深度学习:从数据采集到模型测试的全面指南
摘要
随着人工智能和大数据技术的迅猛发展,深度学习已成为解决复杂问题的有力工具。然而,从项目启动到模型部署,包含了数据处理和模型研发的多个环节,每个环节的细致和严谨性直接决定了最终模型的性能和可靠性。本论文详细探讨了大数据和深度学习项目的研发流程,包括数据采集、数据清洗与预处理、数据标注、数据划分、模型设计、模型初始化、模型训练、模型验证、模型保存和模型测试,旨在为从事该领域的研究人员和工程师提供系统化的方法和实践指南。
引言
随着数据量和计算能力的不断增加,深度学习技术在各个领域的应用越来越广泛。然而,成功的深度学习项目不仅依赖于先进的算法,还需要系统化的流程和方法论。本文旨在提供一份详细的指南,涵盖从数据采集到模型测试的完整过程,帮助研究人员和工程师更好地理解和实施大数据和深度学习项目。
1. 数据采集
1.1 定义数据需求
在任何大数据和深度学习项目中,数据是核心要素。定义数据需求是项目的起点,包括明确项目目标、所需数据类型、数据特征、格式和来源等。需要考虑以下几点:
- 项目目标:明确项目要解决的问题,例如图像分类、语音识别、自然语言处理等。
- 数据类型:确定需要处理的数据类型,包括文本、图像、音频、视频等。
- 数据特征:定义数据的关键特征,例如图像的分辨率、文本的长度、音频的采样率等。
- 数据格式:明确数据的存储格式,如CSV、JSON、XML、JPEG、MP4等。
- 数据来源:识别可能的数据来源,包括公开数据库、公司内部数据、API接口等。
1.2 找到数据源
找到合适的数据源是数据采集的关键步骤。数据源可以包括:
- 公开数据库:如ImageNet、COCO、OpenAI GPT-3数据集等,这些数据集通常包含大量标注数据,适合用于模型训练和测试。
- 公司内部数据:企业内部可能拥有大量未利用的数据,这些数据可以通过数据挖掘和清洗用于深度学习项目。
- API接口:通过调用公开或私有的API接口获取实时数据,例如Twitter API、Google Maps API等。
- 网络爬虫:通过编写爬虫程序从互联网上收集数据,需注意遵守相关的法律法规和网站的Robots协议。
1.3 收集数据
数据收集包括使用各种工具和方法获取所需数据:
- 数据库导出:从数据库中导出结构化数据,例如MySQL、PostgreSQL等。
- API调用:使用编程语言(如Python、Java)编写脚本,通过API接口获取数据。
- 网络爬虫:使用爬虫工具(如Scrapy、BeautifulSoup)从网页上抓取数据。
- 文件导入:从本地文件系统导入数据,例如读取CSV、JSON、XML文件。
1.4 存储数据并检查数据质量
数据收集后,需要进行存储和初步的数据质量检查:
- 存储数据:将数据存储在数据库、分布式文件系统(如HDFS)、云存储(如AWS S3)等。
- 数据质量检查:检查数据的完整性、准确性、一致性。使用统计方法和可视化工具(如Pandas、Matplotlib)进行数据质量分析,发现并处理缺失值、重复值、异常值等问题。
2. 数据清洗和预处理
2.1 处理缺失值
缺失值处理是数据清洗的第一步。缺失值可能由于各种原因(如数据采集错误、系统故障等)导致:
- 删除缺失值:对于缺失值较少的情况下,可以删除包含缺失值的数据记录。
- 填充缺失值:使用均值、中位数、众数等方法填充缺失值。
- 插值法:对于时间序列数据,可以使用线性插值、多项式插值等方法填充缺失值。
2.2 处理重复值
重复值会导致模型的性能下降,需要在数据清洗过程中进行处理:
- 去重方法:使用编程语言(如Python)中的去重函数(如Pandas中的drop_duplicates())删除重复值。
- 业务逻辑处理:根据业务逻辑,合理地合并或保留部分重复数据。
2.3 处理异常值
异常值的存在可能会显著影响模型的表现,需要通过统计方法进行处理:
- 箱型图法:使用箱型图(Box Plot)识别并处理异常值。
- 标准差法:使用标准差识别数据的离群值,根据数据分布设置合理的阈值。
3. 数据标注
3.1 理解任务需求
在数据标注前,需要明确任务需求:
- 分类任务:标注数据的类别,如图像分类、文本分类。
- 物体检测任务:标注图像中的目标物体及其边界框。
- 信息抽取任务:从文本中提取特定的信息,如命名实体识别(NER)。
3.2 制定标注规范
制定详细的标注规范,确保数据标注的一致性和高质量:
- 标注指南:编写详细的标注指南,说明每个标签的定义和标注方法。
- 标注样例:提供标注样例,帮助标注人员理解标注标准。
3.3 选择或开发标注工具
根据项目需求,选择或开发合适的标注工具:
- 开源标注工具:如LabelImg、LabelMe等,用于图像标注。
- 定制化标注工具:根据特定需求开发定制化的标注工具,提高标注效率。
3.4 进行数据标注
组织团队进行数据标注,确保标注质量:
- 标注团队:组建标注团队,进行培训,确保标注一致性。
- 质量检查:定期进行质量检查,反馈和修正标注问题。
4. 数据划分
4.1 确定划分策略
根据项目需求,确定数据划分比例:
- 训练集:用于模型训练,占总数据的70%-90%。
- 验证集:用于模型验证,占总数据的10%-20%。
- 测试集:用于模型测试,占总数据的10%-20%。
4.2 保存划分后的数据
将划分后的数据进行存储和备份:
- 数据存储:将训练集、验证集和测试集分别存储在不同的文件夹或数据库中。
- 数据备份:对划分后的数据进行备份,确保数据安全和可重复性。
5. 模型设计
5.1 理解问题类型
根据问题类型选择合适的模型:
- 分类问题:如图像分类、文本分类,选择适合的分类模型。
- 回归问题:如房价预测、股票价格预测,选择适合的回归模型。
- 序列预测问题:如时间序列预测、自然语言生成,选择适合的序列模型。
5.2 选择算法
选择适合的算法,包括传统机器学习算法和深度学习算法:
- 传统机器学习算法:如逻辑回归、决策树、支持向量机等。
- 深度学习算法:如卷积神经网络(CNN)、循环神经网络(RNN)、长短期记忆网络(LSTM)等。
5.3 设计模型架构
设计模型的具体架构,包括层数、激活函数、损失函数等:
- 层数设计:确定模型的层数和每层的神经元数量。
- 激活函数:选择适合的激活函数,如ReLU、Sigmoid、Tanh等。
- 损失函数:根据任务选择适合的损失函数,如交叉熵损失、均方误差等。
5.4 设置超参数
根据实验经验和理论知识,设置超参数:
- 学习率:决定模型训练的步长。
- batch_size:决定每次迭代的样本数量。
- epoch:决定整个训练集被训练的次数。
5.5 定义评估指标
定义评估模型性能的指标:
- 分类指标
:如准确率、精确率、召回率、F1值等。
- 回归指标:如均方误差、均方根误差、R平方等。
6. 模型初始化
6.1 选择初始化策略
选择合适的初始化策略:
- 零初始化:所有参数初始化为零,通常不推荐使用。
- 随机初始化:参数随机初始化,常用于简单模型。
- He初始化:适用于ReLU激活函数的深度神经网络。
- Xavier初始化:适用于Sigmoid或Tanh激活函数的神经网络。
6.2 初始化权重和偏置
使用框架(如Pytorch)进行模型权重和偏置的初始化:
import torch.nn as nn# 定义模型
class SimpleModel(nn.Module):def __init__(self):super(SimpleModel, self).__init__()self.fc1 = nn.Linear(784, 256)self.fc2 = nn.Linear(256, 128)self.fc3 = nn.Linear(128, 10)def forward(self, x):x = torch.relu(self.fc1(x))x = torch.relu(self.fc2(x))x = self.fc3(x)return x# 初始化模型
model = SimpleModel()# 初始化权重和偏置
def init_weights(m):if isinstance(m, nn.Linear):nn.init.xavier_uniform_(m.weight)nn.init.zeros_(m.bias)model.apply(init_weights)
7. 模型训练
7.1 设置训练参数
设置模型训练的参数,包括学习率、优化器等:
import torch.optim as optim# 设置学习率
learning_rate = 0.001# 选择优化器
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
7.2 准备训练数据
准备训练数据,进行数据增强和数据归一化处理:
from torchvision import transforms# 数据增强
transform = transforms.Compose([transforms.RandomHorizontalFlip(),transforms.RandomCrop(32, padding=4),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])# 准备数据集
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=100, shuffle=True)
7.3 进行前向传播和损失计算
通过前向传播计算模型输出,并根据真实值计算损失:
import torch.nn.functional as F# 前向传播
outputs = model(inputs)
loss = F.cross_entropy(outputs, labels)
7.4 执行反向传播更新模型参数
通过反向传播算法更新模型参数,不断优化模型:
# 清空梯度
optimizer.zero_grad()# 反向传播
loss.backward()# 更新参数
optimizer.step()
7.5 验证和调整模型
在训练过程中进行模型验证,使用正则化技术防止过拟合:
# L2正则化
for param in model.parameters():loss += torch.sum(param ** 2)# Dropout
self.dropout = nn.Dropout(p=0.5)
x = self.dropout(x)
8. 模型验证
8.1 准备验证集
准备验证集,用于模型性能评估:
# 准备验证数据集
valset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
valloader = torch.utils.data.DataLoader(valset, batch_size=100, shuffle=False)
8.2 进行模型测试
在验证集上进行模型测试,计算评估指标:
# 进行验证
model.eval()
correct = 0
total = 0with torch.no_grad():for data in valloader:images, labels = dataoutputs = model(images)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()accuracy = 100 * correct / total
print('Accuracy on validation set: %d %%' % accuracy)
9. 模型保存
9.1 选择保存格式
选择合适的模型保存格式,如pkl、pth等:
# 保存模型
torch.save(model.state_dict(), 'model.pth')
9.2 保存模型参数
保存训练好的模型参数,确保模型的可复现性:
# 加载模型
model.load_state_dict(torch.load('model.pth'))
model.eval()
10. 模型测试
10.1 准备测试集
准备测试集,用于最终模型评估:
# 准备测试数据集
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=100, shuffle=False)
10.2 进行模型预测
在测试集上进行模型预测,计算评估指标:
# 进行测试
model.eval()
correct = 0
total = 0with torch.no_grad():for data in testloader:images, labels = dataoutputs = model(images)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()accuracy = 100 * correct / total
print('Accuracy on test set: %d %%' % accuracy)
10.3 分析结果并记录
分析模型预测结果,记录评估指标,为模型部署提供参考:
- 混淆矩阵:绘制混淆矩阵,分析模型在各个类别上的表现。
- ROC曲线和AUC值:绘制ROC曲线,计算AUC值,评估模型的分类性能。
- 模型优化建议:根据测试结果提出模型优化建议,如调整超参数、增加训练数据、改进模型架构等。
结论
本论文详细探讨了大数据和深度学习项目的完整研发流程,从数据采集、数据清洗与预处理、数据标注、数据划分、模型设计、模型初始化、模型训练、模型验证、模型保存到模型测试,涵盖了项目的各个阶段。通过系统化的方法和严谨的步骤,确保了项目的有效性和可靠性,为相关领域的研究人员和工程师提供了有价值的参考。
相关文章:

深度学习:从数据采集到模型测试的全面指南
摘要 随着人工智能和大数据技术的迅猛发展,深度学习已成为解决复杂问题的有力工具。然而,从项目启动到模型部署,包含了数据处理和模型研发的多个环节,每个环节的细致和严谨性直接决定了最终模型的性能和可靠性。本论文详细探讨了…...

Excel第29享:基于sum嵌套sumifs的多条件求和
1、需求描述 如下图所示,现要统计12.17-12.23这一周各个人员的“上班工时(a1)”。 下图为系统直接导出的工时数据明细样例。 2、解决思路 首先,确定逻辑:“对多个条件(日期、人员)进行“工时”…...
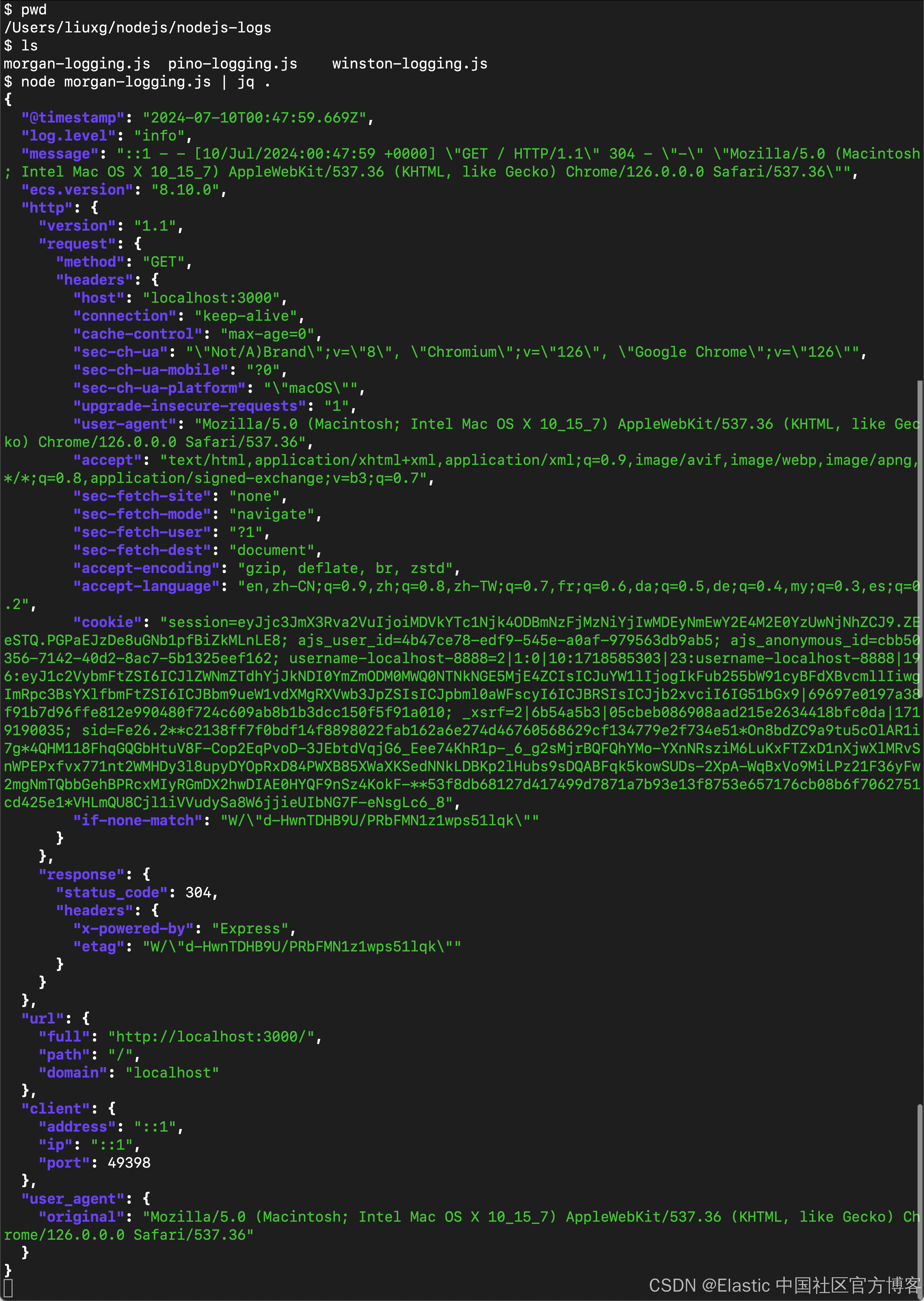
Elasticsearch:Node.js ECS 日志记录 - Morgan
这是之前系列文章: Elasticsearch:Node.js ECS 日志记录 - Pino Elasticsearch:Node.js ECS 日志记录 - Winston 中的第三篇文章。在今天的文章中,我将描述如何使用 Morgan 包针对 Node.js 应用进行日子记录。此 Morgan Node.j…...

ChatGPT对话:Python程序自动模拟操作网页,无法弹出下拉列表框
【编者按】需要编写Python程序自动模拟操作网页。编者有编程经验,但没有前端编程经验,完全不知道如何编写这种程序。通过与ChatGPT讨论,1天完成了任务。因为没有这类程序的编程经验,需要边学习,边编程,遇到…...

Unity 之 抖音小游戏集成排行榜功能详解
Unity 之 抖音小游戏集成排行榜功能详解 一,前言1.1 为游戏设计利于传播的元素2.2 多人竞技、社交传播二,集成说明2.1 功能介绍2.2 完整代码2.3 效果展示三,发现的问题和迭代计划一,前言 对于 Unity 开发者而言,在开发抖音小游戏时集成排行榜功能是提升游戏社交性和玩…...

【学习笔记】Redis学习笔记——第13章 客户端
第13章 客户端 redisServer通过clients链表保存全部客户端的状态信息。 13.1 客户端属性 13.1.1 套接字描述符 fd:-1时伪客户端,载入AOF文件或Lua脚本。 13.1.2 名字 默认无客户端名,可以通过SETNAME命令设置。 13.1.3 标志 flags&am…...

Android中的JSON解析:从基础到实践
在Android应用开发中,JSON(JavaScript Object Notation)是最常用的数据交换格式之一,因其轻量级、易读性强以及跨平台兼容性好等特点,被广泛应用于服务器与客户端之间的数据传输。解析JSON数据对于提取和处理这些信息至…...
力扣-回溯法
何为回溯法? 在搜索到某一节点的时候,如果我们发现目前的节点(及其子节点)并不是需求目标时,我们回退到原来的节点继续搜索,并且把在目前节点修改的状态还原。 记住两个小诀窍,一是按引用传状态…...
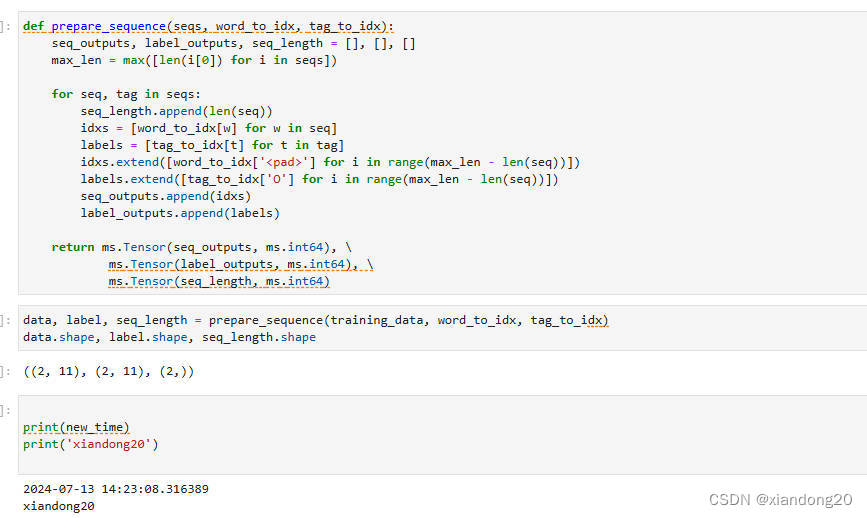
240713_昇思学习打卡-Day25-LSTM+CRF序列标注(4)
240713_昇思学习打卡-Day25-LSTMCRF序列标注(4) 最后一天咯,做第四部分。 BiLSTMCRF模型 在实现CRF后,我们设计一个双向LSTMCRF的模型来进行命名实体识别任务的训练。模型结构如下: nn.Embedding -> nn.LSTM -&…...

python requests关闭https校验
python requests关闭https校验 import requests# 关闭SSL验证 requests.get(https://***.com, verifyFalse)...

PG大会周五于杭州举办;Pika发布4.0;阿里云MySQL上线Zero-ETL集成能力
重要更新 1. PostgreSQL中国技术大会举行12日(周五)于杭州举办,是PostgreSQL社区年度的大会,举办地点:杭州君尚云郦酒店(杭州市上城区临丁路1188号),感兴趣的可以考虑现场参加 ( [1]…...
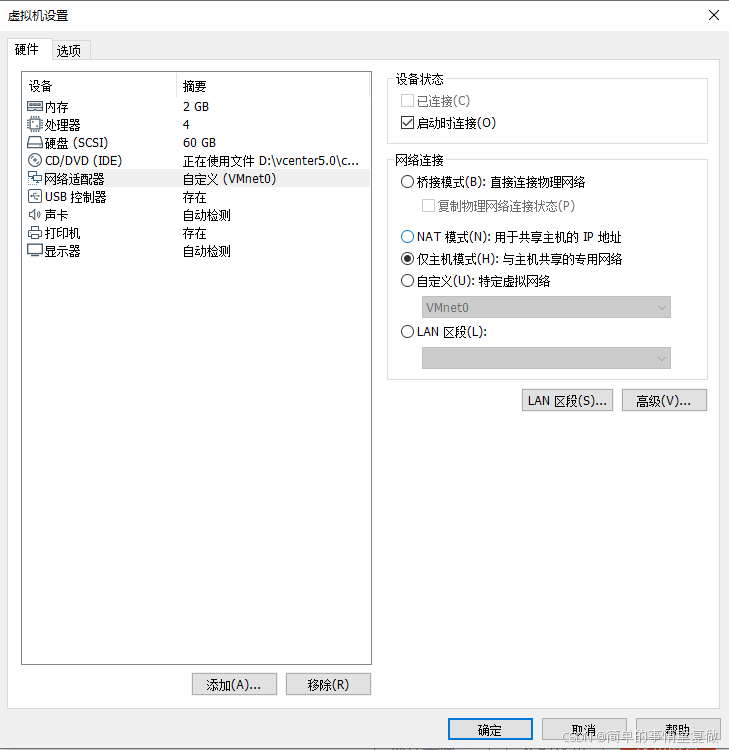
虚拟机vmware网络设置
一、网络分类 打开vmware workstation网络编辑器可以知道有三种网络类型,分别是:桥接模式、nat模式、仅主机模式。 1、桥接模式 桥接模式是将主机网卡与虚拟机虚拟的网卡利用虚拟网桥进行通信。在桥接的作用下, 类似于把物理主机虚拟为一个交换机, 所有设…...
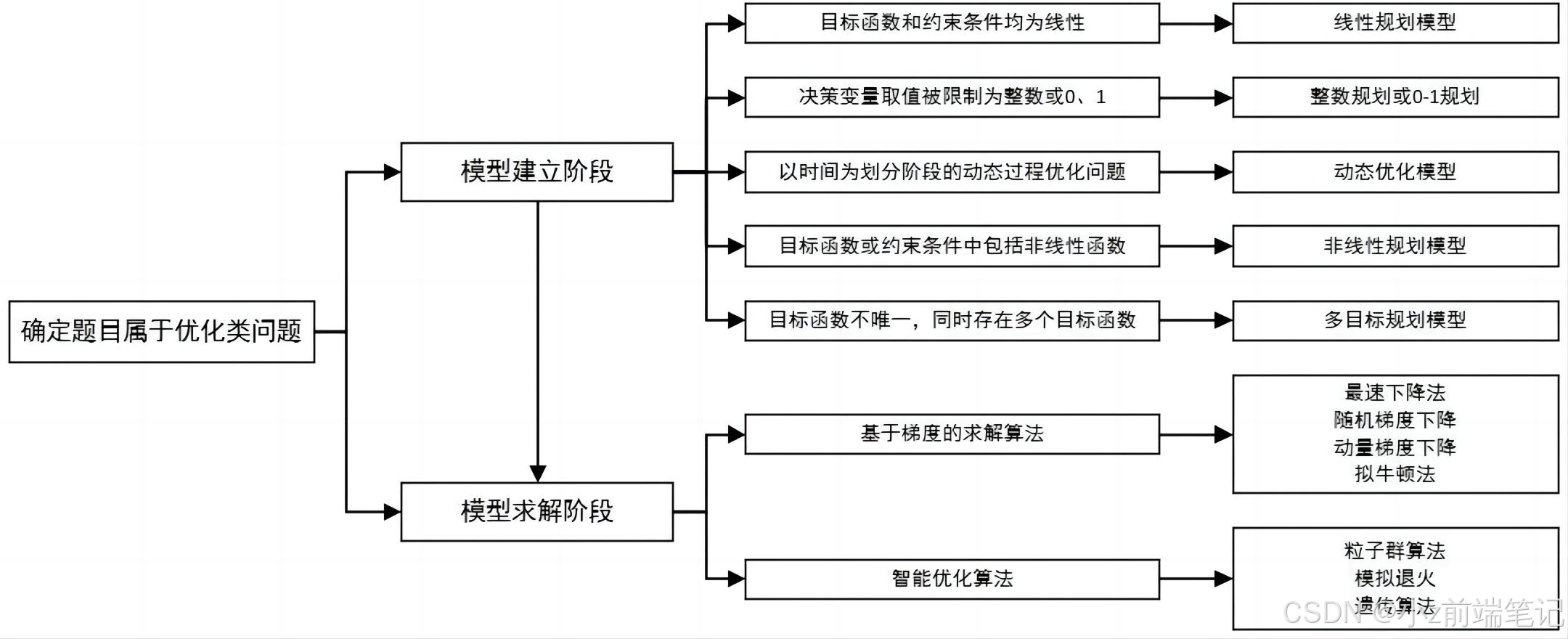
数学建模国赛入门指南
文章目录 认识数学建模及国赛认识数学建模什么是数学建模?数学建模比赛 国赛参赛规则、评奖原则如何评省、国奖评奖规则如何才能获奖 国赛赛题分类及选题技巧国赛赛题特点赛题分类 国赛历年题型及优秀论文 数学建模分工技巧数模必备软件数模资料文献数据收集资料收集…...
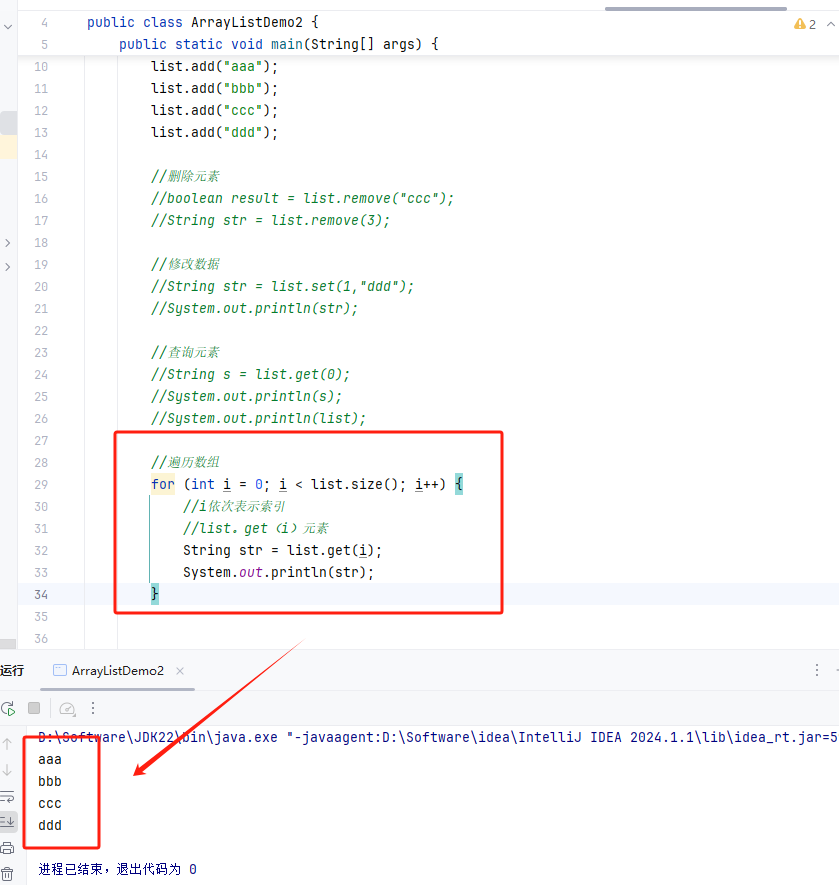
Java基础之集合
集合和数组的类比 数组: 长度固定可以存基本数据类型和引用数据类型 集合: 长度可变只能存引用数据类型存储基本数据类型要把他转化为对应的包装类 ArrayList集合 ArrayList成员方法 添加元素 删除元素 索引删除 查询 遍历数组...

深度学习和NLP中的注意力和记忆
深度学习和NLP中的注意力和记忆 文章目录 一、说明二、注意力解决了什么问题?#三、关注的代价#四、机器翻译之外的关注#五、注意力(模糊)记忆?# 一、说明 深度学习的最新趋势是注意力机制。在一次采访中,现任 OpenAI 研…...

自用的C++20协程学习资料
C20的一个重要更新就是加入了协程。 在网上找了很多学习资料,看了之后还是不明白。 最后找到下面这些资料总算是讲得比较明白,大家可以按照顺序阅读: 渡劫 C 协程(1):C 协程概览C20协程原理和应用...
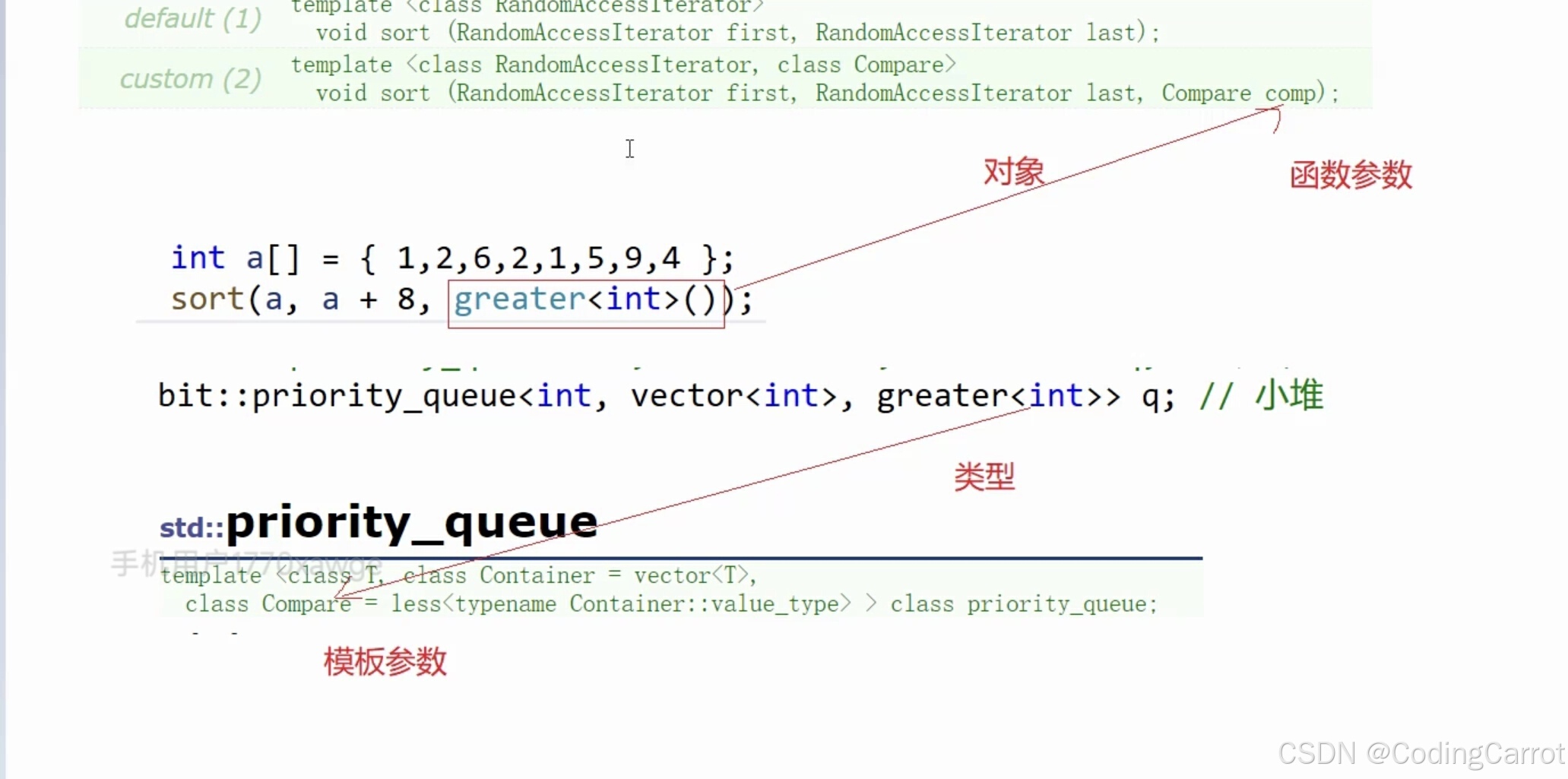
【C++】优先级队列(底层代码解释)
一. 定义 优先级队列是一个容器适配器,他可以根据不同的需求采用不同的容器来实现这个数据结构,优先级队列采用了堆的数据结构,默认使用vector作为容器,且采用大堆的结构进行存储数据。 (1)在第一个构造函数…...
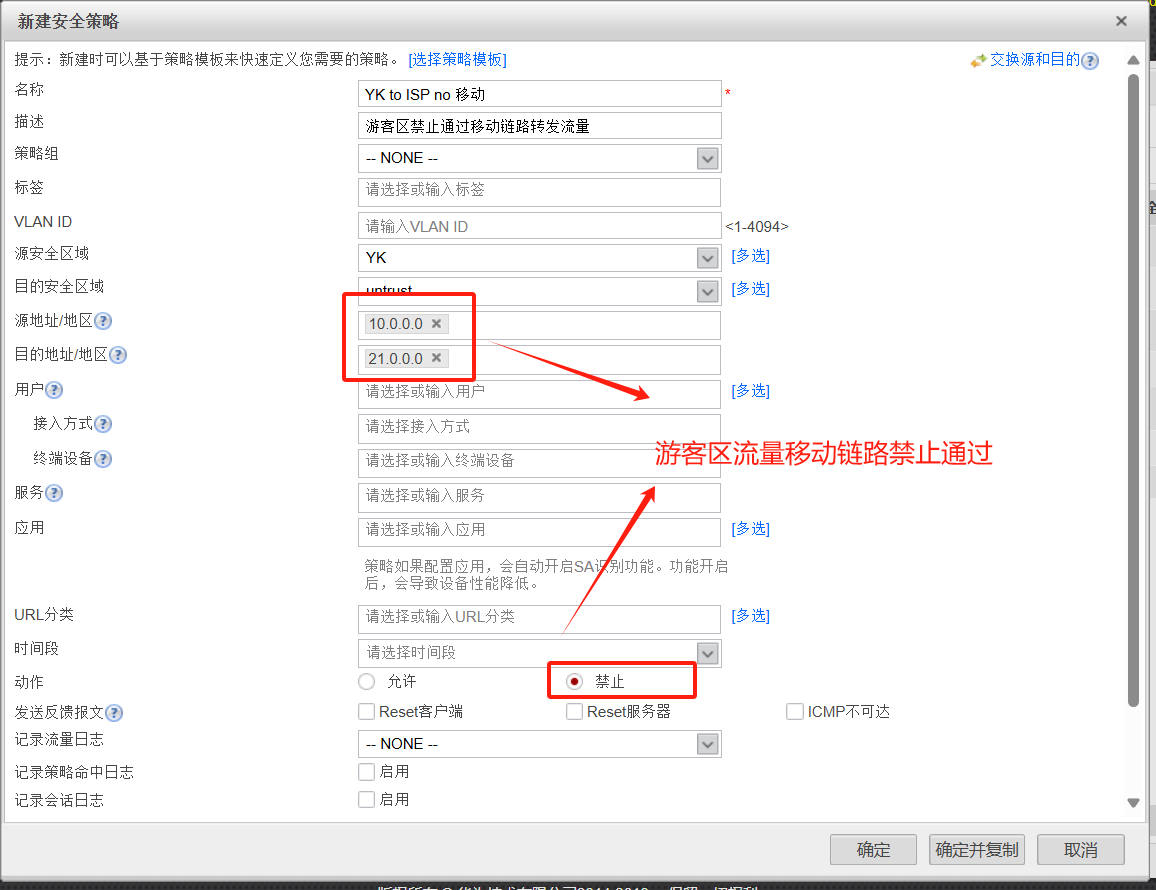
华为模拟器防火墙配置实验(二)
一.实验拓扑 二.实验要求 1,DMZ区内的服务器,办公区仅能在办公时间内(9:00 - 18:00)可以访问,生产区的设备全天可以访问. 2,生产区不允许访问互联网,办公区和游客区允许…...

group 与查询字段
需求 每周周一,统计菜单在过去一周,点击次数,和点击人数(同一个人访问多次按一次计算) 表及数据 日志表 CREATE TABLE t_data_log ( id varchar(50) NOT NULL COMMENT 主键id, operation_object varchar(500) DE…...

PlantUML 教程:绘制时序图
绘制时序图是 PlantUML 的一个强大功能,下面是详细的 PlantUML 时序图教程,帮助你理解如何使用它来创建清晰的时序图。 基本概念 时序图(Sequence Diagram)用于展示对象之间的交互以及它们之间的消息传递顺序。它主要由以下元素…...

ARM PMU外部接口与性能监控寄存器详解
1. ARM性能监控寄存器外部接口深度解析性能监控单元(PMU)是现代处理器架构中用于硬件性能分析的核心模块,它通过一组可编程计数器实时捕获处理器微架构层面的各类事件。在ARMv8/v9架构中,PMU不仅可以通过系统寄存器访问,还提供了标准化的外部…...

BLE四大广播模式详解:可连接/不可连接/定向/周期广播
一、前言在低功耗蓝牙(BLE)开发中,广播(Advertising)是设备发现、连接建立、数据广播、设备重连的核心基石,所有BLE交互流程均始于广播报文的收发。不同于传统经典蓝牙,BLE所有广播行为标准化、…...

鸿蒙系统微博应用锁常见问题解答
为微博设置应用锁后,不少用户会有各种疑问:忘记密码怎么办?会不会影响消息推送?能不能只锁定某些功能?应用锁耗电吗?本文将针对这些高频问题逐一解答,帮助您更好地使用鸿蒙系统(Harm…...

打不开JupyterLab
因为安装某些依赖导致JupyterLab的依赖被动升级或降级,从而影响了JupyterLab的运行,此时可以SSH登录到实例,然后输入jupyter-lab命令进行确认,如果执行命令报错则说明是此问题,那么可以通过pip install jupyterlab再次…...

差分隐私GDP机制紧密度量化:从隐私剖面到∆度量的实践指南
1. 差分隐私GDP机制:从理论到实践,如何量化隐私保护紧密度在差分隐私(Differential Privacy, DP)的实际部署中,尤其是在机器学习的隐私保护训练(如DP-SGD)场景里,我们常常面临一个核…...

如何在浏览器中一键解密所有加密音乐文件:Unlock-Music完全指南
如何在浏览器中一键解密所有加密音乐文件:Unlock-Music完全指南 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地…...
)
别再手动测模型了!用Simulink Test Manager实现自动化测试(附Excel表格配置详解)
从手动测试到智能验证:Simulink Test Manager全流程自动化实战指南 在模型开发的迭代过程中,工程师们常常陷入"修改-测试-记录"的循环泥潭。每次参数调整后,手动运行模型、记录数据、比对结果不仅消耗大量时间,更可能因…...

PS5 NOR Modifier深度解析:如何通过Windows工具修复PS5硬件故障与实现光驱版转数字版
PS5 NOR Modifier深度解析:如何通过Windows工具修复PS5硬件故障与实现光驱版转数字版 【免费下载链接】PS5NorModifier The PS5 Nor Modifier is an easy to use Windows based application to rewrite your PS5 NOR file. This can be useful if your NOR is corru…...

如何在5分钟内使用CrewAI Studio快速搭建AI工作流:零代码AI智能体开发终极指南
如何在5分钟内使用CrewAI Studio快速搭建AI工作流:零代码AI智能体开发终极指南 【免费下载链接】CrewAI-Studio A user-friendly, multi-platform GUI for managing and running CrewAI agents and tasks. Supports Conda and virtual environments, no coding need…...

如何优化 MySQL 千万级数据分页查询的性能?
它的本质是:**传统 LIMIT offset, size 在大数据量下性能急剧下降,是因为 MySQL 必须 扫描并丢弃 前 offset 行数据。当 offset 很大时(如 LIMIT 1000000, 10),MySQL 需要读取 1,000,010 行记录,执行 1,000…...