微调Qwen2大语言模型加入领域知识
目录
- 试用Qwen2做推理
- 安装LLaMA-Factory
- 使用自有数据集微调Qwen2
- 验证微调效果
试用Qwen2做推理
参考:https://qwen.readthedocs.io/en/latest/getting_started/quickstart.html
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto# Now you do not need to add "trust_remote_code=True"
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2-7B-Instruct",torch_dtype="auto",device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-7B-Instruct")# Instead of using model.chat(), we directly use model.generate()
# But you need to use tokenizer.apply_chat_template() to format your inputs as shown below
prompt = "Give me a short introduction to large language model."
messages = [{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)# Directly use generate() and tokenizer.decode() to get the output.
# Use `max_new_tokens` to control the maximum output length.
generated_ids = model.generate(model_inputs.input_ids,max_new_tokens=512
)
generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
执行此操作后模型会缓存到如下目录
/root/.cache/huggingface/hub/models–Qwen–Qwen2-7B-Instruct/
安装LLaMA-Factory
参考:https://github.com/hiyouga/LLaMA-Factory
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch,metrics]"
使用自有数据集微调Qwen2
参考:https://qwen.readthedocs.io/en/latest/training/SFT/llama_factory.html
启动web ui 界面来进行微调
llamafactory-cli webui

数据集选择提前准备好的自有数据集train_data.json
编辑LLaMA-Factory/data路径下的dataset_info.json,把自有数据集加入进去
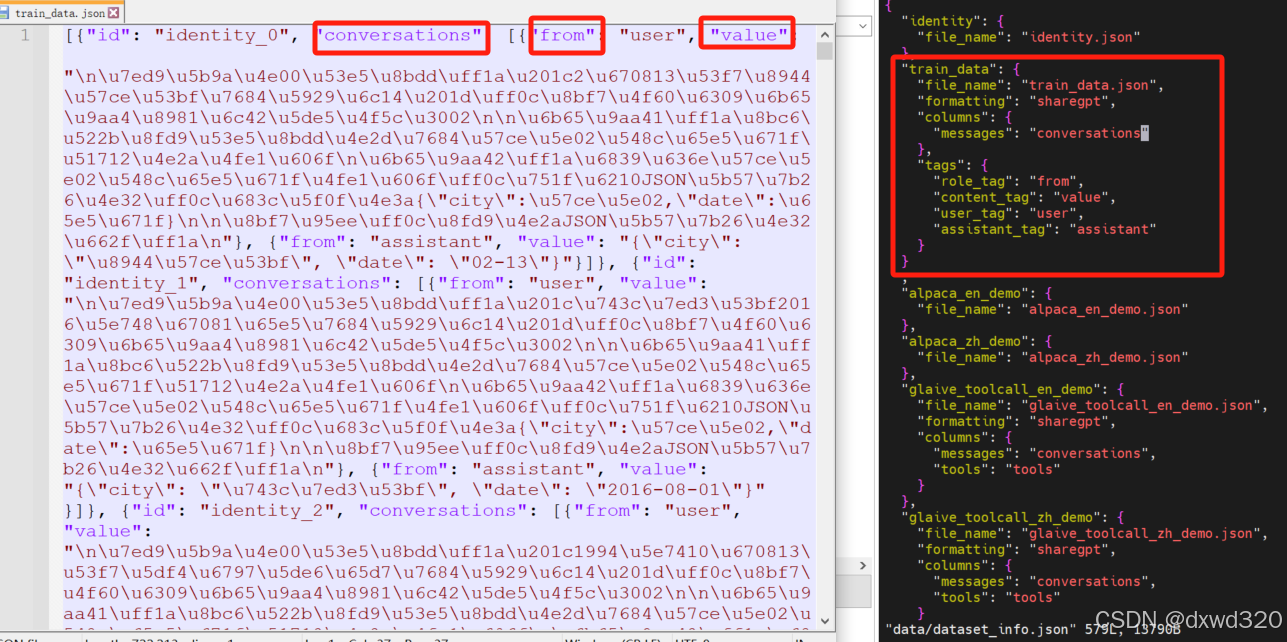
按照自己需求配置训练参数,所有的参数都配置好之后,点一下“预览命令”,确认命令没有问题之后,就可以点击“开始”进行训练了。训练的过程中可以看到 loss的变化曲线、训练耗时等。
参考:https://blog.csdn.net/u012505617/article/details/137864437
验证微调效果
可以直接点击webui界面中的“chat”选项卡,然后点击“加载模型”,然后就可以进行对话了,不过使用A100实测非常慢,一次会话花了四十多分钟。
所以建议在webui 界面训练好模型之后点击“Export”选项卡,然后,在“模型路径”中输入原始模型路径,然后在“检查点路径”中选择自己微调得到的 checkpoint路径,然后在“最大分块大小(GB)”中设置为4,同时设置一下导出目录,最后点击“开始导出”,就可以看到输出的模型了
本地部署模型,并做推理测试
参考:https://qwen.readthedocs.io/en/latest/run_locally/llama.cpp.html
这里使用的是vLLM
参考:https://qwen.readthedocs.io/en/latest/deployment/vllm.html
from transformers import AutoTokenizer
from vllm import LLM, SamplingParams# Initialize the tokenizer
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-7B-Instruct")# Pass the default decoding hyperparameters of Qwen2-7B-Instruct
# max_tokens is for the maximum length for generation.
sampling_params = SamplingParams(temperature=0.1, top_p=0.1, repetition_penalty=1.05, max_tokens=512) #这里想要推理的结果跟我们微调的预期严格一致,所以调低了前两个参数的值。# Input the model name or path. Can be GPTQ or AWQ models.
llm = LLM(model="LLaMA-Factory/saves/Qwen2-7B-Chat/sft") #这里填写前面Export时填写的Path# Prepare your prompts
prompt = "这里输入与微调数据集中类似的问题来验证"
messages = [{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True
)# generate outputs
outputs = llm.generate([text], sampling_params)# Print the outputs.
for output in outputs:prompt = output.promptgenerated_text = output.outputs[0].textprint(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
相关文章:
微调Qwen2大语言模型加入领域知识
目录 试用Qwen2做推理安装LLaMA-Factory使用自有数据集微调Qwen2验证微调效果 试用Qwen2做推理 参考:https://qwen.readthedocs.io/en/latest/getting_started/quickstart.html from transformers import AutoModelForCausalLM, AutoTokenizer device "cuda…...

【Linux】内核文件系统系统调用流程摸索
内核层可以看到当前调用文件处理的进程ID 这个数据结构是非常大的: 我们打印的pid,tgid就是从这里来的,然后只需要找到pid_t的数据类型就好了。 下图这是运行的日志信息: 从上述日志,其实我也把write的系统调用加了入口的打印信…...
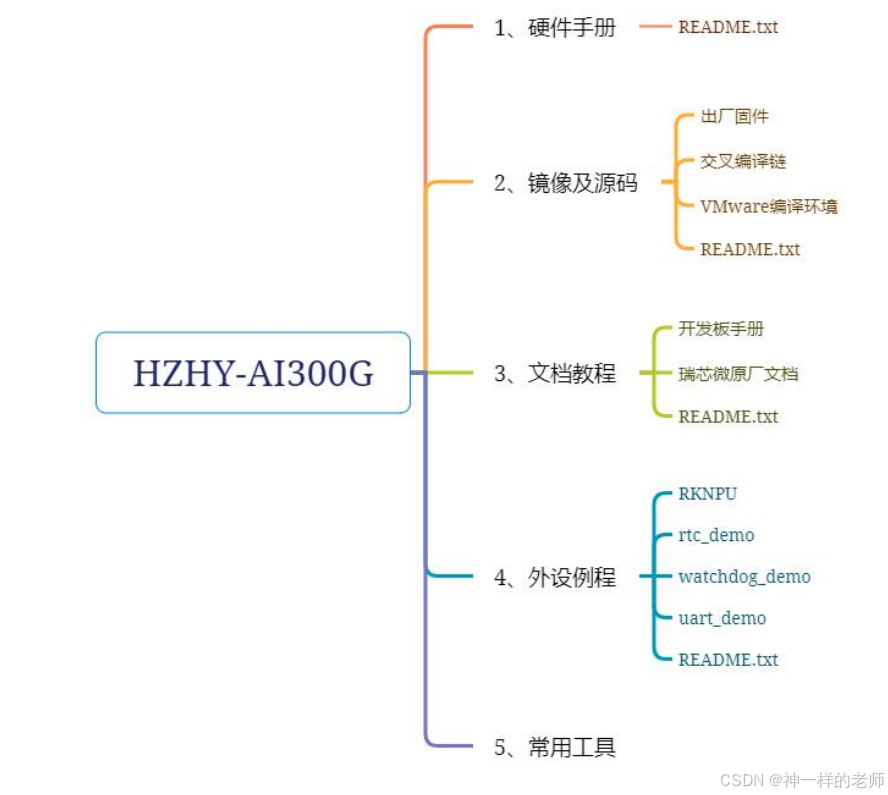
【HZHY-AI300G智能盒试用连载体验】文档资料
感谢电子发烧友和北京合众恒跃科技有限公司提供的的产品试用机会。 HZHY-AI300G工业级国产化智盒,采用RK3588工业级芯片组适应-40℃-85℃工业级宽温网关。 以前测试过其他厂家的RK3568产品,对瑞芯微的工具也比较了解。 在合众恒跃的网站上可以看到基本…...
Linux--深入理与解linux文件系统与日志文件分析
目录 一、文件与存储系统的 inode 与 block 1.1 硬盘存储 1.2 文件存取--block 1.3 文件存取--inode 1.4 文件名与 inode 号 编辑 1.5 查看 inode 号码方法 1.6 Linux 系统文件的三个主要的时间属性 1.7 硬盘分区结构 1.8 访问文件的简单了流程 1.9 inode 占用 1.…...

Postman 中的 API 安全性测试:最佳实践与技巧
在当今快速发展的数字化世界中,API(应用程序编程接口)已成为软件系统之间通信的桥梁。然而,随着API使用的增加,安全风险也随之上升。本文将详细介绍如何在 Postman 中进行 API 的安全性测试,帮助开发者和测…...

PTC可复位保险丝 vs 传统型保险丝:全面对比分析
PTC可复位保险丝,又称为自恢复保险丝、自恢复熔断器或PPTC保险丝,是一种电子保护器件。它利用材料的正温度系数效应,即电阻值随温度升高而显著增加的特性,来实现电路保护。 当电路正常工作时,PTC保险丝呈现低阻态&…...
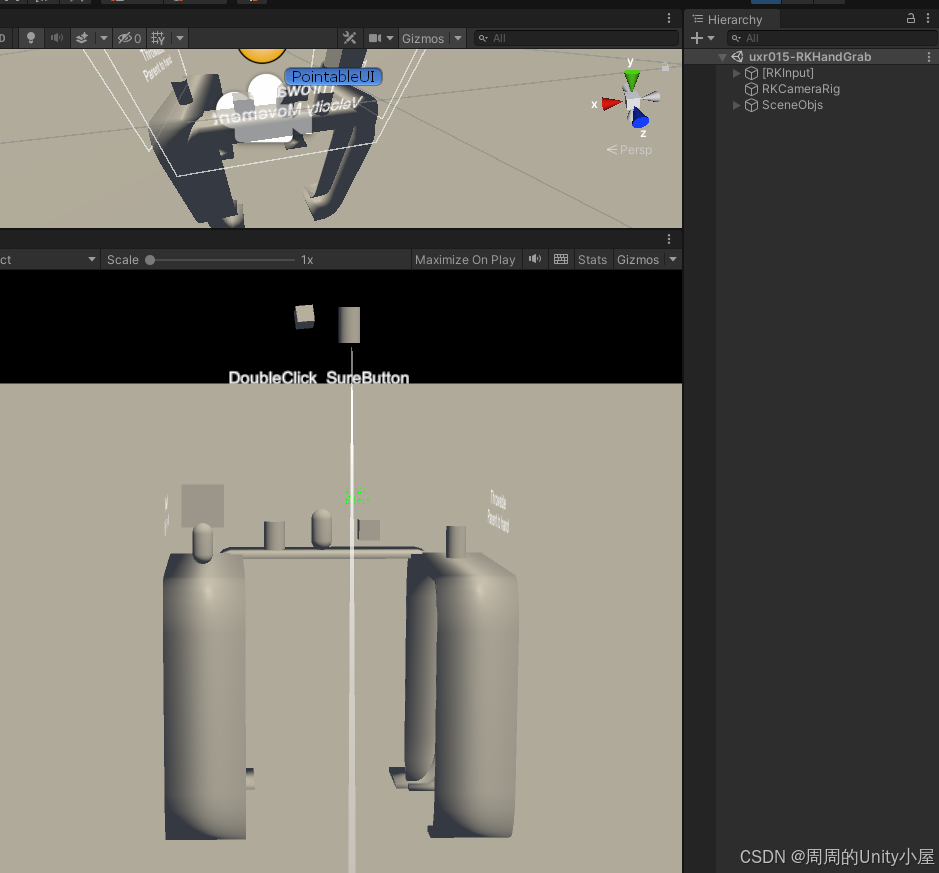
深入了解Rokid UXR2.0 SDK内置的Unity AR Glass开发组件
本文将了解到Rokid AR开发组件 一、RKCameraRig组件1.脚本属性说明2.如何使用 二、PointableUI组件1.脚本属性说明2.如何使用 三、PointableUICurve组件1.脚本属性说明2.如何使用 四、RKInput组件1.脚本属性说明2.如何使用 五、RKHand组件1.脚本属性说明2.如何使用3.如何禁用手…...
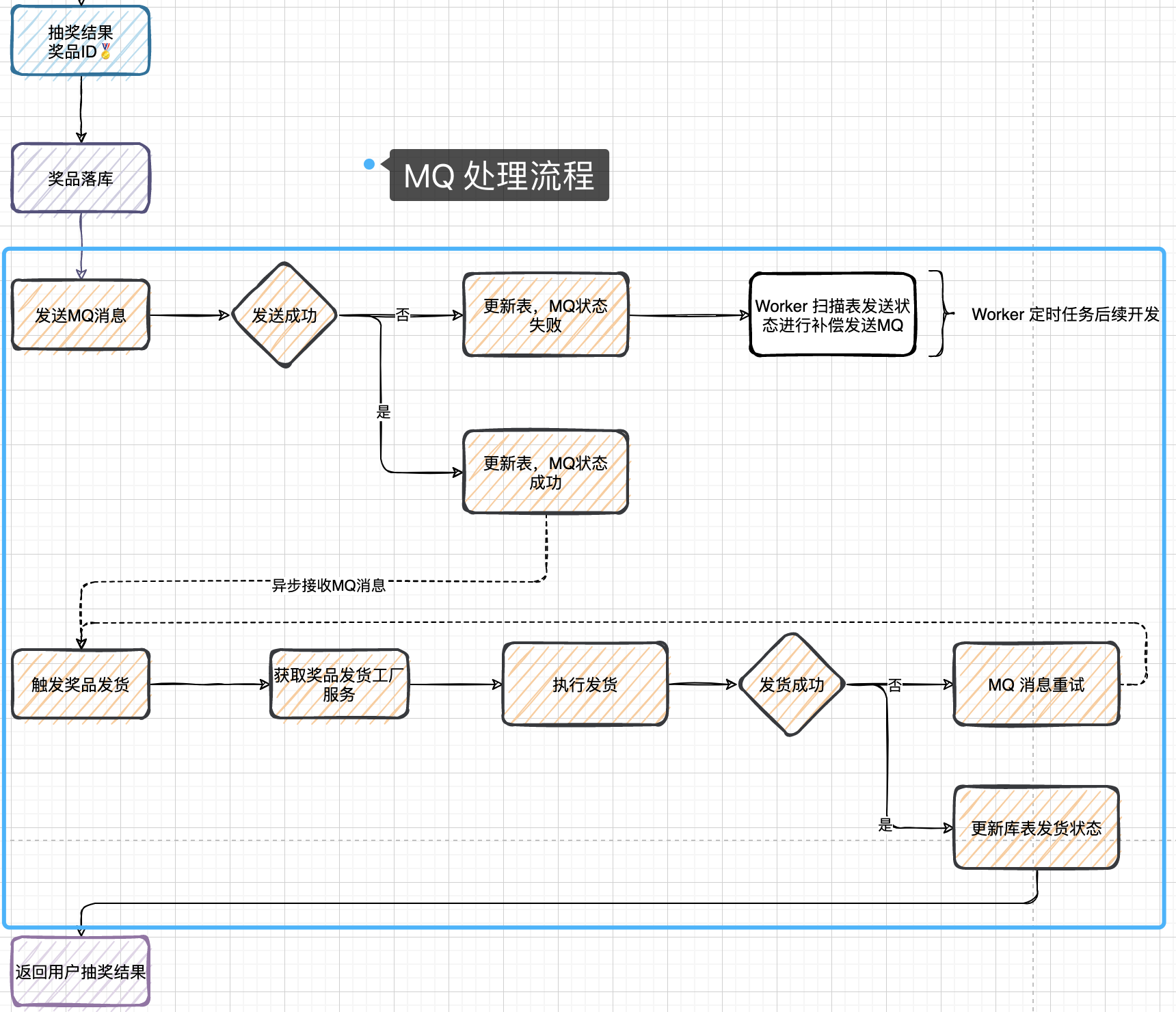
Lottery 分布式抽奖(个人向记录总结)
1.搭建(DDDRPC)架构 DDD——微服务架构(微服务是对系统拆分的方式) (Domain-Driven Design 领域驱动设计) DDD与MVC同属微服务架构 是由Eric Evans最先提出,目的是对软件所涉及到的领域进行建…...
我的AI音乐梦:ChatGPT帮我做专辑
🌈个人主页:前端青山 🔥系列专栏:AI篇 🔖人终将被年少不可得之物困其一生 依旧青山,本期给大家带来ChatGPT帮我做音乐专辑 嘿,朋友们! 想象一下,如果有个超级聪明的机器人能帮你写…...
新手-前端生态
文章目录 新手的前端生态一、概念的理解1、脚手架2、组件 二、基础知识1、HTML2、css3、JavaScript 三、主流框架vue3框架 四、 工具(特定框架)1、uinapp 五、组件库()1、uView如何在哪项目中导入uView 六、应用(各种应…...

C#中的类
声明类 public class MyClass{ } 注意 类里面 的属性可以输入prop之后再按Tab键 然后再按Tab进行修改属性的名称等等 Random rnd new Random(); int arnd.Next(3); 范围是0-3的整数 但是不包含3 Random rnd new Random(); int arnd.Next(2,3); 只包含2一个数 int?[]…...

探索数据库编程:基础与进阶之存储函数
引言❤️❤️ 数据库存储过程是一组为了执行特定功能的SQL语句集合,它被存储在数据库中,可以通过指定存储过程的名称并给出相应的参数来调用。使用存储过程可以提高数据库操作的效率,减少网络传输量,并且可以封装复杂的逻辑。 编…...
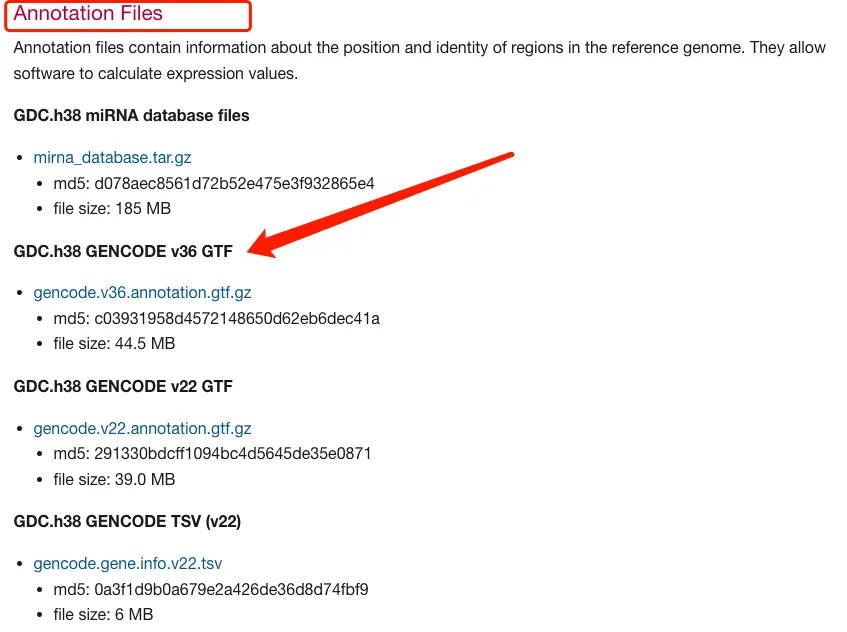
Count数据转换为TPM数据方法整理-常规方法、DGEobj.utils和IOBR包
在正式分析之前,对于数据的处理是至关重要的,这种重要性是体现在很多方面,其中有一点是要求分析者采用正确的数据类型。 对于芯片数据,原始数据进行log2处理之后可以进行很多常见的分析,比如差异分析、热图、箱线图、…...
简易限流实现
需求描述 写一个1秒两个的限流工具类,2r/s 使用semaphore 代码实现-类似令牌桶算法 public class LimitHelper {private int maxLimit;private Semaphore semaphore;private int timeoutSeconds;public LimitHelper(int maxLimit, int timeoutSeconds) {this.max…...
用Qwt进行图表和数据可视化开发
目录 Qwt介绍 示例应用场景 典型QWT开发流程 举一些Qwt的例子,多绘制几种类型的图像 1. 绘制折线图 (Line Plot) 2. 绘制散点图 (Scatter Plot) 3. 绘制柱状图 (Bar Plot) 4. 绘制直方图 (Histogram) Qwt介绍 QWT开发主要涉及使用QWT库进行图表和数据可视化…...

sqlalchemy使用with_entities返回指定数据列
sqlalchemy使用with_entities返回指定数据列 在 SQLAlchemy 中,with_entities 方法用于指定查询语句返回的实体(Entity)或列(Column)。它允许你限制查询的返回结果,只包含你感兴趣的特定字段或实体 使用方法 假设有一个名为 User 的 SQLAlchemy 模型类,包含以下字段:…...
express
文章目录 🟢 Express⭐️ 1.初始Express✨安装✨使用Express 搭建一台服务器⭐️2.Express-基本路由✨1.使用字符串模式的路由路径示例:✨2.使用正则表达式的路由路径示例:✨3.中间件浅试(demo)⭐️3.Express-中间件✨1.应用级中间件✨2.路由级中间件✨3.错误处理中间件✨4…...
HTML网页大设计-家乡普宁德安里
代码地址: https://pan.quark.cn/s/57e48c3b3292...

深度学习:从数据采集到模型测试的全面指南
摘要 随着人工智能和大数据技术的迅猛发展,深度学习已成为解决复杂问题的有力工具。然而,从项目启动到模型部署,包含了数据处理和模型研发的多个环节,每个环节的细致和严谨性直接决定了最终模型的性能和可靠性。本论文详细探讨了…...

Excel第29享:基于sum嵌套sumifs的多条件求和
1、需求描述 如下图所示,现要统计12.17-12.23这一周各个人员的“上班工时(a1)”。 下图为系统直接导出的工时数据明细样例。 2、解决思路 首先,确定逻辑:“对多个条件(日期、人员)进行“工时”…...

CAPL调用DLL实现UDS 27服务加密算法:从C代码到Vector环境的完整打通
CAPL调用DLL实现UDS 27服务加密算法:从C代码到Vector环境的完整打通 在汽车电子测试领域,UDS(Unified Diagnostic Services)协议的安全访问(27服务)是保护ECU免受未授权访问的关键机制。当我们需要在Vector…...

SQL调优实战手册:索引、并行、参数调优一站式解决方案
做企业级业务开发久了,都会碰到同一个难题:数据量越积越多,原本跑得顺畅的SQL慢慢开始变慢,轻则接口响应延迟,重则整个系统卡顿,甚至影响核心业务流转。尤其是用KingbaseES这款国产企业级数据库(…...

数字记忆策展:WeChatMsg与数据主权时代的个人记忆管理
数字记忆策展:WeChatMsg与数据主权时代的个人记忆管理 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/WeCha…...

lychee-rerank-mm保姆级教程:支持中文的轻量级多模态打分工具
lychee-rerank-mm保姆级教程:支持中文的轻量级多模态打分工具 你是不是经常遇到这样的烦恼?在搜索引擎里输入“猫咪玩球”,结果出来的图片有的是狗,有的是风景,真正可爱的小猫玩毛线球的图却排到了后面。或者…...

Clawdbot汉化版实测:企业微信接入AI客服,响应速度提升92%
Clawdbot汉化版实测:企业微信接入AI客服,响应速度提升92% 1. 企业客服场景的痛点与解决方案 1.1 传统客服面临的挑战 在电商和客户服务领域,企业微信已成为重要的客户沟通渠道。然而传统客服模式存在三个核心问题: 响应延迟&a…...

AI智能二维码工坊性能优化:多线程并发处理识别请求实战
AI智能二维码工坊性能优化:多线程并发处理识别请求实战 1. 项目核心价值与应用场景 想象一下,你运营着一个大型活动签到系统,或者管理着一个需要批量处理商品信息的电商后台。用户或同事上传的图片里,可能包含成千上万个二维码。…...
**)
**发散创新:基于Go语言的服务网格实践与流量治理实战**在微服务架构日益复杂的今天,**服务网格(Service Mesh)**
发散创新:基于Go语言的服务网格实践与流量治理实战 在微服务架构日益复杂的今天,服务网格(Service Mesh) 已成为云原生生态中不可或缺的一环。它通过将网络通信逻辑从应用代码中剥离出来,实现了对服务间调用的精细化控…...

Qwen2.5-7B-Instruct入门指南:7B模型对输入token长度的鲁棒性压力测试
Qwen2.5-7B-Instruct入门指南:7B模型对输入token长度的鲁棒性压力测试 1. 项目概述 Qwen2.5-7B-Instruct是阿里通义千问系列的旗舰级大模型,相比1.5B和3B轻量版本,7B参数规模带来了质的飞跃。这个模型在逻辑推理、长文本创作、复杂代码编写…...

彻底清理C盘自带软件方法:2026最新版强力卸载预装软件工具教程
电脑用着用着C盘就满了,开机小助手总提醒“磁盘空间不足”。点进控制面板一看,全是买电脑时自带的那些从未用过的软件,想卸载又怕卸不干净,甚至担心把系统搞崩溃。其实,彻底清理这些自带软件有章可循,关键是…...

18650圆柱锂电池电化学模型与Comsol锂电模型参数化研究及电化生热分析结果图集
18650圆柱锂电池模型电化学模型,comsol锂电模型参数已配置,电化学生热研究,三种放电倍率,参数化扫描,各种结果图都有。今天我们来聊聊18650圆柱锂电池的电化学模型,尤其是在COMSOL中的实现。说到锂电池&…...