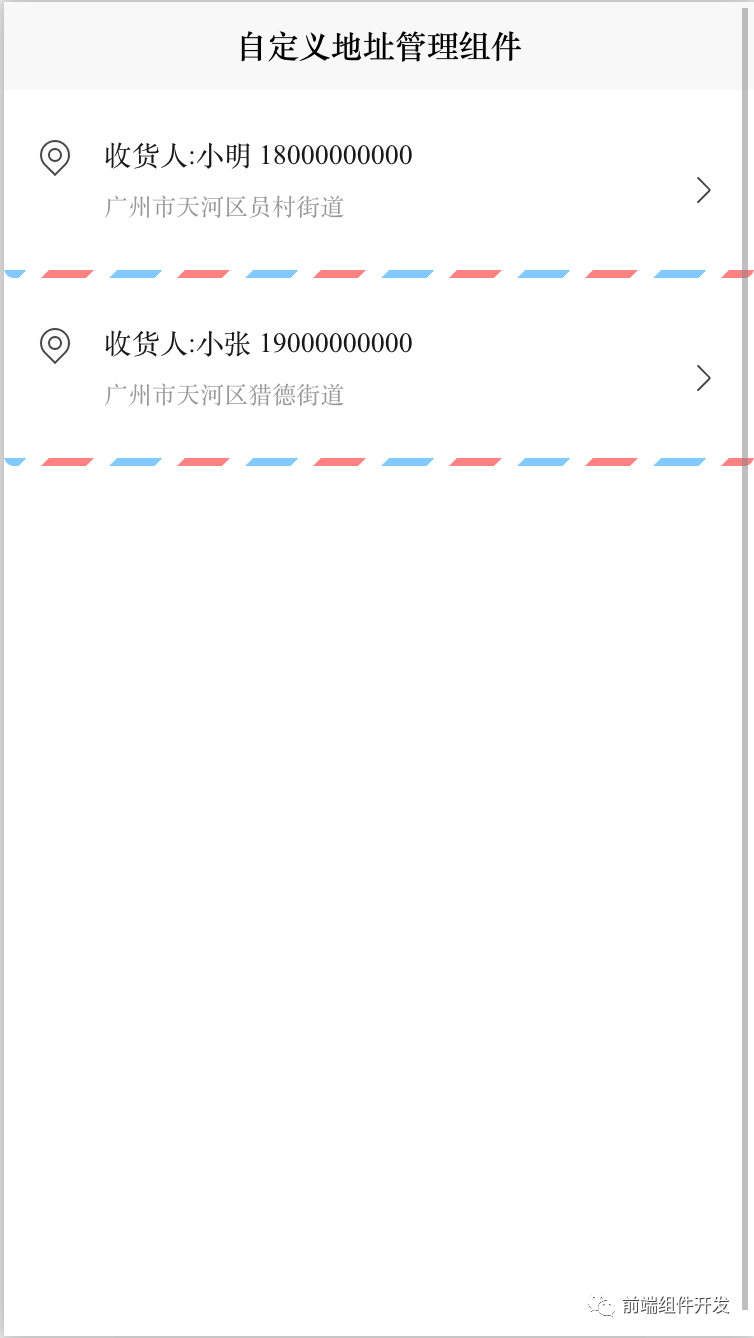
前端Vue组件化实践:打造灵活可维护的地址管理组件
随着前端技术的不断演进,复杂度和开发难度也随之上升。传统的一体化开发模式使得每次小小的修改或功能增加都可能牵一发而动全身,严重影响了开发效率和维护成本。组件化开发作为一种解决方案,通过模块化、独立化的开发方式,实现了…...

虚幻引擎ue5游戏运行界面白茫茫一片,怎么处理
根剧下图顺序即可调节游戏运行界面光照问题: 在大纲里找到post,然后选中它,找到Exposure 把最低亮度和最高亮度的0改为1即可...

《代理选择与反爬虫策略探究:如何优化网络爬虫效率与稳定性》
代理IP如何选以及常见反爬策略 为什么需要代理? 因为有的网站会封IP,用户如果没有登录,那IP就是身份标识,如果网站发现用户行为异常就非常可能封IP 什么是代理IP 就是让一个人帮你转交请求,帮你转交的人对面不熟&a…...

Kotlin Flow 防抖 节流
防抖和节流是针对响应跟不上触发频率这类问题的两种解决方案。 一:防抖(debounce)的概念: 防抖是指当持续触发事件时,一定时间段内没有再触发事件,事件处理函数才会执行一次, 如果设定时间到来之前&#x…...

Android Studio下载与安装
Android Studio下载与安装_android studio下载安装-CSDN博客...

【LC刷题】DAY24:122 55 45 1005
122. 买卖股票的最佳时机 II class Solution { public:int maxProfit(vector<int>& prices) {int result 0;for(int i 1; i < prices.size(); i ){result max(prices[i] - prices[ i - 1], 0);}return result;} };55. 跳跃游戏 link class Solution { public…...

从零开始的python学习生活2
接上封装 class Phone:__volt0.5def __keepsinglecore(self):print("让cpu以单核运行")def if5G(self):if self.__volt>1:print("5G通话已开启")else:self.__keepsinglecore()print("电量不足,无法使用5G通话,已经设置为单…...

【并发编程】进程 线程 协程
进程(Process)、线程(Thread)和协程(Coroutine)构成了计算机科学中实现任务并发执行的三种核心抽象机制。通常,为了提高程序的执行效率,开发者会根据应用场景和性能需求,…...

Vue的生命周期函数有哪些?详细说明
Vue.js 的生命周期函数包括以下几个阶段,每个阶段都有相应的钩子函数可以用来在特定时机执行自定义的逻辑。这些生命周期钩子函数使得我们可以在组件的不同阶段进行操作,从而管理组件的状态和行为。 1. beforeCreate: - 描述:…...

大语言模型应用--AI工程化落地
文章目录 大语言模型概述什么是大语言模型什么是机器学习什么是深度学习 理解大语言模型历史沿革关键 AIGC系统AI工程化项目的落地落地的方法Prompt工程(第一阶段)RAG检索(第二阶段)训练特定功能模型(第三阶段…...

我会什么开发技能
java我会什么? 一、并发编程 1、并发编程:jdk中的courren包只能够类实现(seamplore,CountDownLaunch,Pharse,CycliBarrier,CompletableFuture),AQS的原理,线…...

Run LoongArch64 Alpine VM on x86_64
一、Build from source(build on x86_64) Obtain the latest libvirt, virt-manager, and qemu source code, compile and install them. 1.1 Build libvirt from source sudo apt-get update sudo apt-get install augeas-tools bash-completion debhelper-compat dh-apparm…...

4层负载均衡和7层负载均衡
四层负载均衡(Layer 4 Load Balancing)指的是在网络传输层(TCP/IP模型中的第四层)进行负载均衡的技术。四层负载均衡通常使用IP地址、端口号和协议等信息来将网络流量分配到多个服务器上。它主要关心网络层的信息,不涉…...
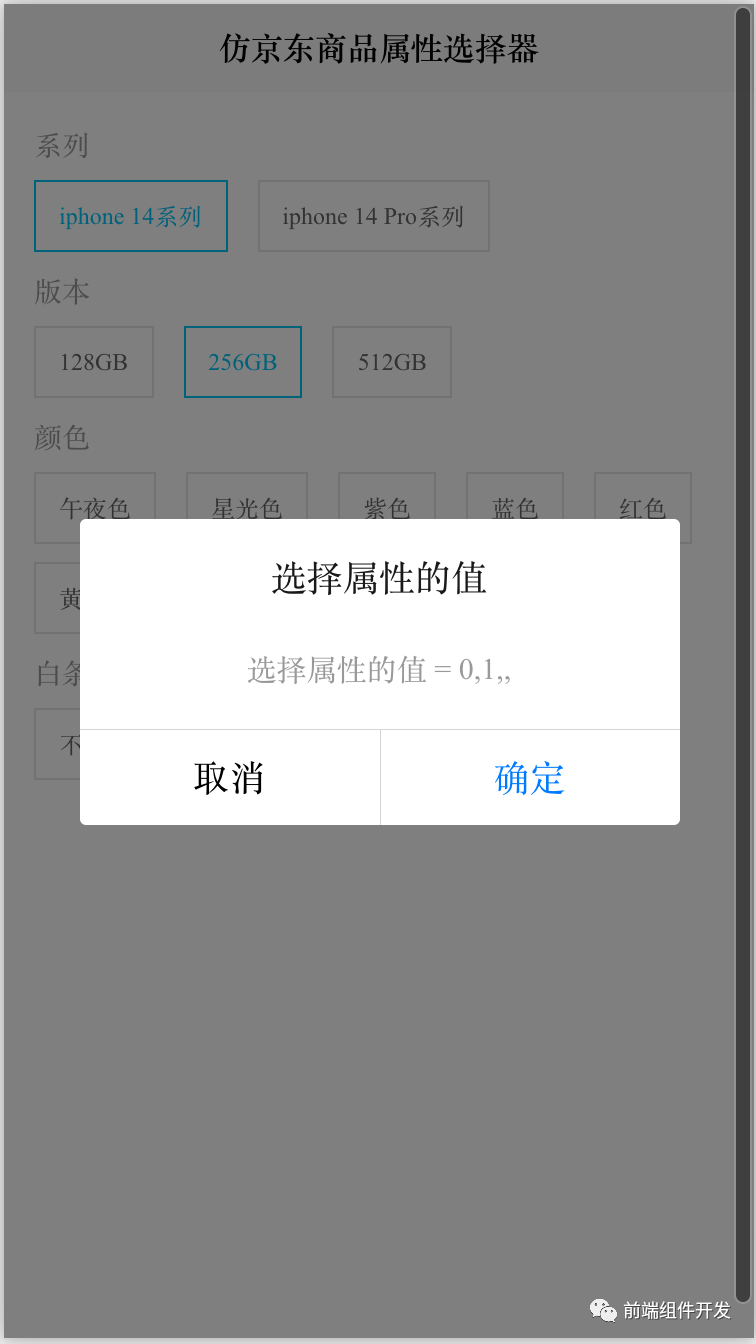
前端Vue组件化实践:打造仿京东天猫商品属性选择器组件
在前端开发领域,随着业务需求的日益复杂和技术的不断进步,传统的整体式应用开发模式已逐渐显得捉襟见肘。面对日益庞大的系统,每次微小的功能修改或增加都可能导致整个逻辑结构的重构,形成牵一发而动全身的困境。为了解决这一问题…...

智慧城市3d数据可视化系统提升信息汇报的时效和精准度
在信息大爆炸的时代,数据的力量无可估量。而如何将这些数据以直观、高效的方式呈现出来,成为了一个亟待解决的问题。为此,我们推出了全新的3D可视化数据大屏系统,让数据“跃然屏上”,助力您洞察先机,决胜千…...

Git 详解(原理、使用)
git 快速上手请看这篇博客 Git 快速上手 1. 什么是 Git Git 是目前最主流的一个版本控制器,并且是分布式版本控制系统,可以控制电脑上所有格式的文档 版本控制器:记录每次修改以及版本迭代的管理系统 对于文本文件,可以记录每次…...
)
android11为开机动画添加铃声(语音)
一、碰到的问题 1、第一次开机无铃声 2、开机时铃声和动画不同步,开头的铃声会丢失 3、开机时铃声/动画不能完全播放完 二、解决 以下为添加的patch /开机铃声不同步,语音第一段无声 diff --git a/media/libmediaplayerservice/MediaPlayerService…...

C++详解实现Stack方法
栈简介栈本着先进后出的原则,来存取数据。作为数据结构中的一种,这里不多介绍相关栈。仅以此文记录C中栈的实现,可帮助提升编程能力与对栈的理解。stack模拟stack是一种容器适配器,专门在具有后进先出的上下文环境中,其…...
)
直线模组选型别再“先选电机“了!导程才是起点(附正向推导五步法)
引言:一个高频"翻车"现场在直线模组(丝杆模组)选型中,有个环节经常出现逆向翻车——工程师先选好了电机,再去配丝杆导程,结果发现:❌ 速度上不去❌ 推力不够大❌ 电机严重发热问题的根…...

保姆级教程:手把手教你用Python搭建HTTP服务器,为安信可BL602模组OTA升级铺路
从零构建Python HTTP服务器:物联网开发者的OTA升级基石 在物联网设备开发中,固件升级(OTA)是产品生命周期管理的关键环节。想象一下这样的场景:当您需要为部署在数百公里外的设备更新功能时,无需物理接触设备,只需通过…...

ESP32-C3 I²S实战:手把手教你驱动ES8311音频编解码器实现回声消除
ESP32-C3与ES8311音频系统实战:从硬件连接到回声消除算法优化 在智能语音交互设备、会议系统和便携式录音设备中,音频处理能力已成为核心需求。ESP32-C3作为一款高性价比的Wi-Fi/BLE双模芯片,其内置的IS接口为音频应用提供了专业级数字音频传…...

RollBack RX Professional 快照管理避坑指南:锁定、任务属性设置与常见误区解析
RollBack RX Professional 快照管理避坑指南:锁定、任务属性设置与常见误区解析 在系统维护和数据安全领域,快照技术已经成为保障业务连续性的重要手段。RollBack RX Professional作为一款专业的系统还原工具,其快照管理功能在实际应用中展现…...

Omdia:2025年第一季度,东南亚手机市场下滑9%,但厂商利润率正在改善
Omdia最新研究显示,2026年第一季度东南亚智能手机市场出货量同比下降 9%,总量为 2160万部。然而,市场最值得关注的并非出货量下滑,而是平均售价(ASP)的变化:受存储成本上涨影响,2026…...

从审稿人到作者:我审了10篇论文后,总结出的5个投稿避坑指南和3个加分项
从审稿人到作者:10篇论文审阅经验提炼的5大避坑策略与3个关键加分项 第一次收到审稿邀请时,我正对着自己第三篇被拒的论文修改意见发呆。这种身份错位带来的震撼,让我开始系统记录审稿笔记——如今这些笔记已形成超过2万字的"审稿人思维…...

ZYNQ平台SGMII光口实战:从Vivado连线、设备树到静态IP设置的完整避坑指南
ZYNQ平台SGMII光口实战:从Vivado连线到静态IP部署的全流程解析 在嵌入式系统开发中,以太网通信的稳定实现往往是项目成功的关键。对于采用Xilinx ZYNQ系列FPGA的开发者而言,SGMII(Serial Gigabit Media Independent Interface&…...
)
告别网页版!用Alist+RaiDrive把阿里云盘、百度网盘变成电脑本地文件夹(保姆级教程)
一键打造云端硬盘:AlistRaiDrive实现本地化文件管理全攻略 你是否经常在多个云盘平台间频繁切换,忍受着网页端上传下载的龟速?每次想修改云盘里的文档,都得先下载到本地,编辑完再重新上传?今天我要分享的这…...

RISC-V RTOS任务栈与上下文切换:寄存器保存策略与栈初始化详解
1. 项目概述与核心问题上一篇文章我们聊了RISC-V内核单片机移植RTOS时,任务切换的“开关”——中断与异常机制是如何工作的。今天,我们顺着这个思路,深入到最核心的“现场保护”环节:当一个任务被切换出去时,它的“工作…...