240713_昇思学习打卡-Day25-LSTM+CRF序列标注(4)
240713_昇思学习打卡-Day25-LSTM+CRF序列标注(4)
最后一天咯,做第四部分。
BiLSTM+CRF模型
在实现CRF后,我们设计一个双向LSTM+CRF的模型来进行命名实体识别任务的训练。模型结构如下:
nn.Embedding -> nn.LSTM -> nn.Dense -> CRF
其中LSTM提取序列特征,经过Dense层变换获得发射概率矩阵,最后送入CRF层。具体实现如下:
# 定义双向LSTM结合CRF的序列标注模型
class BiLSTM_CRF(nn.Cell):def __init__(self, vocab_size, embedding_dim, hidden_dim, num_tags, padding_idx=0):"""初始化BiLSTM_CRF模型。参数:vocab_size: 词汇表大小。embedding_dim: 词嵌入维度。hidden_dim: LSTM隐藏层维度。num_tags: 标签种类数量。padding_idx: 填充索引,默认为0。"""super().__init__()# 初始化词嵌入层self.embedding = nn.Embedding(vocab_size, embedding_dim, padding_idx=padding_idx)# 初始化双向LSTM层self.lstm = nn.LSTM(embedding_dim, hidden_dim // 2, bidirectional=True, batch_first=True)# 初始化从LSTM输出到标签的全连接层self.hidden2tag = nn.Dense(hidden_dim, num_tags, 'he_uniform')# 初始化条件随机场层self.crf = CRF(num_tags, batch_first=True)def construct(self, inputs, seq_length, tags=None):"""模型的前向传播方法。参数:inputs: 输入序列,形状为(batch_size, seq_length)。seq_length: 序列长度,形状为(batch_size,)。tags: 真实标签,形状为(batch_size, seq_length),可选。返回:crf_outs: CRF层的输出,如果输入了真实标签则为损失值,否则为解码后的标签序列。"""# 通过词嵌入层获取词向量表示embeds = self.embedding(inputs)# 通过双向LSTM层获取序列特征outputs, _ = self.lstm(embeds, seq_length=seq_length)# 通过全连接层转换LSTM输出到标签空间feats = self.hidden2tag(outputs)# 通过CRF层计算损失或解码crf_outs = self.crf(feats, tags, seq_length)return crf_outs完成模型设计后,我们生成两句例子和对应的标签,并构造词表和标签表。
# 设置词嵌入维度和隐藏层维度
embedding_dim = 16
hidden_dim = 32# 定义训练数据集,每条数据包含一个分词后的句子和相应的实体标签
training_data = [("清 华 大 学 坐 落 于 首 都 北 京".split(), # 分词后的句子"B I I I O O O O O B I".split() # 相应的实体标签),("重 庆 是 一 个 魔 幻 城 市".split(), # 分词后的句子"B I O O O O O O O".split() # 相应的实体标签)
]# 初始化词典,用于映射词到索引
word_to_idx = {}
# 添加特殊填充词到词典
word_to_idx['<pad>'] = 0
# 遍历训练数据,构建词到索引的映射
for sentence, tags in training_data:for word in sentence:# 如果词不在词典中,则添加到词典if word not in word_to_idx:word_to_idx[word] = len(word_to_idx)# 初始化标签到索引的映射
tag_to_idx = {"B": 0, "I": 1, "O": 2}len(word_to_idx)
接下来实例化模型,选择优化器并将模型和优化器送入Wrapper。
由于CRF层已经进行了NLLLoss的计算,因此不需要再设置Loss。
# 实例化BiLSTM_CRF模型,传入词汇表大小、词嵌入维度、隐藏层维度以及标签种类数量
model = BiLSTM_CRF(len(word_to_idx), embedding_dim, hidden_dim, len(tag_to_idx))# 初始化随机梯度下降优化器,设置学习率为0.01,权重衰减为1e-4
optimizer = nn.SGD(model.trainable_params(), learning_rate=0.01, weight_decay=1e-4)# 使用MindSpore的value_and_grad函数创建一个函数,它会同时计算模型的损失值和梯度
# 第二个参数设置为None表示不保留反向图,第三个参数是优化器的参数列表
grad_fn = ms.value_and_grad(model, None, optimizer.parameters)def train_step(data, seq_length, label):"""训练步骤函数,执行一次前向传播和反向传播更新模型参数。参数:data: 输入数据,形状为(batch_size, seq_length)。seq_length: 序列长度,形状为(batch_size,)。label: 真实标签,形状为(batch_size, seq_length)。返回:loss: 当前批次的损失值。"""# 使用grad_fn计算损失值和梯度loss, grads = grad_fn(data, seq_length, label)# 使用优化器更新模型参数optimizer(grads)# 返回损失值return loss将生成的数据打包成Batch,按照序列最大长度,对长度不足的序列进行填充,分别返回输入序列、输出标签和序列长度构成的Tensor。
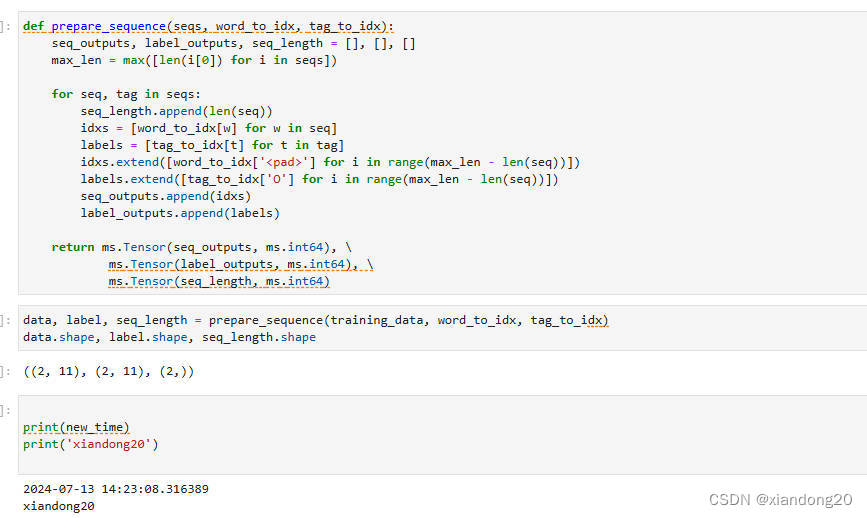
def prepare_sequence(seqs, word_to_idx, tag_to_idx):"""准备序列数据,包括填充和转换成张量。参数:seqs: 一个包含句子和对应标签的元组列表。word_to_idx: 词到索引的映射字典。tag_to_idx: 标签到索引的映射字典。返回:seq_outputs: 填充后的序列数据张量。label_outputs: 填充后的标签数据张量。seq_length: 序列的真实长度列表。"""seq_outputs, label_outputs, seq_length = [], [], []# 获取最长序列长度max_len = max([len(i[0]) for i in seqs])for seq, tag in seqs:# 记录序列的真实长度seq_length.append(len(seq))# 将序列中的词转换为索引idxs = [word_to_idx[w] for w in seq]# 将标签转换为索引labels = [tag_to_idx[t] for t in tag]# 对序列进行填充idxs.extend([word_to_idx['<pad>'] for i in range(max_len - len(seq))])# 对标签进行填充,用'O'的索引填充labels.extend([tag_to_idx['O'] for i in range(max_len - len(seq))])# 添加填充后的序列和标签到列表seq_outputs.append(idxs)label_outputs.append(labels)# 将列表转换为MindSpore张量return ms.Tensor(seq_outputs, ms.int64), \ms.Tensor(label_outputs, ms.int64), \ms.Tensor(seq_length, ms.int64)# 调用prepare_sequence函数处理训练数据,并获取处理后的数据、标签和序列长度
data, label, seq_length = prepare_sequence(training_data, word_to_idx, tag_to_idx)# 打印处理后的数据、标签和序列长度的形状,以确认数据转换是否正确
print(data.shape, label.shape, seq_length.shape)
对模型进行预编译后,训练500个step。
训练流程可视化依赖
tqdm库,可使用pip install tqdm命令安装。
from tqdm import tqdm# 定义训练步骤的总数,用于进度条的设置
steps = 500# 使用tqdm创建一个进度条,总进度为steps
with tqdm(total=steps) as t:for i in range(steps):# 执行单步训练,这里假设train_step是一个已定义的训练函数# 参数data为训练数据,seq_length为序列长度,label为标签loss = train_step(data, seq_length, label)# 更新进度条的附带信息,显示当前的损失值t.set_postfix(loss=loss)# 更新进度条,表示完成了一步训练t.update(1)最后我们来观察训练500个step后的模型效果,首先使用模型预测可能的路径得分以及候选序列。
# 调用模型进行预测或评估,返回得分和历史记录
score, history = model(data, seq_length)# 输出得分,用于查看模型的表现或决策
score使用后处理函数进行预测得分的后处理。
predict = post_decode(score, history, seq_length)
predict
最后将预测的index序列转换为标签序列,打印输出结果,查看效果。
# 通过索引和标签的映射关系,构建标签到索引的反向映射
idx_to_tag = {idx: tag for tag, idx in tag_to_idx.items()}def sequence_to_tag(sequences, idx_to_tag):"""将序列中的索引转换为对应的标签。参数:sequences: 一个包含标签索引的序列列表。idx_to_tag: 一个字典,用于将索引映射到对应的标签。返回:一个列表,其中每个元素是输入序列中索引转换为标签后的结果。"""# 初始化一个空列表,用于存储转换后的标签序列outputs = []# 遍历输入的序列列表for seq in sequences:# 对每个序列,将索引转换为标签,并添加到输出列表中outputs.append([idx_to_tag[i] for i in seq])# 返回转换后的标签序列列表return outputssequence_to_tag(predict, idx_to_tag)
打卡照片:
相关文章:
240713_昇思学习打卡-Day25-LSTM+CRF序列标注(4)
240713_昇思学习打卡-Day25-LSTMCRF序列标注(4) 最后一天咯,做第四部分。 BiLSTMCRF模型 在实现CRF后,我们设计一个双向LSTMCRF的模型来进行命名实体识别任务的训练。模型结构如下: nn.Embedding -> nn.LSTM -&…...

python requests关闭https校验
python requests关闭https校验 import requests# 关闭SSL验证 requests.get(https://***.com, verifyFalse)...

PG大会周五于杭州举办;Pika发布4.0;阿里云MySQL上线Zero-ETL集成能力
重要更新 1. PostgreSQL中国技术大会举行12日(周五)于杭州举办,是PostgreSQL社区年度的大会,举办地点:杭州君尚云郦酒店(杭州市上城区临丁路1188号),感兴趣的可以考虑现场参加 ( [1]…...
虚拟机vmware网络设置
一、网络分类 打开vmware workstation网络编辑器可以知道有三种网络类型,分别是:桥接模式、nat模式、仅主机模式。 1、桥接模式 桥接模式是将主机网卡与虚拟机虚拟的网卡利用虚拟网桥进行通信。在桥接的作用下, 类似于把物理主机虚拟为一个交换机, 所有设…...
数学建模国赛入门指南
文章目录 认识数学建模及国赛认识数学建模什么是数学建模?数学建模比赛 国赛参赛规则、评奖原则如何评省、国奖评奖规则如何才能获奖 国赛赛题分类及选题技巧国赛赛题特点赛题分类 国赛历年题型及优秀论文 数学建模分工技巧数模必备软件数模资料文献数据收集资料收集…...
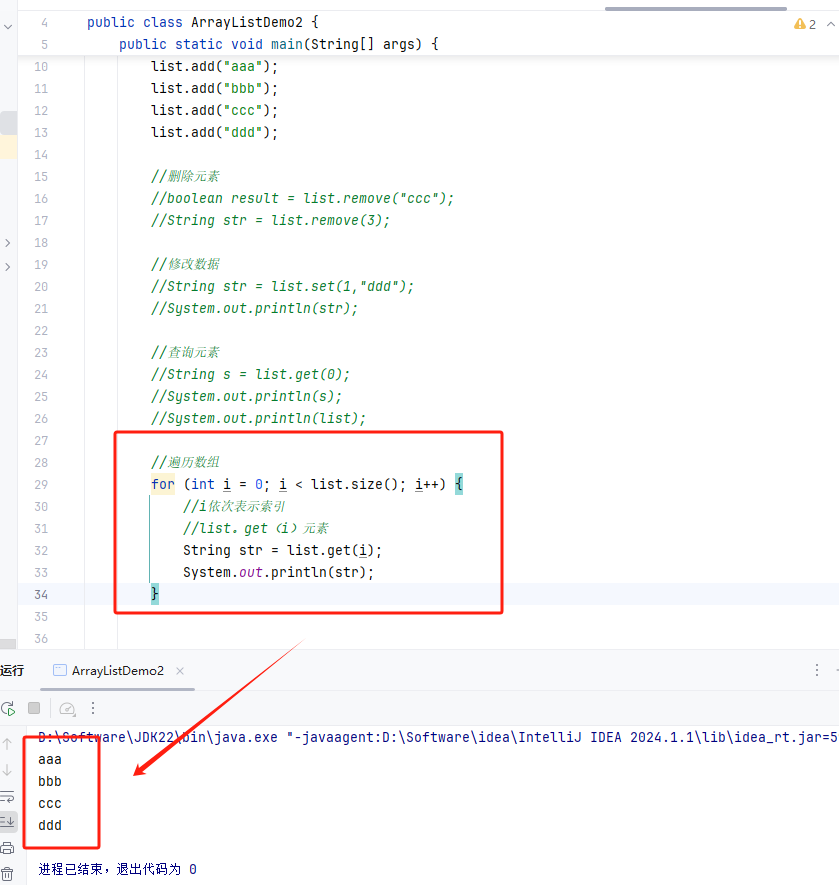
Java基础之集合
集合和数组的类比 数组: 长度固定可以存基本数据类型和引用数据类型 集合: 长度可变只能存引用数据类型存储基本数据类型要把他转化为对应的包装类 ArrayList集合 ArrayList成员方法 添加元素 删除元素 索引删除 查询 遍历数组...

深度学习和NLP中的注意力和记忆
深度学习和NLP中的注意力和记忆 文章目录 一、说明二、注意力解决了什么问题?#三、关注的代价#四、机器翻译之外的关注#五、注意力(模糊)记忆?# 一、说明 深度学习的最新趋势是注意力机制。在一次采访中,现任 OpenAI 研…...

自用的C++20协程学习资料
C20的一个重要更新就是加入了协程。 在网上找了很多学习资料,看了之后还是不明白。 最后找到下面这些资料总算是讲得比较明白,大家可以按照顺序阅读: 渡劫 C 协程(1):C 协程概览C20协程原理和应用...
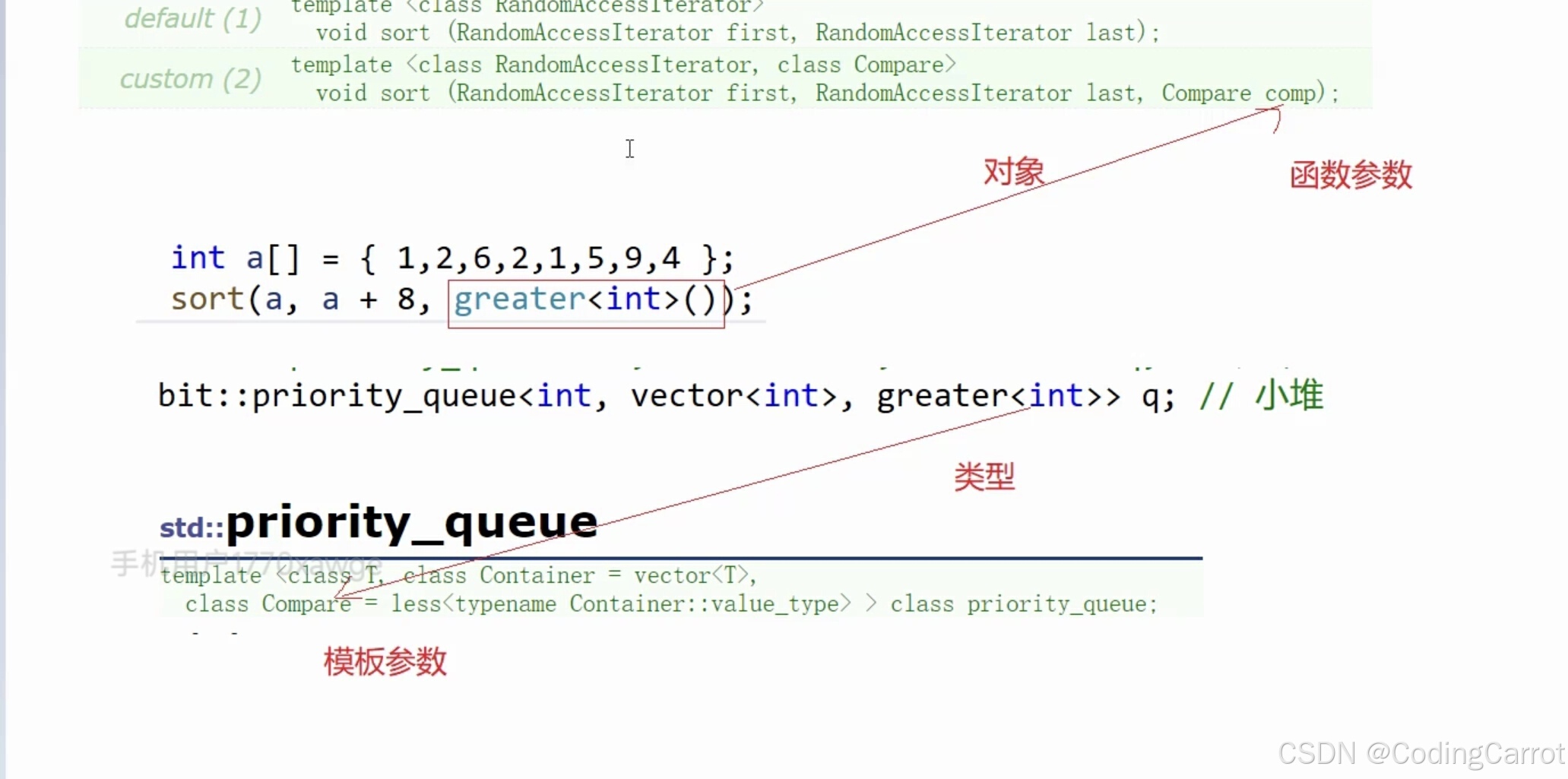
【C++】优先级队列(底层代码解释)
一. 定义 优先级队列是一个容器适配器,他可以根据不同的需求采用不同的容器来实现这个数据结构,优先级队列采用了堆的数据结构,默认使用vector作为容器,且采用大堆的结构进行存储数据。 (1)在第一个构造函数…...
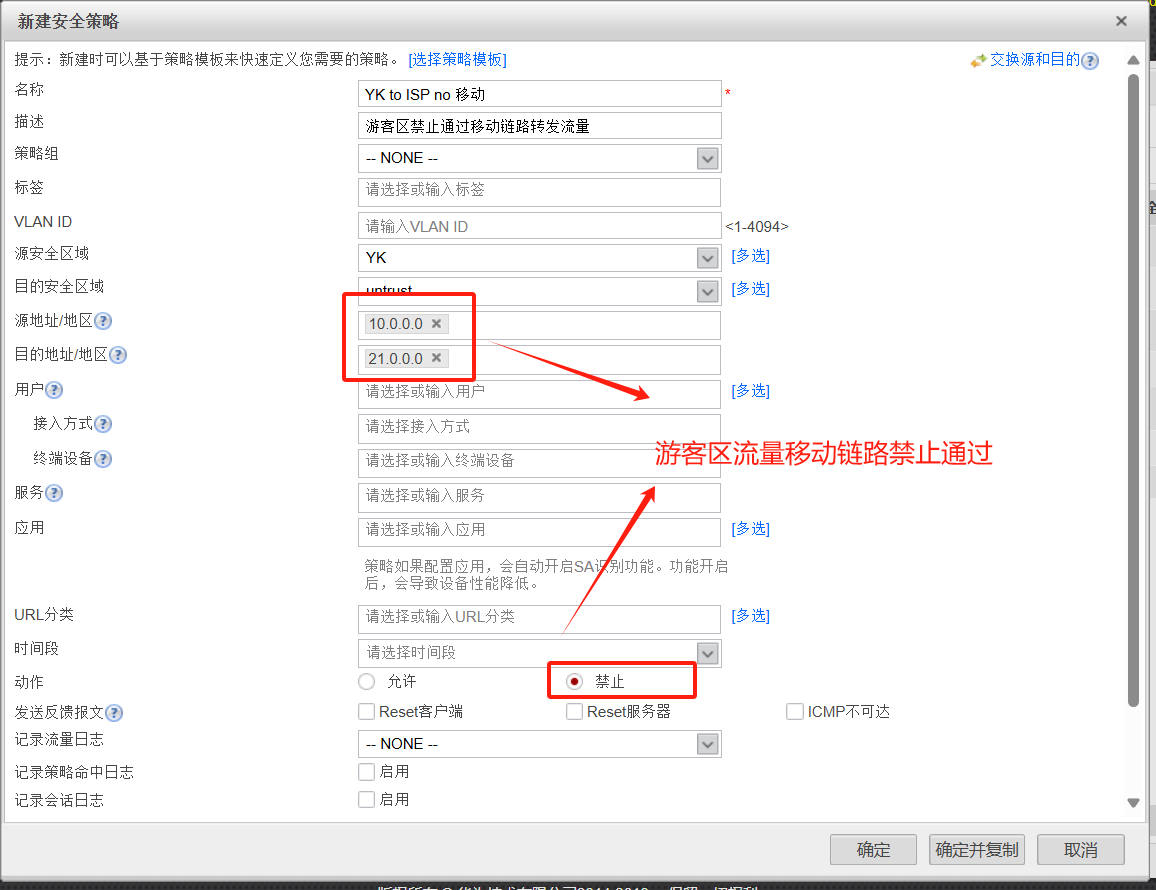
华为模拟器防火墙配置实验(二)
一.实验拓扑 二.实验要求 1,DMZ区内的服务器,办公区仅能在办公时间内(9:00 - 18:00)可以访问,生产区的设备全天可以访问. 2,生产区不允许访问互联网,办公区和游客区允许…...

group 与查询字段
需求 每周周一,统计菜单在过去一周,点击次数,和点击人数(同一个人访问多次按一次计算) 表及数据 日志表 CREATE TABLE t_data_log ( id varchar(50) NOT NULL COMMENT 主键id, operation_object varchar(500) DE…...

PlantUML 教程:绘制时序图
绘制时序图是 PlantUML 的一个强大功能,下面是详细的 PlantUML 时序图教程,帮助你理解如何使用它来创建清晰的时序图。 基本概念 时序图(Sequence Diagram)用于展示对象之间的交互以及它们之间的消息传递顺序。它主要由以下元素…...
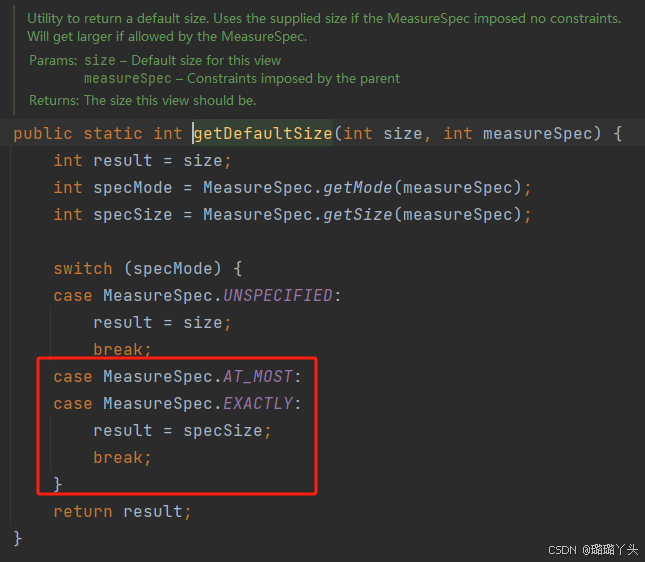
自定义ViewGroup-流式布局FlowLayout(重点:测量和布局)
效果 child按行显示,显示不下就换行。 分析 继承ViewGrouponDraw()不重写,使用ViewGroup的测量-重点 (测量child、测量自己)布局-重点 (布局child) 知识点 执行顺序 构造函数 -> onMeasure() -> …...
C++的入门基础(二)
目录 引用的概念和定义引用的特性引用的使用const引用指针和引用的关系引用的实际作用inlinenullptr 引用的概念和定义 在语法上引用是给一个变量取别名,和这个变量共用同一块空间,并不会给引用开一块空间。 取别名就是一块空间有多个名字 类型& …...

显示产业如何突破芯片短板
尽管中国在显示IC领域面临一定的不足,但新技术的不断涌现为中国企业提供了重要的发展机遇。随着手机、平板电脑和液晶电视对显示屏性能要求的不断提高,显示驱动IC也必须相应地发展,向更高分辨率、更大尺寸和更低功耗的方向迈进。例如…...
STM32HAL库+ESP8266+cJSON+微信小程序_连接华为云物联网平台
STM32HAL库ESP8266cJSON微信小程序_连接华为云物联网平台 实验使用资源:正点原子F407 USART1:PA9P、A10(串口打印调试) USART3:PB10、PB11(WiFi模块) DHT11:PG9(采集数据…...

debian或Ubuntu中开启ssh允许root远程ssh登录的方法
debian或Ubuntu中开启ssh允许root远程ssh登录的方法 前因: 因开发需要,需要设置开发板的ssh远程连接。 操作步骤如下: 安装openssh-server sudo apt install openssh-server设置root用户密码: sudo passwd root允许root用户…...

C++《日期》实现
C《日期》实现 头文件实现文件 头文件 在该文件中是为了声明函数和定义类成员 using namespace std; class Date {friend ostream& operator<<(ostream& out, const Date& d);//友元friend istream& operator>>(istream& cin, Date& d);//…...
)
【面试题】MySQL(第三篇)
目录 1. MySQL中如何处理死锁? 2. MySQL中的主从复制是如何实现的? 3. MySQL中的慢查询日志是什么?如何使用它来优化性能? 4.存储过程 一、定义与基本概念 二、特点与优势 三、类型与分类 四、创建与执行 五、示例 六、总…...

tensorflow之欠拟合与过拟合,正则化缓解
过拟合泛化性弱 欠拟合解决方法: 增加输入特征项 增加网络参数 减少正则化参数 过拟合的解决方法: 数据清洗 增大训练集 采用正则化 增大正则化参数 正则化缓解过拟合 正则化在损失函数中引入模型复杂度指标,利用给w增加权重,…...

Rydberg原子量子门实现原理与优化技术
1. Rydberg原子平台中的量子门实现基础1.1 Rydberg原子特性与量子计算优势Rydberg原子是指外层电子被激发到高主量子数能级的原子态,这类原子具有三个关键特性使其成为量子计算的理想平台:强偶极-偶极相互作用:当两个原子同时处于Rydberg态时…...

别再只用Service了!ROS1 Action通信保姆级教程:从导航进度条到任务取消,手把手教你实现带反馈的机器人任务
别再只用Service了!ROS1 Action通信保姆级教程:从导航进度条到任务取消,手把手教你实现带反馈的机器人任务当你的机器人正在执行一个长达10分钟的导航任务时,突然发现目标点设置错误,这时候如果只能干等着任务完成或者…...
)
ParaView时间戳设置全攻略:从基础标注到自定义格式(5.8.0实测)
ParaView时间戳设置全攻略:从基础标注到自定义格式(5.8.0实测) 在科学可视化领域,时间戳不仅是数据演变的见证者,更是研究成果呈现的专业语言。ParaView作为开源可视化工具链的标杆,其时间标注功能在学术论…...

iPaaS 应用场景深度解析:从系统孤岛到数据自由流动的六大实战路径
写在前面 一个企业的数字化程度越高,系统就越多。系统越多,集成问题就越严重。 这不是假设,而是我们在服务客户过程中反复验证的结论——企业数字化转型的瓶颈,往往不在于"造新系统",而在于"连老系统&q…...

别再死记硬背SMO公式了!用Python手写一个SVM分类器,带你一步步拆解SMO核心逻辑
用Python手写SVM分类器:代码驱动理解SMO算法核心在机器学习领域,支持向量机(SVM)以其优秀的分类性能和坚实的数学基础著称。然而,许多学习者在理解其核心算法——序列最小优化(SMO)时,往往被复杂的数学推导所困扰。本文将采用一种…...

1901-2022年中国气温变化分析实战:用这份1km栅格数据我们能发现什么?
1901-2022年中国气温变化分析实战:如何从1km栅格数据中挖掘气候演变规律当一份覆盖122年、分辨率精确到1公里的气温栅格数据摆在面前时,我们看到的不仅是数字矩阵,更是一部写在经纬度坐标里的气候变迁史诗。这份由逐月数据聚合生成的逐年气温…...
)
保姆级避坑指南:在Ubuntu 22.04上搞定ROS2 Humble、PX4与Gazebo的联合仿真(附Empy版本降级)
保姆级避坑指南:Ubuntu 22.04下ROS2 Humble与PX4联合仿真的21个关键陷阱当你在Ubuntu 22.04上第一次尝试搭建ROS2 Humble、PX4与Gazebo的联合仿真环境时,可能会遇到比预期更多的挑战。这不是一个简单的"复制粘贴命令就能完成"的任务——版本冲…...
)
在线文档协作工具选型必看:14款产品对比(2026版)
一、在线文档协作工具的概念解析及其核心功能 在线文档协作工具是基于云端的文档创建、编辑、共享与协同沟通平台,核心目标是让团队在同一份资料上“实时共同工作”,减少反复传文件、版本混乱与沟通成本。 企业常见的核心能力包括: 多人实…...

构建智能音乐档案:SoundCloud Downloader 的技术架构与实现哲学
构建智能音乐档案:SoundCloud Downloader 的技术架构与实现哲学 【免费下载链接】scdl Soundcloud Music Downloader 项目地址: https://gitcode.com/gh_mirrors/sc/scdl 在流媒体音乐主导的时代,音乐爱好者面临着一种矛盾:我们享受着…...

如何在5分钟内使用CrewAI Studio快速搭建AI工作流:零代码AI智能体开发终极指南
如何在5分钟内使用CrewAI Studio快速搭建AI工作流:零代码AI智能体开发终极指南 【免费下载链接】CrewAI-Studio A user-friendly, multi-platform GUI for managing and running CrewAI agents and tasks. Supports Conda and virtual environments, no coding need…...