Python库 - Scrapy
Scrapy 是一个用于爬取网站数据、提取结构性数据的开源和协作框架。它最初是为网页抓取设计的,但也可以用于获取 API 提供的数据或作为通用的网络爬虫。
文章目录
- 主要特性
- 主要组件
- 使用流程
- 1. 安装 Scrapy
- 2. 创建 Scrapy 项目
- 3. 定义 Item(数据)
- 4. 创建和编写 Spiders 文件
- 5. 修改 settings.py 文件
- 6. 运行 Scrapy 爬虫
- 运行项目生成文件说明
- 1. `scrapy.cfg`
- 2. `myproject/`
- a. `__init__.py`
- b. `items.py`
- c. `middlewares.py`
- d. `pipelines.py`
- e. `settings.py`
- 3. `myproject/spiders/`
- a. `__init__.py`
- b. `myspider.py`
- 数据存储
- 1. 文件存储
- a. JSON 文件
- b. CSV 文件
- 2. 数据库存储
- a. SQLite
- b. MySQL
- c. MongoDB
- 3. 其他存储方式
- a. Elasticsearch
- b. Amazon S3
主要特性
- 异步处理:Scrapy 使用 Twisted 异步网络库,可以高效处理多个并发请求。
- 内置支持选择器:Scrapy 内置支持 XPath 和 CSS 选择器来提取数据。
- 数据管道:提供数据处理管道,可以对抓取的数据进行清洗、验证和存储。
- 中间件:支持下载中间件和爬虫中间件,可以在请求和响应处理过程中插入自定义逻辑。
- 扩展性:可以通过编写扩展和中间件来扩展 Scrapy 的功能。
- 支持多种输出格式:可以将抓取的数据导出为 JSON、CSV、XML 等格式。
- 自动限速:内置支持自动限速,可以防止对目标网站造成过大压力。
主要组件
- Spider(爬虫):定义如何抓取某个网站或一组网站,包括如何执行抓取(即跟进链接)以及如何从页面中提取结构化数据。
- Item(项目):定义抓取的数据结构,类似于 Python 中的字典,但提供了更强的类型检查和验证。
- Item Pipeline(项目管道):负责处理被抓取的项目,通常包括数据清洗、验证和存储。
- Downloader Middleware(下载中间件):处理请求和响应的钩子框架,可以用于修改、丢弃或重试请求。
- Spider Middleware(爬虫中间件):处理爬虫的输入(响应)和输出(请求和项目)的钩子框架。
使用流程
Scrapy 是一个强大的 Python 爬虫框架,用于从网站中提取数据。以下是从创建项目到运行爬虫的详细步骤:
1. 安装 Scrapy
首先,需要安装 Scrapy。可以使用 pip 进行安装:
pip install scrapy
2. 创建 Scrapy 项目
使用以下命令创建一个新的 Scrapy 项目:
scrapy startproject myproject
这将在当前目录下创建一个名为 myproject 的文件夹,包含 Scrapy 项目的结构。
3. 定义 Item(数据)
Item 是用来定义要从网页中提取的数据结构。在 myproject/items.py 文件中定义 Item:
import scrapyclass MyItem(scrapy.Item):# 定义字段name = scrapy.Field()description = scrapy.Field()
4. 创建和编写 Spiders 文件
Spider 是 Scrapy 中用于定义如何抓取网站的类。在 myproject/spiders 目录下创建一个新的 Spider 文件,例如 myspider.py:
import scrapy
from myproject.items import MyItemclass MySpider(scrapy.Spider):name = "myspider"start_urls = ['http://example.com',]def parse(self, response):for item in response.css('div.item'):my_item = MyItem()my_item['name'] = item.css('h1::text').get()my_item['description'] = item.css('p::text').get()yield my_item
5. 修改 settings.py 文件
在 myproject/settings.py 文件中,可以配置 Scrapy 的各种设置,例如 USER_AGENT、ROBOTSTXT_OBEY 等:
BOT_NAME = 'myproject'SPIDER_MODULES = ['myproject.spiders']
NEWSPIDER_MODULE = 'myproject.spiders'USER_AGENT = 'Mozilla/5.0 (compatible; MyProject/1.0; +http://example.com)'ROBOTSTXT_OBEY = True
6. 运行 Scrapy 爬虫
使用以下命令运行的 Spider:
scrapy crawl myspider
这将启动 myspider 并开始抓取数据。
运行项目生成文件说明
1. scrapy.cfg
这是项目的配置文件,通常位于项目的根目录下。它主要用于定义项目的部署配置。
[settings]
default = myproject.settings[deploy]
#url = http://localhost:6800/
project = myproject
2. myproject/
这是项目的主目录,包含了项目的所有代码和配置文件。
a. __init__.py
这是一个空文件,用于标识 myproject 目录是一个 Python 包。
b. items.py
这个文件用于定义爬虫抓取的数据结构,即 Item。Item 类似于数据库中的表结构,用于存储爬取到的数据字段。
import scrapyclass MyItem(scrapy.Item):name = scrapy.Field()description = scrapy.Field()
c. middlewares.py
这个文件用于定义自定义的中间件。中间件可以用于处理请求和响应,例如添加自定义的 HTTP 头、处理重定向等。
class MyCustomMiddleware(object):def process_request(self, request, spider):request.headers['User-Agent'] = 'MyCustomUserAgent'return None
d. pipelines.py
这个文件用于定义数据处理管道。管道用于在数据被爬取后进行处理,例如清洗数据、验证数据、存储数据等。
class MyPipeline(object):def process_item(self, item, spider):# 处理 item 的逻辑return item
e. settings.py
这个文件包含了项目的所有配置。可以在这里设置爬虫的行为,例如设置 User-Agent、启用中间件、配置管道等。
BOT_NAME = 'myproject'SPIDER_MODULES = ['myproject.spiders']
NEWSPIDER_MODULE = 'myproject.spiders'USER_AGENT = {}
ROBOTSTXT_OBEY = TrueITEM_PIPELINES = {'myproject.pipelines.MyPipeline': 300,
}
3. myproject/spiders/
这个目录用于存放爬虫的代码。可以在这里创建多个爬虫文件,每个文件定义一个爬虫。
a. __init__.py
这是一个空文件,用于标识 spiders 目录是一个 Python 包。
b. myspider.py
这是一个示例爬虫文件,用于定义如何抓取网站的数据。
import scrapyclass MySpider(scrapy.Spider):name = "myspider"start_urls = ['http://example.com',]def parse(self, response):for item in response.css('div.item'):yield {'name': item.css('h1::text').get(),'description': item.css('p::text').get(),}
数据存储
1. 文件存储
a. JSON 文件
JSON 是一种轻量级的数据交换格式,易于阅读和编写。
import jsondef process_item(item):with open('data.json', 'a') as f:line = json.dumps(dict(item)) + "\n"f.write(line)return item
b. CSV 文件
CSV 文件是一种简单的表格数据存储格式。
import csvdef process_item(item):with open('data.csv', 'a', newline='') as f:writer = csv.writer(f)writer.writerow(item.values())return item
2. 数据库存储
a. SQLite
SQLite 是一种嵌入式数据库,适合小型项目。
import sqlite3def process_item(item):conn = sqlite3.connect('data.db')c = conn.cursor()c.execute("INSERT INTO items VALUES (?, ?)", (item['name'], item['description']))conn.commit()conn.close()return item
b. MySQL
MySQL 是一种流行的关系型数据库,适合大型项目。
import mysql.connectordef process_item(item):conn = mysql.connector.connect(user='user', password='password', host='host', database='database')c = conn.cursor()c.execute("INSERT INTO items (name, description) VALUES (%s, %s)", (item['name'], item['description']))conn.commit()conn.close()return item
c. MongoDB
MongoDB 是一种 NoSQL 数据库,适合存储非结构化数据。
from pymongo import MongoClientdef process_item(item):client = MongoClient('localhost', 27017)db = client['mydatabase']collection = db['items']collection.insert_one(dict(item))return item
3. 其他存储方式
a. Elasticsearch
Elasticsearch 是一个基于 Lucene 的搜索引擎,适合存储和搜索大量数据。
from elasticsearch import Elasticsearchdef process_item(item):es = Elasticsearch()es.index(index='items', doc_type='item', body=dict(item))return item
b. Amazon S3
Amazon S3 是一种云存储服务,适合存储大量文件。
import boto3def process_item(item):s3 = boto3.client('s3')s3.put_object(Bucket='mybucket', Key='data.json', Body=json.dumps(dict(item)))return item
相关文章:

Python库 - Scrapy
Scrapy 是一个用于爬取网站数据、提取结构性数据的开源和协作框架。它最初是为网页抓取设计的,但也可以用于获取 API 提供的数据或作为通用的网络爬虫。 文章目录 主要特性主要组件使用流程1. 安装 Scrapy2. 创建 Scrapy 项目3. 定义 Item(数据ÿ…...

函数(实参以及形参)
实际参数(实参) 实际参数就是在调用函数时传递给函数的具体值。这些值可以是常量、变量、表达式或更复杂的数据结构。实参的值在函数被调用时传递给对应的形参,然后函数内部就可以使用这些值来执行相应的操作。 int main() {int a 0;int b …...
地理数据库 8 拓扑)
ArcGIS Pro SDK (八)地理数据库 8 拓扑
ArcGIS Pro SDK (八)地理数据库 8 拓扑 文章目录 ArcGIS Pro SDK (八)地理数据库 8 拓扑1 开放拓扑和进程定义2 获取拓扑规则3 验证拓扑4 获取拓扑错误5 标记和不标记为错误6 探索拓扑图7 找到最近的元素 环境:Visual …...

uniapp如何发送websocket请求
方法1: onLoad() {uni.connectSocket({url: ws://127.0.0.1:8000/ws/stat/realTimeStat/,success: (res) > {console.log(connect success, res);}});uni.onSocketOpen(function (res) {console.log(WebSocket连接已打开!);uni.sendSocketMessage({d…...

RabbitMQ的工作模式
RabbitMQ的工作模式 Hello World 模式 #mermaid-svg-sbc2QNYZFRQYbEib {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-sbc2QNYZFRQYbEib .error-icon{fill:#552222;}#mermaid-svg-sbc2QNYZFRQYbEib .error-text{fi…...
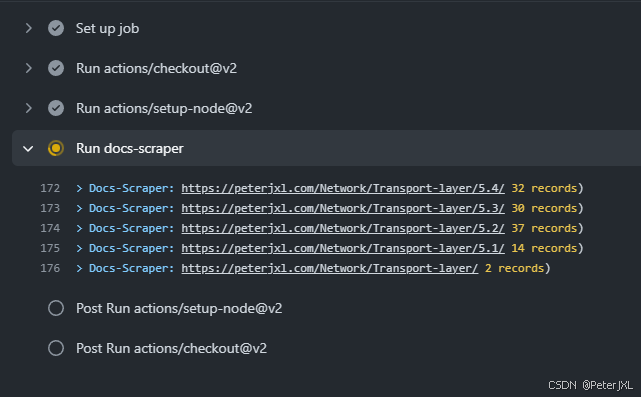
自建搜索引擎-基于美丽云
Meilisearch 是一个搜索引擎,主程序完全开源,除了使用官方提供的美丽云服务(收费)进行对接之外,还可以通过自建搜索引擎来实现完全独立的搜索服务。 由于成本问题,本博客采用自建的方式,本文就…...
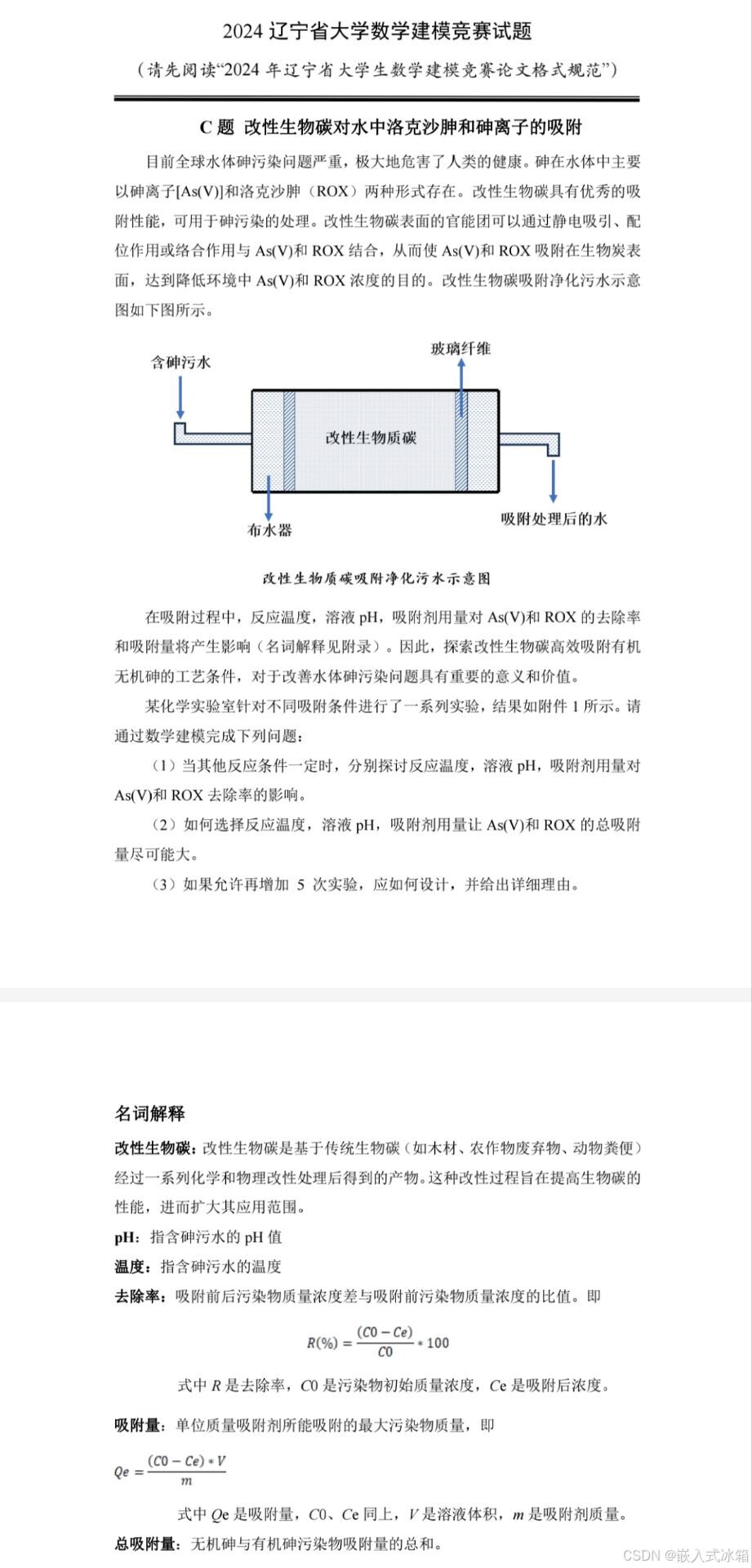
2024辽宁省大学数学建模竞赛试题思路
A题 (1) 建立模型分析低空顺风风切变对起飞和降落的影响 模型假设 飞机被视为质点,忽略其尺寸和形状对风阻的影响。风切变仅考虑顺风方向的变化,忽略其他方向的风切变。飞机的飞行速度、高度和姿态(如迎角、俯仰角)是变化的&am…...
循环结构(一)——for语句【互三互三】
文章目录 🍁 引言 🍁 一、语句格式 🍁 二、语句执行过程 🍁 三、语句格式举例 🍁四、例题 👉【例1】 🚀示例代码: 👉【例2】 【方法1】 🚀示例代码: 【方法2】…...
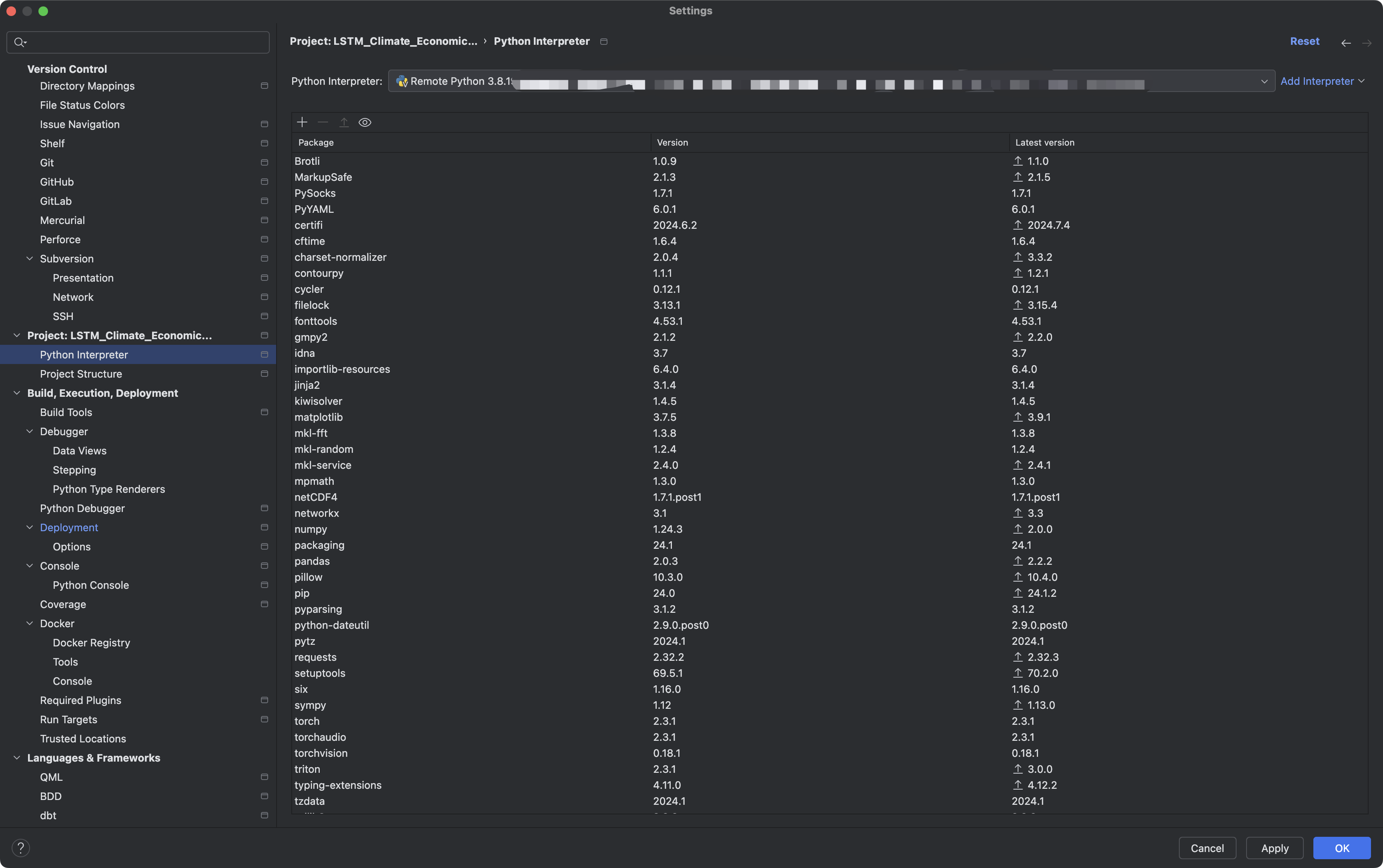
【深度学习基础】MacOS PyCharm连接远程服务器
目录 一、需求描述二、建立与服务器的远程连接1. 新版Pycharm的界面有什么不同?2. 创建远程连接3. 建立本地项目与远程服务器项目之间的路径映射4.设置保存自动上传文件 三、设置解释器总结 写在前面,本人用的是Macbook Pro, M3 MAX处理器&am…...
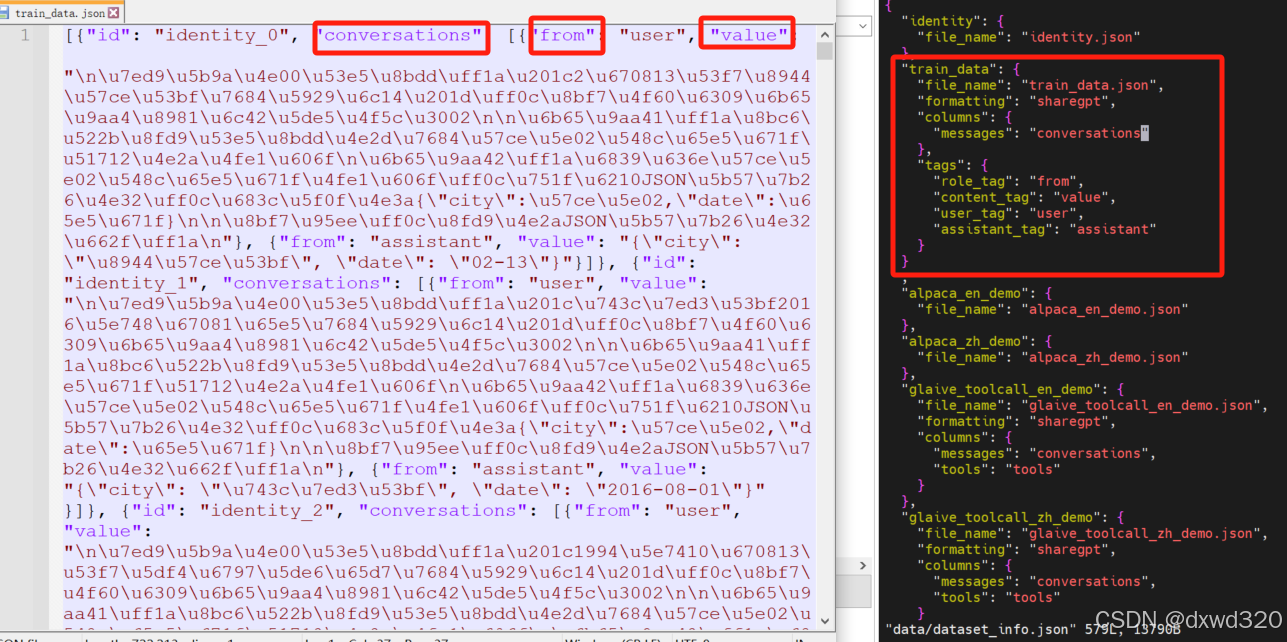
微调Qwen2大语言模型加入领域知识
目录 试用Qwen2做推理安装LLaMA-Factory使用自有数据集微调Qwen2验证微调效果 试用Qwen2做推理 参考:https://qwen.readthedocs.io/en/latest/getting_started/quickstart.html from transformers import AutoModelForCausalLM, AutoTokenizer device "cuda…...

【Linux】内核文件系统系统调用流程摸索
内核层可以看到当前调用文件处理的进程ID 这个数据结构是非常大的: 我们打印的pid,tgid就是从这里来的,然后只需要找到pid_t的数据类型就好了。 下图这是运行的日志信息: 从上述日志,其实我也把write的系统调用加了入口的打印信…...
【HZHY-AI300G智能盒试用连载体验】文档资料
感谢电子发烧友和北京合众恒跃科技有限公司提供的的产品试用机会。 HZHY-AI300G工业级国产化智盒,采用RK3588工业级芯片组适应-40℃-85℃工业级宽温网关。 以前测试过其他厂家的RK3568产品,对瑞芯微的工具也比较了解。 在合众恒跃的网站上可以看到基本…...
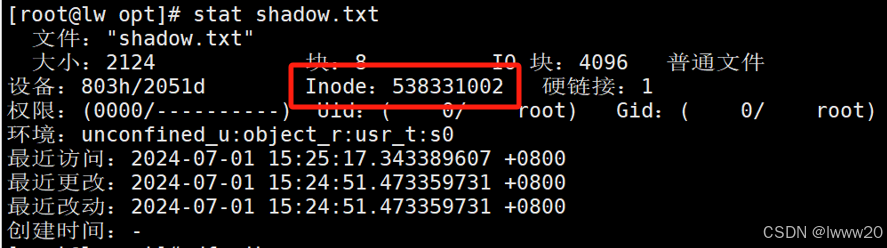
Linux--深入理与解linux文件系统与日志文件分析
目录 一、文件与存储系统的 inode 与 block 1.1 硬盘存储 1.2 文件存取--block 1.3 文件存取--inode 1.4 文件名与 inode 号 编辑 1.5 查看 inode 号码方法 1.6 Linux 系统文件的三个主要的时间属性 1.7 硬盘分区结构 1.8 访问文件的简单了流程 1.9 inode 占用 1.…...

Postman 中的 API 安全性测试:最佳实践与技巧
在当今快速发展的数字化世界中,API(应用程序编程接口)已成为软件系统之间通信的桥梁。然而,随着API使用的增加,安全风险也随之上升。本文将详细介绍如何在 Postman 中进行 API 的安全性测试,帮助开发者和测…...

PTC可复位保险丝 vs 传统型保险丝:全面对比分析
PTC可复位保险丝,又称为自恢复保险丝、自恢复熔断器或PPTC保险丝,是一种电子保护器件。它利用材料的正温度系数效应,即电阻值随温度升高而显著增加的特性,来实现电路保护。 当电路正常工作时,PTC保险丝呈现低阻态&…...
深入了解Rokid UXR2.0 SDK内置的Unity AR Glass开发组件
本文将了解到Rokid AR开发组件 一、RKCameraRig组件1.脚本属性说明2.如何使用 二、PointableUI组件1.脚本属性说明2.如何使用 三、PointableUICurve组件1.脚本属性说明2.如何使用 四、RKInput组件1.脚本属性说明2.如何使用 五、RKHand组件1.脚本属性说明2.如何使用3.如何禁用手…...
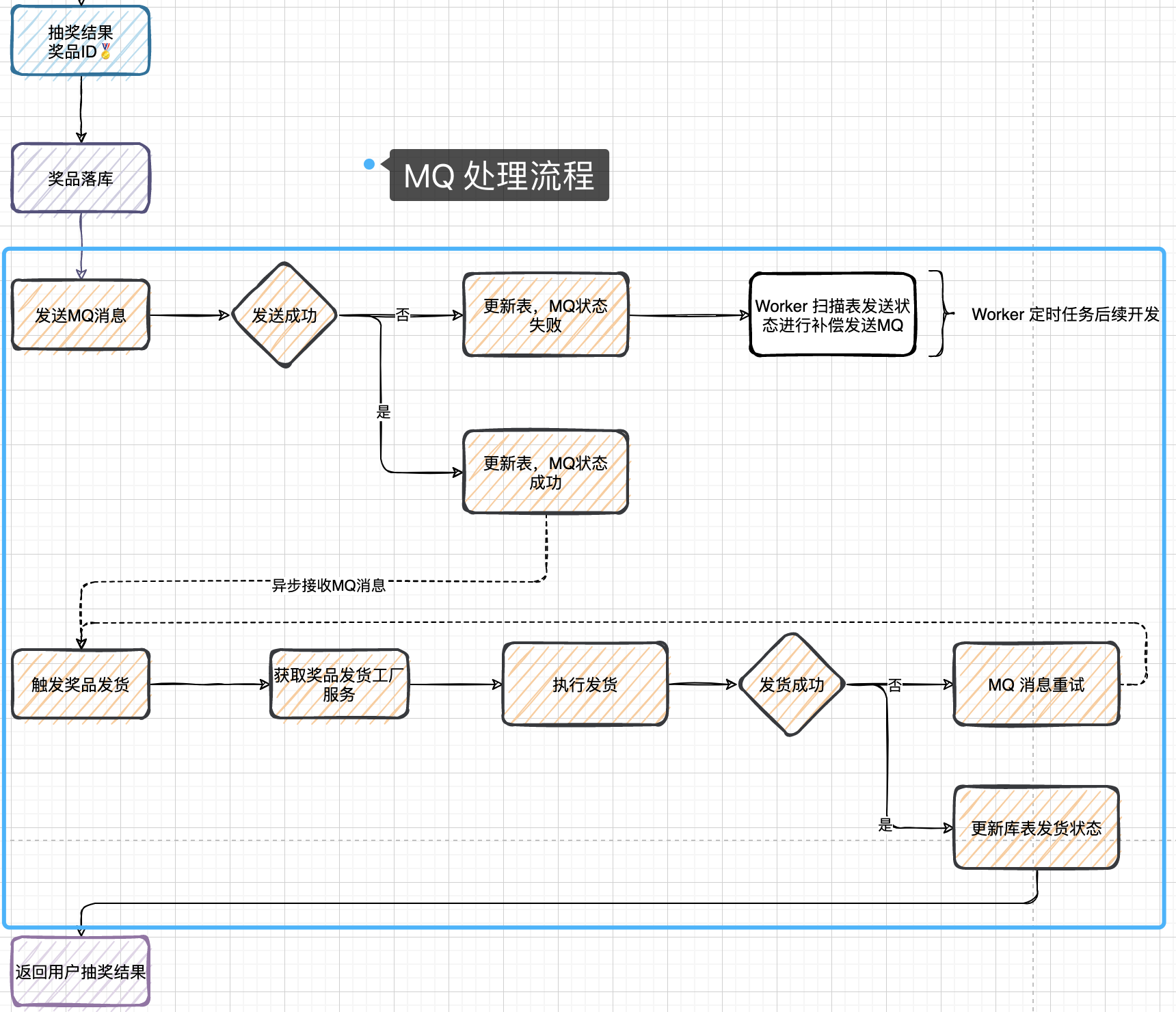
Lottery 分布式抽奖(个人向记录总结)
1.搭建(DDDRPC)架构 DDD——微服务架构(微服务是对系统拆分的方式) (Domain-Driven Design 领域驱动设计) DDD与MVC同属微服务架构 是由Eric Evans最先提出,目的是对软件所涉及到的领域进行建…...
我的AI音乐梦:ChatGPT帮我做专辑
🌈个人主页:前端青山 🔥系列专栏:AI篇 🔖人终将被年少不可得之物困其一生 依旧青山,本期给大家带来ChatGPT帮我做音乐专辑 嘿,朋友们! 想象一下,如果有个超级聪明的机器人能帮你写…...
新手-前端生态
文章目录 新手的前端生态一、概念的理解1、脚手架2、组件 二、基础知识1、HTML2、css3、JavaScript 三、主流框架vue3框架 四、 工具(特定框架)1、uinapp 五、组件库()1、uView如何在哪项目中导入uView 六、应用(各种应…...

C#中的类
声明类 public class MyClass{ } 注意 类里面 的属性可以输入prop之后再按Tab键 然后再按Tab进行修改属性的名称等等 Random rnd new Random(); int arnd.Next(3); 范围是0-3的整数 但是不包含3 Random rnd new Random(); int arnd.Next(2,3); 只包含2一个数 int?[]…...

网络配置工具类详解
CNet 网络配置工具类详解平台:仅支持 Linux,大量使用 ioctl 系统调用一、概述 CNet 是一个 纯静态方法的网络配置工具类,封装了 Linux 下常用的网络操作:功能类别涵盖内容IP 地址读取/设置本机 IP、子网掩码网关读取/添加/删除/设…...
)
别再手动编译了!Matlab一键调用CEC2017测试函数的完整配置指南(附30个函数调用示例)
别再手动编译了!Matlab一键调用CEC2017测试函数的完整配置指南(附30个函数调用示例) 算法研究者们常常需要借助标准测试函数来验证优化算法的性能,而CEC2017测试函数集因其复杂性和多维度的挑战性,成为评估算法鲁棒性的…...

基于随机森林的低成本传感器机器学习校准实践指南
1. 项目概述:当低成本传感器遇上机器学习校准在物联网和智能感知系统铺天盖地的今天,低成本传感器几乎无处不在。从监测办公室的空气质量,到追踪城市街道的噪音污染,再到农业大棚里的温湿度控制,这些价格亲民的“小眼睛…...

基于Netburner NANO54415构建工业级嵌入式Web服务器:从硬件选型到广域监控实战
1. 项目概述:一个为广域与本地监控而生的嵌入式Web服务器如果你正在寻找一个能部署在野外、工厂角落或者任何需要远程数据采集与控制场景下的嵌入式Web服务器方案,并且对市面上那些要么性能孱弱、要么开发门槛极高的开发板感到厌倦,那么这个基…...
)
手把手教你用Mind+和Blynk,让手机轻松遥控掌控板(含自建服务器避坑指南)
从零搭建物联网控制平台:Mind与Blynk深度整合实战 当你第一次尝试用手机控制硬件设备时,那种"隔空取物"的奇妙感总会让人兴奋不已。想象一下,躺在沙发上就能调节书桌上的智能台灯亮度,或者在外出时随时查看家中的温湿度…...

WarcraftHelper终极指南:深度解析魔兽争霸III现代化兼容性解决方案
WarcraftHelper终极指南:深度解析魔兽争霸III现代化兼容性解决方案 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper WarcraftHelper是一款专…...

Graphin高级应用:结合GISDK构建配置化图分析模块的完整指南
Graphin高级应用:结合GISDK构建配置化图分析模块的完整指南 【免费下载链接】Graphin 🌌 A React toolkit for graph visualization based on G6. 项目地址: https://gitcode.com/gh_mirrors/gr/Graphin 在当今数据驱动的时代,图可视化…...

如何在3分钟内为任何活动搭建专业级滚动抽奖系统?Magpie-LuckyDraw全平台开源方案深度解析
如何在3分钟内为任何活动搭建专业级滚动抽奖系统?Magpie-LuckyDraw全平台开源方案深度解析 【免费下载链接】Magpie-LuckyDraw 🏅A fancy lucky-draw tool supporting multiple platforms💻(Mac/Linux/Windows/Web/Docker) 项目地址: https…...

解决claude code频繁封号与token不足的taotoken接入方案
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 解决Claude Code频繁封号与Token不足的Taotoken接入方案 1. 问题背景:Claude Code用户面临的挑战 对于依赖Claude Cod…...

自然语言处理的实战项目:从0到1搭建属于自己的文本分类系统
对于软件测试从业者而言,日常工作中我们每天都会接触大量的文本数据:缺陷管理系统中的bug描述、测试用例的步骤说明、用户反馈的问题报告、需求文档的规格描述,甚至是接口返回的异常信息文本。这些非结构化文本往往隐含着关键业务信息&#x…...